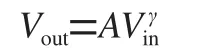



摘" 要:医学图像是临床诊断的重要参考,如何快速且准确地分割出医学图像中的病灶区域,受到了人们的广泛关注。当前,利用深度学习进行图像处理已成为主流,医学图像分割因其独特的应用场景,成为深度学习在图像处理领域应用的成功范例。U-Net网络凭借其特有的U型结构,在医学图像分割领域取得了不错的性能,但该网络仍存在精度不够高等问题。文章对基于优化U-Net模型的医学图像自动分割方法展开研究,将CBAM(Convolutional Block Attention Module)和SE(Squeeze-and-Excitation)模块与U-Net网络结构相结合,实现了对人体器官的高度准确分割。在眼球数据集上的实验结果表明,优化后的U-Net网络相较于单纯的U-Net网络,准确率更高(0.905)。该研究具有重要的临床应用前景,能够对人体器官、病变区域等目标进行有效分割,为医疗实践带来积极影响。
关键词:U-Net神经网络;图像分割;医学图像;注意力机制
中图分类号:TP391.4;TP18" 文献标识码:A" 文章编号:2096-4706(2025)04-0047-06
Application of Medical Image Segmentation Based on Optimized U-Net Neural Network Model
ZHANG Xiaoxu, SHAO Yinglong, YAN Menghui, WANG Jianqing
(Zhejiang Chinese Medical University, Hangzhou" 310053, China)
Abstract: Medical images are important references for clinical diagnosis. How to segment the lesion areas in medical images quickly and accurately has received extensive attention. At present, the use of Deep Learning for image processing has become the mainstream. Medical image segmentation has become a successful example of Deep Learning in the field of image processing due to its unique application scenarios. With its unique U-shaped structure, the U-Net network has achieved good performance in the field of medical image segmentation, but the network still has problems such as insufficient accuracy. This paper studies the automatic segmentation method of medical images based on the optimized U-Net model. The CBAM and SE modules are combined with the U-Net network structure to achieve highly accurate segmentation of human organs. The experimental results on the eyeball dataset show that the optimized U-Net network has higher accuracy (0.905) than the simple U-Net network. This study has important clinical application prospects, which can effectively segment human organs, lesion areas and other targets, and has a positive impact on medical practice.
