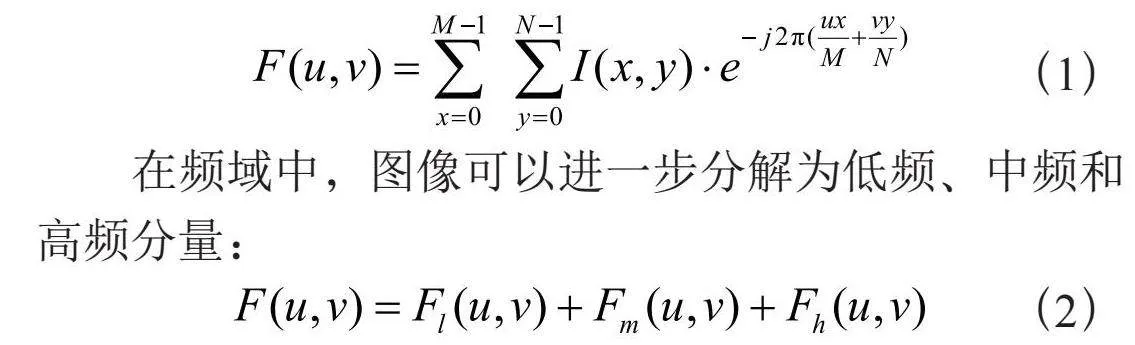




摘" 要:针对现有的图像融合方法在特征提取和融合策略上的不足,提出了一种基于频域分解的近红外与可见光图像自适应融合模型STAFuse。通过引入Transformer与CNN的特征提取模块,以及自适应融合模块,实现不同模态图像特征的有效融合。在多模态图像的获取上,为解决传统多传感器系统体积大、校准复杂等问题,设计了一种新型多模态传感器,可同时获取高分辨率的可见光图像和低分辨率的近红外图像。实验结果表明,STAFuse在多个指标上优于现有模型,在结构相似性上比DenseFuse模型提升了102.7%,在视觉信息保真度上比DIDFuse模型提升了25%,在保持视觉质量和图像细节方面表现突出。
关键词:近红外与可见光融合;自适应融合;Transformer;CNN;多模态传感器;频域分解
中图分类号:TP212;TP183" 文献标识码:A" 文章编号:2096-4706(2024)24-0163-08
Adaptive Fusion Model for Near-infrared and Visible Light Images Based on Multimodal Sensors
LI Zhenwei1,3,4,5, SHI Wenzao1,3,4,5, FU Qiang2, YUAN Junru1,3,4,5
(1.College of Photonic and Electronic Engineering, Fujian Normal University, Fuzhou" 350117, China; 2.Tucsen Photonics Co., Ltd., Fuzhou" 350003, China; 3.Fujian Provincial Engineering Technology Research Center of Photoelectric Sensing Application, Fujian Normal University, Fuzhou" 350117, China; 4.Key Laboratory of Optoelectronic Science and Technology for Medicine (Ministry of Education), Fujian Normal University, Fuzhou" 350117, China; 5.Fujian Provincial Key Laboratory for Photonics Technology, Fujian Normal University, Fuzhou" 350117, China)
Abstract: Aiming at the shortcomings of feature extraction and fusion strategies in the existing image fusion methods, this paper proposes an adaptive fusion model for near-infrared and visible light images, called STAFuse, based on frequency domain decomposition. It realizes the effective fusion of different modal image features, by introducing feature extraction modules of Transformer and CNN and the adaptive fusion modules. To address the issues of large size and complex calibration in traditional multi-sensor systems on the acquisition of the multimodal images , a novel multimodal sensor is designed, capable of simultaneously