中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)08-0111-06
Abstract: With the popularity of intermet music services,how to accurately recommend music for users has become an importantresearch topic.This paperaimsattheshortcomingsof theexistingmusicrecommendationsystemindealingwith problemssuchascold-startanddatasparsity.AmusicrecommendationalgorithmbasedonNon-NegativeMatrixFactorization (NMF) is proposedThe studyusesadataset fromacolaborationproject with NetEaseCloud Music,whichcontains more than 57 millon music interactionrecordsofmore than2millonusers.Byintroducinguserbehavior weightsandsparseconstraints, weighted NMFand sparse NMF models are constructed respectively.The experimental results show that the weighted NMF performs best when dealing with high-frequency interactive users,and the F1 score reaches 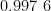 .The sparse NMF has more advantages in dealing withcold-start users.Forusers with fewer than1O interactions,therecommendation accuracy is 1 5 % higher than that of the basic NMF.The research results provide new solutions for the optimization of the music recommendation system.
.The sparse NMF has more advantages in dealing withcold-start users.Forusers with fewer than1O interactions,therecommendation accuracy is 1 5 % higher than that of the basic NMF.The research results provide new solutions for the optimization of the music recommendation system.
Keywords:Machine Learning; music recommendation model; NMl
0 引言
随着互联网和信息技术的快速发展,数字音乐产业得到了迅猛扩展。用户通过流媒体平台能够随时随地获取数百万首歌曲的服务。然而,随着音乐库规模的增加,用户面临的信息过载问题日益严重,如何为用户推荐其可能感兴趣的音乐成为一个重要的研究课题[]。推荐系统作为解决此类信息过载问题的核心技术,已经在电子商务、电影、新闻等多个领域得到了广泛应用[2]。
