
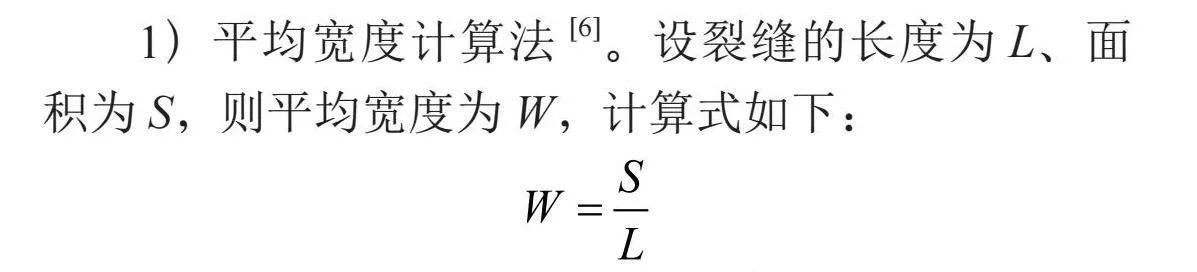



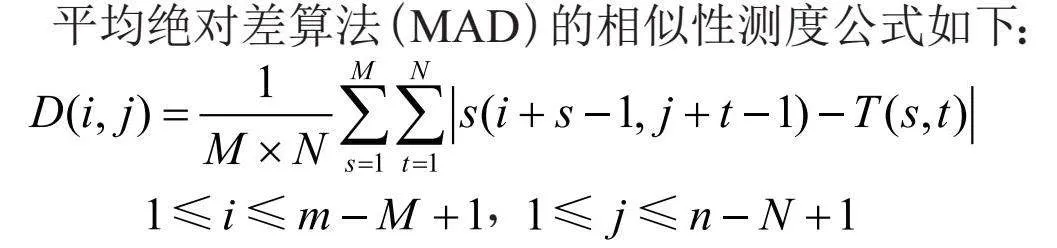





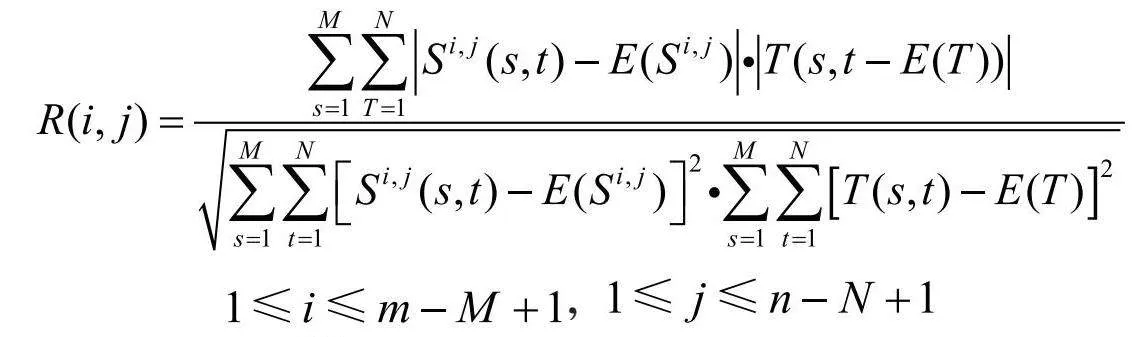





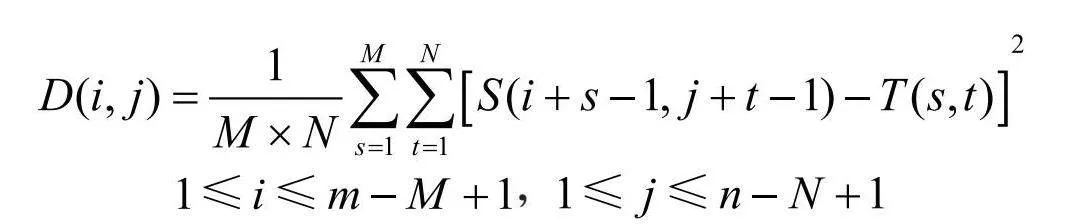




摘" 要:桥梁在道路交通中占据着重要地位。桥梁检测和维护经历了从人工阶段到基于数字图像处理技术的自动检测的转变,如今人工智能技术也被广泛应用于道路桥梁检测中。文章主要综述了数字图像处理技术和机器学习技术在桥梁裂缝检测中的应用,并进行了比较研究。首先,传统的机器学习方法用于道路桥梁裂缝检测时,需要提前对图像进行预处理,包括图像降噪和图像增强。文章对图像降噪和图像增强算法的效率进行了比较。其次,在桥梁检测中,图像分割和拼接是关键步骤,文章对图像拼接算法的效率进行了实验比较。再次,针对裂缝宽度、长度和面积的计算,提出了一种方法,并进行了实验研究。最后,比较了传统机器学习和深度学习在桥梁裂缝检测中的差异。
关键词:桥梁裂缝检测;图像处理;深度学习
中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2025)03-0128-12
Application of Image Processing and Machine Learning in Bridge Crack Detection
JIANG Xiuli, WEN Jinhui, LUAN Shangmin
(North China Institute of Science and Technology, Langfang" 065201, China)
Abstract: Bridges hold an important position in road traffic. The detection and maintenance of bridges have experienced a transformation from the manual stage to the automatic detection based on digital image processing technology. Nowadays, Artificial Intelligence technology is also widely applied in road and bridge detection. This paper mainly reviews the applications of digital image processing technology and Machine Learning technology in bridge crack detection and conducts a comparative study. Firstly, when traditional Machine Learning methods are used for road and bridge crack detection, it is necessary to pre-process the images in advance, including image denoising and image enhancement. This paper compares the efficiencies of image denoising and image enhancement algorithms. Secondly, in bridge detection, image segmentation and splicing are key steps. This paper experimentally compares the efficiencies of image splicing algorithms. Thirdly, a method is proposed for calculating the width, length, and area of cracks, and an experimental study is carried out. Finally, the differences between traditional Machine Learning and Deep Learning in bridge crack detection are compared.
Keywords: bridge crack detection; image processing; Deep Learning
0" 引" 言
根据文献[1],到2022年底,我国的公路桥梁总数已突破103万座,高速铁路桥梁的总长度也超过了1万千米,在综合交通运输体系中发挥着重要作用。这些桥梁大都是混凝土结构,而裂缝是桥梁健康检测的重要内容之一[2],其检测的手段经历了从手工阶段到基于数字化手段的自动检测阶段。
人工检测受到检测人员和检测仪器的影响,导致检测结果差别大、难以量化,并且检测精准度低,检测效率也低,使其在经济性、效率、精度和数据管理等方面无法满足对大量桥梁裂缝检测的需求。
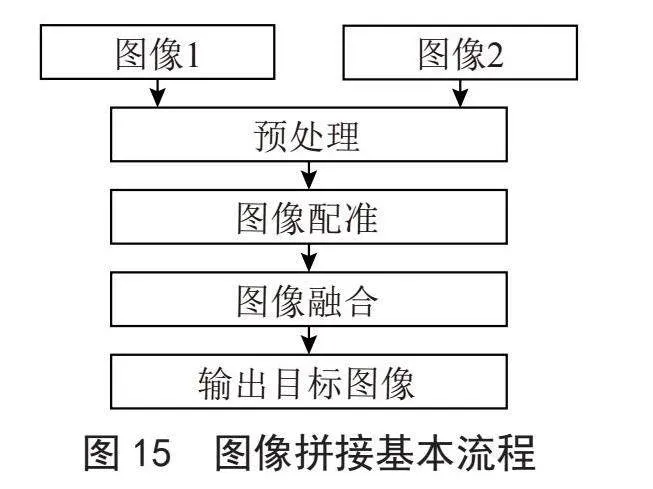