Keywords: U-Net neural network; image segmentation; medical image; Attention Mechanism
0" 引" 言
医学影像技术在当今医学领域占据着日益重要且不可或缺的关键地位,已成为疾病诊断、治疗规划以及疗效评估的重要基石[1]。然而,在影像学广泛应用的背后,有一个不容忽视的挑战,即病灶区域的精准标注。长期以来,这一任务依赖资深医生手工操作,既耗时又费力。虽然医生凭借丰富的临床经验,能够相对高效地定位病灶,但这种高度依赖人工的方式,也存在显著风险。例如,长时间高强度工作容易导致医生出现判断失误[2],这不仅可能延误患者的治疗时机,还可能加剧医患之间的误解与冲突[3]。
随着深度学习的迅猛发展,利用深度学习进行医学图像分割已成为医学图像分割领域的主流方法[4-5]。医学图像分割作为医学图像处理与图像分割技术的交叉领域,具有独特性,其处理的样本较为特殊,这使得诸多在普通图像分割中广泛应用的技术,难以直接迁移并应用于医学图像分割领域,存在不完全适用的情况。
U-Net网络[6]凭借在医学图像处理中的卓越性能脱颖而出。它的出现极大地推动了医学图像分割技术的进步,是当前医学图像分割领域极为热门的方法。然而,若仅使用原始U-Net进行训练,会出现梯度消失、特征利用率低等问题,最终致使模型的分割准确率难以提升[7]。此后,研究者基于U-Net提出了许多改进方案,这些改进后的网络也相继在医学图像分割领域取得了较好的分割效果。
因此,基于优化U-Net的医学图像分割方法研究极具意义。针对原始U-Net存在的问题,将注意力机制、稠密模块、特征增强等深度神经网络领域的最新技术,融入基于U-Net的基础结构,成为广泛采用的改进手段。这些改进工作有的面向不同优化目标,有的通过结构改进、添加新模块等方式,致力于提高医学影像分割的准确性、运算效率和适用范围[8]。
Milletari等人[9]提出了V-Net网络,其整体构造与U-Net极为相似,但V-Net直接运用3D卷积处理图片,省去了将三维图像转换为二维图像的复杂过程。后来,Zhou等人[10]提出U-Net++分割网络,首次对U-Net网络的跳跃连接部分进行改进,为后续网络设计提供了新思路,进一步提升了性能。基于ResNet的思想,Ibtehaz等人[11]将残差连接与U-Net相结合,提出多尺度残差U-Net(Multi-scale Residual U-Net, MultiResUNet),通过建立残差连接避免过拟合对网络性能的影响,以此提高分割精度。此外,Vaswani等人提出了结合Transformer技术[12]的TransUNet[13],虽然TransU-net在提取全局信息方面具有优势,但容易导致局部细节信息丢失,在医学图像数据集上难以取得良好的分割性能。总体而言,改进U-Net网络模型在医学图像分割领域具有巨大潜力。
综上所述,本研究在原有U-Net网络结构基础上,针对其存在的不足,分别加入SE[14]和卷积块注意力模块(Convolutional Block Attention Module, CBAM)[15],以增强特征,进而提高医学图像分割的准确率。
1" 相关理论介绍
1.1" U-Net神经网络
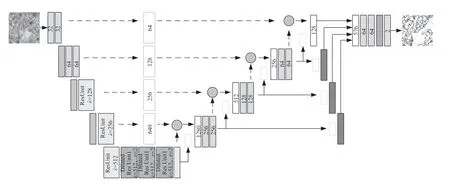
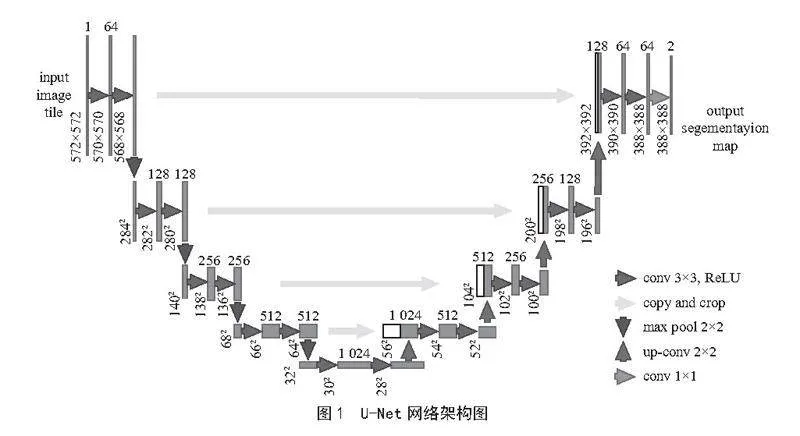
