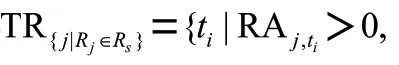


摘" 要:实现暗网违法犯罪情报的规模化产出是打击暗网违法犯罪的一项重要前置任务。当前研究较难解决暗网数据量不足的问题,且主要针对西文暗网数据进行。为实现中文暗网文本的针对性分析,提出了一种基于多任务学习的BERT-BiLSTM违法犯罪分类和命名实体识别多任务学习模型,其在文本分类和命名实体识别任务间共享BERT-BiLSTM层,并分别采用全连接层和条件随机场(CRF)层作为文本分类和实体识别的输出层,以加强不同任务间的知识共享。在自建的中文暗网数据集上的实验结果表明,该多任务学习模型相比基线模型在两类任务上均有一定性能提升。
关键词:暗网;犯罪治理;多任务学习;BERT
中图分类号:TP183;TP391 文献标识码:A 文章编号:2096-4706(2024)23-0165-06
Research on Dark Web Crime Intelligence Mining Technology Based on BERT Model
ZHOU Yu, CAI Du
(Jiangsu Provincial Public Security Department, Nanjing" 210024, China)
Abstract: Achieving the large-scale production of illegal and criminal intelligence on the dark web is a crucial preliminary task for combating illegal and criminal activities on the dark web. Current research struggles to address the issue of insufficient dark web data and primarily focuses on Western language dark web data. In order to achieve targeted analysis of Chinese dark web texts, this paper proposes a multi-task learning model for BERT-BiLSTM illegal and criminal classification and named entity recognition based on multi-task learning. It shares the BERT-BiLSTM layer between the text classification and named entity recognition tasks, and adopts the fully connected layer and the Conditional Random Field (CRF) layer as the output layers for text classification and entity