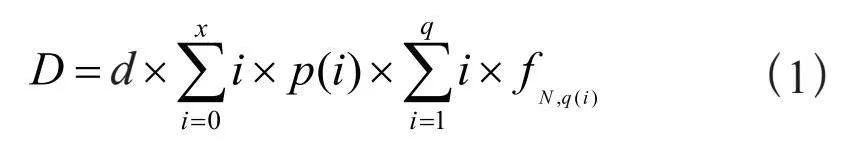
收稿日期:2023-08-19
DOI:10.19850/j.cnki.2096-4706.2024.06.022
摘 要:在“数据爆炸”的当代,数据的价值与日俱增,数据创造价值,数据科学作为一门目前全国最火爆的学科,其目的是从大量数据中提取出有价值的信息用于生产活动。文章基于CiteSpace采用文献计量法,对CNKI和Web of Science两大通用主流文献库进行分析,总结了数据科学领域国内外近十五年研究热点与技术前沿的推进情况。研究结果显示,该领域的当前热点有卷积神经网络等,其热点算法有分类算法,如支持向量机,热点框架有PaddlePaddle等。文章还比较了近年国内外机器学习研究的侧重与发展规模,积极探讨了数据科学基础技术的研究热点,为该领域今后研究提供了方向借鉴。
关键词:CiteSpace;数据科学;机器学习;热点前沿;文献计量法
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)06-0095-08
Research Hotspot and Advance of the Frontier of Data Science at Home and Abroad
—Visualization Analysis of CNKI and WOS Literature Based on CiteSpace
ZHANG Jinquan
(School of Information and Communications Engineering, University of Electronic Science and Technology of China,
Chengdu 611731, China)
Abstract: In the modern era of “data explosion”, the value of data is increasing day by day, and data creates value. Data science, as the most popular subject in China, aims to extract valuable information from a large number of data for production activities. In this paper, based on CiteSpace, the bibliometrics method is used to analyze two general mainstream bibliothems, CNKI and Web of Science, and summarize the advancement of research hotspots and technological frontiers in the field of Data Science at home and abroad in the past 15 years. The research results show that the current hotspots in this field include Convolutional Neural Networks, hotspot