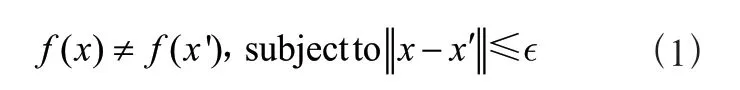
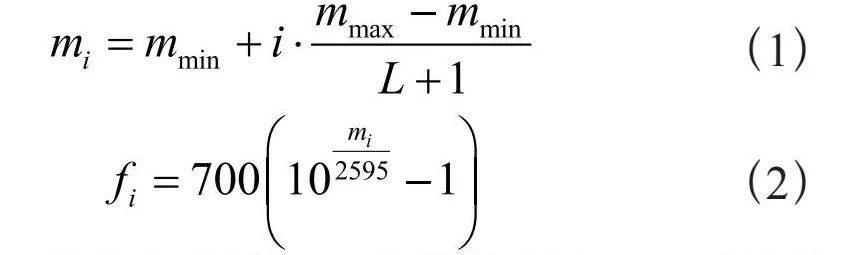

摘" 要:随着人工智能技术的不断进步,语音识别技术作为人工智能技术领域的一项关键技术,可以帮助医生和护士更高效的沟通和操作。文章提出了一种基于YAMNet模型迁移学习网络的智能手术语音识别方法,通过迁移学习技术将YAMNet模型应用于手术语音识别任务中,实现对手术器械清点过程中语音的自动识别。首先收集了手术清点常用器械语音数据,其次利用训练集对迁移学习后的网络模型进行训练,最后通过验证集对该网络模型进行验证。实验结果表明,所提方法在智能手术语音识别任务中取得了显著的性能,识别准确率达到97%,为智能手术系统的发展提供了新的思路和方法。
关键词:语音识别;YAMNet;迁移学习;手术清点
中图分类号:TP39;TP183 文献标识码:A 文章编号:2096-4706(2024)24-0061-05
Research on Intelligent Surgical Speech Recognition Based on YAMNet Transfer Learning
SUN Wenye1, XU Wei2, WANG Chunliang1
(1.The Second Affiliated Hospital of Soochow University, Suzhou" 215004, China;
2.Changshu Institute of Technology, Suzhou" 215500, China)
Abstract: With the continuous advancements in Artificial Intelligence technology, as a key technology in Artificial Intelligence technology field, speech recognition technology can help doctors and nurses communicate and operate more efficiently. This paper proposes an intelligent surgical speech recognition method based on the YAMNet model and Transfer Learning network. By Transfer Learning technology, it applies the YAMNet model to surgical speech recognition tasks, realizing automatic speech recognition during the counting of surgical instruments. Firstly, speech data of commonly used surgical instruments during the counting process is collected. Secondly, the network model after Transfer Learning, is trained using the training set. Finally, the network model is validated by the validation set. Experimental results show that the proposed method achieves significant performance in intelligent surgical speech recognition tasks, with a recognition accuracy rate of 97%, providing new ideas and methods for the development of intelligent surgical systems.
