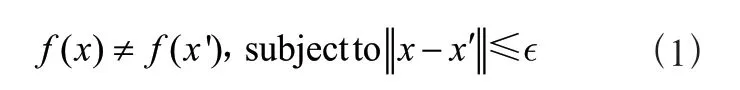


摘" 要:正确识别用户意图有助于提高医疗搜索的准确性,为医疗搜索系统的使用者提供便利。为了提高医疗搜索的意图识别准确率,文章利用中文医疗信息处理评测基准中的医疗搜索检索词意图分类数据集,对LERT预训练模型(Chinese-LERT-base)和BERT预训练模型(BERT-base-Chinese)进行了微调,并对微调后模型的意图分类准确率进行了评估。微调后的LERT模型在“治疗方案”“疾病表述”和“病因分析”类别的分类准确率较微调后的BERT模型分别提高了4.53%、8%和8.34%,在“其他”类别的分类准确率降低了9.45%,总体分类准确率提高了0.22%。
关键词:信息系统;意图识别;自然语言处理;大语言模型;医疗搜索
中图分类号:TP391.1;R319" 文献标识码:A" 文章编号:2096-4706(2024)24-0044-06
Research on Medical Search Intention Recognition Based on LERT Pre-trained Model
ZENG Jiahui, TIAN Xiaoqiong, LIU Chaoyi
(Hunan Cancer Hospital, Changsha" 410013, China)
Abstract: Correct identification of user intention can help improve the accuracy of medical search and provide convenience for users of medical search systems. In order to improve the accuracy of intention recognition in medical search, this paper uses the KUAKE-Query Intent Criterion dataset in the Chinese Biomedical Language Understanding Evaluation to fine-tune the LERT pre-trained model (Chinese-LERT-base) and the BERT pre-trained model (BERT-base-Chinese), and evaluates the intention