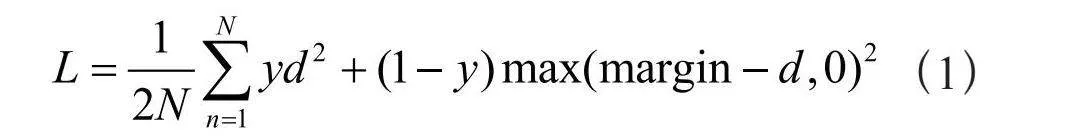



摘" 要:为提高车辆再识别的准确率,提出了一种全局特征与局部特征相结合的方法,解决了车辆再识别时因车牌模糊,车辆轮廓不清晰,遮挡等因素而导致车牌识别精度低的问题。首先,使用孪生网络对待检测的车辆图像进行车尾形状、车头外观、车辆整体形状匹配,然后,使用基于YOLOv3的车牌识别网络,进行车辆局部形状、整体形状和车牌识别结合进行车辆再识别。结果表明,提出的方法在道路环境多变的情况下能很好地实现车辆再识别,再识别的综合准确率达到了93.63%,比DRDL、OIFE、RAM算法的再识别模型的准确率分别高7.28%、3.08%、0.75%。
关键词:人工智能;深度学习;车辆再识别
中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2024)24-0040-04
Research on Vehicle Re-recognition Algorithm of Image Feature Fusion Based on YOLOv3
LIU Yanyang1, YAN Hao2
(1.Zhangjiakou University, Zhangjiakou" 075000, China;
2.Artificial Intelligent Interconnection Technology Co., Ltd., Zhangjiakou" 075000, China)
Abstract: In order to improve the accuracy of vehicle re-recognition, a method combining global and local features is proposed, which solves the problem of low license plate recognition accuracy caused by factors such as blurred license plates, unclear vehicle contours, and occlusion during vehicle re-recognition. Firstly, this paper uses Siamese Network to match the rear shape, front appearance, and overall vehicle shape of the vehicle images to be detected. Then, it uses the LPRNet based on YOLOv3 to combine