



摘" 要:准确把握日语农业科技术语的汉译规则,可以促进吸收国外先进科技成果、推动实现中国农业现代化。利用Python编程语言创建专业语料库并分析了术语的构词类型,依据设定的翻译程序、原则和技术要点创建了日汉双语语料库,应用Python丰富的函数和库、包探讨了互译检索、日语分词、关键字词频数统计等开发应用。日语农业科技术语数量庞大并且词形和专业领域日趋多样,为创建数字化语料库和准确翻译术语提出了新的挑战。Python为语料库开发和农业科技术语翻译提供了诸多便利工具,具有广阔的应用前景。
关键词:农业;科技术语;语料库;日语汉译;Python
中图分类号:TP391.1" " " 文献标识码:A" " 文章编号:2096-4706(2024)22-0068-07
Research on Word Formation Types and Translation Methods of Japanese Agricultural Science and Technology Terminology Based on Python
Abstract: Accurately grasping the Chinese translation rules of Japanese agricultural science and technology terminology could promote the absorption of advanced foreign scientific and technological achievements and Chinese agricultural modernization. This paper uses Python programming language to create a professional corpus and analyzes word formation types of the terminology. A Japanese-Chinese bilingual corpus is built based on the designed translation programs, principles, and technical key points. The rich functions, libraries, and packages in Python are applied to explore the development and application such as mutual translation retrieval, Japanese word segmentation, and keyword frequency statistics. The number of Japanese agricultural science and technology