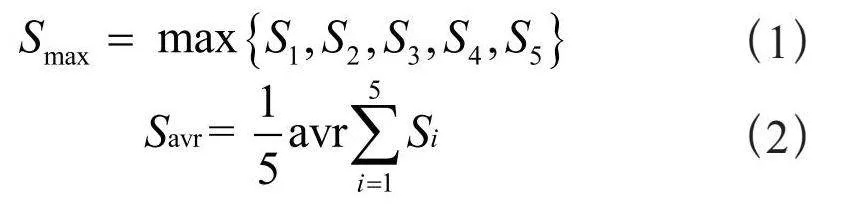


摘" 要:针对传统中小企业客户数据呈现杂乱无序状态且缺乏标准化的现状,提出一种创新的数据治理技术。该技术整合多源异构数据,该技术汇聚多源异构数据,融合光学字符识别(Optical Character Recognition, OCR)等多种方法,构建标准化的中小企业基础信息数据湖,从源头提升数据质量。引入“熵减”理念,利用智能算法对数据质量进行量化评估,能够及时定位并解决数据质量问题。同时,搭建时序数据库并构建基于熵减的马尔科夫链模型,以此预测未来数据质量趋势,精准治理潜在问题区域。该技术不仅实现了数据价值的最大化,还显著降低了治理成本,提高了数据治理的效率与准确性,为企业降本增效提供了有力支撑。
关键词:熵减;数据治理;马尔科夫链;中小企数据湖;时序数据库
中图分类号:TP311.1" " 文献标识码:A" 文章编号:2096-4706(2025)03-0140-07
Customer Data Governance Technology of Small and Medium Enterprises Based on Entropy Decrease and Markov Chain
LIU Min, HUANG Yixiao, CHEN Zhiyang, ZHANG Zhanmei
(China Mobile Communications Group Guangdong Co., Ltd., Guangzhou" 510623, China)
Abstract: Aiming at the current situation that the customer data of traditional small and medium enterprises is disorderly and lacks standardization, an innovative data governance technology is proposed. This technology integrates multi-source heterogeneous data, fuses Optical Character Recognition (OCR) and other methods, and constructs a standardized basic information data lake of small and medium enterprises, to improve data quality from the source. By