吕俊杰
(西南政法大学图书馆,重庆 401120)
0 引 言CiteSpace 是在科学计量学、数据可视化背景下逐渐发展起来的引文可视化分析软件,着眼于分析科学文献中蕴含的潜在知识,通过可视化的手段来呈现科学知识的结构、规律和分布情况。2005年,中国引入“科学知识图谱”(mapping knowledge domains)。科学计量学界的权威专家刘则渊教授将CiteSpace 知识图谱的形态概括为“一图展春秋,一览无余;一图胜万言,一目了然”。近10年来,随着软件的逐渐普及,使用CiteSpace 开展的研究、发表的论文呈逐年递增的趋势,其优秀的文献分析能力得到各领域学者的充分认可,如图1所示。为了真实反映学者利用CiteSpace 进行学术研究的详细情况,以及应用过程中存的问题,本文对近5年来CiteSpace 相关文献的全文内容进行深度挖掘,了解这些文献涉及哪些领域的研究,研究数据获取方式,学者能否熟练使用软件功能等,以期大多数使用者能够更合理、更高效地学习或使用该工具,同时促进文献计量学分析软件的发展和进步。
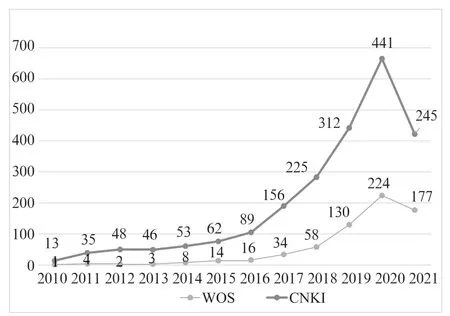
图1 年度发文趋势
1 研究方法1.1 数据采集研究数据来源于WOS Core Collection 和CNKI(CSSCI.CSCD.北大核心),主题=“Citespace”,发表年份=“2017—2021”,语言=“中文、英文”,文献类型=“Article & Review”,数据检索时间为2021年6月30日。最终采集到符合此次研究要求的期刊论文样本1 881 篇,中文1 347 篇,英文534 篇。
1.2 全文挖掘对所采集样本文献的全文内容进行挖掘,从研究主体、期刊载文、数据采集策略、研究领域(含交叉领域)、数据来源、研究时限、软件组合、软件版本、功能视图和制图问题10 个维度进行分类统计。