Keywords: speech recognition; YAMNet; Transfer Learning; counting of surgical instruments
0" 引" 言
智能化手术室可以实现手术室内部的非接触式远程示教、手术识别、手术全流程信息的管理。近些年,随着人工智能技术的不断进步,如语音识别技术等,使得通过非接触式的方式实现人与计算机之间的相互交互得以实现,这些技术的发展为建立新型的非接触式自然交互智慧化手术室信息系统提供了得以实现的方法和技术上的可能[1]。2019年中国科学院软件研究所联合陆军军医大学,将语音识别技术和多模态信息处理技术相融合,构造了手术室无菌条件下的非接触式多通道的自然交互环境,使得医生在需要观察相关病灶成像时,可以通过相应的语音命令、手势命令等非接触式交互方式快速定位到,为智能化手术室提供了技术与方法验证[1]。
作为手术患者进行诊断、治疗、手术及抢救的重要场所的手术室,随着手术量的不断攀升,对手术室护理工作提出严峻的挑战,手术室护理工作也将面临巨大压力[2]。手术清点记录是手术护理重要一环,其中的清点记录单是手术室护士对手术患者术中所用器械、敷料等相关物品的记录,是手术过程中的重要记录文书,应当在手术结束后即时完成。但在临床中手术清点记录单在实际操作时会出现各种各样的问题,如书写不规范、不准确等,如何避免和减少这些问题是手术室管理者急需解决的问题[3]。华中科技大学同济医学院附属协和医院于2019年尝试基于PDA移动技术实现手术器械质量追踪与数据清点一体化共享,通过前后馈控制方法,形成器械质量追踪与器械清点的闭环管理,提高护理工作效率,但存在改变医护人员的工作习惯、PDA书写不太方便等问题[4]。在实际临床工作中,手术室清点物品时需坚持“点唱”原则。语音识别技术可以在不改变临床操作流程的基础上,在“点唱”的过程中智能地完成手术器械清点单的内容,解放手术人员双手,减少重复录入操作,进而提高效率。然而,国内外对语音识别技术的应用主要集中于医生电子病历的录入[5-6],对手术室环境中的语音识别技术尚在探索期,其中针对手术护理中的智能语音技术少之又少。传统的语音识别系统往往受到噪音干扰、特定场景下的识别困难等问题的限制,因此需要更加高效和精准的解决方案。
近年来,深度学习技术的持续进步为语音识别领域注入了新的活力和可能。YAMNet是一个基于深度学习的预训练模型,可以有效地提取音频中的语义特征,被广泛应用于音频分类和分析任务中[7]。本论文旨在提出一种基于YAMNet模型迁移学习神经网络的智能手术清点语音识别方法,通过利用YAMNet模型提取音频特征,并结合迁移学习技术,实现对手术过程中语音指令的自动识别和清点。本文将探讨该方法模型设计的原理、实现的方式以及实验结果的验证,以期为智能手术系统的进一步发展提供新的思路和方法。