capturing high-resolution visible light images and low-resolution near-infrared images. Experimental results demonstrate that STAFuse outperforms existing models in multiple metrics, which improves by 102.7% compared with DenseFuse model in Structural Similarity (SSIM), improves by 25% compared with DIDFuse model in Visual Information Fidelity (VIF), and is outstanding in maintaining visual quality and image details.
Keywords: near-infrared and visible light fusion; adaptive fusion; Transformer; CNN; multimodal sensor; frequency domain decomposition
0" 引" 言
图像融合在各个领域都有着广泛的应用[1-3]。由于硬件设备的限制,单一传感器成像常面临信息不完全的问题,影响图像质量和应用[4]。可见光传感器虽然分辨率较高,但容易受到光照和天气的影响;近红外传感器则能在恶劣光照下工作,但其空间分辨率较低,纹理和细节信息匮乏。图像融合技术通过结合两者优势,生成的融合图像不仅具备了更加全面的场景信息,还提高了视觉感知的准确性。
为了解决图像融合的问题,这些年来学者们已经提出了许多方法。这些方法大致可以分为传统方法[5-6]和深度学习方法[7-11]。尽管现有方法已经取得了不错的效果,但仍存在特征提取效率低、融合策略复杂等问题。此外,多模态图像通常来自捕获不同波段信息的双传感器,但在体积和成本受限的应用场景(如微型无人机)中,双传感器配置会增加系统复杂性和维护成本。针对目前方法存在的缺点,我们提出了一个基于频域分解的近红外与可见光图像自适应融合模型STAFuse。我们的方法的主要功能如下:
1)针对现有方法在图像特征提取方面的局限性,引入了一种结合Transformer与CNN的模块,用于增强图像的全局特征提取能力。
2)针对现有方法在融合策略上的不足,我们引入了Pag(Pixel-attention-guided fusion module)模块[12]。Pag模块通过自适应地调整不同特征图之间的权重分配,能够根据特征图的语义信息有效融合,从而避免了传统方法中人工设计策略的复杂性。
3)针对多传感器系统在体积、重量和维护成本上的问题,在获取多模态源图像的途径上,提出了一种多模态传感器的改进方案。该传感器可以在同一块芯片上同时获取高分辨率的可见光图像和低分辨率的近红外图像。这种多模态传感器的设计不仅降低了系统的体积和重量,还减少了对多传感器校准的需求,从而降低了维护成本。
1" 相关工作
1.1" 基于频域分解的图像融合原理
频域分解是图像处理中的一种重要方法,通过将图像从空间域转换到频域,能够有效地分离图像中的不同特征。在频域中,图像被分解为低频、中频和高频分量,分别代表图像中的不同信息:低频分量通常包含全局结构和亮度信息,中频分量包含边缘和纹理等细节信息,而高频分量则主要是噪声及微小的细节[13]。对于一幅图像I(x,y),通过二维傅里叶变换可以得到其频域F(u,v):
(1)
在频域中,图像可以进一步分解为低频、中频和高频分量:
(2)
其中Fl(u,v)表示低频部分,Fm(u,v)表示中频部分,Fh(u,v)表示高频部分。通过对图像有雾图像和无雾图像的观察发现:在一小块无雾图像中,RGB图像和近红外图像的高频分量相似;相比之下,在模糊图像的一小块区域中,它们彼此不同[14]。基于这一点,我们将图像的分解为相似的低中频部分和不相似的高频部分,再通过自适应的融合策略进行融合。
1.2" 多模态传感器的设计
在源图像的获取上,本文采用了多模态传感器的设计,在一个传感器上同时得到了可见光和近红外光的信息,再通过后续的处理得到可见光和近红外光图像对。