the vehicle local shape, overall shape, and license plate recognition for vehicle re-recognition. The results show that the proposed method can achieve vehicle re-recognition under the changeable road environment, and the comprehensive accuracy of re-recognition reaches 93.63%, which is 7.28%, 3.08% and 0.75% higher than the re-recognition model of DRDL, OIFE and RAM, respectively.
Keywords: Artificial Intelligence; Deep Learning; vehicle re-recognition
0" 引" 言
车辆作为城市监控中的重要对象,涉及检测、跟踪与识别等任务。车辆再识别技术即实现跨镜头下车辆的自动跟踪与识别,在智慧城市与智慧交通规划、管理以及调度上,发挥着重要的作用。
图像融合是将在同一场景下拍摄的多帧图像进行冗余互补,信息整合后形成的一帧具有完整信息的图像。早期的车辆再识别算法主要基于车牌识别算法实现的,并得到广泛的应用,但在实际道路交通场景中,车牌经常受到不同程度的遮挡和伪造。因此,结合车牌特征以及车辆外观特征开展再识别研究是非常必要的。
Bai[1]等人为提高车辆再识别的准确性,提出了一种新的三元组损失函数,该函数同时利用了车辆再识别过程中的类内误差和类间误差,但是该方法只利用了车辆的外观特征,在复杂环境下的识别准确率仍不高。Zhou[2]等人为解决复杂场景下的车辆再识别,提出了一种双向长短时间网络(Long Short-Term Memory, LSTM),实现了在各种复杂场景下的车辆再识别。李熙莹[3]等人针对同一车型不同车辆的车辆再识别问题,采用局部代替整体的办法,提取并融合被检测车辆窗口和车辆人脸区域的车辆特征,该算法的Rank1匹配率达到66.67%,验证了算法的可行性和有效性。De[4]等人提出一种双层级联的车辆再识别网络,将输入图像压缩成两个不同尺寸的图像,通过两个级联的孪生网络分别检测不同尺寸的车辆图像外观特征[5],提升了车辆再识别的准确率。
上述算法大都仅考虑了单方面因素,车辆再识别的准确率存在一定的局限性。基于图像特征融合的车辆再识别方法能够提取到车辆的局部特征和全局特征,在特征提取上具有很大的优势。综上所述,本文提出了一种全局特征与局部特征相结合的方法,该算法在实际道路环境下能很好地实现车辆再识别。
