
摘" 要:为了提高非约束环境下的人脸表情识别效果,研究并设计了一种嵌入注意力机制的两阶段特征融合表情识别深度卷积神经网络框架。该网络框架设计和引入了多个注意力模块,旨在精准提取图像局部位置的表情特征信息。同时,通过构建密集连接残差块,有效提升了特征提取的质量并增强了网络的稳定性。在此基础上,将局部特征与多尺度模块提取的全局特征进行融合,从而获得更具判别力的表情特征。实验结果显示,所提方法在RAF-DB数据集上表现出较好的表情识别性能。
关键词:表情识别;注意力机制;局部特征;特征融合
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)04-0043-05
Expression Recognition Method Based on Attention Mechanism and
Feature Fusion
JIANG Tao, LI Chuzhen
(School of Information Technology, Guangdong Technology College, Zhaoqing" 526100, China)
Abstract: In order to improve the performance of facial expression recognition in unconstrained environments, a two-stage feature fusion expression recognition deep Convolutional Neural Network framework with embedded Attention Mechanism is studied and designed. This network framework designs and introduces multiple attention modules aimed at accurately extracting expression feature information of local image positions. Meanwhile, by constructing densely connected residual blocks, the quality of feature extraction is effectively improved and the stability of the network is enhanced. On this basis, the local features are fused with the global features extracted by the multi-scale module to obtain more discriminative expression features. The experimental results show that the proposed method exhibits good expression recognition performance on the RAF-DB dataset.
Keywords: expression recognition; Attention Mechanism; local feature; feature fusion
0" 引" 言