1.3 统计分析利用Excel 数据透视图从各个维度对汇总数据进行可视化分析。利用R 语言和Eclat 算法计算样本中最常用功能(如作者合作、关键词共现、文献共被引等)及功能组合。基于样本插图效果分析制图问题,划分学者软件使用熟练度层次,探究学者在应用CiteSpace 过程中存在的不足。
2 数据分析2.1 研究主体应用CiteSpace 最多的是中国学者和中国高校,在整体样本中占比超过95%。国内发文前5 的是武汉大学36 篇、中国科学院大学26 篇,华东师范大学25 篇、华中师范大学25 篇、中国人民大学19 篇。国际发文前5 的是四川大学30篇,中国科学院大学20 篇,北京师范大学15 篇,中国医科大学14 篇、武汉大学14 篇、浙江大学14 篇。
2.2 数据采集策略依据样本文献中的“数据集”采集策略,把样本分为定向研究、期刊研究、学科研究、专利研究、区域研究、学者研究、机构研究和工具研究8 类,分类标准及实际数据为:(1)定向研究。该类型样本以明确的“关键词”为检索条件,以某一时段内与之相关的所有文献为数据集。此类型样本在所有样本中占比最大。中文1 273 篇,占比97.51%;英文519 篇,占比97.01%。(2)期刊研究。该类型样本以“期刊名”为检索条件,以一本或多本期刊在某一时段内的所有载文为数据集。中文55 篇,占比4.08%;英文10 篇,占比1.87%。(3)学科研究。该类型样本以数据源的“学科分类”为主要检索条件,以该学科分类下的所有文献为数据集。仅在中文样本中有3 篇。以上三类都有明显的学科领域趋向,是CiteSpace的主要应用类型。(4)专利研究。该类型样本以DII(Derwent Innovations Index)专利引文信息数据库为数据源,针对专利数据的计量分析中文10 篇,英文1 篇。