本研究的主要目标是通过研究基于用户行为数据的NMF算法,探讨其在音乐推荐系统中的应用效果。通过对比加权NMF和稀疏NMF两种算法的性能,揭示它们在处理不同用户行为数据时的适用场景和优势,旨在为提升音乐推荐系统的精度与个性化提供有效的解决方案[3]。
1文献综述
推荐系统自20世纪90年代以来,逐渐发展成为解决信息过载问题的核心技术。最早的推荐系统主要基于内容过滤(Content-based Filtering)[4],然而,内容过滤在处理冷启动和数据稀疏性问题上存在一定的局限性[5]。为了克服这些问题,协同过滤(CollaborativeFiltering)逐渐成为主流方法之一,主要分为基于用户的协同过滤和基于项目的协同过滤[7]。近年来,基于深度学习的推荐系统也逐渐崭露头角,通过结合神经网络和矩阵分解,进一步提高了推荐精度[8]。
在音乐推荐领域,非负矩阵分解(NMF)已被证明能够有效处理用户的隐式反馈数据,如点击、收藏、播放行为等。传统的奇异值分解(SVD)尽管能够有效分解用户和物品的交互矩阵,但由于分解结果中存在负值,导致结果的可解释性较差[]。Hu等人提出了基于NMF的隐式反馈矩阵分解方法,通过引入置信度参数来处理用户隐式行为的不同权重,从而提高推荐精度[1]。NMF强制分解矩阵中的元素为非负值,保证了结果的可解释性,从而在推荐系统中得到了更广泛的应用。此外,NMF通过提取用户和物品的隐含特征,能够处理更复杂的用户行为数据,如用户的隐式反馈[12]。
尽管NMF在推荐系统中取得了良好的效果,但其在处理稀疏性和冷启动问题上仍存在一定局限性。研究人员提出了多种改进模型,如加权NMF和稀疏NMF,以适应不同的推荐场景。加权NMF通过对用户行为数据赋予不同的权重,增强了模型对关键行为的捕捉能力[13]。稀疏NMF 则通过引入L1正则化项,控制分解矩阵的稀疏性,在处理维度高、数据稀疏性强的数据集时表现出色[14]。近年来,结合加权NMF和稀疏NMF的方法逐渐受到关注。这些方法在保证稀疏性的同时,对用户行为数据进行加权处理,从而提高推荐精度和结果的可解释性。
2 研究方法与设计
本章详细介绍了研究的整体方法论设计、数据处理过程以及模型构建方案,为实现音乐推荐系统的优化奠定了理论和技术基础。
2.1 研究方法概述
本研究采用定量分析方法,以非负矩阵分解(NMF)为基础构建音乐推荐系统。研究重点关注两种改进的NMF模型:加权NMF和稀疏NMF。这两种模型分别针对用户行为权重差异化和数据稀疏性问题进行了优化,通过系统的对比分析验证了其在提升推荐系统准确性和个性化程度方面的效果。
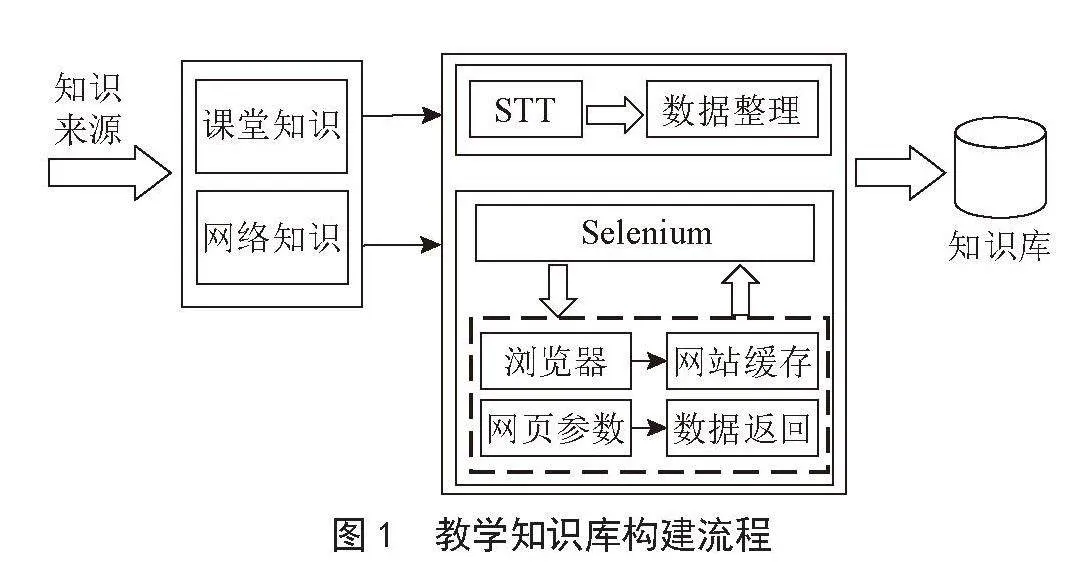
遵循数据完整性、特征显著性、模型可解释性和实验可重复性四项原则,确保研究的科学性和可靠性。本研究采用“数据收集一预处理一建模一验证一优化”的技术路线,如图1所示。
数据收集→数据预处理→模型构建 模型验证 模型优化
2.2 数据集介绍与描述
在开展具体的模型研究之前,首先需要对研究所使用的数据集进行全面的了解和分析,以确保后续建模的科学性和可靠性。
2.2.1数据来源与基本情况
本研究所使用的数据集来源于INFORMS与网易云音乐的合作项目,具有全面且丰富的数据特征。在时间维度上,数据收集覆盖了2019年11月1日至30日的完整月度周期,保证了数据的时间连续性和完整性。在用户规模方面,数据集包含了2085533名活跃用户的行为记录,涵盖范围广泛且具有代表性。数据总量达到5700多万条音乐内容卡片的展示记录,包括点击、点赞、收藏、分享等多种用户行为类型。
每条数据记录都包含用户ID、音乐ID、行为类型、时间戳等完整信息。经过初步清洗后,已去除明显异常和重复数据,确保了数据质量的可靠性。数据集中各类用户行为的具体分布情况如表1所示,这种多样化的行为数据为后续的特征工程和模型构建提供了坚实的基础。