表情是人类传达情感最有力和最自然的信号之一,在交流中扮演着重要的角色[1]。面部表情识别(Facial Expression Recognition, FER)因其在多个领域的广泛应用,正成为计算机视觉领域备受关注的研究课题。无论是在人机交互[2]、驾驶员疲劳监测[3],还是在智能教育和医疗诊断中[4],FER都展现出重要价值,使其成为学术界和工业界共同关注的焦点。FER旨在将图像或视频片段分类为几种基本情绪之一,即中性、快乐、悲伤、惊讶、恐惧、厌恶、愤怒,甚至更多[5]。这就需要去建立表情图像与表情类别之间的映射关系,然后计算机根据这种映射关系自动确定面部表情。
近年来,深度卷积神经网络(DCNN)在计算机视觉领域大放异彩,其最大的优势之一在于能从海量的原始数据中,智能地提取出有价值的特征,拥有出色的自适应学习特性。与传统的手工特征相比,DCNN在揭示高层语义和挖掘数据本质方面显得更为出色[6]。然而,面部表情识别任务的复杂性高于其他图像识别任务,因为它要求对面部特征进行细致的刻画,以实现更高的识别精度。在应用DCNN进行面部表情识别时,可能会因为对面部关键部位如眼部和嘴部的特征关注不够,而导致部分有效特征信息的丢失,这种不足可能会影响识别的准确性[7]。由此,为了提升识别性能,需要不断探索如何更好地提取面部关键区域的局部特征,以确保在处理复杂表情时,能够充分捕捉和利用这些细节特征,从而提高整体识别的精确度和可靠性。因此,本文提出了一种基于注意力机制和特征融合的人脸表情识别算法,该算法旨在融合全局特征和局部特征,提升模型的特征提取能力,并增强对不同表情的辨识能力。本文所提算法将注意力模块、多尺度模块、密集连接残差块嵌入到FER的DCNN架构中。采用不同特征提取分支对面部局部特征、全局特征分别进行提取,并通过两阶段融合方法来提高整体性能。
1" 网络结构
1.1" 网络整体结构
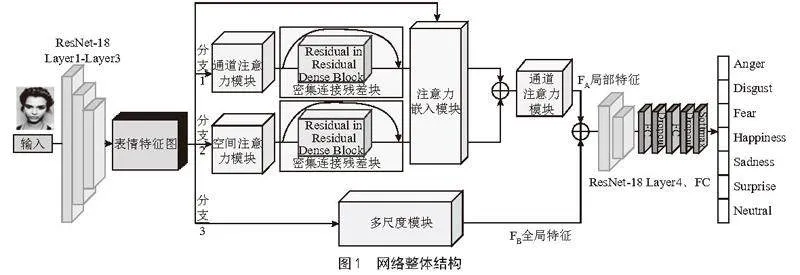
本文提出的基于注意力机制局部与全局特征融合的表情识别网络整体结构如图1所示。首先由ResNet-18的前三个卷积层模块组成特征提取网络来获取输入图片的浅层表情特征图,接着将得到的表情特征图采用一个三分支网络进行处理,分别进入通道注意力模块,空间注意力模块以及多尺度模块。通道注意力模块以及空间注意力模块所提取的局部特征,再由注意力嵌入模块做特征增强后进行第一阶段的特征融合,再将融合后的局部特征与多尺度模块提取的全局特征进行第二阶段的特征融合,以形成全面丰富的特征表示。最后将特征融合结果送到ResNet-18的最后一个卷积模块得到输出特征,再通过全连接层以及Softmax函数进而得到表情辨别的结果。在本文提出表情识别网络中,嵌入了数个注意力机制模块来提升模型的聚焦能力,并嵌入密集连接残差块来提高特征提取的质量和增加网络的稳定性,现对各个模块的结构设计进行说明。
1.2" 通道注意力模块
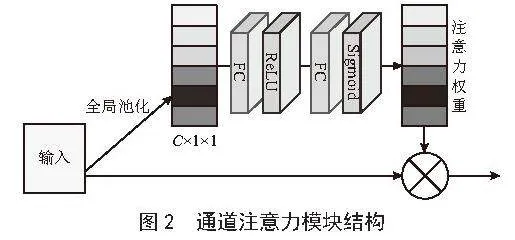
通道注意力模块结构如图2所示,通过使用全局平均池化(Global Average Pool)以及Reshape操作进行特征转换,将特征图大小变成C×1×1。接着引入了两个全连接(Fully Connected, FC)层,用于学习通道间的关系,得到一个与输入通道数相同的权重向量。这个权重向量可以被看作是每个通道的注意力权重。最后把注意力权重和特征图相乘,生成针对通道增强后的特征图。这种自适应的通道权重调整可以加强有用的特征,抑制无用特征,使网络更好地聚焦于重要的特征信息。
1.3" 空间注意力模块
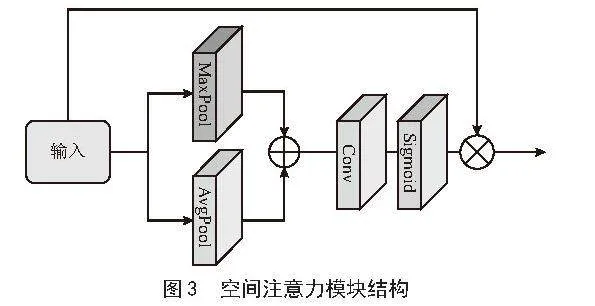
空间注意力模块结构如图3所示,通过使用最大池化(Maxpool)以及平均池化(Average Pool)将特征图变成H×W×1的大小。紧接着将两特征图进行特征融合,经过一个大小1×1的卷积,再使用Sigmoid激活函数产生出注意力权重。最后,将注意力的权重与特征图相乘,生成针对空间增强后的特征。
