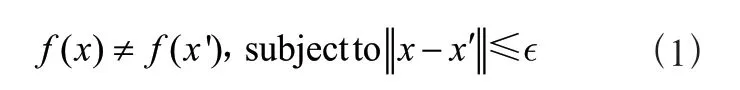
收稿日期:2023-08-01
基金项目:2020年陕西省教育科学“十三五”规划课题(SGH20Y1480);2022年西安欧亚学院校级项目(2022GCPY01)
DOI:10.19850/j.cnki.2096-4706.2024.05.003
摘" 要:构建有效的个人信用风险评价系统,用以应对潜在的个人信贷风险,这对金融行业和社会公众皆有重要的现实意义。文章首先对数据进行清洗、预处理,然后通过WOE编码分箱、IV值进行变量筛选,构建了逻辑回归模型并基于逻辑回归模型建立了个人信用评分卡模型,该模型可辅助决策者制定合理的授信政策、定价策略以及其他相关业务运营策略。
关键词:个人信用评估;评分卡;AUC
中图分类号:TP39;O212.1 文献标识码:A 文章编号:2096-4706(2024)05-0012-05
Research on Personal Credit Score Card Model Based on Logistic Regression
ZHANG Junli1, GUO Shuangyan2, REN Cuiping1, MA Qian1
(1.Xian Eurasia University, Xian" 710065, China; 2.Shaanxi Branch of Bank of Communications, Xian" 710004, China)
Abstract: Building an effective personal credit risk assessment system to address potential personal credit risks is of great practical significance for the financial