中图分类号:TP391;TP301.6;TP311.1 文献标识码:A 文章编号:2096-4706(2025)08-0106-06
Abstract: Inorder to extract valuable information from Web pages eficientlyand accurately,this paper proposes a Web content parsing methodbasedonDeep Learning.This methodaims to extracttext information fromcomplex HyperText MarkupLanguage(HTML).This methodcombines the feature extractionabilityofDeepLeaming,NaturalLanguageProcessing technologyandlayoutinformationinHMLdocumentstoconstructaMulti-LayerNeuralNetworkmodel,soastoealizete recognitionof Webcontent.The experimentalresultsshowthatcompared withthe traditional Webcontentextraction method based on text density, this method has obvious advantages in accuracy,adaptability and robustness.
Keywords:Web content parsing;DeepLearning; Neural Network; adaptability
0 引言
随着互联网的发展,网页的功能、样式结构变得越来越复杂。网页内常常包含大量其他信息:广告、外部链接、导航栏等,而一般来说,人们关心的只有网页的正文内容。所谓正文,是人在阅读网页时关心的内容信息,包括目标文字、图片、视频等。但本文研究的正文范围仅限于文字。网页作为互联网信息的主要载体,包含了丰富的文本、图像、视频等多媒体数据。然而,网页内容通常以非结构化的超文本标记语言(Hyper TextMarkup Language,HTML) 文档形式存在,直接从中提取有效信息具有一定的难度。
根据HTML结构的内部特征完成内容提取的方法称为包装器方法。该方法通过分析网页代码的方式手动配置HTML页面的正则表达式,并采用XML路径查询语言XPath实现程序自动或半自动内容提取。包装器方法[虽然在一定程度上能够解决问题,但在处理复杂多变的网页结构时往往显得力不从心,或者需要大量的人工维护和规则更新。郑志建等[设计了一种算法,该算法通过对比HTML源代码,能够自动且有效地生成XPath代码,取得了显著成效。陈迎仁等[3提出了一种创新方法,该方法利用特征相似度原理,实现了旧包装器对新页面信息的自适应提取。
2003年,微软公司亚洲研究所提出了一种对网页进行视觉分块,算法——VIPS算法。该算法的思想是模仿人类看网页的动作,基于网页视觉内容结构信息结合DOM树对网页进行处理。简单地说,就是把页面切割成不同大小的块,在每一块中又根据块内网页的内容和CSS样式渲染成的视觉特征将其分成小块,最后建立一棵树。但是,VIPS必须完全渲染一个页面才能对其进行分析。这就导致VIPS算法占用的内存资源以及CPU运算资源较多。由于该算法在提取一个网页时消耗的资源过多,所以这种网页提取方法在面对海量网页处理时并不适用。张鑫等提出了一种基于视觉特征和领域本体的Web信息抽取算法,该算法利用HTML标签和层叠样式表( Cascading Style Sheets, CSS)所定义的网页字体、背景颜色、分块等页面视觉特征准确划定信息抽取区域。
此外,基于文本及符号密度的网页正文提取方法也普遍存在于网页内容的自动提取中[8-9]。该种方法依赖于网页中文本和符号(如标点符号)的密度来区分正文内容和网页中的其他噪声信息(如广告、导航栏、版权信息等)。该方法通过计算网页中文本和符号的密度,来识别并提取网页中的正文内容。但对于一些特殊格式的网页,如使用大量图片、视频或复杂布局的网页,或者在噪声密度较高或正文内容较为稀疏的网页结构中,其识别效果可能不佳。
