


摘" 要:针对目前学科知识图谱缺乏学习者学习行为信息的问题,以操作系统课程为例,以教材和百度百科为主要数据源,设计操作系统课程本体库,并依照设计的本体结构构建课程知识图谱,同时将在线开放平台上142名学生产生的学习数据作为学习反馈,对课程知识图谱进行动态更新,使得知识图谱能根据学生对知识点掌握程度,进行动态的学习路径规划和学习资源推荐,对构建动态环境中的自适应学科知识图谱具有相应的参考价值。
关键词:智慧教育;学习反馈;自适应;知识图谱;操作系统
中图分类号:TP391.1" " " 文献标识码:A 文章编号:2096-4706(2024)24-0182-08
Construction of Adaptive Knowledge Graph with Learning Feedback
—Taking the Operating System Course as an Example
WANG Quanrui
(School of Computer Science and Technology, Henan Institute of Science and Technology, Xinxiang" 453003, China)
Abstract: In view of the problem that current subject Knowledge Graph lacks learners learning behavior information, this paper takes the operating system course as an example, designs the operating system course ontology library with textbooks and Baidu Baike as the main data sources, and constructs the course Knowledge Graph according to the designed ontology structure. Meanwhile, the learning data generated by 142 students on the online open platform is taken as learning feedback to dynamically update the course Knowledge Graph. In this way, the Knowledge Graph can conduct dynamic learning path planning and provide learning resource recommendation according to students mastery degree of knowledge points. It has corresponding reference value for constructing an adaptive discipline Knowledge Graph in a dynamic environment.
Keywords: smart education; learning feedback; adaptability; Knowledge Graph; operating system
0" 引" 言
在人工智能、大数据技术的飞速发展的同时也为教育机构在学科教育方面提供了更智能化的数据存储、分析、管理和决策支持,推动着学科教育朝着更智慧的方向发展。与此同时随着网络教育的兴起,涌现了大量的在线学习平台,如中国大学MOOC、学堂在线、超星、智慧树网等,这些在线学习平台打破了传统教育的时空限制,使得教育资源更均衡化,在逐步扩大了教育的普及面的同时也加速了教育的高质量发展。在线学习平台俨然已成为学习者学习的主要阵地,而线上学习也将成为学习者主要的学习方式。然而面对网络中浩瀚的学习资源,如何使得学习者在数据迷航中找到正确的方向识别有用的信息,如何帮助学习者在信息过载的网络中通过信息重组发现知识,是知识图谱在自动构建、自适应更新方面亟待解决的关键问题。