terminology is large and the word forms and professional fields are increasingly diverse, posing new challenges for building digital corpus and accurately translating the terminology. Python provides many convenient tools for corpus development and agricultural science and technology terminology translation, and it has broad application prospects.
Keywords: agriculture; science and technology terminology; corpus; Japanese-Chinese translation; Python
0" "引" 言
加速建设农业强国和实现农业现代化,需要大量翻译引进国外先进农业科技成果以提高自主研发和应用创新能力。作为东亚发达国家,日本农业机械、作物育种、智慧农业等领域科技水平位居世界前列,对推进中国式农业现代化具有较强的参考借鉴价值。日语农业科技用语数量巨大、种类繁多、涉及领域广泛,结合使用汉字、假名、英文字母、罗马字等多种文字,存在多词同义、同词异形、部分汉字与中文语义差异较大等现象。这就需要译者有扎实的日汉双语、农学、语言学基础和广博的科技知识,结合每个术语特点进行加工创作,给信息检索和翻译交流带来困难。
日本学者的研究偏向于信息技术条件下推进日语农业科技术语的便捷、规范交流和应用[1-3],涉及汉译的文献接近空白。中国学者已经开始关注农业科技日语的翻译方法,有较早出版的专业教材讲解了各种农业日语词汇的用法及翻译技巧[4]。从翻译学角度分析了日语农业术语汉译中对等模式的表现和影响因素,论述了日本农业科技术语语素、语法功能、词汇系统的汉译适应化现象及价值[5-6]。目前,构筑日汉双语农业科技语料库系统探讨术语翻译方法的研究较少,为数不多的大型农业日语工具书[7]出版时间已较为久远,亟待增加收录新出农业科技术语,拓展翻译方法研究的应用性、覆盖面和前沿性。作为一种开源、高效、实用的计算机编程语言,Python对自然语言处理特别是语料库开发的价值已得到学界认可[8-11]。
本文广泛参考日本术语库及专业文献,借助Python语言创建日语农业科技语料库,结合在日本开展系列课题积累的研究经验,开发语料库在总结科技术语构词规则及趋势、汉译原则及技术要点等方面应用。目的在于更准确把握日本农业科技动向、增强中国科技信息资源保障能力。
1" "语料库创建与术语的构词类型
1.1" 语料库的创建及分析框架
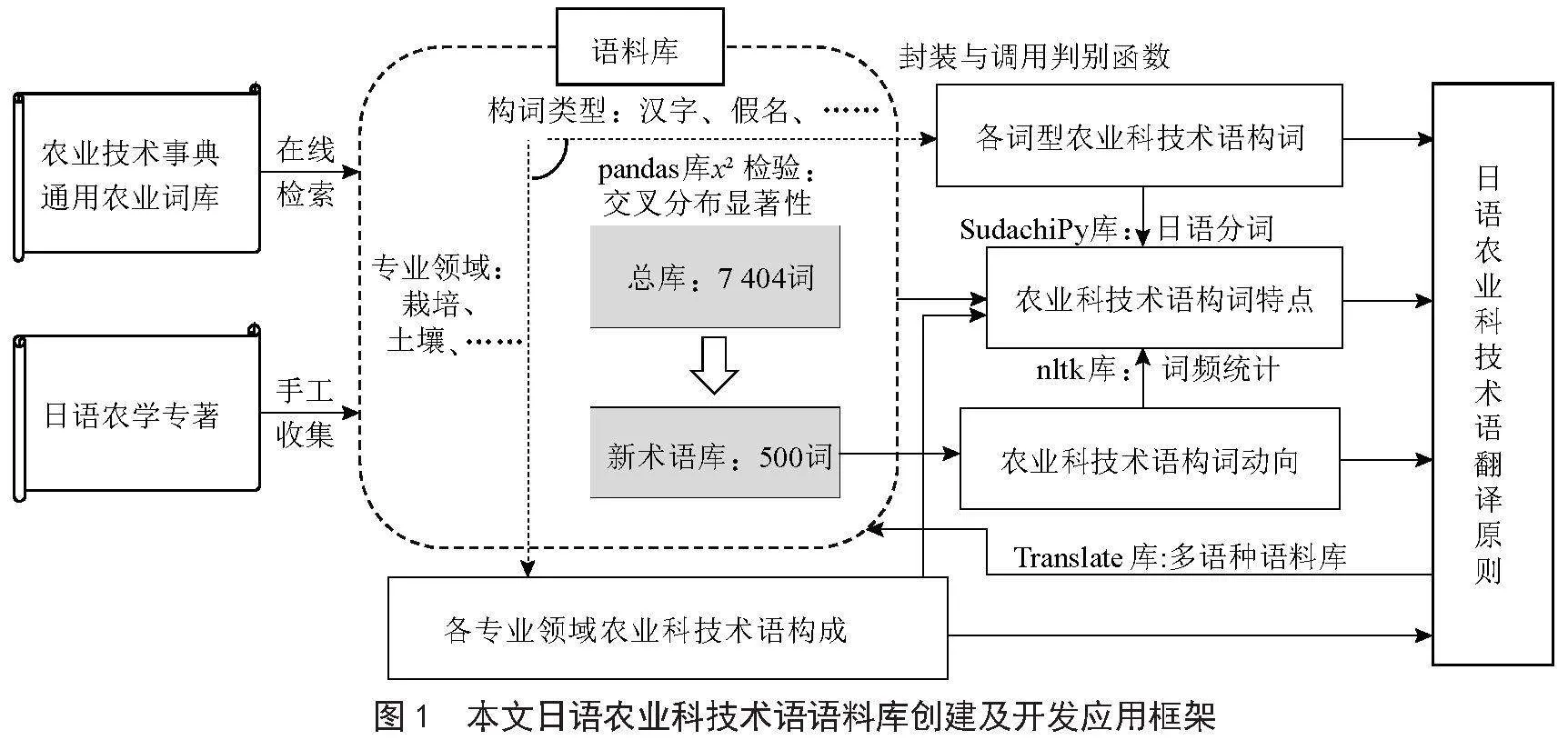
