

摘" 要:针对股票价格受复杂因素及投资者情绪影响导致的预测难题,提出了一种融合情感分析与Informer模型的股票价格预测方法。首先,运用AdaBoost模型从大量数据中提取关键特征变量,以降低模型过拟合的风险。其次,构建金融情感词典,对通过网络爬虫获取的金融文本数据进行情感分析,并计算情绪指数。最后,利用Informer模型对中信证券、华泰证券、东方财富三只具有代表性的证券龙头股票进行预测。评估结果显示,该方法有效提升了预测的准确性,验证了其有效性和实用性。
关键词:情感分析;股票预测;Informer模型
中图分类号:TP181;TP391;F832.5" 文献标识码:A" 文章编号:2096-4706(2025)04-0139-06
Stock Prediction Method Based on Sentiment Analysis and Informer
NI Xueyao
(School of Information Engineering, Huzhou University, Huzhou" 313000, China)
Abstract: Aiming at the prediction problem of stock price caused by complex factors and investor sentiment, a stock price prediction method based on sentiment analysis and Informer model is proposed. Firstly, the AdaBoost model is used to extract key feature variables from a large amount of data to reduce the risk of model overfitting. Secondly, a financial sentiment dictionary is constructed to analyze the sentiment of the financial text data obtained by the web crawler, and the sentiment index is calculated. Finally, the Informer model is used to predict three representative security leading stocks of CITIC Securities, Huatai Securities and Eastmoney Securities. The evaluation results show that the method effectively improves the accuracy of prediction, and verifies its effectiveness and practicability.
