杨晓叶
(中国人民大学商学院,北京 100872)
引 言随着经济的发展,很多融资行为成为促进经济发展和产业升级的重要措施。但是目前仍然有大量的中小企业无法得到充足的资金支持,且融资难、融资贵的现象早已非常普遍,而且随着经济的持续放缓这种现象将变得更加明显[1]。根据有关数据统计,中国99%的中小企业提供了80%的就业,贡献了50%的GDP[2]。很显然,这种不均衡、不适当的发展情况是目前很多中小企业面临的问题,同时这种融资难的情况也越来越值得学界进行深入研究。
由于环境问题越来越严重,绿色生产、绿色经营得到了社会各界的重视。党的十八届五中全会中将绿色发展作为重点,并提倡将绿色环保的理念与供应链融资相结合,为能源行业、钢铁行业、化工行业等中小企业解决资金问题,并完善绿色生产、回收资源等环节,最终形成环境友好、文明绿色的可持续发展,因此绿色供应链应运而生。而地处沿海的河北省有着独特的港口资源,包括秦皇岛港、唐山港、黄骅港等,也包括钢铁行业和化工加工行业,这些地区的中小企业如果无法合理进行绿色生产和资源回收再利用,那么危害的将不仅仅是陆地环境,同时还有海洋环境。
因此中小企业会面临可再生材料回收以及资金问题这两个核心问题[3]。现在赊销已经成为交易的一种主流方式,处于上游的供应商将货物供给下游企业后,由于资金无法及时返回,容易造成资金短缺的后果,甚至有些信用较低的企业会造成资金供应链的断链[4]。 “互联网+金融”以及“互联网+绿色资金管理”则可以解决资金融通以及绿色材料回收问题。因此, “绿色供应链金融”系列金融产品可以缓解中小企业的困境[5]。
供应链金融的发展也会带来风险。由于面对的不确定因素更多,环境更复杂,绿色供应链金融风险更具隐蔽性、多样性和复杂性。因此本文重点探讨如何科学的识别和评估绿色供应链金融风险,进而达到规避与防控供应链金融风险的目标。