适应信息技术高度发达条件下语料库大样本和数字化建设的普遍趋势[12],本文采用在线检索电子资源和手工收集纸质文献相结合的方法,构筑了包括7404词的日语农业科技术语语料库。词源《农业技术事典》[13]的6 833词、日本通用农业词库(CAVOC)[14]的400词,以及多部日语农学专著[15-18]的171词。收集的术语首先录入和保存为csv格式文件,再由Python读取并分析词形后将结果回传保存,为后续的开发应用奠定基础(如图1所示)。
1.2" 日语农业科技术语构词类型划分
为判断各术语构词类型,将代码封装为如下所示的函数TermTypeIdentifier,遍历单个术语中的各个字符并根据其Unicode编码确定类型,将结果放入集合term_type中去除重复的字符类型。遍历结束后形成以“+”分隔的整个术语构词类型,作为函数的返回值供主程序调用。主程序中首先导入用于处理和分析数据的第三方库pandas,从csv类型文件导入语料库数据命名为Corpus。遍历所有日语术语,调用函数TermTypeIdentifier收集各术语构词类型存入相应列表并最终转化为语料库数据框中的一列,从而高效便捷地实现对库内所有日语术语的词形分类。
def TermTypeIdentifier(term):" "#定义术语构词类型判断函数
term_type = set()" "#设定该术语构词类型为空集合
for char in term:" "#遍历该术语中所有字符
char_int = ord(char)" "#输出各字符的Unicode编码以判断字符类型
if (65 lt;= char_int lt;= 90) or (97 lt;= char_int lt;= 122):
char_type = \"a\"" "#该字符是字母
elif (12353 lt;= char_int lt;= 12439) or (12449 lt;= char_int lt;= 12536):
char_type = \"b\"" "#该字符是假名
elif 19968 lt;= char_int lt;= 40959: char_type = \"c\"" "#该字符是汉字
else: continue" "#跳过汉字、字母和假名以外的字符
term_type.add(char_type)" "#忽略重复元素将字符类型加入该术语类型集合
term_type = sorted(term_type)" "#将代表各字符类型的字母进行排序
term_type = [i.replace(\"a\", \"字母\").replace(\"b\", \"假名\").replace(\"c\", \"汉字\") for i in term_type]" "#将字母a、b、c分别替换回以汉字表示的构词类型
term_type = +.join(term_type)" "#遍历结束形成该术语整体类型