industry and the general public. This paper first cleans and preprocesses the data, and then uses WOE coding and binning and IV values for variable screening. A logistic regression model is constructed, and a personal credit score card model is established based on the logistic regression model. This model can assist decision-makers in formulating reasonable credit policies, pricing strategies, and other related business operation strategies.
Keywords: personal credit evaluation; score card; AUC
0" 引" 言
随着经济和互联网技术的高速发展,信用消费的方式逐渐兴起,已融入人们的日常生活,如住房贷款、汽车贷款,以及个人信用卡、蚂蚁花呗、借呗、京东白条金条等小额消费贷款。这些金融服务的使用都离不开个人信用,其中个人信用风险评估是一个必不可少的环节[1-3]。因此,对个人信用风险进行合理评估,对客户是否会违约进行预测,成为金融机构控制风险的重要手段。信用消费产业的健康发展,可以为消费者带来极大的便利。对金融机构来说,信用消费有着广阔的市场空间,蕴含着巨大的利润增长点;对金融市场来说,信用消费可以分散金融风险,促进金融体系的健康发展;对社会经济来说,信用消费能够拉动社会需求,促进经济增长。
在如今这个信息时代,互联网技术的发展也带动了互联网金融行业的繁荣。互联网金融是指传统金融机构与互联网企业利用互联网技术和信息通信技术实现资金融通、支付、投资和信息中介服务的新型金融业务模式。简单来说就是利用互联网技术实现了更快捷、更便利的支付、征信、投资理财、融资、信贷业务。现如今,不仅可以通过手机进行网购,还可以通过手机申请信贷,例如人们所熟知的花呗、京东白条等。互联网金融的发展从面对面的业务办理向手机业务办理方向发展。随着居民购买力的不断提高,信贷、信用卡这一系列具备信贷消费功能的产品接踵而来。而个人平常使用这些产品时无不反衬着消费者的信用特征信息,金融机构可以通过诸如此类的个人征信记录来审批是否向某人提供贷款或信贷等服务。对客户信用风险的准确预测对银行和金融企业来说至关重要,可以最大限度地减少向客户放贷的风险,降低做出错误决策的概率。因此,相对于传统操作中业务人员的主观判断,信用评分模型更具客观性、全面性、准确性、效率性。
目前,消费信用正处于高速发展的阶段,一些信用企业在经营上也面临着大大小小的风险。为了促进我国消费信贷的良性发展,需要建立科学、合理的个人信用风险评估与预测机制。与此同时,促进行业健康发展、健全个人征信系统、严评用户的违约风险、防范不良信贷的发生、提升信贷机构风险管控能力变得更加重要。在信贷产品不断涌现与数据利用率低下的客观矛盾下,应用数据挖掘技术进行个人信用评价具有十分重要的意义。实行个人信用评价不但可以提升银行的审批效率,还可以降低银行的信贷风险,规避人工审核过程中出错情况的发生。这对于金融业的发展具有举足轻重的作用。
1" 个人信用风险评估介绍