introducing the concept of “entropy decrease” and using intelligent algorithms to quantitatively evaluate data quality, data quality problems can be located and solved in time. At the same time, a time series database is built and a Markov Chain model based on entropy decrease is constructed to predict future data quality trends and accurately govern potential problem areas. This technology not only maximizes the value of data, but also significantly reduces the cost of governance. It improves the efficiency and accuracy of data governance and provides strong support for enterprises to decrease costs and increase efficiency.
Keywords: entropy decrease; data governance; Markov Chain; data lake of small and medium enterprises; time series database
0" 引" 言
中小企业作为数量最为庞大、最具活力的企业群体,贡献了50%以上的税收、60%以上的国内生产总值(GDP)、70%以上的技术创新成果、80%以上的城镇劳动就业岗位以及90%以上的企业数量。在“发挥运营商的数智化优势,以创新驱动向各产业赋能,提升社会数智化水平”的发展新要求下,如何有效地管理和治理运营商大数据中的中小企业客户数据,成为亟待解决的关键问题。
传统的中小企业大数据存在诸多问题。数据源杂乱无章,人工录入的数据缺乏有效的数据问题检测手段,导致错误数据较多;同时,对数据质量缺乏客观评估和量化分析;针对数据问题,也缺乏有效的治理方案和修复方案。此外,数据治理过程中投入的人力成本大,方法复杂,手动维护成本高,处理时间长且效率低下,这些问题严重阻碍了中小企业大数据价值的发挥。
1" 现有中小企业客户数据治理问题