1" 车辆再识别网络
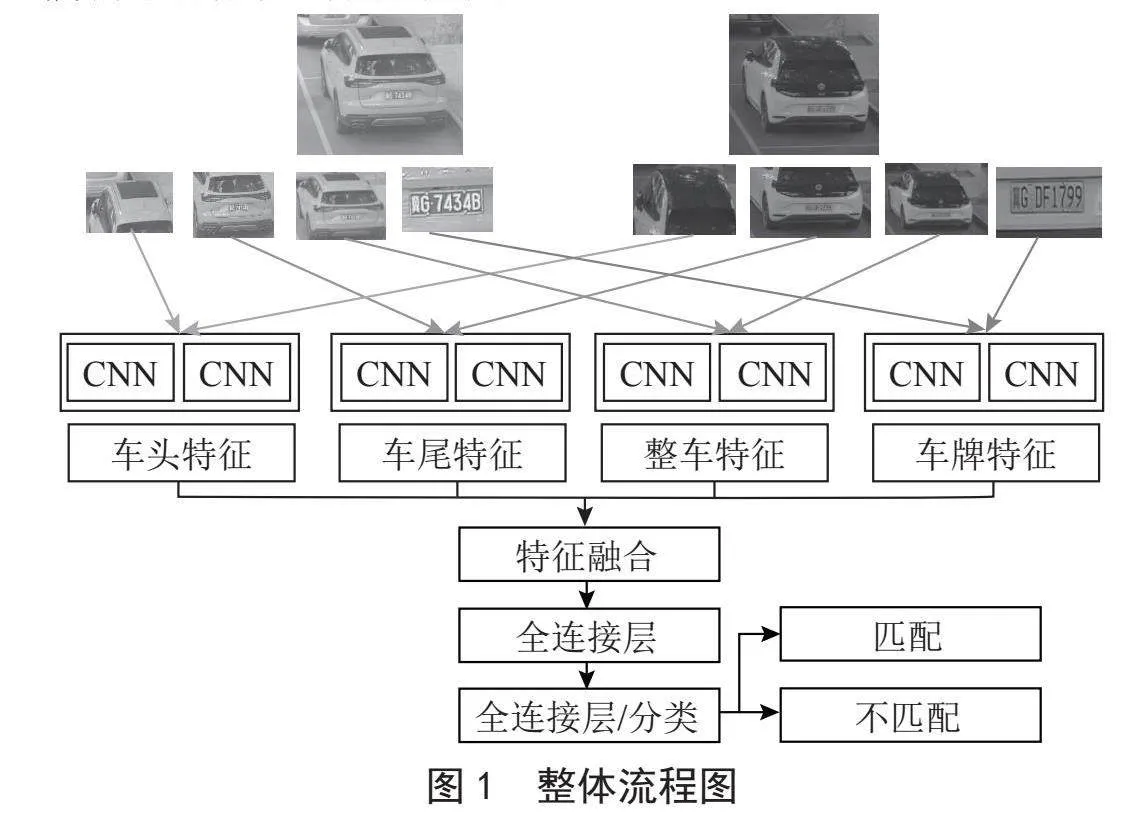
本研究将车辆外观区域和车牌字符区域作为两个独立的局部特征,选择两种网络模型对两块区域分别进行处理。采用孪生神经网络来判别车辆外观的形状相似性,该网络通过共享权重将同时输入的两幅图像进行对比,获取车辆外观相似度。采用YOLOv3网络作为车牌字符的识别网络,识别同时输入的两张车辆图像中的车牌号码信息,车牌识别的准确度由车牌号码的字符相似度判别。采用一个全连接层来组合形状识别的相似度和车牌号码识别的相似度。图1为车辆再识别的整体流程图。
由图1可以看出,本文设计了一个多分支检测模块,检测模块包含车辆全局外观检测模块、车头外观检测模块、车尾外观检测模块、车牌字符检测模块,对这些特征进行联合学习。通过对不同摄像头拍摄的车辆图片进行匹配,本研究提出的再识别方法,一方面提高了再识别模型的精度,另一方面也提高了再识别算法的可解释性,简单易实现。
1.1" 孪生网络
Siamese孪生网络在2005年由Chopra[6-7]进行了改进,自此以后,原始的孪生网络分为两部分,分别用于特征提取和距离度量,将两帧图像输入网络,得到两个特征向量,即可计算输入图像的相似度以判别两张图片的相似性[8]。
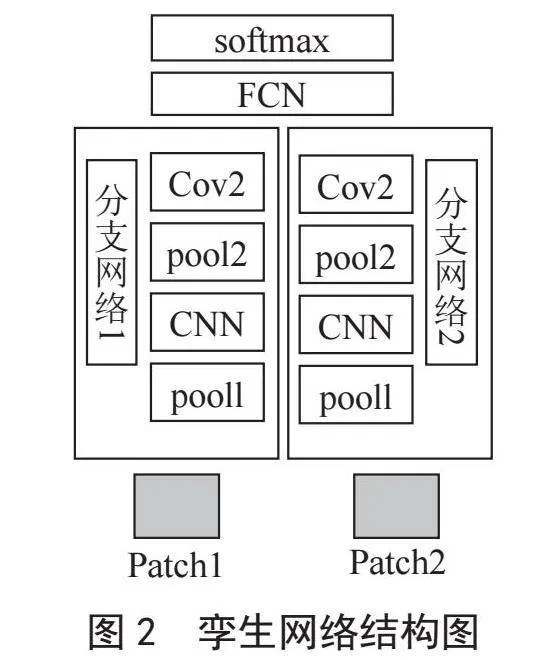
本文所采用孪生网络,左右两边的两个部分在结构上是完全一致的,共享相同的权重和偏置。该孪生网络是由两个卷积层,两个池化层,一个残差块以及一个全连接层组成。卷积层和池化层的通道数都是16,其卷积核大小为3×3,池化窗口的大小为2×2,卷积方式为零填充,激活函数采用ReLU。该孪生网络所采用的损失函数为对比损失函数,对比损失函数为式(1):
(1)
其中,d为两个样本特征之间的欧氏距离,y为两个样本相似或相匹配,margin为设定的阈值。图2为孪生网络结构图。
1.2" YOLOv3网络
YOLOv3[9]是一个端到端的深度神经网络系统,其损失函数主要包括边界框坐标回归损失、分类损失和置信度损失。
假设由YOLOv3预测所得的车牌字符目标框位置信息为(X1,Y1,W1,H1),而真实的车牌字符位置信息为(X2,Y2,W2,H2),那么车牌字符位置回归损失为式(2):
(2)
用于判断决策图网格内是否存在车牌字符目标,采用的置信度损失为式(3):
(3)
分别表示车牌字符预测的置信度和真实置信度。分类损失可以表示为典型的交叉熵形式损失函数为式(4):
(4)
式中,表示第i个网格点归属于车牌字符类的预测概率和真实概率,其中真实概率通过网格点与车牌字符实际位置的重叠率计算得到的。总体损失函数为:
(5)