return term_type" "#返回该术语类型供主程序调用
import pandas as pd" "#主程序:导入扩展库pandas并设置别名为pd
Corpus = pd.read_csv(\"日语农业科技术语语料库.csv\")" "#读入csv型数据并设置别名为Corpus
Corpus.构词类型 = []" "#设立空列表以承接各术语的构词类型
for i in Corpus[日语术语]:" "#遍历语料库内各个术语
i = str(i); Corpus.构词类型.append(TermTypeIdentifier(i))" "#调用术语构词类型判断函数
Corpus[构词类型] = pd.Series(Corpus.构词类型)" "#将构词类型列表转化为数据框的一列
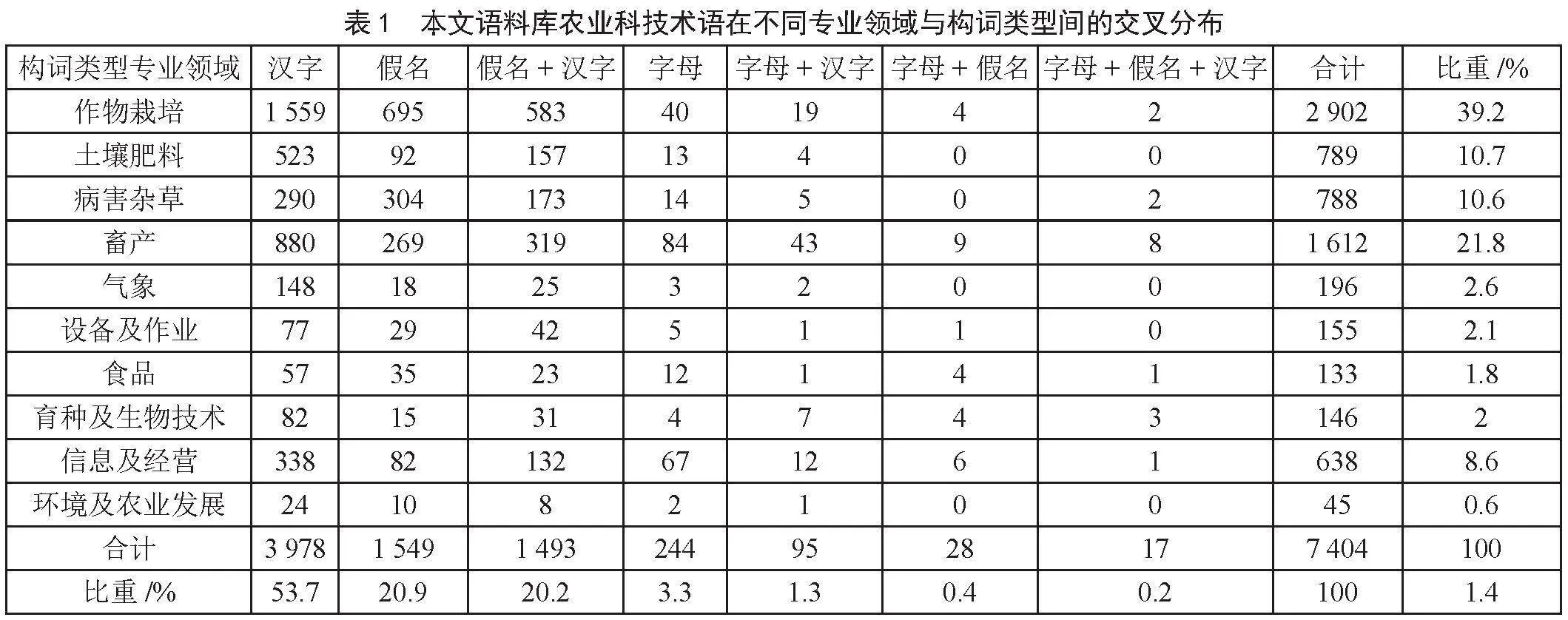
词形分类确定后,本文语料库收录的日语农业科技术语包括表1所示的7种构词类型。表中基于pandas库的列联分析显示汉字共3 978字,占库内术语总量的53.7%,其他类型按照词数从多到少依次是假名、假名+汉字、字母、字母+汉字、字母+假名、字母+假名+汉字。在专业领域方面,参照《农业技术事典》的分类标准将术语划分为10个专业领域并对库内术语逐个归类,个别存在领域交叉的术语按照就近原则确定领域归属。各个领域中作物栽培术语最多,以2 902词占库内术语总量的39.2%;其次是畜产,以1 612词占库内术语总量的21.8%。其他领域词数从多到少依次是土壤肥料、病害杂草、信息及经营、气象、设备及作业、育种及生物技术、食品;环境及农业发展领域术语最少,以45词仅占库内术语总量的0.6%。因而,语料库内术语在构词和专业性上都具有较为广泛的代表性。
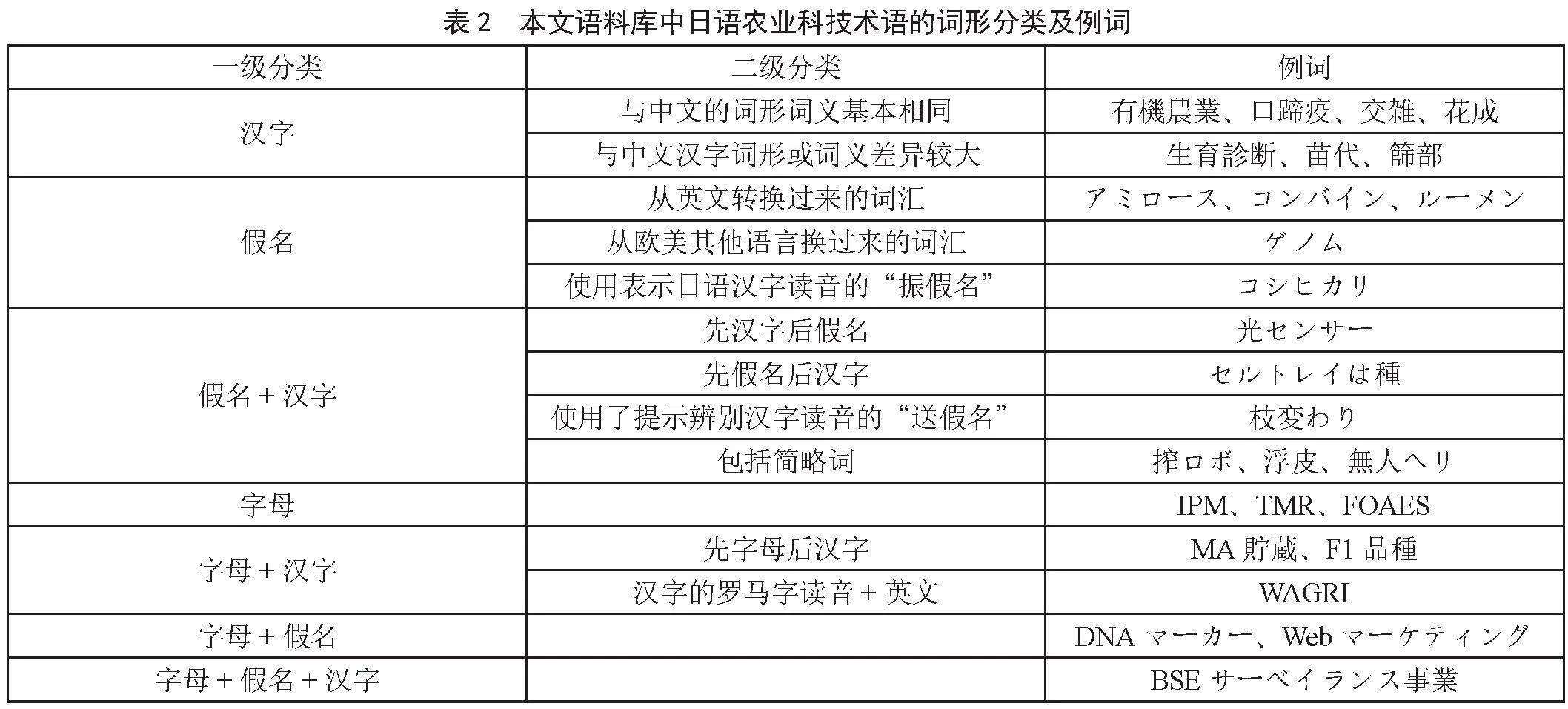
按照汉字、假名、英文字母三种文字的组合形式,上述7类日语农业科技术语可参照表2做进一步细分,为把握日语科技术语构词动向、完善语料库和科技翻译理论提供支持。
2" 日语农业科技术语的翻译方法
2.1" 术语汉译翻译程序设计
导入Python的自然语言机器翻译库Translate,可以逐个翻译日语农业科技术语。但是,受专业性强、词形多样和新出词汇多等因素制约,仍然有很多术语未能被译出或存在错译,需要人工核对修改。运行如下代码 时,首先调用定义的日汉翻译函数Translation_JtoC输出对应的中文术语列表,然后将列表转化为语料库文件的一列并保存为Excel文件,便于对中文翻译进行检查和修正润色。
2.2" 术语翻译的原则及技术要点