1 绿色供应链和绿色供应链金融的概念绿色供应链金融是为了达到绿色制造的目的,充分发挥供应链中企业的综合优势,绿色供应链金融与一般供应链金融的区别见表1[5]。

表1 两种供应链融资的区别
2 绿色供应链金融模式框架绿色供应链金融发展的前提是存在着供应链关系,且该供应链应该是正向且稳定的。处于下游的回收商将包括零售商、消费者、物流公司等的可回收再利用或再生产的产品交付给上游制造商或生产商,以满足制造商或者生产商的重新加工,这样就形成了绿色供应链的循环。由于赊销方式的畅行,中小企业如果没有及时回收资金,则会产生资金缺口,因此需要与上游的制造商签订电子订单,向银行申请资金融通,并以订单收益来偿还银行贷款。与此同时,环保部门也需要向制造企业和回收商提供排污权证明,为这些企业顺利向银行申请融资提供了保障。本文主要参考沿海地区的生产制造企业循环供应链的研究成果,并进行实地走访调研,得到图1所示的绿色供应链金融模式流程。
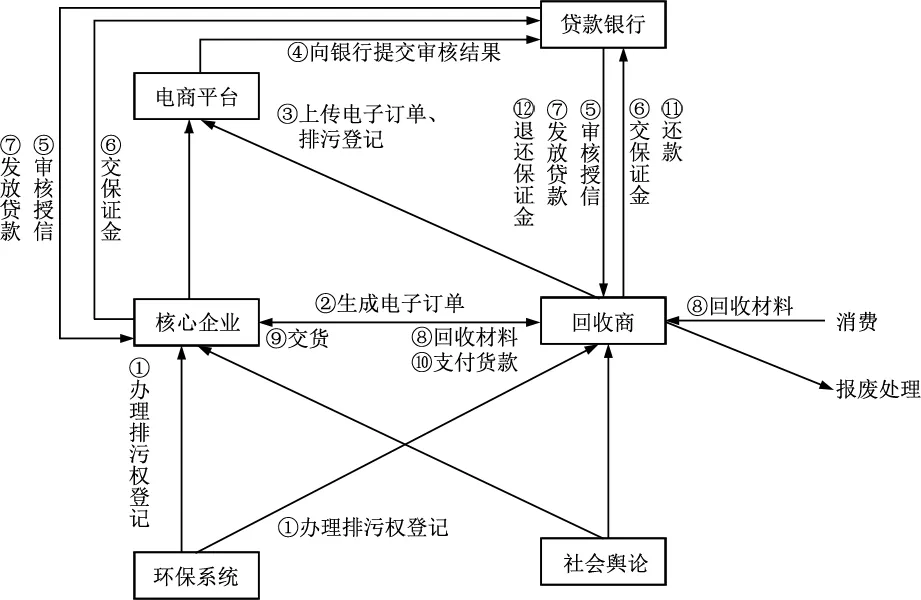
图1 绿色供应链金融的流程
3 绿色供应链金融风险评价指标的确定根据前文对绿色供应链金融风险影响因素的相关分析,初步设计出绿色供应链金融风险评价综合指标体系,如表2所示,共五大类,分15个二级指标,34个三级指标。
4 模型样本的选取本文主要针对 《中小企业划型标准规定》的要求,选取钢铁制造业为主要研究背景,在将某些数据遗失和数据残缺的中小企业剔除后,本文共挑选了30家中小企业。这些中小企业均为符合要求的员工人数在1000以内,营业收入在4亿元以下,同时普遍有着巨大的资金需求。由于钢铁制造业会排放污水、废气等污染物,因此政府部门会综合考察企业排放污染物的程度和是否达到标准,进而发放排污权证明。