为了模拟这种多模态传感器得到的图像,我们设计了一个软件模拟流程,在MATLAB上完成了模拟,该流程的核心步骤如下:
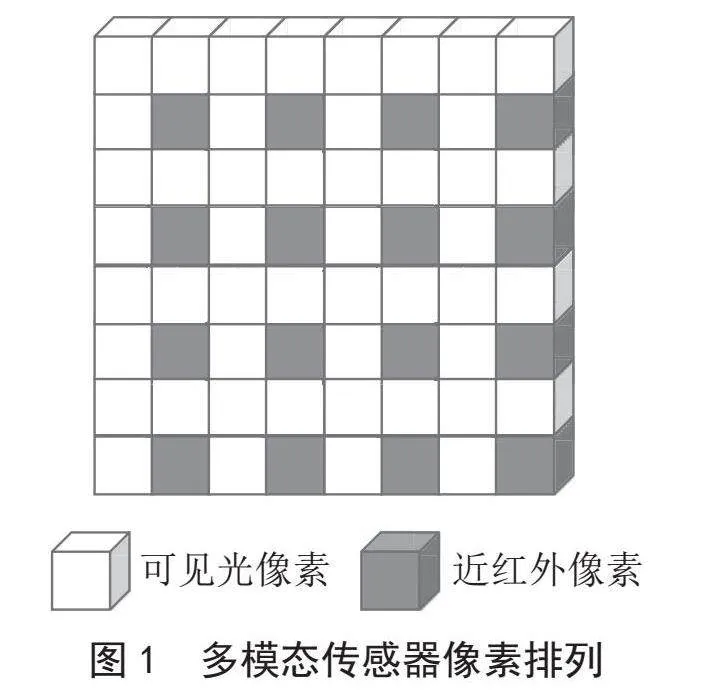
1)多模态传感器像素排列定义。本文设计的多模态传感器的像素排列方式为以四个像素为一组,右下角像素为近红外像素,其他三个像素为可见光像素,如图1所示。
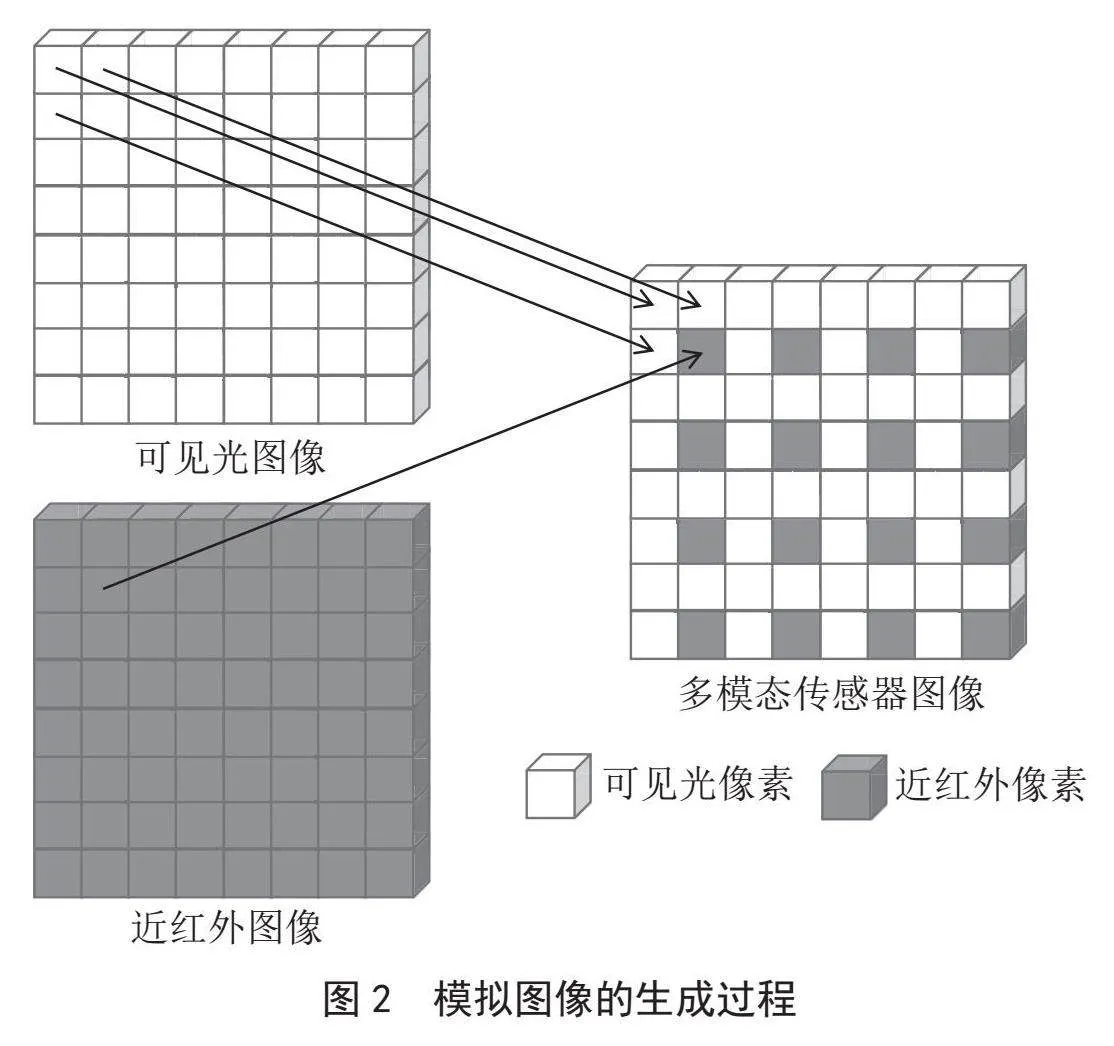
2)获得多模态传感器的模拟图像。为了模拟得到图1所示的多模态传感器的图像,选取RGB-NIR Scene Dataset[15]下的若干对近红外和可见光图像对,通过循环遍历可见光和近红外图像,将可见光图像和近红外图像的像素按多模态传感器的像素排列方式重新组合。以多模态传感器的一组四个像素为例,右下角的像素来自近红外图像,其余三个像素来自可见光图像,模拟图像的成长过程如图2所示,模拟图像的生成结果如图3所示。
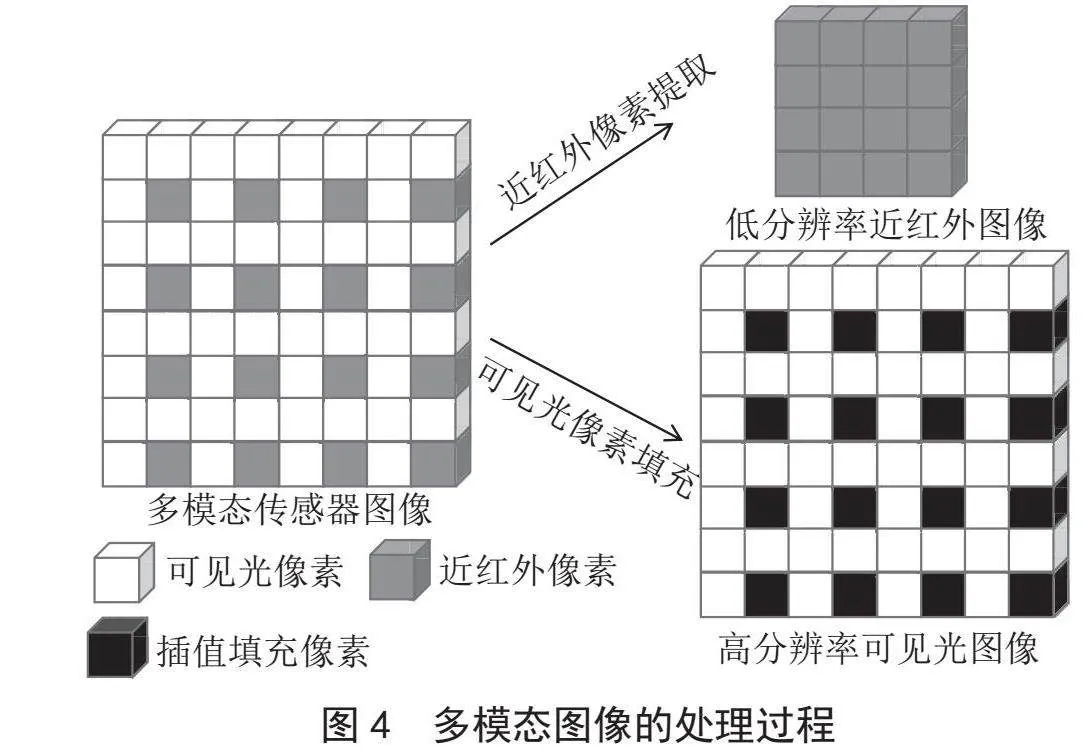
3)对多模态传感器图像的处理。为了适应图像融合模型的输入,对模拟生成的多模态传感器图像进行处理。将可见光像素和近红外像素分离。近红外像素直接提取出来,组成一个低分辨率的近红外图像。在多模态传感器的像素排列中,已经提取了近红外像素组成了低分辨的近红外图像,因此剩下的像素排列中,原本近红外像素的位置为空,采取插值法进行了填充,得到了一个高分辨的可见光图像。最终得到了一个低分辨率的近红外图像和高分辨率的可见光图像,对多模态传感器图像的处理过程如图4所示,处理得到的图像如图5所示。
1.3" 特征提取模块
近年来,Vision Transformer在图像处理领域中取得了显著的成功,尤其是在分类[16]、目标检测[17]和分割[18]等任务中表现出色。然而其对局部信息的捕捉能力相对较弱,且由于其对空间自注意力机制的依赖,计算开销较大。
为了克服传统方法在图像特征提取方面的局限性,受到ConvFormer模块[19]的启发,本文提出了MultiScaleTransformer模块,该模块结合了Transformer与CNN的优势,在标准Transformer架构中引入了多尺度特征提取机制,使得模型能够在不同尺度上提取特征,增强了对图像局部和全局信息的捕捉能力,尤其适合处理高分辨率图像。相比传统的CNN和Vision Transformer,MultiScaleTransformer在结构上更好地平衡了计算效率与特征提取能力,不仅能捕捉图像中的全局依赖关系,还能有效保留空间细节信息。
在高频特征提取模块上,本文提出了DEN模块,该模块在INN模块[20]的基础上引入了动态特征处理节点和批归一化层,增强了特征提取的灵活性和稳定性,提高了对不同输入数据的适应能力和细节特征的捕捉精度。
1.4" Pag模块
在多模态图像处理任务中,传统的融合策略如简单的加法或加权平均,往往未能充分挖掘不同模态特征之间的互补性,导致融合效果不佳。针对这一问题,本文引入了Pag模块。
Pag模块的核心思想是利用特征图之间的语义信息,动态调整每个特征图的权重,以提高融合结果的准确性。与传统的固定融合策略不同,Pag模块通过计算特征图的相似度,自适应地调整每个特征图的权重,使得模型能够根据输入数据动态优化融合方式,避免了固定策略的局限性。此外,Pag模块还可以选择性地引入通道注意力机制,进一步提升特征融合的精度,充分挖掘不同模态特征的互补性。更重要的是,Pag模块能够与模型的其他部分一起参与训练,使得融合策略在训练过程中自动优化,简化了手动调整参数的复杂性,并显著提升了多模态图像融合任务的表现。
2" 近红外与可见光图像自适应融合模型
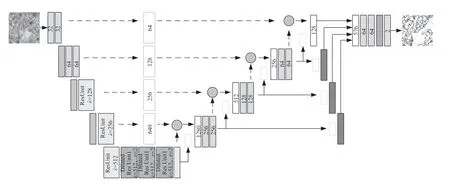
本节详细介绍了所提出的近红外与可见光图像自适应融合模型STAFuse的细节,包括编码器的中低频特征和高频特征提取模块、自适应融合模块、损失函数。这里为了表示方便,将中低频特征和高频特征分别用结构特征和纹理特征来表示。首先分别将可见光图像和近红外图像输入编码器得到结构特征和纹理特征,通过自适应融合模块得到融合特征,再将融合特征输入到解码其中得到输出,其中将特征提取模块中的多尺度特征与注意力融合后的特征在特征重建模块中进行连接,来补偿卷积操作后的信息丢失,从而保留更多的图像细节信息,提高图像融合的质量。