在现有的中小企业客户数据治理工作中,主要面临以下几方面问题:中小企业数据采集杂乱繁多,数据治理难度大;数据治理缺乏量化的计算和评估;缺乏中小企业数据治理监控预测机制;缺少中小企业数据治理的闭环机制。具体分析如下:
1)中小企业数据采集杂乱多,数据治理难:现有技术方案中,中小企业数据采集杂乱繁多,人工录入的数据错误率高,标准化程度低,难以清晰地获取中小企业的数量、公司名称、地址分布等基础信息。
2)中小企业数据质量缺乏量化的计算和评估:目前主流的中小企业数据质量管理,对系统数据质量情况缺乏量化的计算和评估。仅能知晓系统存在数据质量问题,但缺乏客观的评估标准,只能大概了解某个模块存在较大数据质量问题,却无法准确掌握各个模块的数据质量问题详情。
3)缺乏中小企业数据质量监控预测机制:现有技术方案缺少数据质量预测机制,无法得知哪个模块在未来几个月数据质量会变差,不能及时排查和解决数据质量问题,从而引发数据使用过程中的各种投诉,影响数据的使用价值。
4)缺少中小企业数据治理的闭环机制:现有技术方案缺乏数据治理的闭环机制,没有建立数据质量调整知识库,无法智能设置数据质量调整策略,也不能针对外部原因和业务原因进行智能的数据质量监控调整。
2" 基于熵减和马尔科夫链的数据治理
为解决上述技术问题,在当前主流的中小企业客户数据治理基础上,结合运营商大数据的特性,创新性地融合熵减理论与马尔科夫链,构建数据湖并对数据质量进行智能评估[1-5]。通过量化评估与监控、优化时序数据库查询、预测数据质量趋势,形成了高效、精准的数据治理体系,降低了数据治理成本,提升了治理效率与数据质量,确保实现数据价值的最大化。具体技术方案如下:
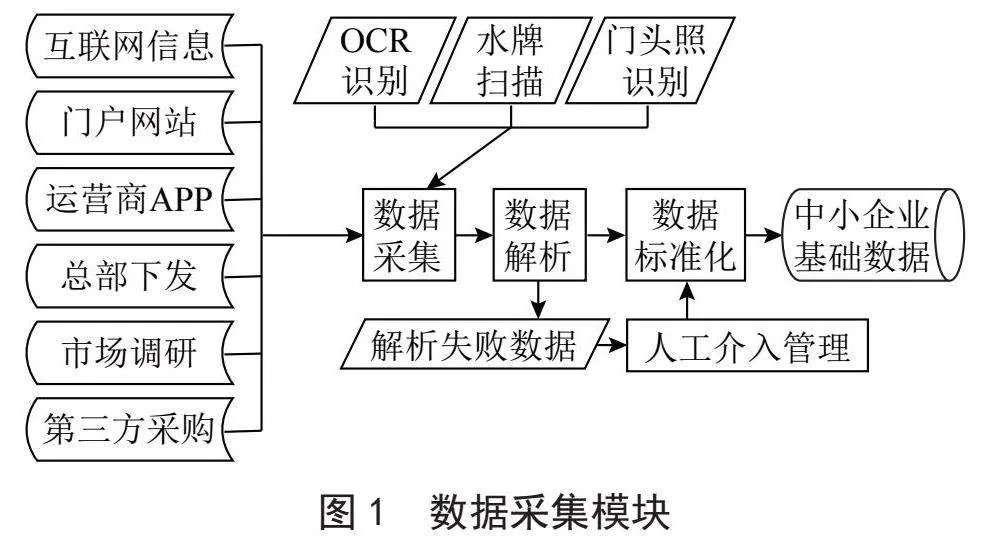
1)多源异构的中小企业运营商大数据获取和融合。通过汇聚互联网信息、运营商门户网站、运营商APP、运营商总部下发信息、市场调研数据以及第三方采购数据等,运用基于OCR识别、水牌扫描、门头照识别等多源异构数据汇集和融合处理技术,智能构建运营商中小企业基础信息数据湖。
2)创建基于熵函数的智能算法。引入“熵减”理念构建中小企业数据治理模式,创建基于熵函数、最大熵、均熵的智能算法,对中小企业数据信息进行动态智能化数据质量监控,查找数据质量失衡的问题原因并加以解决。
3)构建中小企业数据质量时序数据库。根据熵值和均熵的时序排列,构建中小企业数据质量时序数据库。采用标签+时间戳分区检索方式、TSM树存储技术,数据导入时间缩短了31.87%,占用空间减少了46.74%;运用预聚合和多维分组聚合查询技术、保留删除策略,查询速度提升了一倍。