classification accuracy of the fine-tuned model. The classification accuracy of the fine-tuned LERT model in the “treatment plan” “disease description” and “etiological analysis” categories is improved by 4.53%, 8%, and 8.34%, respectively, compared with the BERT model after fine-tuning, and the classification accuracy in the “other” category is reduced by 9.45%. The overall classification accuracy is improved by 0.22%.
Keywords: information system; intention recognition; Natural Language Processing; Large Language Model; medical search
0" 引" 言
随着信息系统和人工智能技术的发展,越来越多的就医者在遇到医疗问题时,会先在互联网上检索相关信息以便做出下一步决策,如“头晕挂什么科”“小孩流鼻血怎么处理”等。考虑到医疗搜索服务能为就医者提供指导,不少医院上线了专门的医疗搜索系统供就医者使用。这些系统以人机对话或搜索框的形式,为就医者提供医疗问题的自助查询服务,方便就医者在诊前、诊中、诊后等各个阶段了解医疗相关的就医建议、注意事项等问题。而医疗搜索系统能否为就医者提供精准的医疗信息,其关键之一在于该系统能否准确识别就医者搜索问题的意图,即判断就医者想要了解的具体内容。
近年来,自然语言处理迅速发展,相关技术被广泛应用于机器翻译、文本分类、对话系统、语音识别等领域。人们日常使用的许多产品也使用了自然语言处理技术,例如,手机、智能家居、汽车等产品中嵌入的智能对话系统。在智能对话系统中,准确识别用户的意图有助于提高系统反馈信息的相关性。随着智能对话产品的普及,针对意图识别的研究也越来越多。意图识别又称意图分类,其方法主要有基于规则的方法、基于传统机器学习的方法和基于深度学习的方法[1]。