2.1" STAFuse模型结构
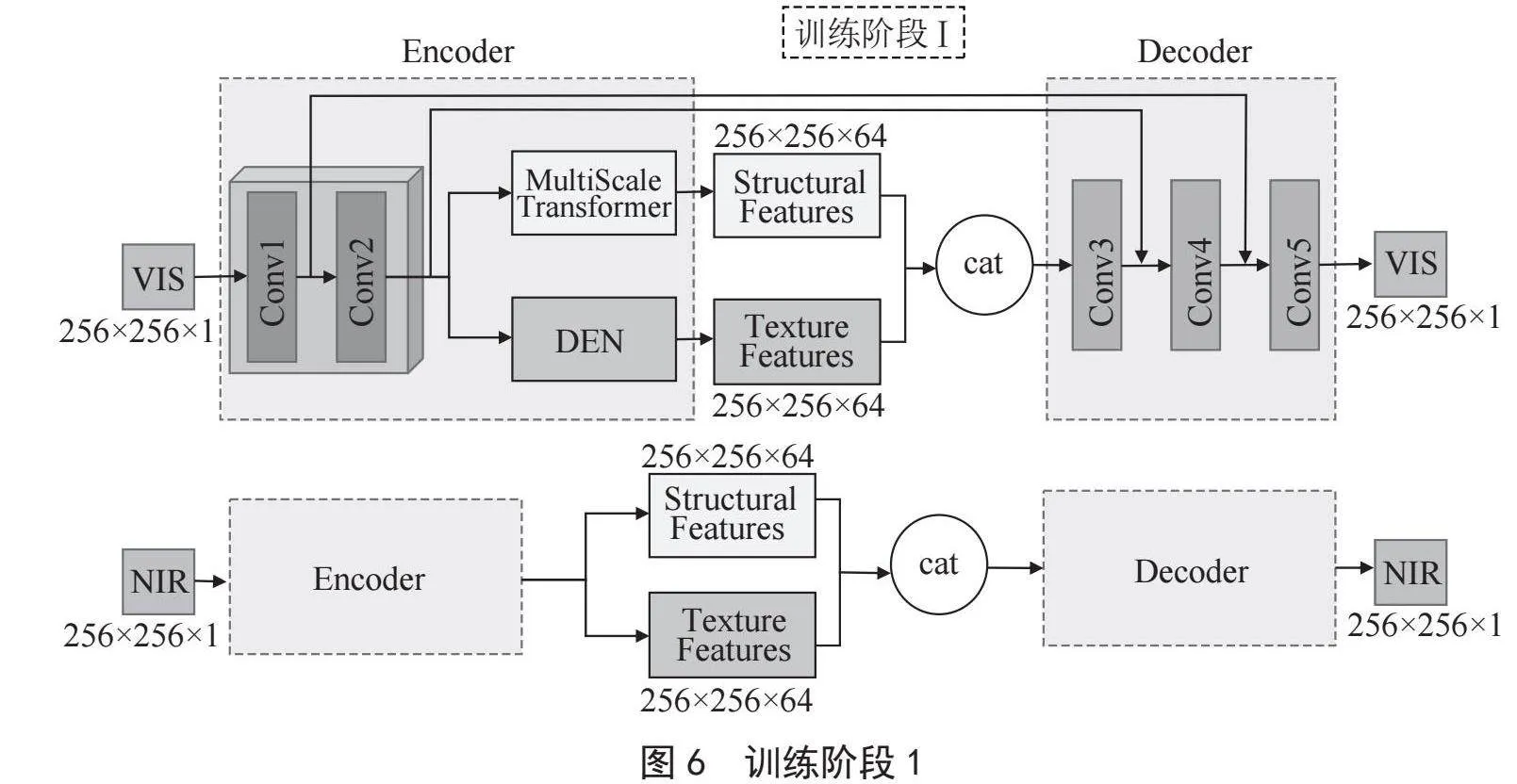
在STAFuse中,受到Li等[21]提出的RFN-Nest模型的启发,模型训练过程采用二阶段训练法,并在两阶段中加入了跳跃连接以充分利用编码器、Pag自适应融合模块和解码器的能力。在第一阶段主要集中于优化编码器和解码器的性能。编码器从输入的近红外和可见光图像中提取多尺度的特征,并通过跳跃连接将低层次特征直接传递到解码器。解码器负责从编码器传递的特征中重建出图像。第一阶段训练的结构如图6所示。
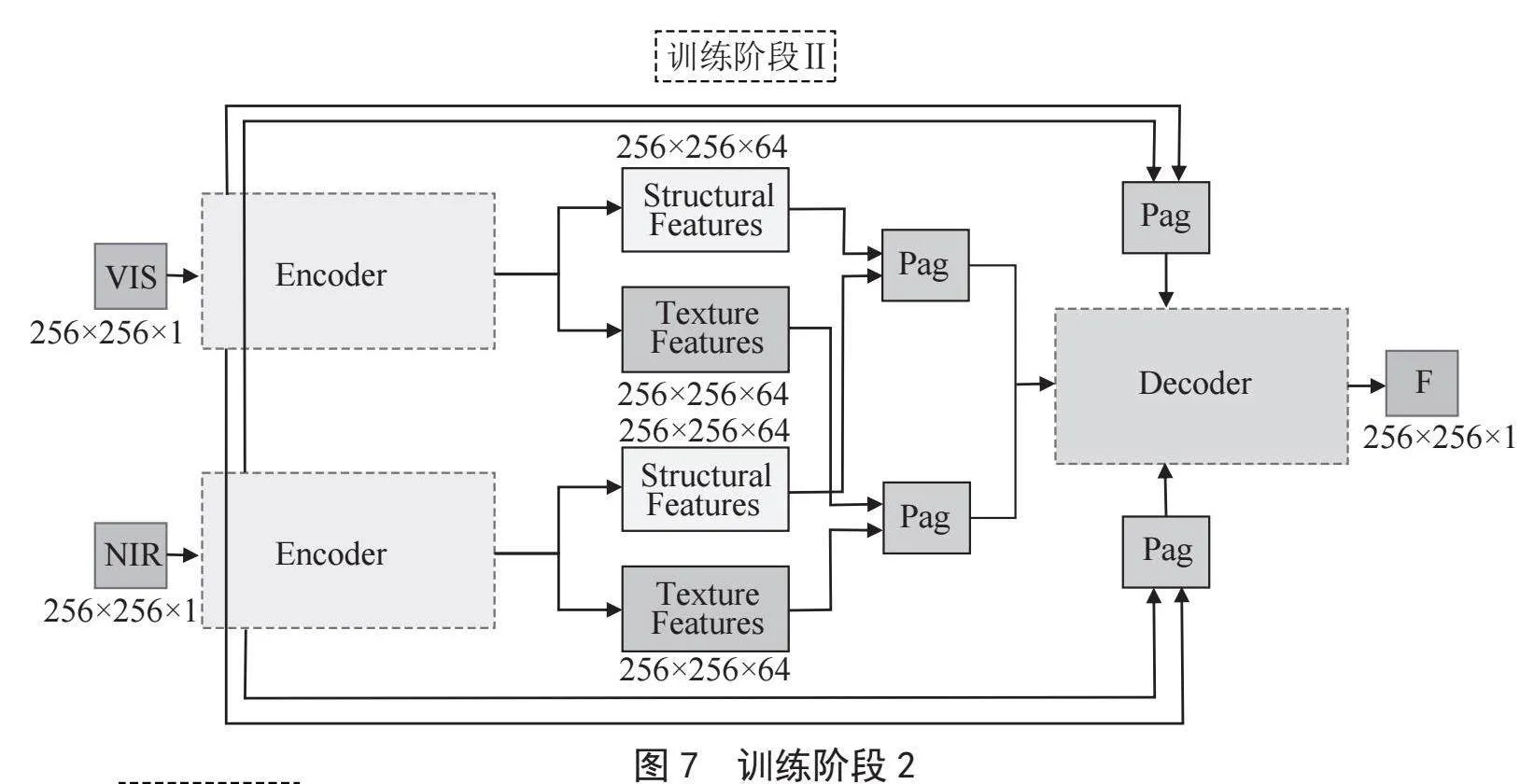
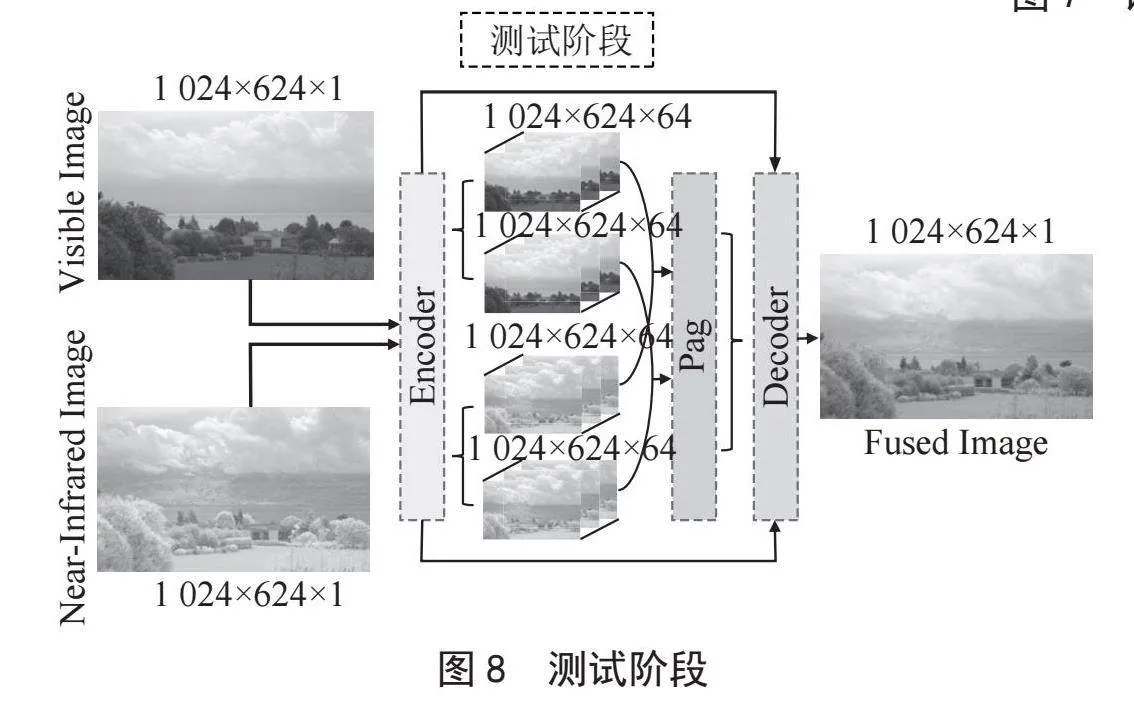
第二阶段训练中,自适应融合模块Pag与编码器和解码器共同参与训练,并且继续利用跳跃连接以保留多尺度特征。Pag模块负责动态调整不同模态图像的特征权重,结合这些特征生成融合图像。在此阶段,编码器继续优化其特征提取能力,解码器则通过跳跃连接增强其对低层次细节特征的重建能力。第二阶段训练的结构如图7所示,测试阶段的结构如图8所示。
2.2" 编码器模块
如图6所示,本文的编码器模块由三个主要部分构成:公共卷积层、中低频特征提取模块MultiScale Transformer和高频特征提取模块DEN。
首先,公共卷积层有两个卷积层Conv1和Conv2,卷积核大小为3,使用零填充。如图1在第一阶段的训练中,对于可见光图像的输入,公共卷积层的计算过程可以表示:
(3)
其中,Fshared表示公共卷积层的输出,Ivis表示输入的可见光图像。
之后,在编码器中的第二部分引入了MultiScale Transformer模块和DEN模块。如图1在第一阶段的训中,对于可见光图像的输入,MultiScale Transformer和DEN的计算过程可以表示:
(4)
其中,表示经过MultiScale Transformer得到的结构特征,表示经过DEN得到的纹理特征。
2.3" 融合策略
在多模态图像融合任务中,本文引入了Pag模块作为融合策略的核心组件,实现了更加有效的特征融合。如图7所示,在第二阶段训练中,Pag模块的计算过程如下:
对于输入的特征图x和y,分别通过卷积层进行特征变换:
(5)
其中,fx和fy分别表示特征图x和y的卷积变换。
之后通过逐通道求和计算特征图xk和yq的相似度:
(6)
其中,σ表示Sigmoid激活函数,sim_map表示求得的权重图。
最后根据求得的相似度映射,将两个特征图进行加权融合:
(7)
其中,xfused表示最后融合得到的特征图。
2.4" 解码器模块
在STAFuse模型中,解码器模块的作用是将编码器和自适应融合模块Pag处理后的特征图进行上采样和重建,以生成最终的融合图像。如图6所示的第一阶段的训练中,解码器模块由三个卷积层构成分别为Conv3、Conv4和Conv5。Conv3、Conv4和Conv5都采用3×3的卷积核和边缘填充,Conv3的目的是对融合的特征图进行初步的上采样和特征融合,为后续的重建过程提供基础。Conv4进一步处理经过Conv3层的特征图,增强图像的细节和纹理信息,同时通过跳跃连接接收来自编码器的Conv2层的输出,增强图像的全局结构信息。Conv5负责最终的图像重建,该层通过跳跃连接接收来自编码器的Conv1层的输出,确保最终输出的融合图像能够保留丰富的细节和纹理信息。
2.5" 损失函数
如图6所示,在第一阶段的训练中,第一步将近红外和可见光图像对Inir和Ivis分别输入共享的公共卷积层中得到初始特征fnir和fvis。第二步将得到的初始特征分别输入独立的特征提取模块中,这个特征模块由MultiScale Transformer和DEN组成,fnir经过MultiScale Transformer和DEN分别得到结构特征和纹理特征,fvis经过MultiScale Transformer和DEN得到结构特征和纹理特征。第三步将和、和分别在通道上做拼接之后送入解码器得到输出Onir和Ovis。第一阶段的损失函数:
(8)
其中Lvis表示:
(9)
其中表示图像之间的L2范数,表示两个图像在像素值上的差异。SSIM(Ivis,Ovis)表示结构相似度函数,用于衡量两个图像在结构、亮度和对比度上的相似性。Lgrad表示梯度损失:
(10)
其中∥∇Ivis-Ovis∥使用的是L1范数,∇表示梯度算子,这一项的作用是度量Ivis和Ovis在边缘和细节上的相似性。
如图7所示,在第二阶段的训练,将近红外图像的结构特征和可见光图像的结构特征作为Pag模块的输入,得到融合的结构特征,将近红外图像的纹理特征和可见光图像的纹理特征作为Pag模块的输入,得到融合的纹理特征,最后将和在通道上做拼接后作为解码器的输入得到融合图像。第二阶段训练的损失函数表示为:
(11)
其中表示:
(12)
表示:
(13)
代表融合模块的损失,表示:
(14)
3" 实验及结果分析
在本节中对所提出的模型进行了实验验证。首先介绍对多模态传感器分离后得到的图像对的预处理,接着介绍了训练阶段的参数设置,之后将融合网络和现有的其他算法进行了定性比较和定量分析,最后提出了几项消融实验,用于研究融合网络中一些因素的影响。
本文所提出的融合网络是使用PyTorch作为编程环境,在NVIDIA GeForce RTX 3060上实现的。
3.1 图像预处理
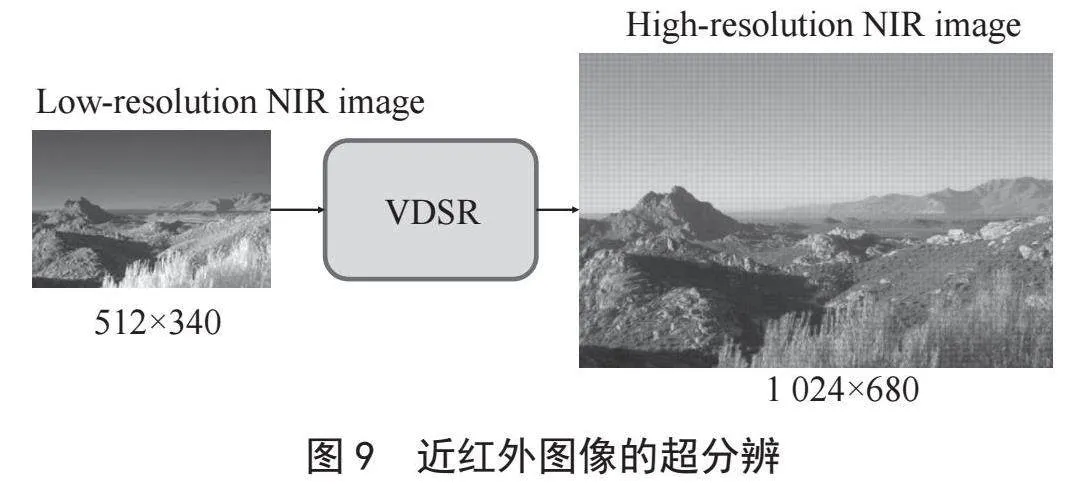
在2.3小节中提到,为了适应融合网络的输入,对多模态传感器的图像进行了预处理得到了低分辨率的近红外图像和高分辨率的可见光图像,且可见光图像的分辨率是近红外图像的4倍。本文设计的STAFuse需要相同分辨率的图像对输入,为了解决这个问题,引入了预训练的超分辨模块VDSR[22],该模块可以实现多种尺度的图像超分辨,本文选择了将低分辨的近红外图像分辨率变为原来的4倍,实验结果如图9所示。
3.2" 参数设置
在训练阶段,使用了RGB-NIR Scene Dataset的477对近红外和可见光图像对中的380对图像对。在2.3节中先将这380对图像对用于多模态传感器模拟图像的生成,在4.1节中将多模态传感器生成的低分辨率近红外图像和高分辨的可见光图像进行预处理得到380对图像对。对着380对图像对进行裁剪,裁剪的大小为256×256,得到4 128对近红外和可见光的图像对。
在第一阶段的训练中,设λ1 = 5,训练轮次为60轮,学习率设置为10-4且每隔20轮学习率降低为原来的一半,batch_size = 8。在第二阶段的训练中,设λ2 = 1,λ3 = 1,λ4 = 2,训练轮次为80轮,学习率也设置为10-4且每隔20轮学习率降低为原来的一半。
3.3" 实验结果
在测试阶段中,使用了RGB-NIR Scene Dataset中来自不同场景的97对近红外和可见光图像对作为测试集用于测试STAFuse的性能,并将融合结果与最先进的方法进行比较,包括Shallow CNN[10]、DenseFuse[9]、DIDFuse[4]和DDcGAN[11]。
3.3.1" 定性比较和定量分析
本节中将STAFuse模型的融合结果与几种最先进的图像融合方法进行了定性比较和定量比较。
在图10中展示了多对近红外和可见光源图像及其通过不同方法生成的融合图像,并将部分关键区域进行了放大比较。从图10中可以看到,Shallow CNN在细节保留上表现欠佳,特别是在复杂场景中,生成的图像较为模糊。DenseFuse在细节和对比度上有一定提升,但在边缘处理上仍显不足。DIDFuse虽然在边缘清晰度和全局结构还原上表现较好,但细节丰富度和对比度仍有所欠缺。相比之下,STAFuse能够更好地结合近红外图像在低光或复杂环境中的表现和可见光图像的细节信息。特别是复杂场景下的细节,例如树木的纹理或人行道的细微特征,STAFuse生成的融合图像在亮度、对比度和边缘清晰度方面均有显著提升,呈现出更好的视觉效果。
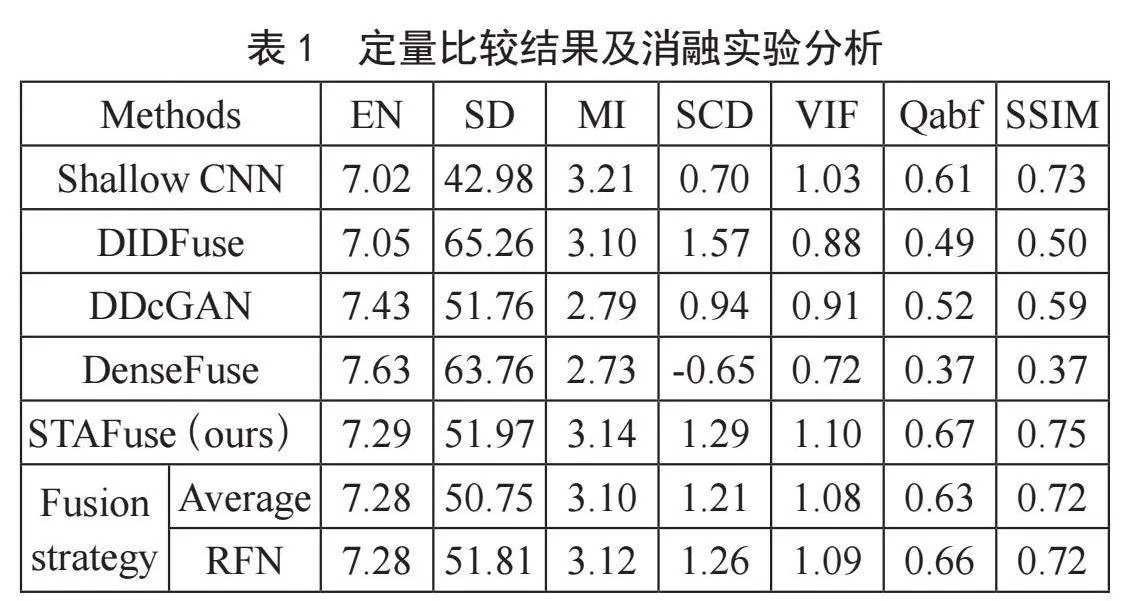