Keywords: sentiment analysis; stock prediction; Informer model
0" 引" 言
期投资者主要通过技术分析和经典时间序列模型预测股价。技术分析基于市场指标(如成交量和价格)来判断股价趋势。常用的时间序列模型包括ARIMA、GARCH和VAR。此外,灰色模型、BP神经网络和模糊理论也被应用于股价预测,但它们对非线性、长期时间序列的效果较差。随后,为了解决多重共线性问题,研究者们使用主成分分析(PCA)[1]或LASSO方法[2]进行变量的降维筛选。智能优化算法也被广泛应用于参数优化,尤其是果蝇算法、狼群算法、遗传算法等,常被用于优化机器学习模型(如BP神经网络、Elman神经网络和SVM)的最优权值结构[3]。由于单一模型各有局限性,有学者开始集成多个模型的预测结果,以提高预测准确性。此外,结合CNN和LSTM的方法也被提出,用于提取股价的图像和时序特征[4]。小波分析和经验模态分解(EMD)也被用于股价的预测与重构,并取得了良好的效果,尤其是EMD与LSTM、TSVR等模型的结合,被证实能有效预测股价[5]。
随着人工智能的发展,深度学习在股价预测中越来越受欢迎。LSTM能够捕捉股价序列中的关键信息,并克服RNN的梯度消失和梯度爆炸问题,因此在股价预测中得到了广泛应用。此外,研究者们将技术性指标和基本面数据与LSTM、GRU模型结合,构建了新的预测模型。同时,MDT和CBAM也被有效地融入LSTM模型中[6]。近年来,研究者们开始关注投资者的心理情绪因素,例如百度搜索指数和新浪微博情绪指数等,这些因素在股价预测中发挥了重要作用。此外,研究者还利用非结构化数据信息(如新闻资讯、股吧评论等)来提取情感时间序列,以增强预测效果[7]。
近年来,Transformer及其变体模型已成为时间序列预测领域的研究热点。这些模型凭借其独特的编码-解码结构和自注意力机制,能够有效捕捉时序特征的长时相关性,同时支持并行训练,并具备出色的特征提取、多模态融合和可解释性。例如,基于分层多尺度高斯改进的Transformer[8]能够很好地刻画股票价格的长短期相互依赖关系;而将经验模态分解(EMD)与嵌入时间注意力网络相结合的股票价格预测方法[9]则可以提高股票价格的预测准确率。此外,Stockformer模型[10]基于因果自注意力机制,挖掘股价与特征因素之间的时序依赖,并提出了一种基于趋势增强模块的预测方法,提供序列趋势特征,同时利用编码器直接提供输入特征的先验信息。
然而,根据以上文献,目前基于Transformer的股票预测研究仍较少,且在考虑特征变量时,尚未充分结合情绪分析。本文基于流行的Informer模型,综合考虑了基本面、技术分析和投资者情绪等多种因素作为特征,对股价进行分析和预测。为了量化投资者情绪,本文构建了金融情感词典库,并借助SnowNLP模型计算和分析投资者情绪。
1" 方法与原理
1.1" Informer模型