在教育领域中,教育大数据主要包括教育管理数据、教育行为数据、教育情景和环境数据、教育其他数据,蕴含了丰富的用户行为和偏好信息。目前在智慧教育发展初期,这些教育大数据多是以无序、分散、异构的形式出现且没有被有效地组织与管理、利用与共享、搜索与理解[1-2]。通过知识图谱,可以将教育领域海量异质数据整合为一个直观可理解的语义知识网络,由此很好的实现知识融合。因此教育领域中的知识图谱构建任务不仅是知识导航视角下生成面向学习目标的个性化学习路径推荐的基础工作,也是学习认知视角下形成学习者的认知图式的基础,还是知识库视角下以计算机可“理解”的方式存储教育领域知识的结构化语义知识库的关键性工作[3]。
1" 现状分析
知识图谱以揭示知识间的逻辑关系为表征,广泛渗透到教育技术领域,衍生了教育知识图谱和学科知识图谱等概念[4]。学科知识图谱作为认知智能技术,可有效将各类学科知识与资源建序优化,并以动态语义图式结构,映射学习者高阶认知活动[5]。通过构建学科知识图谱可以将割裂无序状态的知识进行重组进而表示成具有语义关系的知识网络,优化学科知识表示并为学习者提供个性化服务,由此实现网络资源从数据到信息再到知识的自动转化,提高学习者的高阶认知活动和深度学习能力。
美国早在2008年就开始将知识图谱应用到教育学科领域,通过建立知识地图来增强教学效果。国内在这一方面的应用研究稍晚于国外,2012年在谷歌正式提出知识图谱概念之后,才在真正意义上出现了使用引文分析方法构建教育技术学科知识图谱的研究,随着智慧教育理念的提出和深度学习技术的发展,学科知识图谱构建研究和应用而快速发展。目前学科知识图谱主要应用于学情诊断、智慧课堂、自适应学习、深度阅读等场景,并逐渐成为教育研究机构和学术研究者关注的重点。美国Knewton自适应学习平台是当前最为成熟的自适应学习平台之一[6],它在知识图谱的支持下通过不断完善自适应反馈链路,为用户提供自适应学习服务;北京师范大学智慧学习研究团队构建的唐诗语义检索与可视化平台基于知识图谱技术,对诗歌的主题、情感、风格,诗人的轨迹、社交关系等实现了全方位的抽取和可视化呈现[7];北京师范大学未来教育高精尖创新中心设计和开发的“AI好老师”智能助理系统通过不同的育人数据定义育人知识模式,进行知识的获取和融合,构建育人领域的知识图谱[8];学者陆星儿等人以学堂在线“心理学概论”课程为例,采用共词分析法和社会网络分析法建立基于课程知识点的知识图谱,并将其作为优化MOOC教学的一种可视化方式[9];周东岱等人针对目前学科知识图谱缺少教与学的动态行为信息,提出了学科教学图谱的概念,并解析了其深层内涵,建构了学科知识、学科学习活动、学生学科认知发展三视图融合的结构模型[10]。郑志宏等人以学科知识图谱构建过程为研究对象,分析并实施学科知识图谱技术路线,提炼大单元特征提取与质量评估方法,构建出面向大单元设计的信息科技学科知识图谱[11]。
不同学科领域的知识图谱涉及知识的内容和形式往往差别很大,而要保证学科知识的准确性、完备性、系统性和科学性,就会使得构建学科知识图谱很难借鉴其他领域知识图谱构建的方法和流程。而目前学科知识图谱大都是在静态环境下构建的,导致知识图谱很难反映学习者的学习状态、学习能力、学习偏好等动态特征,严重降低了知识图谱在个性化学习路径规划和推荐上的可解释性。因此本文试图将自适应学习引入到学科知识图谱的构建过程中,将学习者的在线学习行为表征于知识图谱中,使得知识图谱能够将学习者的学习行为数据作为反馈信息,自动学习并更新知识图谱知识点之间的关联关系和关联强度,同时自动调整学习者学习路径和学习资源,以提高路径生成的精准性和资源推荐的适配性。
2" 课程知识图谱概念模型
2.1" 课程概念体系
课程概念是对课程知识以一种以简明扼要的形式进行归纳总结的载体,可以看作课程知识的模型。明确课程的概念有助于梳理课程知识脉络,使课程知识体系更加条理化和清晰化,有助于学生更好地理解课程内容的本质和核心,同时也是课程知识图谱构建工作的重要基石。鉴于操作系统课程的特点,即操作系统本身是一个十分复杂庞大的系统软件,且课程与高级编程语言、数据结构与算法、计算机组成原理等多门课程相关,导致该课程的概念抽象且繁杂,容易混淆,学生在学习过程没有辅助的情况下很可能会导致学生失去学习的兴趣,使学生产生学科孤立感。因此构建清晰的课程概念体系,学生能够逐步建立对操作系统关键概念的认知框架,形成有机的知识脉络。这有助于减少概念混淆,使学生更容易掌握操作系统的核心原理和技术。
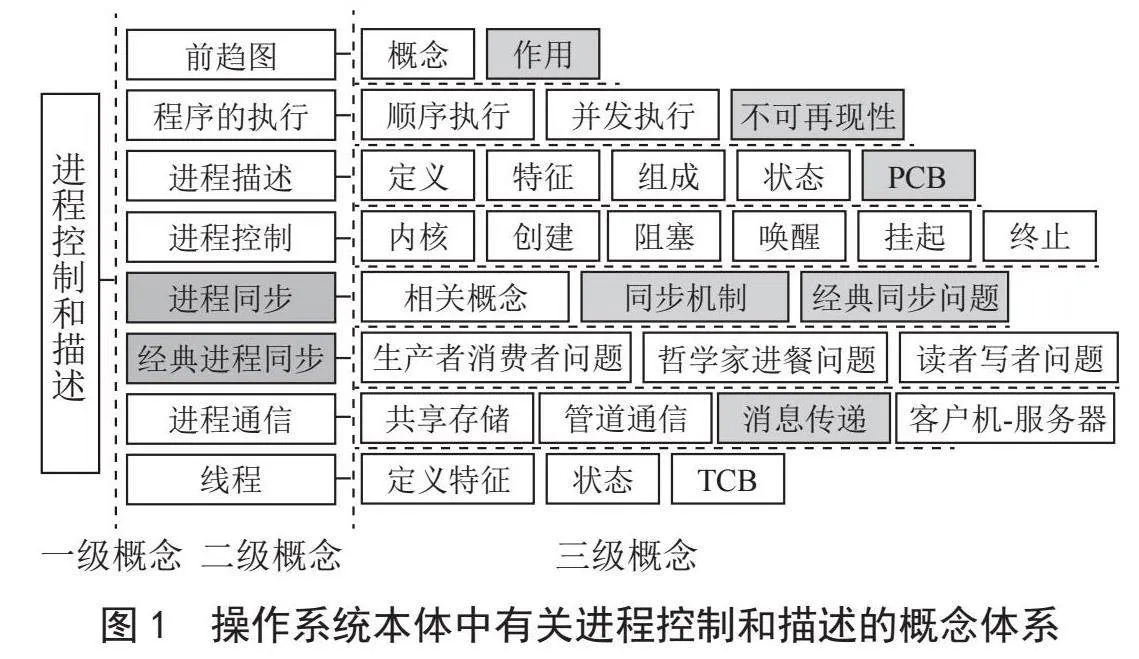