翻译汉译日语农业科技术语需要把握以下原则。第一,准确体现农业技术的内涵。使用对应的中文汉字翻译日语汉字术语,完整体现片假名和英文字母缩写词的含义,还要使翻译出的中文词汇尽量做到简洁、准确。第二,结合中文构词新动向使用合适词汇进行准确翻译。既要贴合中文农业科技新型汉字术语的造词习惯,又要直接保留中文中也普遍使用英文缩写的词汇,结合相应的英文原词,使用反映技术内涵的中文汉字译好片假名词汇。第三,有利于国际交流。使用中文直接翻译源于英语等西方主流语种的词汇,甄别并及时修正日语中的自造片假名词汇,保留国际通行的固定英文字母搭配。第四,体现日语文化特色。采用简体汉字翻译中文中有对应词汇的术语,使用日语汉字直接翻译中英文都没有通行词汇的日本特有名词。具体应结合各术语词形把握如下技术要点。
1)汉字词汇。第一,采用简体中文汉字对译词义相同的汉字词汇。例如,“染色体”“紫外线杀菌”等。第二,按照中文表达习惯,找准异形同义词汇对应的中文汉字。例如,“走查电子顕微镜”“在来种”“遗伝子”可分别译为“扫描电子显微镜”“原有品种”“遗传基因”。第三,区分日语与汉语中同一字词的含义差别。例如,日语中“肥大”一般是指生理性生长发育,而非病理性细胞、组织或器官的体积增大,因而“肥大期”应译成“发育期”。第四,对于中文没有固定词形的新词、日语特有汉字或表达方式,原则上保留与中文同形近义的日语汉字。例如,“仮植”可直译作“假植”,是指将暂不栽种或出圃的苗木临时栽植在保温抗风无积水的场所以保障成活;“房”的意思是一串葡萄,所以可直译“整房”表示为增加着果量、提高果品质量而实施的葡萄生长管理。
2)假名词汇。第一,准确还原假名代表的汉字、字母、单词及含义。例如,“シンク”(sink,代谢库)指植物体内种子、根、茎、果实等接受碳、氮等光合作用同化物的器官,“ソース”(source,代谢源)指功能叶、胚乳等产生或提供同化物的器官,“シンク·ソース”可译成“代谢库-源”;“コート”对应英文coat(外衣),“コート种子”可译成“包衣种子”。第二,识别并合理翻译日语自造和截取英文单词片段的词汇。例如,“マルドリ”由“マルチ”(mulch,地膜)与“ドリップ”(drip,滴水)的前两个假名组合而成,表示通过在树根部埋设自动控制的滴水管,再在上面铺设透气性地膜,以保障柑橘等果树水分供给、提高果物品质的技术,可以翻译作“膜下滴灌”。第三,遵循符合中文构词习惯。例如,分别将“不完全米”“忌地”翻译成“不饱满米粒”“忌地现象”(作物重茬栽培时引起的生长发育不良)。第四,翻译出词汇中包含的文化内涵。例如,“アイガモ”对应汉字“合鸭”是指在稻田饲养鸭子吃掉杂草和害虫、不断游动提高水温刺激水稻生长、用鸭粪为肥生产无公害优质稻米和鸭肉,因而“アイガモ饲育”可以译为“稻鸭共作”,以体现“和合共生”的东方智慧以及绿色农业发展理念。
