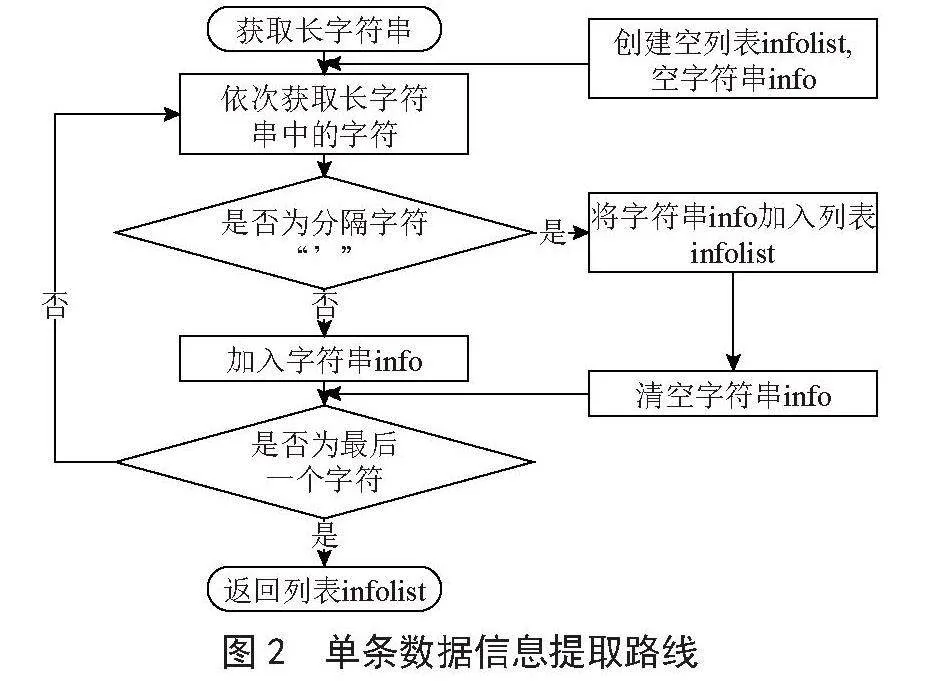
魏迪海
(乐山开放大学,四川 乐山 614800)
0 引 言为了探索适合学生的最优学习要素,一门被称为教育数据挖掘(Educational Data Mining,EDM)的新学科产生。教育数据挖掘实际上就是基于计算机技术的学习系统,交互学习环境,模拟学习环境,现有学校学习系统等采集用户学习行为数据。在心理学和学习科学的理论指导下,利用计算机科学、数据挖掘等领域的知识,发现学生是如何学习。EDM 的优势体现在可以把不同领域的各种数据连接在一起。它关注从研究所提供的大量数据中提取特征以支持教育过程的进展。
1 研究背景EDM 与传统数据库技术不同,它可以回答问题,例如谁是潜在的课程成绩不及格学生?EDM 可以回答更深层次的问题,例如预测学生的成绩(如果他在考试中通过或失败)。研究人员还可以建立学生模型来单独预测每个学生的特征和表现。因此,参与EDM 领域的研究人员使用不同的数据挖掘技术来评估讲师,以便提高他们的教育能力。
由于当前教育系统并没有重视对学生表现的预测,因此这些系统效率并不高。预测学生感兴趣的课程并了解他在教学活动过程的学习行为可以提高教育效率。结合深度学习和EDM 技术,完成学生的评估过程,可以更好地提高学生的表现以及优化教育过程。此外,深度学习还可以用在更广泛的教育数据,通过模式识别、图像处理、对象检测和自然语言处理等方法。通过机器学习技术实现的学习管理系统,可以利用数据挖掘来获得更好、更准确的结果。
本文提出一种深度学习方法,通过在长短期记忆(LSTM)上实施卷积神经网络来构建学生表现的预测模型,可以基于学生数据预测他将来的学习表现。本文还引入了数据预处理技术(如mini-max scaler 和quantile transforms)以提高结果的准确性。本研究的目的是提取新特征并找到它们的权重,以根据从特征中导出的权重来构建变量节点和隐藏层的神经网络系统。然后,在构建系统后使用这些特征及其权重来预测有关学生的信息。