U-Net是一种专门为图像分割而设计的卷积神经网络(Convolutional Neural Network, CNN),由Ronneberger等人[6]于2015年提出,最初应用于生物医学图像处理领域。U-Net的架构呈对称的U形,主要包含编码路径、中心部分和解码路径,其结构如图1所示。U-Net的核心思想是采用编码器-解码器结构。在编码器部分,网络通过一系列卷积层和最大池化层,逐步提取图像特征,同时降低图像的空间分辨率。这一过程不仅能够捕捉图像的上下文信息,还能有效减少计算量。在解码器部分,网络则通过上采样操作,逐步恢复图像的空间分辨率。为了在恢复图像分辨率的同时保留图像细节信息,U-Net创新性地采用了跳跃连接。即在上采样的过程中,将编码器中相应层的特征图直接拼接至解码器的对应层。这种跳跃连接能够让网络在进行上采样时,充分利用低层特征,从而有效提高了分割边缘的准确性。此外,U-Net网络在上采样部分还运用了卷积层,以进一步融合特征。并且在每个上采样层之后,使用两个3×3的卷积层对特征图进行调整。最终,通过一个1×1的卷积层,输出所需的分割结果。
1.2" 损失函数
损失函数用于衡量模型预测结果与真实结果之间的差异,常被用于评估模型性能。其核心意义在于提供一个数值化指标,能量化模型预测的准确程度或误差大小,进而指导模型在训练过程中进行参数更新,使其能更好地逼近真实目标。通过最小化损失函数,模型在训练数据上的表现得以提升,在未见过的数据上的泛化能力也会增强,从而提高模型的实用性和可靠性。
在深度学习领域,常见的损失函数包括交叉熵损失函数(Cross-Entropy Loss)、Dice损失函数、Jaccard损失函数(也称作IoU损失函数)以及Tversky损失函数等[16]。交叉熵损失函数通常应用于分类任务,在多类别分类问题中,它衡量的是模型预测概率分布与真实标签分布之间的差异。Dice损失函数和Jaccard损失函数则常用于图像分割任务,它们在像素级别比较模型预测结果与真实分割结果的重叠程度,以此衡量分割的准确性。Tversky损失函数[17]是结合了Dice损失函数和Jaccard损失函数的一种形式,旨在平衡模型对正负样本的关注度,适用于处理不平衡数据集的情况。
总体而言,选择合适的损失函数对模型的训练和性能起着关键作用。由于不同的任务和数据特点可能需要使用不同的损失函数来进行训练和优化,所以在实际应用中,需依据具体情况灵活选择损失函数,以实现最佳的模型性能。基于本文数据集的特点,实验研究选取了二元交叉熵损失函数(Binary Cross-Entropy, BCE),BCE损失函数的定义如下:
(1)
1.3" 注意力机制(Attention Mechanism)
注意力机制的概念最初由Treisman等人提出,他们的研究为后续发展奠定了基础[12]。该机制模拟人脑的注意力模式,旨在揭示人类如何在众多视觉刺激中,优先处理某些关键信息。注意力机制的一个关键特性是,它可被视为一种组合函数,能够对输入信息进行加权与整合。在深度学习领域,注意力机制Attention模型能够获取全局信息。人类在观察事物时,会有选择性地关注重要信息,这一过程被称为注意力。视觉注意力机制在提升信息处理的效率与准确性方面,发挥着重要作用。深度学习中的注意力机制,通过模仿人类处理视觉信息的方式,能够有选择性地聚焦于特定输入信息。这种机制的核心功能在于,将注意力集中在与当前任务最为相关的重要信息上,同时忽略不重要或无关的信息。就如同人类视觉系统的运作方式一样,这种注意力机制使系统能够更高效地处理海量数据,减少信息冗余,进而加快计算进程,提高决策的准确性。在深度学习领域,注意力机制的设计与应用,受到人类对环境生理感知过程的启发。在日常生活中,人类借助视觉注意力机制,能够快速识别和处理环境中的关键信息,比如识别危险或者寻找食物,同时忽略背景中的次要细节。与之类似,深度学习中的注意力机制赋予网络在处理输入数据时更大的灵活性,使其能够在复杂任务中提取最相关的信息,并基于这些信息做出准确判断。
1.3.1" CBAM模块
CBAM是一种卷积神经网络模块,其目的是通过引入注意力机制,提升网络的表示能力,CBAM结构如图2所示。