1" 方法模型设计
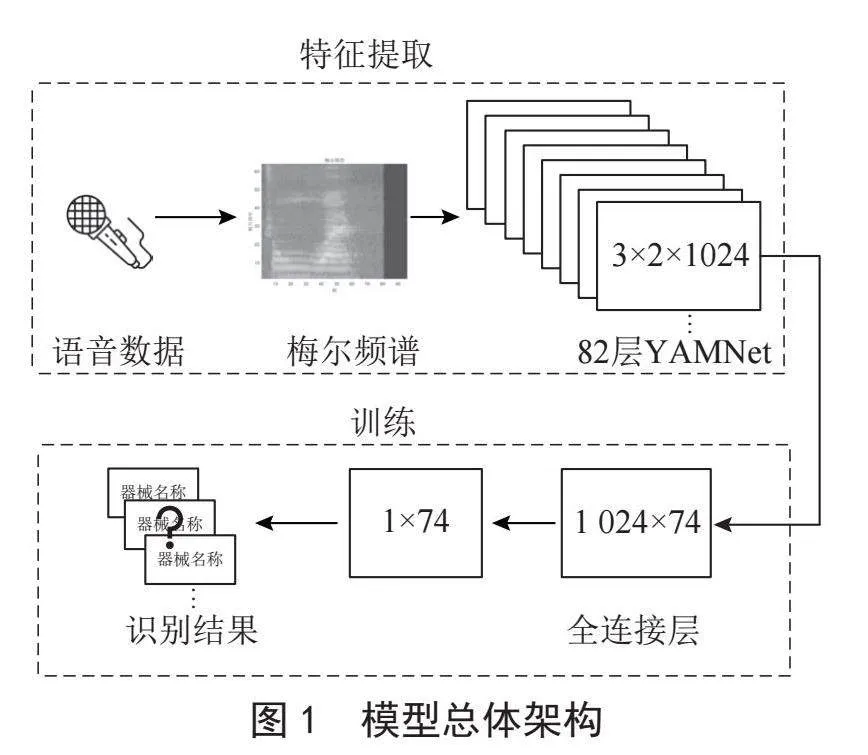
本文所提出的基于YAMNet模型迁移学习神经网络的智能手术语音识别方法总体架构如图1所示,主要包括语音信号采集、语音信号预处理、语音信号特征提取、YAMNet迁移学习神经网络模型训练。将原始语音数据进行预处理以及特征提取后,对获取到的数据进行数据集分割,分割成训练集和验证集。使用训练集数据训练迁移学习网络,再使用验证集数据进行识别验证,最后得到该迁移学习神经网络语音识别系统的识别结果。
1.1" 语音采集
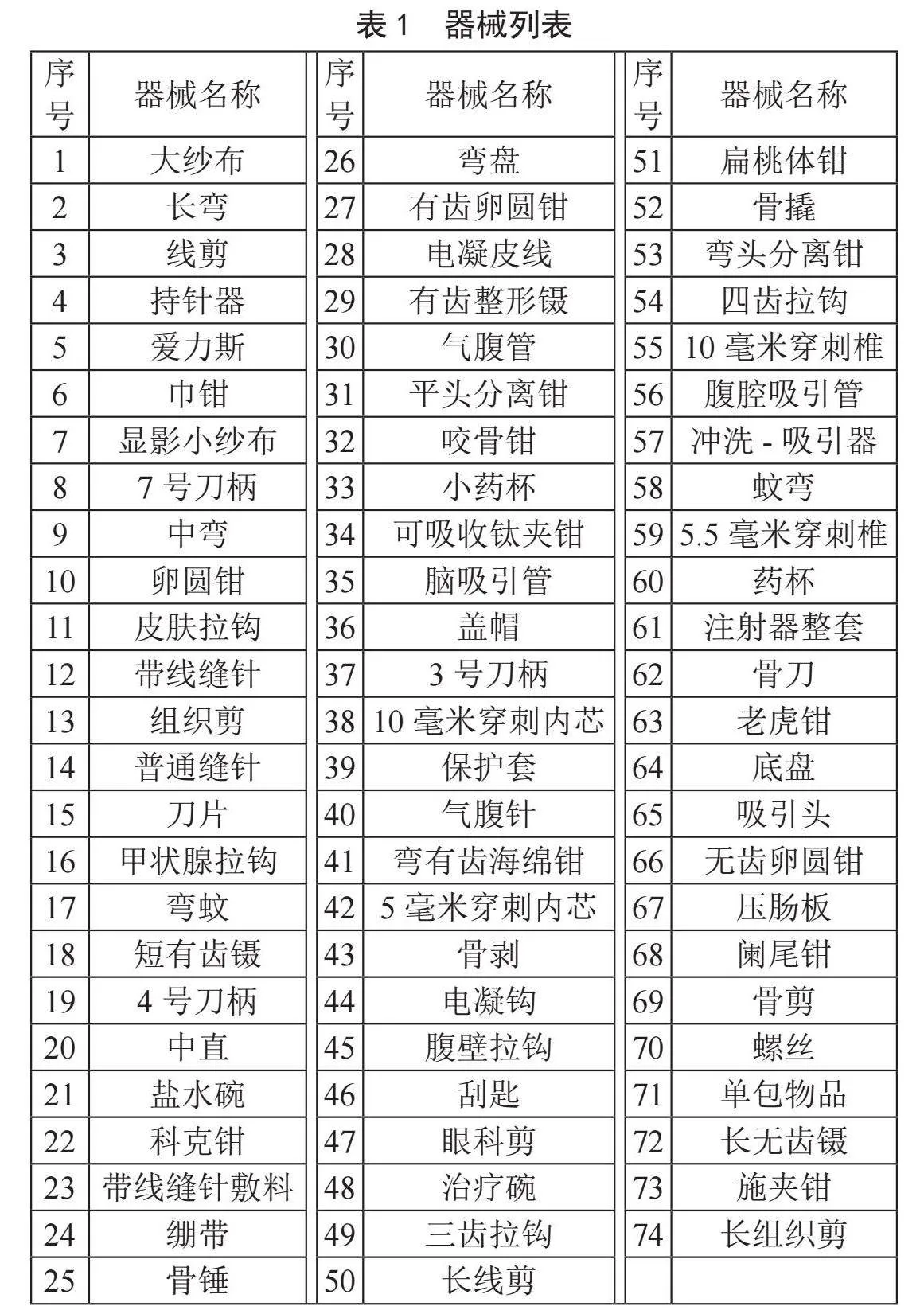
分析了某三甲医院2023年全年手术清点记录单,从中选取出现频次最高的74种手术器械,器械列表如表1所示。对其分别采集了16例样本的音频数据,组成1 184个不同语音的语音库,其采样率为48 000 Hz。文中的音频样本采用了作为音频数据标准的WAV文件格式。
本实验聚焦于孤立词语音识别的研究,所处理的语音片段时长主要在0.5秒至2.7秒之间,对于孤立词语音识别来说,相比时序相关信息,语音的全局信息要更加重要。在实际操作过程中,我们首先对每段语音进行分帧、加窗以及音频增强等预处理步骤,以便为后续的特征提取工作奠定基础。随后,我们进一步提取语音中的特征信息,为后续的语音识别任务提供关键依据。最后构建迁移学习网络模型。
1.2" 语音信号预处理
为了确保识别模型的兼容性和理想输入,从而提高模型的鲁棒性和模型的泛化能力,要对语音信号进行预处理。通过在训练过程中引入音频增强技术,模型可以更好地适应各种不同的语速、语调和发音方式,从而提高其在真实世界中的性能。本文通过时间伸缩、时间偏移、音量调节、音调调节等技术对原始音频进行增强,从而增加样本的数量和泛化性。
1.3" 语音特征提取
特征提取的过程就是去除冗余信息提取重要信息的过程,特征参数的选择对整个系统具有举足轻重的影响,它的最重要的两个因素是有效性和鲁棒性。人耳对于听觉反馈具有非线性特征,语音特征参数应能反映出这一特性。研究表明这些非线性特征的倒谱系数不受音频特性的影响,不仅对输入的语音信号没有特定要求,还能直接运用人耳的听觉模型。提取这些特征参数后,语音信息能够与实际工作中人耳的听觉特性高度契合,即使在信噪比低于标准音频要求的情况下,仍能保持良好的语音识别性能,从而展现出优越的鲁棒性[8]。本文采用梅尔频谱(Mel-spectrogram)对每段音频信号进行特征提取。整个语音特征提取的过程可以概括为:重采样、分帧/填充、短时傅里叶变换(Short Time Fourier Transform, STFT)、梅尔滤波器组、对数运算、标准化。