个人信用指的是客户与信贷机构之间(即受信人与授信人之间),为满足受信人个人生活消费需求,建立在诚实守信基础上的一种履行契约关系、遵守契约约定的能力。所以个人信用评估即是授信人对受信人在信贷过程中所承担的还贷义务及其可信程度做出判断和评估。个人信用评价也是一个客户偿债能力和履约能力的综合反映和写照。狭义上说,信贷机构评价的是客户的履约能力、偿债能力和守信程度;广义上是指客户个人履行各类经济承诺的守信程度和可信任程度。个人信用评估,又称“消费者信用评估”,它是根据对客户的个人信用历史资料,综合微观环境和个人特征(内外主客观原因)的考察,结合经济、金融、司法、社会、工商、财产等因素(例如信用历史记录、行为记录、个人特征、交易记录),通过使用科学、严谨的分析方法或信用风险评估模型,对客户的偿付能力或信用程度进行全面的判断和评估,从而根据评估结果对客户进行信用评级。
个人信用风险评估的方法有很多,传统的个人信用风险评估主要是评估人员根据自己的主观意愿对客户进行评判。由于这种方法的不确定性因素和主观因素太多,评判指标过少,从而会造成评估结果的非全面性和非有效性。随着基于统计方法的个人信用评估模型的大量涌现,我们现在可以十分客观地预测客户的个人信用等级[4-7]。
个人信用评估方面在国外已有150年的发展历史,最早启用的评估方法是Fisher于1936年提出的判别式分析法。在这150年的发展历程中,判别分析法、非参数分析法、人工智能和统计学方法纷纷应用在信用评估上。以往学者通常将个人信用评估问题分成分类和回归这两大问题。分类问题是根据多个贷款人在相同地点以及类别中的特征指标,去判断不同贷款人的所属类别。分类问题的主要算法有:线性判别、神经网络、遗传算法、K近邻、分类树;回归问题是指根据多个贷款人在未知的所属类别中的特征指标,估计和预测其信用分数和违约概率,线性回归是这类问题将会用到的重要方法。在国内,个人信用体系起步较晚,2000年才开始起步。这个时期最典型的方法便是:银行要求客户填写一张表单,然后银行根据预定义的计分表对每个指标进行打分,再根据打分结果决定是否接受该客户的申请。而预定义计分表中每个指标的权重分数都是根据专家的主观意见和经验给出的,缺少必要的信用评价机制和惩戒规范机制[8,9]。因此,如果信贷机构想要降低信贷所带来的风险,就必须科学有效、公平公正、有理有据地对个人信用风险进行评估。