recognition respectively, so as to strengthen knowledge sharing between different tasks. The experimental results on the self-constructed Chinese dark web dataset show that, compared with the baseline model, this multi-task learning model achieves certain performance improvements in both types of tasks.
Keywords: dark web; crime governance; multi-task learning; BERT
0" 引" 言
“暗网”指利用Tor、I2P等特殊路由技术架设的隐藏网站,因具有良好的匿名性、隐蔽性,滋生了毒品、色情、洗钱、网络攻击、非法数据买卖乃至网络恐怖主义等多种违法犯罪[1],且近年来在我国境内发案量呈增长态势[2]。暗网犯罪的打击难度主要体现在打击成本和犯罪成本的不对等上[3],如何降低暗网犯罪的发现和取证难度是相关研究中的重要问题。
深度学习技术的发展为解决该问题提供了新路径。回顾已有研究发现,机器学习方法已在暗网流量和网站指纹识别[4-5]、图像识别[6]、命名实体识别[7-8]、用户身份对齐[9]、内容分类[10-11]等任务上取得了良好效果。但现有研究多集中于特定问题的理论探讨,且以英文暗网数据集为主,针对中文暗网网站开展模型训练和应用的研究不足。研究表明,英文暗网的犯罪生态[12]与中文暗网犯罪生态[2]存在一定差异,而现有基于英文暗网数据集的模型则难以弥补这部分差异。
为了解决中文暗网文本违法犯罪内容识别与发现的问题,本文构建了一套面向中文暗网犯罪内容的多任务学习情报挖掘模型。主要工作包括:
1)针对主要的中文暗网非法网站开发了一套爬虫框架,收集了12 107条页面和帖文数据;并在此基础上,通过半自动标注构建了中文暗网内容数据集。
2)提出了基于BERT-BiLSTM模型进行暗网非法活动分类和命名实体识别的方法。该方法结合了BERT预训练模型良好的语义理解能力和双向长短时记忆网络(BiLSTM)的序列特征提取能力,提高对暗网长文本的语义理解和特征提取能力;运用多任务学习方法,在文本分类和实体识别任务间共享BERT-BiLSTM层,并分别采用全连接层和条件随机场(CRF)作为输出层,在文本分类和实体识别任务两类任务下均有良好表现。
3)基于我们构建的数据集对中文暗网文本识别进行测试,实验结果表明模型具备良好的准确率。
本文其余部分安排如下。第二节回顾相关研究工作;第三节描述了本研究的内容分类和命名实体识别方法;第四节介绍实验过程,包括数据集构造过程和实验的技术细节;最后,第五节总结本文工作并对下一阶段研究提出展望。
1" 相关技术
1.1" 文本分类