基于规则的方法需要人为预先定义规则,这些规则通常源自人类语言体系既有的语法或词法,因此规则的定义准确清晰,便于转化为计算机能够执行的代码。但自然语言的表达方式多种多样,相同的含义可以通过不同的方式表达,因此需要定义足够多的规则去覆盖尽可能多的场景。此外,自然语言本身是随时代不断发展的,会不断涌现新的表达方式,这要求不断增加新的规则以适应自然语言本身的发展。然而,规则数量的不断增加会使规则库的维护愈发困难,所以基于规则的方法在复杂的意图识别场景下难以适用。基于传统机器学习的方法需要先从语料中提取出关键特征,然后利用朴素贝叶斯[2-3]、支持向量机[4-5]、逻辑回归[6]等机器学习算法和特征数据训练分类器。在基于传统机器学习的方法中,关键特征的构建和训练数据的质量都会对结果产生重要影响。由于基于传统机器学习的方法很难准确理解用户文本的深层次语义信息[1],因此,不管是基于规则的方法还是基于传统机器学习的方法,都难以满足医疗信息检索的需求。
随着深度学习的发展,CNN[7-10]、RNN[11]、LSTM[12]、GRU[13]等神经网络模型被逐渐应用到意图识别任务中。与传统机器学习的方法相比,基于深度学习的方法使意图识别的性能有了进一步的提升[1]。2017年,Vaswani等人[14]提出了Transformer模型,该模型及其相关的变体在自然语言处理的任务中发挥了巨大的作用。在Transformer的基础上,Google公司提出了基于Transformer结构的BERT模型[15],该模型适用于文本分类、情感分析、意图识别等自然语言理解任务。2022年,哈工大讯飞联合实验室在BERT结构的基础上提出了一种语言学信息增强的预训练模型(Linguistically-motivated bidirectional Encoder Representation from Transformer, LERT),该模型引入了更多的语言学知识,在多个自然语言处理任务中取得了性能的提升[16]。鉴于BERT模型在意图识别方面的优异表现[17-19],本研究将BERT模型和在BERT基础上做了优化的LERT模型应用到医疗搜索问题的意图识别任务中,以评估两种模型在医疗搜索领域的意图识别性能。
1" 数据与方法
1.1" 整体方案
本研究将LERT预训练模型应用于医疗搜索的意图识别任务中,整体方案流程如下:
1)原始数据集中,不同意图类别标签下的搜索问题数量差异较大,为了使训练过程和测试过程覆盖所有意图类别,先将原始数据集中已标注了意图类别标签的搜索问题按照固定比例划分到训练集、验证集和测试集中。
2)将训练集和验证集输入LERT预训练模型中进行微调,选择训练过程中在验证集上分类准确率最高的模型作为微调后的模型。