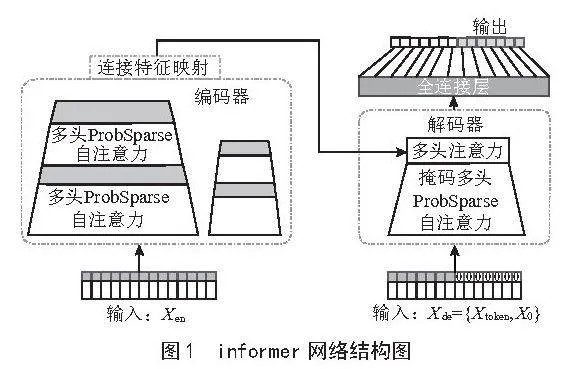
Informer模型[11]是一种专为时间序列预测设计的深度学习模型,它基于Transformer的序列建模方法,尤其擅长解决长序列预测的挑战。Informer模型采用了一种新的注意力机制,即概率自注意机制,该机制在降低时间复杂度和内存使用至O(nlogn)的同时,保持了出色的序列依赖对齐性能。
如图1所示,Informer模型的核心结构采用了编码器-解码器的框架。编码器和解码器均包含多层自注意力机制、全连接层和正则化层,这种设计使得模型能够全面捕捉不同时间尺度的信息。此外,一个跨时间步的交互层被引入在编码器和解码器之间,以有效捕捉时间步之间的复杂依赖关系。
ProbSparse Self-Attention是Informer模型中的一个关键组件。它通过稀疏化的方式有效减少了计算量和内存使用量,同时保持了模型的性能。Self-Attention Distilling技术则进一步提高了模型的计算效率和特征提取能力。此外,Informer模型通过复制和堆叠多个相同的层,增强了模型的鲁棒性和表达能力。
Informer模型的关键在于其独特的注意力机制和自适应能力。自注意力机制能够建模输入序列中每个元素与其他元素之间的关系,从而生成一个全局性的表征。这种机制使得模型能够学习并捕捉输入序列中不同位置之间的相关性,有效处理长期依赖问题。同时,Informer模型具备强大的自适应能力,无须针对特定任务设计特定的模型结构,即可适应不同的时间序列预测任务。其高效处理长期依赖和缺失值问题的能力,以及出色的计算性能和自适应能力,使得Informer模型在股票预测等时间序列预测任务中表现出色,为相关领域的研究和应用提供了新的思路和方法。
1.2" 基于情感分析方法
情感分析的一种主要方法是基于词典的方法,它通过对正、负两种情绪词汇的加权来判定一个句子的情绪极性。相对于机器学习方法,该方法具有更好的解释性。目前,已有大量开源的情感词典,例如Hownet和NTUSD等。然而,这些词典大多是针对通用情绪设计的,并不能涵盖所有具体领域的专业术语,比如金融领域的“牛市/熊市”和“背离”等。因此,研究者们常采用与领域相关的词典相结合的方法来进行情感分析。例如,Li等人[12]将Harvard心理情绪词典与Loughran–McDonald金融情绪词典相结合,探讨了财经新闻对股价的影响;Tan等人[13]针对财经新闻文章,提出了基于规则的情感分析方法。Day等人[14]基于四种数据集建立了一个情感词库,并利用Suffix Array算法对其进行扩展,用于情感分析。结果显示,利用财经领域词典进行情感分析能够有效提升投资者的投资收益率。此外,Zhang等人[15]基于六种词库构建了微博情感词典,并以此对微博文本进行情感分析。还有研究[16]通过构建心理情感词典,利用字典法分析Twitter信息对股市的影响;Xu等人[17]则通过计算情感词和语句词向量之间的相似性来进行情感分析,进而提取股票特征并预测股票走势。