在获得了排污许可之后,则会面临这融资难问题,这正是本文研究的重点。本文样本数据来自中国钢铁网、国泰安数据库、钢铁信息网、河北省统计局、河北省国资委、国家企业信用信息公示系统,经综合整理后得到30家中小企业近3年的样本数据,样本将这3年的数据整理成90个样本点。为了进一步检验模型的预测精度,研究过程中按2∶1的比例将总样本随机分为训练样本和测试样本,训练样本数据60个,测试样本30个,共90个样本。同时,训练样本和测试样本中又各包括违约样本和非违约样本,将存在违约行为的企业称为ST企业,3年内未出现违约记录的企业称为非违约企业,用非ST企业来表示。违约企业主要是指近3年的财务数据不良、存在不良资产或无法盈利的企业,这样的企业可能会有破产的风险。面临破产的企业会出现大量的违约行为,如无法按时偿还贷款、履行合同等。
将指标数据进行归一化处理,逆向指标进行负向处理。企业的各种指标水平和量纲都是不同的,有些是正向的,有些是负向的,为了使各指标的相关性保持一致,本文将指标进行正向化和无量纲化处理。

表2 绿色供应链金融风险评价指标体系
5 绿色供应链金融指标体系的优选本文采用SPSS20软件计算指标相关矩阵,将相关程度超过0.8的指标进行过滤。除此之外,发现绝大多数指标之间是存在相关性的,说明可以做主成分分析和因子分析,提取共同因子。限于篇幅,以 “核心企业风险”这个一级指标为例,列举出了不同企业之间的相关性和显着性,如表3所示。
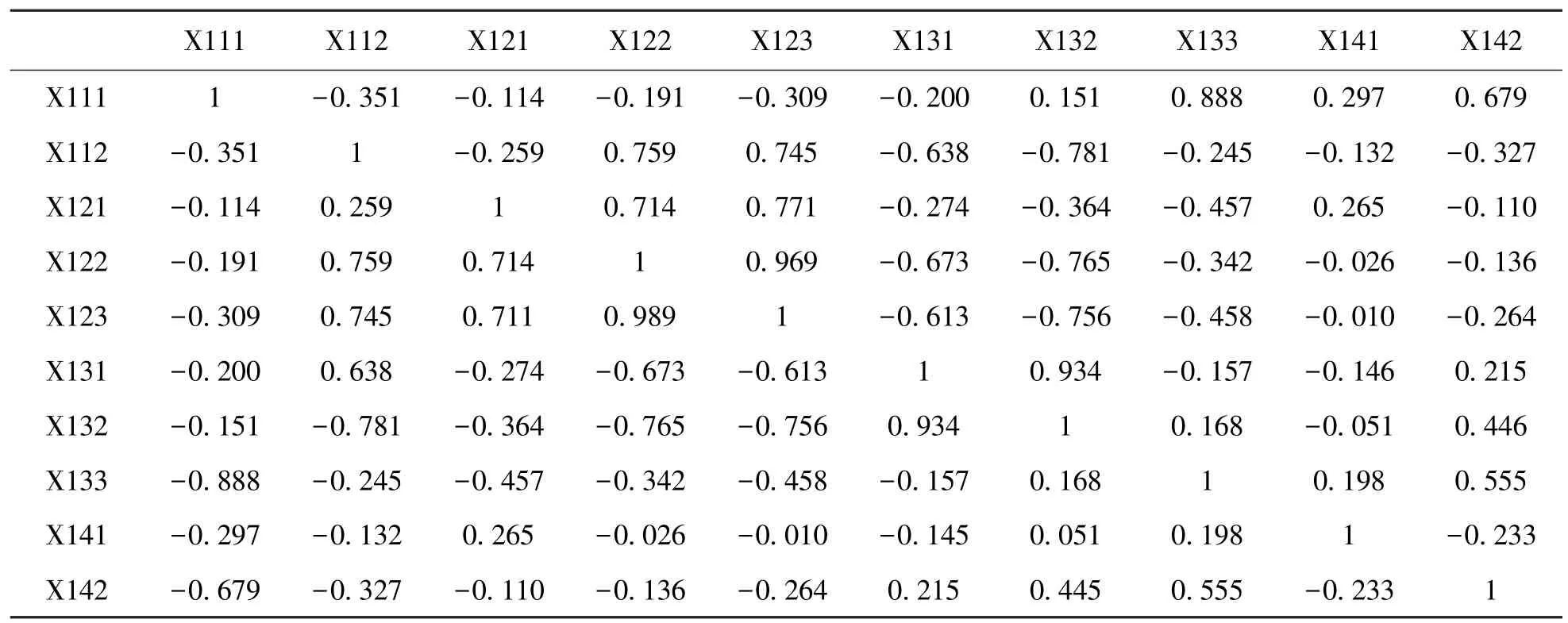
表3 核心企业风险指标相关系数分析
