中图分类号:TP3191.4;TP301.6 文献标识码:A
文章编号:2096-4706(2025)08-0046-09
Abstract:To address theisues of low detection accuracy and highcomputational load in infrared smalltarget detection from UAVaerial perspectives,a lightweight infrared smalltargetdetectionmodel,YOLO-IRLight,is proposed basedon YOLOv8s.Thismodelintroduces theEMA(EffcientMultiscaleAttention)Atention Mechanism toenhancefeatureextraction capabilities.APConv-C2f module isadded tothe neck of the network toreducecomputationalloadand fuse scale sequence features,andaP2detectionlayerisincorporatedtootimizethenetworkstructure,therebyimprovingsmaltargetdetection performance.Aovellgtweightdetectionead,Goup-Detect,isesigned,andtheNWD(NoaledussnWten Distance)lossfunctionisincorpoatedintothelossfunctionof themodelinalinearcombination maer.Experimentalresults on the open dataset show that compared to the original YOLOv8s, the proposed model improves detection accuracy ( m A P@ 0 . 5 ) ( by 1 . 7 % ,reduces the number of parameters by 4 5 . 9 % ,decreases computational complexity (GFLOPs) by 3 3 . 5 % ,and increases F1 score by 0 . 9 % .The improved algorithm significantly outperforms traditional algorithms,with notable improvements in detection accuracy compared to current mainstream algorithms.
Keywords: Small Target Detection; infrared target; lightweight; YOLOv8; network optimization
0 引言
目标检测是计算机视觉的重要任务,在各种领域如搜索救援、智能监控中都有广泛的使用。而无人机近年来不断发展,因其能够无视地形因素进行拍摄和定位,将目标检测技术应用于无人机上,能提升功能性从而为社会提供应用价值。无人机拍摄的红外图像相较于可见光(Visible,VIS)图像,能更好地反应图像的热目标特性。但在大部分应用场景中,红外小目标缺少相对明显的颜色、形状、纹理等特征信息,且边界模糊,环境噪声与杂波导致红外图像的信噪比降低,进一步加大了复杂环境下的红外小目标检测难度。所以对于红外小目标的检测过程仍面临诸多挑战[1]。实时性和准确性对于无人机目标检测任务至关重要,将深度学习模型部署到小型设备上具有挑战性,而轻量化模型又难以在提高准确度的同时满足实时性要求。基于这一点,本文提出设计一种模型复杂度较低的无人机航拍红外小目标图像目标检测算法。
