钱吴永 张浩男
(江南大学商学院,无锡 214122)
引 言新冠疫情的蔓延对全球供应链、产业链产生了巨大的冲击,在供应链金融领域,我国中小微企业由于疫情所带来的资金回流难、偿贷能力下降等问题导致其面临更加严峻的融资困境,传统供应链金融业务的服务方式难以适应当前形势下的金融活动要求。随着大数据、云计算和人工智能等技术的快速发展和5G网络等基础设施的持续完善,运用新的数字算法理论和技术方法来提高供应链金融信用风险评价的效果,成为解决我国中小微企业融资问题、提升供应链金融创新能力的一个重要方向。
近年来,众多学者基于决策树(Decision Tree,DT)、 人工神经网络(Artificial Neural Network,ANN)、 遗传算法(Genetic Algorithms,GA)等机器学习的理论和方法构建人工智能模型,并成功应用于信用风险评价的工作中[1-3]。相较于传统的Logistics回归分析法易受样本规模的限制和层次分析法(AHP)主观性较强的问题[4,5],人工智能的方法能够有效处理高维度非线性样本的评价问题且不受指标权重等主观因素的影响。支持向量机(Support Vector Machine,SVM)[6]作为一种稳定的分类器,在信用风险评估中得到了大量的应用,在处理高维数据时表现出了较优的性能,SVM以结构风险最小化为原则,相较于其他的智能学习算法,具有更好的鲁棒性。如胡海青等[7]通过将SVM与PCA和Logistic回归方法建立的信用风险评价模型进行对比,结果表明基于小样本下SVM的信用评价模型具有更优的稳定性和准确性。Shin等[8]以韩国中型制造业企业作为样本,使用SVM建立了企业破产预警模型,对比总结了SVM相比于BPNN模型的优点,实验结果表明,随着训练集样本的减少,SVM在精度和泛化能力上优于BPNN。