2" 方法描述
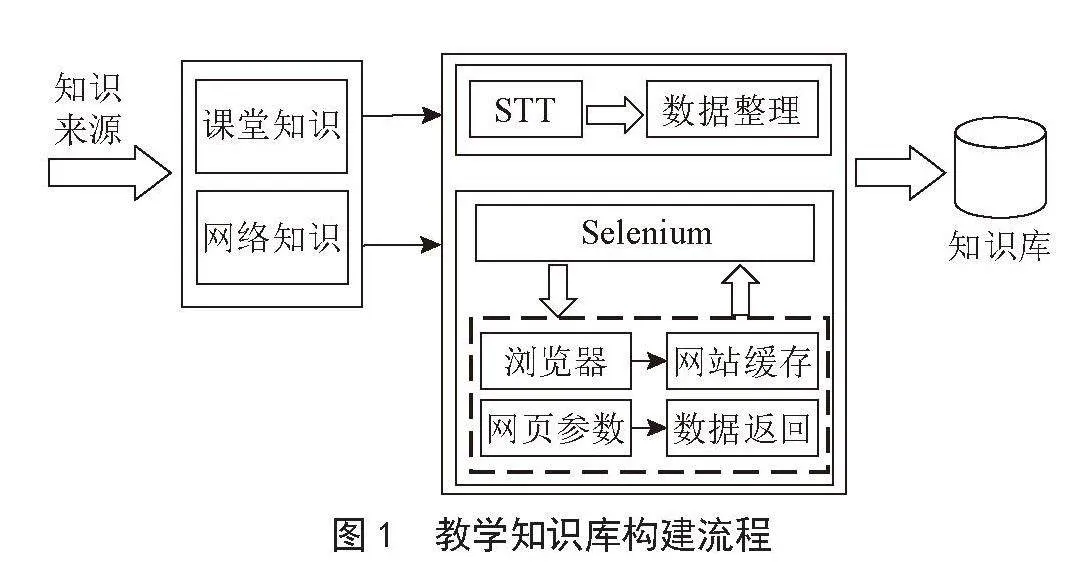
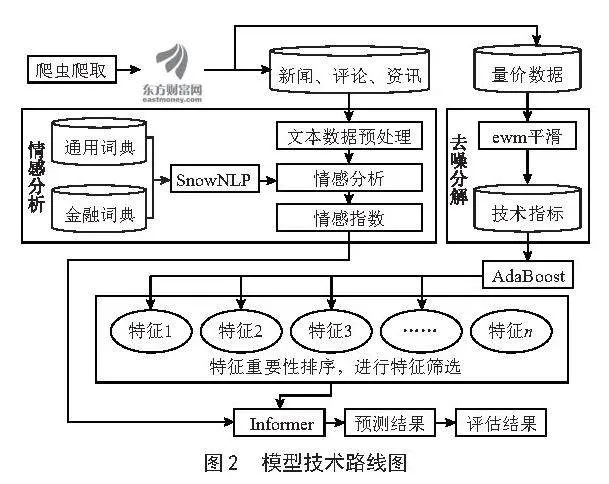
本文所采用的方法的主要步骤如下:
1)获取量价数据和基本面数据。
2)使用AdaBoost模型对技术指标特征进行重要性分析,提取相对重要的特征变量。
3)爬取东方财富网的财经新闻、评论和资讯。
4)使用哈工大讯飞SnowNLP模型进行情感分析,并计算情绪指数。
5)使用Informer模型对股价进行预测。
6)评估模型性能。
模型的技术路线图如图2所示。
2.1" 金融领域情感词典构建
证券投资者在进行投资时,往往会参考有关股票市场的消息,例如网络平台上的意见等。对股票市场消息进行情绪倾向性分析是其中的一个关键环节,对后续的预测有一定的指导作用。为了准确判断金融文本的情感倾向,我们采用了基于词典的方法。这种方法首先利用Jieba分词算法将文本切分成单词,并去除无意义的停用词。接着,我们将正面情绪词汇的初始权重设为1,负面情绪词汇设为-1。如果在表示情绪的词语前面有否定词,则将其权重调整为相反数。如果在情感词语之前存在程度副词,则将该情感词语的权重乘以对应的程度副词权重。最后,通过对一个句子中正面和负面单词的加权总和,我们可以判断句子的情感极性。
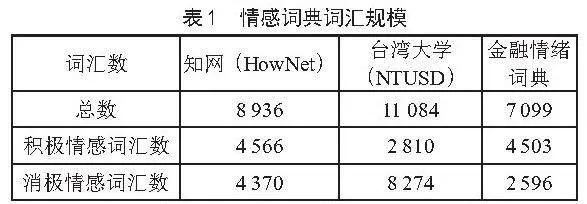
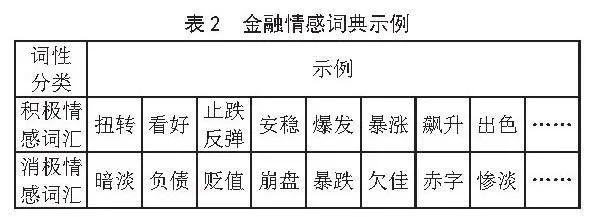
情感词典的构建对于情感分析的结果至关重要。在本文中,我们使用了多个情感词典,如表1所示,包括HowNet、NTUSD和金融情绪词典[18]。我们计划进一步融合通用词典和金融领域的情绪词典,以提升情感分析的准确率。
2.2" 情感指数计算
通过爬虫技术,从东方财富网等财经网站爬取新闻、资讯、评论等数据。其中,中信证券相关数据共爬取了434 134条,华泰证券相关数据共爬取了163 381条,东方财富相关数据共爬取了631 137条。对这些文本数据进行预处理,去除重复数据以及不符合要求的内容。随后,利用哈工大讯飞SnowNLP模型计算每条数据的情绪极性,判断其为积极或消极。
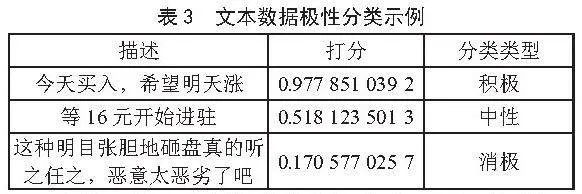
情感计算通常采用机器学习方法,通过分类模型(如SVM、朴素贝叶斯等)将文本划分为正面和负面,并训练这些模型以应用于实际数据,从而计算每条文本的情绪得分。另一种方法是构建情感词典,利用所建立的情感词典筛选出文本中的正面词和负面词。因此,构建一个完善且详尽的中文金融情感词典是非常重要的。本文结合这两种方法,利用建立的情感词典训练SnowNLP模型,并将其应用于情感分析。具体而言,打分大于0.55的文本被判定为积极情感(标记为1),打分小于0.45的文本被判定为消极情感(标记为-1),而打分在两者之间的文本则被判定为中性情感(标记为0),如表3所示。