目前,传统的检测方法和基于深度学习的检测方法都能完成红外图像小目标检测。传统的目标检测算法通过特定的图像处理技术,建立背景模型来消除或降低背景噪声,从而突出目标信号完成目标检测。宋[2]等人提出一种基于改进加权局部对比度的检测方法,利用目标的各向同性采用六方向梯度法选择目标点进行决策,判断出目标的位置。但是对于变化剧烈的背景或光照条件敏感,容易产生虚假目标。Younsi[3]等人在采用高斯混合模型(GaussianMixtureModel,GMM)背景差分法提取图像序列中所有目标后,引入基于形状、外观等组合相似函数来检测目标。但是背景中的小物体容易干扰主体目标的检测,导致目标信息的丢失。
目前卷积神经网络和深度学习技术都在不断进步,基于深度学习的目标检测算法层出不穷,而红外小目标检测是重要的研究方向之一。Qi等人将Transformer和CNN的网络架构融合,CNN获取局部细节,Transformer用自注意机制来学习上下文依赖关系,增强了红外图像的目标特征。文献[5]中 Jiang等人基于Transformer针对可见光(visible,VIS)和热红外(thermalinfrared,TIR)图像设计了目标检测模型。Liang等以FasterR-CNN为网络结构,利用空间自适应模块的特征金字塔网络(FeaturePyramidNetwork,FPN)结构,减少了红外小目标图像中特征融合信息的损失。这类方法对于目标检测的精度提升较大,但检测速度较慢,计算量偏高,不适合以无人机为载体进行目标检测。近年来还出现许多基于单次检测器(Single ShotDetector,SSD)的网络结构[7-9],在文献[10]中,Zheng等在融合单次检测器(FusionSingleShotMultiBoxDetector,FSSD)的浅层网络中添加了一个特征增强模块,用于检测红外目标,提高了检测精度,且速度明显优于上面的二阶段网络。但同为一阶检测网络的YOLO目前对小目标的检测精度已经超越了单次检测器(Single ShotDetector,SSD)类网络,文献[11]中基于YOLOv5改进了上下采样,减少采样阶段小目标特征的损失,文献[12]改进YOLOv7网络使高级和低级语义之间能够线性融合,克服了红外小目标检测中噪声引起的误报问题,文献[13]通过融合多个输入的多帧信息对YOLOv8进行改进。这些基于YOLO的网络结构都在红外小目标检测方面表现出色。这表明YOLO系列算法在红外目标检测上优势很大。以上算法对红外目标的检测精度都有大幅提升,但对于无人机的红外小目标检测来说,兼顾模型的参数量和检测精度仍是一个挑战。
1基于改进Y0L0v8s的红外小目标检测
YOLOv8是一种实时目标检测算法,其相较于其他算法表现出色。但它目前的损失函数未能充分对全局感知能力的充分利用,并且其特征融合策略限制了其对小目标的检测能力。YOLOv8有五个模型版本:n、s、m、1和x;模型的尺寸和精度是依次递增的。为了保证一定的精度,又追求轻量化,选择其中的YOLOv8s模型进行改进。实验结果表明,改进后的模型有效地提高了对地面密集小目标的检测精度。改进方法主要包括以下几点:
1)针对网络模型参数量大、计算速度慢的问题,在C2f模块中引入FasterBlock[14模块,形成新的PConv-C2f模块替换进颈部网络中。在PConv-C2f的基础上添加EMA注意力机制,形成PConv-C2f-EMA模块替换主干网络中。这一改进让网络融合时运算速度更快,提取特征时对红外模糊小目标更有针对性。
2)在颈部引入ASF-YOLO[15]中的 SSFF(ScaleSequence Feature Fusion)和 TFE(Triple FeatureEncoder,TFE)模块,并融合P2检测层改进,对网络结构进行优化,形成新结构SSFF-P2-TFE。原本的三尺度检测升级为四尺度检测,提高了小目标的检测精度。
3)在模型中引入NWD[16](Normalized GaussianWassersteinDistance)损失函数,更好地平衡不同目标尺度的损失,强调对小目标的定位预测,提升小目标的定位性能。
4)针对无人机硬件部署网络不能过于臃肿的问题,设计了轻量化的Group-Detect检测头,在保持精度的同时显著减轻检测头的计算量。