1.4" 多尺度模块
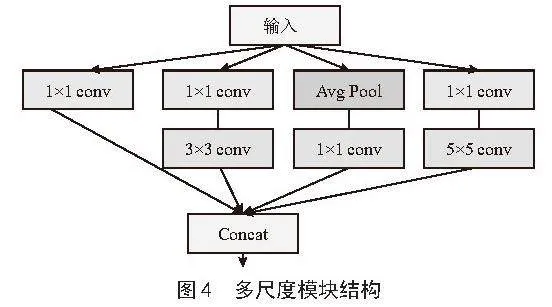
传统的卷积神经网络存在卷积核单一、只能获取某种固定尺度的特征的缺点,鉴于此,本文在表情识别模型中设计了多尺度模块,利用多分支卷积提取多尺度特征,增强网络的全局特征提取能力。本文设计的多尺度模块如图4所示,基于Inception结构[8]思想,通过使用1×1的卷积层对通道数做变换,然后再通过不同大小的卷积核并行卷积和池化,提取多尺度特征,最后将得到的不同尺度特征在通道维度进行合并,形成一个具有丰富特征表示的输出。
1.5" 注意力嵌入模块
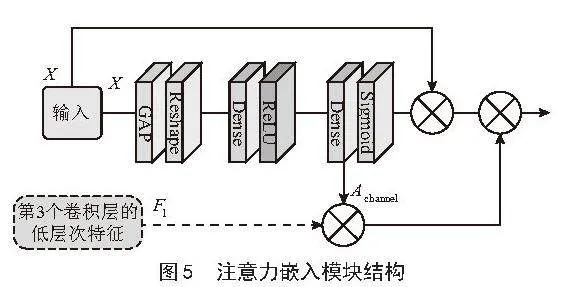
注意力嵌入模块(Attention Embedding Module, AEM)结构如图5所示。在AEM中,通过将高阶的特征与低阶的特征相乘,补足模型在卷积中可能丢失的特征信息,使得模型训练出的信息能够更加丰富。AEM运行的流程表达如下:
(1)
(2)
其中Fl是来自第3个卷积层的特征,X是来自密集连接残差块(Residual in Residual Dense Block, RRDB)的输入特征,GAP是全局平均池层,R表示Reshape层,DReLU是具有ReLU激活函数的Dense层,DSigmoid是具有Sigmoid激发函数的Dense层。
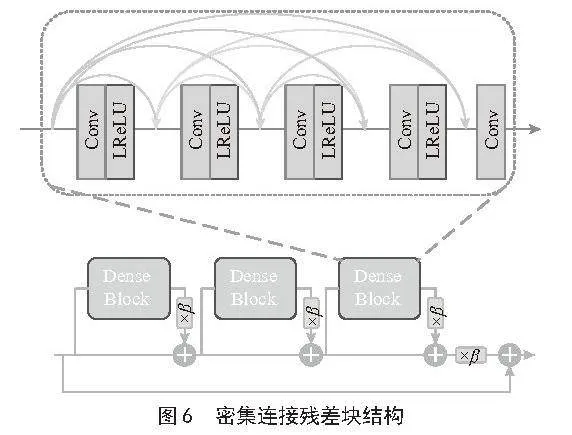
1.6" 密集连接残差块
为了更有效地提取丰富的表情特征并稳定网络训练过程,模型中嵌入了密集连接残差块(Residual in Residual Dense Block, RRDB),如图6所示,RRDB模块由三个Dense Block构成,每个Dense Block内部包含四组卷积层,每组均配以Leaky ReLU激活函数,并使用3×3的卷积核。每组卷积层包含32个卷积核,通过密集连接方式实现特征的有效复用,最后,模块通过一个3×3的卷积层进行特征整合。为了增强模型的稳定性,设计了一种机制,即在每个Dense Block的输出端,都会应用一个介于0和1之间的系数来进行残差缩放。这种设计思想源自密集连接策略和多级残差网络,RRDB模块通过在卷积层之间建立跳跃连接,充分利用每一层卷积特征。连接的构建不仅能够增强特征保留的完整性,还能确保信息在最小化噪声干扰的情况下高效流动。跳跃连接方式加强了特征间的传播,也在模块内部实现了信息的深层交互,使每一层信息都能参与到整体学习中,进而提高网络的表现力和泛化能力。这样的设计策略除了能稳定模型训练还能提升网络整体的训练速度以及最大限度地保留图像特征的同时,增进网络的深度。
2" 实验与分析
2.1" 数据集
为了验证所提方法的有效性,本文在人脸表情数据集RAF-DB[9](Real-world Affective Faces DataBase)上进行了实验。RAF-DB是一个大规模的真实世界非约束环境下的面部表情数据集,广泛应用于表情识别、情感计算、人机交互等领域的研究[6],同时因为图像来自真实的场景,反映了现实生活中的复杂情感表达,比实验室环境下拍摄的标准化数据更具有挑战性,其中包含大约3万张多样的脸部图片,基于众包标注,每张图片已由约40位标记者独立标记。RAF-DB包含了七种基本表情类别,分别是愤怒(Angry)、厌恶(Disgust)、恐惧(Fear)、高兴(Happy)、伤心(Sad)、惊讶(Surprise)和中性(Neutral),涵盖了人类情感表达的主要类型[10]。本文共使用15 339张被标注为不同表情类别的面部表情图像,其中用于训练的有12 271张,用于测试的有3 068张。