综合考虑,剔除指标销售利润率X123、速动比率X131、应收账款周转率X111。同理,通过相关性分析,其他初始指标予以剔除的有:污染治理水平X211、注册时间X311、交易总额增加率X313、销售利润率X422、企业管理水平X411、周转率X522、订单有效性X541。
5.1 指标敏感性检验运用SPSS20软件包计算变差系数,并将变差系数从大到小进行排序,然后将敏感性较低,即变差系数较小的指标过滤掉。根据以往文献和实际样本特征综合分析,本文对变差系数小于0.1,即Cvi<0.1的指标予以剔除。共有核心企业的资产负债率X133(0.0848)、外部环境的产业政策X221(0.0402)、绿色质押物中的排污权评估值X532(0.0807)被剔除。基于以上分析,共剩余21个指标,如表4所示。
5.2 指标的主成分分析由图2可见,主成分7之后特征值下降变得稍微平缓,通过碎石图也可以发现主成分个数确定的较为合理,可以反映指标体系的几乎全部信息。本文选择前7个主成分作为特征根进行分析。
在建立和运行一个较为完善的评价模型过程中,验证是十分重要的,验证既包括样本的训练,也包括对测试样本的回代检验。在训练样本时,模型通常有两种错误,一种是企业有违约情况出现,而模型验证错误,称其为第1类错误;另一种是企业没有违约记录而模型结果显示为有错误,这类情况称为第2类错误。一般来说,第1类错误损失为第2类错误损失的60倍左右,因此应该尽量预防第1类错误。因此在验证模型性能时,除了关注两种错误出现的概率,还应该重点关注第1种错误。因此本文通过Logit模型和BP神经网络模型对样本进行检验。
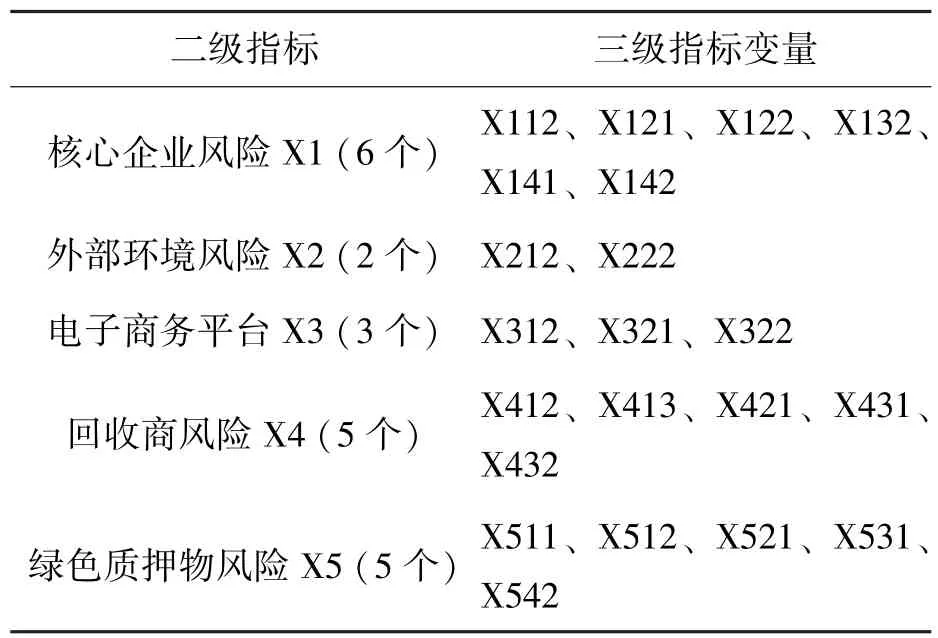
表4 敏感性分析所得指标
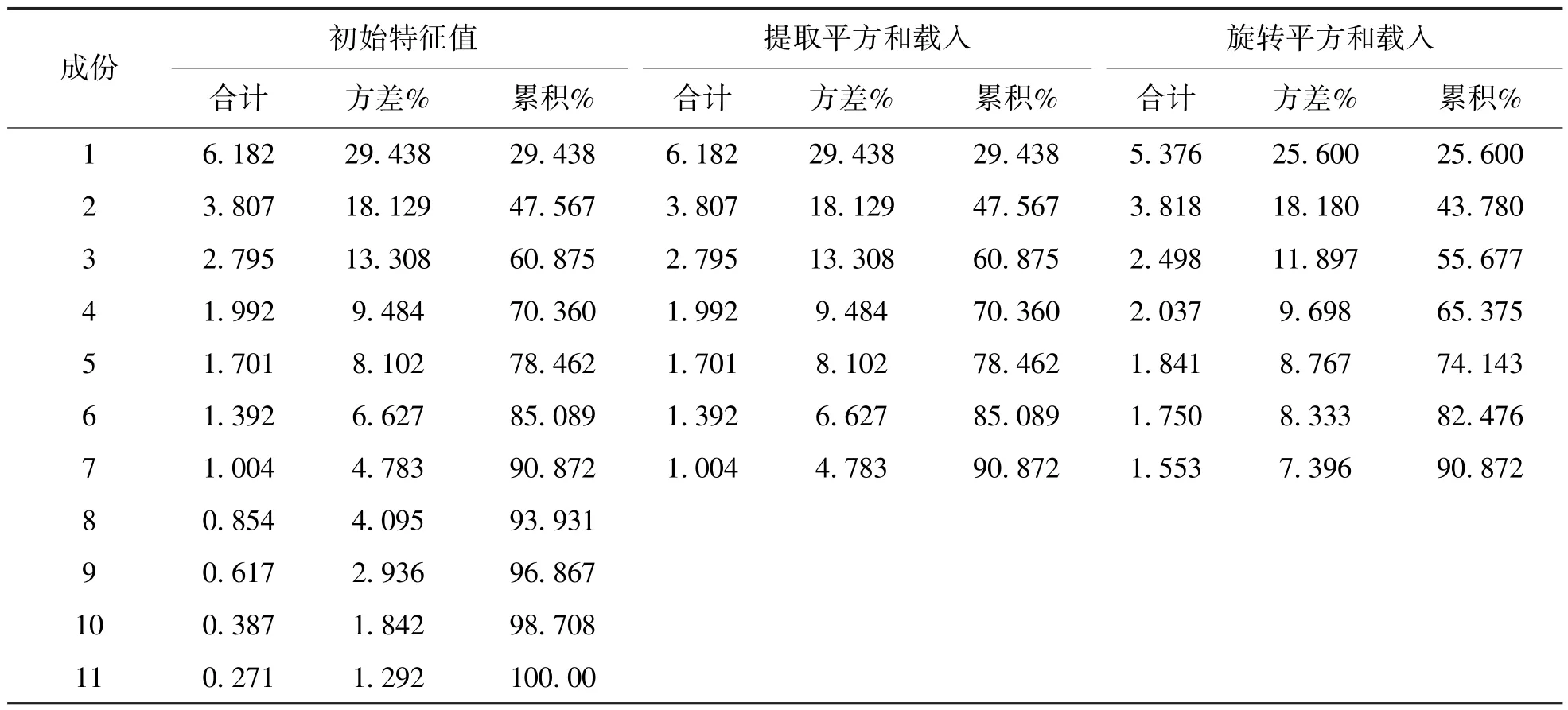
表5 主成分提取表