式中,表示正数的权值参数,并通过误差反向传递的方式进行网络参数的更新。
YOLOv3网络模型对于图片中的目标检测和识别更加快速和准确。检测过程如下:
1)首先要对输入的车辆图像进行处理,图像尺寸全部转换为480×480,即32的整数倍。
2)采用Darknet-53网络提取特征后,提取出3个不同尺度的特征图,特征图的尺寸分别为15,30,60。
3)将提取出的特征图缩小到原输入图像的1/32,并对车牌字符做出预测。
4)YOLOv3网络产生多种尺度的特征图,即得到不同尺度的预测锚点。
对于最终车牌字符的检测和分类,YOLOv3网络基于二值交叉熵以及逻辑回归的方法,实现车牌字符的识别。
2" 试验结果分析
2.1" 数据集
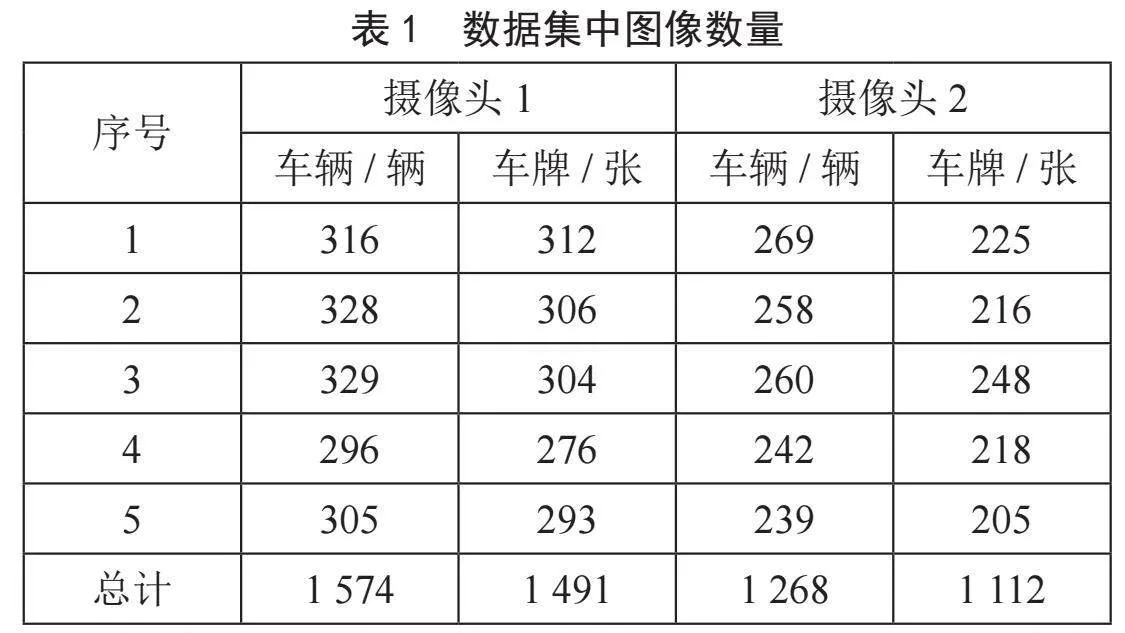
为了验证本文所提出的车辆再识别网络的有效性,在实际应用场景下分别采集白天和夜晚车辆数据构建数据集。该数据集包括两个摄像头拍摄的不同车辆的图像:不同摄像头拍摄的同一ID的车辆图像、同一摄像头拍摄的不同ID的车辆图像。使用了来自2个不同摄像机拍摄的10个视频,每个视频长度约20分钟,分辨率为1 920×1 080,每秒30帧。表1显示了不同摄像头拍摄的车辆图片数量和车牌数量统计。
摄像机1和摄像机2拍摄到了不同时间段的车辆图像,创建图像对,这些获取的图像大都来自拍摄到的车辆视频的连续帧,因为连续帧序列中的车辆图像的外观通常具有较小的变化,采集的连续帧图片可避免车辆运动造成的模糊、视野亮度、背景影响等。
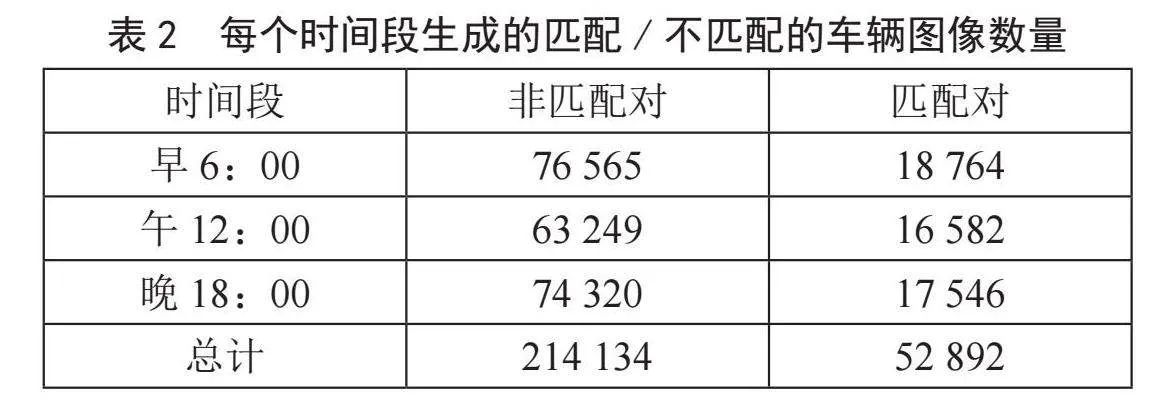
在两个摄像头生成了3组时间段内拍摄的的车辆ID匹配/不匹配对,如表2所示,出现ID相同地同一辆车的配对数为52 892,剩余的拍摄到的214 134辆车,均无法配对。
2.2" 数据特征
数据集包含的车辆图中,包含车头外观、车尾外观、车辆整体外观、车牌区域外观和车牌字符等不同的识别标志特征。在车头、车尾区域中,不同车辆可能会存在不同的装饰物,车辆年检标志等,这些显著的特征可用于区分不同车辆,有效地减小车辆再识别过程中类间误差和类内误差。同时车牌是车辆地唯一地身份标志,将其融入车辆再识别网络中,可有效提升再识别模型地准确性。表3对车辆外观和车牌区域进行了特征描述。
2.3" 评价指标
通常用准确率(precision),和召回率(recall)来评价车辆再识别模型的性能效果,准确率(P)和召回率(R)函数如式(5):
(5)
其中TP表示摄像头1和摄像头2之间的车辆ID真实匹配数,TP是错误匹配的数量,TP是漏匹配数。为更准确的评估再识别网络的性能,采用准确度和召回率的调和平均值F,如式(6)所示:
(6)
2.4" 车辆再识别效果