胡海青等[9]运用SVM和BP神经网络两种算法建立信用风险评估模型并进行实证对比,结果表明基于SVM的信用评估模型具有更优的稳定性和准确性。此外,由于信用风险评价存在小样本、多缺失值与奇异值等特点,运用神经网络进行信用风险评价时容易导致局部最优解、过度拟合、泛化能力弱等问题,而支持向量机能够利用核函数实现低维空间分类问题向高维空间的转化,具有较强的泛化能力和较优的鲁棒性,被多数学者所采用。淳伟德和肖杨[10]通过构建不同核函数SVM模型、Logistic回归模型、DDA以及BPNN模型来对供给侧改革背景下的系统性金融风险进行研究预警,对比分析的结果表明,使用多项式核函数的SVM预警模型具有优越的预测性能。Fan和Palaniswami[11]将SVM模型的预测结果与MDA模型、多层感知器(Multi-Layer Precep⁃tion,MLP)神经网络模型和学习矢量化(Learning Vector Quantization,LVQ)神经网络模型的预测结果进行比较,结果表明,SVM在预测准确性上总高于其他3个模型。以上研究表明SVM在进行信用风险评估方面相较于其他的机器学习模型具有天然的优势,然而,由于SVM在选取核函数和分类参数时要求较高,如何对SVM参数进行优化成为学者研究的重点。刘颖等[12]采用二进制粒子群算法来优化支持向量机(SVM)的惩罚系数和核参数,结果表明,基于优化算法的评价模型在解决供应链金融信用风险评价问题中具有很好的性能。此外,多位学者的研究表明,运用集成学习的思想将多个弱学习器组合成一个强学习器能够降低评价模型对参数选择的依赖性。如陈舒期和梁雪春[13]使用AdaBoost算法对最优SVM个体进行非线性集成,建立了SSVM集成模型,进一步提高了SVM的分类识别性能;陈云等[14]基于混合集成策略,将随机子集和AdaBoost两种算法进行合成,建立基于SVM的集成学习模型,提高了SVM预测准确率。
