蒋博文
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言图像分类是机器视觉研究热点之一。顾名思义,图像分类即给定输入图像,卷积神经网络对输入进行图像预处理、特征图特征提取以及使用分类器进行分类,最终输出预测类别标签,其中特征图的有效信息提取是至关重要的一步。传统的图像分类算法提取图像的色彩、纹理和角点等特征信息,其在早期较为简单的图像分类任务中具有较好得表现,但在复杂场景下却不能满足要求 。
注意力机制作为捕捉特征图显著特征、提高卷积神经网络特征提取能力的新方法。随着现代科技的发展,海量复杂的信息不断地向人们袭来,信息无处不在。然而人类接受信息的能力是有限的,研究发现在人类接受视觉数据的初始,人类的视觉处理系统会快速地将自己的大部分注意力集中在场景中相对重要的区域上,这种选择处理机制可以极大地减少人类视觉系统需要处理的数据量,并在复杂信息环境中,抑制不重要的视觉刺激,从而将更多的精力分配给现实场景中更重要的部分,提取更重要的信息以便于大脑进行更高层次的决策。接触人类视觉研究,研究者们提出了注意力机制的思想。对于现实中的事物其所具有的特征是不同的,在卷积神经网络中反映为每张特征图的差异性。注意力机制就是通过一系列手段捕捉每张特征图显著特征的像素或通道信息,具体反映在将重要的通道或者像素信息的权重增大并抑制不重要的信息权重,
本文以图像分类任务为载体,通过结合现有的SE 通道注意力机制,将其嵌入到原始的ResNet 网络中,提高网络特征提取能力,捕捉特征图中的显著特征信息。通过在CIFAR-10 和CIFAR-100 数据集上使用基准网络进行了实验,验证了其有效性。