4)形成基于熵减的马尔科夫链。根据历史数据质量熵值和对应的数据质量状态,利用数据质量状态向量和数据质量状态转移矩阵,形成基于熵减的马尔科夫链,预测未来几个月的数据质量情况,并对大概率存在数据质量问题的模块进行数据治理。
通过打造一套完备的中小企业数据治理技术和体系,有效降低了数据治理的人力成本,解决了数据治理效率低、数据质量问题定位不准确、解决不及时等问题,实现了数据价值的最大化。
3" 基于熵减和马尔科夫链治理实现
3.1" 多源异构的大数据获取和融合
我国中小企业数量庞大,在城市中分布广泛且分散。“清晰获取中小企业的数量、公司名称、地址分布等基础信息”是运营商拓展中小企业市场的重要手段。如何获得一份全面且高质量的“中小企业”名单,是业务发展的重要问题。
本系统基于“熵减”理念,汇集多源异构的中小企业数据来源。通过汇聚互联网信息、运营商门户网站、运营商APP、运营商总部下发信息、市场调研数据以及第三方采购等商机线索,运用基于OCR识别、水牌扫描、门头照识别等多源异构数据汇集和融合处理技术,智能构建运营商中小企业基础信息数据湖,降低人工收集及整理的成本,提高运营商在中小企业市场上的商机获取效率[6-10]。
获取的数据包括结构化、半结构化、非结构化数据,经过识别、解释、归一化处理后生成标准化的中小企业基础数据。
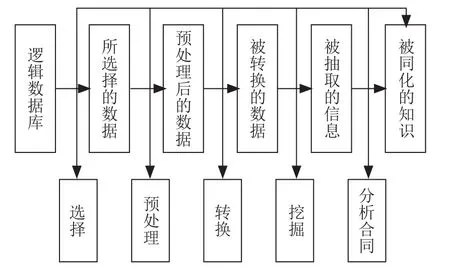
基于多源异构数据汇集和融合处理的中小企业运营数据采集处理的主要流程如图1所示。由于每个外部系统采集来的原始数据格式各异,所以需要对接口协议进行解析,以获取中小企业的基本信息,这些信息涵盖企业名称、企业网址、创建日期、员工数量、行业分类、注册资金、年营业额、信用信息等关键数据。部分信息借助OCR识别、水牌扫描、门头照识别等技术进行处理,以提升数据的精确度。对于无法直接通过系统解释处理的原始数据,则通过人工介入处理后再生成标准化数据。最终形成统一的中小企业基础数据仓库和数据湖。
3.2" 创建基于熵函数的智能算法
在大数据管理中,通常用熵的大小来表示数据质量偏离其平衡态或稳态的程度。由于大数据系统的数据来源于外部系统,若不加以控制,熵会逐渐增大,数据质量也会随之变差。因此,我们需要定义熵来衡量大数据系统的整体数据质量状况,并依据熵的情况对系统的数据质量进行控制,以确保数据的准确性。
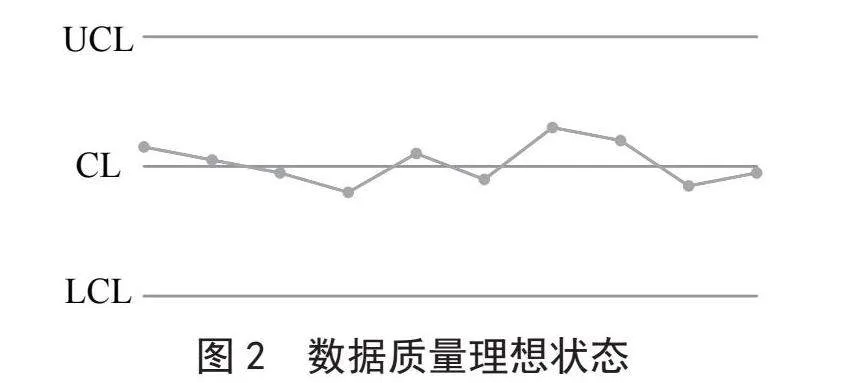
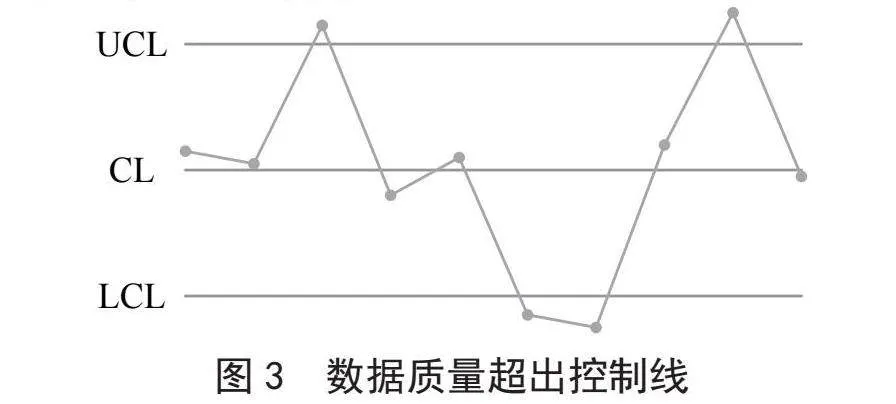