文本分类(Text Classification)任务主要关注将一段文本自动归属到一个类别中的方法,是情报抽取和分析的一个重要前置问题。采用统计机器学习解决文本分类问题的方法包括K-近邻(K-Nearest Neighbors, KNN)、支持向量机(Support Vector Machine, SVM)和朴素贝叶斯算法(Naive Bayes)[13]等。
深度学习方法兴起以来,卷积神经网络(Convolutional Neural Network, CNN)[14]和循环神经网络(Recurrent Neural Network, RNN)[15]等深度学习模型,因具备了从文本中隐含的序列信息中捕获单词间语义的能力在文本分类任务上取得了广泛应用。其中,循环神经网络的一个变种长短时记忆网络(LSTM)[16]在处理长距离依赖关系中表现良好,成为该领域重要的基础性模型。近年来,图神经网络[17]、大规模预训练模型BERT[18]和GPT[19]等在文本分类任务上亦有良好表现。目前,使用预训练模型获取语义特征已成为该领域广泛应用的典型方法。
围绕暗网文本内容的分类,文献[20-22]分别运用IF-IDF、支持向量机和卷积神经网络训练了暗网文本分类器,效果良好;文献[11]关注到暗网违法文本样本不足的问题,利用《美国法典》中与暗网常见违法犯罪相关的条文,训练了基于TF-IDF和朴素贝叶斯法的暗网违法内容分类器。围绕使用大规模预训练模型提高分类效果,文献[23]对比了BERT、RoBERTa、ULMFit和LSTM四类模型在分类任务上的效果,结果显示原生BERT在准确度(Accuracy,指正确的样本占总样本的比例)方面表现较好,而BERT变种RoBERTa则在F1分数上取得优势。
1.2" 命名实体识别
命名实体识别(Named Entity Recognition, NER)主要关注从非结构化文本中识别特定类型实体的问题。早期,基于统计机器学习的命名实体识别方法受到较多关注,并出现了隐马尔可夫模型(Hidden Markov Model, HMM)[24]、支持向量机[25]和条件随机场(Conditional Random Field, CRF)[26]等主流命名实体识别模型。统计机器学习模型研究历史较久,但其识别质量受特征的影响较大,模型的鲁棒性有限。
近年来,深度学习方法在命名实体识别方面取得了良好效果。文献[27]结合了词向量和语义特征,构建了BiLSTM-CRF模型用于实体识别任务。在暗网分析领域,文献[28]运用ElMo-BiLSTM-CNN模型,实现了暗网交易市场中交易相关实体的抽取。文献[8,29-30]亦关注深度学习方法在暗网公共风险、毒品、非法交易等场景下实体识别问题上的应用。文献[7]聚焦于用户身份标识信息聚合问题,提出一种实体关系敏感的共指关系抽取模型,并引入少样本学习任务解决暗网训练集不足的问题。
1.3" 多任务学习
针对一系列彼此相关的任务,多任务学习(Multi-Task Learning)旨在共享多个学习任务中的有效信息以强化每种任务的性能。缓解数据稀疏性问题是多任务学习的一项重要目标,它被证明可以充分利用数据中的现有知识,降低数据要求和标记成本[31]。针对利用大规模预训练模型的场景,多任务学习也可实现对既有训练和微调成果的充分运用,降低模型训练所需的计算资源成本[32]。以上两个特性在解决暗网情报分析面临的训练文本不足、预训练微调成本过高方面均具有显著意义。文献[33]提出了一种基于多输出多任务学习的文本分类模式,对本文采取的多任务学习方案有所启发。