2 深度学习技术2.1 基本概念数据科学和现代技术(如大数据和高性能计算机)的发展为机器学习提供了通过复杂系统理解数据及其行为的机会。机器学习使计算机能够在不同的算法中学习,而无须严格执行来自某个程序或有限指令集。
深度学习是直接从不同媒介的数据学习有用特征的机器学习技术,其利用许多神经网络层来进行无监督或有监督的非线性数据处理,以进行分类和模式识别任务,模拟了人脑分析、决策和学习方面的能力。深度学习的目标是模拟人脑直接从无监督数据中提取特征。
深度学习的核心是对信息的特征和表示进行分层计算,例如对低层到高层的特征分别进行定义。虽然机器学习获得大量学生的前期学习表现数据,但执行时由于忽略了数据行为特征常常不能得到理想的效果。而深度学习的特征是从特定的学生数据中自动提取的。这种特征方法是深度学习系统独立的一部分。
可见,利用输入数据计算表示特征是预测学生未来表现的关键。本文通过大量的实际学生课程数据,例如学生之前学期的平均成绩绩点和所获得学分,作为深度学习的提取特征,来进行学生学习表现的预测研究。
2.2 常见的深度学习技术2.2.1 深度神经网络(DNN)
DNN 是一个具有多个隐藏层的神经网络。它的模型在复杂的数据和非线性函数下表现更好。这种类型的深度学习可以适应训练期间对隐藏层的任何改进,并且训练通过反向传播算法进行。由于DNN 在使用复杂数据的预测模型时具有良好的可扩展性,因此被认为适用于教育深度学习预测。
2.2.2 卷积神经网络(CNN)
CNN 由于能够识别各种完整的特征行为而被广泛应用于图像识别的各个领域。因此,它的用途被扩展到包括教育和学习预测过程。从这个意义上说,CNN 与神经网络类似,一般是由连接的多个神经元以分层的形式组成,通过训练完成分层结构。DNN 在连接上与网络不同,例如深度信念网络、反向传播和稀疏自动编码器;网络中的每一层可以共享每个神经元的权重,因此权重可以控制网络中的层。CNN 通过在特定时间点提取新特征用于学生行为,该特征考虑了教育状况的特征。
2.2.3 递归神经网络(RNN)