在理想状态下,数据质量控制点应处于预警线内,且排列无异常现象,如图2所示。中控制线(Control Line, CL)代表数据质量稳定状态下的预期表现;控制上限(Upper Control Line, UCL)代表数据质量可能波动的上限,若超过该上限,则表明数据质量出现问题;控制下限(Lower Control Line, LCL)代表数据质量可能波动的下限,若低于该下限,同样表明数据质量出现问题。
数据质量控制点X =实际指标值Ai-标准指标值Si,其中Si可根据业务情况进行设置和调整。例如,对于运营商用户通信时长指标,工作日的通信时长通常偏大,休息日的通信时长通常偏小,因此通信时长的标准指标数值,在休息日会比工作日少约20%。
而数据质量不理想的状态主要有以下几种情况,针对这些情况构建相应的熵函数,以进行数据质量监控和调整,从而达到熵减的目的:
1)数据质量监控点超出控制线范围,如图3所示。若有若干数据质量监控点超出了控制线界限,超出的点越多,数据质量问题就越严重,此时需要进行数据质量问题的查找和解决。
针对数据质量超出控制线情况,我们构建熵函数S1,用于表示当n个数据点超出控制线时,出现数据质量问题的概率。
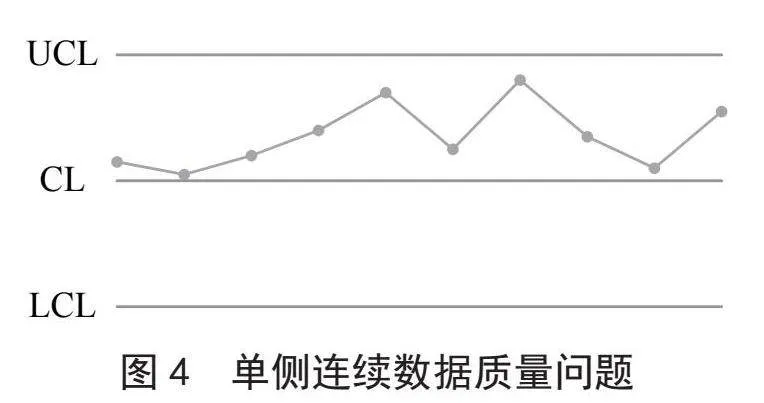
2)数据质量监控点在控制界限内,但在单侧连续出现数据质量问题,如图4所示。当若干个连续的数据质量监控点出现在中心线同一侧时,就出现了单侧连续数据质量问题。
针对单侧连续数据质量问题情况,我们构建熵函数S2,用于表示当连续n个数据点处于中心线同一侧时,出现数据质量问题的概率。
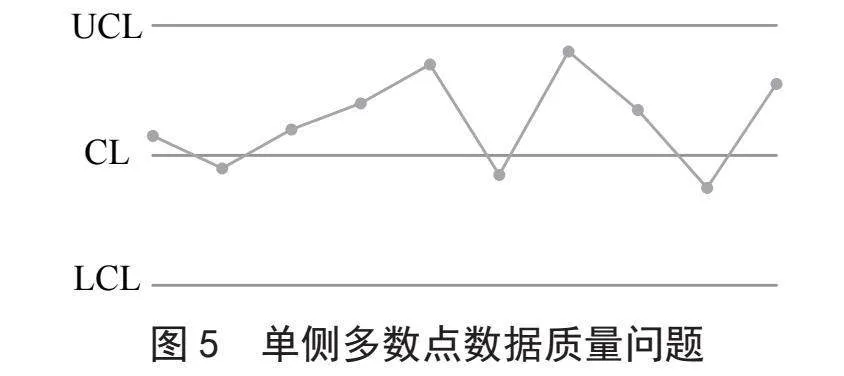
3)数据质量监控点在控制界限内,但在单侧多数点出现数据质量问题,如图5所示。若多数数据质量监控点出现在中心线同一侧,则出现单侧多数点数据质量问题。
针对单侧多数点存在数据质量问题情况,我们构建熵函数S3,用于表示连续n个数据质量监控点中,至少有t个数据质量监控点处于中心线同一侧时,出现数据质量问题的概率。
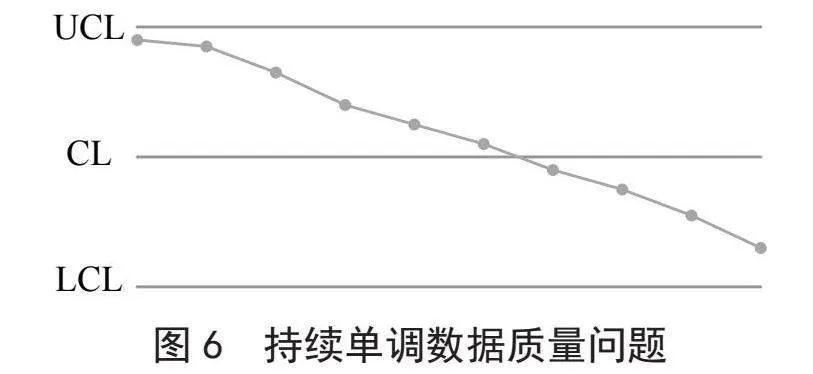
4)数据质量监控点在控制界限内,但出现持续单调数据质量问题,如图6所示。当若干个连续的数据质量监控点出现持续上升或下降现象时,就出现了持续单调数据质量问题。
针对持续单调数据质量问题情况,我们构建熵函数S4,用于表示连续n个数据质量监控点连续上升或下降时,出现数据质量问题的概率。
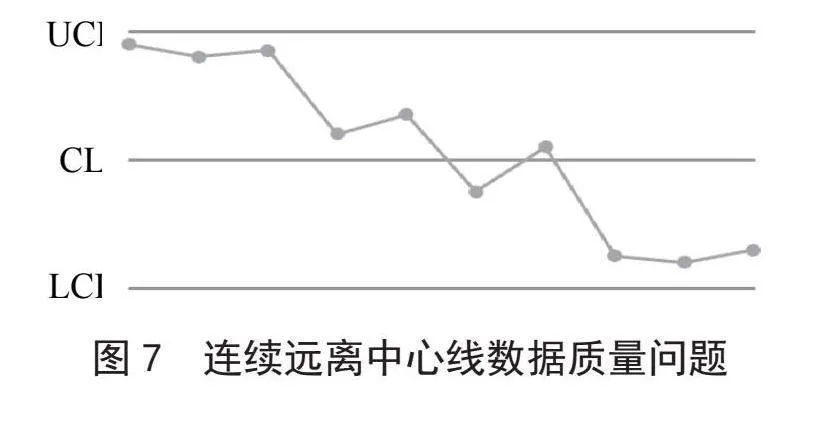
5)数据质量监控点在控制界限内,但连续远离中心线,如图7所示。当连续若干个数据质量监控点远离中心线,接近控制界限时,就出现了远离中心线数据质量问题现象。
针对连续远离中心线情况,我们构建熵函数S5,用于表示连续若干个数据质量监控点接近控制线限制时,出现数据质量问题的概率。