随着图像数字化的发展,人们尝试桥梁裂缝的自动化检测方法。特别是随着图像数字化的发展和道路桥梁里程的快速增长,人们寻找桥梁裂缝检测的自动化方法的愿望更加迫切。随着人工智能之机器学习技术的应用,基于图像数字化的智能化方法出现在了桥梁裂缝检测中,这种方法的步骤如图1所示。
文献[1]对图像采集的方法和设备已经进行了详细综述,例如攀爬机器人、无人机等检测设备。
桥梁表面光照的不均匀、水渍和污点等会影响桥梁裂缝的识别,就需要对图像进行降噪处理,以减少这些因素的影响。为了更好地进行裂缝的识别,最好能把裂缝进行增强,这可以使用图像增强技术来进行处理。对于裂缝较大的情况,在一张图里面不可能包含整个裂缝,这时候就需要采用图像拼接技术,拼接出整幅图像,这就涉及了图像的拼接和配准。所以,在裂缝识别中,涉及了图像去噪、增强、拼接和配准。
在对图像预处理完之后,接着就是采用机器学习方法来对桥梁裂缝进行识别,这其中涉及了传统的机器学习方法和最近兴起的深度机器学习方法。
传统机器学习算法在裂缝检测上的应用主要包括决策树、主成分分析及K-近邻算法等。王睿等人[3]使用RBF-SVM算法构建了自动判别模型,通过比较使用全部特征和部分特征作为输入参数的工况结果,证明该模型有很好地适应能力,并能够高效地进行裂缝识别;Shi等人[4]提出了一种利用随机结构化森林技术的裂缝检测框架,改进了对强度不均匀裂缝的表示,提高了检测精度;廖延娜等人[5]改进了YOLOv3网络,提高了对小裂缝的检测精度。并提出通过聚类算法确定适用于裂缝特征的先验框尺寸,利用生成对抗网络扩增数据集。结果表明,在相同数据集和迭代次数下,改进后的YOLOv3网络比原YOLOv3的裂缝检测精度提高了0.013 7。
Adhikari等人[6]结合裂纹量化、变化检测、神经网络和3D可视化等技术,开发了一种缺陷数字化表示的集成模型,可实现混凝土裂纹长度评估。Kim等人[7]对具有弯曲桥面和不同桥墩高度的桥梁,提出了一种基于深度学习的桥梁部件自动识别方法,该方法减少了处理背景区域点云预处理的耗时。Lee等人[8]提出了一个基于图的分层DGCNN模型,该模型在相邻点总数保持不变的情况下逐步考虑相邻点来获得局部特征,用于准确表示具有电线杆的铁路桥梁,提高了电杆约3%的召回率和交并比。
目前,图像分类和目标检测算法尚无法独立完成裂缝的提取,需要结合图像分割算法才能实现。全卷积神经网络能够实现像素级的图像分割,并且在多个领域有广泛应用。随着相机等硬件设备的提升,裂缝的像素级分割已经成为未来裂缝识别的发展趋势[9]。近年来,Transformer在计算机视觉领域取得了迅速发展,因此其在裂缝检测中的应用前景同样值得关注。
目标检测算法分为单阶段目标检测算法和双阶段目标检测算法。其中单阶段目标检测算法是一种端到端的方法,常包括一个神经网络模型,直接从图像中预测出目标类别和位置信息,无须额外的区域提议生成过程。常见单阶段算法有YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)。它们设计简单高效,YOLO通过网格单元预测目标信息,而SSD在不同特征图尺度上实现多尺寸目标检测。双阶段目标检测算法通过生成候选区域和对这些区域进行分类与回归,来实现高精度的目标检测。常见的算法如R-CNN、Fast R-CNN和Faster R-CNN,它们通过不同方式进行区域提议和目标分类与定位,通常具有更高的准确性,但速度可能不如单阶段算法。图像分割算法的核心在于对每个像素进行分类,如FCN、U-Net和DeepLabv3+等。物体检测的进步往往需要在速度与精度之间找到平衡,因为提高精度通常会增加计算量,因此如何权衡这两者是一个重要的研究方向。
裂缝的几何特征主要包括长度、宽度和面积等,裂缝的这些几何特征不仅有助于了解现有的破坏情况,还能揭示潜在的破坏机理。因此,准确测量和分析这些特征对于结构健康监测和维护决策至关重要。
裂缝的长度、宽度、面积的测量是项很重要的工作,因为裂缝长度和宽度揭示了结构破坏程度。裂缝长度的计算通常基于骨架线方法。这种方法首先对裂缝进行骨架化处理,将裂缝视为由一系列单个像素点组成的骨架线。然后,通过对这些单个像素点进行累加求和来确定裂缝的总长度。具体的计算方法有基于欧氏距离计算法、基于链码计算法、基于骨架线计算法等。裂缝的宽度检测是常见的有平均宽度计算法、基于中心线的裂缝宽度法、基于内切圆的裂缝宽度法、基于边缘线最小距离的裂缝宽度法、基于灰度值的裂缝宽度法、基于边缘梯度的裂缝宽度法。这些内容在文献[1]中已经进行了综述。裂缝面积对裂缝的分析具有重要意义,它直观反映了裂缝的大小,裂缝面积的计算主要有像素当量法和近似估计法。像素当量法采用公式A = Nμ2来计算裂缝的面积,其中N为区域所占像素个数,μ为像素当量,为图像对应的实际尺寸与图像相应方向上像素点数的比值。有些裂缝成网状,有的裂缝是交叉的,对这种情况,像素当量法就不适用了,人们提出了用裂缝外接多边形的面积近似代替网状裂缝和交叉裂缝的面积,多边形有凸多边形,也有凹多边形,我们也提出了凹多边形和凸多边形面积的计算方法[10]。
1" 桥梁裂缝检测中的图像处理技术比较研究
这一节我们讨论桥梁裂缝检测中涉及的数字图像处理技术,主要有去噪、增强、拼接和配准。
1.1" 图像降噪
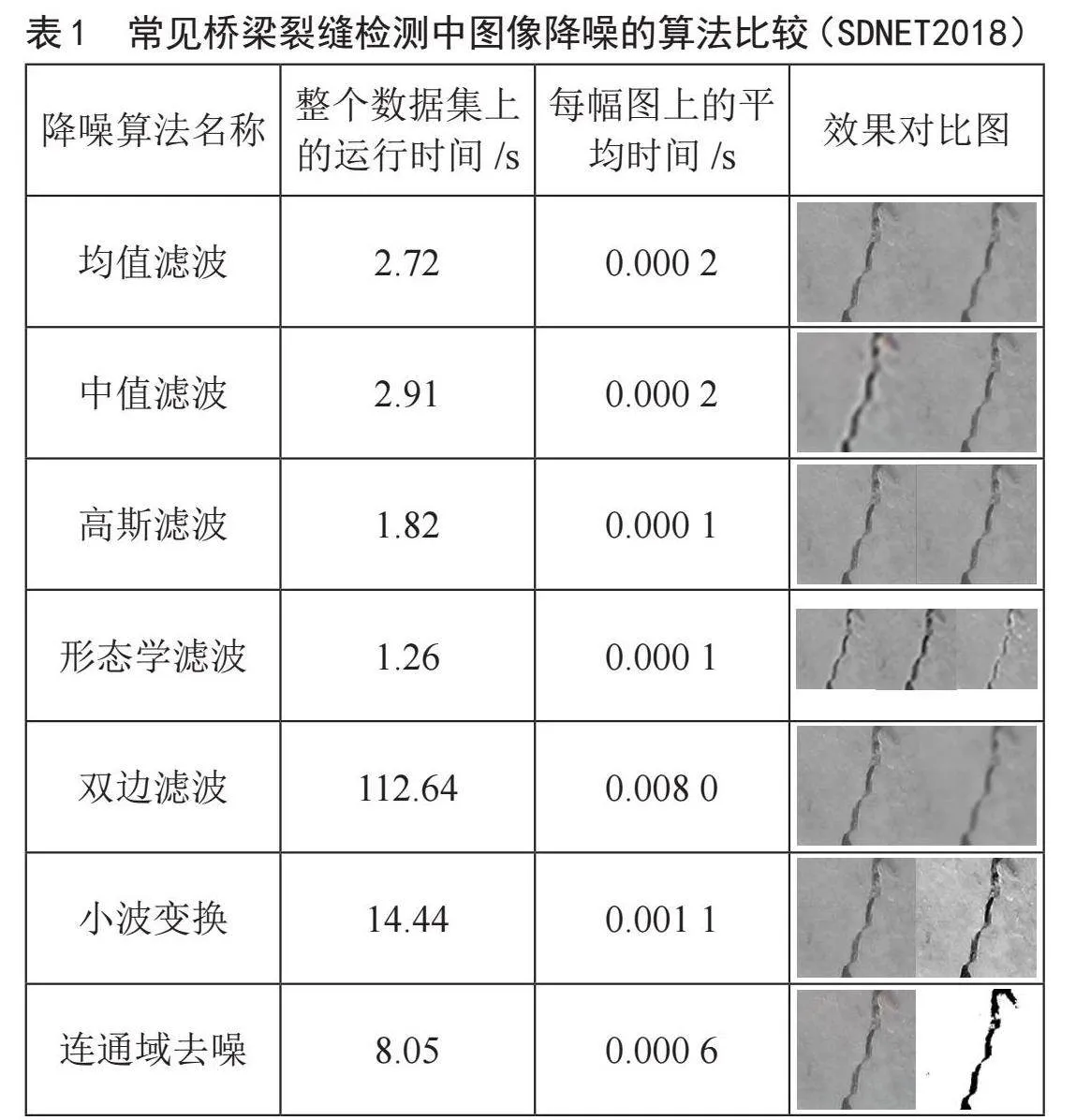
桥梁裂缝检索的一个重要步骤就是预处理,在预处理的步骤中,降噪是图像预处理中的关键步骤,许多学者已经对不同的降噪方法在混凝土表面图像上的效果进行了对比研究[11]。在实验过程中需要进行数据集的选择,并且数据集的选择也很重要,我们的实验选择SDNET2018[12]作为数据集,它包含13 620余张带注释的有裂缝和无裂缝的混凝土桥面图像,用于训练、验证和基准测试基于人工智能的混凝土裂缝检测算法。下面我们在数据集上对一些降噪算法进行实验对比。具体数据如表1所示。