最终,每个文本数据都会被赋予一个情感极性。股市历史数据是一个随时间变化的序列,因此需要每天计算情绪的波动趋势。情绪指标用于衡量事件与舆情的总体倾向,其计算式为:
(1)
其中:pn表示这一天中正面的新闻资讯、股吧评论总量,而nn表示这一天中负面的新闻资讯、股吧评论总量。
2.3" 变量筛选
为防止过拟合和多重共线性等问题,需要对各变量进行筛选。为此,采用Adaboost模型对各变量进行分类分析,评估各变量的重要性,并进行相关性和显著性检验。同时,利用常见的方差膨胀因子(VIF)对变量进行判定,以完成变量的筛选。
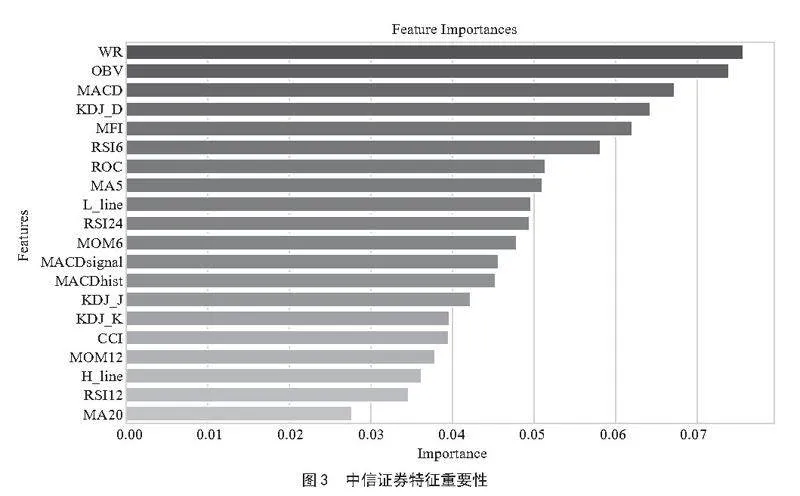
如图3所示,根据变量的重要性进行排序。中信证券的分析结果表明,按重要性从高到低排序,具有显著影响的变量依次为WR、OBV、MACD、KDJ_D、MFI、RSI6等。华泰证券的分析结果表明,按重要性由高至低排序,影响较大的特征依次为OBV、MFI、MOM12、CCI、MACD、WR等。东方财富的分析结果表明,按重要性从高至低排序,影响较大的变量依次为MFI、WR、OBV、ROC、KDJ_J、MACD等。
3" 实证研究
3.1" 评价指标
为更清晰、更精确地评判该模型的有效性,本文使用以下评价指标对该模型的预测效果进行评估。
3.1.1" MSE均方误差
MSE是一种用于衡量预测模型误差的指标,用于评估模型的预测能力。MSE越小,说明模型的预测能力越好。其计算式为:
(2)
3.1.2" RMSE均方根误差
RMSE是一种常用的衡量预测准确度的指标,通过计算预测值与真实值之间的平方误差,并平均后开方。其计算式为:
(3)
3.1.3" MAE平均绝对误差
MAE是一种衡量预测准确度的指标,计算预测值和真实值的绝对误差的平均值,可以用于评估预测模型的精度。MAE越小表示预测模型的精度越高。其计算式为:
(4)
3.1.4" MAPE平均绝对百分比误差
MAPE是一种衡量预测准确度的指标。它计算的是预测值与实际值之间的误差百分比平均值,不受量纲的影响,可以用于评估预测模型的精度。MAPE越小表示预测模型的精度越高。其计算式为:
(5)
3.1.5" R2拟合优度
决定系数(R2)是用于衡量回归模型拟合数据好坏的一个统计量。R2的值介于0和1之间,值越接近1,说明模型拟合得越好。计算式为:
(6)
3.2" 预测分析
由于中信证券、华泰证券和东方财富是我国证券行业的龙头企业,具有一定的代表性,因此本文选取了中信证券、华泰证券和东方财富这三支个股的量价数据作为研究对象。研究数据涵盖2013年至2023年的量价数据,并计算了股民们较为常用的技术指标。由于股票价格属于时间序列预测,需要保证其时序性,因此选择前80%的数据作为训练集,中间10%的数据用于验证,最后10%的数据用于预测和评估。利用滚动预测法,基于前64天的特征自变量信息,预测未来5天的收盘价。由于Informer模型的特性,需要额外回顾5天的数据。基于前期研究结果,中信证券选取了以下变量:OBV、MOM6、ROC、L_line、RSI12、KDJ_D;华泰证券选取的特征变量包括:OBV、MFI、MOM12、CCI、MACD、WR;东方财富选取的特征变量包括:MFI、WR、OBV、ROC、KDJ_J、MACD。此外,还结合了根据金融词典计算得到的情绪指数(Emotion)和初始的量价数据,共13个特征变量。