1.1 整体网络结构
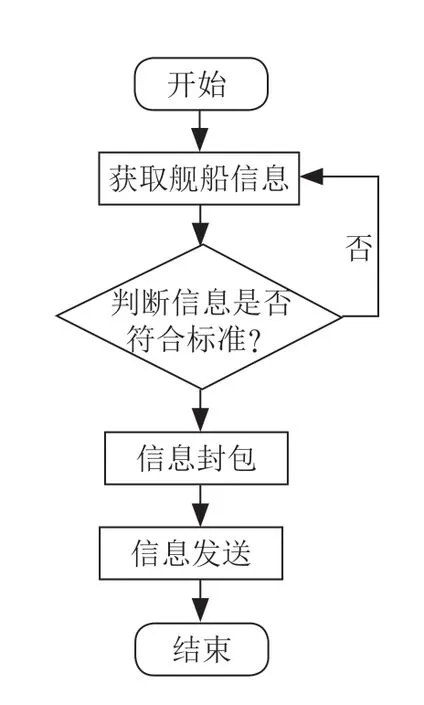
如图1所示,本网络分别改进了主干和颈部的C2f模块,并将主干中的P3、P4、P5级特征层送入SSFF模块,P2和经过TFE模块处理后的P3、P4级特征图送入SSFF模块,最后得到多尺度特征输入Group-Detect检测头检测。
1.2 基于PConv改进  模块
模块
1.2.1 PConv-C2f模块
在实际使用场景中,算法需要能够部署在边缘计算设备上并满足实时检测的要求,为了让设计能实际投入使用,需要减少冗余计算和内存访问,提高空间特征提取能力,而PConv卷积就是一个解决问题的切入点。通过引入PConv卷积和倒残差结构,采用1个PConv层和2个点卷积层并结合倒残差结构构建FasterBlock模块,使用FasterBlock模块替换C2f模块中的BottleNeck模块,同时保留其他位置的普通卷积块,提出了一种全新的轻量级PConv-C2f模块,如图2所示。
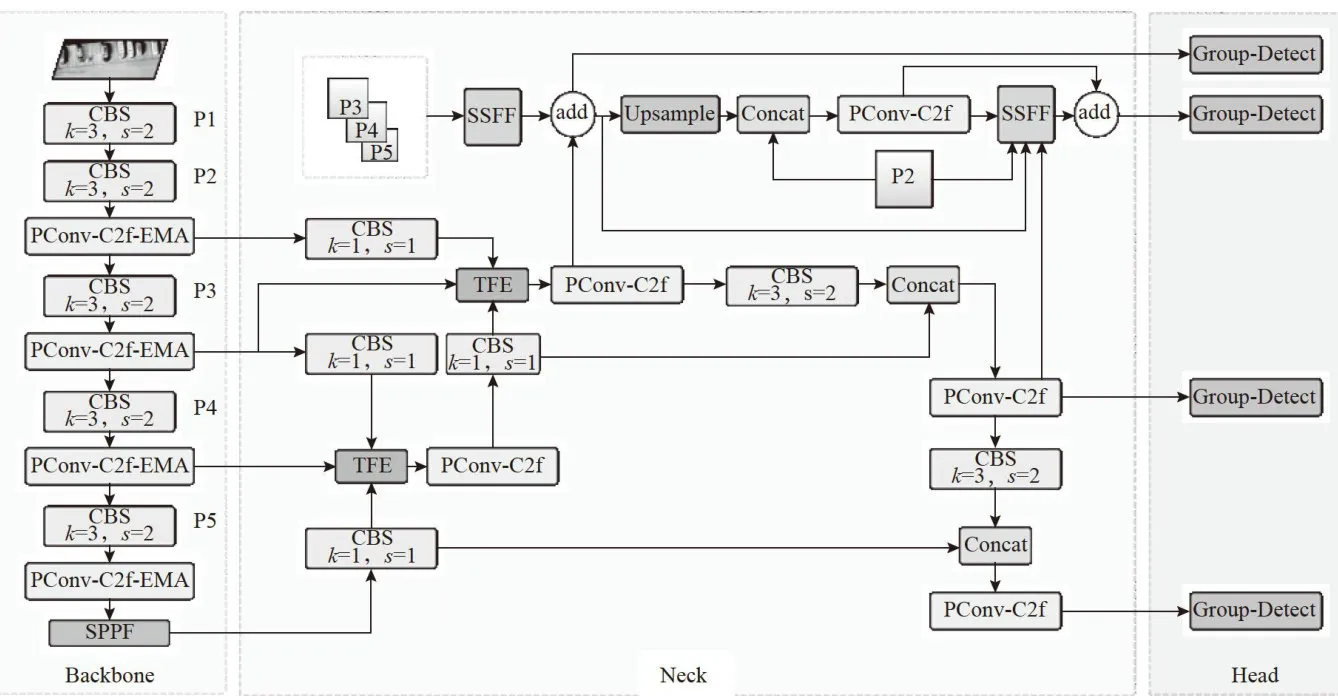 图1YOLO-IRLight 网络结构
图1YOLO-IRLight 网络结构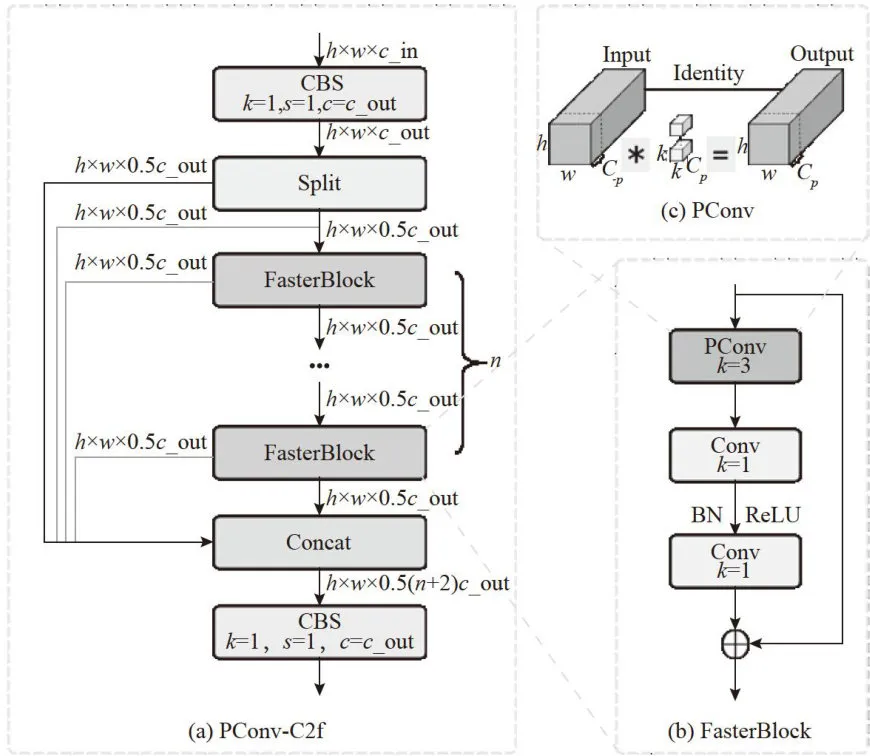 图2PConv-C2f结构
图2PConv-C2f结构
PConv只需要在输入的部分通道上进行卷积操作来提取空间特征,保持其他通道不变,这减少了计算负担并降低了信息丢失。利用网络的连续或规则性的内存访问特点,PConv选取前段或后段连续CP个通道来代表整个特征图,不需要对所有被选择的通道都进行独立计算,在不丧失一般性的情况下,假设输入和输出特征图具有相同数量的通道。如式(2)所示,当部分比例(partialratio) 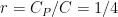 时,由于卷积过程占用内存较少,FLOPs仅为普通卷积的1/16,如式(1)所示。内存访问量MAC仅为普通卷积的1/4,如式(3)所示。
时,由于卷积过程占用内存较少,FLOPs仅为普通卷积的1/16,如式(1)所示。内存访问量MAC仅为普通卷积的1/4,如式(3)所示。
通过以上对C2f模块的改进,能够有效减少网络的参数量和计算量,提高检测效率。因此将原模型中颈部的C2f模块全部替换为PConv-C2f模块来达到轻量化的目的。
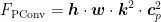
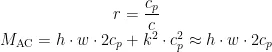
1.2.2 PConv-C2f-EMA模块
为了增强模型表征能力,通常采用增加卷积层数的方法,卷积层数的增加,往往会造成模型计算资源的消耗。添加注意力机制是增强模型表征能力的一种方式,它可以让模型着重关注输入序列中的关键信息,提高模型精度。因此考虑采用高效多尺度注意力机制(EfficientMulti-ScaleAttention,EMA),EMA与其他注意力方法相比,在参数量上优势显著。EMA采用并行子结构减少网络深度,在不进行通道降维的情况下,扩展网络的全局感受野、保留通道的精准信息,同时降低计算需求。EMA针对输入特征 X ∈ 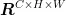 ,在通道维度将其划分成 G 个子特征
,在通道维度将其划分成 G 个子特征 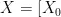 ,
,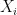 , ⋅ s ,
, ⋅ s , 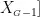 ,
, 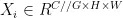 ,取 G ≪ C ,针对每个子特征,EMA通过3条并行分支提取分组特征图的注意力权重,其中对不同空间维度方向的信息进行了聚合,再将此权重用于每组的特征增强。
,取 G ≪ C ,针对每个子特征,EMA通过3条并行分支提取分组特征图的注意力权重,其中对不同空间维度方向的信息进行了聚合,再将此权重用于每组的特征增强。