均值滤波通过计算像素周围邻域内像素值的平均值来平滑图像。在这种滤波方法中,每个像素的值被替换为其周围邻域内像素值的平均值,以消除噪声并减少图像中的突变。均值滤波通常用于去除轻微的高斯噪声或均匀分布噪声,但可能会导致图像细节的模糊。对数据集中的图片进行均值滤波,整个数据集上用时2.72秒,平均每张用时0.000 2秒。
中值滤波是将每个像素点的值替换为它周围像素值的中值。与均值滤波不同,中值滤波在选择替换像素值时取周围像素值的中间值,而不是平均值。这使得中值滤波在处理图像中的非常大噪声或异常值时表现更好,因为它能有效地去除极端值的影响,同时保留图像的边缘信息和细节。中值滤波通常用于去除椒盐噪声和脉冲噪声等形式的噪声。对数据集中的图片进行中值滤波,整个数据集上总共用时2.91秒,每张图片的平均用时为0.000 2秒。
高斯滤波使用高斯函数作为权重核来对图像进行卷积操作,以模糊图像并减少图像中像素值的变化。在高斯滤波中,每个像素的新值是其周围像素值的加权平均,其中权值由高斯函数决定,距离中心像素越远的像素拥有更小的权值。这种滤波技术可以有效地平滑图像,并且在处理高斯噪声或其他连续分布的噪声时表现良好。高斯滤波通常用于保持图像的整体特征和细节,同时降低噪声水平。对数据集中的图片进行高斯滤波,总共用时为1.82秒,每幅图片的平均用时0.000 1秒。
形态学滤波是一种基于形态学操作如腐蚀和膨胀的图像处理技术,通过对图像进行腐蚀和膨胀操作来去除噪声、填充空洞、连接分离的图像部分以及检测边缘等功能。这种滤波方法在数字图像处理中有广泛的应用,特别在二值图像处理、图像分割和特征提取方面发挥着重要作用。这种方法可以在不改变物体形状的情况下平滑图像并去除一些小的像素点,但对于较大的噪声则难以有效去除。对数据集中的图片进行形态学滤波,总共用时为1.26秒,每幅图片的平均用时0.000 1秒。
双边滤波考虑了像素之间的空间距离和像素值之间的相似度,从而在滤波过程中综合考虑了空间信息和像素值之间的关系,旨在平滑图像的同时保留图像的边缘和细节信息。双边滤波在减少噪声的同时能够保持图像的清晰度,并避免边缘模糊化的问题,因此在图像降噪和平滑处理中得到广泛应用。但是在去噪的同时,会移除图像纹理,并且会保留图像中的阴影。对数据集中的图片进行双边滤波,总共用时为112.64秒,每幅图片平均用时0.008 3秒。
小波变换用于分析信号的频率特性和时域特征,通过不同尺度和频率的小波基函数对信号进行分解和重构。其优点包括可以在时频域上定位信号特征、提供多尺度分析、在压缩和去噪方面表现优良;然而,小波变换会引入一些边缘效应,基函数选择需要谨慎,同时计算复杂度较高,需要选择合适的小波基和参数以用于不同应用场景。对数据集中的图片进行小波变换,总共用时为14.44秒,每幅图片平均用时0.001 1秒。
连通域去噪通过识别和过滤图像中的小区域(连通域)去除噪声。其优点包括能够有效保留图像边缘和纹理信息、简单易理解、适用于各种噪声类型;然而连通域去噪可能会影响图像的细节,对于大面积噪声或复杂噪声可能效果不佳,且在参数设置和处理效率方面需谨慎考虑。对数据集中的图片进行连通域去噪,总共用时为8.05秒,每幅图像的用时为0.000 6秒。
综上所述,形态学滤波在整个数据集上的运行时间是最快的,双边滤波在整个数据集上的运行时间是最慢的,连通域去噪的图像增强效果是最明显的。
1.2" 图像增强
图像增强是通过一定的途径和手段来改善图像质量,这些技术包括图像锐化、图像去噪、图像对比度增强以及色彩增强等。图像增强增强在桥梁裂缝检测中有着广泛应用,图像增强有针对空间域的算法,也有针对频率域的算法。具体的有空间域的灰度变换、直方图方法和图像锐化算法,频率域的低通滤波和高通滤波等滤波,以及用于光线处理的Mask匀光法。下面我们实验比较的方法主要有空域的灰度变换、直方图方法和空域滤波。
1.2.1" 灰度变换
灰度变换是一种用于改善图像视觉效果的图像处理技术,它通过对图像中每个像素的灰度值进行特定运算来改变图像的灰度分布,从而增强图像的对比度,包括有线性变换、对数变换和幂律(伽马)变换等。
一般的线性变换方程为y = kx + b,其中,y是变换后的灰度值,x是变换前的灰度值。
当k>1,则线性变换会加大灰度之间的对比度,当0<k<1则会减小对比度,这个是直线方程的特点。通过改变这k和b两个变量的值,来调整图像变换的结果。当k = -1,b = l-1时,y = -x + l-1,其中l为灰度的取值范围,也就是灰度的取值范围为[0,l-1],这个称为灰度反转。
有时候需要对不同区间里的灰度值做不同的线性变换,这就是分段线性变换。分段线性变换可以将感兴趣的区域与别的区域对比度增大。
对于非线性变换,主要有对数变换和幂律(伽马)变换。对数变换的公式为y = clog(x + 1),其中c为常数。通过该公式可以看出,它可以拉伸较窄范围的低灰度值,同时压缩较宽范围的高灰度值;也可以用来扩展图像中的暗像素值,同时压缩亮像素值。幂律(伽马)变换的公式为y = cxγ,其中c为常数。γ值小于1时,会拉伸图像中灰度级较低的区域,同时会压缩灰度级较高的部分;γ值大于1时,会拉伸图像中灰度级较高的区域,同时会压缩灰度级较低的部分。多用在图像整体偏暗,或者需要压缩中高以下的大部分的灰度级的情况。图2展示了三个灰度变换的结果。