algorithms include classification algorithms such as Support Vector Machines, and hotspot frameworks include PaddlePaddle and so on. This paper also compares the focus and development scale of Machine Learning research at home and abroad in recent years, and actively discusses the research hotspot of Data Science basic technology, and provides a reference for future research in this field.
Keywords: CiteSpace; Data Science; Machine Learning; hot frontier; bibliometric method
0 引 言
近年来,“大数据”逐渐成为大众耳熟能详的热门词汇。当“大数据”依次取代“信息”成为一个新时代的标志[1],大数据的价值和重要性也被越来越多人认知。“数据科学”作为一门应对大数据挑战的多学科多技术融合的新兴学科[2],其实很早就被提及。在20世纪60年代,“数据科学”一词就已经出现[3],但直到20世纪90年代,才有了它准确的名称——“Data Science”[4]。目前,我国在数据科学领域的研究方兴未艾,国外同领域则有着较为深入的研究。同时,作为数据科学门下的一个分支,也是如今非常流行的一种机器学习,深度学习开始盛行并逐渐成为统计学领域一种重要模型建立理念。深度学习的概念起初由多伦多大学的Hinton教授于2006年提出[5]。此后的同一年里,该教授和他的学生又提出关于深度学习的另一观点:含多隐层的人工神经网络具有很优秀的特征学习能力,甚至可以对处理后的数据有更加直观的展示,最终得到的网络数据更有利于分类或可视化;通过研究国内外机器学习成果,有助于我们反映数据科学的发展情况,为前沿发展方向提供新思路。
数据科学的实际操作便是对大量数据进行处理,提取得到可以使用的有价值信息。海量数据的复杂性和快速变化给人们检索提取有效信息带来了困难,由此可视化方法应运而生[6]。目前,国际上被广泛使用的可视化软件众多,如Thomson Reuters公司开发的Pajek [7],陈超美教授团队开发的CiteSpace [8]等。文章基于文献计量法对数据科学(深度学习)相关的论文文献进行分析,其中包括但不限于关键词聚类分析、共现分析、突变分析等。通过梳理重要主题及进展,以期为数据科学的相关研究热点与前沿提供参考。
1 基本概念
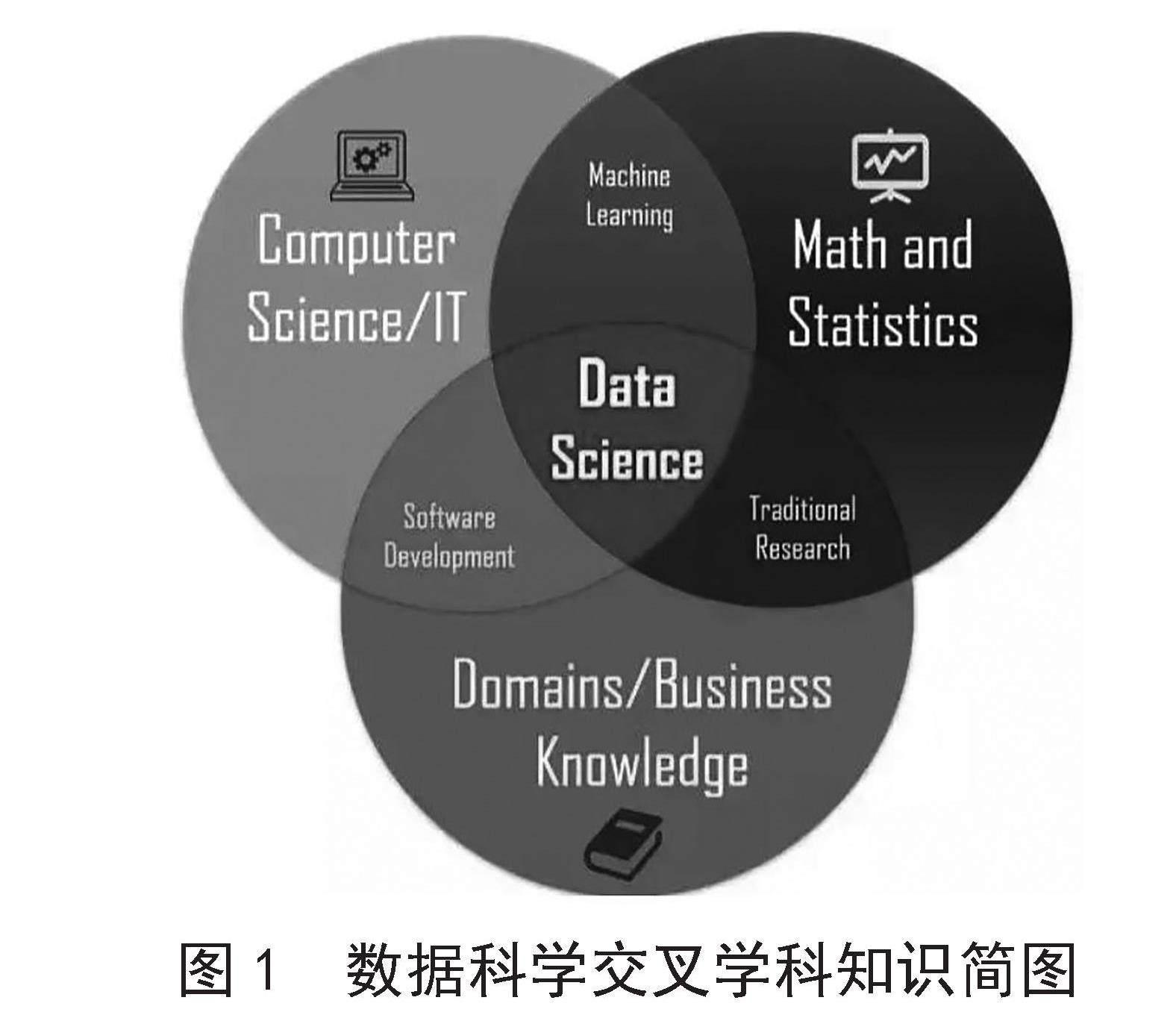
数据科学、人工智能、机器学习、深度学习经常被科研学者提及,但事实上,这些概念经常被混淆,虽然它们的边界确实具有一定的模糊性,但其侧重的关键点却不尽相同,如图1所示(来源:Towards Data Science)。在此,文章给出一些非权威但仍具参考价值的定义。
图1 数据科学交叉学科知识简图