基于上述分析,本文针对SVM参数选择不准确导致分类精度较低的问题,使用一种动态变异的粒子群优化算法(Dynamic Particle Swarm Opti⁃mization,DPSO)对SVM径向基核函数中的参数进行选择,并用AdaBoost集成算法将优化后的PSO-SVM基分类器进行加权组合成强分类器,建立基于AdaBoost-PSO-SVM的评价模型,最后,将该模型应用于我国新能源汽车行业的供应链金融信用风险评价中,实验结果表明,所建立的模型大大提高了SVM的分类准确率,同时相比于其他评价模型也具有更优秀的性能。
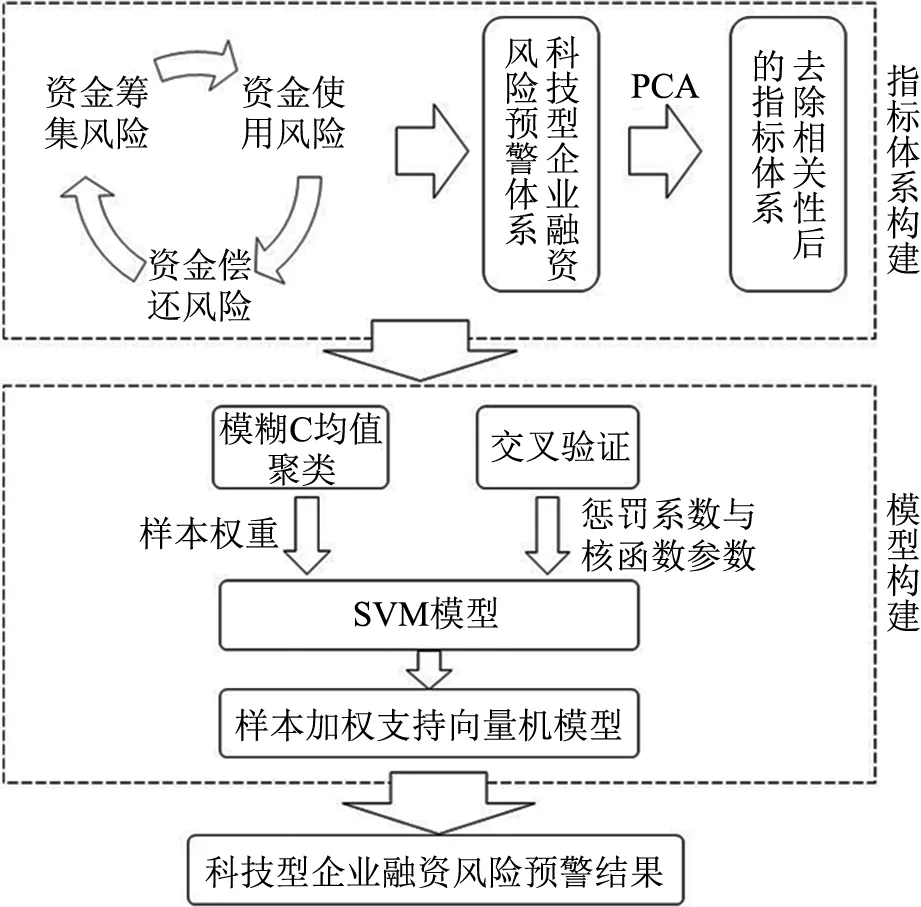
1 中小企业信用风险评价指标体系的设计在传统的融资模式下,银行与申请融资的中小企业之间存在严重的信息不对称,仅仅通过对融资企业自身的信用风险水平进行评估很难使那些规模较小、财务制度不健全、自身不能满足银行担保或质押资产要求的中小企业获得授信。在供应链金融模式下,评价指标应更多考虑中小企业与核心企业之间的关系以及供应链全链条的整体情况,从而更全面、准确地把握融资企业的资信情况。因此,本文基于供应链的视角,考虑融资企业和核心企业的财务和非财务状况以及供应链整体的运营状况,在现有文献[15-19]对供应链金融指标体系研究的基础上,将定性与定量指标相结合,重新设计了反映全链条风险水平的信用风险评价指标体系,如表1所示。

表1 信用风险评价指标
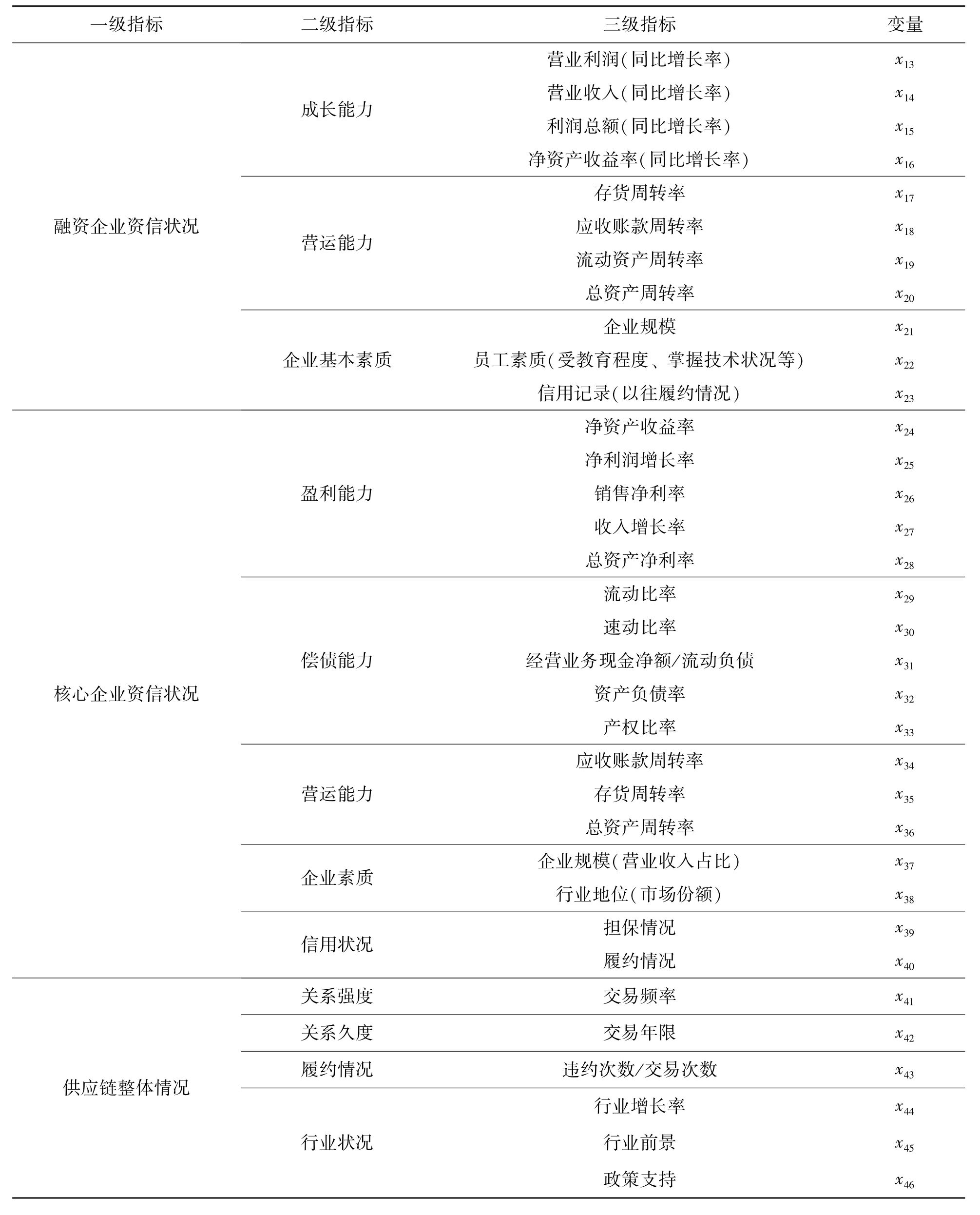
续 表
2 理论模型设定2.1 支持向量机(SVM)假设n个样本的训练样本集表示输入的第i个样本,yi∈{1,-1},分类超平面方程为wx+b=0(w是超平面的法向量,b是偏置)。
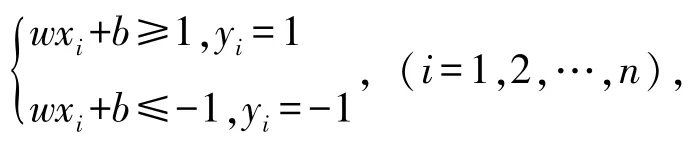