RNN 考虑了一种神经网络算法,并在数据序列方面表现良好。该算法的优点之一是它记录了当前状态或下一个状态中使用的先前状态。除隐藏层外,还有动态输入输出层;在隐藏层内部,输入和输出情况由一个节点到另一个节点的输出权重表示。由于隐藏层中的连接和反馈路径,此类算法在训练期间的优势适用于预测。
2.2.4 长短期记忆(LSTM)
LSTM 模型被定义为RNN 的变体。该算法的价值在于在隐藏层中创建了自环。它在系统运行过程中自动生成路径,并在每次迭代中生成短路径。它类似于DNN,但在更新影响神经网络中排序路径的权重方面有所不同。这种类型使用历史中的先前数据来提取有用的信息(通常为特征),以实现更好的学生行为预测。
本研究的主要目的是通过考虑以长短期记忆(LSTM)为代表的深度学习技术并利用基于时间的特征提出一种新方法。
3 基于深度学习长短期记忆网络的预测为了从前一门课程的表现中预测学生下一门课程的表现,本文利用收集的数据去训练所提出的模型。从多学科大学采集真实数据后,进行数据预处理,去除冗余属性、噪声等。然后,根据数据获取日期将数据分为两组:第一个数据集来自2007年到2016年,用于训练,而第二个数据集来自2016年到2019年,用于测试所提出模型的预测能力。测试过程一些评价指标评估所提出的预测模型的准确能力。
本文提出的整体模型框架如图1所示,包含四个阶段。第一阶段为收集数据,并建立一个简单的学生数据库。第二阶段为数据预处理过程,提取操作数据和有用信息数据并进行预处理操作,包括对它们的权重根据特征进行计算。第三阶段为把这些特征输入到神经网络,然后创建多个隐藏层来处理数据。第四阶段是模型评估,包括训练模式和带有评价指标的测试模式。
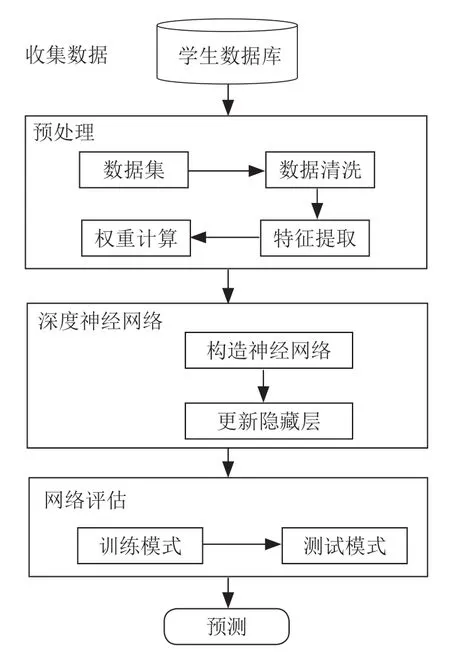
图1 学生成绩预测网络流程图
3.1 数据说明本文从某所大学收集数据,包含2007年至2019年的课程、学生、分数等信息,有4 699 个科目(课程)、83 993 名学生和3 828 879 条记录。除了训练和测试样本之外,这些数据集还使用样本信息描述数据分布。还考虑了训练率和总样本数。