在以上五个熵函数的基础上,再定义最大熵和均熵,以此表示系统的数据质量情况。
(1)
(2)
通过计算这些熵和均熵,能够判断系统的数据质量情况,及时查找数据质量失衡的原因并加以解决。此外,根据这些熵和均熵的时序排列,结合时序数据库和马尔科夫链方法,还可以提供数据质量问题预警,及时解决数据质量问题。
3.3" 构建中小企业数据质量时序数据库
基于前面步骤得到的五个熵、最大熵和均熵,以及这些熵函数随时间变化而得到的时序数据序列,可以构建数据质量时序数据库。
时序数据即时间序列数据,是指某个指标按照时间顺序记载的数据序列。在以时间为横轴的坐标系中将时序数据值连成线,并将历史时序数据制作成多维度数据表,有助于发现其中的规律和异常。因此,在时序数据库中对数据质量熵函数进行大数据分析,能够更精确地进行数据质量异常预警。
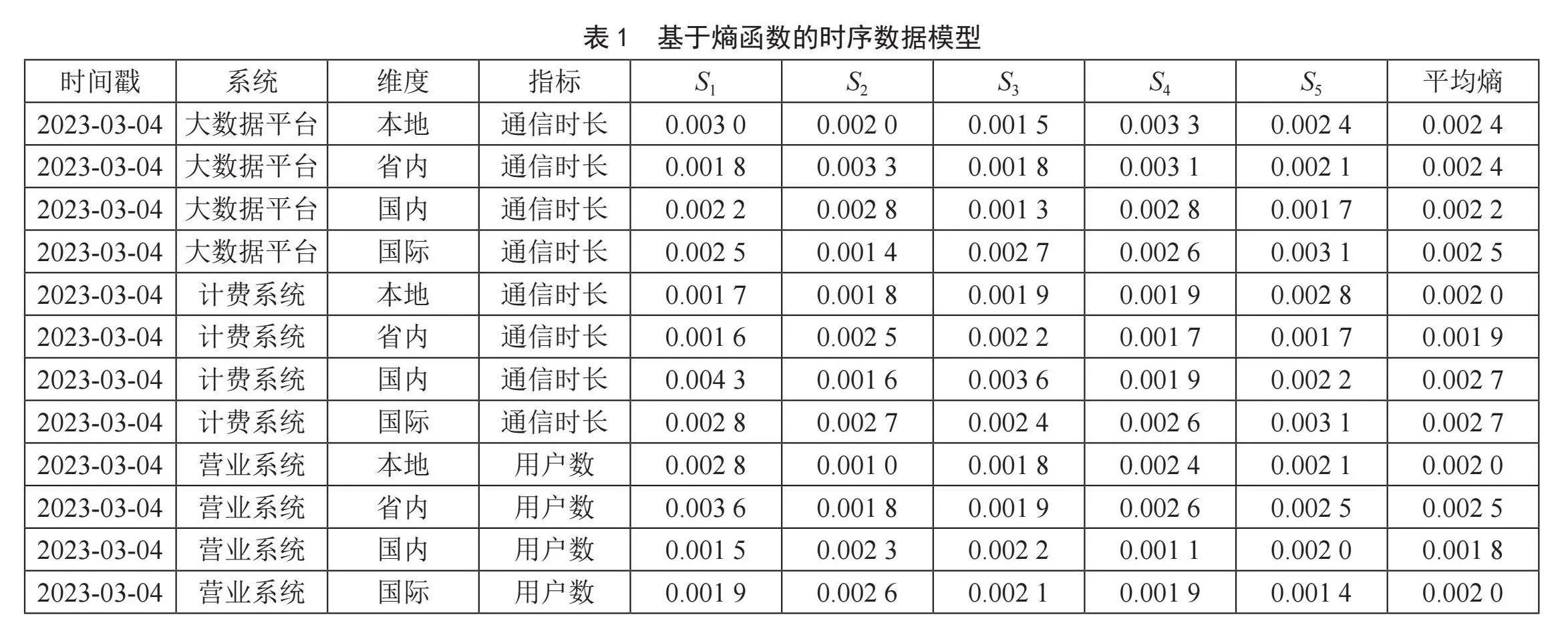
首先设计基于熵函数的时序数据模型,该模型应包含时间戳、熵函数所属系统、维度分类、指标名称、五个熵函数、均熵等信息。具体举例见表1。
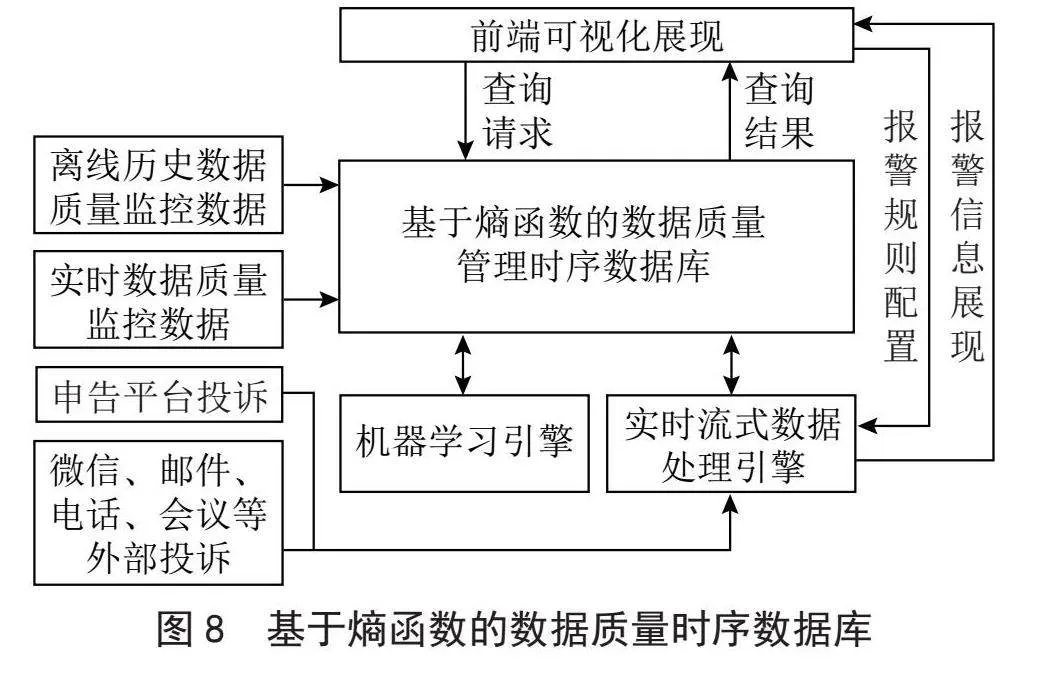
接下来,构建基于熵函数的数据质量时序数据库。在该时序数据库中,存储离线历史数据质量监控数据以及实时数据质量监控数据。此外,申告平台投诉数据和外部投诉数据,经实时流式数据处理引擎处理后,也被标准化为数据质量监控数据,并存入时序数据库。这些数据在前端进行可视化展示,并根据客户的使用情况对报警规则进行配置调整,如图8所示。
3.4" 形成基于熵减的马尔科夫链
马尔科夫链是一种用于描述数据相关性的数学模型,能够精确计算出一系列观测结果之间的相关程度。我们可以依据现有的数据质量报告和熵函数,估算系统数据质量情况(即数据质量熵)。这些带有时间戳的数据质量熵,构成了马尔科夫链。借助马尔科夫链模型,我们能够预测系统数据质量情况,并对大概率存在数据质量问题的模块进行数据治理,以达到 “熵减”效果。
具体设计步骤如下:
1)根据前面计算得到的数据质量熵函数和均熵Savr进行数据质量等级划分,并设置马尔科夫链状态:
E1:数据质量优秀,基本无数据问题,Savr<0.001
E2:数据质量良好,偶尔有小数据问题,0.001≤Savr<0.005
E3:数据质量一般,时常有数据问题但仍可接受,0.005≤Savr<0.020
E4:数据质量不好,偶尔有较大数据问题,需要整改。0.020≤Savr<0.100
E5:数据质量糟糕,无法忍受,亟须整改。Savr≥0.100
2)获取历史数据质量熵值和对应的数据质量状态,形成带时间戳的状态向量A =(E1、E2、E3、E4、E5)。