预处理过程主要包含重采样、分帧/填充等操作。重采样主要用于将音频信号重采样到16 000 Hz,与YAMNet网络相匹配[7]。分帧主要用于将音频信号切割为960毫秒的片段,而填充则用于对音频过短信号的填充,通常是补零,从而达到960毫秒的长度。
短时傅里叶变换(STFT)主要用于提取单边带时间频率图。傅里叶变换的长度为512点、步进长度为10毫秒。梅尔滤波器组则用于将线性功率谱转换为梅尔频率刻度上的非线性功率谱[9]。梅尔滤波器通常设计为三角滤波器,并在梅尔尺度上等间隔分布。即滤波器的中心频率首先在梅尔尺度上等间距分布,然后再转换回线性频率。中心频率计算式如下:
(1)
(2)
其中,mi是梅尔频率,fi是线性频率,L是滤波器的数量。
最后将所有提取特征用于构建基于YAMNet的迁移学习神经网络,实现不同语音的识别。
1.4" YAMNet模型迁移学习网络
在传统的分类识别学习中,为了确保训练后的神经网络具有较高的识别准确率,通常会采用独立同分布的训练集和测试集。此外,通过增加训练样本的数量也可以提升训练效果。然而,在实际应用中,同时满足这两个条件往往是困难的。对于医院而言,对手术清点而言,缺少大规模的标记样本。迁移学习是将一个已经训练好的模型参数迁移到另一个新的神经网络模型中,并使用迁移来的参数辅助新的神经网络模型进行训练[9],这将在保证识别率的基础上,同时大大减少训练的时间和复杂度。
深度迁移学习方法的优势在于其能够同时处理分类识别任务和源域到目标域的迁移任务。一方面,深度迁移学习在学习过程中整合了这两项任务,另一方面,这种端到端的训练方式不仅能提取更具表现力的相关特征,还摒弃了传统迁移学习中先迁移再分类的步骤。因此,深度迁移学习方法更加简洁,且更符合实际应用的需求[10]。
YAMNet是Google开发的一个预训练模型,用于对音频信号进行高效的音频事件分类。它可以识别数千种不同的声音,包括动物声、乐器声、自然声音等。YAMNet是建立在深度学习技术基础上的,利用了卷积神经网络(Convolutional Neural Network, CNN)对音频信号进行处理和分类[11]。