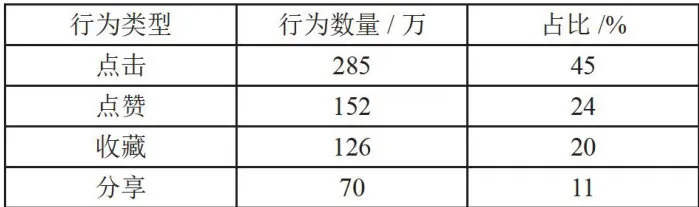 表1用户行为类型分布统计
表1用户行为类型分布统计2.2.2 数据特征分析
通过深入分析,发现数据集包含三类主要特征,分别从不同角度描述用户的行为模式。在用户基础特征方面,包含了用户的人口统计学特征(如年龄段、性别等)、用户的注册信息(如注册时长、账号状态等),以及反映用户活跃程度的指标(如月均访问频次、使用时长等)。这些基础特征为理解用户的基本属性提供了重要参考。
在内容交互特征方面,收集了用户的显式反馈(如评分、评论等)、隐式反馈(如播放时长、跳过次数等),以及社交行为(如分享、推荐等)。这些交互特征直接反映了用户对音乐内容的偏好和兴趣程度。在时序特征方面,关注用户的行为时间分布(包括每日、每周的活跃模式)、行为的连续性指标(如访问间隔、行为序列等),以及时间衰减特征(体现近期行为的权重)。
通过对数据的初步分析,发现了几个重要的特征规律:首先,用户行为呈现明显的长尾分布特征,如图2所示;其次,不同类型的用户行为之间存在显著的相关性;第三,用户的活跃度与其行为的多样性呈现正相关关系;最后,时间特征对于预测用户兴趣具有重要影响。这些发现为后续的模型设计提供了重要的指导。
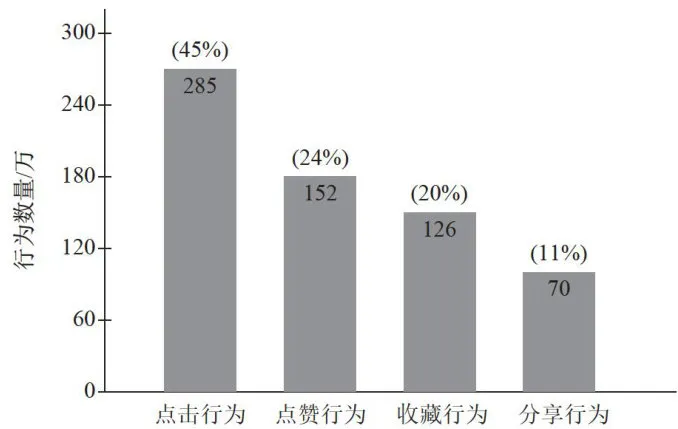 图2用户行为分布统计图
图2用户行为分布统计图2.3数据预处理与特征工程
基于对数据集的深入理解,本研究设计了系统的数据预处理流程和特征工程方案,以提升数据质量并构建有效的特征表示。
2.3.1 数据预处理方法
数据预处理主要包括以下几个步骤:本研究采用了多阶段的数据处理策略,确保数据质量满足建模需求。在数据清洗阶段,首先对完全重复的记录进行删除,随后使用四分位距(IQR)方法识别和处理异常值,特别是对播放时长等连续型特征进行重点处理。计算式为:
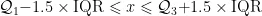
其中, 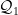 和
和 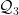 分别为第一和第三四分位数,IQR为四分位距。
分别为第一和第三四分位数,IQR为四分位距。
针对缺失值处理,研究对不同类型的特征采用了差异化的处理策略。对于连续型特征,采用中位数进行填充,这种方法能够保持数据的分布特征;对于类别型特征,则使用众数填充,保证填充值的合理性;对于时序特征,采用临近时间点的数据进行插值,维持数据的时间连续性;对于具有关联性的特征,则基于特征间的相关性进行推断填充,提高填充的准确性。
在数据标准化阶段,对不同类型的特征采用了相应的标准化方法。对于数值型特征,采用Min-Max标准化使其范围统一到[0,1]区间;对于类别型特征,通过独热编码转换为数值表示;对于时序特征,则进行时间窗口化处理,便于后续建模使用。
2.3.2 特征工程
特征工程阶段重点构建了三个层面的特征系统:用户行为权重特征、时间相关特征和内容交互特征。行为权重特征包括基于行为类型的静态权重(详细权重设计如表2所示)和时间衰减的动态权重;时间相关特征包含全局时间特征、周期性特征和序列特征;内容交互特征则涵盖基础统计特征和行为类型的交叉特征。时间衰减特征的计算采用了指数衰减函数,其计算式为:
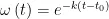
其中, ω 为衰减系数, k 为潜在特征维度, 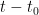 为时间间隔。
为时间间隔。
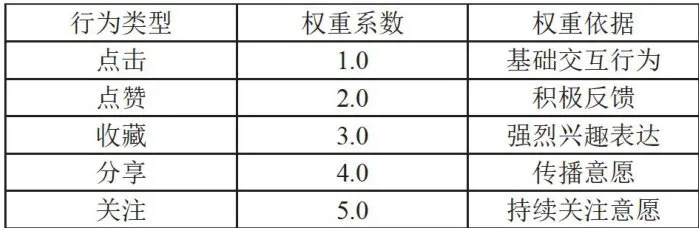 表2用户行为权重设计
表2用户行为权重设计2.4模型设计与实现
在完成数据准备和特征工程后,本研究进入核心的模型设计与实现阶段,重点关注基础NMF模型的改进和优化。