3)根据历史不同时间的数据质量变动情况,计算状态转移概率矩阵B,矩阵中的各行元素之和为1,即对于某一时间的数据质量状态,将来转换为本状态和其他各种状态的概率之和为1。
(3)
4)利用已知某时间的数据质量状态向量A,以及根据历史数据计算得到的数据质量状态转移矩阵B,通过A乘以B可以得到未来时间的数据质量情况。
(4)
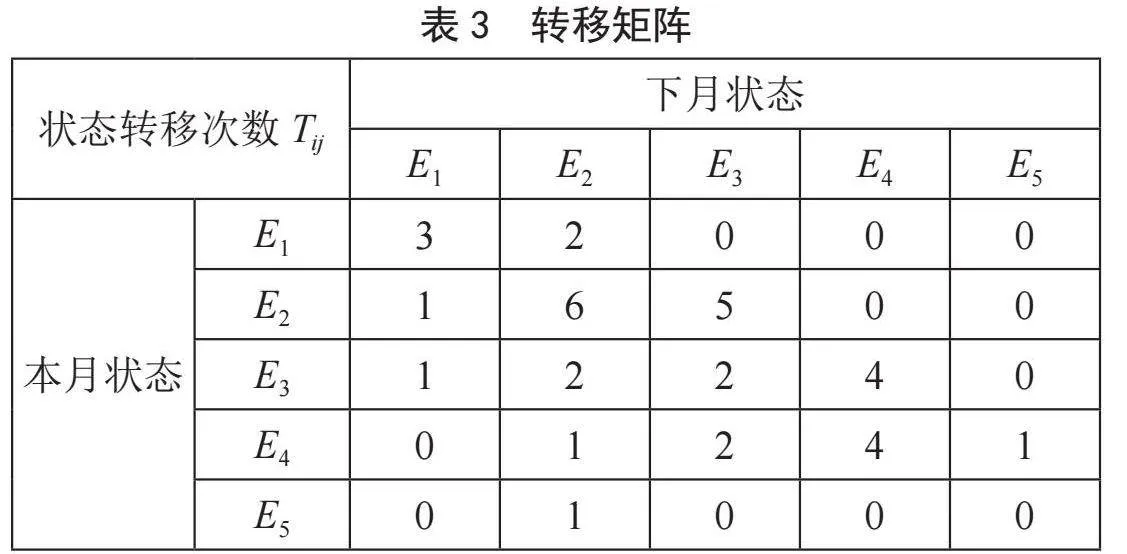
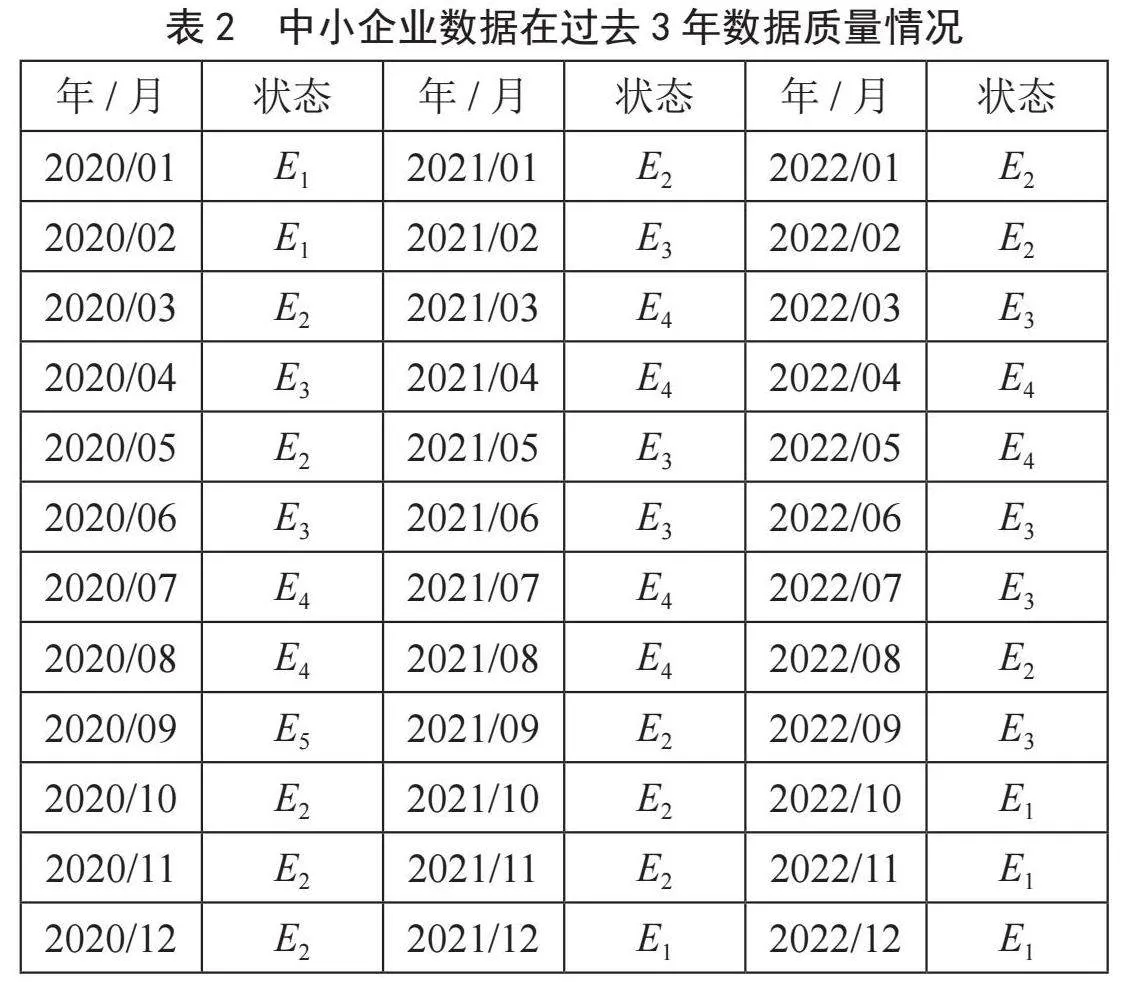
以中小企业的运营商数据质量预测为例,过去三年中小企业的运营商数据质量情况如表2所示。
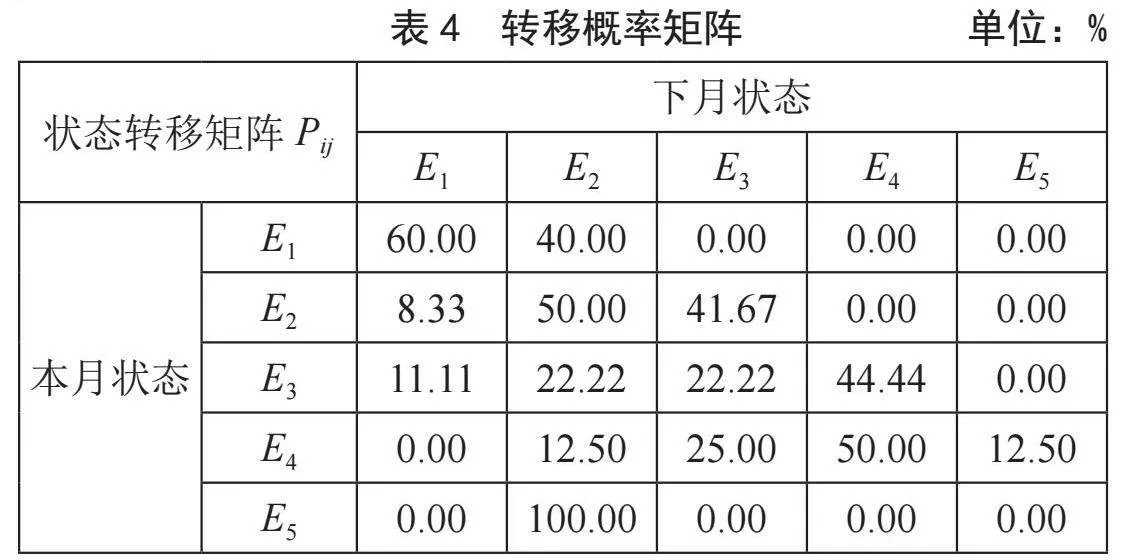
由表2可知,在5个从E1出发的状态中,有3个转移到E1,2个转移到E2。同样也可以得出从E2到E4出发的状态转移情况,如表3转移矩阵和表4转移概率矩阵所示,其中Tij表示从Ei状态转移到Ej状态的次数,例如T12 = 2,表示E1状态转移到E2状态的次数为2;Pij表示从Ei状态转移到Ej状态的概率,例如P12 = 40%,表示E1的5次状态转移中,有2次,即40%的概率转移到E2状态。
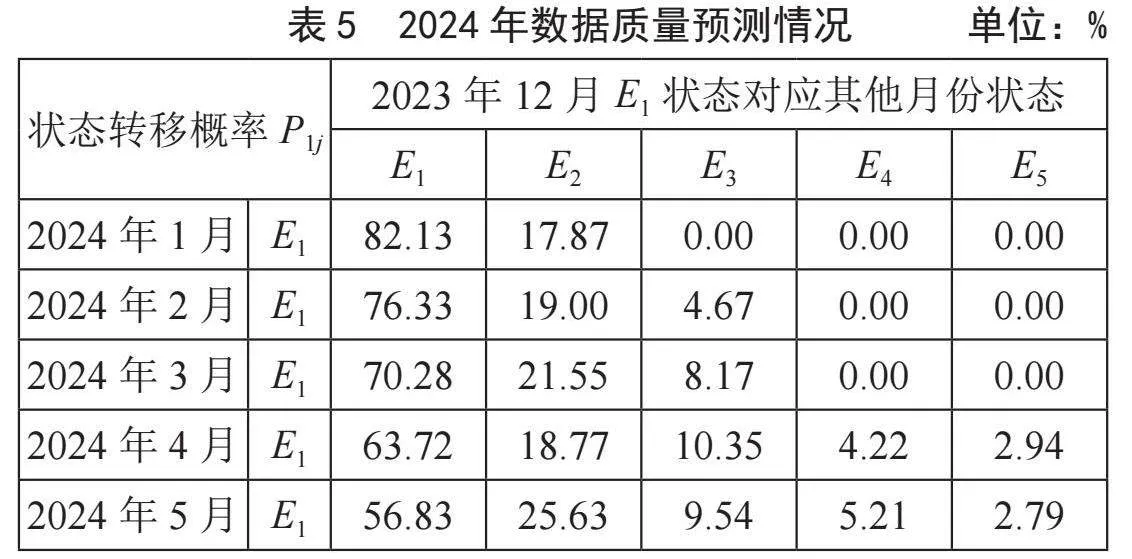
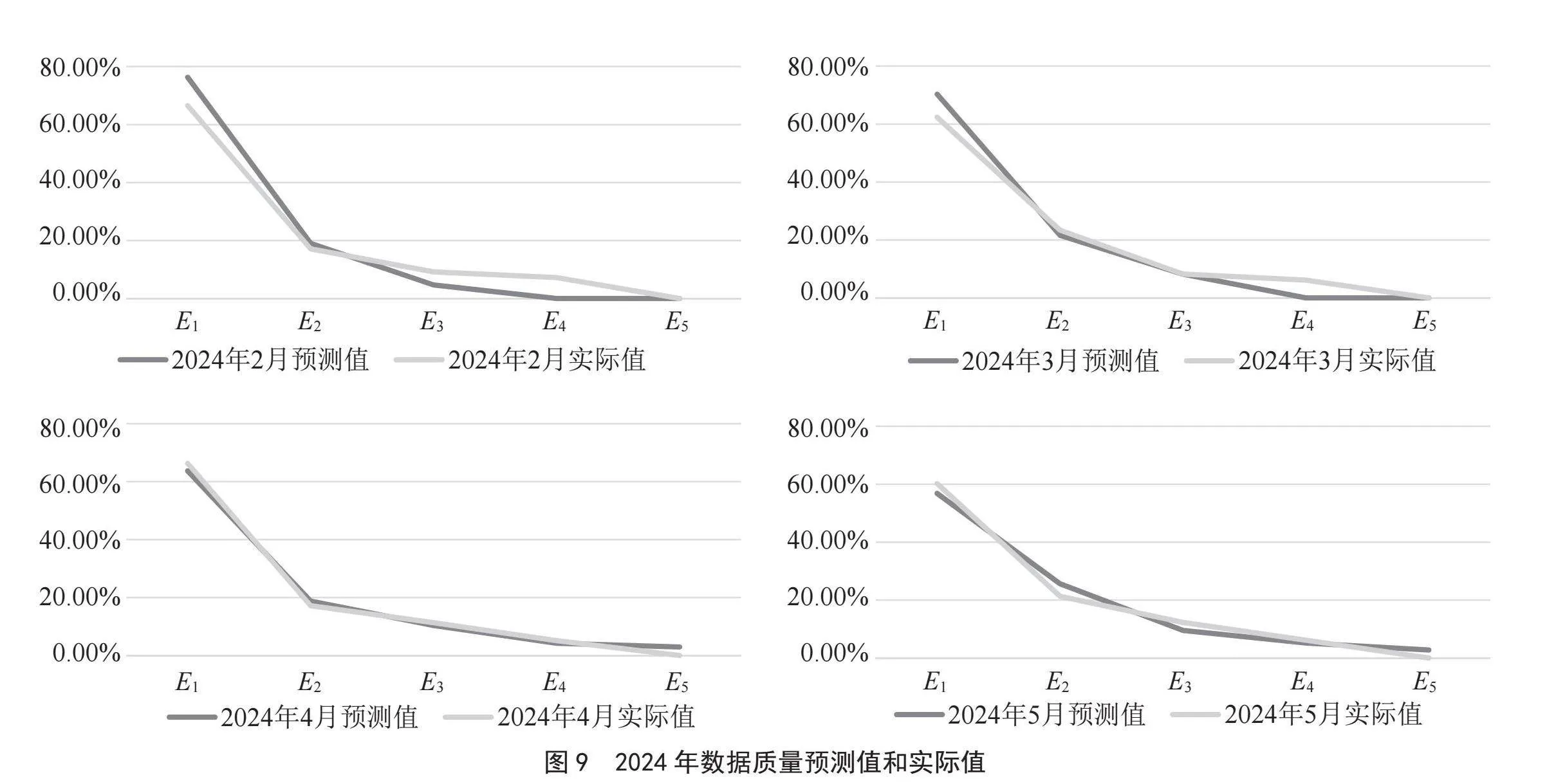
根据转移概率矩阵,可以预测下个月乃至后面几个月的数据质量情况。比如根据2023年12月数据质量为E1的状态,可以预测2024年2月,数据质量保持E1的概率为76.33%,数据质量降低为E2的概率为19%,数据质量降低为E3的概率为0%,如表5所示。
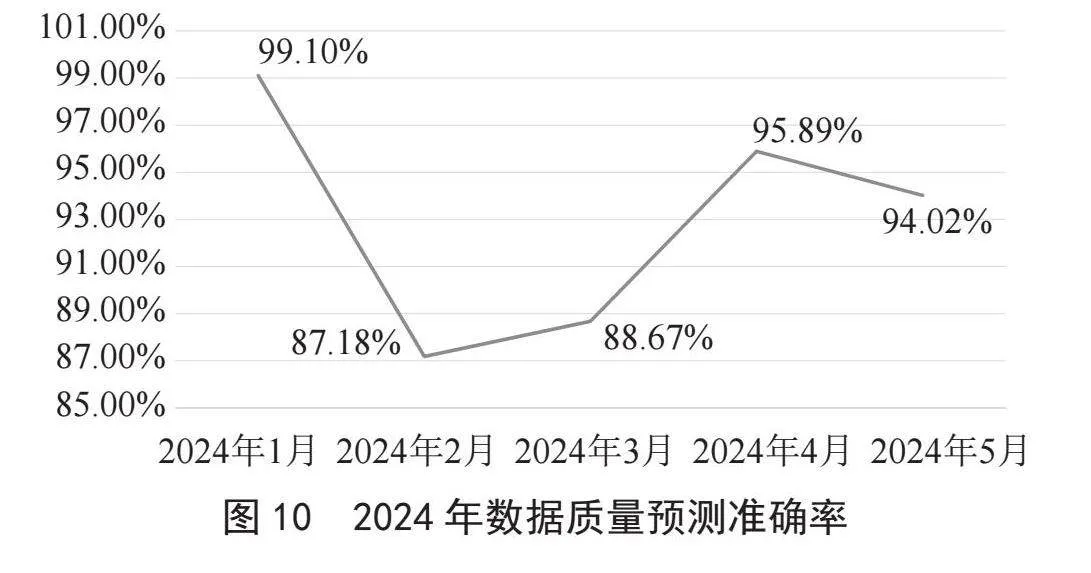
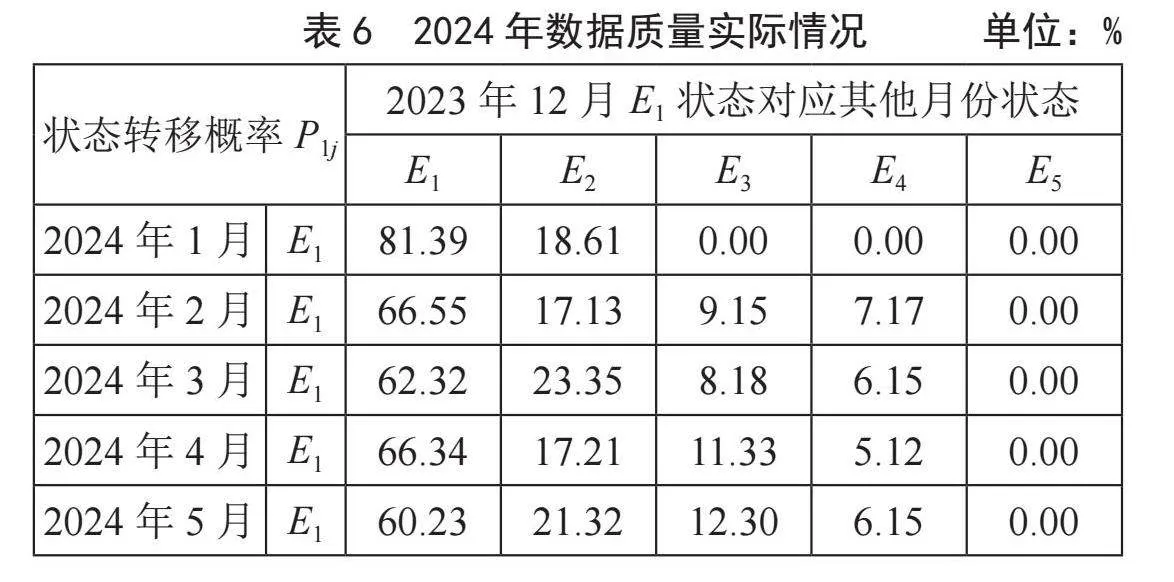
而系统检测到2024年数据质量实际情况如表6所示,2024年数据质量预测和实际的拟合曲线图如图9所示。
第M月的数据质量预测准确率计算方法如下:
(5)
由此可以得到2024年数据质量预测准确率如图10所示。由于2月份是春节期间,2、3月数据波动比较大,所以2、3月的实际数据质量看上去比预测要差一点,后续将增加业务波动因子来提升预测准确性。
4" 结" 论
传统的中小企业数据杂乱繁多,标准化程度低。本文提出的中小企业客户数据治理技术,汇聚多源异构数据,融合多途径识别数据(如OCR识别、水牌扫描、门头照识别),通过标准化处理,智能构建运营商中小企业基础信息数据湖,从源头提升数据质量。