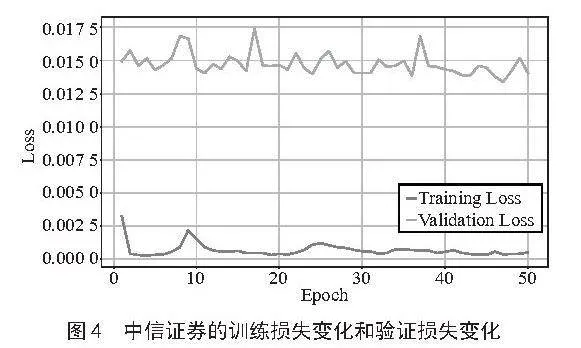
随后,将数据集输入Informer模型进行训练。图4展示了中信证券的训练损失变化和验证损失变化。
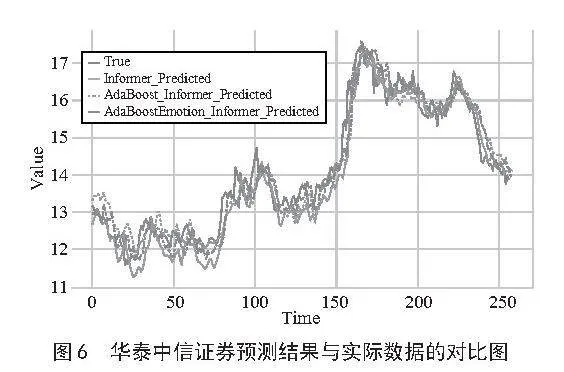
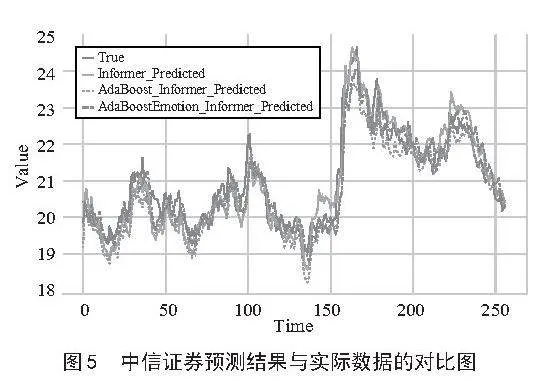
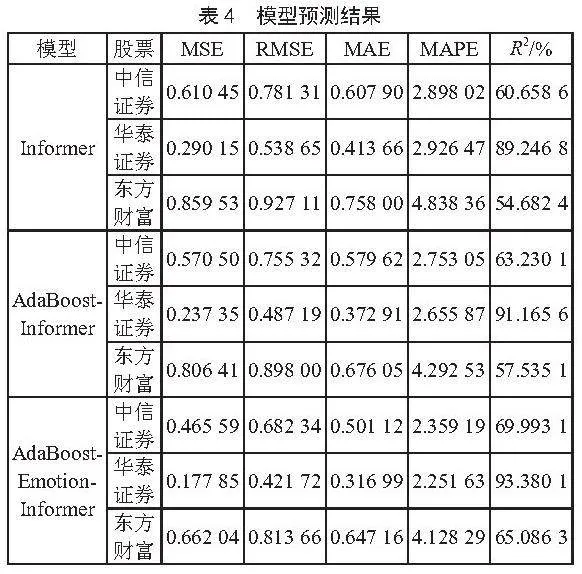
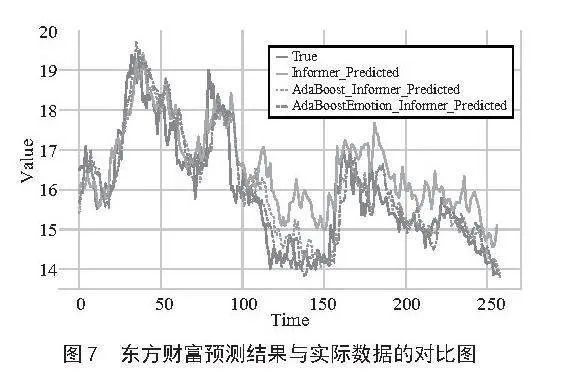
图5至图7分别展示了三支股票的预测结果与实际数据的对比曲线图。从图中可以看出AdaBoost-Emotion-Informer模型的预测结果与真实值最接近,误差最小。
在使用Informer模型时,我们发现即使不加入情感因素,Informer的预测能力已经很出色。接下来,我们对融入了AdaBoost算法和情感指数的模型进行了比较,具体评测指标的数值如表4所示。从表中可以看出,在加入AdaBoost算法和情感指数后,模型的预测性能得到了显著提升。具体来说,AdaBoost-Emotion-Informer模型在所有5个评估指标上均表现更好。这表明融入情感因素和AdaBoost算法后,Informer模型的预测能力得到了进一步增强。
4" 结" 论
基于中信证券、华泰证券和东方财富等证券公司的股价变化,本文从技术指标、基本面数据、投资者情绪和关注度等方面进行了深入分析,并开展了相关的实证研究,取得了一系列具有重要价值的研究结果:
1)多源数据能够更好地挖掘和解释数据的内在特征,并提高股市预测的准确性。在股市预测中,需要重视与股票市场走势紧密相关的技术指标,例如CCI、MACD、MFI、ROC等。在个股投资时,投资者应综合考虑基本面数据和技术指标,同时注意不同股票可能适用不同的技术指标。
2)情绪指数对股票市场至关重要,它与股价波动紧密相关。投资者应关注股市情绪变化,特别是能反映投资者情绪的指数,并且在市场出现异常情绪变化时,应及时调整投资策略以避免亏损。
本文通过Informer模型,利用过去64个交易日的数据对未来5个交易日的走势进行预测。虽然该模型能够有效地把握股市的长期走势,但存在时效性和粒度较大的问题。为了更准确地揭示多源数据对股市波动性的长期影响,未来研究可以考虑采用更短的时间周期,从而更深刻地认识多源数据对股市波动性的直接作用与动态影响。
参考文献:
[1] 谢心蕊,雷秀仁,赵岩.MI和改进PCA的降维算法在股价预测中的应用 [J].计算机工程与应用,2020,56(21):139-144.