2.2" 实验结果与分析
实验使用Python语言和PyTorch深度学习框架,采用AutoDL服务器平台进行实验,实验环境为Liux操作系统,基础镜像为PyTorch 1.10.0,Python 3.8,Cuda版本为11.3,GPU RTX 4090 (24 GB),Xeon(R)Platinum 8362处理器。
在数据集上进行网络训练时,优化器采用随机梯度下降SGD优化器,初始学习率设置为0.01,将经过数据预处理的数据注入模型,每次按照批数量(batch size)64进行训练,训练一共迭代400次,动量设为0.9,权值衰减设为0.000 1,激活函数采用ReLU函数。
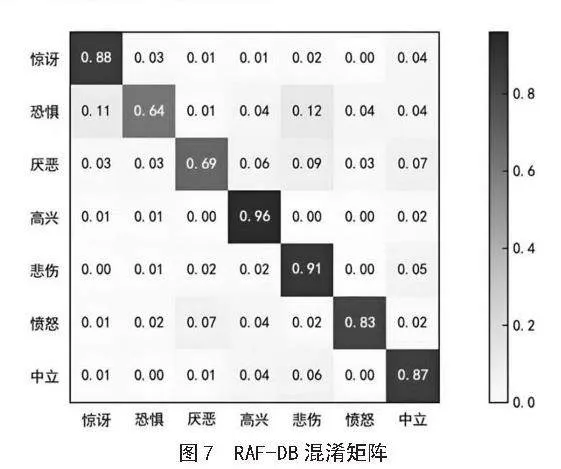
图7为模型在RAF-DB数据集上的混淆矩阵,它的每一行代表了数据的真实归属类别,每一列代表了分类器预测得到的类别。
由图7可见,“高兴”表情的识别准确率最高,达到了96%,其次是“悲伤”,准确率为91%,“惊讶”“中立”和“愤怒”的识别准确率也均超过了80%。相比之下,“恐惧”和“厌恶”这两种表情,由于外观变化不明显,识别率分别为64%和69%,且容易混淆,这可能与它们同属于消极表情类别,之间的表情相似性有关,基础网络对这两类表情的初始识别精度也较低。除此之外,其他表情类别被误识别的情况对比基础网络有明显改善,通过本方法,在充分提取局部特征的同时融合全局特征,使图像特征能最大限度得到利用,提高了表情识别准确率。
2.3" 消融实验
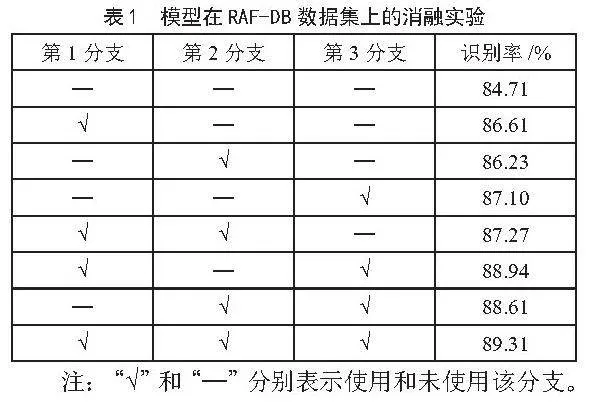
为了验证本文方法中三分支两阶段全局-局部特征融合表情识别模型的有效性,本节在RAF-DB数据集上,对模型进行了消融研究,探索基础网络和模块的不同组合,以验证和分析各个模块对识别结果的影响。结果如表1所示,在RAF-DB数据集上,采用ResNet-18作为基础网络,不添加任何模块时的准确度数据为84.71%;当仅使用第1个分支进行实验时,可以得到86.61%的效果;当仅使用第2个分支进行实验时可以达到86.23%;当仅执行第3个分支时可以达到87.1%;另外,也对第1、2分支和第1、3分支以及第2、3分支组合进行实验,分别的结果为87.27%,88.94%以及88.61%,本文所提出的完整模型(3个分支,2阶段融合)的识别率达到了89.31%,表现最佳。
3" 结" 论
本文针对传统DCNN主要关注整体图像特征提取而忽视局部细节的问题,提出了一种创新的网络模型,此模型将局部与全局特征分两个阶段进行融合。在全局特征提取方面,模型采用多尺度模块,能够捕获不同尺度的全局信息;另一方面,引入三重注意力模块,提取关键区域的局部特征,同时嵌入密集连接残差块,通过残差块的跨连传递不同层次的表情特征,在确保信息完整性的同时防止网络退化。实验结果表明本文所设计方法,在表情识别任务中表现出了较好的性能。
参考文献:
[1] 蒋斌,钟瑞,张秋闻,等.采用深度学习方法的非正面表情识别综述 [J].计算机工程与应用,2021,57(8):48-61.
[2] BARENTINE C,MCNAY A,PFAFFENBICHLER R,et al. A VR Teleoperation Suite with Manipulation Assist [C]//Companion of the 2021 ACM/IEEE International Conference on Human-robot Interaction.Boulder:ACM,2021:442-446.