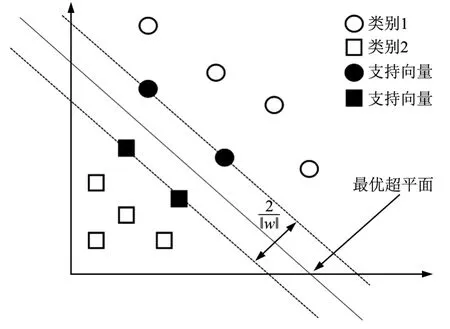
图1 线性可分情况下最优分类超平面
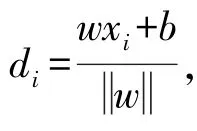
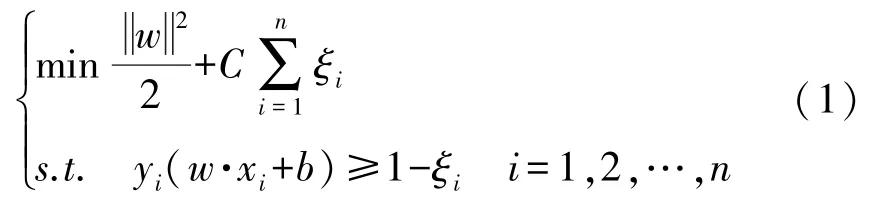
建立Langrange函数:
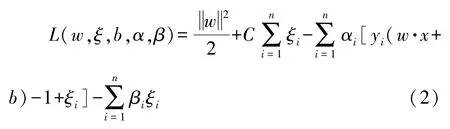
由于供应链金融评价指标具有高维、非线性、动态等特点,此时SVM需要引入核函数K(xi,xj)=Φ(xi)T·Φ(xj)来将高维空间中的非线性分类问题进行转化。径向基(RBF)核函数相比于其他几种SVM的核函数,在线性和非线性的数据集都有较好的表现。因此,本文选用径向基核函数:K(x,输入 SVM。
根据式 (1)和式 (2),将原始问题转化为Langrange对偶问题:
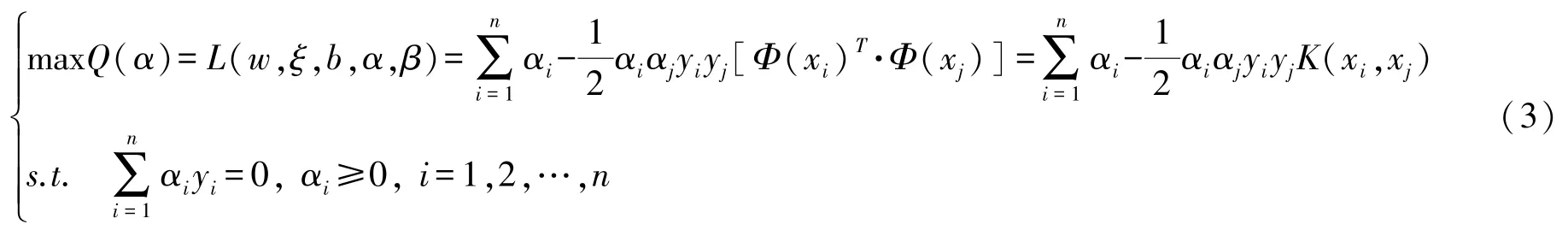
综上,得到最优的分类判别函数:
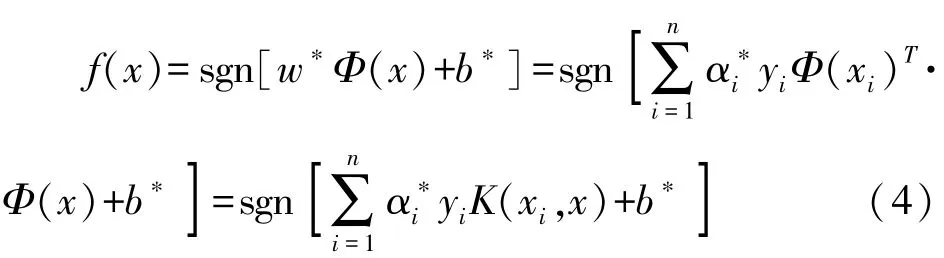
在标准粒子群算法中,通常将惯性权重ω设定为一个固定的值[20],难以满足算法迭代前期全局搜索能力和后期局部搜索能力的动态要求。本文在粒子群算法基本原理的基础上兼顾算法的收敛精度和收敛速度,使用动态变异的粒子群算法(DPSO)来优化SVM的参数,采用动态权重如下:
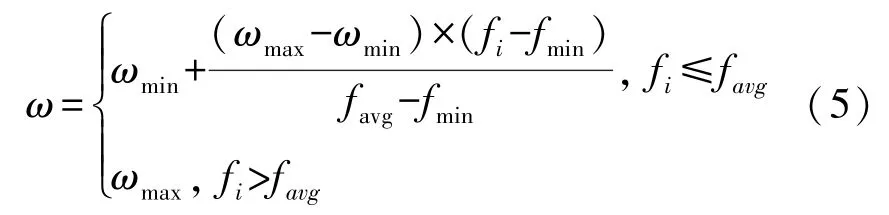
借鉴遗传算法变异的思想,将变异操作引入到粒子群算法中,使粒子跳出原来的区域进入其他新的领域进行搜索,以此来找到新的群体极值,循环变异操作,直到找到全局最优解,具体做法如下:
设粒子群的群体适应度方差为:
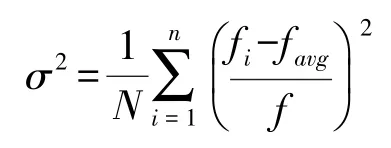