该数据集代表16个学术单位(学院/研究所/学院)的学生表现。数据分为两个不相等的部分。主要部分(从2007年到2016年收集的数据)用于训练,而剩余的样本部分(从2017年到2019年收集的数据)用于测试。训练数据集和测试数据集的课程绩点的统计直方图分别如图2和图3所示。其中,经济学教育的数据占比最高,约为18%,而物理教育的占比最低,仅为0.9%。可以看到,约89.7%的训练数据集的课程绩点水平等于或大于中等等级,而测试数据集等于或大于中等等级的百分比为88.6%。
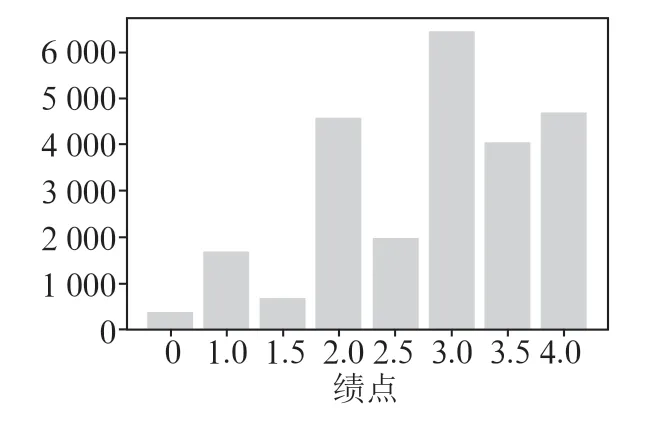
图2 训练数据集的统计直方图
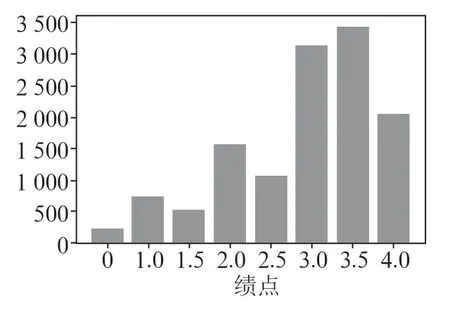
图3 测试数据集的统计直方图
3.2 数据集预处理和转换由于收集的数据包含冗余信息,需要通过预处理解决数据冗余属性和噪声等。主要步骤如下:(1)清除课程名称、讲师姓名、学生姓名等冗余属性;(2)清除学生已注册但考试、免修课程等未完成的冗余或噪音记录;(3)清除一些上课学生总数少于15人时的课程;(4)将字符串或文本值转换为数值。
对整个输入数据进行分析后选择学习模型输入属性,见表1,为本文使用的数据集样本。这些选定的属性是根据实验结果和一些以前的学生表现预测模型选择的。
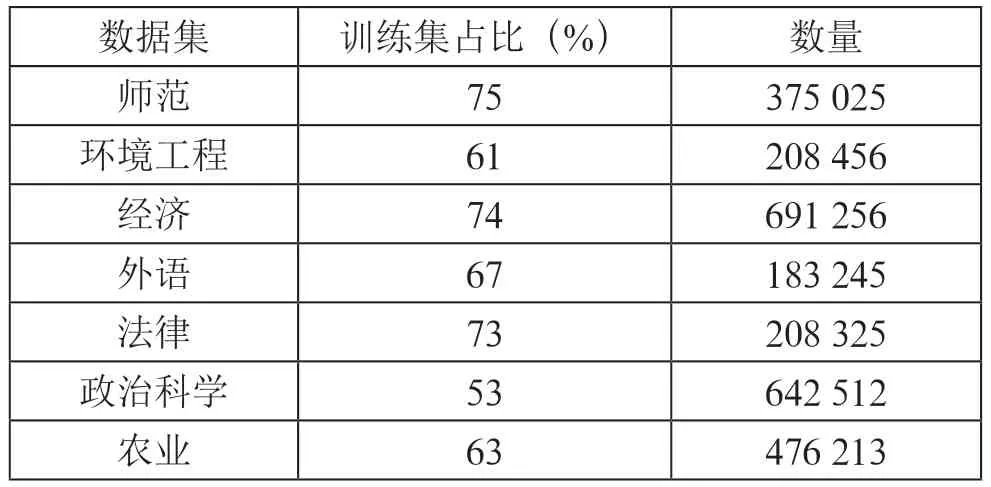
表1 部分训练集内容
由于各种属性存在不同的分布,对预测模型使用分位数变换法(Quantile Trans Formation,QTF)和最小最大缩放法(Min-Max Scaler,MMS)来生成和转换深度学习网络收敛的值范围。
由于非线性变换QTF 可以显著减少异常值的影响,因此它被认为是目前最好的预处理技术之一。高于或低于拟合界限的验证数据/测试数据的值被设置为输出分布范围。在数据转换之前,每个特征的分布和范围都有显着差异。QTF数据将被转换到0 和1 之间。例如,对于工程技术课程,其训练数据如图4所示,而测试数据如图5所示。可见,经过对特征执行MMS 后,数据更接近正态分布。
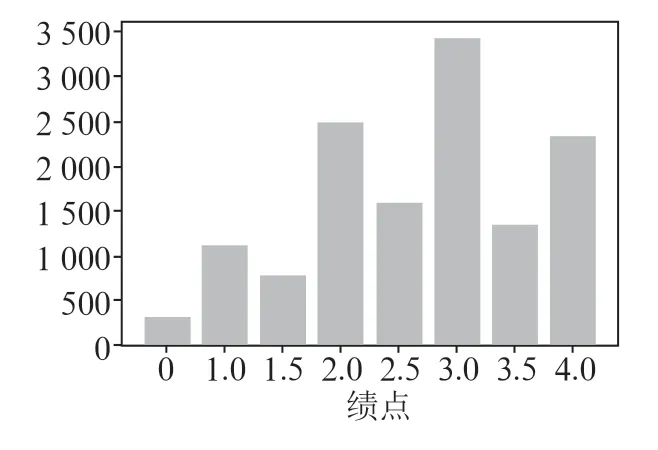
图4 工程技术课程训练数据集的统计直方图