数据科学侧重于产生见解。在伯克利确立开设的数据科学本科项目中,学校对项目给出了如下解释:数据科学学位项目结合了计算推理与推导,以某些现实生活中的数据为基础得到结论。数据科学家来源于社会中的所有领域,所有的研究范畴和各种不同的背景。他们通过数学和科学的思维以及计算编程的力量去理解并解决商业和社会方向的问题。数据科学的目标与人类的目标尤为契合:去获取见解和理解力。
例如,数据科学家可能会使用一些简单的工具:他们计算报告百分比,并根据SQL查询制作线性图。他们也可以使用非常复杂的方法:使用分布式数据存储来分析数以万亿计的数据记录,开发尖端的统计技术,并构建交互式可视化模型。无论他们使用什么,目标都是更好地解读他们的数据。
人工智能,可谓称得上是当下最为热门的科学开拓领域。特别是21世纪20年代OpenAI公司开发的ChatGPT,推动了人工智能领域研究新的热潮。总的来说,人工智能可以称得上是计算机科学的一个子集。“人工智能”的概念诞生于20世纪60年代,它的设计目的是为了解决对人类而言相对较为困难却对计算机较为容易的工作[9]。详细来说,一般认为强人工智能应该能做人类所能做的任何事。其中包括但不限于制订规划、到处移动、识别物体与声音、说话、翻译、商业办公、绘画、作曲等。
机器学习被认为是人工智能的一方面:给定一些可用离散术语描述的人工智能问题,并给出关于这个世界的大量信息,在没有程序员进行编程的情况下弄清楚“正确”的行为。典型的是,需要一些外部流程判断行为是否正确。在数学术语中,也就是函数:馈入输入,产生正确的输出。所以整个问题就是以自动化的方式建立该数学函数的模型。机器学习涵盖了多种算法与技术,如朴素贝叶斯、支持向量机、神经网络、Ensembles、关联规则、决策树、逻辑回归等[10]。
深度学习是机器学习领域中一个细微的研究方向,它源于对神经网络的研究,即通过海量数据用以训练从而构建相关模型来学习特征数据,深度学习能够发现大数据中的复杂结构。其中,较常用的模型或算法有自动编码器、限制波尔兹曼机、深信度网络、卷积神经网络等。
2 研究设计
2.1 数据来源
分析使用的原始数据主要来自CNKI(知网)及Web of Science平台上的核心数据库,包括SSCI、ESCI等。为确保研究文献的客观性和科学性,国内外资料的收集分别选取了“数据科学”“机器学习”和
“Data Science”“Machine Learning”“Datafication”。时间跨度则为过去十五年(2007—2023年),筛选得到了累计82 164条检索结果,选择导出格式为全著录格式分次导入,作为研究分析的源文件。
2.2 研究方法与工具
使用文献计量法,搜集数据库的文献数据,对其进行除重清晰,并以不同的视角进行计量分析,并以可视化的图谱用以辅助分析和直观表达。使用到的知识图谱工具为陈超美教授开发的CiteSpace,该工具在过去的十几年里已被广泛应用于科学文献的计量领域。文章试图基于CiteSpace挖掘数据科学领域的时空分布、研究热点及研究前沿。
2.3 研究流程
如图2所示,研究流程具体可表示为以下三个步骤。首先,对数据样本进行文献计量分析并通过CiteSpace软件进行网络图谱的多维分析,从时空等多重维度,初步了解国内外深度学习研究热点的基本情况;其次,对文献数据进行Keyword(关键词)分析,从可视化的角度展示出数据科学领域当前的热点分析和前沿推进;最后,探讨对比国内外深度学习的研究,并做出总结展望。
3 研究热点基本情况