n为粒子群的粒子数目,σ2代表粒子的 “收敛”程度,随着σ2变小,粒子群由随机搜索状态逐渐趋于收敛。f表示归一化定标因子,取值如下:
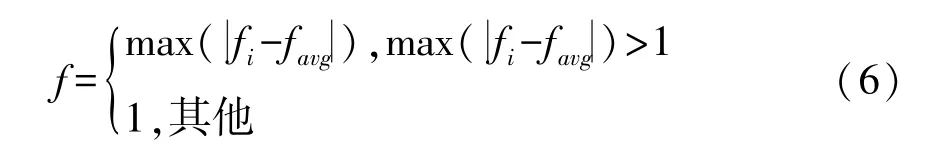
令粒子的聚集程度为α,则t代α的计算公式如下:
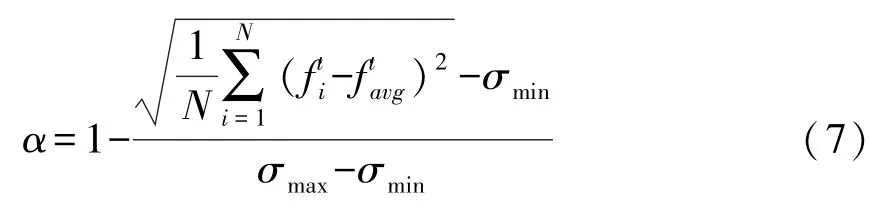
σmax和σmin分别代表全部粒子标准差的适应度最大值和最小值。由种群聚集度的定义设置t+1代粒子变异概率公式如下:

Pt+1与粒子聚集度α成正比,λ∈[3,5]为固定常数的比例增益,N代表种群的规模,m表示优化问题的维数。
DPSO-SVM算法流程如图2所示。
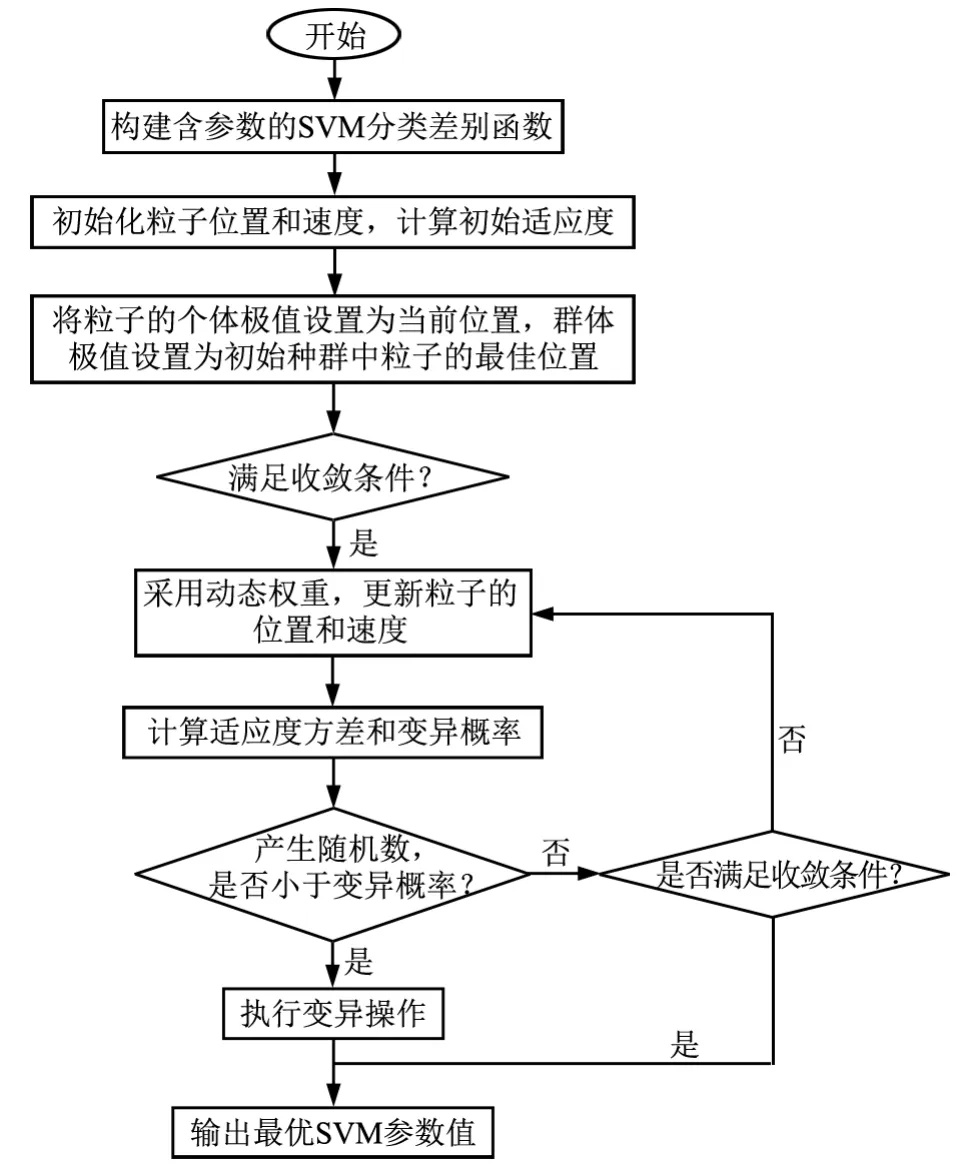
图2 DPSO-SVM算法流程
2.3 AdaBoost集成DPSO-SVMAdaBoost(Adaptive Boosting)是一种通过对训练样本的权值迭代来强化弱学习器的集成学习算法[21]。 本文采用 AdaBoost对 DPSO-SVM 学习器进行训练,算法实现步骤如下:
Step1:输入N个初始学习训练样本集D=是样本空间的样本特征,yi为类别空间的类别符号,设定初始训练样本的权值矩阵:W1=(ω11,ω12,…,ω1i,…,ω1N),假设每个训练样本的权重都是相等的,即:ω1i=1/N,(i=1,2,…,N)。
Step2: 使用具有权值分布的Wt= (ωt1,ωt2,…,ω1i,…,ωtN)训练集数据学习,将 DPSO-SVM作为基分类器:
Step4:计算DPSO-SVM分类器权重:设αt=更新训练样本的权重:ωt+1为归一化因子,返回 Step2 迭代。