本文提出了一种基于深度学习的网页内容解析方法,该方法利用神经网络模型自动学习网页正文特征和结构特征,实现对网页内容的快速、有效提取。
1" 基于深度学习的网页内容解析方法
1.1" 方法概述
本文提出的基于深度学习的网页内容解析方法主要包括以下几个步骤:网页数据采集与预处理、特征提取、模型构建与训练、结果解析与输出。本文致力于将网页内容的提取转化为一项文本分类任务,具体流程概述如下:首要步骤是对网页的字符串内容进行解析,将其细致地分割成多个文本块单元。紧接着,针对每一个独立分割出的文本块,采用一个深度学习模型执行分类操作,此模型会输出一个布尔值结果:若结果为L,则意味着该文本块为正文;反之,若结果为D,则该文本块非正文。深度学习作为文本分类领域的得力助手,在此过程中发挥了关键作用。此外,本文所提出的方法不仅依赖于深度学习模型,还巧妙地利用了HTML文档的树结构属性来表示文本块的从属关系编码。HTML文档可以被解析成一个DOM(文档对象模型)树结构,其中树的每一个节点都对应于一个特定的HTML标签(例如lt;pgt;、lt;divgt;、具有特定class属性的标签等)。采用从DOM树的根节点出发,直至目标文本块所在节点的标签序列,作为该文本块的标签路径表示。这一标签路径不仅反映了元素在HTML结构中的位置,还隐含了它们之间的层级从属关系,为精确提取网页正文提供了有力支持。
1.2网页数据采集与预处理
首先,我们利用Python环境和selenium自动化测试工具,调用无头浏览器发起网页访问请求。无头浏览器通过模拟浏览器操作,打开待提取的网页地址,然后我们使用模拟浏览器对象的page_source属性获取经过动态渲染的网页HTML文档源代码。这满足了网页数据采集的“静态可采、动态可采、可见即可采、可见即可得”的核心需求。
接下来,我们将网页的HTML内容转换为纯文本形式,并进行清洗和格式化处理,去除无关的标签、脚本和样式等信息。这一步是后续处理的基础,直接影响到特征提取的效果。
吕芳证明,网页结构和视觉特征能有效地帮助识别主要内容。为了保存网页布局信息,本方法依靠DOM树结构将网页转换为文本序列。我们使用Python的BeautifuISoup库解析HTML文档,对树结构节点进行深度优先遍历,将其作为额外的位置信息来表示。同时,我们移除JavaScript脚本、CSS样式表、注释等非文本内容,但保留重要的HTML标签(如lt;titlegt;、lt;hlgt;至lt;h6gt;、lt;pgt;、lt;agt;等),用于后续的特征提取。提取HTML标签内的文本内容,去除多余的空格、换行符和特殊字符。对每一行标签路径进行标注:如果这一个文本块是正文,标为1;如果不是,则标为0。通过标注,一个文本块被定义为正文或非正文,这些标签会被用于深度学习模型的训练。
最终生成各节点的文本序列X=xl,X2,X3,…,x。),其中n为数字保留的DOM节点数。
1.3特征提取
XLM-Roberta是Facebook AI团队于20 1 9年11月发布的语言模型,它依赖于掩码语言模型目标,能够处理100种不同语言的文本。相较于原始版本,XLM-Roberta的最大更新是训练数据量的显著增加。经过清洗和训练的常用爬虫数据集占用空间高达2.5 TB。
使用XLM-Roberta模型算法对第一层模型预处理生成的文本序列x进行编码,形成768维特征向量,用h表示。计算公式如下:

其中,i为节点下标。
Transformer模型是一种基于自注意力机制的深度学习模型,广泛应用于自然语言处理任务中。它由编码器( Encoder)和解码器(Decoder)组成,通过自注意力机制捕捉输入序列中不同位置之间的关系,从而处理序列数据。在Transformer模型中,编码器和解码器都由多个堆叠的层组成。每个层都由两个子层构成:多头部自注意力层(Multi-head Self-Attention Layer)和前馈神经网络层(Feed-ForwardNeural Network Layer)。自注意力层允许模型在处理输入序列时对不同位置的信息进行加权考虑,而不仅仅依赖于序列的位置顺序。它通过计算注意力权重,使输入序列的每个位置与其他位置进行交互。这样的注意力机制能够捕捉到序列中重要的上下文信息,从而在处理长距离依赖性时表现优异。
在编码器中,输入序列经过多个编码器层的处理,每一层都会生成一个新的特征表示。编码器的输出可以用于各种下游任务,如文本分类、命名实体识别等。在解码器中,除了自注意力层和前馈神经网络层外,还包含一个编码器一解码器注意力层( Encoder-DecoderAttention Layer)。