文章对数据科学领域的研究热点进行分析。基于某领域的研究热点通常是指在某一时期该领域发表文献中出现的高频次、高中心度和高强度的主题词。根据共词分析法,文章基于数据科学领域近十五年的文献绘制关键词共现图谱,并统计其中的高频关键词,明确近十五年(2007—2023年)数据科学领域的研究热点,进而分析其推进进程。
数据科学领域关键词共现知识图谱中共有节点
N(753)个,连线E(1 696)条,中心度Density=
0.006。依据分析结果,近十五年数据科学(涵盖机器学习)的研究热点(火热程度依次递减)主要为大数据、人工智能、深度学习、数据挖掘、课程培养、情感分析、随机森林、知识图谱、神经网络、算法、统计学、数据分析、可视化、云计算、学习分析、预测等。
通过对于关键词的聚类处理,出现了11个类别。其中最大群集(#0)有8个成员,轮廓值为0.84。其聚类标签为机器学习。第二大聚类群集(#1)有9个成员,轮廓值为0.823。它被LLR算法标记为大数据。
以此类推,聚类标签依次为机器学习、大数据、人工智能、数据科学、知识图谱、情感分析、信息抽取、数据挖掘、金融科技、复杂网络、学习科学。将这些热点词进行逐一整理,以找出近十五年的研究热点。
在最近的十五年范围内,数据科学领域流行的热门词汇的呈现结果如表1所示。
分析如下:
表中排名第一的热点词汇为大数据。海量、高增长率和多样化大数据的信息筛查和有效价值提取离不开新的数据处理模式。在国内,大数据与数据科学被划分为一门高校开设的本科专业名称。对于数据科学的检索,大数据词汇屡屡被提及。同时,作为21世纪20年代以来的新兴技术,大数据成为包括数据科学在内的各大领域的研究热点。
表中排名第二的词汇为机器学习。在前文中已经对数据科学和机器学习做了一定程度上的定义区分。机器学习与热点排名第十的算法等均有一些相关性。对于数据科学中数据的处理,升维降维等,均需要机器学习的算法原理与技术支撑。直白来说,数据科学离不开机器学习,机器学习的发展是数据科学的基础支撑。
表1 2007—2023年数据科学领域文献高频关键词统计结果
排名 频次/次 关键词 最早引用时间/年
1 8 642 大数据 2012
2 8 126 机器学习 2007
3 6 579 人工智能 2007
4 6 249 数据科学 2007
5 4 168 新工科 2018
6 3 522 情感分析 2010
7 3 011 随机森林 2007
8 2 965 知识图谱 2017
9 2 234 神经网络 2008
10 1 876 算法 2009
11 1 552 可视化 2012
12 1 421 分类回归 2008
13 1 292 支持向量机 2008
14 1 310 深度学习 2016
15 1 292 决策树 2008
16 1 148 预测模型 2020
17 1 008 因果推断 2021
18 899 区块链 2018
19 733 数据管理 2016
20 556 复杂网络 2013
表中排名第三的词汇是人工智能。数据科学对于大数据的快速有效处理,大大拓宽了人工智能的发展前景。毫无疑问,人工智能将是社会发展和数据科学发展的热点方向。当下,人工智能已经被广泛应用于交通、数字媒体及服务行业[11]。
表中排名第四的是数据科学,这是由于我们以数据科学为索引查找文献,故出现频次较高,可以忽略。但可以指出的是,数据科学并非频次最高的排名词汇,这是由于数据科学在国内领域中发展还不为成熟,文献中大多采用机器学习、大数据等其他词汇对数据科学加以修饰的结果。