1.2.2" 直方图均衡化
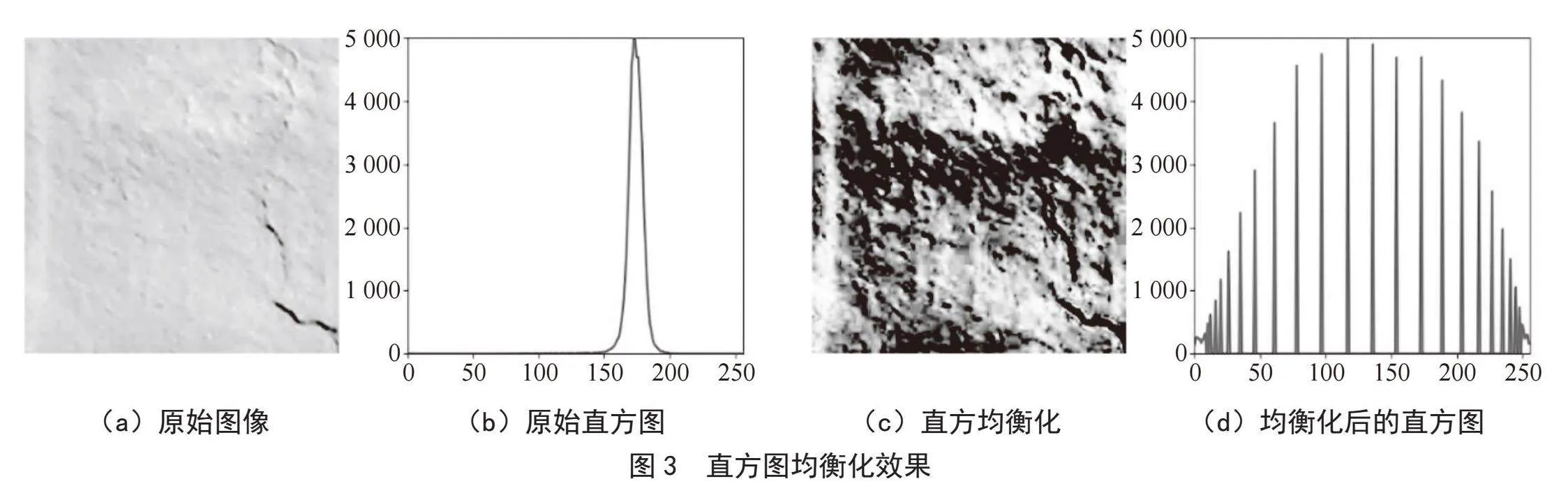
直方图均衡化通过对图像的像素值累积分布进行调整,使得图像的直方图变得更均匀,增强了图像的细节和对比度,从而改善图像的视觉效果,主要用于增强动态范围较小的图像的对比度。我们利用直方图均衡化作了实验对比,结果如图3所示。
1.2.3" 图像锐化
图像锐化是一种突出和加强图像中景物的边缘和轮廓的技术,使图像变得更加清晰。锐化滤波器包括拉普拉斯算子、Prewitt算子、Roberts算子。
拉普拉斯算子是一个二阶微分算子,常用于图像增强和边缘提取。拉普拉斯算子如下所示:
图像处理中,其离散形式如下所示:
在求出二阶偏导数后,再利用如下公式得到新的灰度值:
拉普拉斯算子通过计算邻域中心像素在四个方向或八个方向的梯度,并将这些梯度相加,以判断中心像素灰度与邻域其他像素灰度的关系。最终,根据梯度运算的结果调整像素灰度。拉普拉斯算子的模板分为四邻域和八邻域:四邻域计算中心像素在四个方向的梯度,而八邻域则计算在八个方向的梯度,其模板分别如下:
和
或者:
和
图4为拉普拉斯锐化的结果。
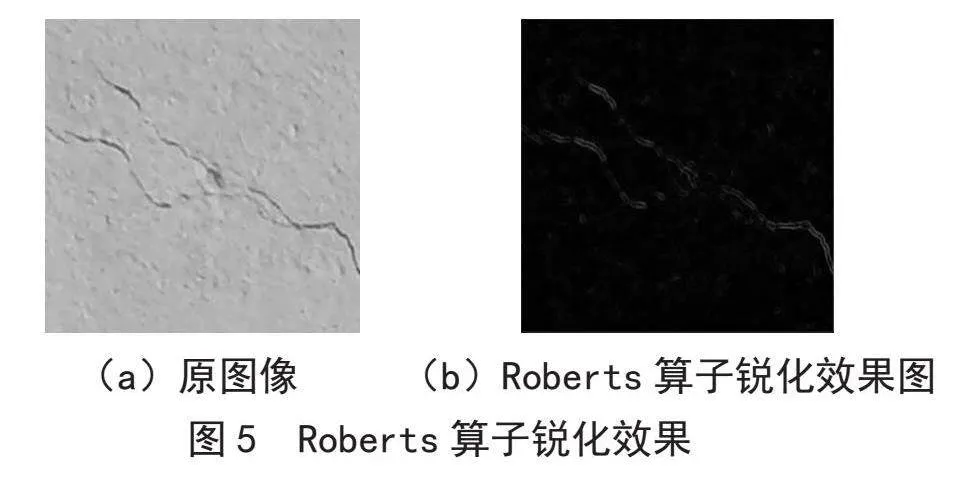
Roberts算子是基于交叉差分的梯度算法,通过局部差分计算检测边缘线条。通常用于处理具有陡峭的低噪声图像,采用2×2的模板求像素的值,如下所示:
和灰度值用如下公式计算:
有的近似为如下公式:
从上述计算式看出来,Roberts算法处理效果更理想的情况是当图像边缘接近于正45度或负45度。其缺点在于边缘定位不够精确,导致提取出的边缘线条显得较为粗糙。图5是Roberts算子锐化的结果。
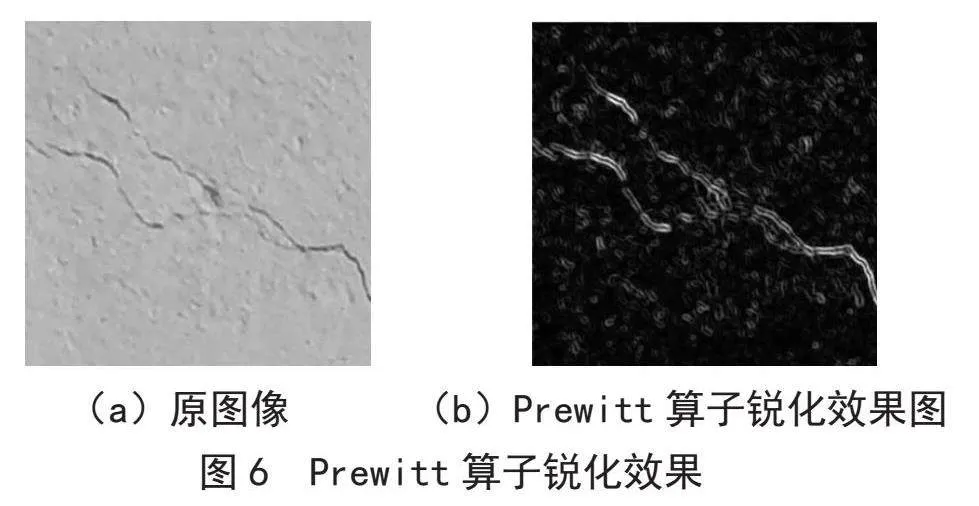
Prewitt算子利用特定区域内像素灰度值产生的差分实现边缘检测,采用3×3模板对区域内的像素值进行计算,分别如下所示:
和
图6是Prewitt算子锐化的结果。
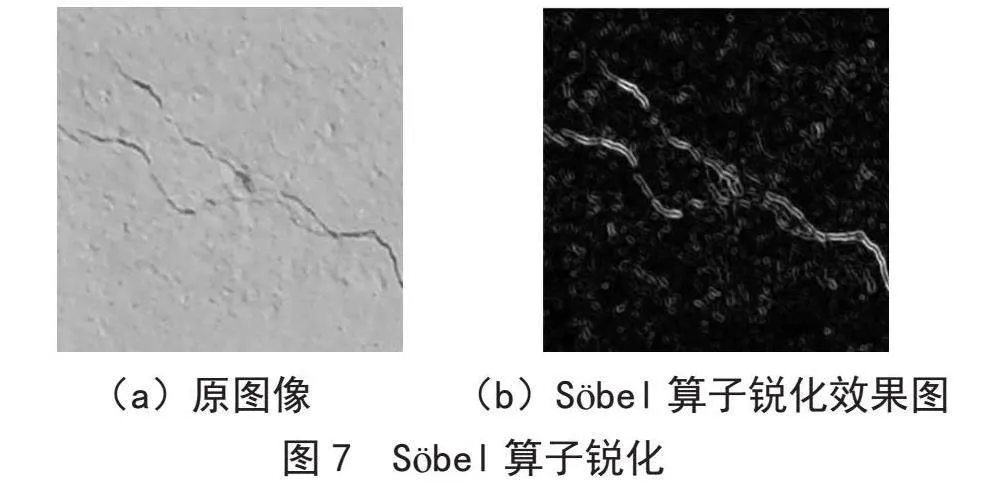
Söbel算子是一种边缘检测方法,通过计算像素点与其上下和左右邻点灰度的加权差异来检测边缘。在边缘处,这些差异达到极值,从而提供了较为精确的边缘方向信息。
和
由于Söbel算子结合了高斯平滑和微分运算,因此对噪声具有较强的抗干扰能力。这使得它特别适用于噪声较多或灰度渐变明显的图像。图7是Söbel算子锐化后的结果。
1.3nbsp; 光照不均匀的处理方法
光照不均匀问题是图像处理中的一个重要问题,在计算机视觉中也是一个普遍关注的问题。现实中,会遇到光照不足和光照不均匀的情况,在这种情况下获得的图像需要进行光线的处理,针对该问题,人们提出了很多种解决的途径。
Mask匀光法[13]不仅用于光线的调整,还用于遥感影像恢复技术[14],假设f(x,y)是不均匀图像,h(x,y)是匀光图像,g(x,y)是反应光照亮度的背景图像,它们之间的关系可以用如下公式表示:
根据上式,原始图像减去背景图像就得到了匀光图像:
对于一般情况,还会增加一个偏移量,使得匀光图像的灰度级在合理的分布范围内,得到如下公式:
在频率域中,低频信息反映了亮度的变化;高频信息反映了图像的纹理。由此可以通过傅里叶变换把图像从空间域转换为频率域,再通过低通滤波,就得到了背景图像。一般取低通滤波后图像g(x,y)的均值作为背景图像。
后来,人们对Mask的方法也进行了改进,例如引进了自适应技术[15]等。还有其他一些光线不均匀的处理方法,例如均值法[16]和基于深度机器学习的方法[17]等。
1.4" 图像配准
图像配准是将不同来源或不同时间拍摄的图像对齐到同一坐标系中的过程,旨在使相同特征或对象在空间上对齐。其关键步骤包括特征提取、特征匹配和图像变换。在医学影像、遥感、图像拼接和计算机视觉等方向有所应用。
配准技术是先从图像中提取关键特征点,然后通过相似性度量匹配这些特征点,接着计算出图像之间的空间变换参数,最后应用这些参数将图像对齐到同一坐标系中。每一步都对最终的配准效果至关重要,特别是特征提取和匹配的准确性直接影响到图像的对齐精度。图像配准的方法大致分为基于灰度和模板、基于特征和基于域变换这三类,下面介绍基于灰度和模板的方法。
基于灰度和模板主要方法有平均绝对差算法(MAD)、绝对误差和算法(SAD)、误差平方和算法(SSD)、平均误差平方和算法(MSD)、归一化积相关算法(NCC)、序贯相似性检测算法(SSDA)和Hadamard变换算法(SATD)等算法。这类算法中的绝大多数算法的基本思想就是:在搜索图S中,从(i,j)为左上角开始,取M×N大小的子图,通过计算模板与图像之间的相似度,遍历整个图像区域以比较所有可能的子图,最终选择与模板最相似的子图作为最佳匹配结果。这一过程涉及对每个子图进行相似度计算,以确定哪个子图最准确地匹配了模板,从而实现精确的图像配准或目标检测。这些算法的不同只是在相似度的计算上不一样。后面用S(x,y)和T(x,y)表示图像S和图像T相应点的灰度值。
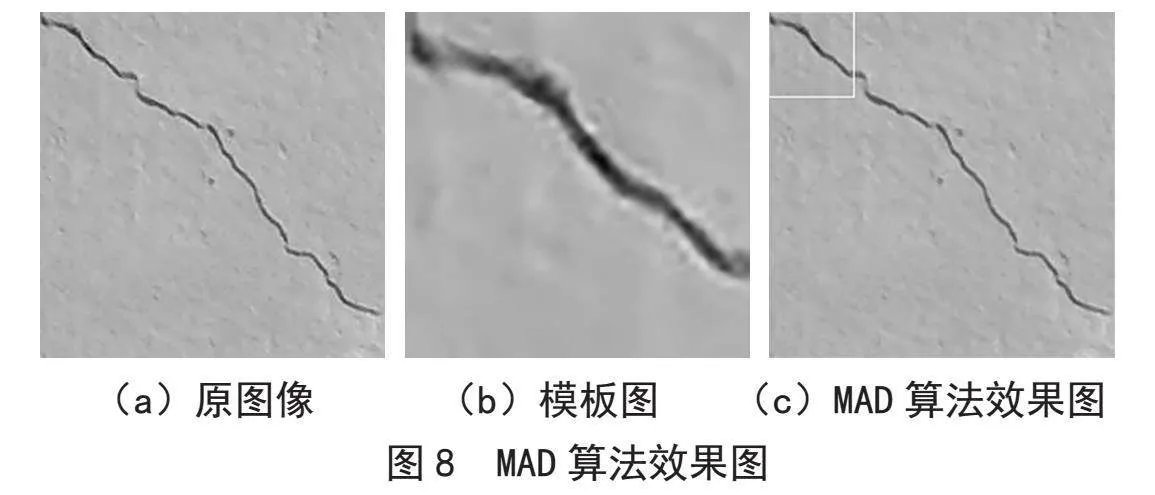
平均绝对差算法(MAD)的相似性测度公式如下:
,显然,平均绝对差D(i,j)越小,说明图像与模板越相似,因此只需找到最小的D(i,j)值,即可确定最佳的子图位置,也称为曼哈顿距离。图8是MAD算法的结果。
绝对误差和算法(SAD)采用的绝对距离来定义相似度,计算式如下:
,绝对差D(i,j)越小,表示图像与模板越相似,因此通过寻找最小的D(i,j)值,可以确定最佳的子图位置。图9是SAD算法的结果。