(5)区域研究。该类型样本数据集较为特殊,仅以“发文机构所在区域”为限制条件,且仅在中文样本中有2 篇。(6)学者研究。该类型样本数据集以“学者姓名”为检索条件,包含该学者所有学术文献,仅英文样本中有1 篇。(7)机构研究。该类型样本以“机构名”为检索条件,以某一学术机构产出的所有学术文献为数据集,仅英文样本中有1 篇。(8)工具研究。该类型样本的主要内容是研究工具本身,包括CiteSpace 的使用方法或特征、相似软件的对比研究、CiteSpace 在实际应用中的效果和存在的问题。中文4 篇,英文2 篇。
2.3 研究领域根据上文的研究类型划分,主要应用类型必有其重点研究方向及其大致可归类的学科。中文样本以教育部“学位授予和人才培养学科目录(2018年)”为标准(以下简称学科目录),英文样本以“Web of Science Categories”和“Research Areas”为标准,对主要应用类型样本进行学科归类。
中文样本涵盖了学科目录中的全部学科(13 个学科门类),其中管理学、工学最多,军事学、历史学最少;涉及一级学科74 门,占学科目录中一级学科的67.3%,教育学是最多的一级学科;涉及二级学科171 门,占学科目录中二级学科的42.3%,情报学是最多的二级学科,如图2所示。样本中有172 篇论文的研究方向呈现学科交叉,占中文样本的13.5%,生态学、环境科学与工程、计算机科学与技术是与其他学科交叉研究最多的,如表1所示。
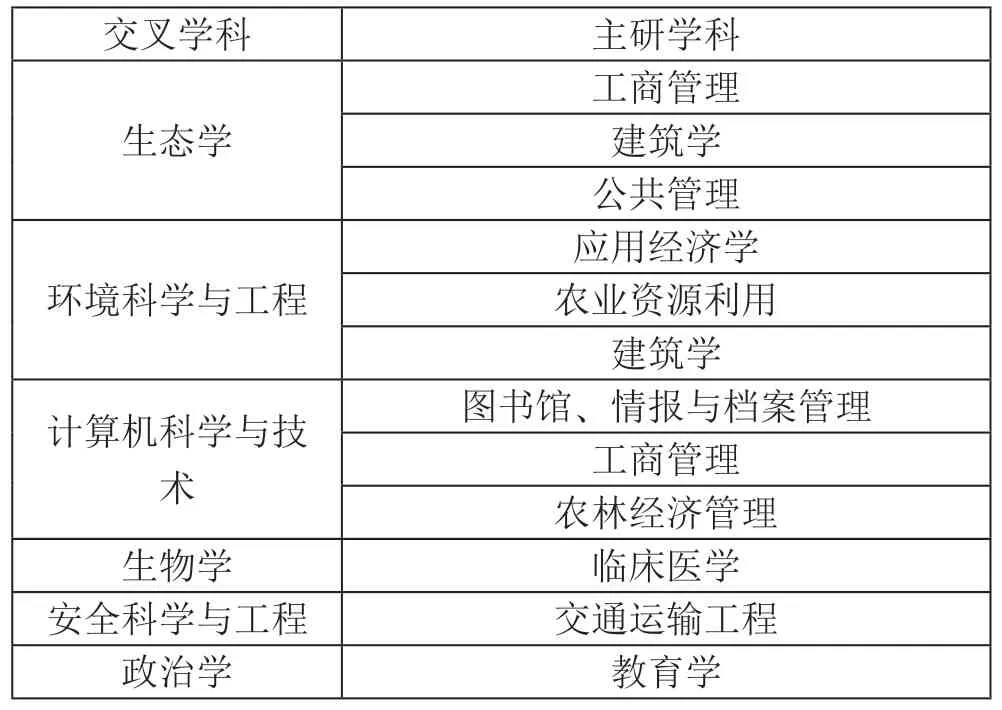
表1 交叉学科
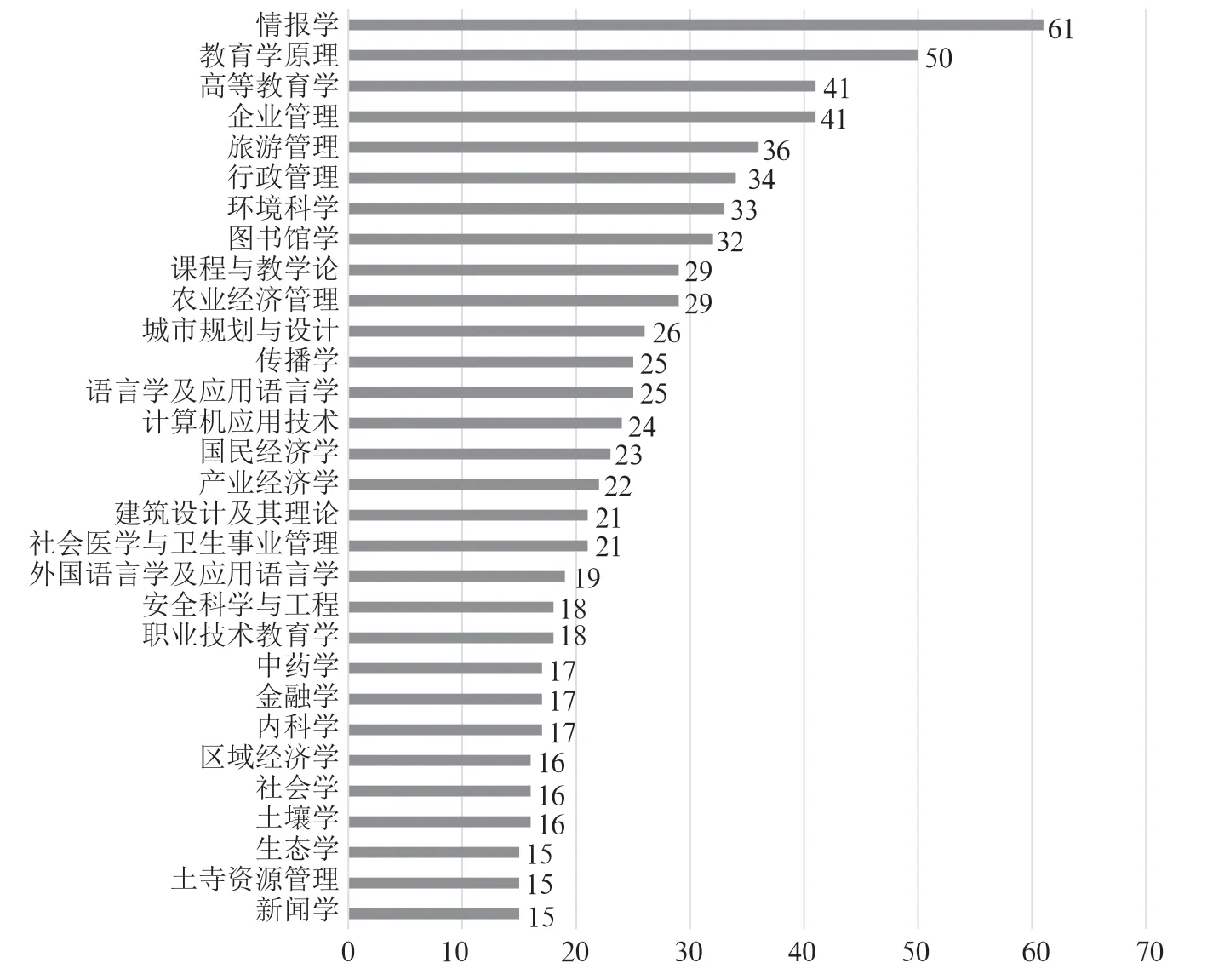
图2 二级学科 Top 30