具体地,使用3层的Transformer模型进行编码,以解决网页结构的位置信息与特征信息融合的问题,最终生成256维特征向量h。
1.4分类器
前馈神经网络(Feedforward Neural Network,FNN)或多层感知器(Multilayer Perceptron,MLP)是深度学习中一种基本且广泛应用的神经网络架构,尤其适用于分类和回归任务。MLP由多个层次组成,包括输入层、一个或多个隐藏层以及输出层。每个层中的神经元(节点)与前一层的神经元全连接,并且信息只能向前传播(即,从输入层到隐藏层再到输出层)。使用前馈神经网络或多层感知器( MultilayerPerceptron,MLP)作为分类器时,采用Sigmoid函数作为激活函数,输出目标数为2,分别代表正文(1)和其他(0)。计算方法按照如下公式:
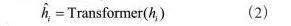
使用交叉熵损失函数在训练阶段通过反向传播调整网络参数。计算公式如下:
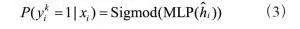
其中,yk为标记标签,它是一个二进制值,取o或1;yk=l为第f个节点属于第k类,c为交叉熵损失函数。
Adam算法与传统的随机梯度下降不同,随机梯度下降保持单一的学习率(即alpha)来更新所有的权重,但学习率在训练过程中不会改变,而Adam算法通过计算梯度的一阶矩估计和二阶矩估计,为不同的参数设计独立的自适应性学习率。因此,我们选择Adam作为优化算法。
1.5模型构建与训练
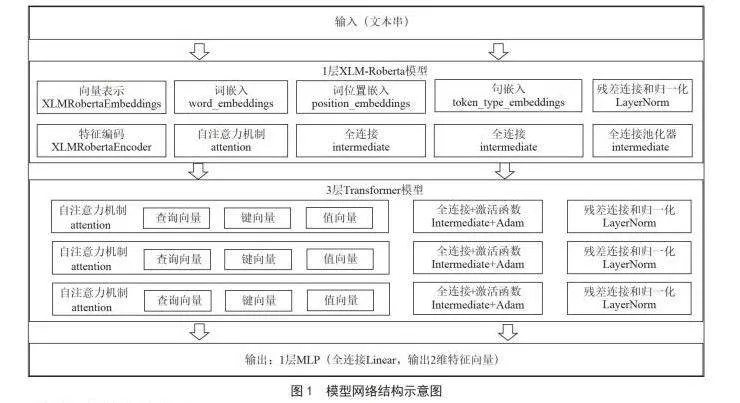
训练过程中,我们将训练样本集中的样本输入模型中进行前向传播,采用损失函数计算与目标类之间的差距,并结合反向传播算法,调整整个网络的参数。向量化过程使用l层XLM-Roberta模型生成768维特征向量,该向量随后经过3层Transformer网络模型处理,其中隐藏层单元数为256,输出为2个类别(是正文或不是正文)。优化算法选取Adam算法。进行迭代训练时,初始学习率设置为0.05,学习率调整遵循余弦衰减时间表,峰值速率在0.000 6处偏移。当误差下降到一定程度或不再下降时,训练结束。网络模型结构图如图1所示。
2.2数据集与评价指标
2.2.1" 数据集
本文采用自己采集的网页数据集进行实验,该数据集涵盖新闻与政务新闻两种类型的网页。数据来源包括贵州省人民政府网、新浪新闻、今日头条、网易新闻、凤凰网、人民网以及四川省人民政府网。我们将数据集按照7:3的比例划分为训练集和测试集。数据集的具体内容和实验分配如表2所示。
2.2.2评价指标
效果评估采取了模糊字符串匹配的方式。为了消除分割方式造成的误差,对测试集进行了统一处理,将正文的空格和换行符全部去除,但这样对比的字符串可能长度不同,因此无法使用Fl分数作为相似度衡量指标,而是使用Fuzzy Wuzzy来实现模糊字符串匹配。Fuzzy Wuzzy是一个基于莱文斯坦(Levenshtein)距离的字符串相似度衡量工具,而Levenshtein距离衡量的是一个字符串至少需要变换几个字符才能变成另一个字符串。Fuzzy Wuzzy衡量字符串相似度的度量是Levenshtein距离和两个字符串平均长度的比率,这个得分越高,说明两个字符串越相似。
本文中,真实正文标签内容记为v,模型提取内容记为可,两个字符串v和可之间的Levenshtein距离可以表示为,两个字符串的相似度计算公式如下:
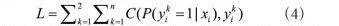
采用值界定法判断识别结果是否正确,公式如下:

2.3实验研究与分析
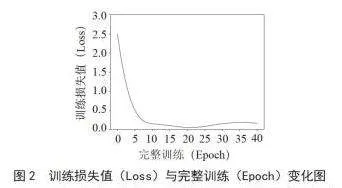
在训练初期,随着Epochs的增加,训练损失值通常会迅速下降,这表明模型正在逐渐学习数据的特征。虽然模型己经学习到了大部分数据特征,但仍有部分难以拟合的复杂特征需要进一步优化,因此训练损失值在训练过程中会持续下降,但速度会变慢。为了防止过拟合,我们采用强制停止策略,即当验证损失在连续几个Epoch中没有改善时停止训练,以获得最佳的模型。训练过程如图2所示。