误差平方和算法(SSD)采用绝对距离来定义相似度,计算式如下:
,绝对差D(i,j)越小,意味着图像与模板的相似度越高,因此,只需找到最小的D(i,j)值,即可确定最匹配的子图位置。图10是SSD算法的结果。
平均误差平方和算法(MSD)是一种用于模式匹配的算法,该算法除了在距离的计算上和MAD不一样之外,其他都一样。MSD算法采用的绝对距离,定义如下:
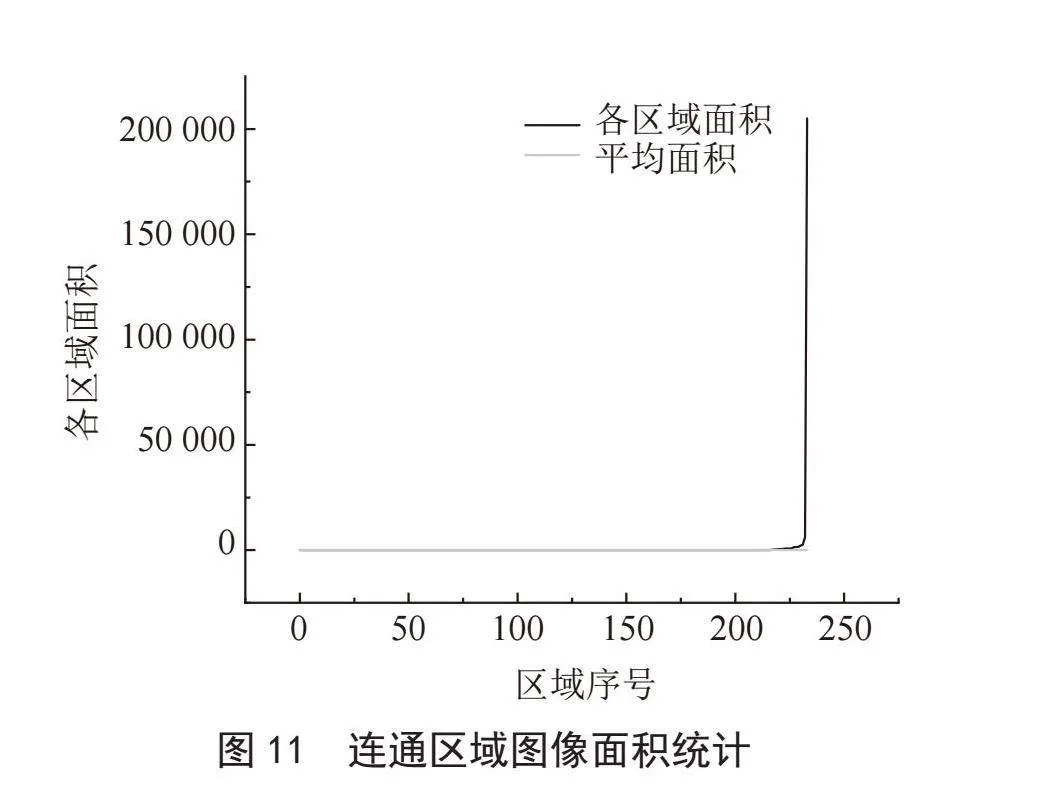
,绝对差D(i,j)越小,表明图像与模板之间的相似度越高,因此只需寻找D(i,j)的最小值,就可以确定最匹配的子图位置。图11是MSD算法的结果。
归一化积相关算法(NCC)是模板匹配中较为常见的互相关计算方法,与上面算法相似,用归一化的相关性度量公式来计算二者之间的匹配程度,计算式如下:
,
其中,表示S的(i,j)坐标开始的和模板一样大小的子图,E()和E(T)表示(i,j)处子图、模板的平均灰度值。
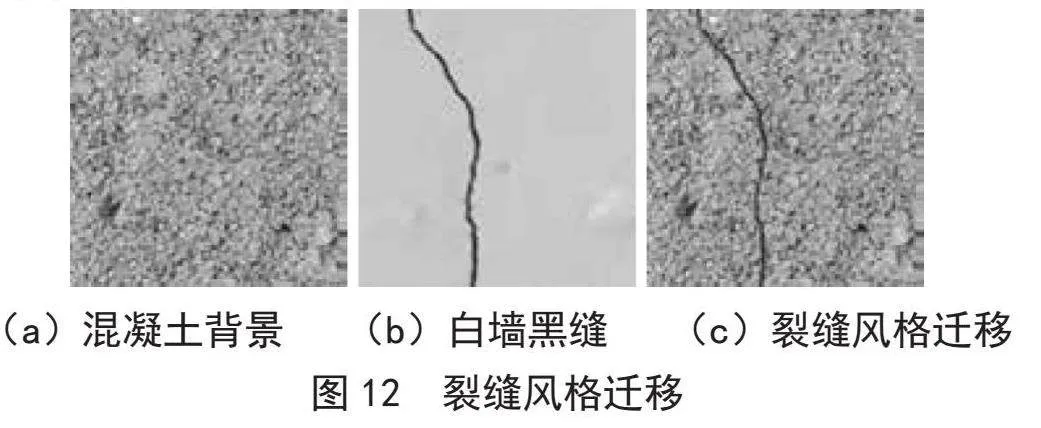
绝对差D(i,j)越小,说明两个子图的相似度越高。因此,只需寻找最小的D(i,j)来确定最佳的子图匹配位置即可。图12是NCC算法的结果。
序贯相似性检测算法(SSDA)如下定义一个绝对误差:
S就是原图,Si,j表示左上角起始位置为(i,j)的搜索图中的一个子图,改为E(Si,j)和E(T )分别表示子图和模板的均值,,。S是m×n的图像,T是M×N的模板。计算每一个子图像中像素点与模板中的像素点的绝对误差累积值,当该值大于设定阈值时,便可放弃计算该子图,进入下一子图的计算,并存下超出阈值时的累加次数。
实际上,绝对误差就是子图与模板图各自去掉其均值后,对应位置之差的绝对值。图13是SSDA算法的结果。
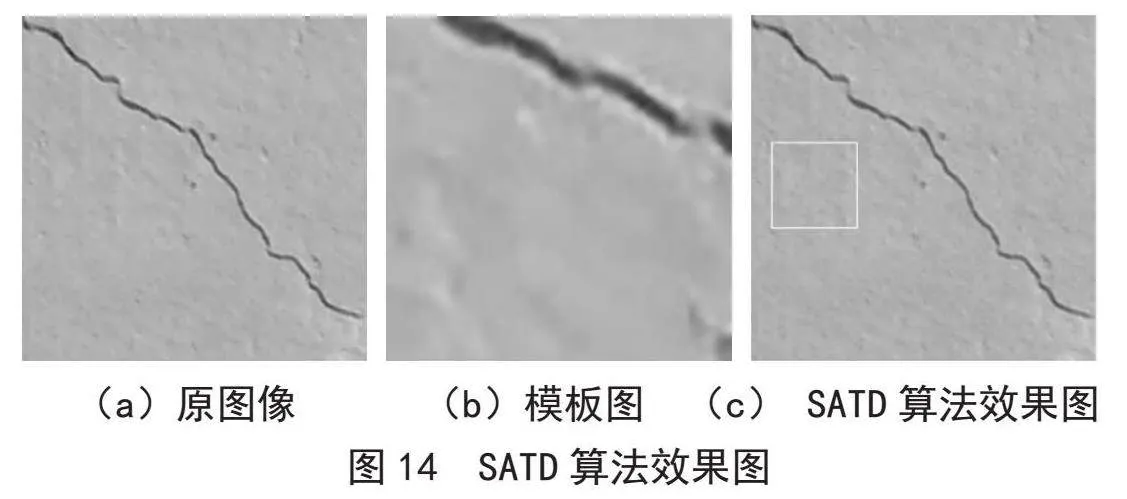
Hadamard变换算法(SATD)在信号处理、图像处理和机器学习等领域有着广泛的应用,它是经Hadamard变换再对绝对值求和算法。Hadamard变换等价于把原图像Q矩阵左右分别乘以一个Hadamard变换矩阵H。其中,Hardamard变换矩阵H的元素都是1或-1,是一个正交矩阵,可以由MATLAB中的Hadamard(n)函数生成,n表示n阶方阵。图14是SATD算法的结果。
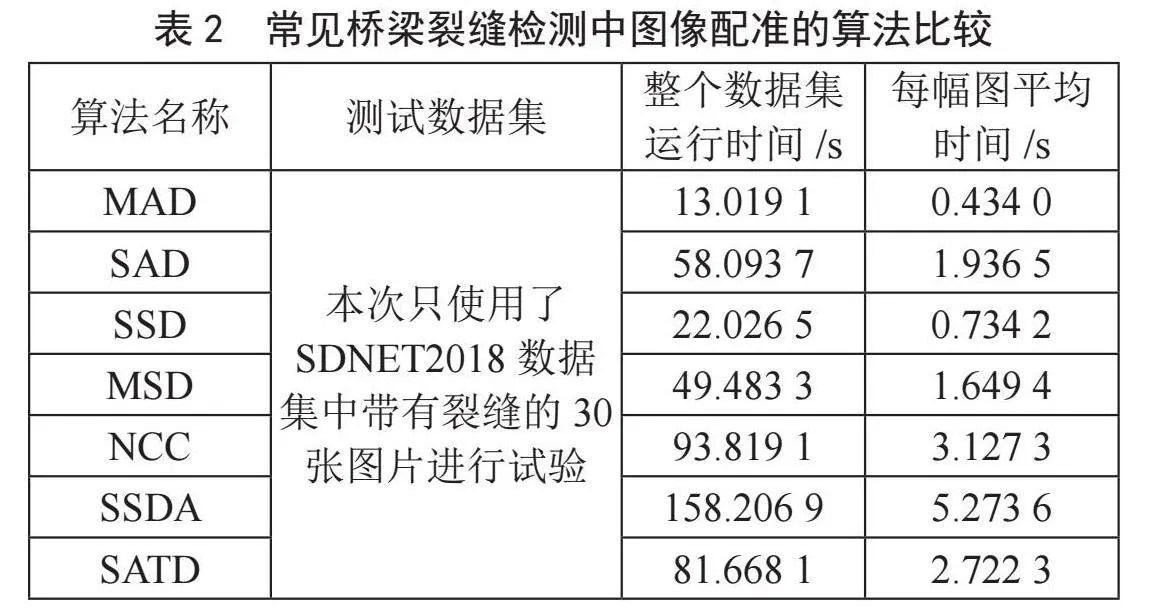
表2给出了以上几种算法运行效率的比较结果。
根据以上数据可以看出,平均绝对差算法在整个数据集上的运行时间是最快的,序贯相似性检测算法在整个数据集上的运行时间是最慢的。
1.5" 图像拼接
现代的数字技术已经可以让人们拍摄多张相邻的图像,并合成一张,以得到他们所期望的图像,这就是图像拼接(Image Stitching)技术的应用之一。图像拼接技术是一种将两张或多张有重叠区域的图像合并成一幅连续且无缝的图像的技术,这些图像可能是在不同时间里、从不同视角或者从不同传感器获得的。图像拼接主要用于计算机视觉、医学成像和目标自动识别等领域。图像拼接的基本流程如图15所示。
图像拼接的算法很多,图像拼接的质量主要依赖于图像的配准程度,因此根据不同的图像匹配方式将图像拼接的算法分为以下两种。
1.5.1" 基于区域相关的拼接算法
该算法是一种常见的传统方法,它通过比较待拼接图像的灰度值,逐块对比待配准图像与参考图像中相同尺寸的区域。这样可以确定待拼接图像中重叠部分的范围和位置,从而完成图像的拼接,生成一幅完整的图像。例如,对于图16中的前两幅图,我们可以采用传统的MAD配准算法进行配准,然后进行融合形成图像。
另外,也可以通过快速傅里叶变换将图像从空间域转换到频域,再进行配准。对于位移较大的图像,首先可以校正图像的旋转角度,然后建立两幅图像之间的映射关系。
1.5.2" 基于特征相关拼接算法
基于特征的配准方法首先从图像中提取特征点,然后以这些特征点为依据,搜索和匹配图像重叠区域中的对应特征。这类拼接算法通常具有较高的健壮性和鲁棒性[18]。
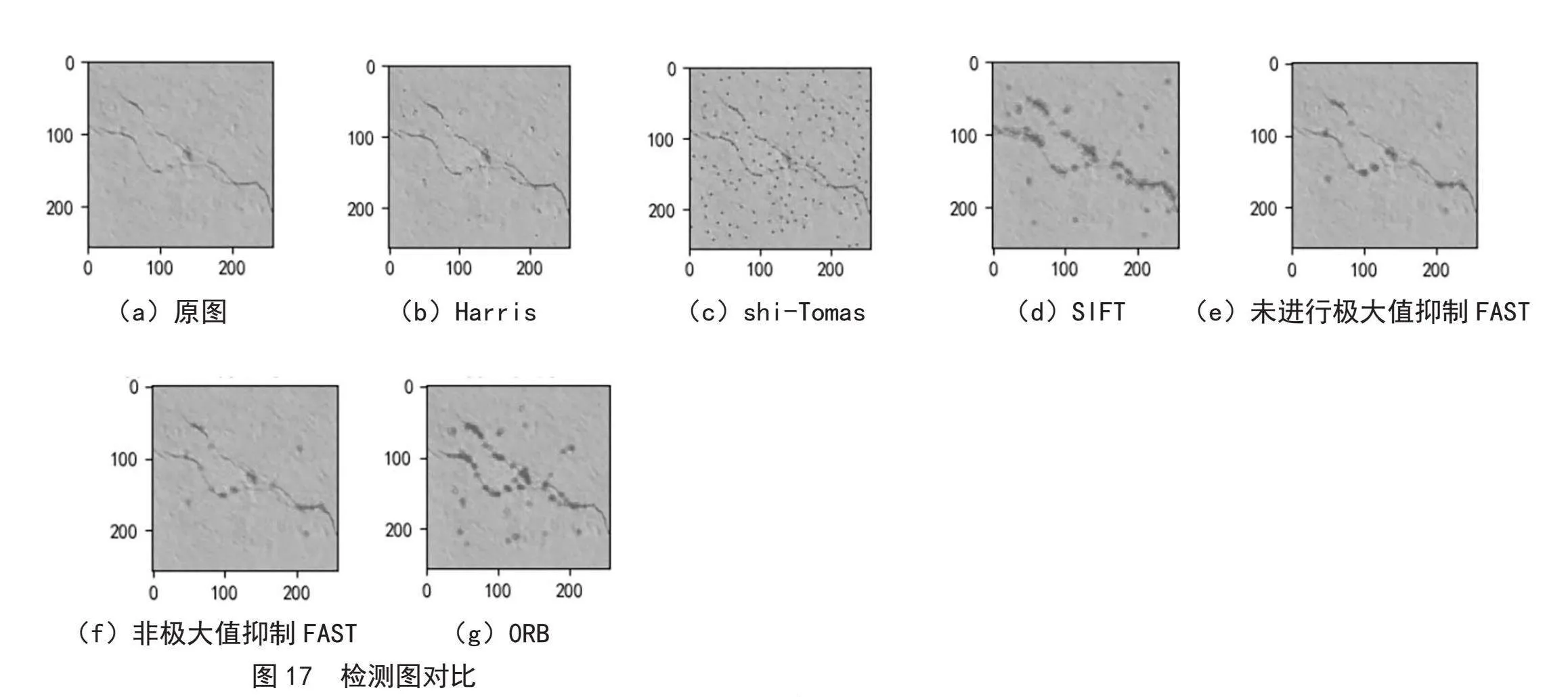
特征是要匹配的两个输入图像中的元素,例如点、线和面等,光线的强弱等,在众特征中,角点特征比较稳定,并且能给图像提供更好的特征匹配,所以在配准中采用角点匹配的例子很多。角点检测算法有Harris角点检测算法、SIFT特征点检测算法、FAST角点检测算法、SURF特征点检测算法等,我们可以自己实现这些算法,同样,很多程序设计语言中也提供了包含这些算法的程序包,例如,OpenCV。
Harris角点检测的思想是通过图像的局部小窗口观察图像,角点的特征是窗口沿任意方向移动都会导致图像灰度的明显变化,cv2中的函数cornerHarris()实现了Harris检测算法,其原型为cv.cornerHarris(img,blockSize,ksize,k),其中,参数img的数据类型为float32的输入图像,blockSize是角点检测中要考虑的领域大小,ksize是sobel卷积核,k是角点检测中的自由参数取值范围为[0.04,0.06]。因为k是一个经验值,不好设置,人们又对Harris角点检测算法进行了改进,称为shi-Tomas算法,其原型为goodFeaturesToTrack(image, maxcorners, qualityLevel, minDistance),参数image是输入的灰度图像,maxCorners是获取角点数的数目,qualityLevel是最低可接受的角点质量水平,在0~1之间,minDistance是角点之间的最小欧氏距离,避免得到相邻特征点;返回corners是搜索到的符合条件的角点的集合。
