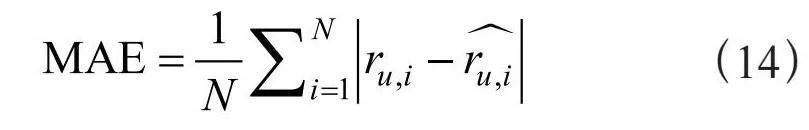


摘" 要:针对传统协同过滤算法的冷启动、推荐精度低等问题,提出基于用户特征和信任度的推荐算法(Recommendation Algorithm Based on User Characteristics and Trust, RA-UCT)。该算法首先利用用户的人口统计学信息和评分数据来计算特征相似度;然后在改进的相似度基础上,构建用户信任网络,计算综合信任度,在特征相似度和综合信任度两个维度上进行推荐。在MovieLens公共数据集上的实验结果表明,与传统协同过滤方法比较,提出的算法能够有效提高推荐精度,冷启动问题也得到有效缓解。
关键词:属性特征;信任度;协同过滤;冷启动
中图分类号:TP391.3;TP312 文献标识码:A 文章编号:2096-4706(2024)24-0049-05
Collaborative Filtering Recommendation Algorithm Based on User Characteristics and Trust
LI Peng
(Taiyuan Normal University, Jinzhong" 030619, China)
Abstract: Aiming at the problems of cold boot and low recommendation accuracy of the traditional Collaborative Filtering algorithm, a Recommendation Algorithm Based on User Characteristics and Trust (RA-UCT) is proposed. The algorithm firstly uses the users demographic information and rating data to calculate the feature similarity. Then, based on the improved similarity, it constructs a user trust network, calculates the comprehensive trust, and makes recommendations based on the two dimensions of feature similarity and comprehensive trust. The experimental results on the