本文从基本概念和核心概念、上位概念和下位概念、实体概念和属性概念等几个维度出发,对操作系统课程相关概念进行分类,对概念进行多属性标注,同时为了更清晰的显示概念层级性,将操作系统概念分为三级。其中一级概念是依据操作系统的五大功能进行划分的,分别是:进程管理、存储器管理、设备管理、文件管理和用户接口。
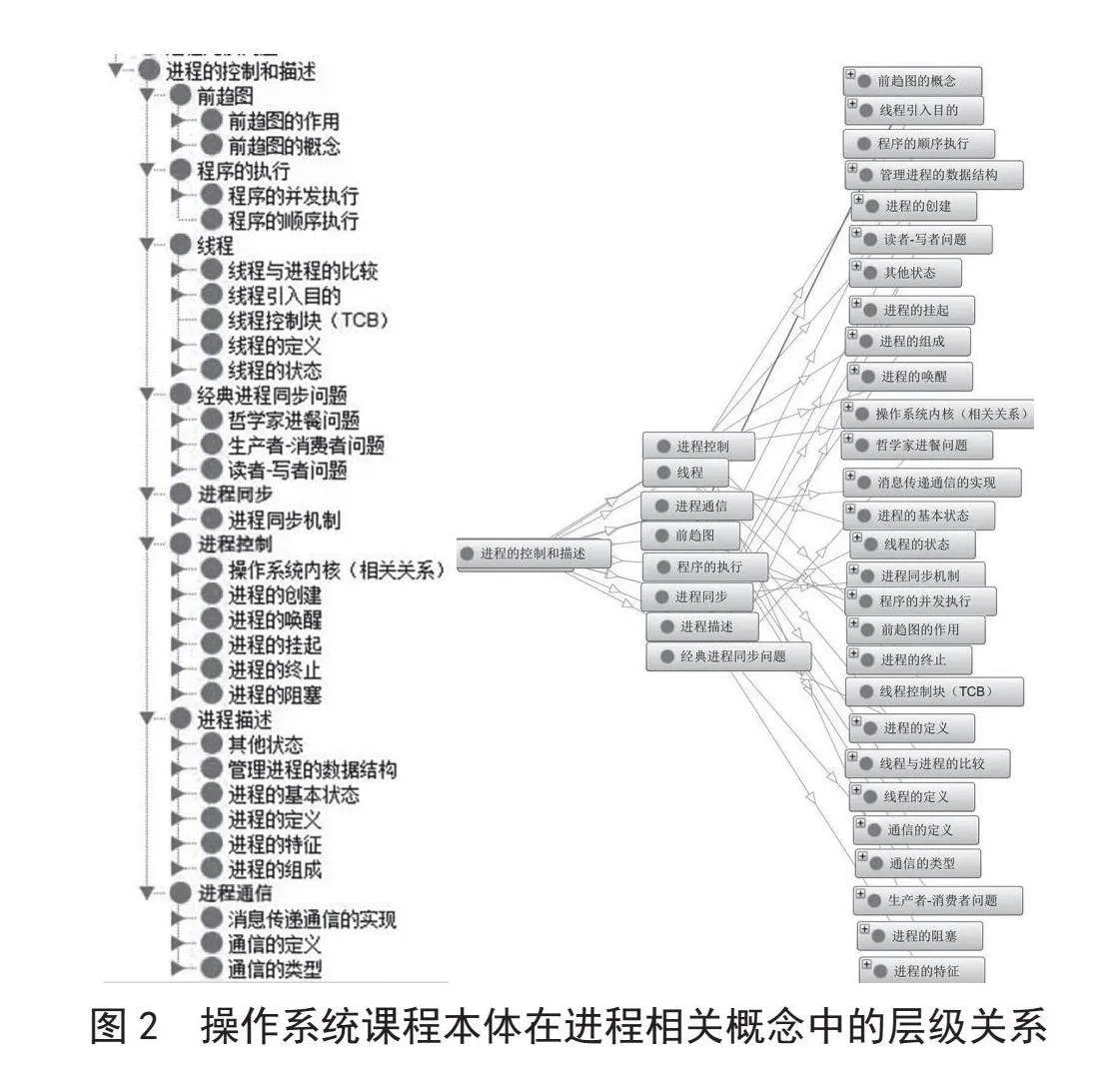
进程控制和管理部分的概念层级关系如图1所示。该概念体系同时也体现了进程管理一部分内容中概念的上下位概念关系、基本概念和核心概念的关系。
课程概念体系能够将学习目标、教学资源、学科领域等进行有机的融合,使得教师能够更好地规划和设计教学内容。构建完备的课程概念体系有助于为学习者提供清晰有序的学习路线图,同时教师能够精准地设计教学内容组织,及时调整授课进度,满足学生的个性化需求,提升教学质量。此外,课程概念体系能够为教师提供更为直观的教学资源管理组织的工具,在确保教学过程与课程内容的适配性的同时也提升了教师的教学方式的创新性。
2.2" 课程本体和关系定义
构建高质量的课程知识本体是课程知识图谱具有完备性的重要保障。通过对课程知识本体在概念层级上进行概念明确、关系约束和属性规范,可以保证后期在构建知识图谱过程中进行实体抽取、关系抽取的工作更具有指导性和更具有可靠性。操作系统课程本体分类和关系定义如下(定义1)。
定义1:操作系统课程本体分为概念concept、算法algorithm、准则guideline和目标target四类,分别对应于概念集合C = {ec1,ec2,…,ecn}、算法集合A = {ea1,ea2,…,eam}、准则集合G = {eg1,eg2,…,egk}、目标集合T = {et1,et2,…,etp},本体集由概念集、算法集、准则集和目标集组成的,即E = C∪A∪G∪T。
对于操作系统课程中归纳出的概念有如进程、内存、输入输入系统之类共478个概念;算法有如先来先服务调度算法、银行家算法、动态分区分配算法之类共28种;准则有如互斥、空闲让进、付出代价最小之类共11个;目标有如吞吐量、可靠性之类共15个。
课程本体之间存在多种关系使得本体所承载的知识形成了特定的脉络和体系。本体知识关系直接决定了知识图谱的上层应用,如学习资源推荐、学习路径查询和学习路径规划、学习偏好分析等。为了使得实体间的关系更为简洁清晰,可以将实体的属性看作实体与属性值之间的属性关系,由此本文将操作系统课程本体之间的关系归纳为四种,定义如下(定义2)。
定义2:操作系统课程本体关系分为包含关系include、递进关系progressive、相关关系correlation和属性关系attribute。具体为:
1)Include = {eci includes ecjeci,ecj∈C},包含关系有两种含义,一种是指实体与实体之间在概念范畴上具有包含和被包含的关系,如进程和父进程、子进程的关系;一种是指部分与整体的关系,如进程和程序段、相关的数据段和进程控制块的组成关系。
2)Progressive = {eci is follow ecjeci,ecj∈C},递进关系也有两种含义,一种是指本体知识在学习过程中具有先后顺序关系,如连续分配存储管理和离散存储管理的关系;一种是具有明显的时间先后发展关系,如单道批处理系统、多道批处理系统、分时系统和实时系统。
3)Correlation = {eai is relation to egi/etieci,eai∈A,egi∈G,eti∈T},相关关系是指本体知识之间具有一定的遵循关系、达到关系、对比分析关系等,如内存分配算法和最小物理块数原则、处理机调度算法和公平性目标、共享段的内存分配方法和非共享段的内存分配方法等。
4)Attribute = {eci is a attribute of ecjeci,ecj∈C},为了便于统一表示三元组,本文将实体的属性也看成是一种关系,即属性关系,如操作系统的特征是操作系统的特征属性关系,其值为并发、共享、虚拟和异步。
2.3" 课程本体库构建
目前对于学科领域中虽然还没有统一的本体构建方法,但许多学者提出了多种不同的本体构建标准,其中大家公认最具影响力的是Gruber[12]提出的本体构建的5个准则,即:明确性、一致性、可扩展性、最小编码偏好、最小本体约定。本文参照该本体构建原则,以《操作系统》教学大纲和电子教案为主要的数据源,结合百度百科相关词条,借助Protégé本体开发和管理工具,由多位领域专家参与共同完成课程知识本体的构建。