3)字母缩写词。第一,用汉字准确还原全拼词汇及含义。例如,“BDF”(Bio-Diesel Fuel)、“LAI”(Leaf Area Index)分别译作“生物柴油燃料”“叶面积指数”。第二,识别并区别代表日语发音的罗马字母缩写或组合,并使用汉字准确翻译其含义。例如,“Nippon”是日语“日本”读音的罗马字母,“NTP”(Nippon Total Profit)表示根据出奶量、乳脂量、无脂固体成分量、乳蛋白质量等特征,计算出的“日式奶牛饲养效益综合指数”。第三,结合中文和国际习惯直接使用原字母及其组合,例如“IoT”(Internet of Things,物联网)、“RFID”(Radio Frequency Identification,射频识别)。
4)汉字、字母和假名组合。第一,尽量采用汉字翻译全词。例如,将“好アンモニア性植物”“GM作物”分别翻译成“嗜氨植物”“转基因作物”。第二,准确反映不同文字组合的技术内涵。例如,“CAS”是“Cells Alive System”的缩写,所以“CAS冷冻センター”可译为“活细胞冷冻中心”;“CAM”的全拼是“Crassulacean Acid Metabolism”,因此“CAM植物”就应译作“景天酸代谢植物”。第三,结合国际学界通行规则适当保留原字母。例如,直译“C3植物”(即碳三植物或三碳化合物植物,是小麦、大豆等光合作用的最初产物)、“C/N比”(碳氮比),将“DNAマーカー育种”译为“DNA标记育种”。
5)作物新品种名称。第一,直接翻译有汉字名称的术语,例如杂交育出“越光”水稻的“农林1号”和“农林22号”,大麦品种“さやかぜ”又名“清风”。第二,准确翻译非汉字术语的含义,在选取假名对应汉字时要贴近农作物特点,译出田园农庄特色。例如,借鉴关东平原西部“武藏台地”的地名,将在该地区培育的水稻品种“むさしこがね”译为“武藏黄金”;将植株柔细、谷粒疏大、耐寒性强的水稻品种“ふさおとめ”译作“流苏少女”;将北海道培育的小麦品种“キタノカオリ”译作“北方之香”。第三,根据农作物特点和汉语习惯适当意译。例如,大麦品种“イシュクシラズ”即“萎缩知らず”(不知萎缩),可译为“叶长青”。第四,对有些品种的翻译要采用国内已有的通行叫法。例如,葡萄品种“デラウェア”(Delaware)的英语和日语名称采用了原产地美国特拉华州的地名,但已在中国东北、华北、华中等地区大范围种植并俗称“玫瑰露”。
2.3" 日汉双语语料库的创建及开发应用
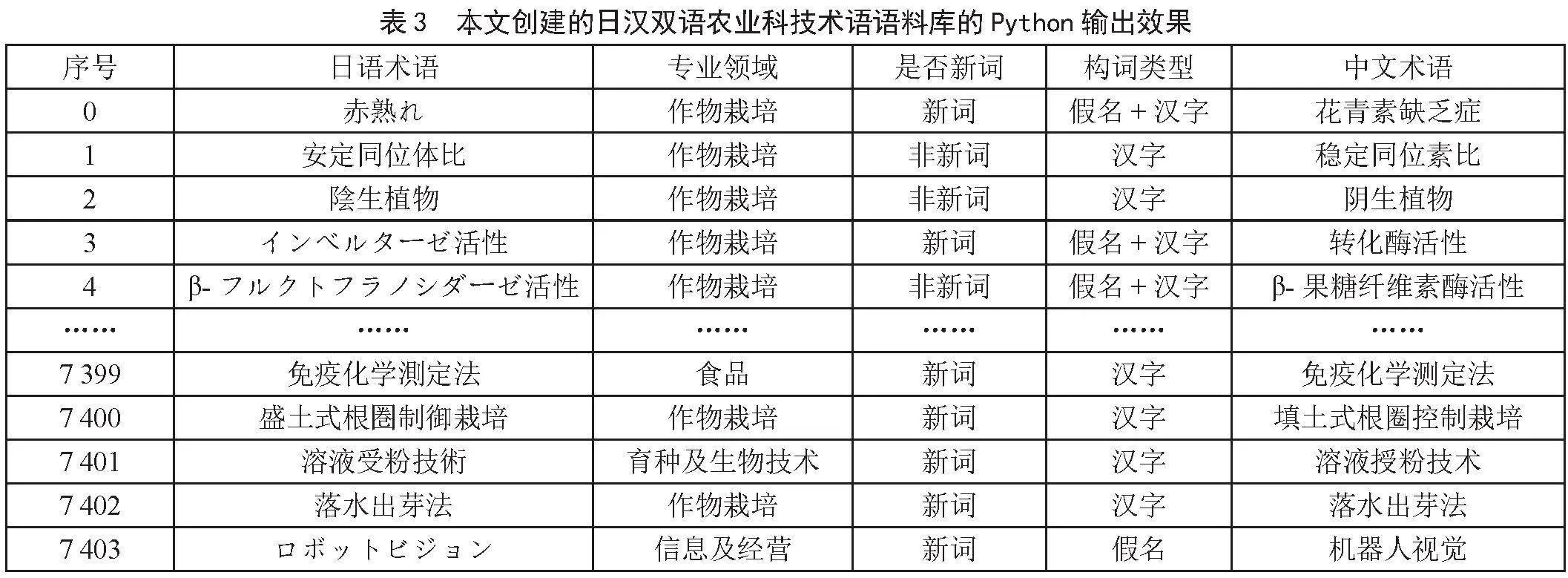
在明确日语术语词形和专业领域分类、提取新词、完成术语汉译的修改确认基础上,创建的日汉双语语料库Python输出的效果如表3所示。
以此为平台可以参考下面的代码实现语料库数据处理。例如,利用Python的dict()、zip()、get()等函数设置创建双语词典,或直接在库中设定检索条件支持输入不同术语进行双语对照和互译。再如,通过运行下栏中各行的简短代码,分别可以检索出语料库中食品领域的日语农业科技新词包括“アミロペクチン”(支链淀粉)、“スクリーニング検查法”(筛检法)等共计16词,日语农业科技新词中的假名型术语包括“カーボンニュートラル”(碳中和)、“アンシミドール”(嘧啶醇)等共计118词。此外,将前文分析日语术语的函数和代码稍做修改,可以很容易分析出对应的中文术语中的汉字、字母及不同组合的词型构成,对比考察中文农业科技术语构词的变动趋势及其与日语的差异。