2.4.1 基础NMF模型
基础NMF模型为研究奠定了理论基础,其核心是通过分解用户-物品交互矩阵来发现隐含的特征模式。模型的目标函数设计充分考虑了非负约束的特点,通过最小化重构误差来优化模型参数。具体的目标函数为:
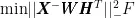
其中, X 为用户-物品交互矩阵, W 为用户特征矩阵, W ⩾ 0 , H 为物品特征矩阵, H ⩾ 0 ,  为Frobenius范数。
为Frobenius范数。
2.4.2 加权NMF模型
在基础NMF模型的基础上,加权NMF模型引入了权重矩阵 V 来区分不同用户行为的重要程度。权重设计综合考虑了三个关键因素:首先是基于行为类型的基础权重,反映不同行为的内在重要性;其次是考虑行为时效性的时间衰减权重;最后是根据用户参与度设计的活跃度权重。这种多维度的权重设计使模型能够更准确地刻画用户偏好。模型的目标函数为:
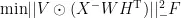
其中, V 为权重矩阵, ⨀ 为Hadamard积(逐元素相乘)。权重矩阵的设计基于表2中的行为权重系数。
2. 4.3 稀疏NMF模型
稀疏NMF模型通过引入 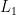 正则化项来增强模型的泛化能力。模型设计遵循三个主要原则:首先是通过参数λ灵活控制模型的稀疏程度;其次是利用正则化实现自动的特征选择;最后是通过适当的正则化强度来防止模型过拟合。这种设计既保持了模型的表达能力,又提高了其在实际应用中的稳定性。模型的目标函数为:
正则化项来增强模型的泛化能力。模型设计遵循三个主要原则:首先是通过参数λ灵活控制模型的稀疏程度;其次是利用正则化实现自动的特征选择;最后是通过适当的正则化强度来防止模型过拟合。这种设计既保持了模型的表达能力,又提高了其在实际应用中的稳定性。模型的目标函数为:
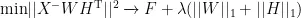
其中,λ为正则化参数,用于控制模型的稀疏程度, 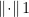 为
为 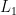 范数。
范数。
2.4.4 模型优化与训练
模型训练采用多阶段优化策略。在参数初始化阶段,首先采用均匀分布对 W 和 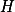 矩阵进行初始化,并引入Xavier初始化方法以提高模型的收敛速度。同时,通过实验选取了合适的初始学习率,为后续优化过程奠定基础。
矩阵进行初始化,并引入Xavier初始化方法以提高模型的收敛速度。同时,通过实验选取了合适的初始学习率,为后续优化过程奠定基础。
在优化过程中,本研究采用交替最小二乘法(AltermatingLeastSquares,ALS)作为核心优化算法。为了提高优化效果,结合Adam优化器进行梯度更新,这种优化器能够自适应地调整学习率,有效提升了模型的训练效果。此外,采用批量训练的方式进行模型训练,通过合理设置批量大小,显著提高了计算效率。
在收敛控制方面,设置了多重控制机制以确保模型训练的稳定性和效果。具体而言,设定最大迭代次数为1000轮,同时引入早停策略,即当连续5次验证集损失没有得到改善时,自动停止训练过程。另外,设置了相对重构误差阈值为 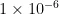 ,当模型达到这一精度时即认为收敛完成。这些策略的组合使用,既保证了模型能够充分训练,又避免了过度拟合的风险。
,当模型达到这一精度时即认为收敛完成。这些策略的组合使用,既保证了模型能够充分训练,又避免了过度拟合的风险。