MovieLens public dataset show that compared with the traditional Collaborative Filtering method, the proposed algorithm can effectively improve the recommendation accuracy and effectively alleviate the cold boot problem.
Keywords: attribute characteristics; trust; Collaborative Filtering; cold boot
0" 引" 言
互联网技术的发展带来了数据量的急剧膨胀,这让用户从海量信息中筛选出有价值的内容变得更加困难。推荐系统(Recommendation System)[1-2]应运而生,有效缓解了信息超载[3]的问题。协同过滤推荐算法[4]作为目前最流行且成效显著的技术之一,在实际应用中却面临着用户和物品数量激增带来的挑战,如冷启动、数据稀疏性[5]等问题,这些问题严重制约了算法的推荐效果。为了应对这些挑战,本文深入探讨了协同过滤算法,并提出了一种融合用户特征和信任度的改进推荐算法。
1" 相关工作
在推荐系统的研究领域,冷启动和数据稀疏性问题一直是研究者关注的焦点。为了应对这些挑战,近年来,众多学者开展了一系列创新性的研究工作。韩立锋等[6]提出一种融合用户人口统计学信息与项目流行度的推荐算法,该算法首先通过聚类将用户划分为不同的簇,然后融合项目流行度进行个性化推荐。申艳梅等[7]提出了一种新的融合推荐算法,通过结合用户属性和项目属性,在一定程度上解决了冷启动问题。杨超等[8]提出融合人口统计属性的协同过滤推荐算法。该算法通过用户聚类和物品类内流行度的计算,改进了传统协同过滤算法中的用户相似度计算方法,可以有效提高推荐准确度。
上述算法虽然在一定程度上缓解了冷启动问题,但它们仍有改进空间,例如,某些算法主要基于用户间的共同评分项目来评估相似度,这可能忽略了那些没有共同评分记录的用户间的潜在联系。此外,一些算法涉及的计算量较大,这增加了算法的执行时间,从而影响了其时间效率。
在现有研究成果的基础上,本文提出了一种改进的推荐算法,该算法综合考虑了用户的个性特征和信任网络。首先,利用用户的人口统计属性,得到用户的属性相似度,将用户属性相似度和评分相似度加权融合,得到用户特征相似度;其次,挖掘不存在共同评分用户间的关系,构建用户信任模型,计算出直接信任度和间接信任度,最后将用户的特征相似度与信任度相结合来提高推荐精度。
2" 基于用户特征与信任度的推荐算法