对于YAMNet的迁移学习,基本思路是将YAMNet的预训练模型作为基础模型,然后根据新的任务需求进行微调或调整。下面是YAMNet迁移学习的工作流程:
1)基础模型加载。从已经训练好的YAMNet模型中加载预训练权重。这个模型通常在大型音频数据集上已进行了训练,能够提取有效的音频特征。
2)修改输出层。根据任务需求,修改YAMNet模型的全连接层,使其能够适应新的分类识别任务。同时,设置全连接层的学习速度是其他层的10倍。
3)微调模型。使用新的数据集对模型进行训练。在训练过程中,YAMNet模型的权重会根据新数据集进行调整,以便更好地适应新的分类识别任务。通常会采用较小的学习率进行微调,以防止过度调整预训练权重。
4)评估模型性能。训练完成后,评估模型在新任务上的性能。可以使用各种指标(如准确率、精确率、召回率等)来评估模型的性能。
5)调整和优化。根据评估结果,对模型进行进一步的调整和优化,例如增加训练数据量等。
总的来说,YAMNet的迁移学习充分利用了预训练模型在大规模数据上学到的知识,并将其应用到新的分类识别任务中。通过微调模型,可在新分类识别任务上获得更好的性能,同时减少训练时间和数据需求。
2" 实验结果
本实验采用的实验环境为Windows 11家庭中文版,处理器13th Gen Intel(R) Core(TM) i7-13650HX 2.60 GHz,内存16 GB,在MATLAB下完成实验。在训练模型时,所有样本被分成训练集和验证集,比例为9∶1,利用YAMNet预训练网络构建迁移学习网络,使用Adaptive Moment(ADAM)优化算法训练,每一小批量训练样本数设置为128,总迭代周期为50个Epoch,在训练前所有数据都被随机打乱,学习率设为0.001。实验使用准确率(Accuracy)、AUC(Area Under Curve)、F1分数、精确率(Precision)、召回率(Recall)等标准分别评判实验方法的效果,具体的数据处理过程如下。
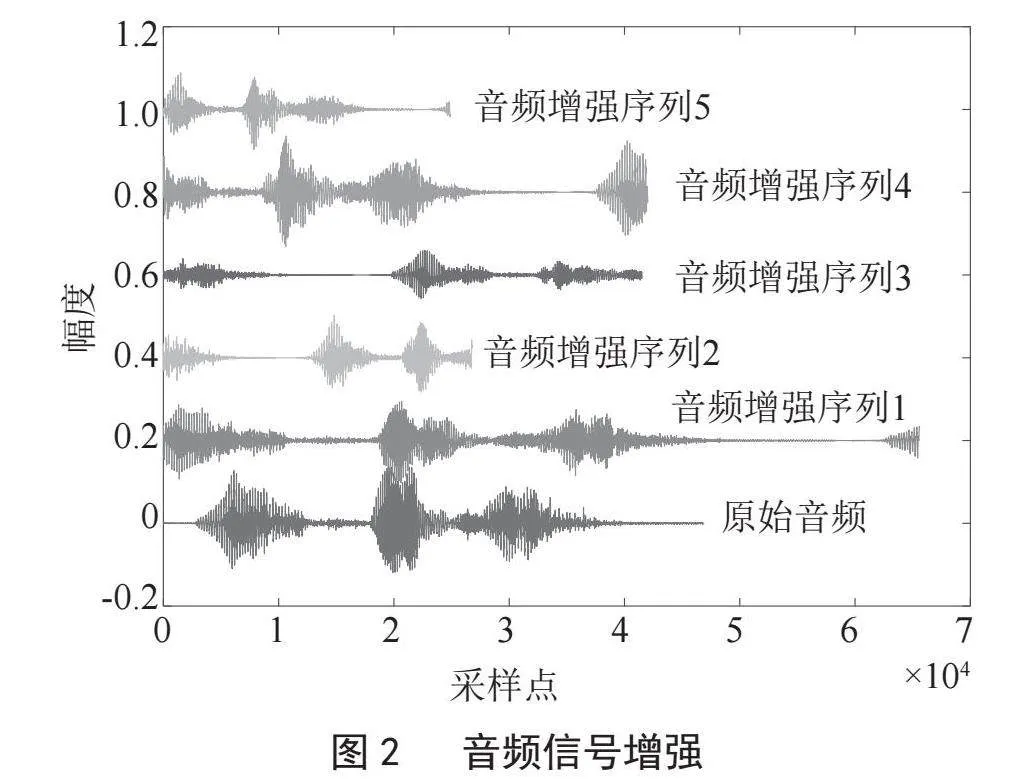
首先是音频数据集的增强处理。利用音频增强技术,包括时间伸缩、时间偏移、音量调节、音调调节等方法,对原始音频进行增强扩展,增加音频数据的泛化性,提升模型稳定性和精度。如图2所示,针对“眼科剪”的原始音频,利用音频增强技术,扩展出5条音频增强序列,该方法可以极大地提升训练数据集的泛化性能。
然后计算音频信号的梅尔频谱,提取特征,如图3所示,给出了图2原始音频“眼科剪”的梅尔频谱图,得到96×64的梅尔频谱图。