3 模型仿真实验与分析3.1 样本搜集与处理本文选取我国供应链金融业务发展相对成熟的新能源汽车供应链为研究对象,以比亚迪、福田汽车、特斯拉、北汽集团、长安汽车五大新能源汽车整车制造厂为核心企业,选取其供应链上下游共54个国内上市公司2017~2020年近4年的财务和其他相关数据,共计216个样本,剔除具有异常数据的样本18个,剩余198个可用样本,并根据各年国资委发布的 《企业绩效评价标准值》对比筛选出 “信用不良”的样本38个,将 “信用良好”的160个样本作为初始数据。由于所建立的评价指标体系变量较多,且各指标间存在一定的相关性,为了在确保数据信息丢失最少的前提下简化输入模型的数据,本文采取主成分分析法(PCA)对搜集的数据进行降维处理:
(1)数据z-score标准化处理:
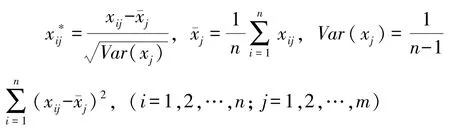
(2)评价指标的主成分提取
表2为主成分特征值及贡献率。由表2可知,前12个主成分的累积贡献率为86.665%,因此提取前12个主成分。
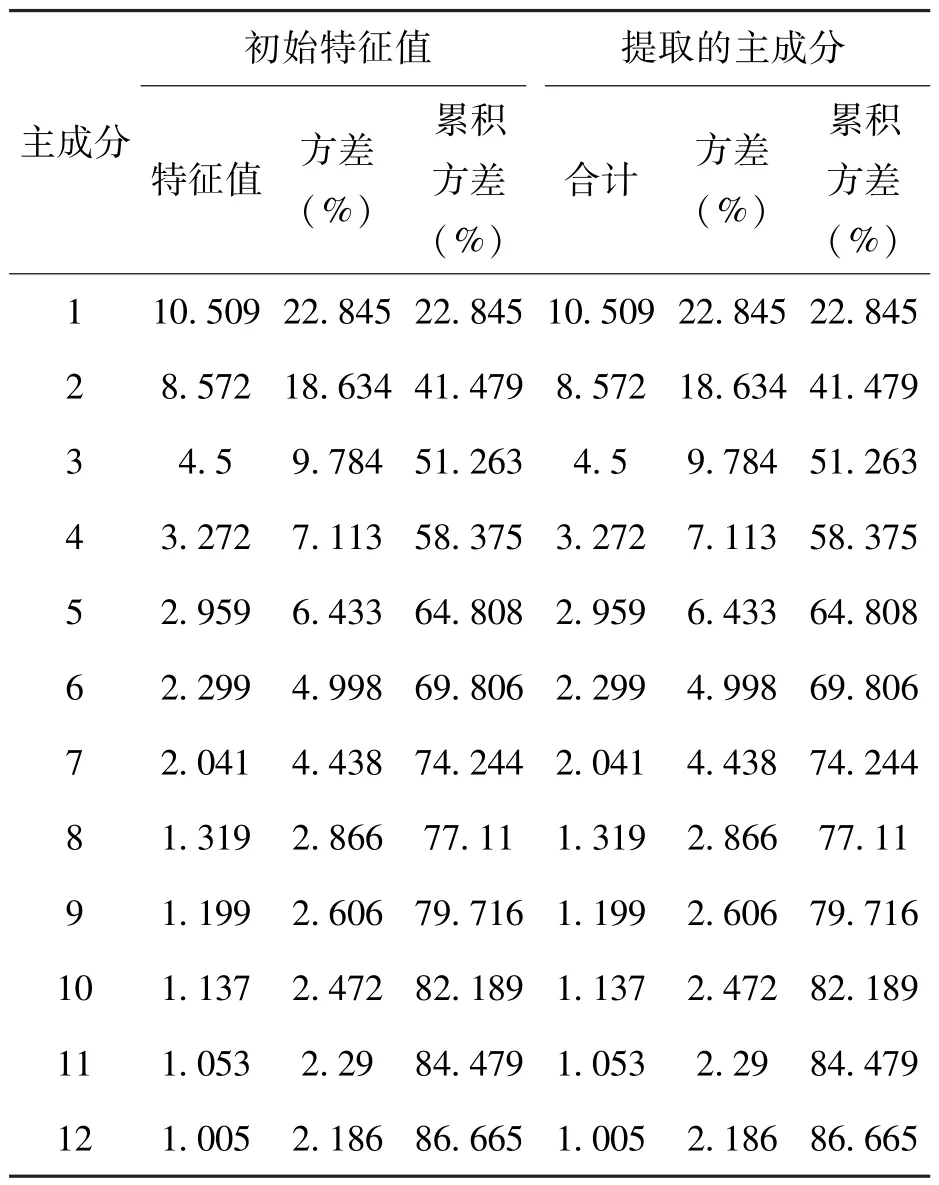
表2 主成分特征值及贡献率
表3为原始数据198个样本的46个供应链金融风险评价指标进行主成分属性约简后提取的12个线性无关的主成分,将降维后的数据输入评价模型能够大大提高运算效率,同时也避免了支持向量机RBF核函数不擅长处理量纲不统一数据集的问题。
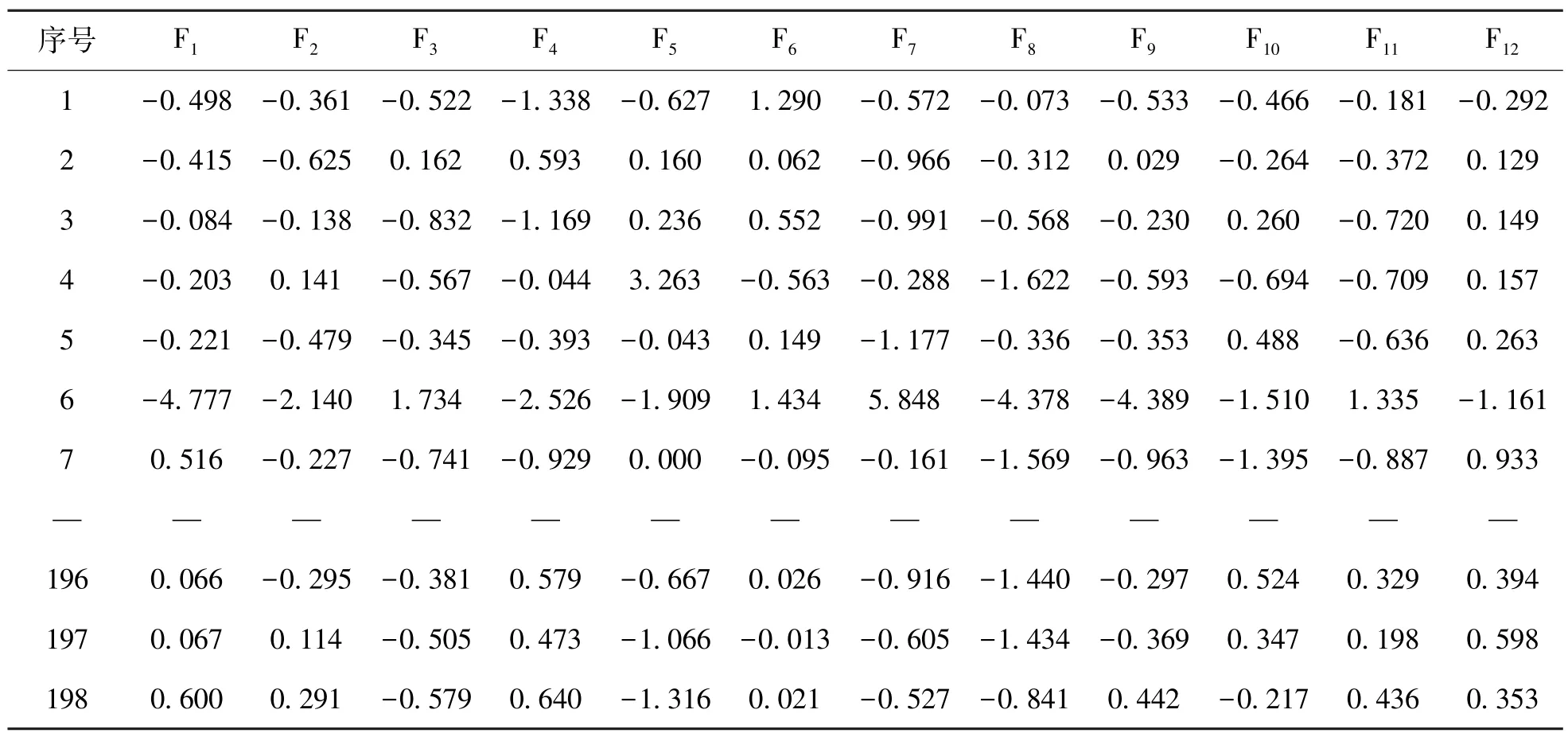
表3 原始数据样本的主成分
3.2 模型结果分析以提取后的12个主成分为支持向量机的输入变量,设置训练集样本120个,测试集样本78个,不良样本的类别标签为1,良好样本的类别标签为0。采用改进后的的粒子群算法对径向基(RBF)核函数的惩罚系数C和参数g进行优化,设定参数C1=1.5、C2=1.7,种群规模为20,最大迭代次数设置为200,SVM惩罚系数C和核参数g的取值范围设置为[0.001,10],粒子的位置Xi∈[-6,6],粒子速度V∈[-10,10]。 