将EMA注意力机制融入FasterBlock中,并添加到PConv-C2f模块中,形成PConv-C2f-EMA模块,如图3所示。在原网络的主干部分替换C2f模块,以提高模块提取小目标以及模糊特征的能力。
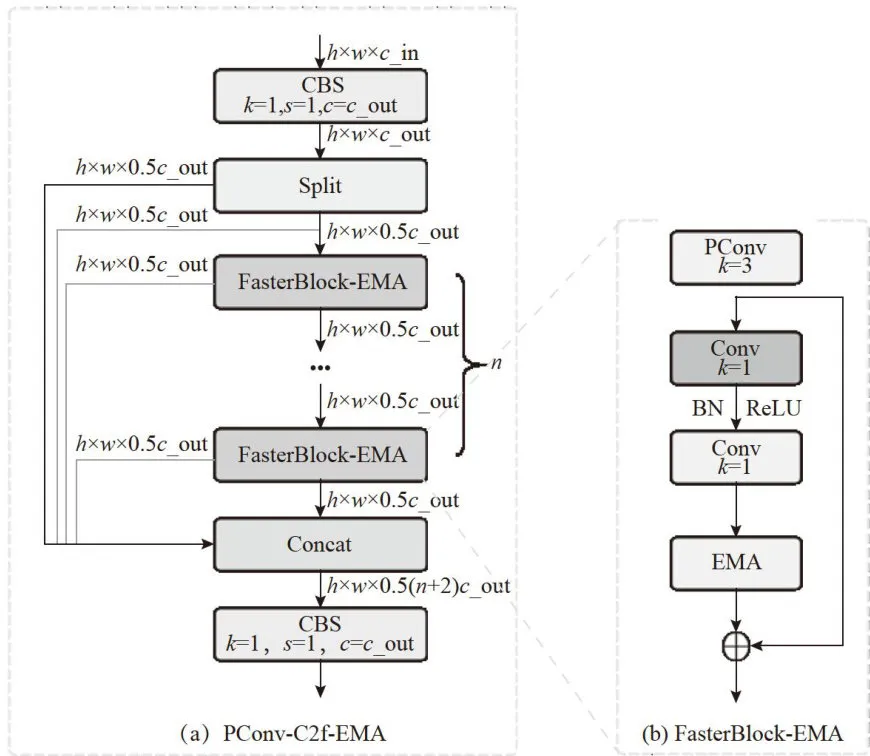 图3PConv-C2f-EMA结构
图3PConv-C2f-EMA结构1.3 改进特征融合层
红外目标样本通常尺寸较小、像素较低且容易发生重叠,这些特性严重影响了检测效果。另一方面,原模型较大的下采样倍数也对小目标检测造成了困难,因为深层次特征图经过了多层网络的处理,具有更大的感受野,很难捕捉到小目标的特征信息。因此本模型在颈部引入了ASF-YOLO中的尺度序列特征融合模块(Scale SequenceFeature Fusion, SSFF)和三重特征编码器(TripleFeatureEncoder,TFE)模块,融合P2小目标检测层,构建了SSFF-P2-TFE网络结构,将四尺度特征送入检测头对目标进行推理预测。
1.3.1 小目标检测层
原始模型中包含三个检测头,它将主干网络的P3、P4、P5输入到PAN-FPN中进行特征融合,由于使用了相较于原图 6 4 0 × 6 4 0 较大的下采样倍率,这三个特征层的尺寸分别为 8 0 × 8 0 、 4 0 × 4 0 和2 0 × 2 0 。这让其预测一些尺度较大的目标更容易,对小目标的检测在大感受野的影响下很难精准定位。因此本文提出增加一个小目标检测层。其原理是从网络主干的P2层特征图引出,添加一个 1 6 0 × 1 6 0 图像的检测层。
1.3.2 SSFF模块
SSFF模块旨在增强网络的多尺度信息提取能力,就是将深层特征图的高级语义信息与浅层特征图的详细空间信息相结合,使网络能够更好地理解图像中的细微细节和尺度变化,其结构如图4所示[15]。在本模型中,首先将主干网络中的P3、P4和P5特征映射归一化到P3级别尺寸,并使用3D卷积来提取它们的尺度序列特征。之后对网络主干的P2层、上一步处理融合后的P3层,以及模型颈部的P4层送入SSFF模块进行融合,来获取更小感受野的浅层次局部特征。这使网络对小目标的特征信息能进行更好传递与融合,可以更好地检测无人机拍摄的微小目标,显著降低漏检和误检的概率。
 图4 SSFF模块
图4 SSFF模块1.4 损失函数改进
YOLOv8为配合其新改进的Anchor-Free形式,增加了DFL(DistributionalFeatureLoss)损失。DFL使用交叉熵的形式计算边界框和标签的损失概率,让网络更快的聚焦到目标位置及邻近区域的分布。之后将边界框分布概率还原为预测框,通过CIoU对预测框的损失和标签的真实框进行损失计算,以达到对预测框整体优化的结果。CIoU的计算式为:
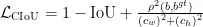
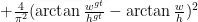
式(4)中,IoU表示预测框与真实框的交集比,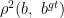 表示预测框与真实框之间的欧氏距离; h 和w 分别表示高度和预测框;
表示预测框与真实框之间的欧氏距离; h 和w 分别表示高度和预测框; 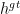 和
和 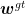 分别表示真实框的高度和宽度;
分别表示真实框的高度和宽度; 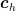 和
和 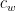 分别表示由预测框和真实框组成的最小包围框的高度和宽度。
分别表示由预测框和真实框组成的最小包围框的高度和宽度。