2" 基于BERT-BiLSTM的暗网内容分类和实体识别模型设计
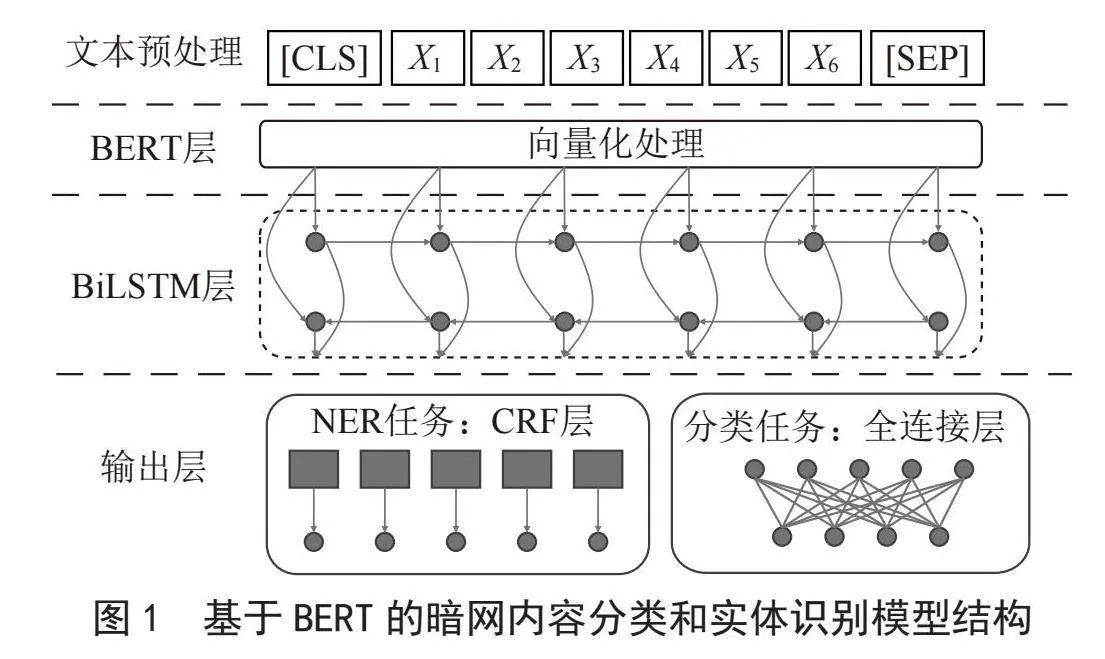
调研发现,暗网情报分析任务中,文本分类和实体识别两类任务间存在较强的相关性。例如对于非法数据买卖一类的帖文,文本内包含网站名、URL、数据量等实体的可能性较大;对于色情类内容,出现年龄、姓名等实体的可能性较大。两类任务共享相同的上下文信息,采取多任务模型方式可能有助于提高任务效率。基于此,提出了一个基于BERT-BiLSTM的暗网内容分类和实体识别多任务模型。模型采取多任务学习模式,共享BERT层和BiLSTM层参数,并为分类任务和实体识别任务添加不同的输出层。模型设计如图1所示。
2.1" BERT层
BERT模型该模型使用自注意力机制分析文本序列中的语义特征,可实现对更大范围的文本上下文特征的分析和捕捉。在输入BERT层前,首先需要对暗网帖文文本进行预处理,包括:1)去除帖文中的HTML标签、无关信息等数据;2)利用BERT的tokenize()方法将文本信息转换为BERT可处理的token序列;3)添加特殊符号,包括:在序列开头和中间添加[CLS]、[SEP]标记、在分类任务的训练数据中添加$和#以标记实体、对长度不足的短文本序列添加[PAD]用以补足。将预处理后文本序列输入BERT层,将获得张量H作为输出:
(1)
其中,Ho为预处理后的token序列,hi为第i个token的词向量。
2.2" BiLSTM层
尽管BERT的自注意力机制已能一定程度解决上下文问题,但作为通用预训练模型,BERT并未显式建模序列顺序、依赖等数据;而在暗网情报分析的特定场景中,引入LSTM可以更细致地捕捉序列的依赖信息,提高模型的特征提取能力,同时优化模型的鲁棒性。考虑到暗网文本同时存在前向依赖和后向依赖,我们选用BiLSTM模型实现双向的上下文信息捕捉。
BiLSTM的双向处理过程可表示为式(2):
(2)
对于每个时间步t,ht为BERT输出的特征词向量,、分别为正向、反向的隐藏状态。输出H′则为每个时间步下正向、反向LSTM隐藏状态的连接。
2.3" 输出层
针对分类任务,经过BiLSTM处理的H′已包含足以实现分类的信息。为了实现分类,我们取出H′中对应[CLS]的初始向量hc,并通过一个全连接层Wc将序列特征映射到类别空间,如式(3)所示;最终,使用Softmax函数输出类别概率,如式(4)所示:
(3)
(4)
尽管可以处理长文本间的依赖关系,但针对命名实体任务所需的标签之间的依赖关系,BiLSTM则不足以实现。添加一个CRF层以实现标签间依赖关系的处理,提高实体识别任务输出的准确率。将BiLSTM层的输出通过一个全连接层输入CRF,则标签序列H的总得分Sh可以表示为式(5)(6):
(5)
(6)
其中,Y={y1,y2,…,yn}为经过全连接层Wn处理后的向量集合,为位置i对应标签yi的得分, 为从标签yi-1转移到标签yi的得分。