为了评估STAFuse模型的融合性能,本文采用了熵(EN)、标准差(SD)、互信息(MI)、差值相关总和(SCD)、视觉信息保真度(VIF)、边缘保持指数(Qabf)和结构相似性指数(SSIM)这7个指标进行评估。定量比较结果如表1所示,STAFuse模型在多数指标上均表现出色,尤其是在EN、SD、MI和VIF方面,取得了明显的提升。
表1" 定量比较结果及消融实验分析
具体而言,STAFuse在熵值和标准差上表现优异,分别达到了7.29和51.97,这表明其融合图像包含了较多信息量,并且保留了丰富的细节。相比之下,DenseFuse和DDcGAN在标准差上的得分分别为63.76和51.76,虽然稍高,但STAFuse在其他指标上的优势更加明显。例如,STAFuse的VIF达到了1.10,相比于DenseFuse的0.72和DDcGAN的0.88,提升了约53%和25%。这表明STAFuse生成的融合图像在视觉质量上更接近于人类的视觉感知。在Qabf和SSIM上,STAFuse也表现突出,分别取得了0.67和0.75的较高得分。相较于DIDFuse的0.49和DenseFuse的0.37,STAFuse的Qabf提升了约37%和81%。同样,STAFuse在SSIM上也有显著提升,达到了0.75,较DenseFuse的0.37提高了102.7%。这些结果表明,STAFuse不仅能在融合过程中保持图像结构的一致性,还能更好地保留边缘信息和关键特征。此外,尽管DDcGAN在熵值上达到了7.43,略高于STAFuse的7.29,但其在MI和SSIM上的表现欠佳,无法充分结合来自不同模态图像的互补信息。
综上所述,STAFuse在多个关键指标上优于现有方法,特别是在细节保留、视觉质量和融合图像的结构完整性方面表现出色。这证明了STAFuse自适应融合策略的有效性和鲁棒性。
3.3.2" 消融实验
为了验证STAFuse中自适应融合策略的有效性,本文设计了消融实验,分别将自适应融合模块替换为平均融合(Average)和残差融合策略(RFN)。表1展示了不同融合策略下模型的性能。结果表明,自适应融合策略能够显著提升融合图像的质量,尤其在VIF和SSIM等关键指标上表现更佳。具体来说,使用自适应融合策略时,模型的VIF指标达到1.10,相较于平均融合策略(1.08)提升了约1.9%,相较于残差融合策略(1.09)提升了约0.9%。此外,SSIM从平均融合策略的0.72提升到0.75,增幅为4.2%;相较于残差融合策略(0.72),SSIM也提升了约4.2%。这些结果证明了自适应融合策略在不同模态图像融合中的优势,能够更好地保留图像的结构和细节信息,显著提升了融合图像的整体质量。
4" 结" 论
本文提出了一种基于频域分解的近红外与可见光图像自适应融合模型STAFuse,利用结合Transformer与CNN的特征提取模块,以及自适应融合模块Pag,实现了不同模态图像特征的有效融合。在多模态数据的获取上,提出了一种多模态传感器的改进方案,为图像融合技术的发展提供了新的思路。实验结果表明,STAFuse在多个评估指标上均取得了较为优异的成绩,能够在复杂环境下生成具有高细节保留、良好对比度和视觉质量的融合图像。此外,通过消融实验验证了自适应融合策略在提升融合图像质量方面的有效性。
在未来的工作中,计划将STAFuse模型部署到FPGA上,结合新型多模态传感器,构建一个集成化的图像采集和处理系统。通过将模型部署到FPGA上,一方面可以充分利用硬件加速的优势,提升图像融合处理的实时性和效率,特别是在低功耗和资源受限的场景下。另一方面,FPGA作为独立的硬件平台,可以实现系统的高度集成,使图像处理系统不再依赖PC端的GPU处理器,从而具备更高的可移植性和灵活性,适合于嵌入式应用场景,特别是在无人机、自动驾驶、智能监控等对体积、功耗和实时性要求严格的应用中,FPGA的硬件加速特性将为此类产品提供更具竞争力的解决方案。
参考文献:
[1] LAHOUD F,SUSSTRUNK S. Ar in VR: Simulating Infrared Augmented Vision [C]//2018 25th IEEE International Conference on Image Processing (ICIP).Athens:IEEE,2018:3893-3897.