CIoU在小目标的位置有偏差时非常敏感,对其值的计算也相对复杂,这会导致训练的计算量较大。为解决这个问题,引入了一种基于归一化的Wasserstein 距离NWD (Normalized GaussianWassersteinDistance)位置回归损失函数。NWD使用二维高斯分布计算预测框与标记框之间的相似度,根据式(6)计算它们之间归一化的Wasserstein距离,其中 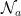 和
和 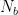 表示由 A 和 B 建模的高斯分布:
表示由 A 和 B 建模的高斯分布:
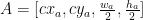
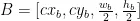
该方法一致地反映了模型检测到的物体分布之间的距离,非常适合用来衡量小目标预测框和实际的相似度。
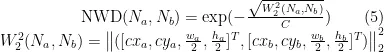
其中,公式(5)中 C 表示数据集中的类别数,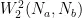 表示一个距离度量。由于CIoU比较关注目标的长宽比差异,可以更好地衡量边界框之间的相似度。因此考虑将CIoU与NWD结合使用,如式(7)所示,其中 α 表示CIoU的权重, β 表示NWD的权重。α 与 β 以式(8)的线性关系来组合使用,经过实验得出(表2),此处 β 值为0.5时效果最好。
表示一个距离度量。由于CIoU比较关注目标的长宽比差异,可以更好地衡量边界框之间的相似度。因此考虑将CIoU与NWD结合使用,如式(7)所示,其中 α 表示CIoU的权重, β 表示NWD的权重。α 与 β 以式(8)的线性关系来组合使用,经过实验得出(表2),此处 β 值为0.5时效果最好。
L o s s= α ⋅ C I o U+ β ⋅ N W D
β = 1 - α
1.5 设计检测头Group-Detect
原模型的检测头包含两个分支,每个分支都需要先分别通过两个 3 × 3 的卷积和一个普通卷积。这致使通道数多的情况下,参数量就会非常高。为了让模型更加轻量化,设计Group-Detect检测头,其结构如图5所示。此检测头采用参数共享的思想,将前面的3 × 3 的卷积分支合并,减少多余的计算开销。
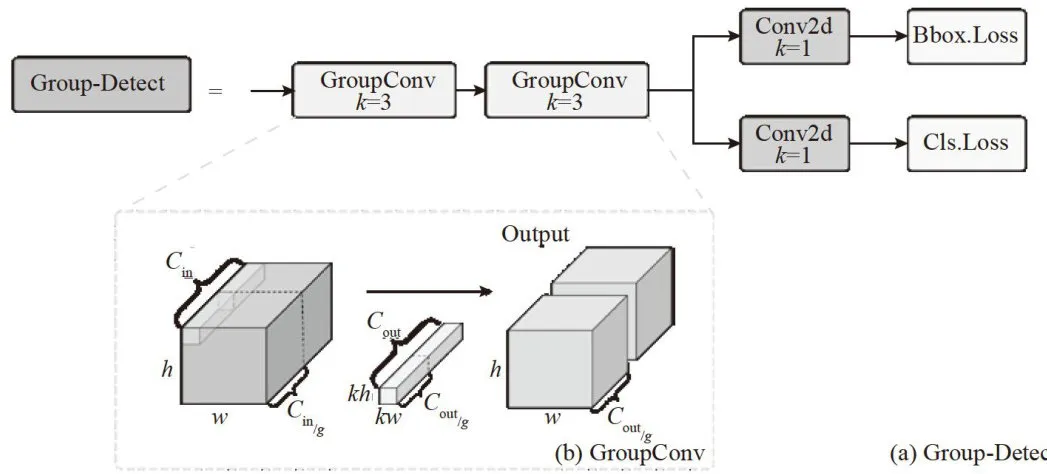 图5Group-Detect 检测头
图5Group-Detect 检测头
我们还在此检测头中添加了分组卷积(GroupConv)[17],即分组卷积。在传统的卷积神经网络中,卷积层通常会对输入的所有通道进行全连接的卷积运算。而在分组卷积中,输入通道被分成若干组,每一组内的通道只与该组内的卷积核相卷积,不同组的通道不相互作用。假设输入特征图有 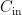 个通道,设定分组数量为 g ,则每组包含
个通道,设定分组数量为 g ,则每组包含 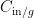 个通道。每组通道分别与对应的卷积核进行卷积操作。每个卷积核只处理一组内的通道,所以卷积核的数量通常是输出通道数
个通道。每组通道分别与对应的卷积核进行卷积操作。每个卷积核只处理一组内的通道,所以卷积核的数量通常是输出通道数 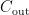 的 1 / g 。将所有组的卷积结果按组顺序拼接起来,就形成了最终的输出特征图。因此分组卷积通过减少每次卷积的通道数,显著降低了参数数量和计算复杂度。在特征图输入检测头后首先经过两个3 × 3 的GroupConv,之后分成两个分支进行普通卷积,以解耦思想执行目标框定位和类别的预测。
的 1 / g 。将所有组的卷积结果按组顺序拼接起来,就形成了最终的输出特征图。因此分组卷积通过减少每次卷积的通道数,显著降低了参数数量和计算复杂度。在特征图输入检测头后首先经过两个3 × 3 的GroupConv,之后分成两个分支进行普通卷积,以解耦思想执行目标框定位和类别的预测。
2 数据集