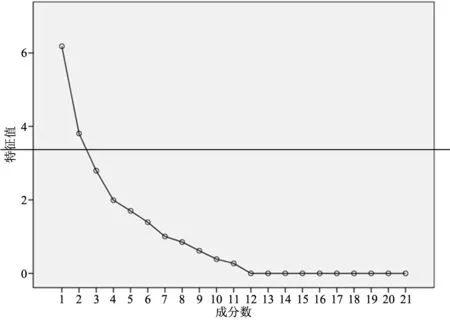
图2 特征根数值碎石图
6 实证分析6.1 基于Logit模型的检验本文在大量研究对比不同风险评估模型的基础上进行综合比较,选定Logit模型作为绿色供应链金融风险预警模型。
Logit模型是一个二元选择模型,其变量仅有0和1两个。为了使因变量Y更容易被理解,本文将违约企业,即被ST的企业用 “1”来表示,没有违约的企业,即未被ST的企业用 “0”来表示。违约企业的概率计算公式为P(Y)=1-F(X)。借鉴以往的论文和科研成果,将临界值定位0.647[7],并对比临界值在0.5和0.647下的模型判定成果。本文一共提取了7个因子 (F1、F2、F3、F4、F5、F6、F7),使用SPSS对计算出的共同因子进行Logit分析,使用最大似然估计法来做参数估计,结果表示所有指标都具有较好的显着程度。模型的主成分系数估计如表6所示。
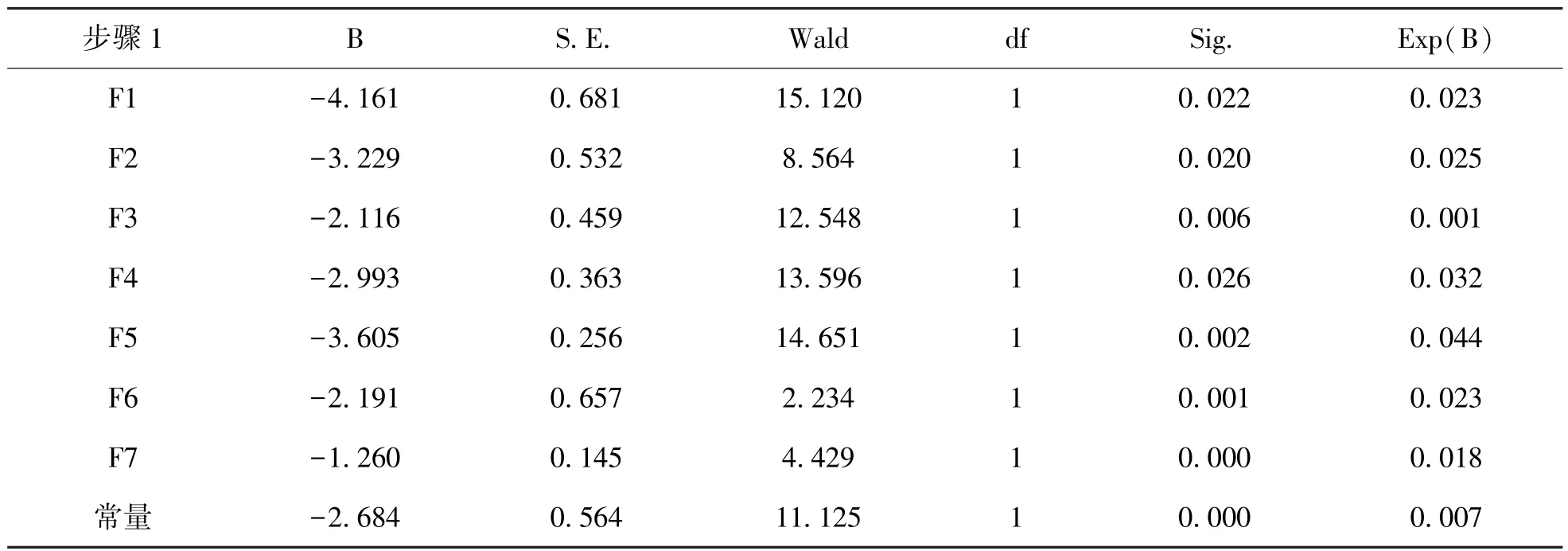
表6 系数估计矩阵
根据计算的系数估计值,带入到Logit模型方程中,可以得到企业违约概率的为:

在进行预测检验时,先用训练样本进行训练,查看预测的准确度,然后再用测试样本进行检验,精确度的临界值分别界定为0.5和0.647。当临界值为0.5时,可以通过表7说明Logit模型对评价的平均准确率为93.15%,其中对违约样本的判别准确率为93%,对非违约样本的判别准确率为93.3%,即违约样本企业15家,只有1家不能完全判别准确,非违约样本企业45家,只有3家不能完全判别准确,说明所建模型具有较高的判别准确率。

表7 Logit模型对训练样本的判断结果