2.4" 多任务损失计算
为了平衡文本分类和实体识别两类任务的影响,采用动态权重计算总的任务损失。记分类任务的损失函数为,实体识别任务的损失函数为,则总损失函数表示为:
(7)
其中,α(t)、β(t)分别为两类任务的损失权重函数,以时间步t为自变量,采取不平衡损失法计算:
(8)
(9)
这可以避免某一单项任务的损失主导训练过程,有助于降低模型对单一任务过拟合的概率。基于两类任务的损失函数分别计算其梯度后,在加权累积基础上采取梯度下降法反向传播到共享层:
(10)
(11)
(12)
其中,η为学习率。
3" 实验与结果分析
3.1" 数据集计算
爬取了暗网12 107个中文页面,经预处理去除其中图片、无文本信息、文本信息过短网页后,共获得7 210个暗网网页文本数据。对标注完成的数据以8∶1∶1的比例划分为训练集、验证集和测试集。
对训练集和验证集,基于以下方案,构建文本分类和实体识别两类集合:
1)文本分类。参考暗网文本聚类分析和人工分析结果,将暗网网页文本处理为网络攻击、色情、毒品、赌博、洗钱、枪支、假证、数据交易、软件、定制服务10个犯罪线索类别。
2)实体识别。根据暗网文本内容的特征和词频分析结果,标注了以下6类命名实体:数据类(DATA)、网络安全类(SECURITY)、毒品类(DRUG)、资金类(FINANCE)、色情类(PORNOGRAPHY)和账号类(ACCOUNT)。其中,前5类为各类别下帖文中的词语和“黑话”,第6类“账号”类别则以暗网文本中常见的账号信息为主,如Twitter、Telegram、Discord账号等。
3.2" 实验环境和评价指标
实验环境的软硬件配置如下:CPU Intel Core i7 12700H@4.70 GHz,内存40 GB;GPU NVIDIA GeForce RTX 3060 Laptop,显存6.0 GB;操作系统为Ubuntu Linux 22.04.4,内核版本 5.15.146.1。
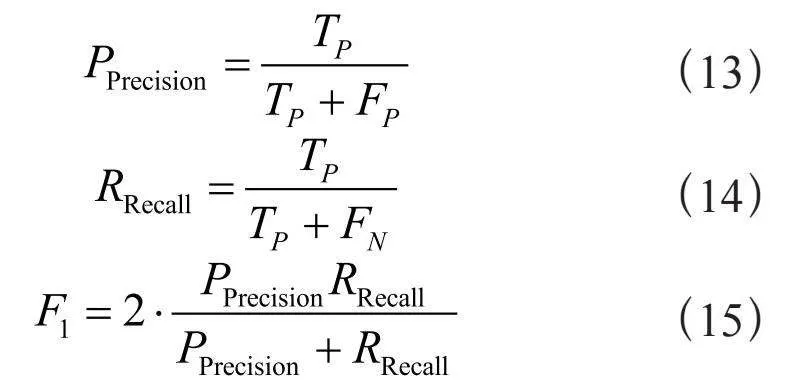
评价指标参考业界主流方式,采用准确率、召回率、F1分数作为性能评估指标。其中,准确率(Precision)也称查准率,指样本中正确预测为真的样本数占全部预测为真的样本数量的比例;召回率(Recall)也称查全率,指样本中正确预测为真的数量占实际为真的样本数量的比例。F1分数则是准确率和召回率的加权平均。各评价指标的计算公式如式(13)~(15)所示:
(13)
(14)
(15)
3.3" 实验设计和结果分析
3.3.1" 与基线模型的比较
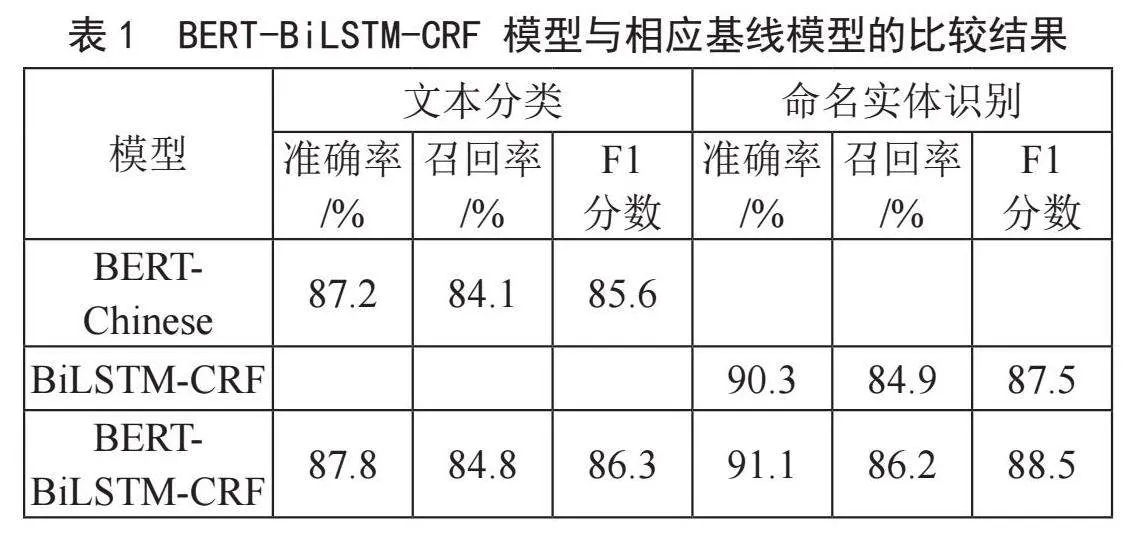
为全面评估本模型效果,选取原生BERT-Chinese模型、BiLSTM-CRF模型分别作为文本分类、实体识别任务的基线模型,测试结果如表1所示。
从表中可知,BERT-BiLSTM-CRF模型的识别效果相比原生的BERT-Chinese模型、LSTM-CRF模型,F1分数均有0.7%以上的提升。特别是针对实体识别任务中,BERT-BiLSTM-CRF模型相较原始BiLSTM-CRF模型具有约1%的水平提升,可认为是BERT良好的语义识别能力在暗网文本上取得了更好的学习效果。