空间注意力(Spatial Attention)[18]能够让网络聚焦于对分类或检测任务具有重要意义的图像像素区域,进而忽略那些无关区域。这种机制通过对每个像素位置进行加权处理,突出图像中的关键区域,使模型能够更精准地识别目标区域的特征。
通道注意力(Channel Attention)[19]则着眼于特征图各通道之间的关系。它通过学习每个通道的重要性权重,对特征图的通道进行调整,让模型能够更好地利用对分类或检测任务有用的特征。
混合域注意力机制将空间注意力和通道注意力相结合,形成了一个综合性的注意力机制,即CBAM。由于CBAM被精心设计为轻量级模块,在大多数情况下,它几乎不会带来额外的参数和计算开销。CBAM注意力模块可广泛应用于提升卷积神经网络在多种任务中的表现能力。图2的CBAM网络结构图中,Channel Attention Module主要关注输入数据中有意义的内容,其计算式为:
(2)
而Spatial Attention Module主要关注哪些位置是有意义的,其计算式为:
(3)
1.3.2" SE模块
SE Block是深度学习中的一个模块化子结构,能够嵌入到各类分类或检测模型之中,以此提升模型性能。其核心思路是通过学习特征权重,强化有效特征,弱化无效特征,进而优化模型的输出结果。
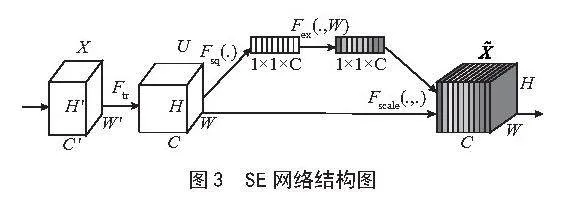
具体操作过程如下:首先,对输入特征图执行全局平均池化操作(Global Average Pooling, AP),将每个通道的空间维度压缩成一个单一数值。接着,把压缩后的特征送入两个全连接层进行处理。最后,利用得到的权重对原始特征进行重新标定。也就是说,将原始特征图每个通道的值与对应的权重相乘,从而放大重要特征,抑制无效或次要特征[20]。SE结构如图3所示。
Ftr可以看作一个标准的卷积算子,计算式为:
(4)
Fsq就是使用通道的全局平均池化,计算式为:
(5)
为了利用压缩操作中汇聚的信息,我们接下来通过Excitation操作来全面捕获通道依赖性,计算式为:
(6)
Scale操作就是将前面得到的注意力权重加权到每个通道的特征上,计算式为:
(7)
2" 实验与分析
2.1" 数据集说明
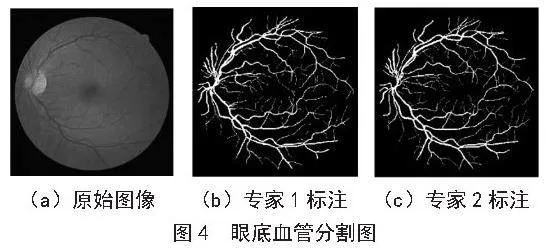
本研究的数据来源于开源数据集Drive[21]。Drive数据集于2004年发布,其目的是支持荷兰糖尿病视网膜病变的筛查研究。该数据集包含40张彩色眼底图像及其对应的标注图像,为糖尿病视网膜病变的检测与分析提供了宝贵资源。每张图像的尺寸为565×568像素。原始图像取自400名年龄在25至90岁之间的糖尿病受试者,最终从中随机选取40张图像用于本研究。其中,33张图像显示无糖尿病视网膜病变迹象,7张图像显示有轻度早期糖尿病视网膜病变迹象。
这40张图像被分为训练集和测试集,两个集合均包含20张图像。每张图像都带有由两个专家组手动分割的标记结果。图4展示了Drive数据集的原始图像和手工标注图像。
2.2" 模型评价指标
2.2.1" 混淆矩阵
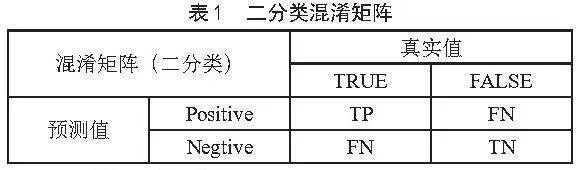
在医学图像分割领域,尤其是针对人体器官的分割任务,混淆矩阵是评估模型性能的重要工具。混淆矩阵以矩阵形式呈现了模型对测试数据在像素级别上的分类结果与真实标签之间的关系[13],这在分割任务中至关重要。以眼球分割为例,其混淆矩阵如表1所示,各单元格含义如下:真正例(True Positive, TP),血管区域的像素预测为血管;假负例(False Negative, FN),将血管区域的像素标记为非血管;假正例(False Positive, FP),非血管区域的像素标记为血管;真负例(True Negative, TN),在分割任务中,通常没有真负例的概念,因此该单元格在混淆矩阵中不会出现[13]。混淆矩阵能够直观地展示模型在血管和非血管区域的分割准确性及错误情况,有助于指导模型的优化与改进,进而提高眼球分割结果的准确性和稳定性,为临床诊断和治疗提供更可靠的支持。