Harris角点检测中,对图像缩放后,原来的角点可能会消失了,为了解决这个问题,人们提出了SIFT算法。在OpenCV中使用该算法进行角点检测的步骤为:
1)创建SIFT对象sift=cv2.SIFT_create()。
2)进行检测kp=sift.detect(img , mask),其中,mask感兴趣区域,默认None。
3)绘制关键点drawKeypoints(gray , kp , img),其中,img是要绘制的图片。
SIFT的速度不理想,人们对此进行了改进,提出了SURF算法,因为知识产权问题,OpenCV2中已经不再支持该算法了。
FAST角点检测算法(Features from Accelerated Segment Test)的思想是:若一个像素周围有一定数量的像素与该点像素不同,则认为其为角点。
ORM(Oriented FAST and Rotated BRIEF)算法,使用OpenCV中该算法的实现来进行角点检测时首先要用函数cv.ORB_create(nfeatures)实例化一个ORM对象,其中参数nfeatures是特征点的最大数量,返回一个ORB对象;再利用orb.detectAndCompute(gray,None)检测关键点并计算,参数gray是输入的灰度图像,返回值包含关键点的信息的kp,例如位置,尺度,方向等,以及 关键点描述符des,包含每个关键点BRIEF特征向量,二进制字符;利用cv.drawKeypoints(image,keypoints,outputimage,flags)将关键点绘制在图像上。图17就是以上算法的检测实例的展示。
上述特征点的检测算法也可以用于图像拼接,图18就是用SIFT算法实现的图像拼接。
2" 裂缝的识别和分割
裂缝的识别和分割是计算机视觉中的重要任务,旨在从图像中自动检测和精确分离裂缝区域。裂缝识别通过图像预处理和特征提取,自动识别潜在的裂缝区域;而裂缝分割则进一步通过图像分割和边界检测,将裂缝区域与背景分离,优化裂缝的边界和形状。这些技术在结构健康监测、建筑维护等领域中至关重要。传统机器学习按照数据的使用方式可以分为3大类:监督学习、无监督学习和强化学习。深度学习通过构建深层神经网络来学习复杂的知识,是当前裂缝检测与分割领域的主要算法,并且得到了广泛应用。
2.1" 传统机器学习算法
在机器学习领域里,虽然越来越多的学者都专注于深度学习算法,但传统机器学习算法仍具有重要的地位。传统机器学习算法不涉及深度神经网络,它是从数据中提取特征,并用各种传统机器学习算法进行训练模型和做出预测,传统机器学习算法包括线性回归、逻辑回归、决策树、随机森林、支持向量机(SVM)、聚类算法和K-最近邻算法(KNN)等算法。
K-means聚类算法是传统机器学习中的无监督学习算法,该算法是将数据集中的n个对象划分为k个聚类,使得每个对象到其所属聚类的均值点的距离之和最小。Yu等人[19]引入K-means聚类算法生成与损伤大小相适配的改进锚点,该方法使得混凝土裂缝、剥落和外露钢筋这三种常见损伤类型的平均识别准确率达到了84.55%。
KNN算法是根据样本在特征空间中的距离找到其最近的k个已标记的数据点,用于分类和回归。Parisi等人[20]使用有限元模型生成了具有不同损坏场景的钢桁架桥的应变数据,通过KNN算法和动态时间规整算法从这些应变数据中选择关键特征,并将这些特征输入到1DCNN中进行损伤识别,该方法的损伤识别准确率达到了93%。
决策树是基于树结构进行决策的分类模型,在构建决策树时,算法会根据数据的特征进行划分,每个内部节点代表一个属性测试,每个分支代表测试的结果,每个叶节点代表一个类别。随机森林是一种集成学习技术,它通过结合多个决策树来增强分类和回归任务的准确性和鲁棒性。Garg等人[21]提出了一种预测桥梁在地震后损坏程度的方法,该方法从地震震级、桥梁和受灾地区的距离、桥梁类型和桥梁建材等因素进行预测。他们对250个样本 分别比较了决策树、随机森林、XGBoost等算法的分类结果,结果表明,随机森林和决策树的准确率达到了96%。
2.2" 深度学习算法
传统的图像处理算法对桥梁裂缝的检测效果不是很好,而深度学习模型可以直接用于桥梁裂缝的检测,基于深度学习的桥梁裂缝识别算法提高了裂缝检测的性能,还为实时监测桥梁健康和维护带来了新的方法。深度学习通过多层神经网络处理数据集和复杂的模式识别和预测等问题。深度学习对数据进行表征学习,能够处理大规模复杂数据,适用于多个领域的模式识别和预测等任务。深度学习算法包括人工神经网络、卷积神经网络、循环神经网络、生成对抗网络和强化学习等算法,在多个领域取得了重要的研究和应用成果。
Pozzer等人[22]使用多种深度学习模型研究常规图像和热图像对混凝土结构损伤进行检测的性能,使用了大坝和混凝土桥的图像进行训练和验证,结果表明,MobileNetV2在热图像中识别分层、裂缝、剥落和斑块等方面表现良好,79.7%的混凝土损伤被识别出来。与常规图像相比,红外热成像可以克服常规图像对光源不敏感的局限性,可使用的范围更广。
Droguett等人[23]提出了一种仅有13层的Dense-Net架构,该架构包含特征提取器和数据路径,用于移动设备检测桥梁结构。使用DenseNet架构对公共数据集进行实验,结果表明,35 000个参数就能得到最好的结果,IoU达到了94.51%。