3)用微调后的LERT模型对测试集中的数据进行分类,计算分类准确率,最后与对照模型进行对比。
1.2" 数据准备
1.2.1" 数据来源
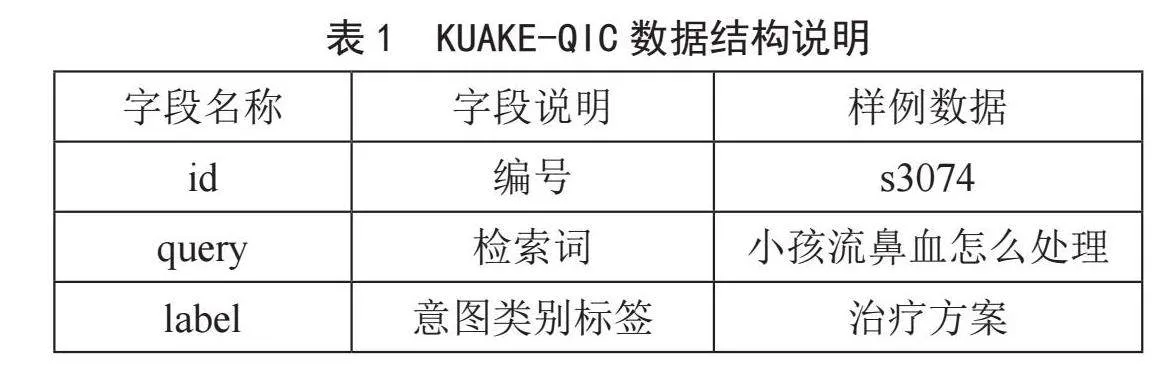
本研究所用的数据来自中文医疗信息处理评测基准(Chinese Biomedical Language Understanding Evaluation, CBLUE)[20]中的医疗搜索检索词意图分类数据集(KUAKE-Query Intent Criterion dataset, KUAKE-QIC)。其中,“检索词”指的是搜索问题的文本,该数据集由阿里夸克提供,并于2023年3月14日发布在阿里云天池平台上。在KUAKE-QIC数据集中,已标注意图类别标签的搜索问题共有8 886个,搜索意图的分类标签共有11种,分别是“治疗方案”“疾病表述”“病因分析”“注意事项”“功效作用”“病情诊断”“就医建议”“医疗费用”“指标解读”“后果表述”和“其他”。原始数据以JSON格式存储在文件中,每条数据包含三个字段,数据结构如表1所示。
1.2.2" 数据预处理
KUAKE-QIC数据集中各意图类别标签下的搜索问题数量如表2所示,可以看到问题数量存在较大差异。标签为“治疗方案”的问题共有2 426个,而标签为“指标解读”的问题仅有169个,样本分布不均会对训练和测试结果造成影响。为了让训练过程和测试过程覆盖所有类别的数据,在数据集划分时,每个类别标签下的搜索问题都按照60%、20%、20%的比例分别划分到训练集、验证集、测试集中,若无法取整,则根据实际情况取上整数或下整数,从而确保各类别的数据能够均匀分布到训练集、验证集和测试集中。
1.3" 预训练模型LERT结构
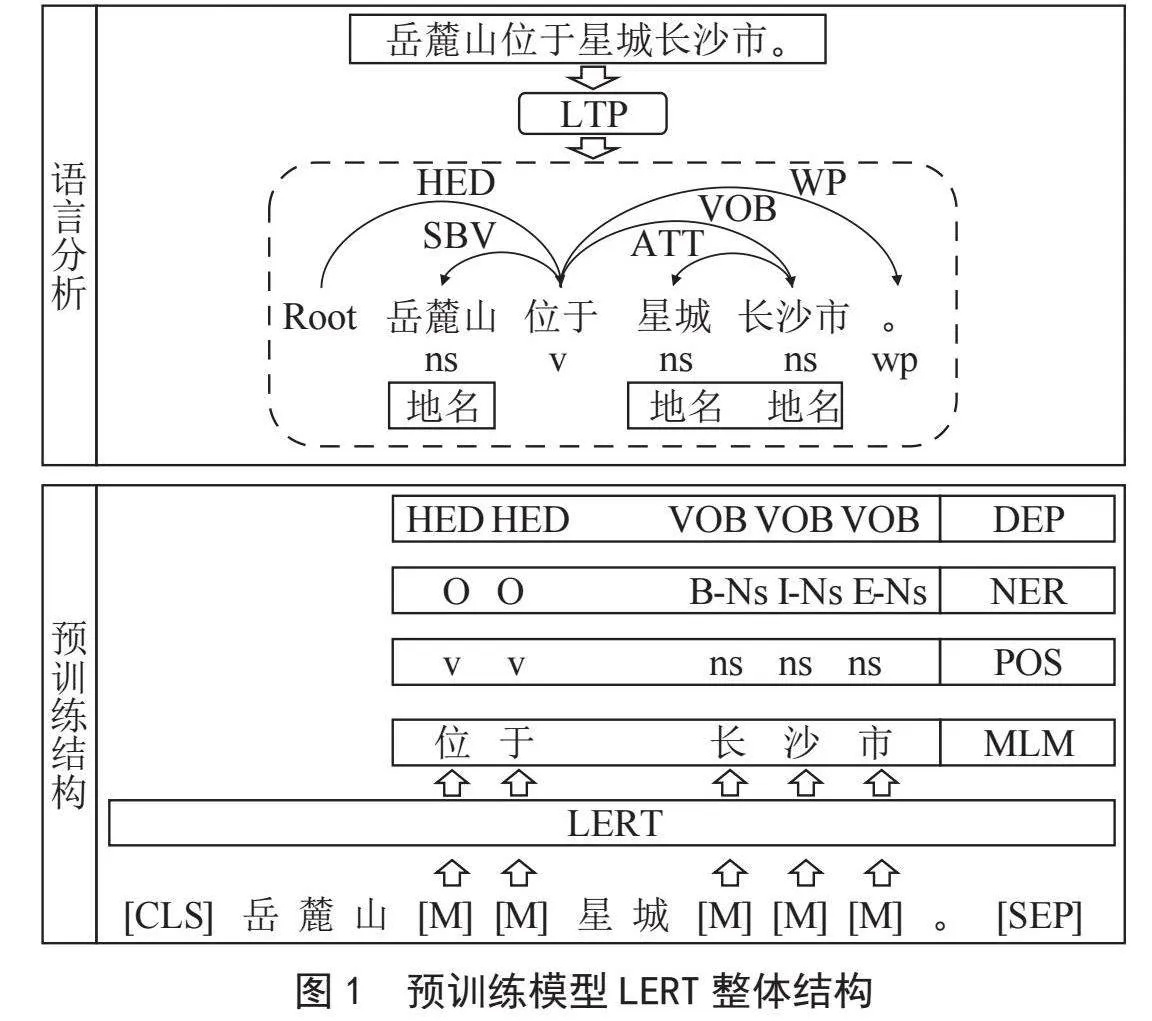
LERT是哈工大讯飞联合实验室提出的一种语言学信息增强的预训练模型。LERT模型除了使用掩码语言模型(Masked Language Model, MLM)进行预训练之外,还采用了词性标注(Part-Of-Speech tagging, POS tagging)、命名实体识别(Named Entity Recognition, NER)、依存句法分析(Dependency Parsing, DEP)三种语言学任务进行训练[16]。图1以文本“岳麓山位于星城长沙市。”为例,展示了预训练模型LERT的整体结构。MLM中每个被遮蔽的token需要预测原始token,而对于POS、NER和DEP任务,预训练模型LERT使用了哈工大社会计算与信息检索研究中心研制的语言技术平台(Language Technology Platform, LTP)[21]对文本进行标注。