表中排名第七的是随机森林。随机森林算法是决策树算法的一个延伸推进,它选用了随机的数据集来提升决策树的分析准确性。自从Leo Breiman开创随机森林算法后,该算法的研究长期处于推进状态[12]。随机森林可以有效处理大量数据,包括海量的不相关数据,用于进行风险评估等。
表中排名第九的热点词汇是神经网络。近年来,神经网络算法屡屡取得突破。比较出名的有递归神经网络,包括时间递归与结构递归。神经网络算法的研究推进,无疑为深度学习、数据科学的发展提供了助力。
表中排名第十三的是支持向量机。作为一种二元分类算法,支持向量机主要思想是将一组多类型的N维地方点线性可分成两种类型。这种划分使用的直线到各点的最近距离需要尽可能的大。一般来说,支持向量机的发展经历了三起三落。当前,支持向量机被广泛应用于人脸面部识别剪接位点处理及一些特殊图片处理问题。
4 研究热点可视化结果及分析
4.1 时空分析图谱
4.1.1 时间线图谱分析
通过对国内数据科学文献的关键词进行时间线图谱可视化,可以得到数据科学领域的研究主题随时间的变化情况,从而得到各个时间段的热点主题的相关分布情况。
如图3所示,在关键词时间线图谱中,首先对于众多关键词进行了聚类操作,对于11个类别下的关键词进行了时间上的切分处理。颜色越鲜艳,代表研究的时间越近,同时也说明研究的火热程度更高。从图上可以发现,机器学习、人工智能、数据科学早在时间线2007年便已经出现,而大数据是在约2012年成为研究的热点,并在之后保持火热状态。深度学习、随机森林等热点词汇也在近十五年内频繁出现。
4.1.2 发文机构空间图谱分析
图4反映了数据科学于国内的文献发表机构情况。其中,出现频次最高的机构是武汉大学信息管理学院(89篇),其次是南京大学信息管理学院(63篇),如表2所示。
对武汉大学信息管理学院合作机构进行网络分析。如图5所示,可见武汉大学信息管理学院就数据科学的研究与西南大学计算机与信息科学学院、电子科技大学中国科教评价研究院、华中师范大学信息管理学院等多个机构开展过合作。可见,这些高校在数据科学领域的合作关系较为密切。图中偏红的色调代表研究时间距现在越近,因此,中国人民大学信息资源管理学院与华中师范大学信息管理学院对于数据科学的研究在该图中表现为近期开展的研究。这些高校间的合作关系,一定程度上能够进一步发挥各高校的优势学科、促进数据科学的快速发展。
图4 2007—2023年数据科学国内发文机构图谱
表2 2007—2023年CNKI数据科学相关文献机构发文数排名表
排名 发文数/篇 最早发文时间/年 发文机构
1 89 2010 武汉大学信息管理学院
2 63 2013 南京大学信息管理学院
3 30 2009 武汉大学信息资源研究中心
4 28 2014 中国科学院文献情报中心
5 27 2013 中国科学院大学
6 26 2015 中国人民大学信息资源管理中心
7 21 2019 中国科学院大学经济与管理学院
8 20 2008 中国人民大学统计学院
9 20 2016 南京理工大学经济管理学院
10 19 2018 江苏省数据工程和知识服务中心
11 19 2009 北京大学信息管理系
图5 武汉大学信息管理学院机构合作网络图谱
4.2 关键词共现及突变词检测图谱
4.2.1 关键词共现分析