1 算法描述1.1 ResNet 算法深度神经网络的深度对于网络性能的提升是最直接的方法,但实践证明网络并不是越深越好,这是由于随着网络层数的增加,在网络回归的过程中梯度消失的现象就会越来越明显,相应的网络训练的效果也会变差。为了解决加深网络深度带来的梯度消失和网络退化问题,ResNet网络应运而生。
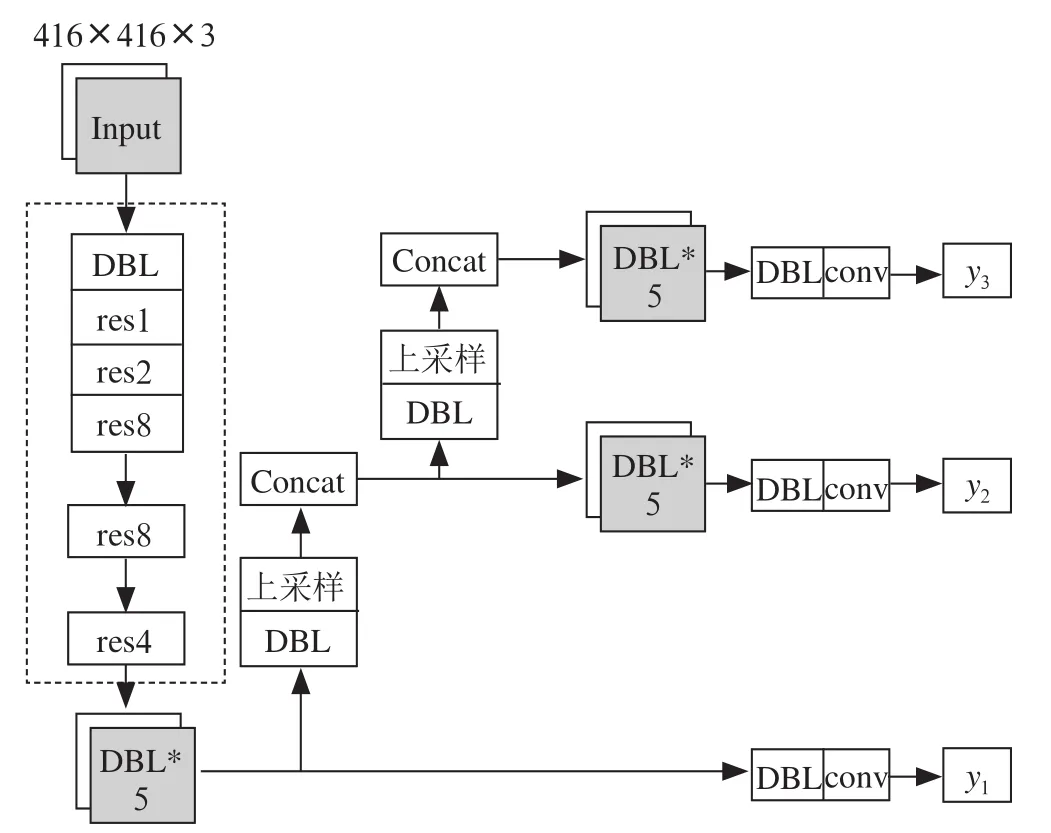
如图1所示,34 层的ResNet 网络由一系列的残差模块、全连接层和下采样层组成。残差模块分为恒等残差和非恒等残差模块两种,分别对应着图中快捷连接(shortcut connections)的实线和虚线两种。恒等残差模块中的实线表示对于本残差模块的输入和输出特征图通道数是相同的,可以直接进行相加。非恒等卷积残差块中的虚线表示输入和输出的特征图通道数是不同的,需要先通过1×1 的卷积改变通道数,然后再相加。

图1 ResNet34
如表1所示,本文列出18 层、34 层、50 层、101 层和152 层五种深度的原始ResNe 网络结构,其中conv代表普通卷积、stride 代表步长、Global average pool 代表全局平均池化、fc 代表全连接层。五种深度的原始ResNet 网络性能随着层数的增加而增加,同时计算量也随之增加。
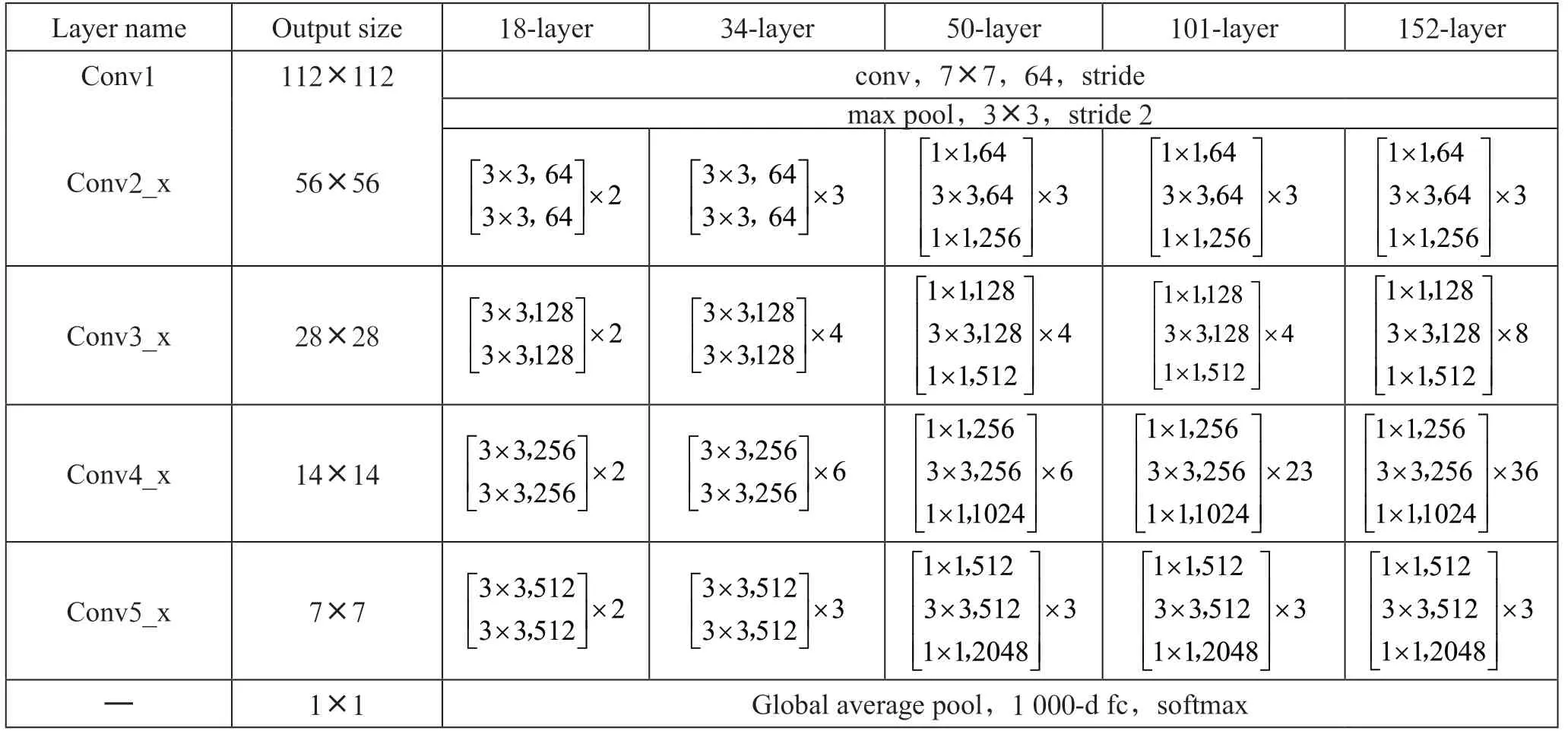
表1 不同深度的ResNet 网络结构配置
损失函数用于在训练过程中的模型反向传播时计算模型预测值和真实标签值之间的不一样程度,以便进行梯度更新。原始ResNet 网络中使用交叉熵函数(Cross Entropy)作为最终的损失函数值,即将输入网络中的每个样本的交叉熵进行加权平均,具体计算公式为:
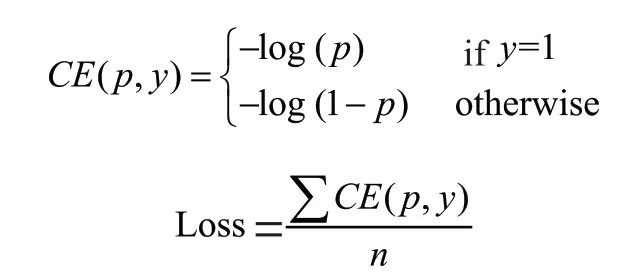