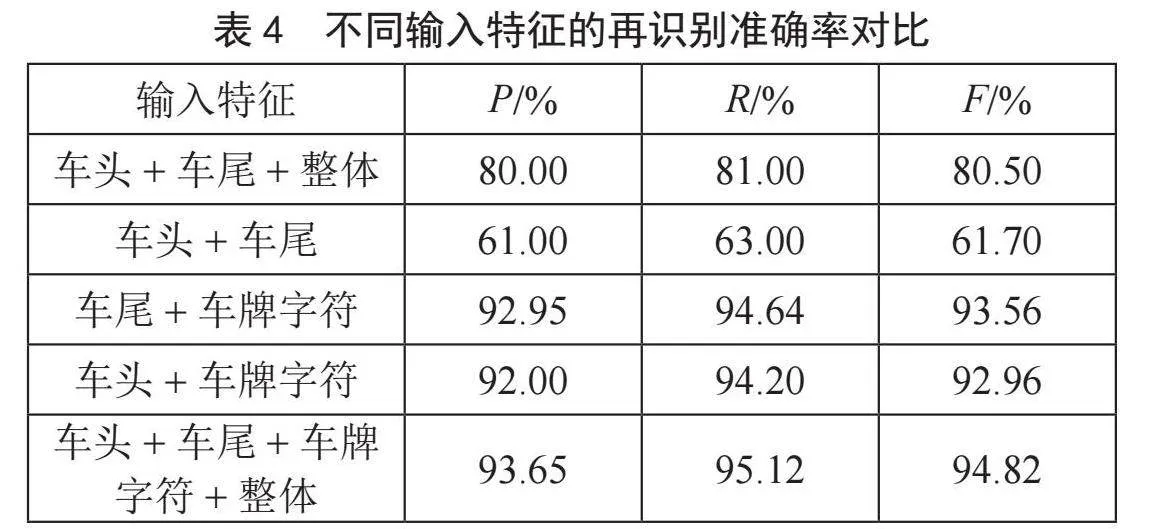
为了验证所提出的车牌识别网络的有效性,用于形状特征匹配的孪生网络,其特征提取网络采用了VGG16网络,并基于不同车辆特征进行了大量的对比实验,如表4所示。可以看出,在原来仅有形状外观的基础上添加车牌区域内容,增加了输入参数的多样性,相较于其他仅形状特征输入的神经网络模型,识别准确率上均有所提升。
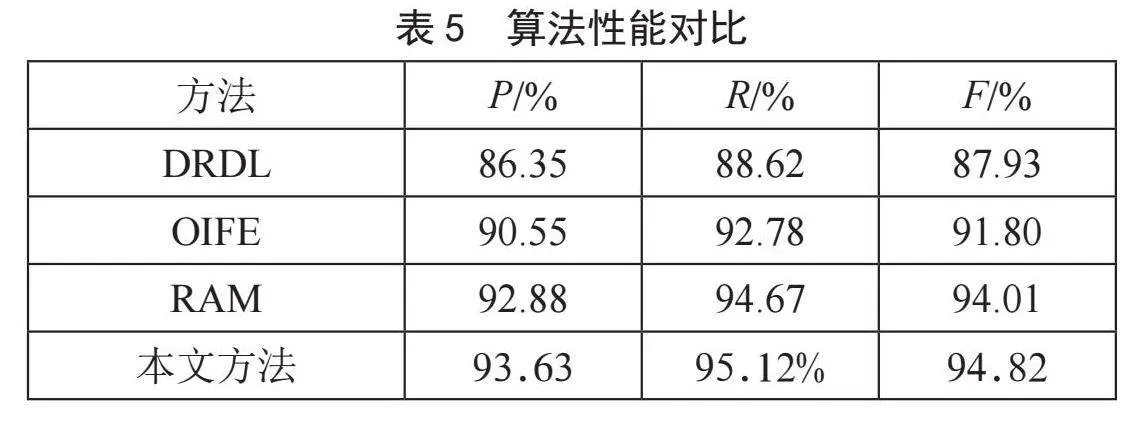
2.5" 算法性能对比
为验证本文提出方法的有效性,评测车辆再识别模型的性能,在输入特征参数完全相同,将本方法分别与DRDL[10]、OIFE[11]、RAM的车辆再识别方法相对比,从表5中可以看出,而本文提出的方法车辆再识别的准确率优于其他两种方法,再识别的综合准确率达到了93.63%,比DRDL、OIFE、RAM这三个经典的再识别模型的准确率分别高7.28%、3.08%、0.75%。
3" 结" 论
本文针对车辆再识别中因图片质量不高存在的车牌模糊,车辆轮廓不清晰,或因行人、机动车以及绿植遮挡等遮挡导致车牌识别精度低的问题,提出了一种全局特征与局部特征相结合的方法。本文提出的方法在道路环境多变的情况下能很好地实现车辆再识别,再识别的综合准确率达到了93.63%,比DRDL、OIFE、RAM这三个经典的再识别模型的准确率分别高7.28%、3.08%、0.75%。
目前大多数车辆再识别方法都是基于深度学习算法利用单帧图像进行测试和研究的,由于单帧车辆图像容易出现不同程度的遮挡或模糊,影响车辆再识别的准确性和鲁棒性。因此,在实际交通场景中,基于视频序列进行车辆再识别算法的研究将是未来研究的热点之一。
参考文献:
[1] BAI Y,LOU Y H,GAO F,et al. Group-Sensitive Triplet Embedding for Vehicle Reidentification [J]//IEEE Transactions on Multimedia,2018,20(9):2385-2399.
[2] ZHOU Y,SHAO L. Vehicle Re-Identification by Adversarial Bi-Directional LSTM Network [C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV).Lake Tahoe:IEEE,2018:653-662.
[3] 李熙莹,周智豪,邱铭凯.基于部件融合特征的车辆重识别算法 [J].计算机工程,2019,45(6):12-20.