经过最优化选择,SVM核函数的参数筛选得到C=2.8284、g=0.088388,以此作为模型的基本参数。将DP⁃SO-SVM作为基分类器,使用AdaBoost集成DP⁃SO-SVM,得到的分类结果与单一分类器SVM和PSO-SVM以及BP-AdaBoost进行对比。各模型不同指标间的分类结果对比如表4所示。
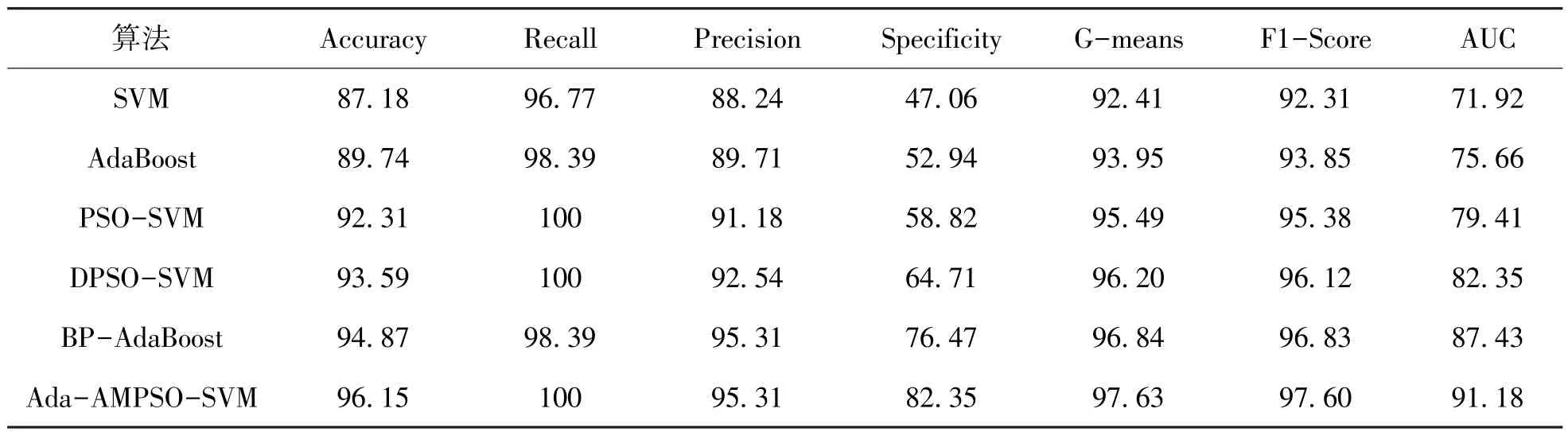
表4 模型结果对比 单位:%
Accuracy反映了分类器对整体样本的分类判别能力,即模型能够正确识别出良好样本和不良样本的能力。在信用评估中,将一个信用好的企业评估为信用差的企业,对于信贷机构来说,只是客户未来的贷款利息的损失,如果将一个信用差的企业评估为信用好的企业,则面临借款者违约的风险,对信贷机构造成无法收回本金和利息的损失。因此,相较于Recall指标表示标签为正样本的实例中的预测正确率,本文更加注重Spe⁃cificity指标的大小,反映标签为负样本的实例中的预测正确率。由于在特定的样本数据下,支持向量机对测试集的预测值为单一数值,ROC曲线发生退化,此时AUC指标不能全面地反映分类器的性能,因此本文使用F1-Score、G-means以及Ac⁃curacy等指标作为主要评价指标,AUC作为辅助性评价指标。
结果表明,所有模型均能对本文搜集的数据进行有效地分类,分类准确率最低为87.19%。同时可以看出负类样本的识别误差总高于正类样本的识别误差,因此在今后的研究中,应更加重视对不良样本的误分类率。比较不同的模型,PSOSVM模型性能在SVM的基础上有了明显改善。采用自适应变异的粒子群算法对SVM进行优化得到DPSO-SVM比标准的PSO-SVM分类效果更好,测试集样本的准确率由92.31%提升到了93.59%。