生成热点关键词共现图谱如图6所示,关键词的节点越大,说明该关键词的被引用频次就越高。根据热点关键词出现的频次排名,联系表1,在20个热点关键词中,除去少数情况,这些关键词基本遵循频次越高中心性越高的规律。而与研究领域数据科学密切相关的大数据、人工智能、机器学习等词汇,均表现出明显的高频高中心性的特点。这些词汇在数据科学研究领域作用较大,对研究有着举足轻重的作用。此外,数据科学的构建离不开算法、数据管理,这些都在关键词共现图谱中得到了表现。
图6 2007—2023年数据科学领域关键词共现知识图谱
如图7所示,对数据科学关键词进行基于LLR的聚类,可以得到11个类别。其中“学习科学”一类的论文时间基本集中在2010年左右(连线颜色为灰色),在此不做考虑。由聚类图可见,数据科学的类别紧靠大数据和数据挖掘表明这几类的密切程度极大。同时机器学习和人工智能节点的最外围表现出明显的红色,说明这两个类别是当下数据科学研究的核心热点主题。可以说明,当前主流开展的数据科学研究基本在这两个类别的范围之内。此外,金融科技、知识图谱、信息抽取没有表现出明显的节点,说明这些是数据科学的广泛应用层面,其热点程度不如机器学习与人工智能,是过去十五年中数据科学应用领域的粗略概括。
4.2.2 突变词检测分析
利用CiteSpace的突变检测(Burst Detection)功能,对数据科学CNKI库近十五年的文献的全部关键词进行探测,利用词频的时间分布与变化趋势,获得突变词的演变进展,演进情况如图8所示。
图8 2007—2023年数据科学研究领域突变词检测图谱
在2007—2023年间共出现了28个突变词,即数据挖掘、本体、科学院、信息抽取、可视化、云计算、数据、大数据、数据科学、统计学、第四范式、数据分析、社会科学、学习分析……这些突变词一起组成了近十五年数据科学领域研究的前沿与新兴领域。
把这28个突变词分成三个时期,从而更好地分析数据科学十五年来的演进进程。2007—2012年,国内的数据科学主要应用在信息抽取、数据挖掘等方面,主要由科学院进行研究;2012—2017年,随着大数据概念被提出[13],数据科学作为一门学习分析的新兴专业,统计学等关键词在这一时期作为研究热点;2017—2023年,在这一时期,数字经济、可解释性、文本分析、预测模型成为数据科学的研究热点,至今仍保持着热度。由此可知,目前数据科学领域的研究侧重点在集成学习、机器学习领域[14],数据科学仍处于不断发展和应用阶段,也有待更加快速、便捷算法的更新迭代。
5 国内外深度学习(数据科学)研究比较
5.1 基于Web of Science核心库的文献分析
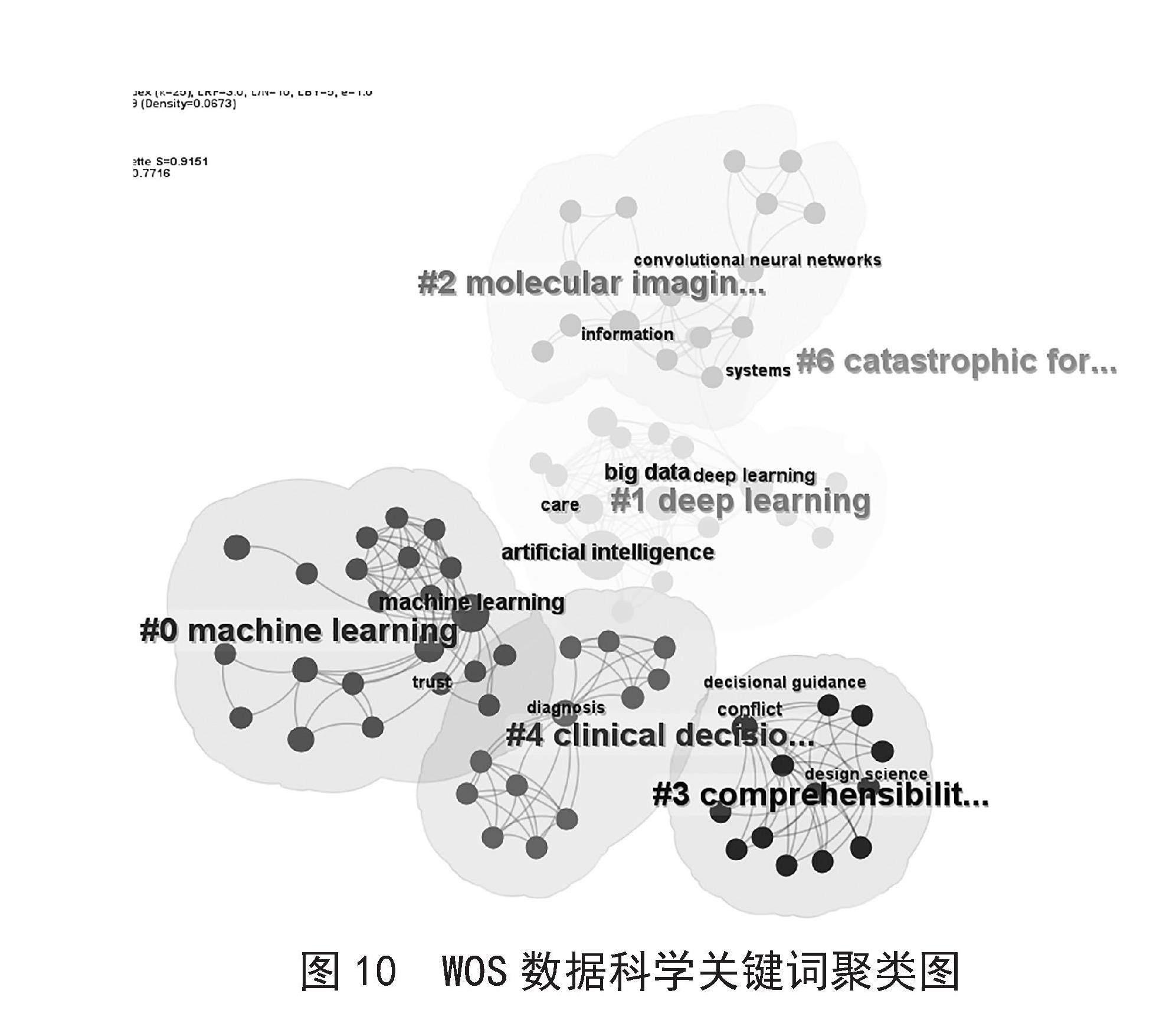
如图9所示,WOS数据科学领域关键词共现知识图谱中共有节点N(108)个,连线E(389)条,中心度Density=0.067 3。分析结果如图10所示,近十五年数据科学的研究热点依次为Artificial Intelligence、Machine Learning、Big Data、Deep Learning、Information、Trust、Health Care、Classification、Computer Version等。
图9 WOS数据科学领域关键词共现知识图谱
图10 WOS数据科学关键词聚类图
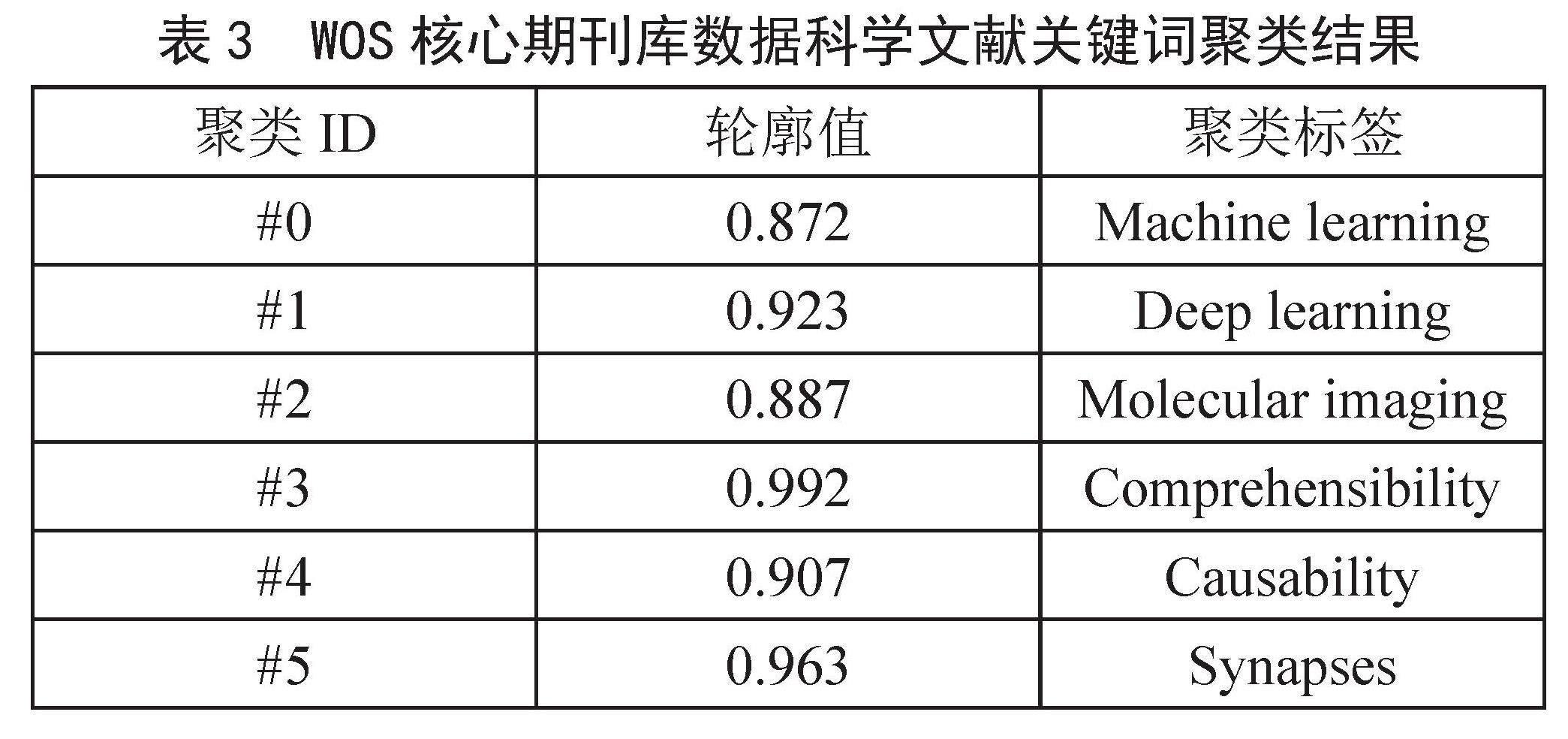
如表3所示,通过对关键词的聚类处理,出现了6个类别。