首先确定操作系统课程基本概念范畴和核心概念,参照课程大纲和教材目录初步列出课程术语;其次根据概念之间的内在逻辑关系定义概念类和类的等级关系;最后通过填充实例确定课程的三个级别上的所有本体。使用Protégé工具构建的课程本体库如图2所示。
在课程概念体系的框架下,课程本体库可以为知识图谱提供一个共享的语义框架,有助于不同的教育参与者之间更准确、一致地理解学科领域的核心概念。本体库作为知识图谱的基础,通过形式化定义领域中的概念、关系和属性,为知识图谱提供了结构化的语义信息。这种清晰的语义定义使得知识图谱的数据更具一致性和规范性。同时,本体库中的概念和关系为知识图谱中的实体和连接赋予了特定的含义,提供了丰富的上下文信息。通过这一结构化的知识表示,知识图谱的可解释性得以增强,用户能够更容易理解和解释知识图谱中的关联、推理和信息。
3" 自适应学科知识图谱构建
为了能更好地保持知识图谱中概念所表述知识点的一致性,构建知识图谱采用自顶向下的方式构建,即从本体构建开始,由领域专家依据课程知识所呈现的特点,设计和抽象对应的本体,再将本体中的概念实例化,同时抽取实体间的关系,表示为三元组存储到数据库中,初步构建静态环境下的知识图谱,用于教师教学过程。针对学生,可以使用学生在线学习行为信息来定义知识点的影响因子,由此反映学生对知识点的内化程度就,同时可以借助学生学习偏好信息为学生在知识图谱上进行学习路线规划和学习资源推荐。
3.1" 知识图谱构建框架
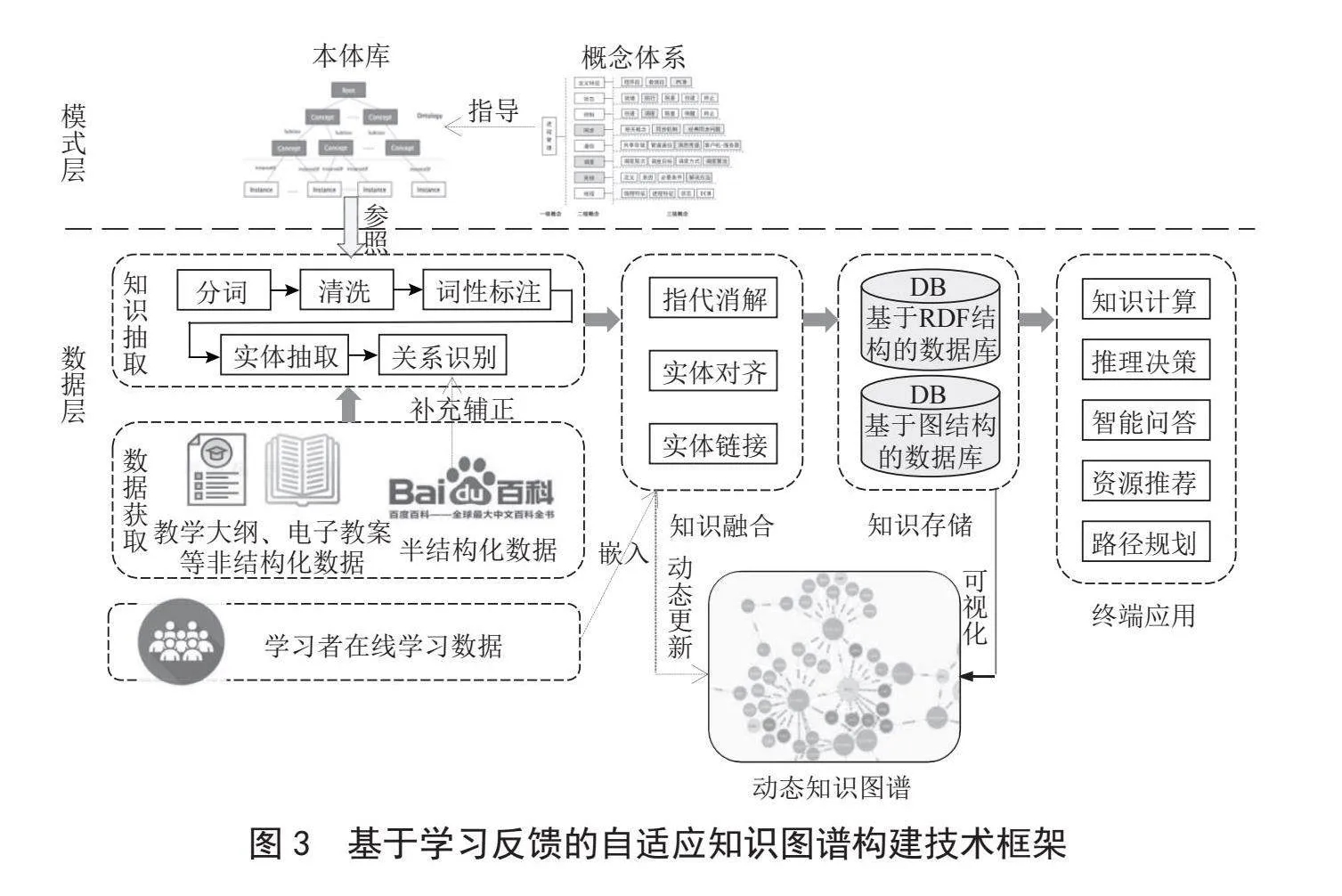
构建知识图谱的第一步是获取数据。数据主要依赖课程的电子教案和教学大纲资源,同时结合百度百科中有关操作系统的词条作为辅助信息。第二步构建本体。使用Protégé工具对通过整理收集到的数据建立一个清晰的课程本体体系框架。第三步抽取知识,包括实体抽取和关系抽取。在实体抽取阶段,首先要对文本进行分词、去除停用词等操作,之后构建一个关键词字典,以便更准确地识别和分类实体。在关系抽取阶段,为能实现半自动化的关系识别,需要事先将文本中显式表示关系的词如“分为/组成/包含”“虽然…但…”“与…不同/与…相似”等抽取出来定义为关系字典,然后利用该关系字典进行实体关系定义和分类。同时为进一步提高关系识别的精准度,采用远程监督技术,通过已知的关系信息来指导模型抽取新的关系。第四步是知识融合和更新,这是用于知识图谱管理中的一项重要任务。首先将从不同来源获得的知识整合到一个一致且完整的知识图谱中,包括去重、解决同一实体不同表述的问题,以及合并来自不同数据源的信息,确保知识的一致性和完整性;其次将知识图谱中的实体和关系表示为节点嵌入和边嵌入训练图注意力网络(Graph Attention Network, GAT)模型,并反复迭代优化模型的预测和推理新关系的性能;然后是知识图谱的自适应更新过程,通过引入学习反馈因子及时对知识图谱中的实体关系关联强度进行调整,以便能反映用户的学习偏好变化;最后是定期评估知识图谱的质量,确保用户学习行为的影响因子对知识图谱的改进是正面的。第五步是知识图谱的终端应用,包括知识计算、推理决策、智能问答、资源推荐、路径规划等。基于学习反馈的自适应知识图谱构建技术框架如图3所示。
3.2" 数据获取
3.2.1" 数据收集
本文从两个方面收集所需数据,一方面是收集课程相关的数据,包括课程大纲、教学教案、电子教材以及后期从百度百科中爬取的词条;一方面是收集学习者在线学习数据,包括学习时间数据、浏览行为数据、作业和测验数据、互动数据、学习进度数据、在线反馈数据等。
3.2.2" 数据预处理
数据预处理的工作包括对以上两种类型数据的处理。首先是对电子教材在转换过程中出现的问题进行修正,由于课程大纲和教学教案本身就是本文类型的数据不需要转换,而电子教案是PDF格式的,需要利用文本转换工具将其转换为文本数据,但是在转换的过程中会出现一些字符识别错误的问题,需要人工排查和矫正以解决该问题,并形成课程文本语料,待以后从中提出实体、关系和属性;其次是对收集的在线学习数据进行数据清洗、标准化和规范化处理,待以后将其表示为矩阵并嵌入知识图谱中。
3.3" 知识抽取