为了评估YOLO-IRLight模型在无人机应用中检测红外小目标的效果,选用了公开数据集HIT-UAV来进行实验。该数据集是一个高空无人机红外数据集,由2898张红外图像组成,包含了Person、Car、Bicycle、OtherVehicle、DontCare共5个类别。为了简化数据集,我们删除了DontCare类,并将Car和OtherVehicle类别合并为单个Vehicle类别,得到3个类别:Person、Vehicle、Bicycle。最后将数据集按照7:2:1的比例划分为训练集、测试集和验证集。图6是训练集的标签尺寸的分布图,坐标数据分别是标签框的长和宽在原图像的占比,从图中可以看出小尺寸标签占绝大多数。
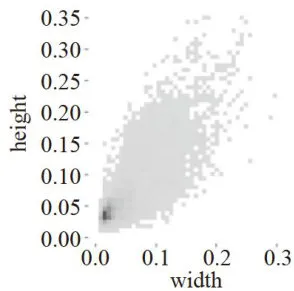 图6标签大小分布图
图6标签大小分布图3 实验分析
3.1实验平台和参数设置
实验使用NVIDIAGPU和PyTorch、Python等,具体参数如表1所示。实验中没有使用任何初始权重,输入图像大小为 6 4 0 × 6 4 0 。训练数据的batchsize为16,训练过程持续200个epoch,且所有实验使用一
致的超参数进行训练验证。
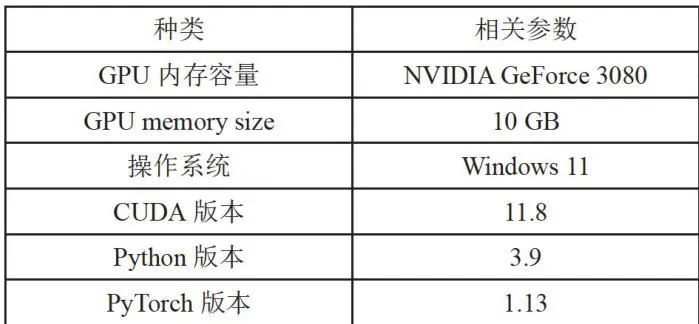 表1实验环境配置
表1实验环境配置3.2 评估指标
使用目标检测中常用的评价指标对模型性能进行全面评估。这些指标包括:F1分数、平均精度均值( m A P@ 0 . 5 ) 、模型参数量(Parameters)。F1分数是评估模型在检测任务中精确度和召回率的一个综合指标,如式(9)所示:

其中Precision为精确度,即模型在预测为正例的样本中的准确程度;Recall为召回率,它评估模型对正例的预测能力。mAP中的AP为P-R曲线下的面积。mAP是所有类面积的平均值, 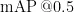 是指使用IoU阈值为0.5,再计算每类图片的AP,最后取平均值,如式(10),其中 K 为类别数。
是指使用IoU阈值为0.5,再计算每类图片的AP,最后取平均值,如式(10),其中 K 为类别数。
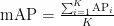
3.3损失函数比例系数
NWD损失函数非常适用于小目标的检测,但考虑到数据集中仍然存在少量的中大尺寸目标,只使用NWD损失函数会导致部分目标漏检和误检。因此尝试将CIoU与NWD线性组合使用,具体比例分配可见表2数据。实验得出 β 值(NWD损失比例)为0.5时,F1分数和检测精度  达到最优效果。
达到最优效果。
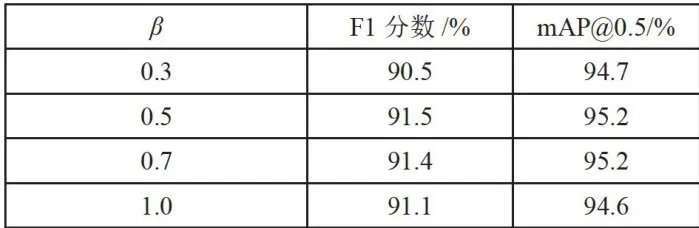 表2损失函数对照实验
表2损失函数对照实验3.4 消融实验
为说明以上所提几项改进方法对基准模型的影响,在HIT-UAV数据集中进行如下消融实验,表3中展示了将各改进点分别添加到YOLOv8s模型中的结果。
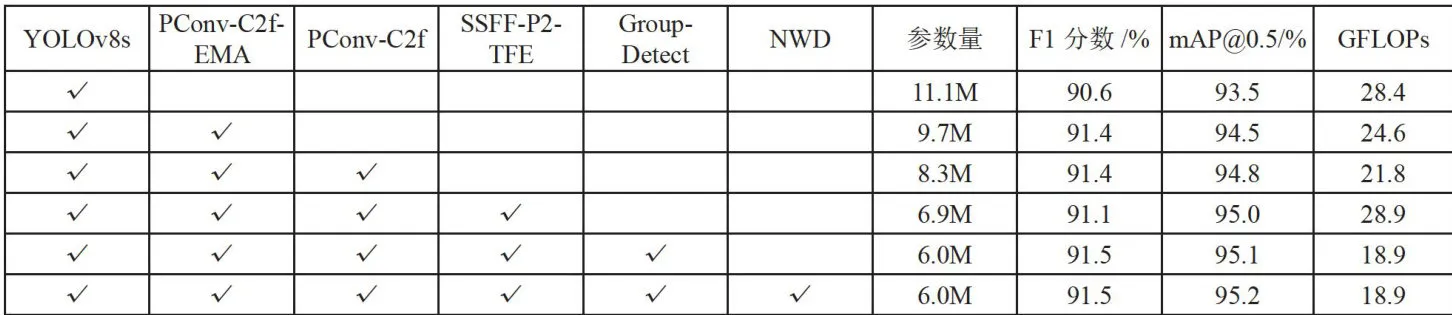 表3消融实验
表3消融实验从表3可以看出,对于红外拍摄的小尺寸目标检测,改进后的算法在每个阶段都有一定的提升。虽然在加入SSFF-P2-TFE模块时,参数量有一定的增长,但是精度也得到了提高,且其他模块都做了轻量化处理,总体参数量和计算量都相较于原模型有所减少。实验结果表明,每个阶段的网络结构优化,都取得了较好的效果。
3.5 比较实验
表4给出了YOLO-IRLight模型与其他5种主流目标检测模型的对比结果,我们可以着出在检测精度⟨ m A P@ 0 . 5 ⟩ 方面我们的模型较其他模型高出至少24 % ,F1精度也位居首位,超出其他模型最好表现的21 % 以上。数据量虽然略高于EfficientDet模型,但是以15GFLOPs的数据量获取了两倍于EfficientDet的检测精度,是非常可观的。
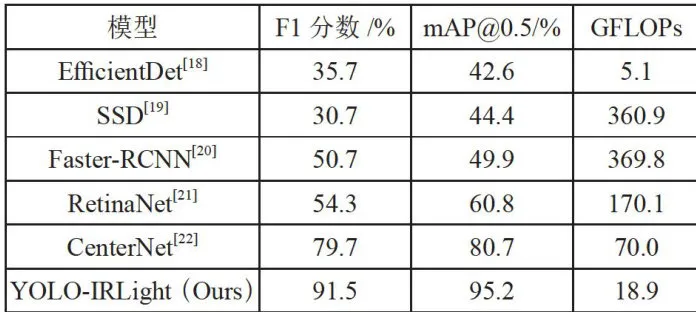 表4主流算法对比