2.1" 用户特征相似度
分别对人口统计学信息、用户评分数据分析计算,得到用户人口统计学相似度、评分相似度。将二者赋予适当的权重,得到了用户特征相似度。
2.1.1" 人口统计学相似度
注册系统的新用户,他们对商品的评分和反馈极为有限,甚至可能一片空白。在用户注册阶段,系统会收集一些基础的个人信息,如年龄、性别、职业、收入水平、教育背景以及居住地区等,这些信息有助于构建用户画像,为个性化推荐提供初步依据。相关研究表明[9],用户在年龄、性别、职业等人口统计学特征上的相似性往往与他们的兴趣爱好有较高的一致性,基于这一理论,本文将用户的年龄、性别和职业作为关键指标,构建了一个综合考量这三个维度的用户相似度评估模型。
用户群体覆盖范围大,从儿童到成年人不等,年龄差异较大。因此,本文采用参考文献[10]提出的利用负指数衰减函数对年龄差异进行相似性转换,两个用户之间的年龄相似性计算方法如式(1)所示:
(1)
其中,m = 3.8,n = 2。通过归一化将用户年龄值进行适当的调整,确保相似度指标取值在0~1之间,具体算式如(2)所示:
(2)
其中,ai表示用户的实际年龄,maxa、mina表示用户集中的最小年龄值和最大年龄值。
在计算性别和职业属性的相似度时,本文将采用重叠测度(简单匹配测度)进行处理,以量化这些非数值型特征。用0和1分别表示“男”和“女”,用不同的数字表示不同的职业,如式(3)所示:
(3)
其中,用户性别相同,则性别相似度gender_sim(u, v) = 1;职业相同,则职业相似度occupa_sim(u, v) = 1。
在构建用户相似度模型时,采用了动态权重分配策略,以反映不同人口统计学特征对用户偏好的影响。具体地,定义了三个权重系数:λ、β和γ(其中γ = 1-λ-β),分别对应年龄、性别和职业特征的重要性,如式(4)所示:
(4)
2.1.2" 融入热门商品惩罚的评分相似度
用户对项目的评分确实能够揭示他们之间的相似性,但这种相似性并不总是准确的。特别是对于广泛受欢迎的项目,尽管许多用户参与了评分,但这并不一定代表他们的偏好是一致的。当两个用户共同评分的项目主要是流行项目时,这可能会误导相似度的评估。在标准Pearson相似度[11]计算过程中,所有项目被赋予相等的权重,这种做法没有充分考虑项目流行度对相似度评估的影响。为了解决这一问题,对标准的Pearson相似度计算式修订为:
(5)
在式(5)中,I表示用户间共同评分项目集合,和分别表示用户u和用户v获得的平均评分,Ni表示项目i在评分数据中被评价的次数。