[2] HU H M,WU J W,LI B,et al. An Adaptive Fusion Algorithm for Visible and Infrared Videos Based on Entropy and the Cumulative Distribution of Gray Levels [J].IEEE Transactions on Multimedia,2017,19(12):2706-2719.
[3] MA J Y,ZHOU Y. Infrared and Visible Image Fusion Via Gradientlet Filter [J].Computer Vision and Image Understanding,2020,197/198:12.
[4] ZHAO Z X,XU S,ZHANG C X,et al. DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion [J/OL].arXiv:2003.09210 [eess.IV].[2024-10-08].https://arxiv.org/abs/2003.09210?context=eess.
[5] LI S T,YANG B,HU J W. Performance Comparison of Different Multi-Resolution Transforms for Image Fusion [J].Information Fusion,2011,12(2):74-84.
[6] ZONG J J,QIU T S. Medical Image Fusion Based on Sparse Representation of Classified Image Patches [J].Biomedical Signal Processing and Control,2017,34:195-205.
[7] LI H,WU X J,KITTLER J. Infrared and Visible Image Fusion Using A Deep Learning Framework [C]//2018 24th international conference on pattern recognition (ICPR).Beijing:IEEE,2018:2705-2710.
[8] MA J Y,YU W,LIANG P,et al. FusionGAN: A Generative Adversarial Network for Infrared and Visible Image Fusion [J].Information Fusion,2018,48:11-26.
[9] LI H,WU X J. DenseFuse: A Fusion Approach to Infrared and Visible Images [J].IEEE Transactions on Image Processing,2019,28(5):2614-2623.
[10] LI L,XIA Z Q,HAN H J,et al. Infrared and Visible Image Fusion Using a Shallow CNN and Structural Similarity Constraint [J].IET Image Processing,2020,14(14):3562-3571.
[11] MA J Y,XU H,JIANG J J,et al. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion [J].IEEE Transactions on Image Processing,2020,29:4980-4995.
[12] XU J C,XIONG Z X,BHATTACHARYYA S P. PIDNet: A real-time Semantic Segmentation Network Inspired by PID Controllers [C]//2023 IEEE/CVF conference on computer vision and pattern recognition.Vancouver:IEEE,2023:19529-19539.