知识抽取是一种从文本数据中自动提取有价值信息的技术,其核心问题就是从结构化数据、半结构化数据、非结构化数据等大量异构数据源中自动抽取候选知识要素[13]。知识抽取过程涉及从大量文本中识别、提取和组织实体、关系和事实,以建立更有结构和可查询的知识库或图谱。知识抽取是构建学科知识图谱的重要步骤,具体分为实体抽取、关系抽取和属性抽取三个方面[14-15]。实体抽取是一种从经过处理后的数据中提取与领域相关信息的技术,其期望获取的知识包括领域相关的实体、实体涉及的属性和展现实体脉络的关系,是知识图谱构建的基石,其抽取效率和准确率将直接影响知识图谱的构建。
3.3.1" 实体识别
实体识别是指从特性形式的学科数据中识别出基本概念、术语、公式、定义、原理等具有可解释性和带有属性的事物的过程。实体识别常采用三种方法:基于规则的方法、面向开放领域的方法和基于机器学习的方法。基于规则的实体识别需要人工制定识别规则,并且需要前期验证规则的有效性和完备性;面向开放领域的实体识别需要从海量的原始数据中获取,耗时耗力且抽取质量不高;基于机器学习的实体识别是对大规模数据集进行训练,使模型能够自动学习特定领域的实体特征。
由于学科领域知识是面向教育工作者和众多学习者的,既要严格保证知识的严谨性和确切性,即保证概念和定义的规范性、公式的正确性、术语的唯一性以及原理的可解释性,又要实现实体识别的高效性,因此在前期可采用基于机器学习的方法,后期可借助学科专家进行人工检验和更正的方法构建高质量的学科领域实体库。
在学科领域中由于缺乏与课程相关的专业词汇字典,导致在对课程文本资源进行分词时精确度不高,如在引论部分出现的“计算机操作系统”概念借助jieba或是jiagu进行分词时会将其分为“计算机”和“操作系统”,其实“计算机操作系统”在操作系统课程中表示一个整体概念;类似的在进程管理部分出现的“进程调度”概念也被分为了“进程”和“调度”两个词,但“进程调度”也是一个整体概念,再对其进行分词没有太大的意义。
本文采用增量式BiLSTM+CRF算法进行实体识别,在初始关键词字典的基础上通过逐步标注新文本语料和不断更新关键字字典,从而获取课程较为固定的实体。本文采用的课程实体识别算法如算法1所示。
算法1:Incremental-NER
输入:课程文本语料、关键词频率阈值α、最大迭代次数max_iter、BiLSTM-CRF模型参数
输出:课程字典course_dictionary、训练好的BiLSTM-CRF模型
1. " " # 初始化课程字典
2. " " course_dictionary=[]
3. " " # 迭代训练模型
4. " " for iter in range(max_iter):
5. " " " " # Tokenize、分块和标注
6. " " " " for text in course_corpus:
7. " " " " " " tokenized_and_labeled=tokenize_and_label(text, course_dictionary)
8. " " " " " " # 利用公式(1)计算相似性
9. " " " " " " similarity=calculate_similarity(tokenized_and_labeled)
10. " " " " " " # 根据阈值判断是否建立关系
11. " " " " " " if 0 lt; similarity lt; alpha:
12. " " " " " " " " establish_relation(tokenized_and_labeled)
13. " " " " # 更新词典,爬取百度百科获取新实体
14. " " " " baidu_baike_entities=crawl_baidu_baike(course_dictionary)
15. " " " " course_dictionary=update_dictionary(baidu_baike_entities, course_dictionary)
16. " " # 训练BiLSTM-CRF模型
17. " " X_train, y_train=prepare_training_data(course_corpus, course_dictionary)
18. " " bilstm_crf_model=train_bilstm_crf_model(X_train, y_train, bilstm_crf_params)
19. " " return course_dictionary, bilstm_crf_model