同样,当训练样本预测产生较为满意的结果后,还需要对测试样本进行检验,验证模型是否具有普遍性。如表8所示,将测试样本带入Logit模型后,结果表明对非违约样本预测的预测准确率为88%,对违约样本预测的准确率为100%,有5家违约企业,均能够检测出;有25家非违约企业,能够准确检测出22家,模型对测试样本的综合预测准确率达到94%,说明Logit模型对该指标体系有着较为准确的评估能力。

表8 Logit模型对测试样本的判断结果
在初步确定了模型的可行性和准确性后,本文改进了以往文献中仅用单一的临界值做判定的方法,通过将临界值设定为两个值来进行对比分析。通过不同的临界值设定,得到不同的测试结果,进一步验证模型的准确性,运行结果见表9。
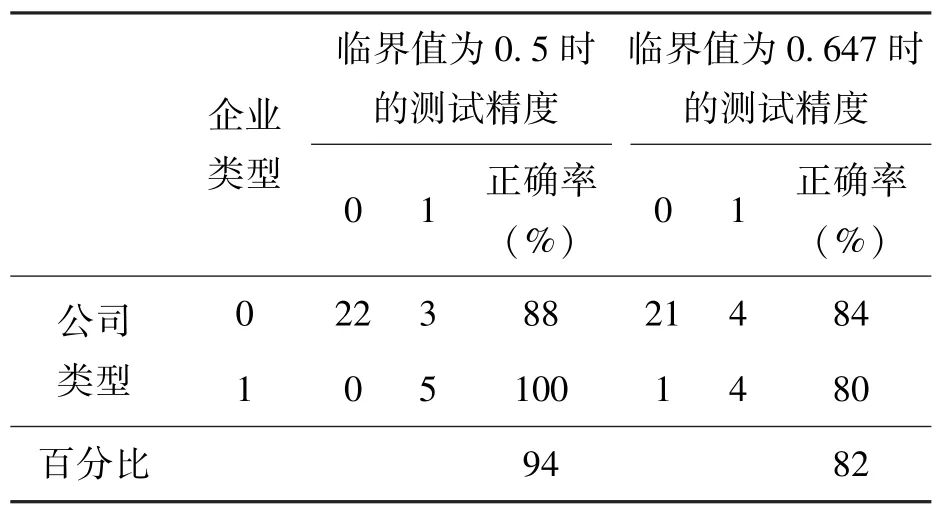
表9 不同临界值的预测准确率
将临界值确定为0.5时,测试样本的准确率为94%,将临界值确定为0.647时,测试样本的准确率为82%。通过研究发现,Logit模型在研究精度为0.5时,无论训练样本还是测试样本的准确率都在90%以上,因此结果较为准确。而当临界值为0.647时,准确率有所下降,但总体也仍然保持在80%以上,属于能够接受的范围,证明该模型具有较高的判定率。
6.2 基于BP神经网络的检验以往的大量研究中将BP神经网络算法运用于供应链金融状况的评估,并且认为BP神经网络在进行风险评价方面有着较高的准确度。因此本文将BP神经网络模型同Logit模型的评价效果进行综合对比,探索更适合绿色供应链金融的风险评估模型[8]。