实验观察表明,加权NMF模型在处理用户行为差异性方面表现出色,显著提升了推荐的准确度。同时,稀疏NMF模型通过正则化约束有效缓解了数据稀疏性带来的影响。不同模型在训练过程中展现出各自的优势特点,这为实际应用中的模型选择提供了重要参考。
模型在不同参数配置下的性能对比如图3所示。
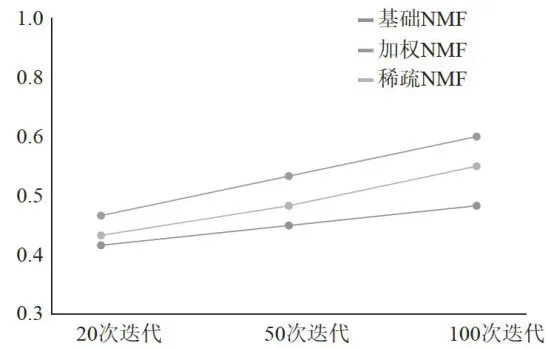 图3不同NMF模型性能对比图
图3不同NMF模型性能对比图3 实验结果及分析
本章系统地展示了模型的实验过程和评估结果,通过多个维度的分析验证了所提出模型的有效性
3.1实验设置与评估指标
为了全面评估模型性能,本研究设计了完整的实验评估体系。
3.1.1评估指标
本研究采用多个标准指标对模型性能进行评估。F1值用于综合评估推荐的准确性和完整性,能够平衡精确率和召回率之间的关系;均方根误差 (RMSE)和平均绝对误差(MAE)分别从不同角度衡量预测评分的准确程度;归一化折扣累计增益(NDCG)则专门用于评估推荐结果的排序质量。此外,考虑到实际应用中的效率需求,还对模型的训练时间进行了记录和分析。
3.1.2 数据集划分
实验采用了标准的训练集、验证集和测试集划分方式,按照8:1:1的比例进行划分。具体而言,训练集包含1668426名用户的45600000条交互记录,验证集和测试集各包含约20万用户的570万条记录。这种划分方式既确保了训练数据的充足性,又保证了验证和测试的可靠性。特别注意的是,划分过程中确保了每个用户在各个数据集中都有对应的行为记录,避免了数据泄露问题,如表3所示。
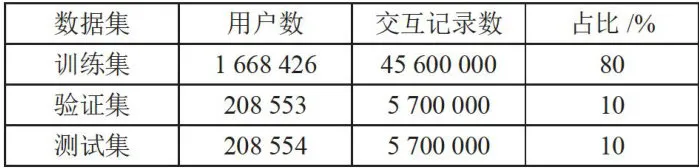 表3数据集划分统计
表3数据集划分统计3.2模型训练与收敛性分析
对三种NMF模型的训练过程进行了详细追踪和分析,重点关注其收敛特性和性能表现。
3.2.1 训练过程分析
实验记录显示,加权NMF在前20轮迭代中就达到了较好效果,展现出快速收敛特性;稀疏NMF因引入正则化约束,收敛较慢但更稳定;基础NMF在后期出现轻微震荡。三种模型在测试集上各具特色:加权NMF获得最高的F1值(0.9976)和NDCG值(0.6150),表明其在整体推荐质量上具有明显优势;稀疏NMF的F1值达到0.9954,展现出良好的泛化能力;基础NMF作为对照组提供了有效基准。不同NMF模型训练过程中损失函数变化趋势如图4所示。
3.2.2 模型性能对比
在测试集上的实验结果显示,三种模型各具特色:加权NMF获得了最高的F1值(0.9976)和NDCG值(0.6150),同时具有最小的RMSE(0.1217)和MAE(0.0158),表明其在整体推荐质量上具有明显优势;稀疏NMF虽然在某些指标上略逊于加权NMF,但其F1值仍达到0.9954,展现出良好的泛化能力;基础NMF作为对照组,在各项指标上均表现稳定,为改进模型提供了有效的基准。三种模型在测试集上的性能对比如表4所示。
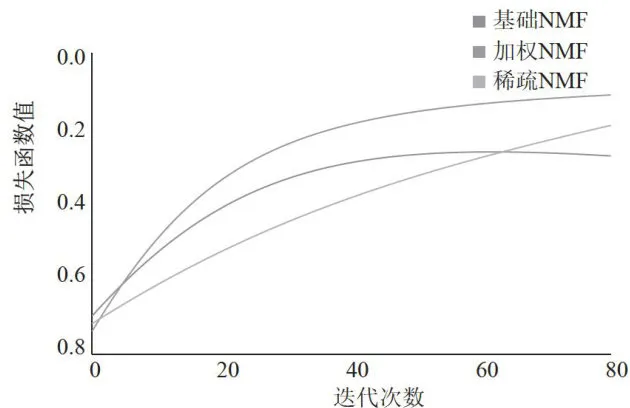 图4不同NMF模型训练过程中损失函数变化趋势
图4不同NMF模型训练过程中损失函数变化趋势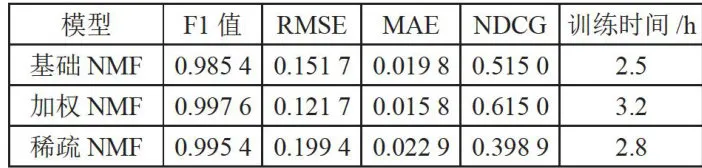 表4模型性能对比
表4模型性能对比3.3用户行为影响分析
基于用户行为权重设计的实验结果表明,不同类型的用户行为对推荐效果具有显著不同的影响。收藏行为(权重3.0)对推荐准确性的贡献最为显著,这与其代表用户强烈兴趣的特性相符。分享行为虽然被赋予了较高权重(4.0),但由于数据的稀疏性,其实际影响相对有限。点击行为虽然单次权重较低(1.0),但由于其高频特性,累积效应显著提升了推荐效果。图5展示了各类行为对推荐准确性的贡献度。
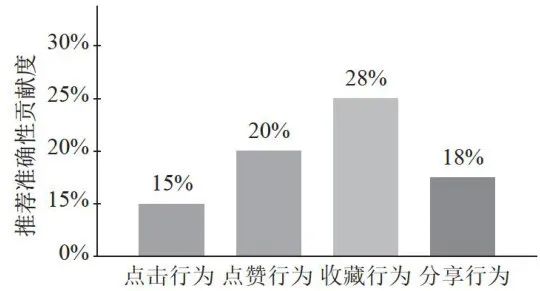 图5不同类型用户行为对推荐准确性的贡献度
图5不同类型用户行为对推荐准确性的贡献度3.4冷启动问题分析