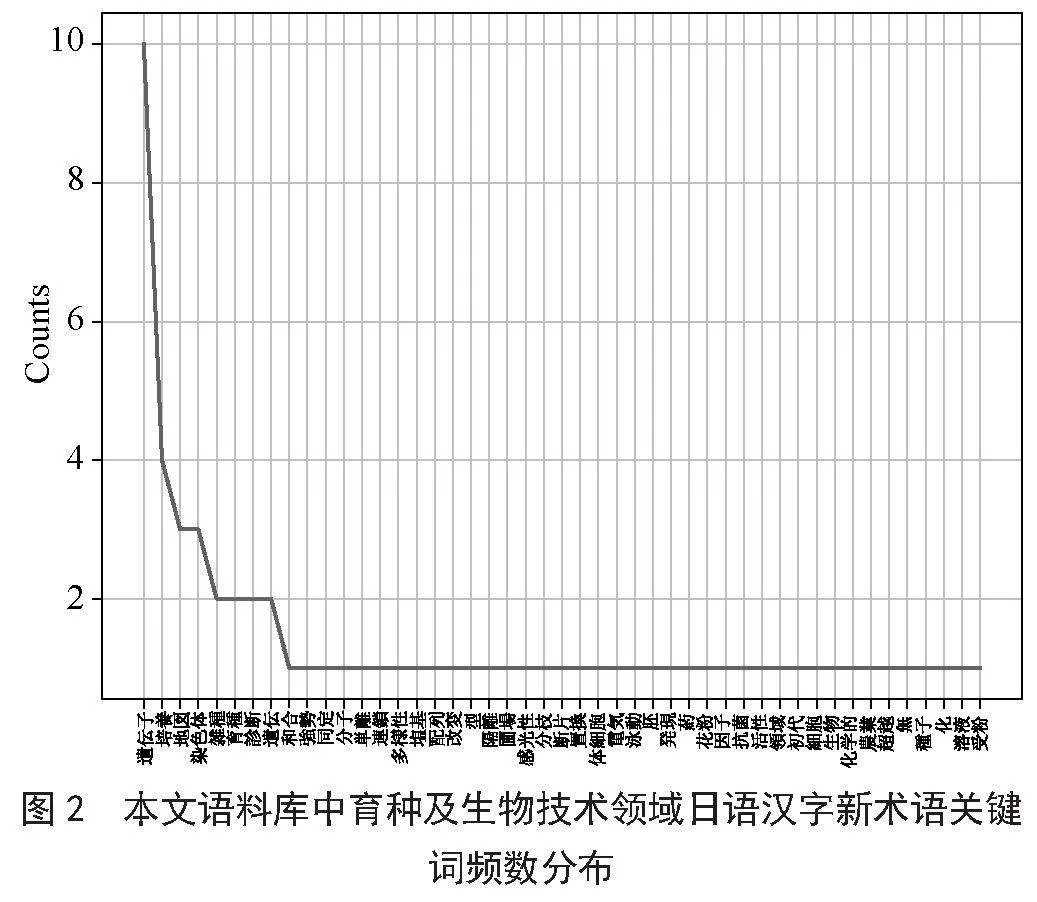
根据图2所示的代码运行结果,纳入分析的31个术语中高频关键词包括出现10次的“遗伝子”,出现4次的“培养”、各出现3次的“地図”(图谱)、“染色体”等。以小规模精耕细作为特色的日本农业,重视研发与应用育种及生物技术改良动植物品性,例如1994年首次构建水稻基因组遗传图谱,促进了染色体上基因排列测定和标记技术的迅猛发展;2006年利用“培养変异”(体细胞无性系变异)品种“北海287号”,培育了低直链淀粉、口感良好的转基因水稻品种“胧月”[16]。
3" 结" 论
本文创建的语料库涵盖7 404个日语农业科技术语,包括了汉字、假名和字母等构词类型,从微观视角体现了农业科学的原理和核心技术,凸显了汉译的重要意义。借助Python的nltk、jieba等功能丰富强大的自然语言处理库和函数资源,拓展语料检索、近义词关联、同义词归并以及上下文关键词检索(KWIC)和提取,通过分析语篇中词汇出现频度、验证新术语选择的合理性。术语汉译不仅要准确表达农业科技内涵,还应符合中文构词习惯、利于国际交流、体现日语文化特色。以此可以深化对日语农业科技术语构词和汉译规律的认识,密切与中外自然语言翻译网站衔接、优化函数性能,提高日汉及日英等多语种术语对译的译出率和准确性。由于日语农业科技术语具有学科交叉属性,本文的研究结论对于把握日语科技术语的整体构词特点并实现准确汉译也具有参考价值。因此,Python为语料库开发提供了函数、专业库等开放高效的工具,在同类研究应用中的开发空
间广阔。也要看到,语料库术语遴选、专业领域和新词区分、汉译的智能化程度偏低,需要进行人工核实润色以纠正错漏。要适应科技语言与人工智能和数字技术加速融合的大趋势,探索建立动态、前沿、好用的多语种农业科技术语语料库,提高中国实现农业现代化和建设农业强国的科技贡献率。
参考文献:
[1] NAGAI M,OHIRA W,ONO M.Development of an Ontology Management Tool to Support Interoperability of Agricultural Information [J].Agricultural Information Research,2017,26(2):27-33.
[2] SEKI K,MIZOGUCHI M. Agroinformatics Encyclopedia System with Wiki [J].Water, Land and Environmental Engineering,2012,80(1):3-6.