Li等人[24]在ResNet-50和ASPP上进行了结构修改,提出了基于深度学习的FCS-Net网络,用于处理具有复杂背景和不平衡样本的细微裂纹分割,FCS-Net网络在全尺寸钢梁图像中实现了0.740 8的MIoU。
崔弥达等人[25]设计了一个结合ROS架构和YOLOv3算法的便携式混凝土桥梁实时检测系统,该系统可以整合硬件性能,完成对混凝土裂缝图像的实时获取和分析处理,实现混凝土裂缝图像检测结果的实时显示。对预应力混凝土进行系统测试,结果表明,该功能成功实现了裂缝的实时检测。
杜敏等人[26]提出了一个YOLOv4-EfficientNet B7的目标检测模型,提高了桥梁裂缝图像检测精度和速度,通过将YOLOv4的主干网络CSPDarkNet53优化为EfficientNet B7,使得mAP提升了3.85%,召回率增长了4.29%。与其他裂缝检测算法相比,本模型的检测精度和性能更高。
3" 裂缝几何特征测定
裂缝的几何特征,如长度、宽度和面积等,能够揭示结构的损伤程度和破坏机制。裂缝的长度和宽度,以及其发展趋势,可以提供有关结构受力情况、应力集中以及潜在的破坏模式的重要线索,有助于评估结构的安全性和制定相应的修复措施。
3.1" 裂缝长度的计算
裂缝的长度是指裂缝的延伸距离,它的测量方法有直尺、刻度尺,并结合全站仪或者GPS进行测量,以提高精确度。图像上的裂缝长度通常定义为裂缝中心线在图像中单层像素的总长度。在进行裂缝长度测量之前,通常需要先对裂缝进行骨架化处理,例如,基于索引表的骨架化算法[27]Hilditch骨架化算法[28]以及Zhang等人提出的骨架化算法[29]等。在得到图像的骨架后,就可以计算裂缝的长度了。根据文献,有几种计算长度的不同方法,例如,有基于欧氏距离计算法[30]、基于链码计算法[31]和基于骨架线计算法[32]。
基于欧氏距离的计算方法是通过逐一计算相邻像素点之间的距离并进行求和,进而得到裂缝的长度,其中像素点之间的距离采用欧氏距离。
基于链码计算法采用8连通Freeman编码,按照逆时针方向对像素点进行编码,从而生成裂缝的链码。
基于骨架线计算法,裂缝的骨架线由一系列单独的像素点构成。通过对这些单个像素点进行累加求和,可以得到裂缝的长度。
3.2" 裂缝宽度的计算
裂缝宽度检测是桥梁裂缝检测的关键部分,其中裂缝宽度指的是垂直于裂缝延伸方向的最大分离距离。常见的测量工具包括裂缝计和厚度尺。在数字图像处理中,定义和计算裂缝宽度的方法有多种,以下列出几种常用的计算方法:
1)平均宽度计算法[6]。设裂缝的长度为L、面积为S,则平均宽度为W,计算式如下:
2)基于中心线的裂缝宽度法[33]。该方法首先确定裂缝的两条边缘线和一条中心线。接着,在裂缝中心线上选择待测宽度点,绘制通过该点的垂直线。该垂直线与两条边缘线的交点之间的距离,即为该点的裂缝宽度。
3)基于灰度值的裂缝宽度法[34]。因为裂缝宽度不同导致其灰度值也不同,我们可以通过试验数据建立裂缝灰度值与裂缝宽度之间的关系,从而评估裂缝的实际宽度。
裂缝长度的计算方法,详细的内容请参阅文献[1]。
3.3" 裂缝面积测量
裂缝面积是裂缝的重要特征,裂缝宽度和面积直接影响桥梁的结构稳定性。图像面积的测量通常通过图像处理技术实现,利用图像分析软件或深度学习算法对裂缝图像进行处理,自动或半自动地提取裂缝的宽度和面积信息。裂缝面积直观地反映了裂缝的开裂程度,因此计算裂缝面积对后续分析非常重要。通常,计算裂缝面积的方法有3种主要方式:
1)像素当量法。其中,N表示区域所占像素个数;μ表示像素当量,为图像对应的实际尺寸与图像相应方向上像素点数的比值。
2)近似估计法。使用像素当量法来计算网状裂缝和交叉裂缝的面积可以得到较为准确的结果,但这种方法的实际意义相对较小。余鑫[35]提出用裂缝外接多边形的面积近似代替网状裂缝和交叉裂缝的面积。
3)多边形计算方法。从道路破损和桥梁裂缝的情况看,不论道路的破损面和还桥梁的裂缝,如果用多边形近似的话,即可能是凹多边形,也可能是凸多边形。温锦辉[36]在研究道路破损面积时提出了计算交叉多边形面积的方法。通过鞋带公式计算两个交叉多边形的面积,公式如下:
这里面涉及了两个多边形交叉部分面积的计算,IoU提供的计算方法是把交叉部分作为矩形进行处理的,但两个多边形的交差部分不一定是矩形,而是多边形。他提出了计算两个交叉凸多边形面积的方法。其计算的步骤:首先计算两个多边形的交集区域的交点坐标。再对这些交点进行排序。最后把排序好的交点带入鞋带公式求交集部分的面积。
4" 结" 论
本文对桥梁裂缝检测涉及的一些技术进行了实验研究。这里面包含了图像处理的方方面面,例如,图像降噪、图像增强、图像配准、图像拼接等,也涉及了光线不均匀的处理方法。还包含了最核心的裂缝的识别和分割技术,最新的深度机器学习在裂缝识别和分割中被广泛应用。最后还对裂缝的几何特征测定的方法进行了讨论和研究。
未来桥梁裂缝检测的发展趋势是结合数字图像处理技术和人工智能技术,因为这种方法相比传统人工检测具有更高的精度、更佳的安全性,并能够对裂缝进行量化管理、自动计算几何特征并进行标记。我们后面主要工作的方向就是把图像处理技术和人工智能技术应用到特定行业的图像处理中,例如地震图像的处理、道路和桥梁的裂缝处理等;在理论上也将结合实际情况对特定环境下的图像的存储方法等进行研究。
参考文献:
[1] 杨国俊,齐亚辉,石秀名.基于数字图像技术的桥梁裂缝检测综述 [J].吉林大学学报:工学版,2024,54(2):313-332.