最后将所有梅尔频谱图构建音频识别数据集(36 815×96×64),并将数据集进行随机打乱,然后将其中的90%(33 134)作为训练,10%(3 681)作为验证。本文采用的模型构建方法是基于YAMNet预训练网络的迁移学习深度神经网络。YAMNet是一个基于MobileNet V1架构的音频分类模型,专门用于识别和分类各种环境音频事件,旨在通过轻量级的网络架构实现高效的音频分类识别任务。
YAMNet的架构可以分为以下几个主要部分:
1)输入层。输入是音频信号的log-Mel频谱图,尺寸为(T,64),其中T是时间帧数,64是Mel频带数量。
2)特征提取部分(基于MobileNet V1)。使用MobileNet V1的架构进行特征提取。MobileNet V1以其高效的深度可分离卷积而著称,大幅减少了参数量和计算量。
3)全局平均池化层。将特征图经过处理转变为固定大小的特性向量。
4)全连接层。将特征向量经过映射对应到不同音频类别。
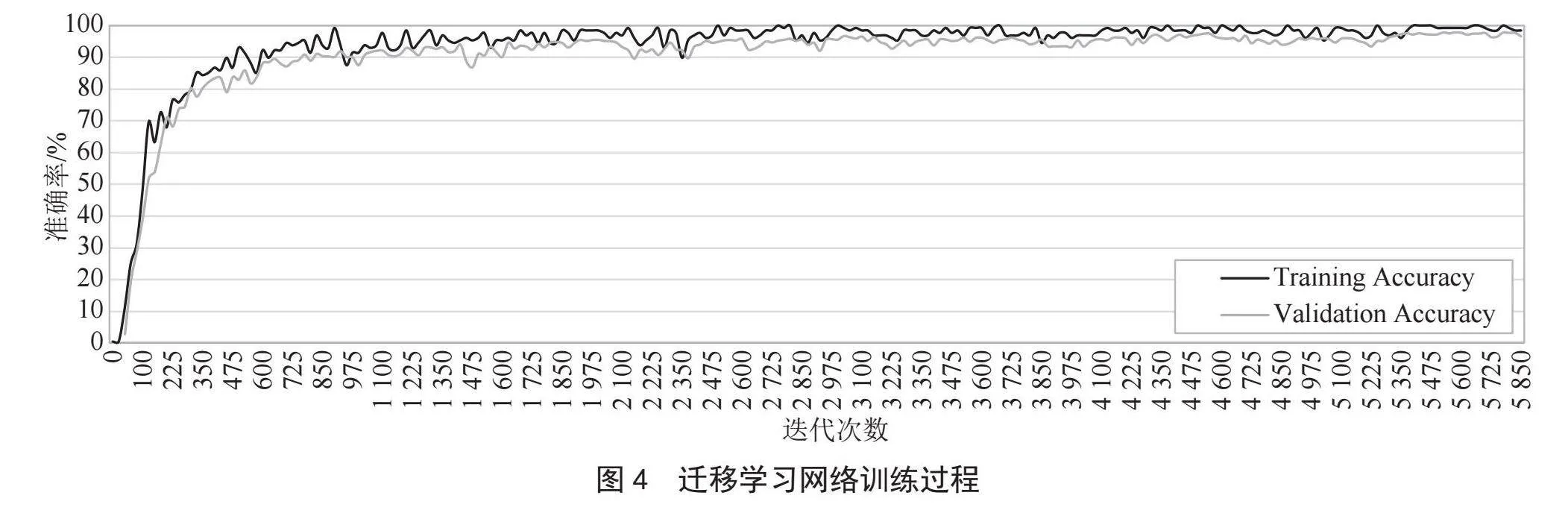
迁移学习中,我们将全连接层的输出层的节点数改为74,与音频分类的种类相同,并将该层的参数更新速度是其他层的10倍,便于全连接层参数的快速迭代更新,然后开始训练,训练过程如图4所示。
如图4所示,在模型迭代5 850次后,训练集准确率达到99%左右,而验证集的精度基本稳定在97%左右。随着迭代次数的增加,网络模型逐渐朝着收敛状态演进,损失逐渐降低,最终达到一个相对稳定的性能水平,可以看出模型表现良好,没有出现过拟合,实验结果如表2所示。
本文主要采用基于YAMNet模型迁移学习网络来实现手术清点语音识别,尽管使用了不同的语音数据集,实验结果仍然显示,即便目标数据集与预训练模型的源数据集有所不同,预训练特征依然普遍适用。此外,在语音识别应用中,迁移学习在小数据集上的效果显著,即便是非常小的数据库,也能实现近97%的精度和准确度,AUC接近1,表明检测方法的真实性高。小数据集的应用不仅减少了数据集生成的时间和成本,还缩短了模型训练时间,并降低了对计算资源的需求。实验结果表明,该方法模型在识别手术过程中的专业语音交流内容方面取得了良好的性能,具有较高的准确性和鲁棒性,在实际应用中具有重要的参考意义。
3" 结" 论
本文提出了一种基于YAMNet模型迁移学习网络的智能手术语音识别方法,该方法在手术专业术语器械清点语音识别中取得了良好的性能,同时具有较好的泛化性。在以后的研究中,将不断改进系统的设计和算法以及使用不同类型的声学模型,以此来探索更有效的深度学习模型和技术,以应对手术环境中的挑战和复杂性。