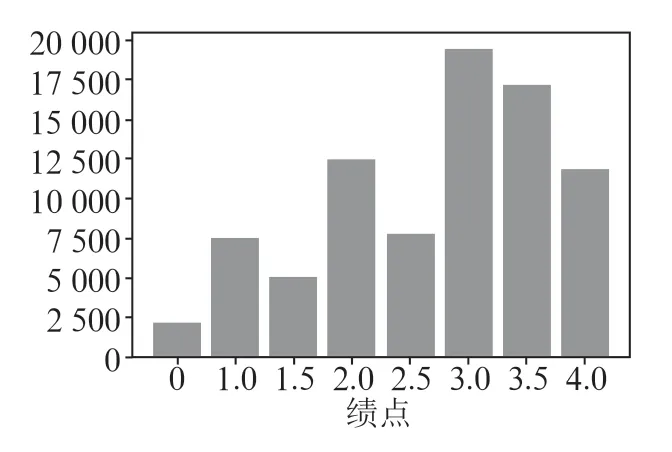
图5 工程技术专业测试数据集的统计直方图
MMS 具体针对每幅图像创建区间,通过使用式(1)和式(2),把每个特征的转换到给定范围内:
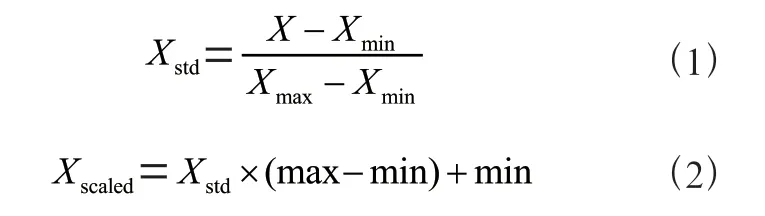
通过这些算法,本文的实验结果与回归任务中的原始数据相比,有较好的效果了可喜的成绩。通过从训练集中学习,将缩放器应用于测试集。
3.3 网络模型训练使用深度学习和线性回归两种算法来实现学生成绩预测模型。1D-CNN 接收21 个特征的1D 数据向量;然后,它将通过一个卷积层的堆栈,该卷积层有64 个节点,每个节点有3 个内核。然后,在每次卷积之后,将执行整流线性单元(rectified linear unit,ReLU)激活函数,如图6所示。
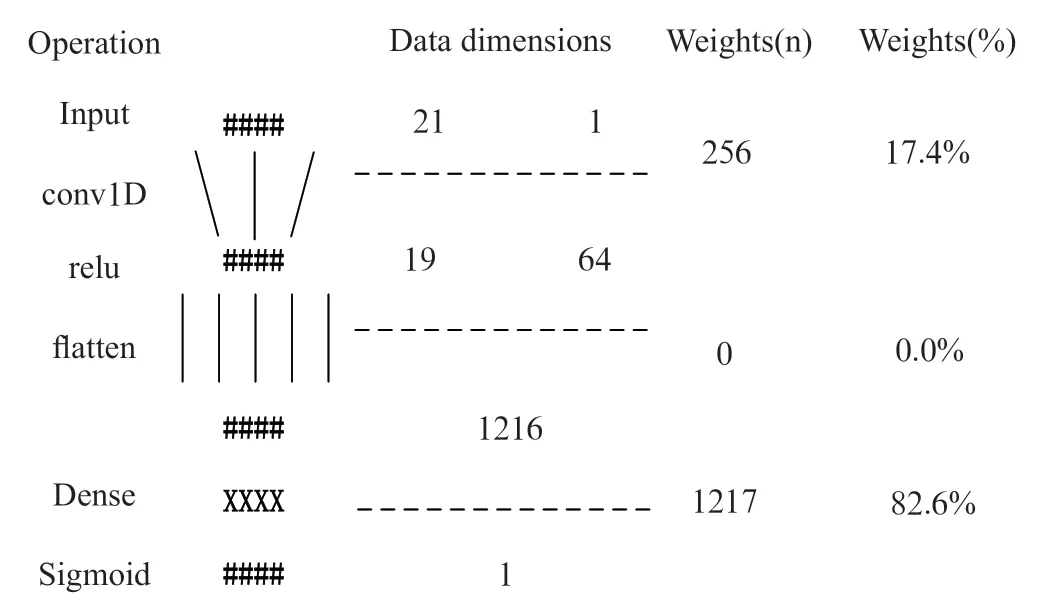
图6 本文实施的整体架构
其中,LSTM 包括64 个Tanh 单元和单次步长。在1D-CNN 和LSTM 上使用式(3)所示的Sigmoid 函数产生范围为0 到1 的输出。为了模拟范围为0.0 到4.0 的学生成绩,方程(3)的输出将乘以4.0:
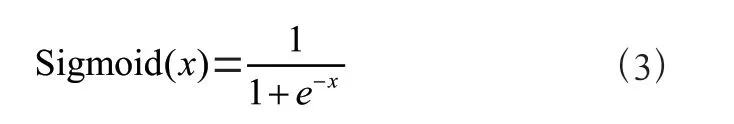
在本文的深度学习模型中,使用均方根传播(RMSProp)算法或Adam 算法,作为优化函数,学习率为0.000 1。在500 个epoch 到达之前,获得了16 000 epoch 的大小。为了减少过拟合的影响,把5 个epoch 作为迭代停止条件。如果在每个连续的epoch 之后损失没有减少,也会停止模型的训练。此外,Scaler 算法针对训练集执行,同时对训练集和测试集进行转换。
回归的性能可以通过MAE 和RMSE 在测试集上平均运行5次来评估。MAE和RMSE可以分别使用式(4)和式(5)计算:
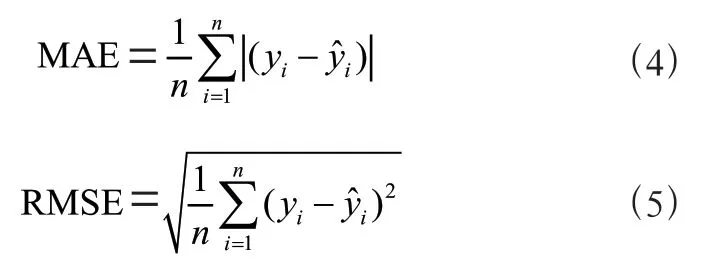
其中y是学生的真实成绩值(范围从0.0 到4.0),是学生的预测成绩值。