在解决冷启动问题方面,不同模型展现出明显的性能差异。稀疏NMF在处理交互次数少于10次的新用户时表现最为出色,这得益于其在数据稀疏情况下的良好泛化能力。加权NMF则在用户交互次数超过20次后表现优异,说明随着用户行为数据的积累,权重机制的优势得到充分发挥。基础NMF对数据量要求较高,需要较多的用户交互才能达到理想的推荐效果。不同模型在处理新用户时的表现如图6所示。
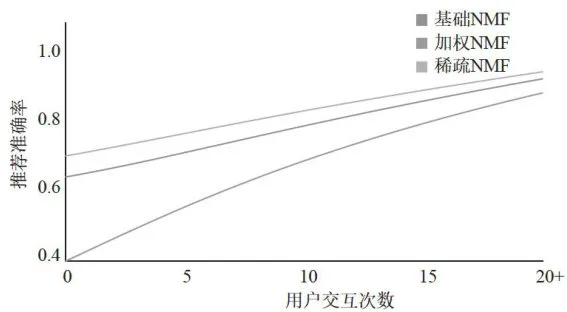 图6不同交互数量下的推荐效果对比
图6不同交互数量下的推荐效果对比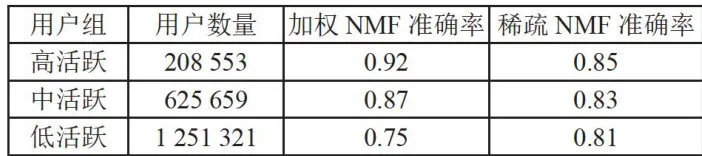 表5不同用户组的推荐性能
表5不同用户组的推荐性能3.5 应用场景分析
基于实验结果,可以针对不同应用场景推荐最适合的模型配置。在高频互动场景(如音乐APP主页推荐)中,加权NMF因其能够精准捕捉用户实时偏好而成为最佳选择。对于冷启动场景(如新用户推荐),稀疏NMF凭借其处理数据稀疏问题的优势,展现出更好的适用性。
这些发现为实际系统的模型选择和部署提供了重要的参考依据,也为后续的模型优化指明了方向。
4结论
本文通过分析加权NMF和稀疏NMF在音乐推荐系统中的应用,探讨了不同NMF模型在处理用户行为数据时的表现和适用场景。研究结果表明,加权NMF由于赋予不同行为权重,能够更好地捕捉用户的实际偏好,在处理交互频繁的用户时表现优异;而稀疏NMF则通过 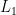 正则化控制模型复杂度,适合处理稀疏性较高的用户行为数据,尤其在冷启动情境中具备优势。
正则化控制模型复杂度,适合处理稀疏性较高的用户行为数据,尤其在冷启动情境中具备优势。
总体来看,结合用户行为特点和数据规模,选择合适的NMF模型可以显著提升音乐推荐系统的性能。加权NMF更适合处理频繁交互数据,而稀疏NMF更适合用户行为较少、数据稀疏的场景。通过实验评估,本文验证了两种模型在不同应用场景下的有效性,为实际推荐系统的优化提供了借鉴。
尽管本研究取得了一定的成果,但仍然存在一些局限性。首先,NMF模型的性能在用户行为极其稀疏的数据集上有所下降。虽然稀疏NMF可以通过正则化改善部分表现,但在处理新用户或交互极少的用户时,推荐效果仍然不够理想。此外,研究仅考察了加权NMF和稀疏NMF两种模型,未来还可以结合其他推荐技术(如深度学习模型)进一步优
化系统性能。
另一个局限性在于权重的设定。加权NMF模型对行为的权重设置依赖于人为经验,未能自动调节权重,可能会导致在某些行为下权重设置不合理,影响模型的推荐效果。因此,未来研究可以探索如何自动化权重分配,从而提升推荐系统的智能化水平。
参考文献:
[1]BOBADILLAJ,ORTEGAF,HERNANDOA,etal.Recommender Systems Survey[J].Knowledge-Based Systems,2013,46:109-132.
[2]SHIY,LARSONM,HANJALICA.CollaborativeFilteringBeyondtheUser-ItemMatrix:ASurveyoftheStateof the Art and Future Challenges[J].ACM Computing Surveys(CSUR),2014,47(1):1-45.
[3]VARGHESEK,MKOLHEKARMM,HANDES.Denoising ofFacial Images UsingNon-Negative MatrixFactorization with Sparseness Constraint [C]//20183rdInternational Conference for Convergence in Technology (I2CT).Pune:IEEE,2004:1-4.