英文样本涉及WOS 学科分类中的126 门,占所有分类的49.6%,环境科学最多。涵盖84 个研究领域,占所有领域分类的53.2%,如图3所示。样本中245 篇论文的研究方向呈现领域交叉,占比45.8%,其中Computer Science 和Environmental Sciences & Ecology 是与其他领域交叉研究最多的,如表2所示。
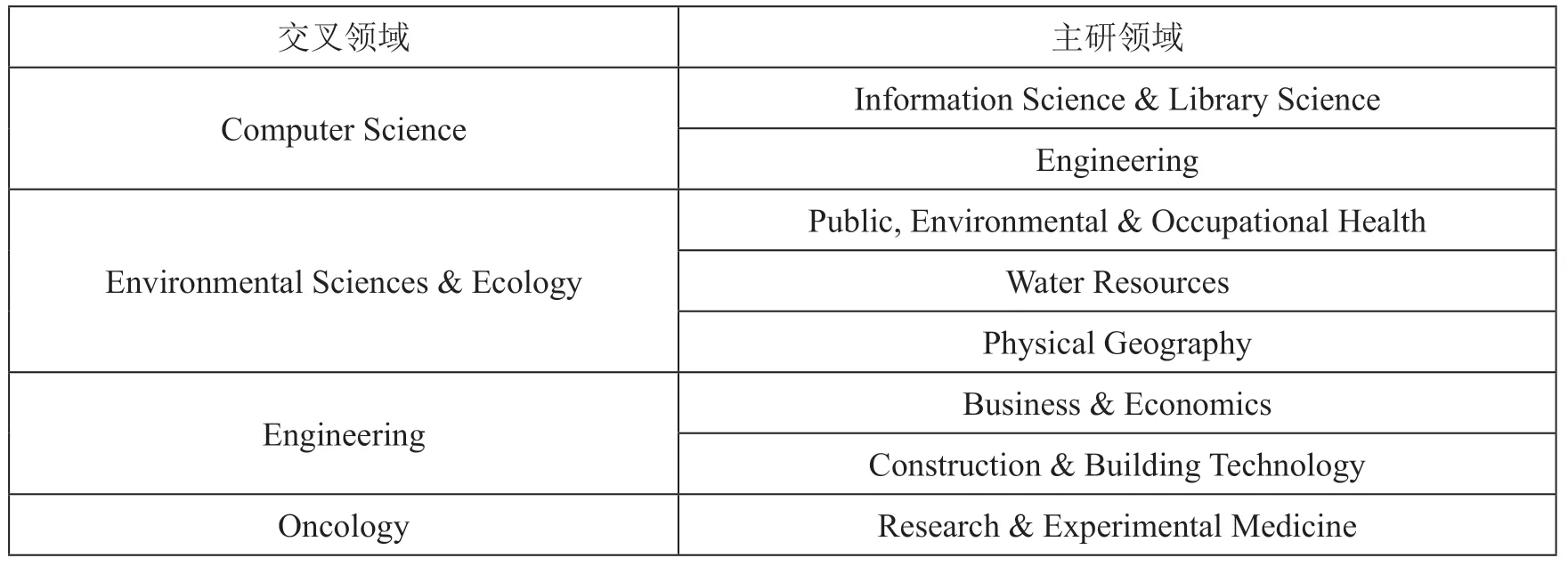
表2 交叉领域
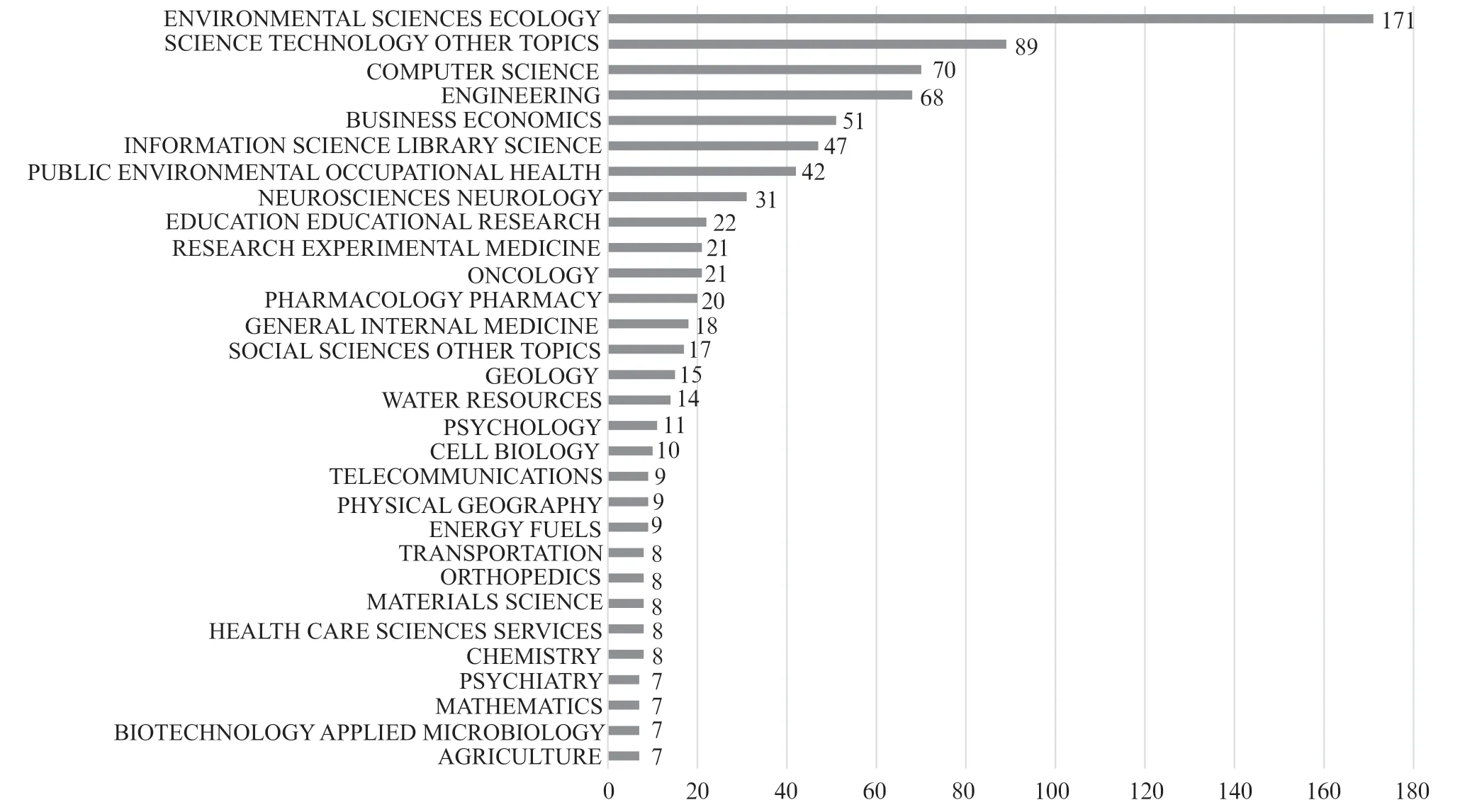
图3 WOS 研究领域Top-30
2.4 数据来源该维度统计样本“数据集”来源于数据库,如表3所示,根据CiteSpace 对数据格式要求,样本数据集主要来源于CNKI、WOS、CSSCI、Scopus、PubMed和DII 这6 个常规数据库,同时非常规数据源有NSF(2019131)、NSFC(w075)、Embase(w195)和政府网站(2017049)。
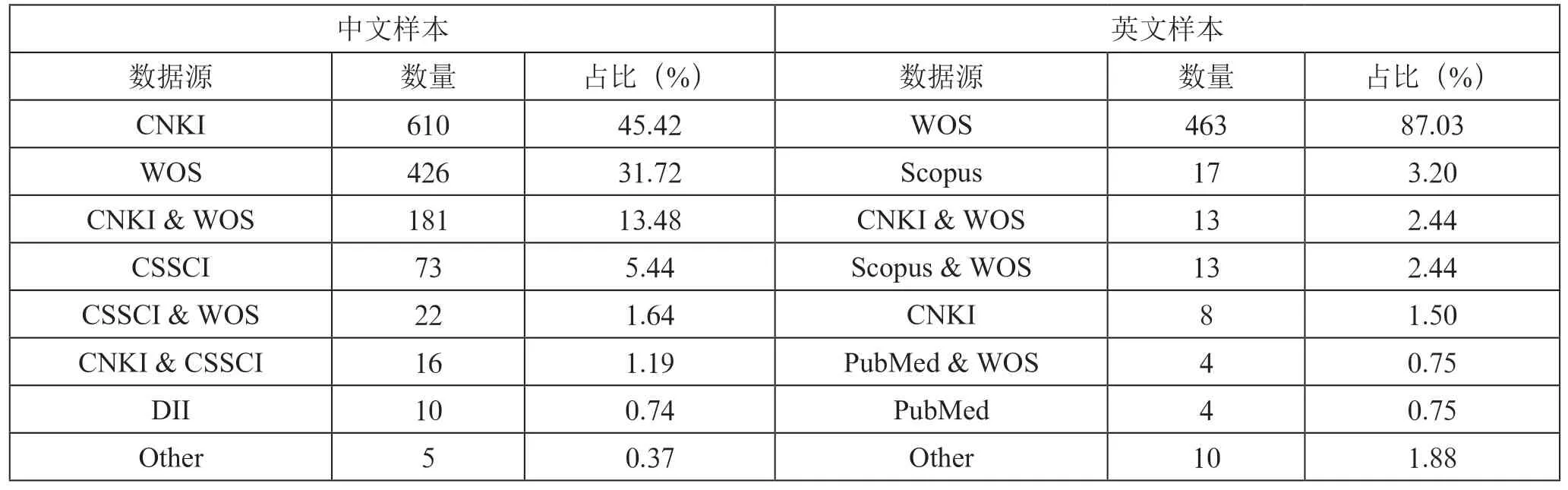
表3 数据来源
2.5 研究时限该维度以样本设置“Time Slicing”参数时的起始时间作为“研究时限”。部分样本在采集数据时采用“All Years”或“1900年至今”策略,实际分析中进行了切割,检索“数据集”和分析“数据集”存在区别。
如表4所示,从全样本来看,83.9%的样本研究时限在30年以内,其中10年期和20年期是最常用时间策略,占整体样本的30.5%。
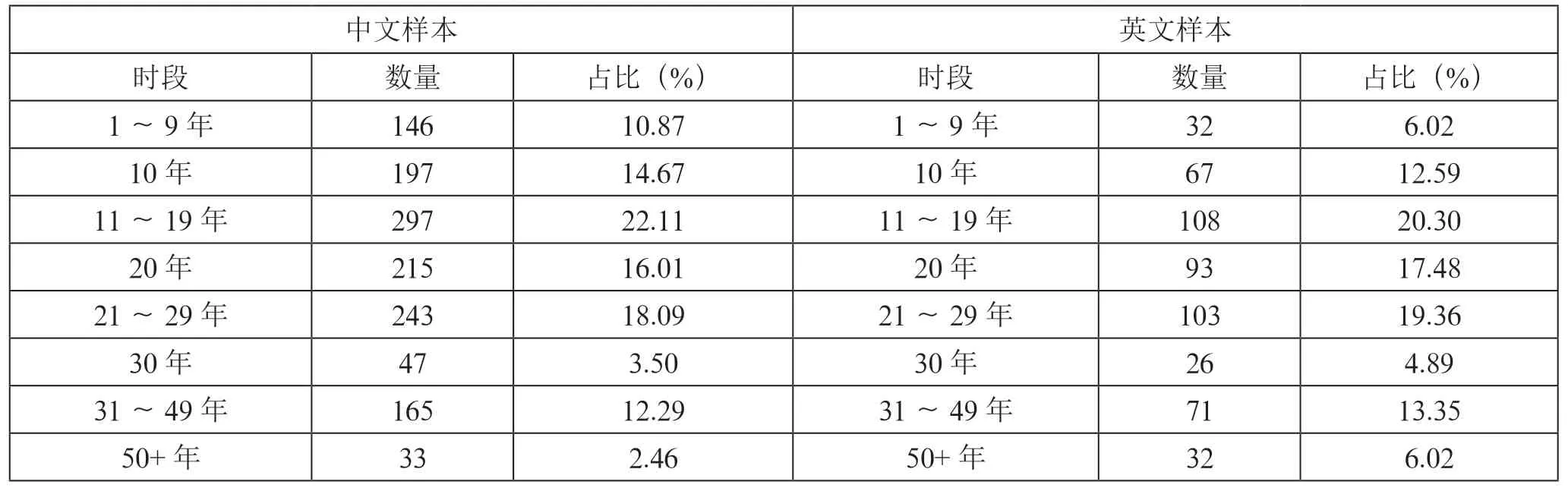
表4 研究时限