SE 通道注意力机制如图2所示,其中为输入特征图,为高,为宽,为通道数,GAP 为全局平均池化操作,fc 为全连接层。先通过Squeeze 操作压缩特征,沿着×方向进行压缩特征图,用1 个实数表示×特征平面,某种程度上该实数具有一定的全局感受野;然后通过全连接层,实现对1×1×特征图进行跨信道信息交互,充分融合不同信道之间的信息;通过Sigmoid 函数获得每个通道权重信息的一维向量,其代表着每个通道的重要性;最后使用一维特征向量对原特征图进行缩放。
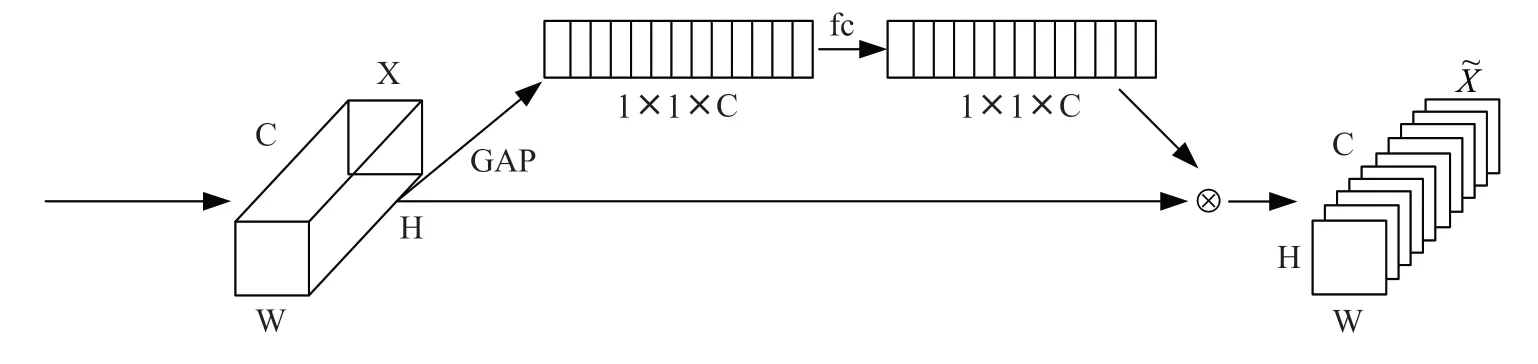
图2 SE 模块
SE 通道注意力机制的核心思想在于通过全连接层和下采样层构建压缩和激励模块以便于获取特征图通道权重信息,让网络学习特征图中更重要的地方,放大显著特征的权重的同时缩小不重要特征权重,从而使训练模型达到更好的效果。SE 通道注意力机制作为一种软注意力机制,属于一个即插即用模块,可以无缝嵌入多种CNN 网络中并进行端到端训练,在模型参数和计算复杂度少量增加的前提下,大幅提升网络性能。
2 实验与结果分析2.1 数据集与实验设置为了评估不同深度得ResNet 网络嵌入SE 通道注意力机制之后的效果,本文在CIFAR-100 和CIFAR-10 图像分类数据集上进行了实验,CIFAR-10 数据集包含10 个类别,共有60 000张彩色图片,尺寸大小为32×32 像素,有50 000 张训练图像和10 000 验证图像,每个类别包含6 000 张图像。CIFAR-100数据集包含100 个类别,共有60 000 张彩色图片,尺寸大小为32×32 像素,有50 000 张训练图像和10 000 验证图像,每个类别包含600 张图像。本文在CIFAR-100 和CIFAR-10 验证集上统计Top-1 Error、Top-5 Error 和Top-1 Acc 并作为评价标准。