词性标注会对每个输入token标注一个词性标签,标注的词性标签包括名词、动词、助词、副词等28种类型。命名实体识别采用“BIEOS”标注方式对输入token标注命名实体识别信息,命名实体识别的标签包括人名、地名、机构名等13种类型。依存句法分析能够分析输入序列中各语言成分之间的依存关系,关系标签包括定中关系、状中结构、动宾关系、主谓关系等14种类型。通过这三类语言学任务的训练,LERT引入了更多的语言学知识[16]。
1.4" 模型微调
LERT预训练模型有3种,本研究使用的LERT预训练模型是Chinese-LERT-base。Chinese-LERT-base的编码器层数是12层,注意力头的数量是12个,隐藏神经元的数量是768个。由于LERT模型的主体部分是BERT结构,本研究选择编码器层数同样为12层的BERT-base-Chinese预训练模型作为对照模型。原始的BERT-base-Chinese预训练模型并未针对中文医疗搜索意图识别任务进行过训练,如果使用原始的BERT-base-Chinese预训练模型进行意图分类,准确率会非常低,从而失去对照的意义。所以在对照模型上也采用相同的训练集和验证集进行微调,然后再在同一个测试集上进行意图分类。通过比较模型分类结果与正确结果间的差异,评估两种模型在中文医疗搜索意图识别任务上的性能表现。
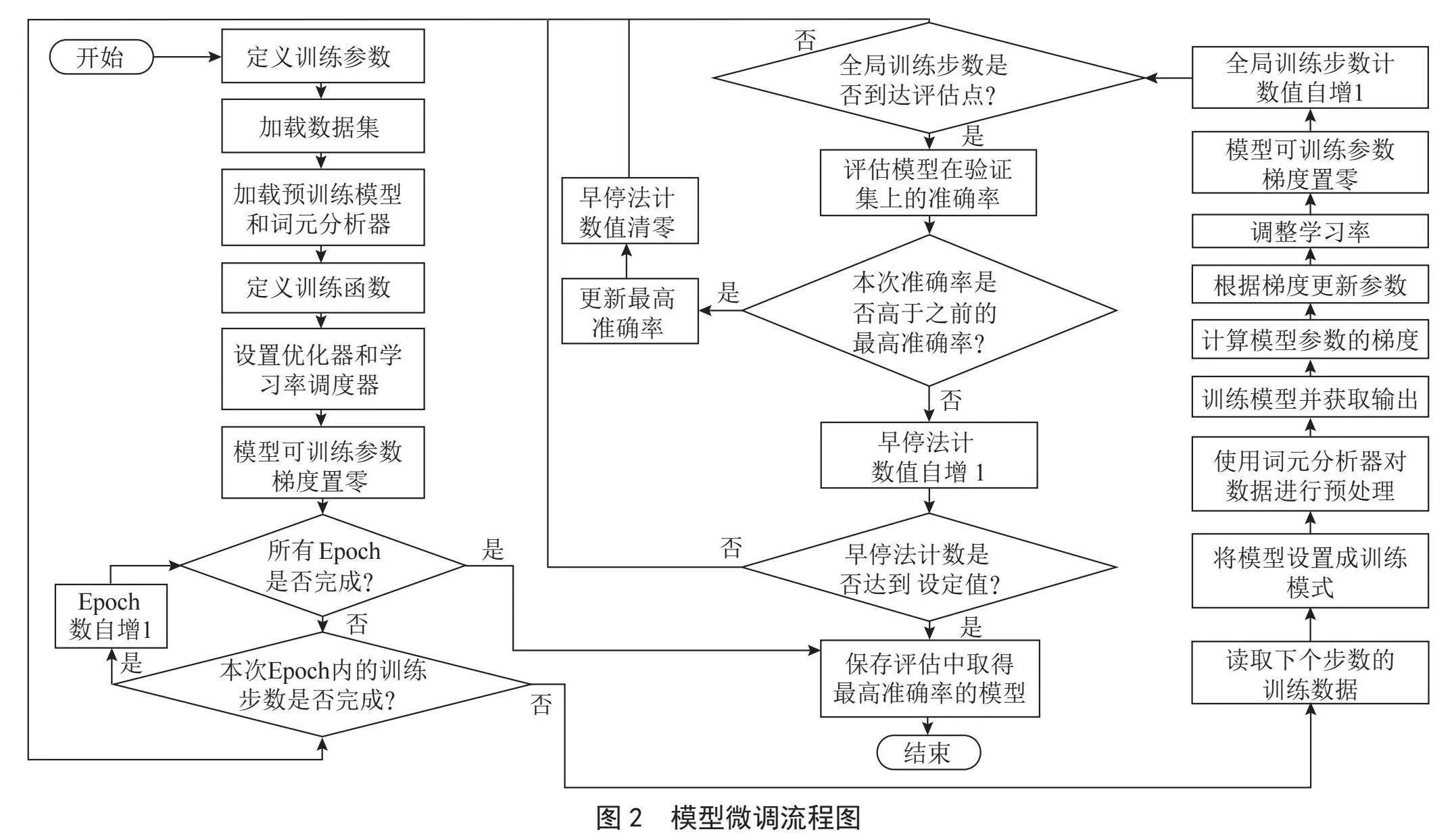
针对预训练模型Chinese-LERT-base和BERT-base-Chinese的微调流程如图2所示。微调过程总共包含3次Epoch,批次大小设置为16。因为训练集中有5 334个搜索问题,根据批次大小,训练集可被分为334个批次。每完成1次Epoch需要训练334步,3次Epoch全部完成则需要训练1 002步。在每一步训练中,先读取本次训练数据,并使用词元分析器对数据进行预处理,获得input_ids、attention_mask、token_type_ids等参数,然后将其和标签等数据一并输入模型进行训练以获取输出。接着计算模型参数的梯度,优化器根据梯度更新模型参数,学习率调度器调整学习率。最后清空模型参数的梯度,更新全局训练步数的计数值,至此当前步数的训练就完成了。当前步数的训练完成之后,会判断是否到达评估点,如果到达了评估点,将在验证集上评估当前微调模型的分类准确率。