最后,结合用户属性相似度dem_sim(u, v)(式(4))与改进的Pearson相似度sim(u, v)(式(5)),形成综合的用户特征相似度Simd(u, v),如式(6)所示。在这个过程中,参数α作为一个权重因子,用于调整用户特征相似度的贡献度。
(6)
2.2" 用户间信任关系的度量
标准协同过滤推荐算法主要依赖于用户间共同评分的项目来评估他们的关系,这限制了算法对那些没有共同评分记录的用户间潜在联系的识别能力。为了解决这一局限性,本文引入了信任机制[12]的概念。
2.2.1" 直接信任度
假如用户之间存在共同评分的项目,则认为用户之间存在直接信任关系。利用Pearson相似度与Jaccard相似度[11]融合得到直接信任度,计算式如下所示:
(7)
其中,dT(u, v)表示用户u对用户v的直接信任度,simPearson(u, v)表示用户u和用户v之间的Pearson相关系数,simJac(u, v)表示用户u和用户v之间的Jaccard相关系数。
2.2.2" 间接信任度
考虑那些没有直接评分交互的用户,引入了间接信任度的概念,以评估他们之间的信任联系。这种评估依赖信任的传递性原理,如图1所示,U1与U2之间存在直接信任关系,U2与U3之间存在直接信任关系,而对于不存在直接信任关系的U1和U3,他们可以通过中间用户U2传递信任。根据六度分割理论(Six Degrees of Separation)可知,信任传递过程中不会超过6个中间节点[13]。
设用户u对用户v之间至少存在一条可传递路径,则可用表示可传递路径集合,每条路径可表示为,由此可知每条路径的权重ωi计算式如式(8)所示:
(8)
其中,d表示信任可以在用户间最多传递的层级数,其值设定为不超过6,dpi(u,v)表示第i条传递路径的长度。
则每条路径的间接信任度计算式如(9)所示:
(9)
综合考量了用户间多条信任传递路径的影响后,定义了用户u与用户v之间存在的可传递路径集合,记为S。基于此集合,得到用户u和用户v之间的间接信任度idTpi(u,v),计算式如(10)所示:
(10)
最终可知改进的用户综合信任度公式:
(11)
其中,Trust(u,v)表示用户综合信任度,Iu和Iv表示用户u和用户v所评价过的商品集合。
2.3" RA-UCT算法的预测评分
为了增强推荐算法的性能,从用户特征相似度和信任度两个关键维度出发,构建了一个综合的相似度评估框架,用以计算用户间的综合相似度。具体算式如下所示:
根据用户综合相似度Simf (u,v)进行评分预测,预测评分算式如下所示:
(13)
其中,H表示与用户u相关性最高的前n个近邻用户。
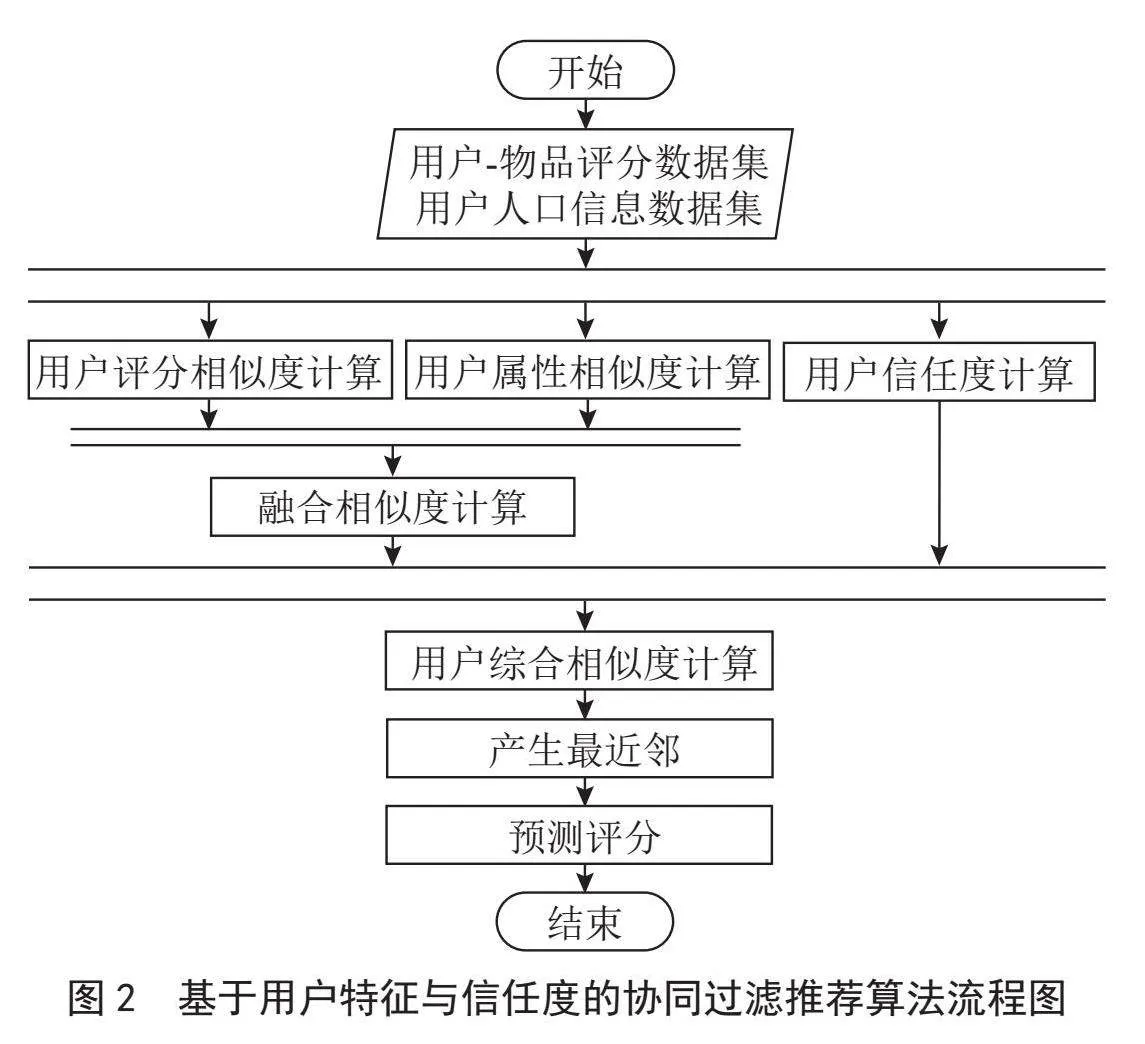