[2] SPENCER B F,HOSKERE V,NARAZAKI Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring [J].Engineering,2019,5(2):199-222.
[3] 王睿,漆泰岳.基于机器视觉检测的裂缝特征研究 [J].土木工程学报,2016,49(7):123-128.
[4] SHI Y,CUI L,QI Z,et al. Automatic Road Crack detection Using Random Structured Forests [J].IEEE Transactions on Intelligent Transportation Systems,2016,17(12):3434-3445.
[5] 廖延娜,李婉.基于卷积神经网络的桥梁裂缝检测方法 [J].计算机工程与设计 ,2021,42(8):2366-2372.
[6] ADHIKARI R S,MOSELHI O,BAGCHI A. Image-based Retrieval of Concrete Crack Properties for Bridge Inspection [J].Automation in Construction,2014,39:180-194.
[7] KIM H,YOON J,SIM S. Automated Bridge Component Recognition from Point Clouds Using Deep Learning [J/OL].Structural Control and Health Monitoring,2020,27:e2591(2020-06-20).https://doi.org/10.1002/stc.2591.
[8] LEE J S,PARK J,RYU Y M. Semantic Segmentation of Bridge Components based on Hierarchical Point Cloud Model [J/OL].Automation in Construction,2021,130:103847(2021-07-29).https://doi.org/10.1016/j.autcon.2021.103847.
[9] HSIEH Y A,TSAI Y J. Machine Learning for Crack Detection:Review and Model Performance Comparison [J/OL].Journal of Computing in Civil Engineering,2020,34(5):04020038(2020-07-13).https://doi.org/10.1061/(ASCE)CP.1943-5487.0000918.
[10] 温锦辉,基于YOLOX-s的公路破损检测研究 [D].廊坊:华北科技学院,2022.
[11] 李若星.基于机器视觉的混凝土裂缝检测方法研究 [D].重庆:重庆大学,2018.
[12] DORAFSHAN S,THOMAS R J,MAGUIRE M. SD-NET2018: An Annotated Image Dataset for Non-Contact Concrete Crack Detection Using Deep Convolutional Neural Networks [J].Data in Brief,2018,21:1664-1668.
[13] 王密,潘俊.一种数字航空影像的匀光方法 [J].中国图象图形学报,2004,9(6):744–748.
[14] 胡庆武,李清泉.基于Mask原理的遥感影像恢复技术研究 [J].武汉大学学报:信息科学版,2004,29(4):319-323.
[15] 李烁,王慧,王利勇,等.遥感影像变分Mask自适应匀光算法 [J].遥感学报,2018,22(3):450-457.
[16] 朱述龙,张振,朱宝山,等. 遥感影像亮度和反差分布不均匀性校正算法的效果比较 [J].遥感学报,2011,15(1):111-122.
[17] 高丽杰,信文雪,基于深度学习的光照不均匀图像识别系统设计 [J].信息与电脑,2023(9):25-27.
[18] 金萍萍.图像拼接和裂缝提取方法研究及在多足机器人桥梁检测中的应用 [D].广州:华南理工大学,2015.
[19] YU L,HE S,LIU X,et al. Engineering-Oriented Bridge Multiple-Damage Detection with Damage Integrity Using Modified Faster Region-Based Convolutional Neural Network [J].Multimedia Tools and Applications,2022,81:18279-18304.
[20] PARISI F,MANGINI A M,FANTI M P,et al. Automated Location of Steel Truss Bridge Damage Using Machine Learning and Raw Strain Sensor Data [J/OL].Automation in Construction,2022,138:104249(2022-04-19).https://doi.org/10.1016/j.autcon.2022.104249.
[21] GARG Y,MASIH A,SHARMA U. Predicting Bridge Damage During Earthquake Using Machine Learning Algorithms [C]//2021 11th International Conference on Cloud Computing,Data Science amp; Engineering(Confluence).Noida:IEEE,2021:725-728.
[22] POZZER S,AZAR E R,ROSA F D,et al. Semantic Segmentation of Defects in Infrared Thermographic Images of Highly Damaged Concrete Structures [J/OL].Journal of Performance of Constructed Facilities,2021,35(1):04020131(2020-10-31).https://doi.org/10.1061/(ASCE)CF.1943-5509.0001541.
[23] DROGUETT E L,TAPIA J,YANEZ C et al. Semantic Segmentation Model for Crack Images from Concrete Bridges for Mobile Devices [J].Proceedings of the Institution of Mechanical Engineers Part O Journal of Risk and Reliability,2022,236(4):570-583.
[24] LI Z,ZHU H,HUANG M. A Deep Learning-based Fine Crack Segmentation Network on Full-Scale Steel Bridge Images with Complicated Backgrounds [J].IEEE Access,2021,9:114989-114997.
[25] 崔弥达,王超,陈金桥,等.基于ROS及YOLOv3的混凝土桥梁裂缝实时检测系统 [J].东南大学学报:自然科学版,2023,53(1):61-66.
[26] 杜敏,杨国庆,张慧.基于YOLOv4-EfficientNet B7的桥梁裂缝检测方法研究 [J].天津城建大学学报,2023,29(1):55-61.
[27] PELEG S,ROSENFELD A. A Min-Max Medial Axis Transformation [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1981(2):208-210.
[28] 王龙云.路面裂缝检测算法研究 [D].南京:南京邮电大学,2012.
[29] ZHANG T Y,SUEN C Y. A Fast Parallel Algorithm for Thinning Digital Patterns [J].Communications of the ACM,1984,27(3):236-239.
[30] 周颖,刘彤.基于计算机视觉的混凝土裂缝识别 [J].同济大学学报:自然科学版,2019,47(9):1277-1285.
[31] 唐钱龙,谭园,彭立敏,等.基于数字图像技术的隧道衬砌裂缝识别方法研究 [J].铁道科学与工程学报,2019,16(12):3041-3049.
[32] 沈立辉,吴保国,杨乃.面状要素主骨架线自动提取算法研究 [J].武汉大学学报:信息科学版,2014,39(7):767-771.
[33] 刘宇飞.基于模型修正与图像处理的多尺度结构损伤识别 [D].北京:清华大学,2015.
[34] 杨世峰,陈化祥,李孝兵.关于通过图像灰度判断裂缝宽度的研究 [J].公路交通科技:应用技术版,2018,14(3):71-72.
[35] 余鑫.复杂背景下桥梁裂缝检测算法研究与应用 [D].西安:长安大学,2021.
[36] 温锦辉,栾尚敏.基于集合与递归运算的两凹多边形交集面积计算方法 [J].数学建模及其应用,2022,11(1):16-22.
作者简介:姜修丽(1999—),女,汉族,山东临沂人,硕士研究生在读,研究方向:应急信息化;温锦辉(1994—),男,汉族,福建龙岩人,硕士,研究方向:计算机视觉;栾尚敏(1968—),男,汉族,山东济南人,教授,博士,研究方向:人工智能及其应用。