根据以往的研究,估计隐含层的节点个数应该在4~15之间,通过反复尝试隐藏层节点数,最终确定隐藏层节点的个数为6。同时,选择不同的训练函数对预测结果会有很大的影响,如收敛快慢、收敛精度[9]。分别采用traingdx函数、traingd函数、trainscg函数和trainlm函数等常用训练函数[10]进行BP神经网络训练,不同函数的训练结果如表11所示。本文设定最大训练步长epoch=5000[11], 误差精度ε= 0.001, 选择概率为 0.9。BP神经网络训练样本和测试样本的选择同Logit的选择是一样的,60组训练样本,30组测试样本,每种样本的ST企业和非ST企业的比例为5∶1。
表10显示,函数traingdx的迭代次数为237次,证明当迭代到237次时候就达到了所要求的函数精度,同时迭代次数较其他4个函数来说是最低的,因此基于BP神经网络的绿色供应链金融训练函数应采用traingdx函数。
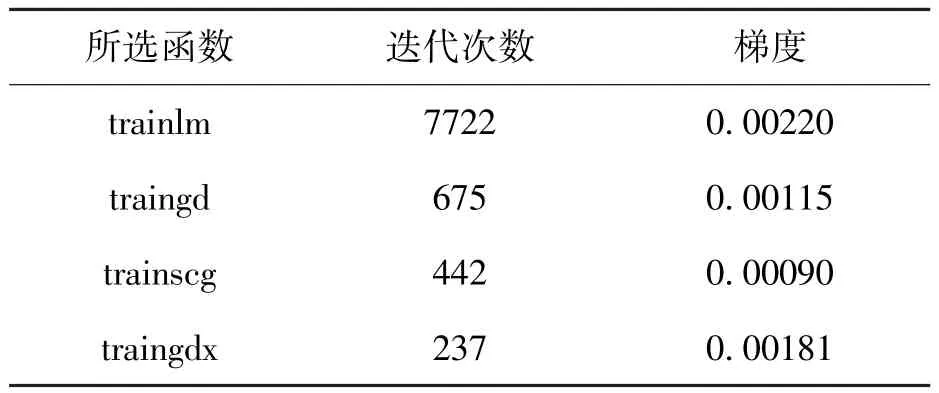
表10 不同训练函数的迭代次数
7 结果分析(1)把Logit模型 (临界值选择为0.5时)与BP神经网络的结果进行比较,比较结果如表10所示,针对训练样本,Logit模型的综合预测准确率为94.5%,高于BP神经网络的47.5%,针对测试样本,Logit模型的综合预测准确率为94%,高于BP神经网络的34%,因此从整体角度考虑,Logit模型要更适合该指标体系的分析。
(2)一般BP神经网络适合大样本分析,而由于目前绿色供应链金融兴起的较晚,供应链中的核心企业和回收商数量较少,加上样本企业的数据涉及到财务、信用等方面,获取较为困难,因此影响了BP神经网络的准确性。
(3)通过观察比较结果,对于第2类错误的预测,两种模型差别不大,但是针对第1类模型,BP神经网络的预测准确度低于Logit模型,而对于整个绿色供应链来讲,第1类错误的损失要明显高于第2类错误,因此Logit模型比较容易发现第1类错误。