评估点是根据全局训练步数设定的,评估间隔设置为200步,微调过程会在第200、400、600、800、1 000步时评估微调模型在验证集上的分类准确率,并记录下取得最高准确率的微调模型。微调过程中还采用了早停法,将早停法的步数上限设置为3。当连续3次评估的准确率未高于之前的最高准确率时,便提早结束训练,以降低过拟合的可能性。
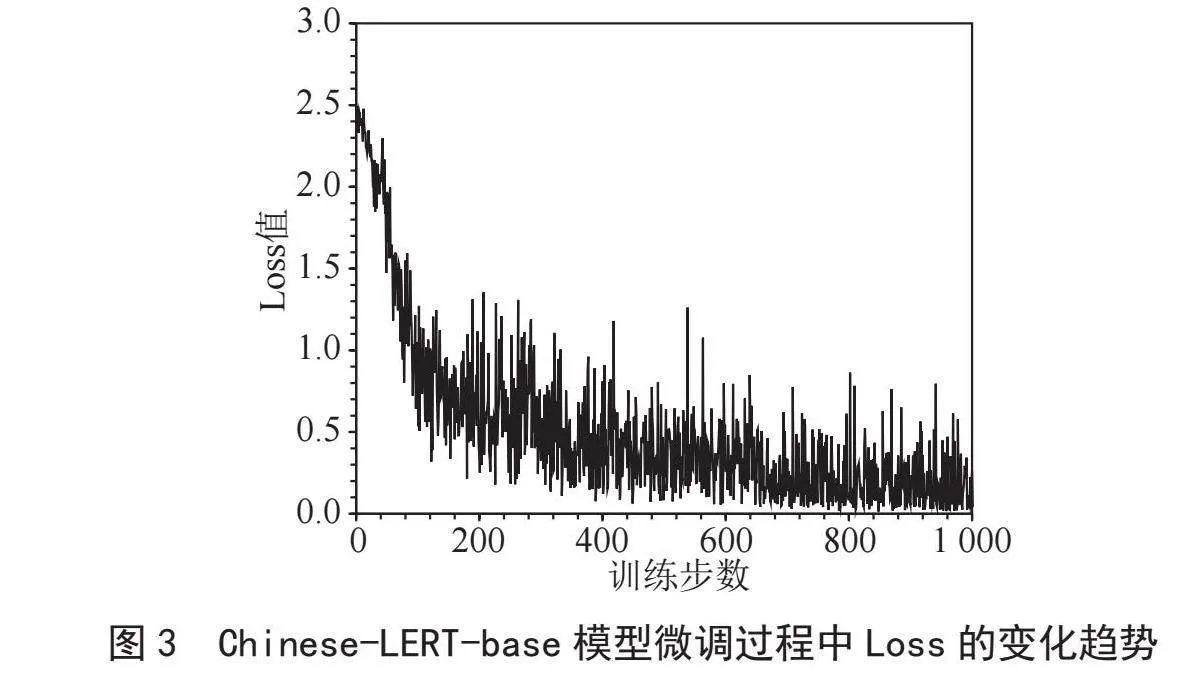
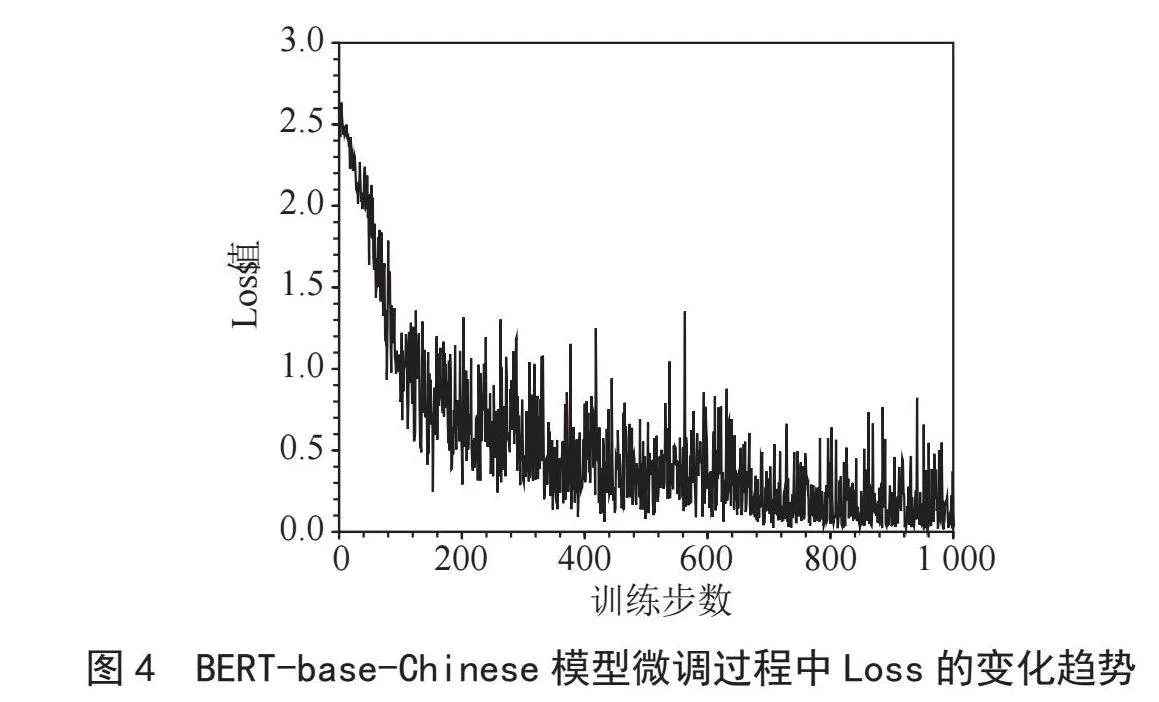
图3和图4分别展示了Chinese-LERT-base和BERT-base-Chinese模型微调过程中Loss值的变化情况。由图可知,两种模型Loss值随训练步数的变化趋势基本一致,均表现为Loss值随训练步数的增长而震荡下降的趋势。具体来说,在训练前期Loss值下降迅速,而在训练后期Loss值下降速度放缓,逐渐在小范围内震荡。
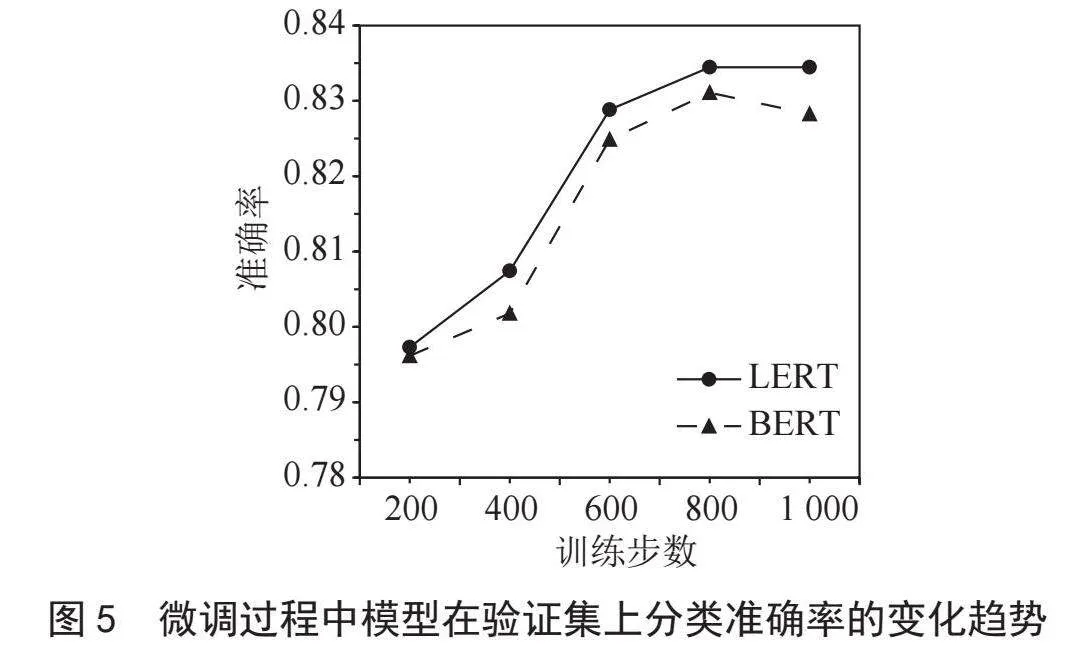
图5展示了Chinese-LERT-base和BERT-base-Chinese模型微调过程中在验证集上的分类准确率变化趋势。从图中可以看到,两种模型在微调前期,准确率均有较大提升,到了后期,LERT的准确率逐渐趋于平稳,而BERT的准确率出现了下降的情况,这可能是过拟合导致的。
2" 实验评价及结果
2.1" 评价标准
本研究参考CBLUE,选用准确率作为评估指标。在本次研究中,共有11种意图类别标签,分别用L1、L2、L3、L4、L5、L6、L7、L8、L9、L10、L11表示,每个类别的分类准确率Pi的计算方法如式(1)所示:
(1)
其中,cii表示被正确分类到Li的条目数,ci表示参与分类的正确意图类别标签为Li的总条目数。所有类别总的准确率等于所有分类正确的条目数除以参与分类的总条目数,计算方法如式(2)所示:
(2)
其中,n表示意图类别数,KUAKE-QIC数据集定义了11种医疗搜索意图类别标签,所以n = 11。
2.2" 结果及分析
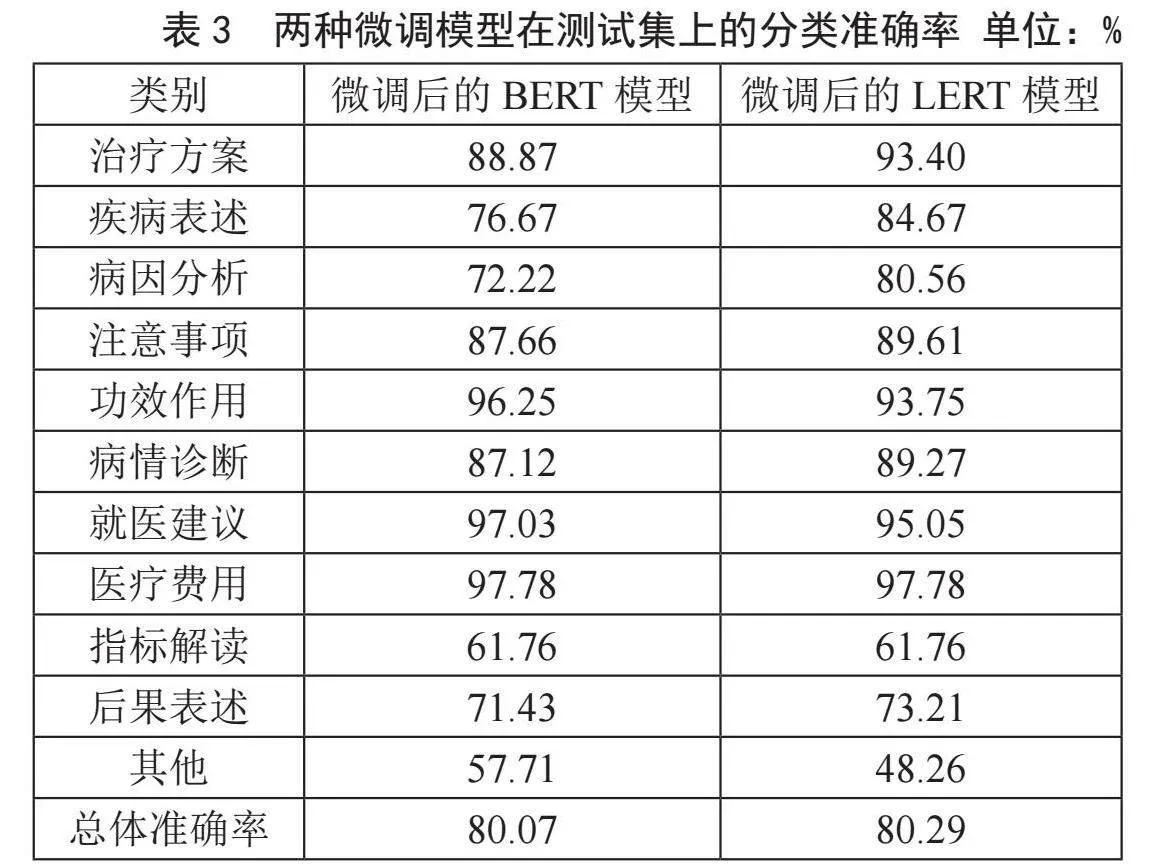
微调后的Chinese-LERT-base模型和BERT-base-Chinese模型在测试集上的分类准确率如表3所示。