[3] VERMA B,CHOUDHARY A. A Framework for Driver Emotion Recognition Using Deep Learning and Grassmann Manifolds [C]//2018 21st International Conference on Intelligent Transportation Systems(ITSC).Maui:IEEE,2018:1421-1426.
[4] LI T H,DU C F,NAREN T Y,et al. Using Feature Points and Angles between them to Recognize Facial Expression by a Neural Network Approach [J].IET Image Processing,2018,12(11):1951-1955.
[5] 蒋斌,崔晓梅,江宏彬,等.轻量级网络在人脸表情识别上的新进展 [J].计算机应用研究,2024,41 (3):663-670.
[6] JIANG M,YIN S L. Facial Expression Recognition Based on Convolutional Block Attention Module and Multi-feature Fusion [J].International Journal of Computational Vision and Robotics,2023,13(1):21-37.
[7] WANG K,PENG X J,YANG J F,et al. Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition [J].IEEE Transactions on Image Processing,2020,29:4057-4069.
[8] SZEGEDY C,LIU W,JIA Y Q,et al. Going Deeper with Convolutions [J/OL].arXiv:1409.4842 [cs.CV].(2014-09-17).https://arxiv.org/abs/1409.4842.
[9] LI S,DENG W H,DU J P. Reliable Crowdsourcing and Deep Locality-preserving Learning for Expression Recognition in the Wild [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:2584-2593.
[10] TENG J N,ZHANG D,ZOU W,et al. Typical Facial Expression Network Using a Facial Feature Decoupler and Spatial-temporal Learning [J].IEEE Transactions on Affective Computing,2023,14(2):1125-1137 :1125-1137.
作者简介:江涛(1983.10—),男,汉族,江西安福人,副教授,硕士,研究方向:深度学习、计算机视觉;李楚贞(1989.10—),女,汉族,广东潮州人,副教授,硕士,研究方向:深度学习。
收稿日期:2024-08-29
基金项目:广东理工学院创新强校工程科研项目(2022GKJZK004);广东理工学院人工智能重点学科项目(2024KDZK001);广东理工学院实验教学示范中心项目(SFZX202402)