通过引入“熵减”理念,构建基于熵、最大熵、均熵的智能算法,量化评估中小企业数据质量,及时查找低质量数据的问题原因并加以解决。同时,构建了中小企业数据质量时序数据库,并在此基础上创建基于熵减的马尔科夫链,建立数据质量状态向量和数据质量状态转移矩阵,用以预测未来几个月的数据质量情况,并对大概率存在数据质量问题的模块进行数据治理。
基于熵减和马尔科夫链的中小企业客户数据治理技术,能够有效地发现数据质量问题、查找原因并解决问题,还能有效预测未来的数据质量情况,切实实现了中小企业大数据价值的最大化,降低了数据治理人力成本,解决了数据治理效率低、数据质量问题定位不准确、解决不及时等问题,助力企业实现降本增效。
参考文献:
[1] 李维刚,钟正,王永强,等.基于时间距离-熵减策略的同步定位与地图构建算法 [J].信息与控制,2023,52(5):660-668+688.
[2] 闫佳和,李红辉,马英,等. 多源异构数据融合关键技术与政务大数据治理体系 [J].计算机科学,2024,51(2):1-14.
[3]黄俊峰,叶滂俊,王敏.基于大数据基础平台的数据治理实践 [J].信息技术与标准化,2022(6):19-23.
[4] 陈璐,郭宇翔,葛丛丛,等. 基于联邦学习的跨源数据错误检测方法 [J].软件学报,2023,34(3):1126-1147.
[5] 于起超,韩旭,马丹璇,等.流式大数据数据清洗系统设计与实现 [J].计算机时代,2021(9):1-5.
[6] 刘鲁文,陈兴荣,何涛.基于马尔科夫链的教学效果评估方法 [J].统计与决策,2014(3):93-94.
[7] 廖普明.基于马尔科夫链状态转移概率矩阵的商品市场状态预测 [J].统计与决策,2015(2):97-99.
[8] 杨海民,潘志松,白玮.时间序列预测方法综述 [J].计算机科学,2019,46(1):21-28.
[9] 张建晋,王韫博,龙明盛,等.面向季节性时空数据的预测式循环网络及其在城市计算中的应用 [J].计算机学报,2020,43(2):286-302.
[10] 郑月彬,朱国魂.基于Twitter数据的时间序列模型在流行性感冒预测中的应用 [J].中国预防医学杂志,2019,20(9):793-798.
作者简介:刘敏(1975—),女,汉族,浙江台州人,工程师,硕士,研究方向:大数据、人工智能;黄倚霄(1978—),男,汉族,广东龙川人,高级工程师,硕士,研究方向:大数据、人工智能;陈智扬(1971—),男,汉族,广东深圳人,高级工程师,硕士,研究方向:大数据、人工智能、网络信息安全;张湛梅(1979—),女,汉族,广东阳春人,正高级工程师,硕士,研究方向:大数据、人工智能。