2.6 软件组合如表5所示,除使用CiteSpace 软件外,中文样本中有6.5%、英文样本中有29.7%的文献同时使用了其他可视化文献计量分析工具,出现较多的有VOSviewer、HistCite、SATI,此外还有SPSS、Ucinet、Nvivo、Gephi、R(Bibliometrix)、Sci等,总计19 种。

表5 软件组合
2.7 软件版本在所有样本中,有54.3%的文献明确标注了CiteSpace软件版本,使用最多的3 个版本是5.3R4—130 篇,5.5R2—99 篇,5.0R1—78 篇。
2.8 功能视图为了对样本文献中的功能项进行较为直观的描述,需要对CiteSpace 功能做进一步的分类,首先是3 类核心功能Cooperation、Co-occurrence 和Co-citation,包括9 种基础视图;其次是在基础视图上叠加Cluster,或变形Timezone 和Timeline 的进阶视图,共8 种;最后是5 种其他视图,共计22 种。此外,为了体现学者的制图水平,只有样本文献中有CiteSpace 功能视图才纳入统计,仅通过文字描述使用功能(中文样本83 篇,英文样本20 篇),或包含其他软件视图的文献,不计入该维度统计范围。分类后,每条样本至少包含1 种视图,最多包含13 种视图,中文样本平均3.4 种/篇,英文样本平均4.6 种/篇。
引入关联分析中的支持度概念,利用R 语言和Eclat 算法,设置支持度阙值为0.05,计算CiteSpace 功能频繁项集,如表6所示。如在中文样本中有898 篇文献使用{Keyword}功能,出现频率67%;420 篇文献同时使用了{Author,Institution}这2 个功能,出现频率31%;159 篇文献同时使用了{Keyword, Author,W-Timezone}这3 个功能,出现频率12%;117 篇文献同时使用了{Keyword, Author,Institution, Burst}这4 个功能,出现频率9%;类似的组合且出现频率大于5%的总计65 种。