表4主流算法对比表5在YOLO系列的检测模型中横向对比。分析可知,我们的模型在红外小目标检测数据上优于最新发布的YOLO11。与前几代YOLO模型相比,也均在保持低计算复杂度、参数量的同时,取得了较好的小目标检测精度,实现了轻量又精准的目标。
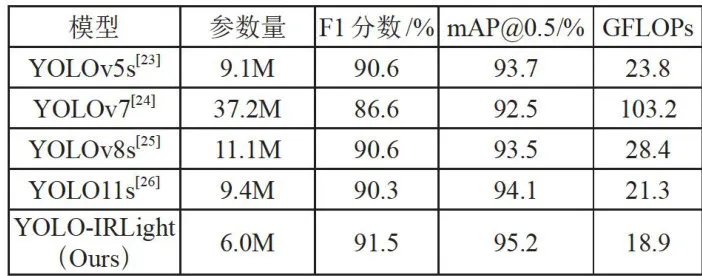 表5YOL0系列算法对比
表5YOL0系列算法对比3.6 可视化对比
为了更直观地展示和比较模型的性能,我们选取几组图像进行预测。
如图7所示,我们挑选了多种类目标同时出现的情况。原始模型在(a)组中对person类误检,在(b)组中将person目标误检为Bicycle类。可以看出原模型在目标种类繁多时有一定的误检率,我们的模型对目标分类较为准确。
 图7 目标误检情况
图7 目标误检情况图8选取的三组图片各有特点,可以看到(c)组图像中小范围内存在不同尺度的目标,(d)组图像的背景非常模糊复杂,(e)组图像有大量目标重叠。在这三种情况中,对比可以看出,原始模型YOLOv8s常出现漏检情况,而我们的模型在多尺度、背景复杂、小目标密集的条件下检测效果依旧良好。
 图8目标漏检情况对比
图8目标漏检情况对比4结论
本文提出了一种基于无人机航拍的红外小目标检测模型YOLO-IRLight。针对航拍目标的低像素、信息匮乏,无人机载模型臃肿、计算不够轻量等问题,使用部分卷积PConv和EMA注意力机制,引入SSFF和小目标检测层重塑网络结构,设计轻量化检测头改进网络模型。新模型的参数量和计算量相较于基准模型都有所下降,平均精度 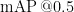 也提升到了 9 5 . 2 % 。我们在HIT-UAV数据集上进行测试和比较,证明了本文中模块改进的可行性。通过对比试验,可以得出YOLO-IRLight在准确率和模型复杂度方面优于主流网络模型,对于红外模糊小目标的识别效果良好,存在一定的实用价值。
也提升到了 9 5 . 2 % 。我们在HIT-UAV数据集上进行测试和比较,证明了本文中模块改进的可行性。通过对比试验,可以得出YOLO-IRLight在准确率和模型复杂度方面优于主流网络模型,对于红外模糊小目标的识别效果良好,存在一定的实用价值。
参考文献:
[1]李文博,王琦,高尚.基于深度学习的红外小目标检测算法综述[J].激光与红外,2023,53(10):1476-1484.
[2]宋婉妮,杨本臣,金海波.基于改进加权局部对比度的红外小目标检测[J].激光与红外,2023,53(6):963-969.
[3]YOUNSIM,DIAFM,SIARRYP.AutomaticMultipleMoving Humans Detection and Tracking in Image SequencesTaken from a Stationary Thermal Infrared Camera [J/OL].ExpertSystems with Applications,2020,146:113171[2024-10-05].https://doi.org/10.1016/j.eswa.2019.113171.
[4]QI M,LIUL,ZHUANGS,etal.FTC-Net:Fusion ofTransformerandCNNFeaturesforInfrared SmallTargetDetection[J].IEEE Journal of Selected Topics in Applied Earth Observationsand Remote Sensing,2022,15:8613-8623.
[5] JIANG CC,REN H Z,YANG H,et al. M2FNet:Multi-ModalFusionNetworkforObjectDetectionfromVisibleand Thermal Infrared Images [J/OL].International Journal ofApplied Earth Observation and Geoinformation,2024,130:103918[2024-10-23].https://doi.org/10.1016/j.jag.2024.103918.