综上所述,RA-UCT算法克服了传统UBCF算法只依靠用户评分进行推荐的弊端,加入了用户的注册信息,将用户属性相似度与评分相似度融合,得到用户的属性特征,对冷启动问题进行了缓解;利用用户间的共同评分得到用户间信任关系,建立信任模型,使推荐结果更加准确。图2展示了算法的具体流程。
输入:用户-项目评分信息、用户特征信息
输出:用户预测评分
步骤:
1)提取人口统计学信息并建模,根据式(1)(3)得到年龄、性别、职业相似度分别为age_sim(u, v)、gender_sim(u, v)、occupa_sim(u, v)。
2)将构造好的age_sim(u, v)、gender_sim(u, v)、occupa_sim(u, v)根据式(4)融合,得到属性相似度dem_sim(u, v)。
3)根据式(5),得到改进的评分相似度sim(u, v)。
4)根据式(6),得到用户特征相似度Simd(u, v)。
5)结合Pearson相关系数和Jaccard相关系数,计算出用户间直接信任度dT(u,v)。
6)依据直接信任度计算用户间接相似度idTpi(u, v)。
7)将5)与6)结合得到用户综合信任度Trust(u, v)。
8)依据式(12),得到基于用户特征与信任度两个维度融合的用户综合相似度Simf(u, v)。
9)计算出目标用户的最近邻用户集。
10)对项目进行预测评分并推荐。
3" 实验
3.1" 数据集
本文选用了广为使用的MovieLens 100K作为实验数据集。该数据集收录了高达100 000条电影评分数据,涵盖了943位用户对1 682部不同电影的评分反馈。评分体系按照1至5的分值范围设计,其中5分代表用户对电影的高度喜爱。对于用户未观看或未进行评价的电影,数据集中相应的评分项被标记为0,以示区分。
本文实验的软件环境如下:操作系统为Windows 11,CPU为Intel Core i5-9300H,2.4 GHz,内存为16 GB,开发语言为Python。
3.2" 评价标准
实验采用平均绝对值误差(Mean Absolute Error, MAE)作为衡量标准。MAE指标反映了预测评分与实际评分之间的接近程度,其数值越低,意味着预测的准确性越高。
(14)
其中N表示预测的总次数,ru,i表示用户u对项目i的实际评分,表示用户u对项目i的预测评分。
3.3" 实验结果对比分析
3.3.1" 参数确定
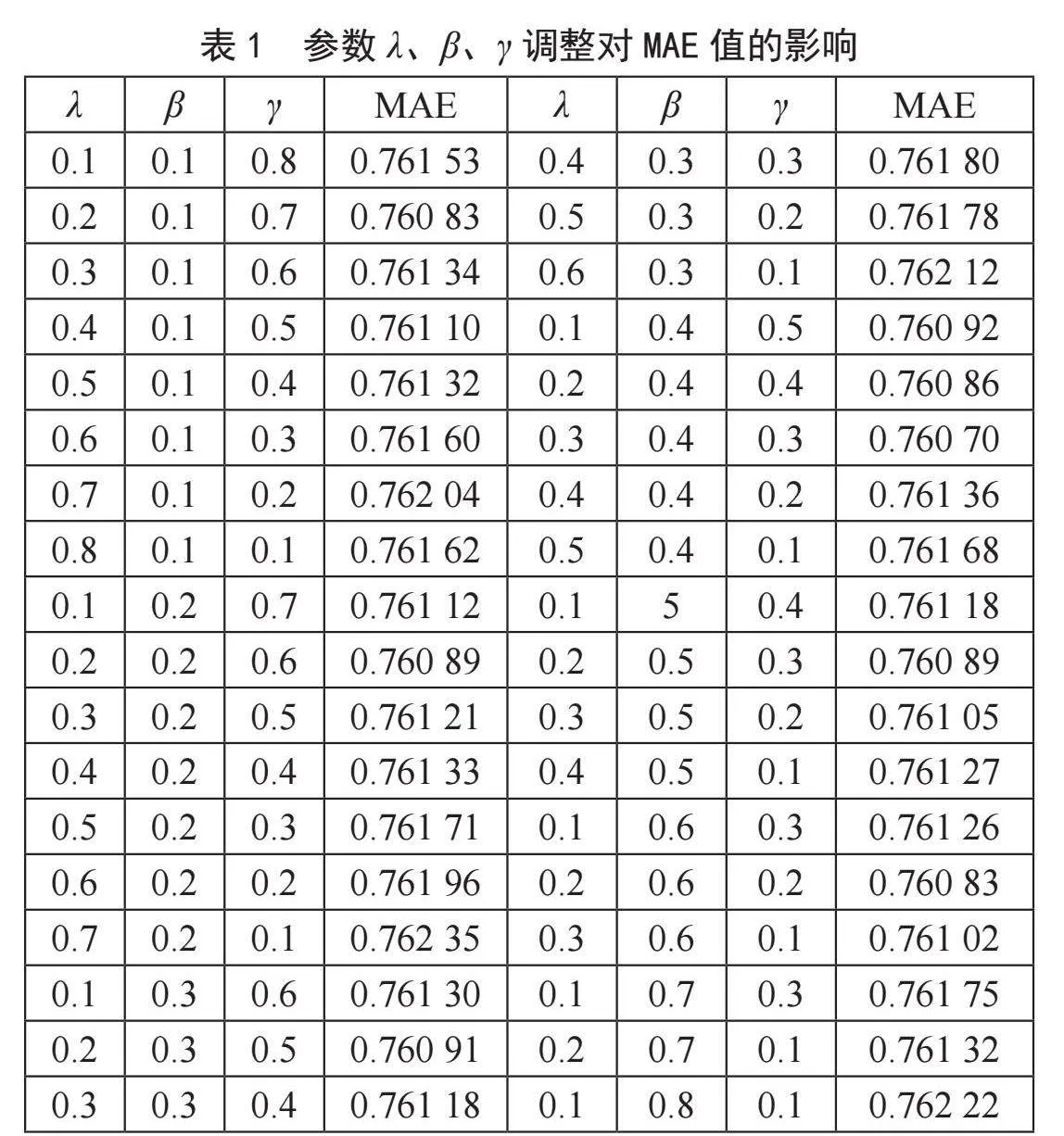
为了验证λ、β、γ对用户统计学相似度影响的差异,采用实验的手段对权重λ、β、γ的取值进行设置。从表1可以看出,当λ、β、γ的权重系数分别为0.3、0.4、0.3时,MAE的值最小。