Top-1 Error 是指取概率向量里面最大的作为最终预测结果,且预测结果和真实标签不同,Top-1 Acc 则是预测结果和真实标签相同。Top-5 Error 是取概率向量里面最大的前五位作为最终预测结果,且预测结果和真实标签都不同。
操作系统及环境:Ubuntu18.04、Python3.7、CUDA11.0、PyTorch1.7.1。
框架:PyTorch。
GPU:NVIDIA GeForce RTX 2080 Ti。
具体实验设置:在训练的过程中,将SGD 作为优化器,训练动量设置为0.9,训练权重衰减设置为5e-4,使用单GPU 进行训练,批量大小为128,学习率初始值设置为0.1。所有模型均设置200 个epoch 进行训练,使用等间隔调整学习率,初始学习率在第60、120、160 个epoch 乘以0.2。
2.2 CIFAR-100 和CIFAR-10 数据集上的图像分类本文使用ResNet-50 和ResNet-101 网络为基准,评估了改进的ResNet 算法模型在CIFAR-100 和CIFAR-10 数据集上的表现。
分别比较嵌入SE 通道注意力机制的SE-ResNet 和原始ResNet 在CIFAR-100 数据集上的Top-1 Error、Top-5 Error、参数量,结果如表2所示。可以观察到,相较于原始的ResNet,添加SE 模块的ResNet 模型在不同的网络深度上都有明显的提升,错误率都降低了一个百分点左右,而模型参数只增加了极小。特别的是,SE-ResNet50 Top-1 Error 和Top-5 Error 分别为20.29%和4.89%,相对于ResNet50 降低了8.40%和14.36%,比更深层次的ResNet101 错误率还要低。