实验结果由以下部分给出。可以看出QTF 对回归任务的预处理数据有不错的性能表现。选择的缩放器与RMSProp和Adam 一起运行,作为两个优化器进行比较。该研究是通过线性回归和深度学习以及优化器函数和最佳缩放器对不同教学单位的所有16 个数据集进行的,并将合并的16 个数据集作为一个数据集进行预测。
结果由多种缩放器计算获得。很明显,缩放器可以提高深度学习性能。在使用的缩放器中,QTF 的表现最好,在16 个数据集中,它得出的15 个数据集通过1D-CNN 和LSTM 方法,在CNN 的一层(1D)有明显的改进。
Adam 优化器函数和RMSProp 的比较结果如表2所示。通过使用RMSProp,16 个数据集中有14 个得到了改进,所有数据集的平均改进约为3.3%。
在测试模式和训练模式下,不同算法中,结果略有不同。相比其他方法,它们在相同的条件有更好的性能表现。本文将所得结果与现有数据集进行比较,图7说明了本文方法与训练集基本同质。
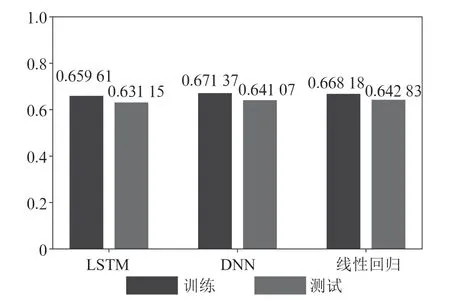
图7 在同一数据集上测试和训练不同方法的模式
对于所提出的系统,我们有两种模式,首先是训练模式,使用标记数据提前学习系统,并使用表2中所示的标准数据集运行系统。然后是测试模式,对所需专业学生进行成绩预测。
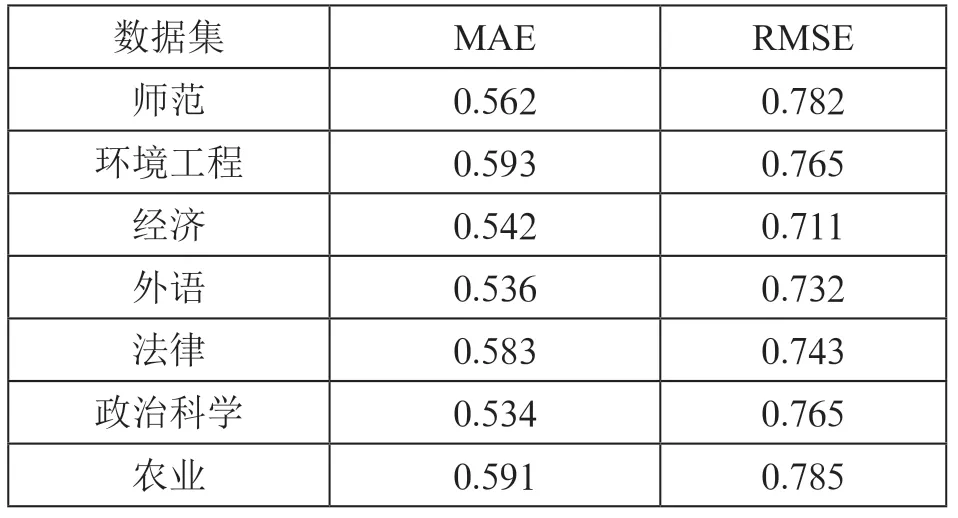
表2 预测性能最优函数
5 结 论本文提出了一种应用于高等教育方面的深度神经网络,并通过比较学生的水平和成绩来识别和预测学生学习表现行为。本文的深度神经网络构建有四个步骤,包括数据初始化和预处理,在神经网络中构建隐藏层的过程,为每个层提取有用的特征和权重。为了提高预测精度,我们使用了Adams 和RMSProp 两种模型在网络训练过程。所提出的方法从所取得的结果中证明了它的价值,并且可以在实际中使用。通过这些结果,在教职员工和学生方面帮助教育机构很容易。将来,可能需要提取的更新特征,并仔细选择它们的权重;通过更新神经网络中的隐藏层,可以使系统更加可靠。