[6]LIANG M,JI T.Research on Unmanned InfraredNight Vision System Based on Improved Faster R-CNN TargetDetection Algorithm[C]//2022 IEEE 5th Advanced InformationManagement,Communicates,Electronic and Automation ControlConference (IMCEC).Chongqing:IEEE,2022:863-869.
[7]WANGK,WANGY,ZHANGS,etal.SLMS-SSD:Improving the Balance of Semantic and Spatial Information inObject Detection [J/OL].Expert Systems with Applications,2022,206: 117682[2024-10-11]. https: //doi.org/10.1016/j.eswa.2022.117682.
[8]LUJ,HUANGT,ZHANGQ,etal.ALightweightVehicle Detection Network Fusing Feature Pyramid and ChannelAttention[J/OL].Internet of Things,2024,26:101116[2024-10-18].https://doi.org/10.1016/j.iot.2024.101166.
[9] WANG H,MO H,LU S,et al.Electrolytic CapacitorSurface Defect Detection Based on Deep Convolution NeuralNetwork [J/OL].Journal ofKing Saud University-Computer andInformation Sciences,2024,36 (2):101935[2024-10-23].https://doi.org/10.1016/j.jksuci.2024.101935.
[10] ZHENG H,SUN Y,LIU X,et al. Infrared ImageDetection of Substation Insulators Using an Improved FusionSingle Shot Multibox Detector [J].IEEE Transactions on PowerDelivery,2020,36(6):3351-3359.
[11] XINGANG M, SHUAI L,XIAO Z. YOLO-FR: AYOLOv5 Infrared Small Target Detection Algorithm Based onFeature Reassembly Sampling Method[J].Sensors,2023,23(5):2710-2710.
[12] ZHU JX,QIN C,CHOI D M. YOLO-SDLUWD:YOLOv7-based Small Target Detection Network for InfraredImages in Complex Backgrounds [J/OL].Digital Communicationsand Networks,2023[2024-10-27].https://doi.org/10.1016/j.dcan.2023.11.001.
[13] SUN S,MO B,XU J,et al. Multi-YOLOv8:An Infrared Moving Small Object Detection Model Basedon YOLOv8 for Air Vehicle [J/OL].Neurocomputing,2024,588:127685[2024-11-05].https://oi.0rg/10.1016/j.neucom.2024.127685.
[14] CHEN J,KAO S,HE H,et al. Run,Dont Walk:Chasing Higher FLOPS for Faster Neural Networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision andPatterm Recognition.Vancouver: IEEE,2023:12021-12031.
[15] KANG M,TING CM,TINGFF,et al. ASF-YOLO:A Novel YOLO Model with Atentional Scale Sequence Fusion forCellInstance Segmentation [J/OLJ.Image and Vision Computing,2024,147: 105057[2024-11-06].https://oi.org/10.1016/j.imavis.2024.105057.
[16] WANGJ,XUC,YANG W,et al.A NormalizedGaussian Wasserstein Distance for Tiny Object Detection [J/OL].arXiv:2110.13389 [cs.CV].[2024-10-23].2021.https://arxiv.org/abs/2110.13389v1.
[17] HE S, GIRSHICK R,DOLLAR P, et al. AggregatedResidual Transformations for Deep Neural Networks [C]//Proceedings of the IEEE Conference on Computer Vision andPattem Recognition.Honolulu:IEEE,2017:1492-1500.
[18] TANMX,PANGRM,LEQV.EfficientDet: Scalableand Efficient Object Detection [C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.Seattle :IEEE,2020:10781-10790.
[19] LIU W,ANGUELOV D,ERHAN D,et al. SSD:Single Shot Multibox Detector [C]//Computer Vision-ECCV 2016:14th European Conference,Amsterdam,The Netherlands,October 11-14,2016,Proceedings,Part I.Amsterdam:Springer International Publishing,2016:21-37.
[20] REN S,HEK,GIRSHICK R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region ProposalNetworks [J].IEEE Transactions on Pattern Analysis and MachineIntelligence,2016,39(6):1137-1149.
[21] LINTY,GOYALP,GIRSHICKR,et al.Focal LossforDense ObjectDetection[C]//Proceedings of the IEEE IntemationalConference onComputerVision.Venice:IEEE,2017:2980-2988.
[22] ZHOU X,WANG D,KRAHENBUHL P. Objects asPoints[J/OL].arXiv:1904.07850[cs.CV]. (2019-04-16) [2024-10-05].https://arxiv.org/abs/1904.07850v1.
[23]Ultralytics.Comprehensive Guide to UltralyticsYOLOv5[EB/OL]. (2022-11-22) [2024-10-07].https://docs.ultralytics.com/yolov5/.
[24]WANGCY,BOCHKOVSKIYA,LIAOHYM.YOLOv7:Trainable Bag-of-Freebies Sets New State-of-the-ArtforReal-Time ObjectDetectors[C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:7464-7475.
[25]Ultralytics.Ultralytics YOLOv8[EB/OL].(2023-01-10)[2024-10-09].https://github.com/ultralytics/ultralytics.[26]Ultralytics.Ultralytics Solutions:Harness YOLO11 toSolve Real-World Problems [EB/OL]. (2024-09-30) [2024-10-15].https://docs.ultralytics.com/zh.
作者简介:倪梦琪(1999—),女,汉族,河南洛阳人,硕士研究生在读,研究方向:计算机目标识别与跟踪;陈凯源(2000一),女,汉族,河南郑州人,硕士研究生在读,研究方向:缺陷检测和自然语言处理。