表3 WOS核心期刊库数据科学文献关键词聚类结果
聚类ID 轮廓值 聚类标签
#0 0.872 Machine learning
#1 0.923 Deep learning
#2 0.887 Molecular imaging
#3 0.992 Comprehensibility
#4 0.907 Causability
#5 0.963 Synapses
5.2 研究比较
对比CNKI和Web of Science核心期刊库的可视化结果,可以发现以下特点。
国内数据科学的研究热点基本涵盖国外研究的热点,如机器学习、大数据、深度学习、可理解性等,同时其分析结果也含有新工科等一些偏学科建设的关键词信息[15]。一方面,这是因为文献去脏化处理作筛除时保留了一些关联性不强的文献,具有一定的客观性;另一方面,国内将“数据科学与大数据技术”列为二级学科,是其研究索引结果中包含了较多教育学的文献内容所致。
国内数据学科研究更多偏向于现有原理的技术应用,因此结果降维聚类后含有交叉学科的聚类标签。而国外数据学科研究更多专注于理论方向上的研究,如深度学习、机器学习算法等。
6 前沿研究难题
新的科学的范式往往来源于数据密集型科学发现,即大数据问题[16]。虽然大量的数据中常常隐藏着非常多的有用价值,能够为科学进步和社会生产提供帮助,但同时大数据也面临着许多的挑战。随着信息增长的速度以指数函数速度增长,海量数据对人们造成极大困扰,无论是数据收集、数据存储,还是数据分析、数据可视化,都存在着众多的挑战与困难[17]。文章结合一些综述性文献,对数据科学前沿面临的难题作一个简单整理。
数据的初步处理。大数据样本的获得,往往需要多个来源,而多数的来源彼此独立。它们汇集而形成大量、复杂且不断增长的数据集[18],这就使得如何选择最有价值的来源并有效融合信息成了数据科学领域的核心问题。
数据的深度挖掘。图片、音频、视频等文件数据大多属于半结构化或非结构化数据,对于这类数据的挖掘处理,需要通过大数据的语义理解与分析。大数据语义分析技术将为基于网络大数据的理解提供关键支持,是众多大数据应用的基础[19]。这就需要在大数据自然语言识别和非结构化数据的集成技术上取得突破。
数据的分析与利用。数据采集、存储、管理与深度处理等最终目的是要挖掘出数据的价值,这也是数据科学兴起与发展的根本[20]。数据科学的研究目的是为了对海量数据进行处理和分析,从异构数据中获取有价值的知识,为决策服务,而决策通常是多维的,需要数据分析人员能够从数据的多维角度对数据进行处理分析,并整合成能够为决策提供有效价值服务的信息,因此数据科学如何进行可视化辅助分析人员提取有效信息也就非常关键了。
个人数据的保护。数据科学的发展,可以较大程度提高对以往看似无用数据的利用率,提取有价值的可处理信息。因此,伴随着数据科学的不断迭代进步,就给如何保护原始个人数据库信息带来了挑战。
7 结 论
文章对国内CNKI和国外Web of Science核心库2007—2023年期间数据科学、机器学习领域为关键词进行了知识图谱分析,使用CiteSpace软件工具绘制了时空分析图谱、关键词共现图谱以及突变词检测图谱,并对各个图谱进行分析,得出了数据科学领域的研究进展和研究热点。从国内研究的关键词共现来看,数据科学的研究热点集中在大数据、人工智能、数据挖掘、算法、随机森林、神经网络和预测等。突变词检测图谱则表明数据科学的当前热点集中在集成学习、文本分析和预测模型。其中深度学习的深度置信网络,也是该领域目前的研究热点之一。此外文章还对比分析了国内外深度学习研究热点的区别,陈述了当前数据科学领域前沿面临的难题。