2.2.2" 常见评价指标
通过分析混淆矩阵,能够计算出多种评估指标,如精准率(Precision)、召回率(Recall)、交并比(IoU)、像素准确率(Pa),以此定量地评估模型在分割任务中的性能。
精准率(P)用于衡量模型预测为正样本的实例中,真正属于正样本的比例。在图像分割任务里,它代表了模型在所有像素上预测正确的比例。召回率(R)体现了模型能够准确找到实际正样本的能力。交并比是一个用于衡量模型预测结果与真实结果之间重叠程度的重要指标。像素准确率则衡量了模型预测正确的像素在总像素中所占的比例。其计算式如下:
(8)
(9)
2.3" 实验过程
2.3.1" 实验设备
本文实验所使用的硬件设备为:AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz CPU,机带RAM16 GB,显卡为NVIDIA GeForce RTX 3070 Laptop GPU。本模型基于PyTorch实现,Python 3.10,PyTorch 1.31。模型训练采用RMSProp优化器,训练周期Epoch为40,学习率(Learning Rate)为0.000 01,采用BCE损失函数来反应模型分割的准确性。
2.3.2" 实验结果及对比分析
在本研究中,选取了传统的图像分割模型U-Net、Nested_Unet,以及分别加入CBAM模块与SE模块的U-Net模型开展对比实验,以评估它们在眼球图像分割任务中的性能表现。
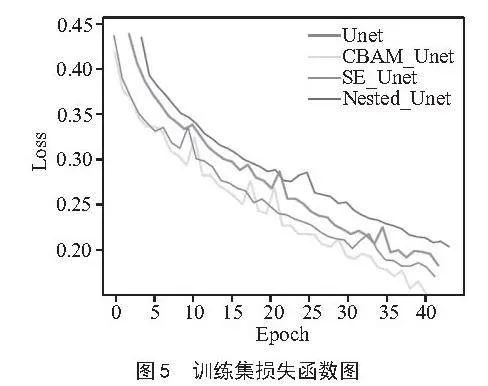
如图5所示,在训练初期,所有模型均出现了损失快速下降的情况,这表明网络正在快速学习并适应数据分布。然而,随着训练的持续进行,各模型呈现出不同的收敛趋势。其中,CBAM_U-Net模型凭借其最低且最为稳定的损失曲线脱颖而出。这一结果表明,在整个训练过程中,该模型不仅能够有效地降低损失,还能始终保持良好的稳定性,这或许得益于其融入注意力机制后强大的特征提取能力。
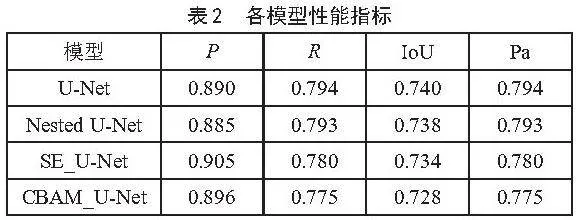
从表2可以看出,SE_U-Net展现出最高的精确度(0.905),这意味着在模型预测为正类的样本中,实际为正类的比例最高。同时CBAM_U-Net的精确度也略高于U-Net,而Nested U-Net精确度最低。对于Recall值,传统的U-Net模型表现最佳。
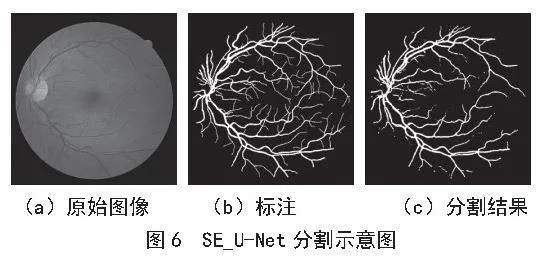
基于控制变量法,选用上述精确度最高的SE_U-Net来验证,其验证集的分割情况如图6所示。由图可知,SE_U-Net在分割边缘细小血管区域时,血管分割结果较好,分割的血管具有完整的脉络结构,对血管细小分支也有较好的分割效果,进一步提高了模型对血管的分割性能。
3" 结" 论
视网膜图像的医学分析中,细小血管的结构复杂且精细,这给图像分割带来了难题。为解决该问题,我们提出一种改进的U-Net医学图像分割算法。该算法结合了注意力机制中的SE模块和CBAM模块,成功实现了对血管的精确分割。相较于传统模型,结合后的模型在准确率上有一定提升。通过优化传统的U-Net网络模型,能够提高人体器官、病变区域等目标分割的精确率,使其发挥出更大潜力。
尽管本研究在眼球分割方面取得了一定成果,但仍存在一些局限性。首先,本研究使用的是开源数据集Drive,样本量小,需要扩大数据集规模或使其多样化;其次,网络结构的设计可能需要进一步优化,以提高分割效果和性能;最后,还需要进一步提高模型的对抗性和鲁棒性,以应对不同医学图像的分割需求。
参考文献:
[1] PECK P V. New Medical Imaging Technology [C]//Proceedings of a Special Symposium on Maturing Technologies and Emerging Horizons in Biomedical Engineering.New Orleans:IEEE,1988:113-114.