本文采用数据挖掘技术,建立并训练优化模型,从而科学有效地对个人信用风险进行快速评估。希望能够在加强及完善互联网金融个人信用风险评估方面尽一点绵薄之力,可以在某种程度上帮助机构拒绝信用风险高的人,达到规避信用风险高人群所带来的损失,即达到降低风险的目的。
2" 个人信用风险变量选择及分箱
本文所用到的分析数据来自Kaggle平台,总共挑选20 000条数据。原始数据特征为47维,其中包含匿名特征15个。本文以isDefault为因变量,以贷款金额、贷款期限、贷款利率、贷款等级等46个变量作为自变量进行分析研究。
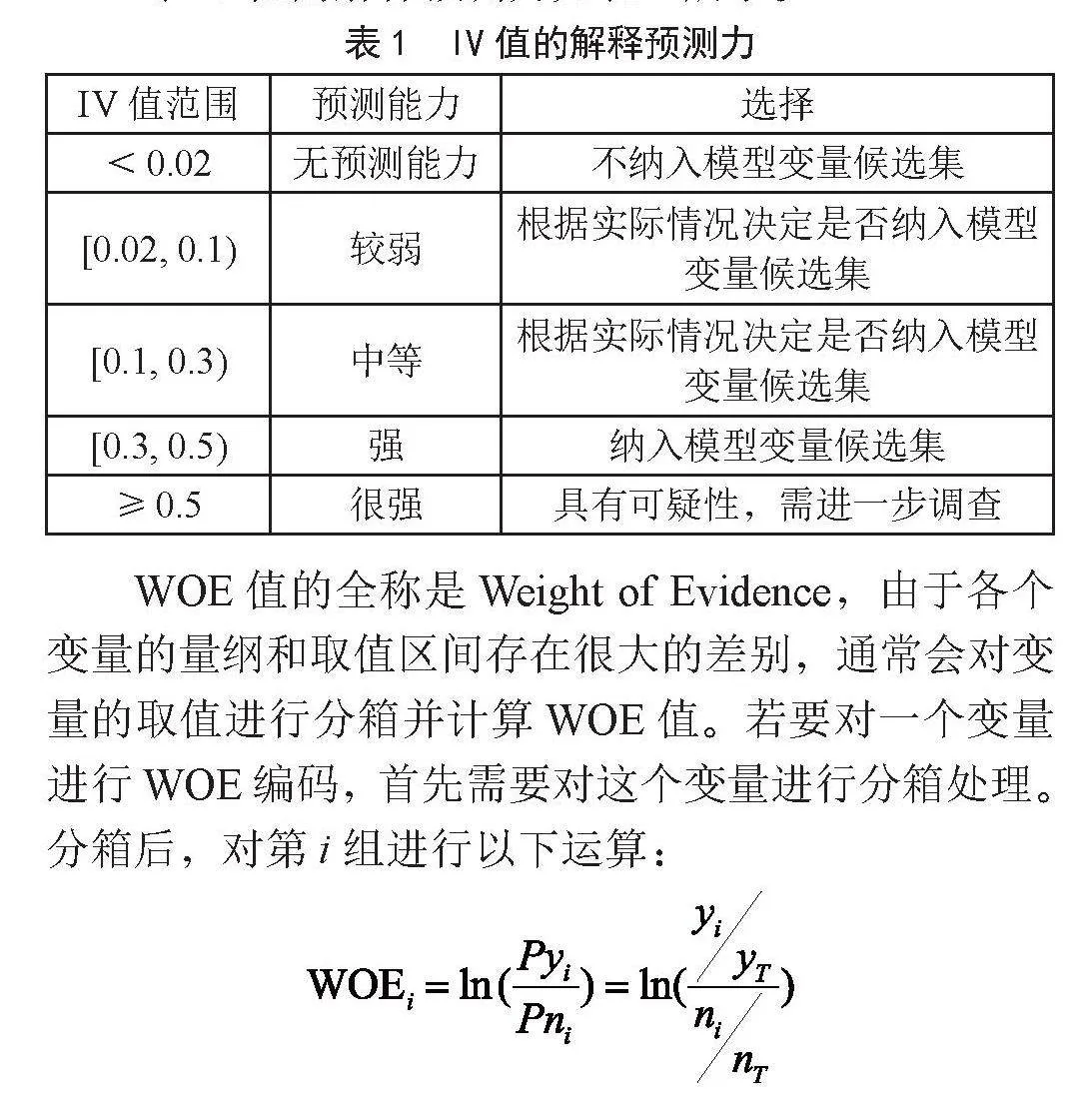
IV值的全称为Information Value,即信息量或信息价值[10],它是评分卡模型中的一个常见指标,广泛应用于金融风控领域。其主要作用是在构建分类模型时对变量进行筛选,对输入变量进行编码和预测能力评估。IV值用于衡量自变量预测能力的大小(强弱),与其相似的还有信息增益、基尼系数等。
对IV值的解释预测力如表1所示。
表1" IV值的解释预测力
IV值范围 预测能力 选择
<0.02 无预测能力 不纳入模型变量候选集
[0.02, 0.1) 较弱 根据实际情况决定是否纳入模型变量候选集
[0.1, 0.3) 中等 根据实际情况决定是否纳入模型变量候选集
[0.3, 0.5) 强 纳入模型变量候选集
≥0.5 很强 具有可疑性,需进一步调查
WOE值的全称是Weight of Evidence,由于各个变量的量纲和取值区间存在很大的差别,通常会对变量的取值进行分箱并计算WOE值。若要对一个变量进行WOE编码,首先需要对这个变量进行分箱处理。分箱后,对第i组进行以下运算:
其中:n为分组个数,表示各分组中“坏”客户占总“坏”客户的比例,表示各分组中“好”客户占总“好”客户的比例。因此,引入WOE的转换,对变量进行筛选并计算WOE、IV值。
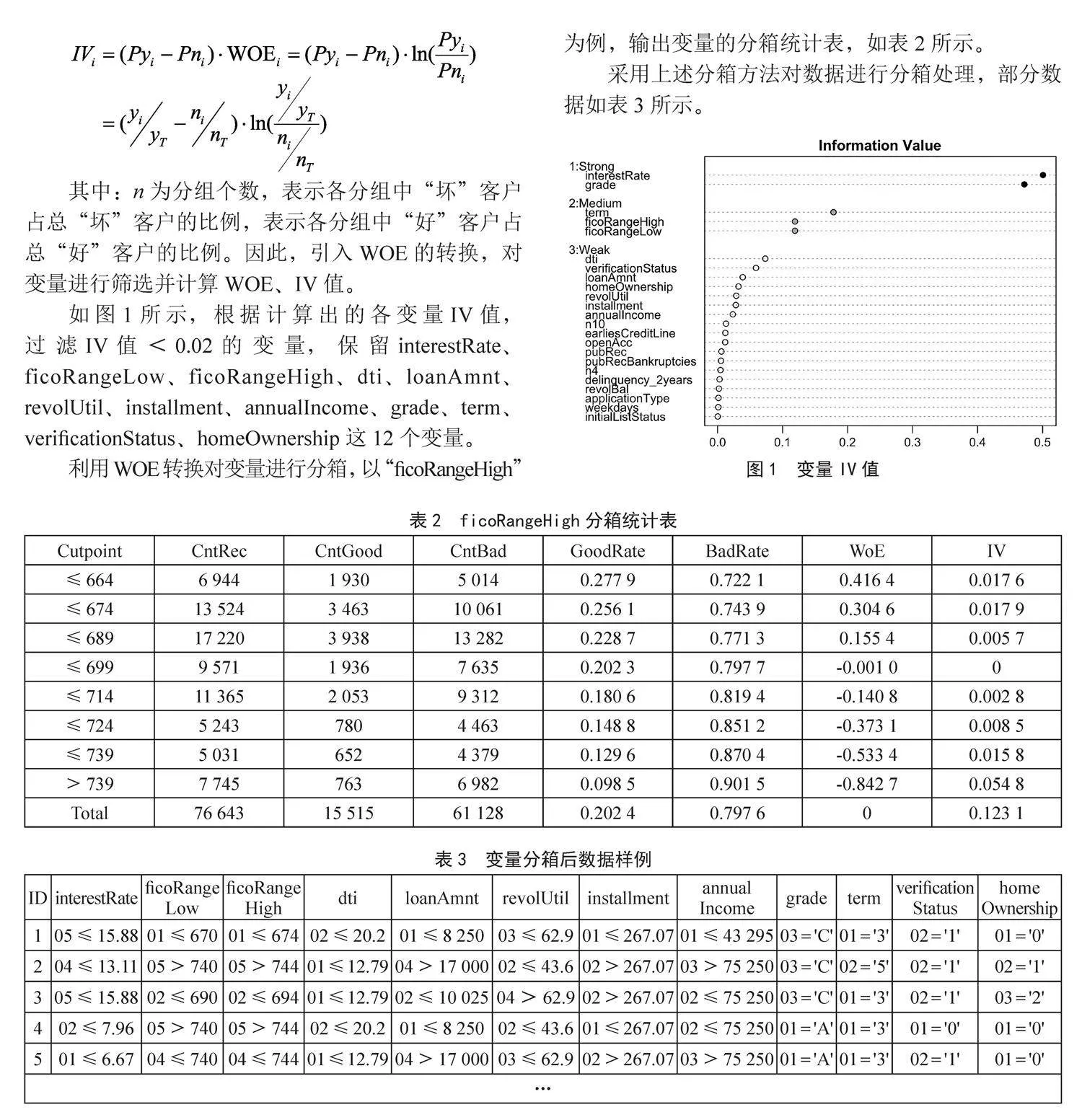
如图1所示,根据计算出的各变量IV值,过滤IV值<0.02的变量,保留interestRate、ficoRangeLow、ficoRangeHigh、dti、loanAmnt、revolUtil、installment、annualIncome、grade、term、verificationStatus、homeOwnership这12个变量。
利用WOE转换对变量进行分箱,以“ficoRangeHigh”为例,输出变量的分箱统计表,如表2所示。
采用上述分箱方法对数据进行分箱处理,部分数据如表3所示。
图1" 变量IV值
3" 基于逻辑回归的个人信用风险评估
现如今常用的个人信用风险评估方法主要有逻辑回归法、判别分析法、人工智能法和非参数分析法。本文建立了基于逻辑回归的个人信用评分卡模型。
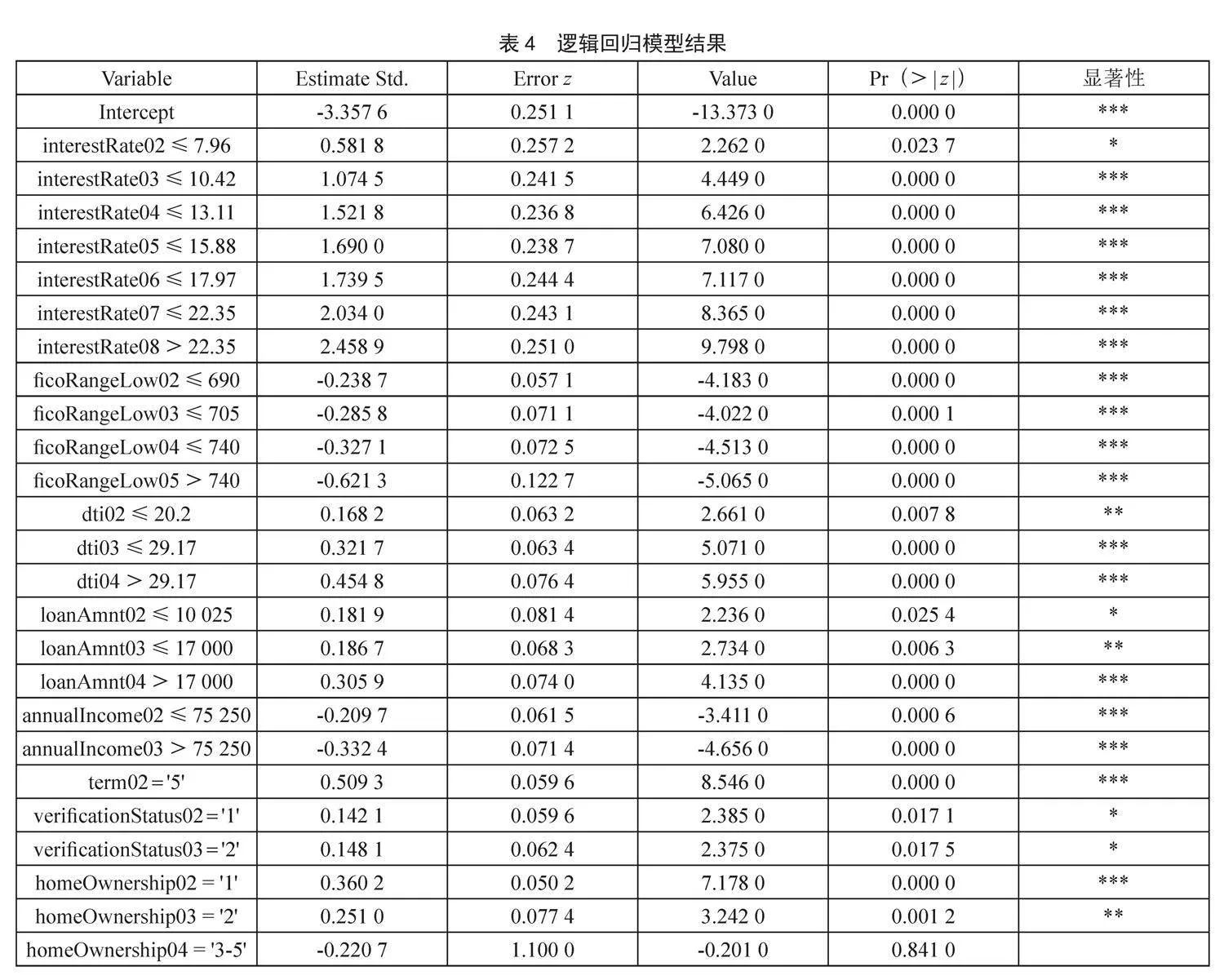
为了深入挖掘影响违约的显著因素,首先按照7:3的比例将数据集拆分为训练集和测试集,在测试集上对模型进行训练,得到逻辑回归模型,如表4所示。
从逻辑回归模型结果可以看出,变量interestRate、ficoRangeLow、dti、loanAmnt、annualIncome、term、verificationStatus、homeOwnership均对违约有显著影响。
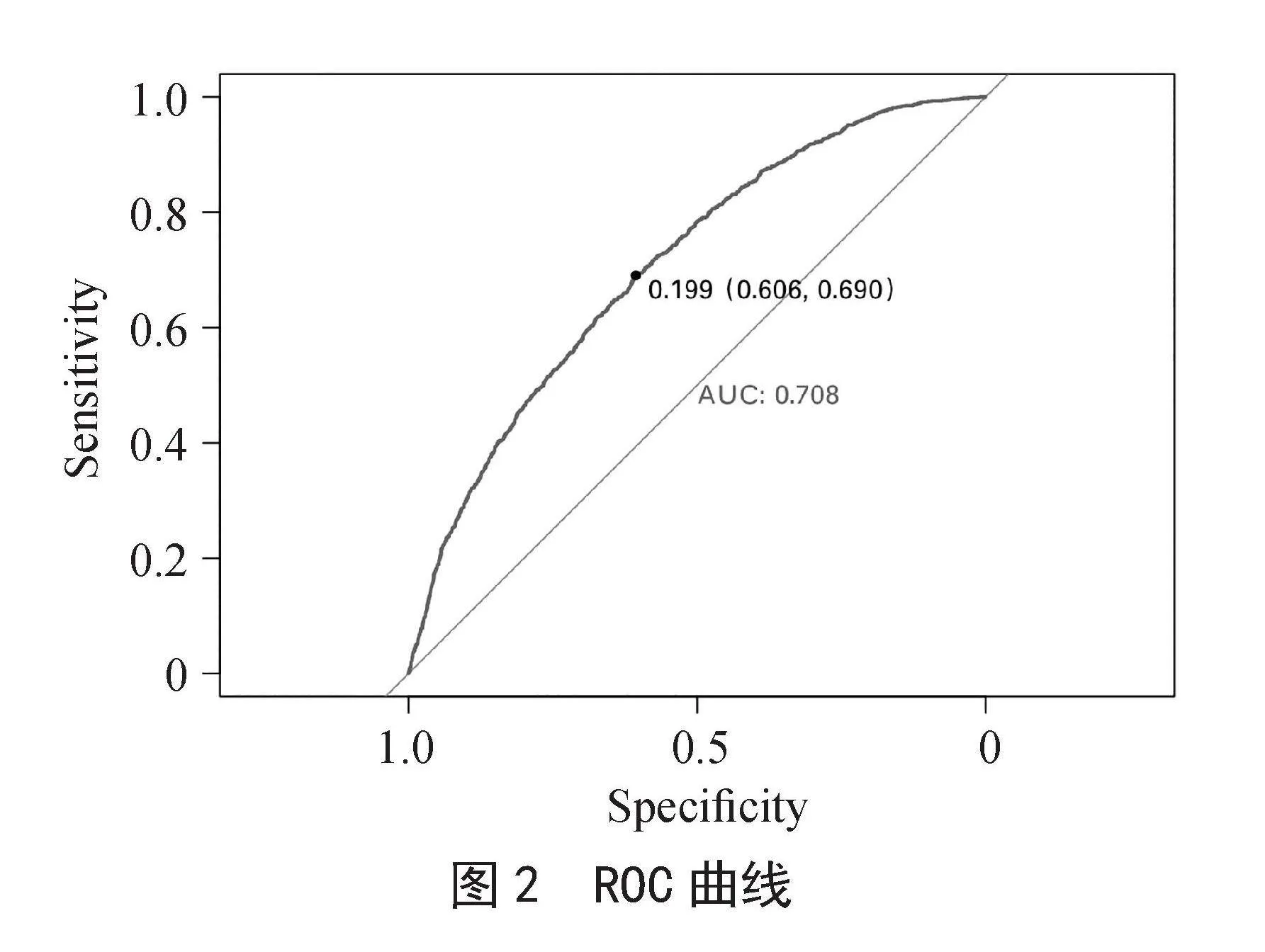