中、英文样本在常用功能的使用上有明显区别,英文样本使用较多的是Cocitation 相关功能,而中文样本使用较多的是Cooperation相关功能。
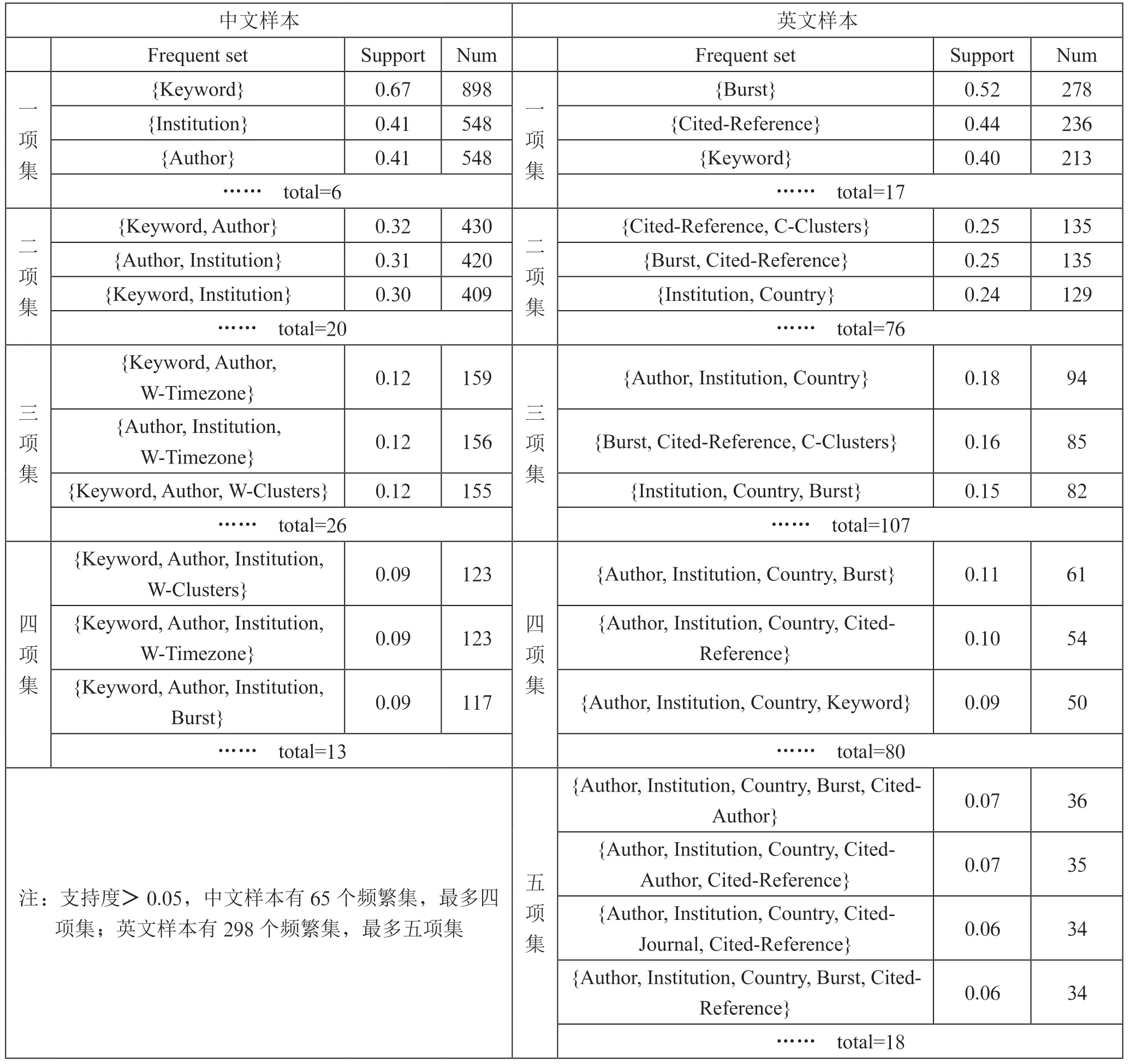
表6 频繁项集
2.9 制图问题制图问题分为两类,一是基础数据的“清洗”问题,有效数据是文献计量分析的“内在”基础,决定分析结果的准确性;二是软件功能的“参数设置”问题,适当的参数调整是数据可视化的“外在”体现,决定视图的可读性。
第一类问题在“Author、Institution、Country、Keyword”合作和共现网络中较为突出,如图4所示。例如在“Institution”合作网络中,同一机构可能出现多种命名方式,“XX 大学教育学院国家重点实验室、国家重点研究基地XX 大学教育学院研究所”。在“Keyword”共现网络中,会出现类似“分析、理论”等无效关键词,或是“三农、三农问题”“精准扶贫战略、精准扶贫策略”等同意关键词。大量的数据噪音会导致样本视图中的网络节点计量不准确,节点间合作关系和合作强度计算错误,研究热点聚类结果出现偏差等情况。
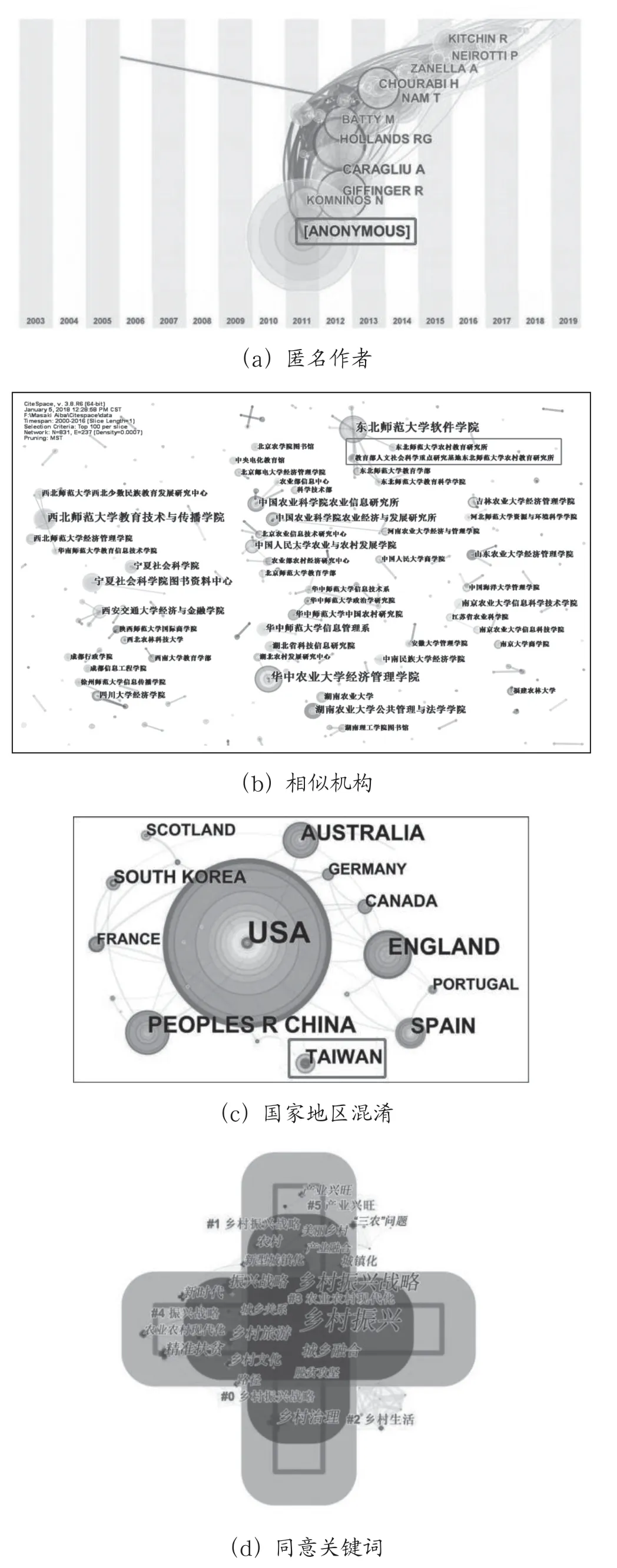
图4 数据清洗问题
第二类问题主要集中在软件的“Pruning、Nodes、Labels、Threshold”等参数设置上,如图5所示,例如在“Keyword”共现网络中,关键词种类太多,未通过“Pruning”网络裁剪的视图中,节点关系纵横交错,节点标签显示混乱;在“Timezone”视图中,“Nodes”位置未调整,标签相互重叠;节点“Threshold”的阙值设置不当,重点不突出;视图功能混淆不清,张冠李戴。以上问题很大程度上降低了视图可读性,造成读者阅读混乱。