(4)从对比结果表11中可以看出,对于训练样本集,Logit模型的预测综合结果要比BP神经网络更加准确;在测试样本集中,Logit模型的预测准确率虽然有所下降,但预测结果仍然在90%以上,而BP神经网络的的准确程度下降达到13.5%。这说明BP神经网络模型的鲁棒性比Logit模型的鲁棒性要差,即证明Logit的学习能力要优于BP神经网络。BP神经网络针对第1类错误无法做出正确判断的结果表明,该模型无法从数据的特征中识别出企业的违约情况,从而影响了 BP 神经网络的泛化能力[12-14]。

表11 Logit模型与BP神经网络评价结果对比
8 结论与建议(1)对于绿色供应链风险分析模型。本文通过对Logit模型应用不同的临界值进行验证,得到的预测精度有所不同,本文验证针对绿色供应链金融指标体系临界值为0.5有较好的预测精度。同时,通过不同的评价模型进行对比分析,证明Logit模型比BP神经网络具有更明显的预测能力,对于两类错误的预测准确程度都较高,特别是针对第1类错误,可以帮助绿色供应链企业有效地规避有可能违约的企业,提高风险预警能力。
(2)对于绿色供应链关系。各产业的核心企业、回收商、银行、电商平台建立良好的、稳定的、长期的战略合作关系,对于供应链的长远发展是非常必要的。同时绿色供应链金融风险的降低,需要有核心企业的信用、责任感、企业实力做保障,同时还需要加强供应链成员之间的合作,确保供应链金融能够顺利展开,提升整个供应链的价值水平。
(3)对于政策支持。由于绿色供应链金融兴起比较晚,对于排污权的申领、排污权的交易等监管不到位,可能会引起资源回收不及时、资源浪费严重等现象;同时,政府应该加强宣传排污权和排污许可的相关政策,为有能力的企业提供更多的政策支持和机会,使得绿色生产、可持续发展成为未来产业发展的主要方向。