[4] DE OLIVEIRA I O,FONSECA K V O,MINETTO R. A Two-Stream Siamese Neural Network for Vehicle Re-Identification by Using Non-Overlapping Cameras [C]//2019 IEEE International Conference on Image Processing (ICIP).Taipei:IEEE,2019:669-673.
[5] 李熙莹,周智豪,邱铭凯.基于部件融合特征的车辆重识别算法 [J].计算机工程,2019,45(6):12-20.
[6] 刘艳洋,张沛纲.基于深度学习的车道线与绿植分割算法 [J].电子技术与软件工程,2020(6):132-135.
[7] CHOPRA S,HADSELL R,LECUN Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification [C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Diego:IEEE,2005:539-546.
[8] 杨雪,郑婷婷,戴阳.基于孪生卷积神经网络的图像融合 [J].计算机系统应用,2020,29(5):196-201.
[9] REDMON J,FARHADI A. Yolov3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-08).https://doi.org/10.48550/arXiv.1804.02767.
[10] LIU H,TIAN Y,YANG Y,et al. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles [C]//IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:2167-2175.
[11] WANG Z,TANG L,LIU X,et al. Orientation Invariant Feature Embedding and Spatial Temporal Regularization for Vehicle Re-identification [C]//IEEE International Conference on Computer Vision.Venice:IEEE,2017:379-387.
作者简介:刘艳洋(1989—),女,汉族,吉林长春人,教师,硕士,研究方向:人工智能、大数据处理;闫昊(1997—),男,汉族,河北石家庄人,算法工程师,本科,研究方向:人工智能、大数据处理、多模态感知。