[13] XU L L,LIANG P X,HAN J,et al. Global Filter of Fusing Near-Infrared and Visible Images in Frequency Domain for Defogging [J].IEEE Signal Processing Letters,2022,29:1953-1957.
[14] JANG D W,PARK R H. Colour Image Dehazing Using near-Infrared Fusion [J].IET Image Processing,2017,11(8):587-594.
[15] ROWN M,SÜSSTRUNK S. Multi-Spectral SIFT for Scene Category Recognition [C]//CVPR 2011.Colorado Springs:IEEE,2011:177-184.
[16] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].[2024-10-08].https://arxiv.org/abs/2010.11929v2.
[17] CARION N,MASSA F,SYNNAEVE G,et al. End-to-End Object Detection with Transformers [C]//16th European conference on computer vision.Glasgow:Springer,2020:213-229.
[18] ZHENG S X,LU J C,ZHAO H S,et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers [C]//2021 IEEE/CVF conference on computer vision and pattern recognition.Nashville:IEEE,2021:6877-6886.
[19] LIN X,YAN Z Q,DENG X B,et al. Conv Former: Plug-and-play CNN-style transformers for improving medical image segmentation [C]//26th International Conference on Medical Image Computing and Computer-Assisted Intervention.Vancouver:Springer,2023:642-651.
[20] ARDIZZONE L,KRUSE J,WIRKERT S,et al. Analyzing Inverse Problems with Invertible Neural Networks [J/OL].arXiv:1808.04730 [cs.LG].[2024-10-09].https://arxiv.org/abs/1808.04730.
[21] LI H,WU X J,KITTLER J. RFN-Nest: An end-to-End Residual Fusion Network for Infrared and Visible Images [J].Information Fusion,2021,73:72-86.
[22] KIM J,LEE J K,LEE K M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks [C]//2016 IEEE conference on computer vision and pattern recognition.Las Vegas:IEEE,2016:1646-1654.
作者简介:李振伟(2000—),男,汉族,福建福鼎人,硕士在读,研究方向:深度学习、图像融合。