由表3可知,微调后的Chinese-LERT-base模型在测试集上的总体准确率高于微调后的BERT-base-Chinese模型。从各个类别的分类准确率可以看出,前者在“治疗方案”“疾病表述”“病因分析”“注意事项”“病情诊断”“后果表述”6个类别中的分类准确率高于后者,在“医疗费用”和“指标解读”2个类别中,两者分类准确率相同,而在“功效作用”“就医建议”“其他”3个类别中,微调后的Chinese-LERT-base模型分类准确率低于微调后的BERT-base-Chinese模型。
在这11个类别中,两种模型分类准确率差距较大的类别有“治疗方案”“疾病表述”“病因分析”和“其他”。其中,微调后的Chinese-LERT-base模型在“治疗方案”“疾病表述”“病因分析”这3个类别的表现优于微调后的BERT-base-Chinese模型,而在“其他”这个类别则相反。微调后的Chinese-LERT-base模型把更多的“其他”类条目错误地分类为别的类别,导致其在“其他”类的分类准确率较微调后的BERT-base-Chinese模型大幅下降。但因其在分类“治疗方案”“疾病表述”“病因分析”等多个类别的条目时取得了更高的准确率,所以总体上,微调后的Chinese-LERT-base模型较微调后的BERT-base-Chinese模型在测试集上有更高的分类准确性。
3" 结" 论
本研究利用KUAKE-QIC数据集分别对Chinese-LERT-base预训练模型和BERT-base-Chinese预训练模型进行微调,随后比较了微调后的两种模型在测试集上的分类表现。具体来说,Chinese-LERT-base模型在测试集上的总体分类准确率略高于BERT-base-Chinese模型,在“治疗方案”“疾病表述”和“病因分析”等类别的分类准确率较BERT-base-Chinese模型有明显提高,在“注意事项”“病情诊断”和“后果表述”等类别的分类准确率上略高于BERT-base-Chinese模型,而在“医疗费用”和“指标解读”类别的分类中,两种模型的准确率基本相同。但在“功效作用”“就医建议”和“其他”类别的分类准确率上,Chinese-LERT-base模型较BERT-base-Chinese模型低。总体上,Chinese-LERT-base模型在KUAKE-QIC数据集上的意图分类准确率高于BERT-base-Chinese模型。在“治疗方案”“疾病表述”和“病因分析”这三类问题较多的医疗搜索场景下,可基于LERT预训练模型开发针对性的意图识别应用,以提高医疗搜索的准确性。
参考文献:
[1] 刘娇,李艳玲,林民.人机对话系统中意图识别方法综述 [J].计算机工程与应用,2019,55(12):1-7+43.