[2] 胡聿文.基于优化LSTM模型的股票预测 [J].计算机科学,2021,48(S1):151-157.
[3] 尹湘锋,崔浩锋,文雪婷.基于两类核函数的TSVR在股价预测中的比较 [J].统计与决策,2021,37(12):43-46.
[4] 方义秋,卢壮,葛君伟.联合RMSE损失LSTM-CNN模型的股价预测 [J].计算机工程与应用,2022,58(9):294-302.
[5] 刘铭,单玉莹.基于EMD-LSTM模型的股指收盘价预测 [J].重庆理工大学学报:自然科学,2021,35(12):269-276.
[6] 曹超凡,罗泽南,谢佳鑫,等. MDT-CNN-LSTM模型的股价预测研究 [J].计算机工程与应用,2022,58(5):280-286.
[7] 许雪晨,田侃.一种基于金融文本情感分析的股票指数预测新方法 [J].数量经济技术经济研究,2021,38(12):124-145.
[8] DING Q G,WU S,SUN H,et al. Hierarchical Multi-Scale Gaussian Transformer for Stock Movement Prediction [C]//Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Special Track on AI in FinTech.Yokohama:IJCAI,2020:4640-4646.
[9] 林昱,常晋源,黄雁勇.融合经验模态分解与深度时序模型的股价预测 [J].系统工程理论与实践,2022,42(6):1663-1677.
[10] 任佳屹,王爱银. 融合因果注意力Transformer模型的股价预测研究 [J].计算机工程与应用,2023,59(13):325-334.
[11] ZHOU H Y,ZHANG S H,PENG J Q,et al. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting [C]//Proceedings of the AAAI Conference on Artificial Intelligence [S.I.]:AAAI Press,2021,35(12):11106-11115.
[12] LI X D,XIE H R,CHEN L,et al. News Impact on Stock Price Return Via Sentiment Analysis [J].Knowledge-Based Systems,2014,69:14-23.
[13] TAN L I,PHANG W S,CHIN K O,et al.Rule-Based Sentiment Analysis for Financial News [C]//2015 IEEE International Conference on Systems, Man, and Cybernetics.Hong Kong:IEEE,2015:1601-1606.
[14] DAY M Y,LEE C C.Deep Learning for Financial Sentiment Analysis on Finance News Providers [C]//2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining(ASONAM). San Francisco:IEEE,2016:1127-1134.
[15] ZHANG S X,WEI Z L,WANG Y,et al. Sentiment Analysis of Chinese Micro-Blog Text Based on Extended Sentiment Dictionary [J].Future Generation Computer Systems,2018,81:395-403.
[16] LI M,YANG C,ZHANG J,et al.Stock Market Analysis Using Social Networks [C]//Proceedings of the Australasian Computer Science Week Multiconference.New York:ACM,2018:1-10.
[17] XU J W,MURATA T. Stock Market Trend Prediction with Sentiment Analysis based on LSTM Neural Network [C]//International Multiconference of Engineers and Computer Scientists.Hong Kong:IAENG,2019:475-479.
[18] 姚加权,冯绪,王赞钧,等.语调、情绪及市场影响:基于金融情绪词典 [J].管理科学学报,2021,24(5):26-46.
作者简介:倪学曜(1998.03—),男,汉族,浙江湖州人,硕士研究生在读,研究方向:股票预测与量化交易。
收稿日期:2024-09-26