图5 参数设置问题
研究发现,中文样本中存在以上一种或几种问题的文献有228 篇,占比17%,英文样本中有46 篇,占比8.6%。
3 研究结果总结以上统计分析内容,可以发现CiteSpace 在国内外论文中的应用现状和应用规律有以下5 点:
CiteSpace 相关研究文献逐年递增,近5年年平均发文376 篇,是文献计量分析的热门工具和热门主题。研究主体以中国学者和中国高校为主,占比在95%以上。武汉大学、四川大学和中国科学院大学,以及师范类和医学类高校是相关研究发文较多的机构。
学者主要利用CiteSpace对某一学术热点进行定向分析,研究数据的目的性强,研究粒度精细,研究灵活度较高。研究所涉及的学科领域众多,完全涵盖了学科目录中的13 个学科门类,教育学是相关研究最多的一级学科,情报学是相关研究最多的二级学科,生态环境、大数据、区块链、教育改革、医疗卫生等领域是与其他学科交叉研究的重点。
CNKI 和WOS 是样本数据的主要来源数据库,学者主要采用以“关键词+时间年限”为检索条件的数据采集策略,研究时限以10年期和20年期居多。中文样本对“Author、Institution”功能使用较多,英文样本对“Burst、Cited-Reference”功能使用较多。英文样本每篇平均功能使用种数多于中文样本。CNKI 数据库不包含引文信息,Co-citation相关功能无法使用,这是中、英文样本在常用功能上有所区别的原因之一。