绘制模型的ROC曲线,得到模型的AUC值为0.708,模型的分类效果较好,如图2所示。基于最佳阈值0.199,可计算得到模型的准确率为0.73,表示测试集数据中有73%的客户会被正确归类,精确率达到0.45,表示预测为违约的客户中确实发生违约行为的客户占比为45%,召回率达到0.76,表示客户发生违约并被模型预测出来的比例为76%。
图2" ROC曲线
4" 基于逻辑回归的个人信用评分卡模型
评分卡是一种以分数形式衡量一个客户信用风险大小的凭借,评分卡设定的分值刻度可以通过将分值表示为比率对数的现行表达式来定义。在实际应用中,计算出每个变量各分箱对应的分值。当有新用户产生时,对应到每个分箱的值,将这些值相加,最后加上初始基础分,得到最终的结果。如果用户的某个变量发生改变,由一个分箱变成另一个分箱,只需将更新后所在分箱的值进行替换,再重新相加即可得到新的总分。因此,可以说个人信用评分卡模型具有很强的业务应用价值。
结合logistic模型和评分计算表达式,可以将评分卡改为以下形式:
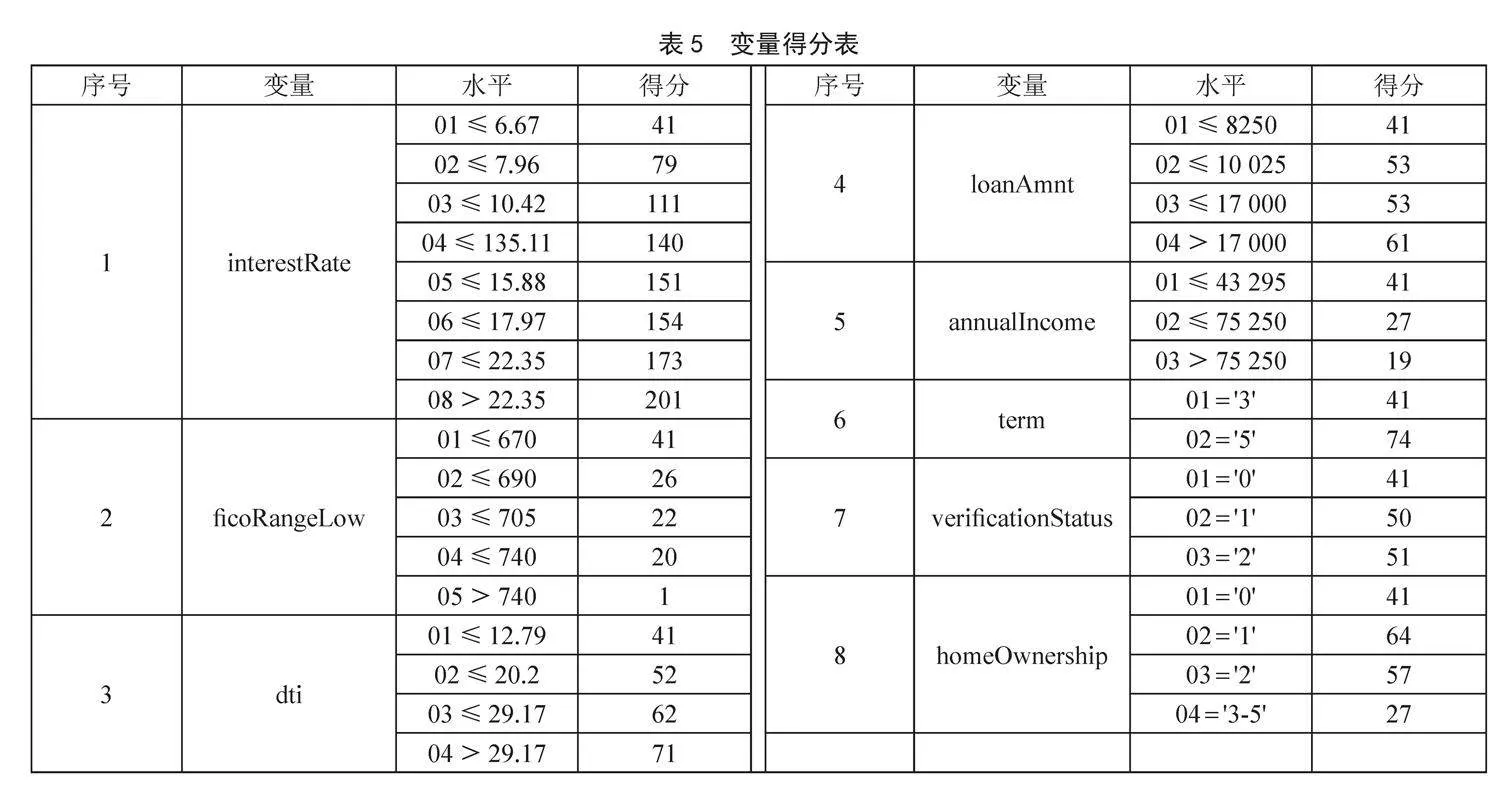
其中,Score为信用得分,A为“补偿”,B为“刻度”,显然,违约概率越高,信用得分越低。采用个人信用评分卡模型,可以通过对不同用户的各种特征进行量化评分,实现对用户信用水平的评估,如表5所示。
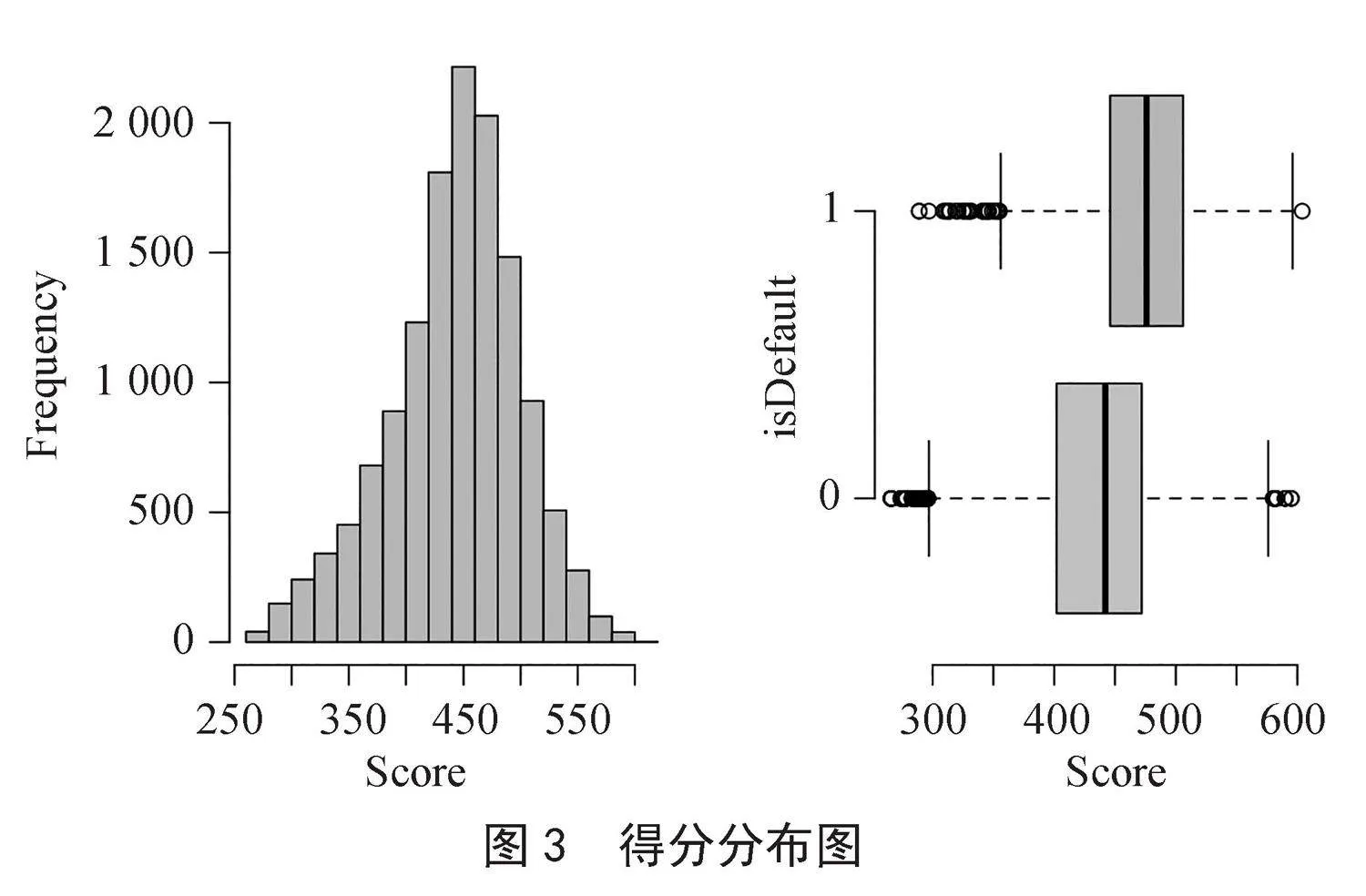
根据各变量得分表最终可得各样本的分值,如图3所示。银行或金融机构可以首先根据个人信用评分卡模型中各预测变量不同分类的信用评分,结合自身的业务需求对每个用户进行量化评分。然后,根据评分的分布特征设定相应的阈值,将用户划分为不同的类别。通过这种方式可以有效控制风险,实现收益的最大化。
图3" 得分分布图
5" 结" 论