3.3.2" 实体关系计算
在对课程文本语料中的实体识别后,知识处于一种离散态和抽象态,只有赋予实体和实体特定关系时,知识才能以一种脉络化体系结构呈现,最终形成带有语义信息的知识网络。因此实体关系计算和发现是将知识组织成图谱的关键。目前,用于关系抽取的常用工具主要有NLTK、Deep-Dive、Stanford CoreNLP以及LTP-Cloud等[16]。但是由于学科课程中对知识点的描述常具有简明扼要特性,导致相关文本语料中显式的能标明实体与实体之间关系词语比较特殊且数量较少,因此直接使用这些常用的关系抽取工具抽取学科实体关系的效果并不理想。本文采用基于模板、关联规则和基于多特征注意机制实体共现的BiLSTM模型[17]三种方法联合进行关系抽取。
首先对课程文本语料进行分词和词性标注,保留词性为动词的词语,筛选出能明显表明四种关系的词语共41个,如表示包含关系的“组成”“分为”“包含”等,表示属性关系的“特征”“定义”等,表示递进关系的“首先”“其次”“进而”等,表示相关关系的“虽然”“尽管”等,同时定义关系匹配模板如式(1)所示:
Pattern=eci(?:分为包含ecj1…ecjn) (1)
其中eci,ecj1,…,ecjn∈C,根据课程文本语料中四种关系定义的关系匹配模板共23个,由匹配模板抽取的实体三元组共352组。
其次借助关联规则挖掘算法找出每小节和每章中所有满足最小支持度阈值α的实体频繁项集,再从频繁项集中找出满足最小置信度阈值β的关联规则,从关联规则中抽取实体对,为了确保抽取出的实体关系的准确性和可解释性,需要人工进一步对实体之间的关系进行分析,并最终确认其所属的关系,最后共得到719组实体三元组。
前两步都是根据文本语料中实体和实体之间存在显式关系进行抽取的,但是对于实体间的隐式关系利用模板和关联规则则无法有效抽取,因此需要借助基于多特征注意机制和实体共现的BiLSTM模型进行关系抽取。
基于多特征注意机制和实体共现的BiLSTM模型抽取关系的过程:第一步利用多特征注意机制提取句子层次的语义特征,这包括将句子输入到模型中进行数据清理,然后提取词性标注、依赖分析、语义角色标注和相对位置四个特征;将特征映射到低维空间,并将上述四个特征向量进行拼接;采用边界层嵌入技术实现高级特征;通过权重向量的乘积,将每次迭代中的词汇层次特征合并为句子层次特征。第二步实体共现网络提取全局语料库级特征。第三步结合以上两部分提取的特征,计算出“包含、属性、递进、相关”四种关系每种关系标签的概率分布,再对实体对进行关系分类。最终该过程进行关系分类共得到176组实体三元组。
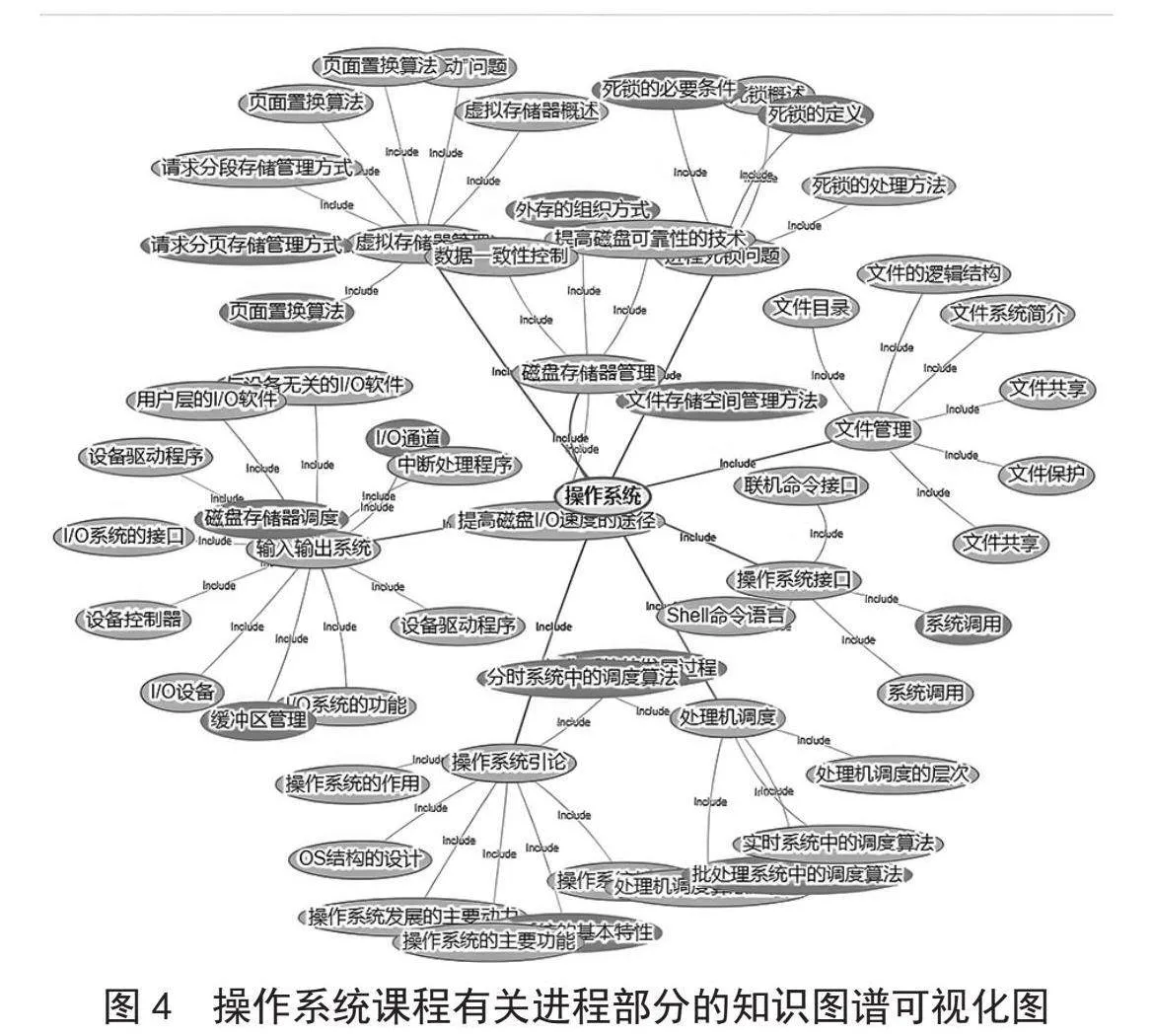
最后对操作系统课程获得的895组三元组使用Neo4j存储,有关进程部分的知识图谱可视化图,如图4所示。
图4" 操作系统课程有关进程部分的知识图谱可视化图
3.4" 知识融合与图谱更新
知识融合与图谱更新是指不断将新的信息、数据或知识集成到已有的知识图谱或数据库中,并对其进行更新和完善的过程。这实际上是一个学习反馈和自适应的循环过程。首先从在线平台上收集学习者的学习数据,然后将其融合到已有的知识图谱中,并进行整合与消解,随后更新与扩展图谱,系统通过学习反馈不断调整自身,包括改进推理能力和更新算法,最终对系统性能进行评估与优化,以提高准确性、效率和可靠性。
3.4.1" 知识融合
知识融合包含指代消解、实体对齐和实体链接知识融合中最关键的三个过程,同时也是交叉关联的过程,它们将来自不同数据源的实体关联到知识图谱中以构建一个更为准确和完整的知识图谱,从而为知识发现和数据分析任务提供更好的支持。
本文将在线学习平台上142名学习者一学年的学习数据融合到知识图谱中,在后期随着学习者学习数据的不断更新,知识图谱也会随之不断更新,从而实现动态知识图谱。
学习者学习数据主要从学习者的四种在线学习行为中获取,包括:
1)在线活跃程度。反映学习者在线学习的活跃程度,包括登录频率、访问时长、学习时段等。
2)课程参与度。衡量学习者参与课程学习的程度,包括问题提问、回答、话题讨论参与等。
3)课程学习程度。反映学习者对课程内容的深入学习程度,包括观看课程视频、课程大纲、课件、测试情况、完成实验任务情况等。
4)迁移学习情况。反映学习者对课程的在线拓展资源阅读情况,包括查阅课程的拓展资料、完成拓展实验任务等。