如表3所示,在本文中自制的中文数据集上进行测试,本文提出的基于深度学习的网页内容解析方法相较于传统方法具有更高的准确率和效率。
在所有阈值下,本文方法的准确率均明显高于GNE[8]方法。随着阈值的增加,两种方法的准确率均有所下降。然而,本文方法的下降幅度相对较小,说明其在高阈值下仍能保持较好的性能稳定性。对于GNE[8]方法,当阈值从0.7增加到0.9时,准确率下降了4.7%,这表明该方法对阈值的变化较为敏感。对于本文方法,在阈值从0.7增加到0.9的过程中,准确率下降了1.6%,这表明本文方法在不同阈值下具有更好的鲁棒性和适应性。
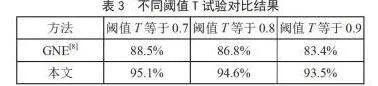
本次试验结果表明,本文方法在不同阈值下均表现出优于GNE[8]方法的性能。具体来说,本文方法在准确率、稳定性和鲁棒性方面均表现更佳。
3结论
本文提出的基于深度学习的网页内容解析方法虽然取得了一定的成果,但仍存在一些不足之处。例如,对于某些极端复杂的网页结构,模型的解析能力仍有待提高;同时,模型的训练过程需要消耗大量的计算资源,如何进一步优化模型结构和训练过程是一个值得深入研究的问题。未来将继续研究更加高效的深度学习模型和技术,以进一步提高网页内容解析的准确性和效率;同时关注网页数据与结构的特征表示,研究如何构建具有更强自适应能力的模型。
参考文献:
[1]BARBARESIA.Trafilatura:A Web ScrapingLibrary and Command-Line Tool for Text Discovery and Extraction [C]// In Proceedings of the Joint Conference of the 59th Annual Meeting oftheAssociation for ComputationalLinguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations.Online:Association for Computational Linguistics,2021:122-131.
[2]郑志建,俞发仁,魏晓微,等.基于Python的职位网站爬取设计与实现[J].计算机与网络,2024,50(1):24-27.
[3]陈迎仁,郭莹楠,郭享,等.基于特征相似度计算的网页包装器自适应[J].计算机科学,2021,48(S2):218-2 2 4 + 2 5 7
[4]SONGRH,LIUHF,WENJR,etal.LearningBlock ImportanceModels forWeb Pages[C]//Proceedingsof the13th internationalconferenceonWorldWideWeb.ACM,2004:203-211.
[5]吕芳.基于视觉特征的钓鱼网页相似性计算技术研究[D].哈尔滨:哈尔滨工业大学,2015.
[6]沈怡涛.基于视觉特征和文本结构分析的中文网页自动摘要技术研究[D].上海:华东师2范大学,2014.
[7]张鑫,陈梅,王翰虎,等.基于视觉特征和领域本体的Web信息抽取[J].计算机技术与发展,2011,21(2):58-6 1 + 6 5
[8]洪鸿辉,丁世涛,黄傲,等.基于文本及符号密度的网页正文提取方法[J]电子设计工程,2019,27(8):133-137.
[9]杨大为,王诗念,包立岩,等.基于文本及HTML标签密度的网页正文提取[J].沈阳理工大学学报,2022,41(4):14-19.
[10]CONNEAUA,KHANDELWALK,GOYALN,et al.Unsupervised Cross-lingual RepresentationLearningat Scale [J/OL].arXiv:1911.02116 [cs.CL].[2024-10-18].https://arxiv.org abs/1911.02116?file=1911.02116.
作者简介:袁公萍(1992一),男,汉族,贵州榕江人,工程师,硕士研究生,研究方向:数据采集、深度学习、机器学习;谢红韬(1992一),男,汉族,贵州遵义人,工程师,硕士研究生,研究方向:机器学习;舒玉淋(1992一),男,汉族,贵州镇远人,工程师,硕士研究生,研究方向:大数据、机器学习;周维(1992一),男,汉族,湖北荆州人,工程师,硕士研究生,研究方向:统计分析、深度学习、机器学习。