本文首先对变量进行了WOE转换、分箱处理,并计算每个变量的IV值来对变量进行选择,剔除相关性不高的变量,然后基于逻辑回归模型建立了个人信用评分卡模型。通过个人信用评分卡模型,金融机构和其他组织可以更加准确地评估借款人、客户的信用风险程度。这有助于决策者制定合理的授信政策、定价策略以及其他相关业务运营策略;同时也可以帮助用户了解自己的信用状况,并采取相应的措施来改善自身的信用评分。
参考文献:
[1] 都珂珂,黄全生,张玥.我国个人信用评估模型综述 [J].经营与管理,2021(1):166-172.
[2] 戴蓓蓓.基于组合预测模型的商业银行个人信贷风险预测 [J].经济研究导刊,2022(35):69-72.
[3] 毛子林,刘姜.基于机器学习方法的信用风险评估综述 [J].经济研究导刊,2021(23):117-119.
[4] 刘念,王文君,高家鸣,等.检验检测机构信用风险评价指标体系建设研究 [J].中国标准化,2023(23):218-222.
[5] 吕秀梅,张儒.网络小额贷款业务个人信用风险评估——基于DNN-SMOTEENN-ExtraTrees组合模型 [J].数学的实践与认识,2023,53(7):14-21.
[6] 杨柳,孙带.基于多分类器串并联结构的个人信用评估模型 [J].湘潭大学学报:自然科学版,2022,44(6):1-11.
[7] 黄宝凤,祁婷婷.基于特征工程的个人信用风险评估组合模型 [J].中国统计,2021(6):37-39.
[8] 范彦勤,黄海午,杨智凯.基于特征工程和树增强贝叶斯网络的个人信用评估研究 [J].桂林航天工业学院学报,2022,27(4):573-579.
[9] 张俊丽,仲崇丽,杨震,等.基于数据挖掘的上市公司高送转预测 [J].财务管理研究,2021(6):90-95.
[10] 张华.基于逻辑回归的驾驶员信用评估研究 [J].计算机时代,2023(3):25-27+35.
作者简介:张俊丽(1982—),女,汉族,陕西韩城人,副教授,硕士,研究方向:数据挖掘与机器学习。