首先,对学习数据进行预处理,包括去除停用词、词干化、标点符号去除等操作。将文本数据划分为单词或短语,并为每个实体和属性赋予唯一的标识符。将预处理后的学习数据构建成语料库,其中每个文档或句子对应一个向量表示。设语料库为D = {d1,d2,…,dn},其中n表示学生数量。使用Word2Vec词向量化技术,将语料库中的每个词w映射到一个d维向量空间,表示为w→vw∈Rd。由此每个文档di可以表示为包含词向量的平均值或加权平均值。采用实体嵌入学习技术将学习数据中的实体转换为向量表示;根据相似度计算的结果,定义一组启发式规则来判断学习数据中的实体与知识图谱中的实体是否匹配,再根据规则,生成学习数据中每个实体的匹配候选集。从候选集中选择最佳的匹配实体进行实体对齐。将匹配好的学习数据中的实体与知识图谱中的实体进行链接,形成实体对齐的结果。这些链接可以被表示为知识图谱中的边,连接对应的实体节点。
3.4.2" 图谱更新
建立学习数据与知识点的关系模型,利用图注意力网络(GAT)及矩阵分解输出学习者学习行为影响因子,根据影响因子动态调整学习者的知识图谱。
使用GAT建模学习者学习数据和知识点之间的关系。将学习数据中的学习者、课程、问题等实体表示为图的节点,将学习者与课程之间的学习行为、学习者与问题之间的交互等关系表示为图的边。形成学习数据的图结构,其中节点表示实体,边表示实体之间的关系。使用GAT对学习数据中的节点进行表示学习。通过聚合相邻节点的信息,学习出每个节点在一个低维空间中的特征表示。同样地,将知识点表示为图中的节点,并使用GAT学习知识点的嵌入向量。通过聚合知识点周围的信息,学习出每个知识点在一个低维空间中的特征表示。利用式(3)计算学习者学习行为的影响影子。即将学习者的学习行为信息表示为学习者-行为矩阵L,行列分别表示学习者和不同在线学习行为信息。使用矩阵分解将L分解为三个矩阵P、Q和R的成绩,即:
(2)
其中,P表示学习者潜在特征矩阵,Q表示学习行为的潜在特征矩阵,R表示一个权重矩阵,表示学习者每种学习行为对影响因子的重要性。通过调整,可以使得P、QT·R尽可能接近原始的用户行为矩阵。由此定义学习者学习行为的影响因子如下:
(3)
其中,U表示学习者,I表示知识点,R表示权重矩阵,表示学习者u对知识点i的行为权重。K表示调节因子数量。该方法可以通过最小化用户行为矩阵和因子矩阵乘积之间的差异,来找到最适合描述用户行为的因子矩阵。在实际应用中,通过梯度下降等方法对U和V进行优化。
最后通过计算得到的学习行为影响因子,设置知识图谱更新阈值,当影响因子达到阈值,则表示学习者对该知识点的掌握度较高以及具有一定的知识内化程度,因此可以对知识图谱中实体的属性关系和实体间的关联度进行及时更新,使知识图谱更加贴近学习者的实际需求和学习状态,提供更加个性化、精准的知识服务和学习指导。
5" 应用分析
自适应知识图谱可以帮助学习者进行个性化学习路径规划、精准学习资源推荐、学习进度与效果监控以及课程知识图谱后期的自适应更新与优化。
5.1" 个性化学习路径规划
通过分析学习者的学习行为和成绩,自适应知识图谱能精准识别学习者的知识掌握情况和薄弱环节,动态的调整学习内容和难度。同时结合学习者的学习进度和反馈,图谱系统能智能推荐下一步的学习路径,确保学习者按适合自己的学习进度学习。这种个性化的学习方式不仅能提高学习者的学习效率,还能激发他们的学习兴趣,使学习者有精力在学科课程的学习中涉猎更广的知识面。
5.2" 精准学习资源推荐
通过持续跟踪和分析学习者的学习行为、成绩以及互动数据,构建出每个学习者的个性化课程知识图谱。基于该个性化课程知识图谱,能够准确识别学习者的知识掌握程度和学习需求,为其推荐适合的学习资源,如视频教程、习题集、实验项目、拓展阅读材料等,以满足学习者不同的学习需求。
5.3" 学习进度与效果监控
在操作系统课程的学习过程中,具有学习反馈的自适应知识图谱可以作为学习者学习进度与效果监控的有力工具。图谱系统通过实时追踪学习者的学习路径,记录他们在各个知识点上的学习时长、答题正确率等关键数据,从而为学生提供一个清晰的学习进度概览。同时,通过深入分析这些数据,知识图谱能够准确评估学习者的学习效果,及时发现他们在理解或应用操作系统概念时存在的障碍,并为学习者提供个性化的学习建议,帮助他们调整学习策略,以更高效地掌握课程内容。由此学习者不仅能够对自己的学习状态有更为准确的认识,还能在系统的引导下,持续优化学习过程,最终实现学习效果的显著提升。