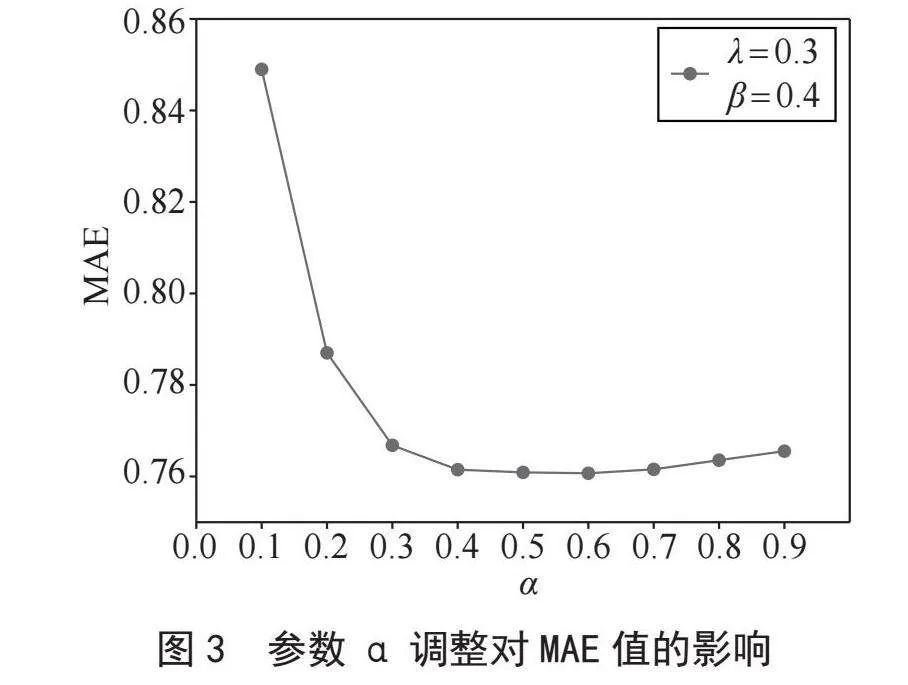
3.3.2" 用户属性相似度与Pearson相似度的参数调整
参数α调整对MAE值的影响如图3所示,可知当α = 0.6时,MAE值最小。
3.3.3" 本文算法与传统协同过滤算法比较
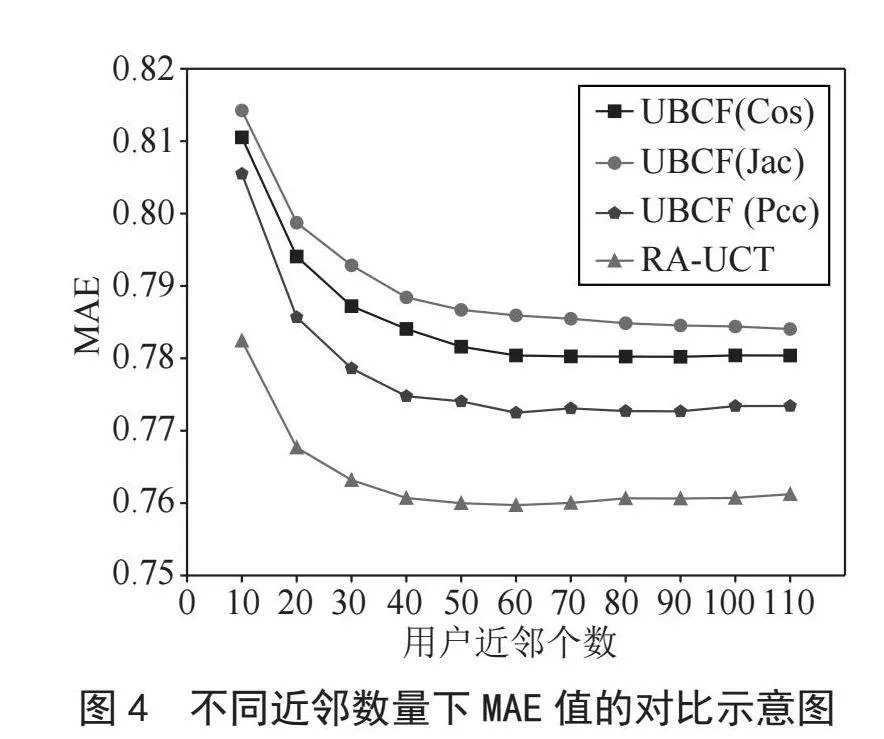
为了验证本文算法的性能,下面将本文提出的RA-UCT算法与传统的UBCF算法进行比较。在UBCF算法中,采用了传统的用户相似度度量方法,包括皮尔森相关系数、杰卡德相似度和改进的余弦相似度,观察在不同数量的最近邻条件下,评价指标MAE的变化。
根据图4所示的实验数据,可以观察到四种算法在初始阶段,即考虑较少的用户邻居时,平均绝对误差(MAE)相对较高,这表明预测的准确性有待提升;随着用户邻居数量的增加,MAE值逐渐降低并趋于稳定,反映了预测性能的稳步提高。此外,不同算法间的性能差异也较为显著,其中,本文提出的RA-UCF在实验中效果最好。
4" 结" 论
本文对传统的协同过滤算法进行改进,通过引入年龄、性别、职业三个用户属性信息,当用户不存在评分数据时,可以根据用户属性信息进行推荐,一定程度上缓解了冷启动问题;通过引入信任机制,使没有共同评分的用户也可以根据信任机制计算相似度,提高了推荐准确性。在公共数据集上的对比,证明了对算法的改进是有效的。但是本文还存在一定的不足,本文算法在计算用户特征相似度时只采用年龄、性别、职业三个属性,但是影响用户特征相似度还存在其他的因素,比如学历、地理位置等,在以后的研究中可以考虑将影响推荐效果的其他因素融合,更好地进行个性化推荐。
参考文献:
[1] NILASHI M,IBRAHIM O,BAGHERIFARD K. A Recommender System Based on Collaborative Filtering Using Ontology and Dimensionality Reduction Techniques [J].Expert Systems with Applications,2018,92:507-520.
[2] 李孟浩,赵学健,余云峰,等.推荐算法研究进展 [J].小型微型计算机系统,2022,43(3):544-554.
[3] SHI C,HU B B,ZHAO W" X,et al. Heterogeneous Information Network Embedding for Recommendation [J].IEEE Transactions on Knowledge and Data Engineering,2019,31(2):357-370.