[2] WIESTLER B,MENZE B. Deep Learning for Medical Image Analysis: A Brief Introduction [J].Neuro-Oncology Advances,2020,2(Supplement_4):iv35-iv41.
[3] FOURCADE A,KHONSARI R H. Deep Learning in Medical Image Analysis: A Third Eye for Doctors [J].Journal of Stomatology,Oral and Maxillofacial Surgery,2019,120(4):279-288.
[4] ROTH H R,SHEN C,ODA H,et al. Deep Learning and its Application to Medical Image Segmentation [J].Medical Imaging Technology,2018,36(2):63-71.
[5] WANG J,ZHU H,WANG S H,et al. A Review of Deep Learning on Medical Image Analysis [J].Mobile Networks and Applications,2021,26(1):351-380.
[6] RONNEBERGER O,FISCHER P,BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation [C]//Medical Image Computing and Computer-Assisted Intervention(MICCAI 2015).Munich: Springer International Publishing,2015:234-241.
[7] 史健婷,崔闫靖,常亮.基于优化U-Net网络的乳腺肿瘤区域分割方法 [J].计算机技术与发展,2021,31(8):156-161.
[8] 殷晓航,王永才,李德英.基于U-Net结构改进的医学影像分割技术综述 [J].软件学报,2021,32(2):519-550.
[9] MILLETARI F,NAVAB N,AHMADI S A. Local Background Enclosure for RGB-D Salient Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:565-571.
[10] ZHOU Z W,SIDDIQUEE M M R,TAJBAKHSH N,et al. UNet++: A Nested U-Net Architecture for Medical Image Segmentation [C]//Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support.Granada:Springer,2018:3-11.
[11] IBTEHAZ N,RAHMAN M S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation [J].Neural networks,2020,121:74-87.
[12] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is All You Need [J].Advances in Neural Information Processing Systems,2017,30:5998-6008.
[13] CHEN J N,LU Y Y,YU Q H,et al. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation [J/OL].arXiv:2102.04306 [cs.CV].[2024-06-16].https://arxiv.org/abs/2102.04306.
[14] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[15] WOO S,PARK J,LEE J Y,et al. CBAM: Convolutional Block Attention Module[C]//Computer Vision-ECCV 2018.Munich:Springer,2018:3-19.
[16] PRIYA R M,VENKATESAN P. An Efficient Image Segmentation and Classification of Lung Lesions in PET and CT Image Fusion Using DTWT Incorporated SVM [J/OL].Microprocessors and Microsystems,2021,82:103958[2024-06-10].https://doi.org/10.1016/j.micpro.2021.103958.
[17] TANG Z X,ZHANG J Y,BAI C L,et al. Dense Swin-UNet: Dense Swin Transformers for Semantic Segmentation of Pneumothorax in CT Images [J/OL].Journal of Mechanics in Medicine and Biology,2023,23(8):2340069[2024-06-10].https://doi.org/10.1142/S0219519423400699.
[18] FU J L,ZHENG H L,MEI T. Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:4476-4484.
[19] HU J,SHEN L,SUN G. Squeeze-and-Excitation Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141.
[20] 温静,李智宏.基于带Squeeze-and-Excitation模块的ResNeXt的单目图像深度估计方法 [J].计算机应用,2021(1):221-225.
[21] STAAL J,ABRÀMOFF M D,NIEMEIJER M,et al. Ridge-based Vessel Segmentation in Color Images of the Retina [J].IEEE Transactions on Medical Imaging,2004,23(4):501-509.
作者简介:张筱旭(2003.01—),女,汉族,河南周口人,本科在读,研究方向:计算机视觉;通信作者:王健庆(1975.12—),男,汉族,河北唐山人,副教授,博士研究生,研究方向:计算机视觉、模式识别、医学影像分析与处理。
收稿日期:2024-07-26