3.3.2" 与单任务模型的比较
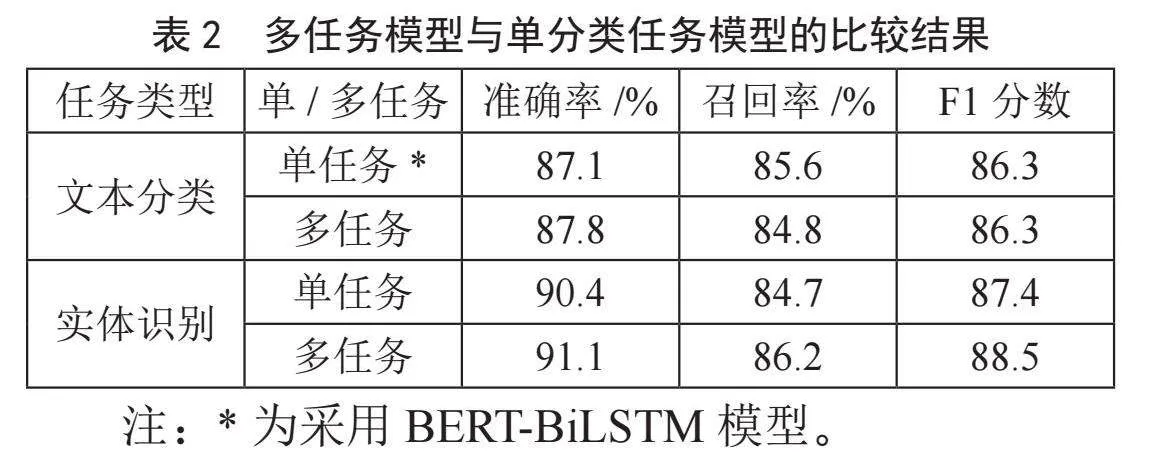
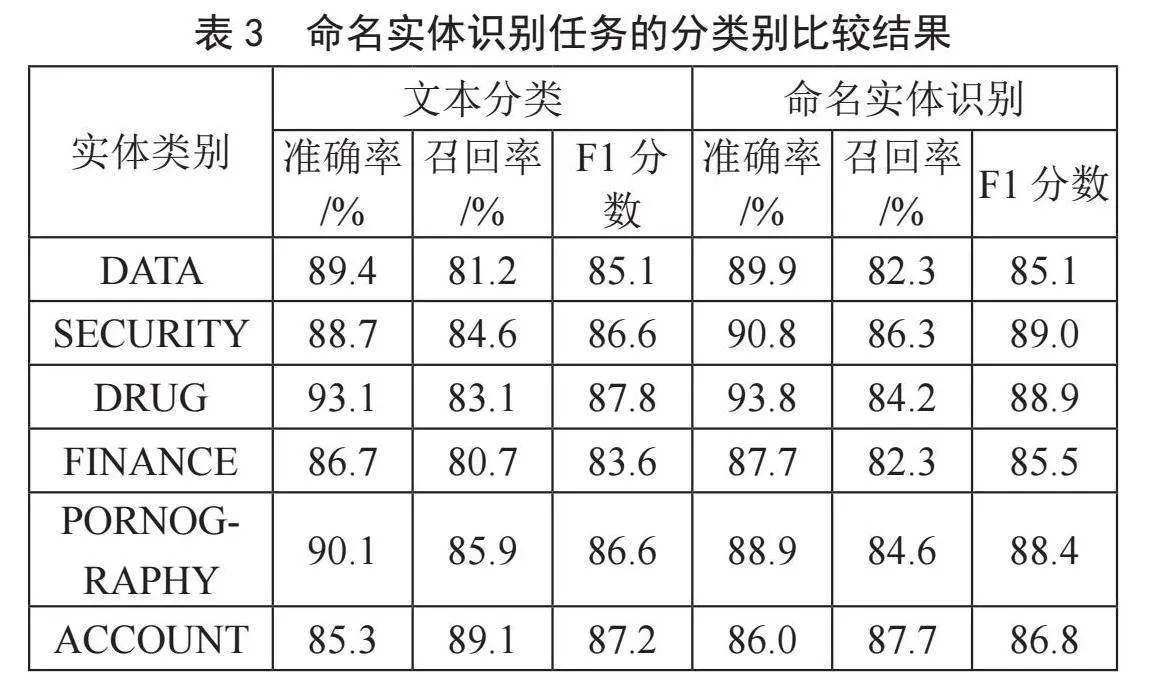
为验证多任务模型有效性,在文本分类、实体识别两类任务上分别将多任务实验结果与单一任务训练的BERT-BiLSTM-CRF模型相比较,结果如表2~表3所示。
可以发现,针对文本分类任务,共享BERT-BiLSTM层的促进作用较好,F1分数提升明显;针对实体识别任务,多任务模型对于DRUG、SECURITY、FINANCE、PORNOGRAPHY四类任务,F1分数均有提升,DATA类别持平;ACCOUNT类别的识别准确率虽有提升,但召回率和F1分数则不如单一任务训练的BERT-BiLSTM-CRF,推测是由于DRUG等类别的任务语义相关性较强,ACCOUNT类别的任务则与语义相关性较弱导致。
4" 结" 论
本文提出了一种基于BERT-BiLSTM-CRF的暗网犯罪情报挖掘模型,采用多任务模型方式共享BERT-BiLSTM两个语义层,帮助文本分类和特定类别的实体识别任务取得了更好的识别效果。同时,通过爬取和半自动标注构建了中文暗网违法犯罪文本训练数据集,并在此基础上验证了本文模型的有效性。本文研究对基于对于暗网违法犯罪情报的挖掘和自动化分析具有较强的现实意义。
目前,本文所提出的暗网犯罪情报挖掘模型仍限于使用文本本身信息开展训练,对于有关部门在过往打击过程中形成的知识积累尚未能有效运用。未来研究将继续探索将知识图谱等知识工程方法引入暗网犯罪情报自动化挖掘的方法,进一步提升暗网违法犯罪情报的挖掘和分析效率。
参考文献:
[1] 罗俊.滋蔓的暗网及网络空间治理新挑战 [J].学术论坛,2020,43(5):1-12.
[2] 王枫梧.我国暗网犯罪现状、治理困境及应对策略 [J].中国人民公安大学学报:社会科学版,2022,38(1):12-19.
[3] SHILLITO M R. Untangling theDark Web: An Emerging Technological Challenge for the Criminal Law [J].Information amp; Communications Technology Law,2019,28(2):186-207.
[4] MOHD AMINUDDIN M A I,ZAABA Z F,SAMSUDIN A,et al. The Rise of Website Fingerprinting on TOR: Analysis on Techniques and Assumptions [J].Journal of Network and Computer Applications,2023,212:103582(2023-01-21).https://doi.org/10.1016/j.jnca.2023.103582.