[4]RICCIF,ROKACHL,SHAPIRAB,etal.Recommender Systems Handbook[M].New York:Springer,2011.
[5]KORENY,BELLR,VOLINSKYC.MatrixFactorization Techniques for Recommender Systems [J].Computer,2009,42(8):30-37.
[6]SUXY,KHOSHGOFTAARTM.A SurveyofCollaborative Filtering Techniques [J].Advances in ArtificialIntelligence,2009,2009(1):1-19.
[7] SCHAFERJB,KONSTANJA,RIEDLJ. E-CommerceRecommendation Applications[J].Data Miningand KnowledgeDiscovery,2001,5(1):115-153. [8] ZHANG S,YAO L,SUNA,et al.Deep LearningBasedRecommender System:A Survey and New Perspectives [J].ACMComputing Surveys,2019,52(1):5.1-5.38.
[9]KIMJ,PARK H.FastNonnegative MatrixFactorization:An Active-Set-Like Method and Comparisons[J].SIAM Journal on Scientific Computing,2011,36(6):3261-3281.
[10]MNIHA,SALAKHUTDINOVRR.ProbabilisticMatrix Factorization [C]//Advancesin Neural InformationProcessing Systems15:Proceedingsof the 2002 Conference.Vancouver:MITPress,2003:1-7.
[11]HUYF,KORENY,VOLINSKYC.CollaborativeFilteringforImplicitFeedbackDatasets[C]//20o8EighthIEEEInternational Conference on Data Mining.Pisa:IEEE,2008:263-272.
[12]ZENGW,FANG,SUNS,etal.CollaborativeFilteringViaMulti-LayerNeuralNetworks[J/OL].Applied SoftComputing,2021,109:107516[2024-10-05].https://doi.org/10.1016/j.as0c.2021.107516.
[13]FANGH,LIA,XUHX,etal.Sparsity-ConstrainedDeepNonnegative Matrix Factorization for HyperspectralUnmixing [J].IEEE Geoscience and Remote Sensing Letters,2018,15(7):1105-1109.
[14] GUO Z X,ZHANG S H. Sparse Deep NonnegativeMatrix Factorization[J/OL].arXiv:1707.09316 [cs.CV].[2024-09-26].https://doi.org/10.48550/arXiv.1707.09316.
作者简介:金龙(2000一),男,汉族,四川广元人,硕士研究生在读,研究方向:数据科学、机器学习。