根据制图问题,可以把学者软件应用熟练度分为高、中、低三个档次。研究发现,20%的学者熟练度较高,能够准确、灵活地使用软件的基础、进阶或高级功能,视图效果清晰美观,可读性强,个别学者还能在原有视图的基础上做进一步的美化和注解。70%的学者熟练度处于中等水平,以使用常规功能为主,进阶功能为辅,视图效果清晰,可读性强。10%的学者熟练度较低,对软件的理解程度不够,仅能使用基础功能,视图效果差,可读性低,更有个别样本存在分析流程不规范,基础数据错误,功能使用混乱,视图无法阅读的情况。CiteSpace 作为一款专业文献计量分析工具,要求使用者具备一定的情报学和计算机专业知识,使用门槛较高,是对学者综合素质的一种考验。随着CiteSpace 的不断普及,涉及的研究领域越来越广泛,此次的研究样本中不可避免地出现了软件滥用的现象。
随着文献计量学理论和计算机软件的发展,各种文献分析软件应运而生,多款软件组合使用的研究模式被越来越多的学者采用,在此次的研究样本中总计出现了19 种,且每种工具都有其独有的优势。CiteSpace 和VOSviewer 是搭配使用最多的组合,在114 篇使用了VOSviewer 软件的英文样本中,有43 篇使用了或只用了CiteSpace 的Burst 功能,由此可见Burst 属于CiteSpace 中较有特色的功能。
4 结 论综上所述,CiteSpace 把文献计量学重要理论与实践操作紧密结合在一起,功能视图多样,可视化效果显著,涉及研究领域广泛,对学术研究起到了重要作用,且软件版本持续更新,成为目前使用体量最大的文献计量分析工具。但其较高的专业性和复杂性使得用户的使用存在一定的难度,就此次研究样本来说,整体应用效果差强人意。鉴于此,初学者在利用CiteSpace 开展相关研究前,应先了解该软件的机制和相应功能,学习借鉴优质制图案例,反复实践练习,熟悉软件细节设置,才能发挥其最好效果,如盲目上手,容易适得其反。就软件本身而言,降低使用难度,有利于初学者更快上手,如能加强数据清洗和智能优化功能,使用效果会更佳。