5.4" 知识图谱的自适应更新与优化
图谱系统通过持续收集并分析学习者的学习行为、成绩和反馈,动态调整知识图谱中的节点和连线,以反映学习者当前的知识掌握情况和学习需求。同时根据领域专家的指导和最新研究成果,图谱系统还能对知识图谱中的实体和关系进行修正和完善,确保其准确性和完整性。
6" 结" 论
构建具有学习反馈的自适应知识图谱通过整合学习者的学习行为数据和知识图谱构建技术实现对知识图谱的动态更新和个性化调整,不仅能够为学习者提供更具针对性和有效性的学习资源推荐、学习路径规划以及学习进度跟踪等服务,以提高学习者的学习成效和满意度,实现个性化、智能化的教育教学目标,同时能够为教育管理者和决策者提供重要的参考信息,帮助他们更好地理解学习者的学习状态和需求,从而制定更加精准和有效的教育政策和措施,推动教育教学的持续发展和进步。
参考文献:
[1] 王运武,彭梓涵,张尧,等.智慧教育的多维透视——兼论智慧教育的未来发展 [J].现代教育技术,2020,30(2):21-27.
[2] 刘新业.智慧教育趋向下学习环境与教学现状的变化与改良——评《智慧教育下的教学变革》 [J].中国教育学刊,2020(9):109.
[3] 李振.基于知识图谱的自适应学习系统关键构建技术研究 [D].长春:东北师范大学,2019.
[4] 范佳荣,钟绍春.学科知识图谱研究:由知识学习走向思维发展 [J].电化教育研究,2022,43(1):32-38.
[5] 林健,柯清超,黄正华,等.学科知识图谱的动态生成及其在资源智能组织中的应用 [J].远程教育杂志,2022,40(4):23-34.
[6] 叶小敏.美国Knewton自适应学习平台研究 [D].重庆:西南大学,2019.
[7] 互联网教育智能技术及应用国家工程实验室.唐诗别苑 [EB/OL].[2018-07-25].https://cit.bnu.edu.cn/kxyj/kyzy/53588.html.
[8] 陈鹏鹤,彭燕,余胜泉.“AI好老师”智能育人助理系统关键技术 [J].开放教育研究,2019,25(2):12-22.
[9] 陆星儿,曾嘉灵,章梦瑶,等.知识图谱视角下的MOOC教学优化研究 [J].中国远程教育,2016(7):5-9+79.
[10] 周东岱,董晓晓,顾恒年.教育领域知识图谱研究新趋向:学科教学图谱 [J].电化教育研究,2024,45(2):91-97+120.
[11] 郑志宏,马涛,孔新梅,等.基于最近发展区的学科知识图谱构建及大单元设计研究 [J].远程教育杂志,2024,42(2):56-64.
[12] GRUBER T R. Toward Principles for the Design of Ontologies Used for Knowledge Sharing? [J].International Journal of Human-Computer Studies,1995,43(5-6):907-928.
[13] 于浏洋,郭志刚,陈刚,等.面向知识图谱构建的知识抽取技术综述 [J].信息工程大学学报,2020,21(2):227-235.
[14] 李冬梅,张扬,李东远,等.实体关系抽取方法研究综述 [J].计算机研究与发展,2020,57(7):1424-1448.
[15] 杨玉基,许斌,胡家威,等.一种准确而高效的领域知识图谱构建方法 [J].软件学报,2018,29(10):2931-2947.
[16] 赵宇博,张丽萍,闫盛,等.个性化学习中学科知识图谱构建与应用综述 [J].计算机工程与应用,2023,59(10):1-21.
[17] SONG M X,ZHAO J S,GAO X. Research on Entity Relation Extraction in Education Field Based on Multi-feature Deep Learning [C]//ICBDT20: Proceedings of the 3rd International Conference on Big Data Technologies.Qingdao:Association for Computing Machinery,2020,10:102-106.
作者简介:王全蕊(1981—),女,汉族,河南新乡人,讲师,硕士,研究方向:智慧教育、知识图谱构建。