[4] YE X J,YUAN P S,GUO X Q,et al. Collaborative Filtering Recommendation Algorithm Based on User Interest and Project Cycle [J].Journal of Nanjing University of Science and Technology,2018,42(4):392
[5] 赵俊逸,庄福振,敖翔,等.协同过滤推荐系统综述 [J].信息安全学报,2021,6(5):17-34.
[6] 韩立锋,陈莉.融合用户属性与项目流行度的用户冷启动推荐模型 [J].计算机科学,2021,48(2):114-120.
[7] 申艳梅,李亚平,王岩.基于用户属性和项目属性的融合推荐算法 [J].河南理工大学学报:自然科学版,2022,41(2):131-137.
[8] 杨超,艾聪聪,蒋斌,等.一种融合人口统计属性的协同过滤算法 [J].小型微型计算机系统,2015,36(4):782-786.
[9] WU Y F,WANG H R. Collaborative Filtering Algorithm Using User Background Information [J].Journal of Computer Applications,2008,28(11):2972-2974.
[10] AL-SHAMRI M Y H. User Profiling Approaches for Demographic Recommender Systems [J].Knowledge-based Systems,2016,100(5):175-187.
[11] 陈功平,王红.改进Pearson相关系数的个性化推荐算法 [J].山东农业大学学报:自然科学版,2016,47(6):940-944.
[12] YAHYAOUI H,AL-MUTAIRI A. A Feature-based Trust Sequence Classification Algorithm [J].Information Sciences,2016,328:455-484.
[13] 杜淑颖,丁世飞.基于六度分割理论的社交好友推荐算法研究 [J].南京理工大学学报,2019,43(4):468-473.
作者简介:李彭(1995—),男,汉族,河南南阳人,硕士在读,研究方向:推荐算法。