[2] MCCALLUM A,NIGAM K. A Comparison of Event Models for Naive Bayes Text Classification [C]//AAAI Conference on Artificial Intelligence.Santa Barbara:AAAI,1998:1-8.
[3] 邢小东.基于混合属性的用户检索意图识别方法 [J].现代计算机,2022,28(9):69-72+77.
[4] HAFFNER P,TUR G,WRIGHT J H. Optimizing SVMs for Complex Call Classification [C]//2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP03).Hong Kong:IEEE,2003:1-1.
[5] 陈浩辰.基于微博的消费意图挖掘 [D].哈尔滨:哈尔滨工业大学,2014.
[6] GENKIN A,LEWIS D D,MADIQAN D. Large-Scale Bayesian Logistic Regression for Text Categorization [J].Technometrics,2007,49(3):291-304.
[7] LECUN Y,BOTTOU L,Bengio Y,et al. Gradient-Based Learning Applied to Document Recognition [J].Proceedings of the IEEE,1998,86(119):2278-2324.
[8] KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL].arXiv:1408.5882 [cs.CL].[2024-08-10].https://arxiv.org/abs/1408.5882.
[9] HASHEMI H B,ASIAEE A,KRAFT R. Query Intent Detection using Convolutional Neural Networks [C]//WSDM QRUMS 2016 Workshop.[S.I.s.n.],2016:1-5.
[10] 杨春妮,冯朝胜.结合句法特征和卷积神经网络的多意图识别模型 [J].计算机应用,2018,38(7):1839-1845+1852.
[11] ELMAN J L. Finding Structure in Time [J].Cognitive Science,1990,14(2):179-211.
[12] HOCHREITER S,SCHMIDHUBER J. Long Short-term Memory [J].Neural Computation,1997,9(8):1735-1780.
[13] CHO K,MERRIENBOER B V,GULCEHRE Caglar,et al. Learning Phrase Representations
using RNN Encoder-Decoder for Statistical Machine Translation [J/OL].arXiv:1406.1078 [cs.CL].[2024-09-03].https://arxiv.org/abs/1406.1078.
[14] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762 [cs.CL]. [2024-08-26].https://arxiv.org/abs/1706.03762.
[15] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2024-08-26].https://arxiv.org/abs/1810.04805.
[16] CUI Y M,CHE W X,WANG S J,et al. LERT: A Linguistically-motivated Pre-trained Language Model [J/OL].arXiv:2211.05344 [cs.CL].[2024-08-19].https://arxiv.org/abs/2211.05344.
[17] 王堃,林民,李艳玲.端到端对话系统意图语义槽联合识别研究综述 [J].计算机工程与应用,2020,56(14):14-25.
[18] 郑新月,任俊超.基于BERT-FNN的意图识别分类 [J].计算机与现代化,2021(7):71-76+88.
[19] 王志明,郑凯.基于BERT的中文医疗问答系统 [J].计算机系统应用,2023,32(6):115-120.
[20] ZHANG N Y,CHEN M S,BI Z,et al. CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark [J/OL].arXiv:2106.08087 [cs.CL].[2024-09-06].https://arxiv.org/abs/2106.08087.
[21] CHE W X,FENG Y L,QIN L B,et al. N-LTP: An Open-source Neural Language Technology Platform for Chinese [J/OL].arXiv:2009.11616 [cs.CL].[2024-08-20].https://arxiv.org/abs/2009.11616.
作者简介:曾嘉慧(1993—),女,汉族,湖南衡阳人,助理工程师,硕士,研究方向:医院信息化。