[5] 朱懿,蔡满春,姚利峰,等.针对Tor暗网流量的MorViT指纹识别模型 [J/OL].计算机工程与应用,2024:1-14(2024-04-20).http://kns.cnki.net/kcms/detail/11.2127.TP.20240104.1104.016.html.
[6] FAYZI A,FAYZI M,AHMADI K D. Dark Web Activity Classification Using Deep Learning [J/OL].arXiv:2306.07980 [cs.IR].(2023-07-01).https://arxiv.org/abs/2306.07980.
[7] 王雨燕,赵佳鹏,时金桥,等.暗网网页用户身份信息聚合方法 [J].计算机工程,2023,49(11):187-194+210.
[8] 范晓霞,周安民,郑荣锋,等.基于深度学习的暗网市场命名实体识别研究 [J].信息安全研究,2021,7(1):37-43.
[9] 杨燕燕,杜彦辉,刘洪梦,等.一种利用注意力增强卷积的暗网用户对齐方法 [J].西安电子科技大学学报,2023,50(4):206-214.
[10] 李明哲.基于Tor网站文本内容和特征的分类方法 [J].网络安全技术与应用,2021(8):36-39.
[11] HE S,HE Y,LI M. Classification of Illegal Activities on the Dark Web [C]//ICISS 19: Proceedings of the 2nd International Conference on Information Science and Systems.New York:Association for Computing Machinery,2019:73-78.
[12] DALINS J,WILSON C,CARMAN M. Criminal Motivation on the Dark Web: A Categorisation Model for Law Enforcement [J].Digital Investigation,2018,24:62-71.
[13] RENNIE J D,SHIH L,TEEVAN J,et al. Tackling the Poor Assumptions of Naive Bayes Text Classifiers [C]//Proceedings of the 20th international conference on machine learning (ICML-03).Washington,D.C.:MIT Press,2003:616-623.
[14] ALBAWI S,MOHAMMED T A,AL-ZAWI S. Understanding of a Convolutional Neural Network [C]//2017 International Conference on Engineering and Technology (ICET).Antalya:IEEE,2017:1-6.