[3] JOO S M,KODE S,TAKEDA H,et al. Building Core Vocabulary of Agriculture Activity for Agricultural Data Integration [J].Agricultural Information Research,2019,28(3):143-156.
[4] 冷平,袁汉青.农业日本语 [M].北京:中国农业出版社,2000.
[5] 李红,卢冬丽,王薇.现代农科术语日汉翻译对等模式再探讨 [J].中国科技术语,2014,16(5):33-37.
[6] 李红,夏建新,卢冬丽.农业科技日语术语汉译适应化现象分析 [J].中国科技术语,2016,18(2):38-42.
[7] 王树江.日汉农业词典 [M].西安:陕西科学技术出版社,1989.
[8] 管新潮.语料库与Python应用 [M].上海:上海交通大学出版社,2018:2-4.
[9] 胡加圣,管新潮.文学翻译中的语义迁移研究——以基于信息贡献度的主题词提取方法为例[J].外语电化教学,2020(2):28-34+5.
[10] 陆晓蕾,倪斌.Python 3:语料库技术与应用 [M].厦门:厦门大学出版社,2021.
[11] GOTO I. Python for Natural Language Processing [J].The Journal of The Institute of Image Information and Television Engineers,2018,72(11):909-912.
[12] 陆俭明.顺应科技发展的大趋势语言研究必须逐步走上数字化之路 [J].上海外国语大学学报,2020,43(4):2-11.
[13] NARO (National Agriculture and Food Research Organization of Japan). NAROPEDIA [DB/OL].[2022-11-01].http://lib.ruralnet.or.jp/nrpd.
[14] CAVOC(Common Agricultural Vocabulary). Agricutlure Activity Ontology [DB/OL].(2021-08-02).http://cavoc.org/aao.html.
[15] 农业情报学会.新スマート农业―进化する农业情报利用 [M].东京:农林统计出版,2019.
[16] 大日本农会.平成农业技术史 [M].东京:农文协プロダクション,2019:522-545.
[17] 南石晃明.デジタル·ゲノム革命时代の农业イノベーション [M].东京:农林统计出版,2022.
[18] 三轮泰史,井熊均,木通秀树.农村DX(デジタル·トランスフォーメーション)革命:アグリカルチャー4.0の时代 [M].东京:日刊工业新闻社,2019.