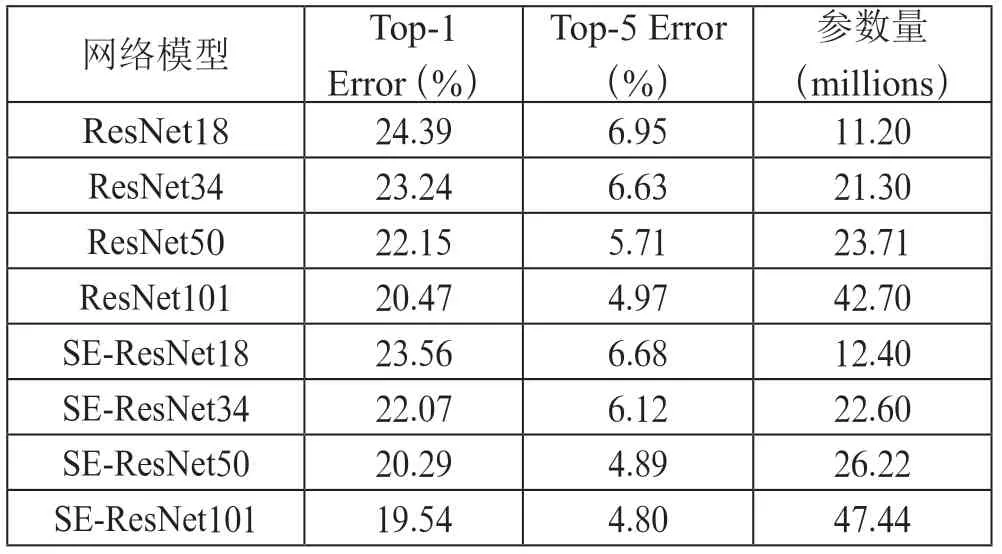
表2 在CIFAR-100 数据集上SE-ResNet 与原始ResNet比较
CIFAR-10 数据集上,由于CIFAR-10 数据集仅有10 个类别,所以模型之间错误率差别不大。本文仅选取SEResNet50 和ResNet50 进行比较,如表3所示。ResNet50的Top-1 Error 为4.88,SE-ResNet50 仅为4.39,相较于原始ResNet50 在Top-1 Error 上降低了10.04%,错误率有大幅降低。
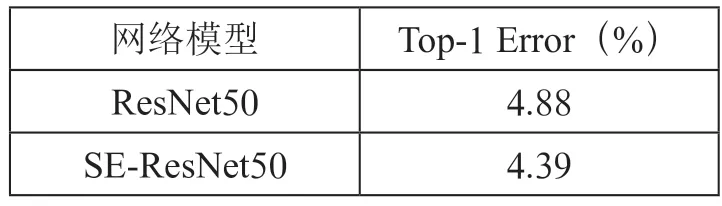
表3 在CIFAR-10 数据集上SE-ResNet 与原始ResNet错误率比较
对于原始ResNet 网络提取特征能力的不足,SE-ResNet通过使用下采样层和池化层构建的压缩和激励模块可以有效地捕捉特征图通道或像素的显著信息,提高网络的特征提取能力,并让网络关注更加重要的地方。
3 结 论为了解决原始ResNet 网络特征提取能力不足的问题,本文结合现有注意力机制SENet,提出一种基于改进ResNet模型的图像分类方法。本研究将SE 模块嵌入到原始ResNet网络每个残差结构的末端,通过压缩和激励模块对原始特征图进行跨通道信息交互,增强网络特征提取和通道信息融合。实验结果表明,与原始ResNet 算法相比,嵌入SE 通道注意力机制的SE-ResNet 在CIFAR-100 和CIFAR-10 数据集上以增加少量的模型参数为代价获得了更高的识别准确率。后续的工作可以从自注意力机制、软注意力机制和硬注意力机制等其他注意力机制入手,进一步提高ResNet 网络的精度和泛化能力。