[15] MEDSKER L R,JAIN L,et al. Recurrent Neural Networks: Design and Applications [J].Boca Raton:CRC Press,1999.
[16] HOCHREITER S,SCHMIDHUBER J. Long Short-Term Memory [J].Neural Computation,1997,9(8):1735-1780.
[17] YAO L,MAO C,LUO Y. Graph Convolutional Networks for Text Classification [C]//Proceedings of the AAAI Conference on Artificial Intelligence.Honolulu:AAAI,2019:7370-7377.
[18] DEVLIN J,CHANG M W,LEE K,et al. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].https://doi.org/10.48550/arXiv.1810.04805.
[19] RADFORD A,WU J,CHILD R,et al. Language Models are Unsupervised Multitask Learners [EB/OL].[2024-04-20].https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
[20] SABBAH T,SELAMAT A,SELAMAT M H,et al. Hybridized Term-Weighting Method for Dark Web Classification [J].Neurocomputing,2016,173:1908-1926.
[21] MURTY C A S,RUGHANI P H. Dark Web Text Classification by Learning Through SVM Optimization [J].Journal of Advances in Information Technology,2022,13(6):624-631.
[22] 洪良怡,朱松林,王轶骏,等.基于卷积神经网络的暗网网页分类研究 [J].计算机应用与软件,2023,40(2):320-325+330.
[23] DALVI A,SHAH A,DESAI P,et al. A Comparative Analysis of Models for Dark Web Data Classification [C]//Proceedings of International Joint Conference on Advances in Computational Intelligence.Singapore:Springer Nature Singapore,2024:245-257.
[24] ZHOU G,SU J. Named Entity Recognition Using an HMM-based Chunk Tagger [C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL,2002:473-480.
[25] EKBAL A,BANDYOPADHYAY S. Named Entity Recognition Using Support Vector Machine: A Language Independent Approach [J].International Journal of Electrical and Computer Engineering,2010,4(3):589-604.
[26] YAO L,SUN C,LI S,et al. Crf-based Active Learning for Chinese Named Entity Recognition [C]//2009 IEEE International Conference on Systems, Man and Cybernetics.San Antonio:IEEE,2009:1557-1561.
[27] HUANG Z,XU W,YU K. Bidirectional LSTM-CRF Models for Sequence Tagging [J/OL].arXiv:1508.01991 [cs.CL].(2015-08-09).http://arxiv.org/abs/1508.01991.
[28] SHAH S A A,MASOOD M A,YASIN A. Dark Web: E-Commerce Information Extraction based on Name Entity Recognition Using Bidirectional-LSTM [J].IEEE Access,2022,10:99633-99645.
[29] ZHANG P,WANG X,YA J,et al. Darknet Public Hazard Entity Recognition based on Deep Learning [C]//Proceedings of the 2021 ACM International Conference on Intelligent Computing and its Emerging Applications.ACM:New York,2021:94-100.
[30] DALVI A,SHAH V,GANDHI D,et al. Name Entity Recognition (NER) Based Drug Related Page Classification on Dark Web [C]//2022 International Conference on Trends in Quantum Computing and Emerging Business Technologies (TQCEBT).Pune:IEEE,2022:1-5.
[31] ZHANG Y,YANG Q. A Survey on Multi-Task Learning [J].IEEE Transactions on Knowledge and Data Engineering,2021,34(12):5586-5609.
[32] TORBARINA L,FERKOVIC T,ROGUSKI L,et al. Challenges and Opportunities of Using Transformer-based Multi-Task Learning in NLP Through ML Lifecycle: A Position Paper [J/OL].Natural Language Processing Journal,2024,7:100076(2024-05-09).https://doi.org/10.1016/j.nlp.2024.100076.
[33] ZHAO W,GAO H,CHEN S,et al. Generative Multi-Task Learning for Text Classification [J].IEEE Access,2020,8:86380-86387.
作者简介:周宇(1986—),男,汉族,江苏盐城人,硕士,研究方向:网络安全技术、网络犯罪侦查;蔡都(1997—),男,汉族,江苏盐城人,硕士研究生在读,研究方向:网络安全技术、网络安全治理。