参考文献:
[1] 陶建华,杨明浩,王志良,等.无菌条件非接触式多通道自然交互手术环境 [J].软件学报,2019,30(10):2986-3004.
[2] 高兴莲,杨英,吴荷玉,等.影响手术物品清点准确性原因分析与改进措施 [J].医学信息,2013(20):630-631.
[3] 林珂,王芳,白菁,等.手术室专科护理专利成果的临床运用实践效果 [J].昆明医科大学学报,2018,39(11):143-148.
[4] 余文静,高兴莲,肖瑶,等.基于PDA移动技术融合手术器械质量追踪与数据清点的实践 [J].护理学报,2020,27(2):27-29.
[5] 丁中正,常翀,曹凯迪,等.医疗智能语音识别系统的建设与应用 [J].电子技术与软件工程,2022(1):188-191.
[6] 赵梦,任海玲,廖聪,等.智能语音识别技术在医疗领域中的应用研究 [J].中国现代医生,2022,60(28):108-112.
[7] VALLIAPPAN N H, PANDE S D, VINTA S R. Enhancing Gun Detection with Transfer Learning and YAMNet Audio Classification [J].IEEE Access,2024,12:58940-58949.
[8] 邓鑫瑞,孔建国.基于双向神经网络的民航陆空通话语音识别研究 [J].电脑与信息技术,2022,30(2):9-12+25.
[9] 蒋佳旺,陈艳,王佳庆.卷积神经网络与迁移学习的颅脑癌症识别方法的研究 [J].中国医疗设备,2020,35(9):70-73+83.
[10] 颜丙聪.基于迁移学习的语音识别算法研究 [D].南京:东南大学,2020.
[11] MOHAMMED K K,EL-LATIF E I A,EL-SAYAD N E,et al. Radio Frequency Fingerprint-based Drone Identification and Classification Using Mel Spectrograms and Pre-trained YAMNet Neural [J].Internet of Things,2023,23:100879.
作者简介:孙文业(1989—),女,汉族,安徽六安人,工程师,硕士,研究方向:语音信号处理;徐伟(1986—),男,汉族,江苏苏州人,讲师,博士,研究方向:人工智能;汪春亮(1979—),男,汉族,安徽铜陵人,高级工程师,硕士,研究方向:医疗信息化。