采用AdaBoost算法集成后的AdaBoost-DPSO-SVM模型在各个指标上都有较大提升,模型准确率(Ac⁃curacy)达到了最高的96.15%,对比BP-AdaBoost模型,其分类性能更优。AdaBoost-DPSO-SVM模型的Specificity指标在5个模型中最高,表明其将信用不良企业识别为信用好的企业的错误率最低,且综合反映模型输出效果的G-means和F1-Score指标值最高,分别为97.63%和97.60%,说明本文所提出的AdaBoost-DPSO-SVM模型能够更好地应用于供应链金融信用风险的评估。
4 总结与展望本文基于我国新能源电动汽车产业上市公司的财务数据和供应链数据,构建了供应链金融信用风险评价指标体系,运用PCA对数据样本进行预处理,作为支持向量机的输入数据,有效地解决了供应链金融存在高维数据的问题。通过对粒子群算法的惯性权重进行改进和引入变异操作,提出了一种动态变异的粒子群优化算法,避免了粒子在寻优的过程中陷入局部极小值的问题。最后将改进后的优化算法对SVM参数进行优化并作为一种弱分类器输入AdaBoost集成,构建了一种在多方面都具有较好性能的AdaBoost-DPSO-SVM模型,并成功应用于我国新能源汽车供应链金融的信用风险评估工作中,为加快推进我国金融领域的供给侧结构性改革,使金融更好地服务于实体经济,实现经济高质量发展提供了一个新视角。
供应链金融包含的业务关系复杂多样,存在大量动态的、非结构化的金融数据,如何在海量复杂的数据中获得一种更为高效、准确、适用性强、动态化的信用评价的指标体系和方法,是未来继续研究的方向。此外,由于SVM本身对于核函数的高维映射解释力不强,对于评价结果中信用不好的企业无法给出较为准确的指导建议,给评价模型分类结果的分析带来一定难度。如何在本文所提出模型的基础上融合其他具有较强记忆性的机器学习算法(如决策树等)来提高模型的可解释性也是未来重点研究的方向。