总体而言,数据科学领域的一些理论尚待完善,各种新型应用也处于探索研究阶段。同时,文章还存在着一定局限性,主要受限于期刊数据仍存在“去脏化”的上限空间,使用CiteSpace的一些剪枝功能的参数还能做到进一步优化与调试等。文章对文献的关键词等基本信息进行现有筛除,获得了数据科学当前的热点方向,后续前沿领域的前进方向还需在文章结果的基础上做进一步的优化分析,总而得到更具指导意义的结论。
参考文献:
[1] 周傲英,钱卫宁,王长波.数据科学与工程:大数据时代的新兴交叉学科 [J].大数据,2015,1(2):90-99.
[2] 陈振冲,贺田田.数据科学人才的需求与培养 [J].大数据,2016,2(5):95-106.
[3] DONOHO D. 50 Years of Data Science [J].Journal of Computational and Graphical Statistics,2017,26(4):745-766.
[4] CAO L B. Data Science: A Comprehensive Overview [J].ACM Computing Surveys,2017,50(3):1-42.
[5] HINTON G E,OSINDERO S,TEH Y-W. A Fast Learning Algorithm for Deep Belief Nets [J].Neural Computation,2006,18(7):1527-1554.
[6] 史纪元.基于CiteSpaceⅢ输血医学研究领域知识图谱分析 [D].西安:第四军医大学,2015.
[7] 李杰,陈超美.CiteSpace:科技文本挖掘及可视化 [M].北京:首都经济贸易大学出版社,2016.
[8] 刘则渊,陈超美,侯海燕,等.迈向科学学大变革的时代 [J].科学学与科学技术管理,2009,30(7):5-12.
[9] 陈悦,陈超美,刘则渊,等.CiteSpace知识图谱的方法论功能 [J].科学学研究,2015,33(2):242-253.
[10] 周金侠.基于Citespace Ⅱ的信息可视化文献的量化分析 [J].情报科学,2011,29(1):98-101+112.
[11] 庄诗梦,王东波.深度学习领域研究热点与前沿分析——基于CiteSpace的信息可视化分析 [J].河北科技图苑,2018,31(1):73-82.
[12] 叶文豪,王东波.基于知识图谱的国外数据科学研究状况分析 [J].河北科技图苑,2017,30(6):73-83.
[13] 张福俊,赵文斌,叶权慧,等.机器学习领域研究热点与前沿演进——基于CiteSpace的可视化分析 [J].软件导刊,2019,18(9):5-8+225.
[14] 徐建国,刘泳慧,刘梦凡.国内深度学习领域研究进展与热点分析——基于CiteSpace与VOSviewer的综合应用 [J].软件导刊,2021,20(1):234-237.
[15] 李嘉雯,李玉斌,袁子涵.国外近十年深度学习研究进展——基于CiteSpace知识图谱的可视化研究 [J].软件,2019,40(2):147-151.
[16] 朝乐门,邢春晓,张勇.数据科学研究的现状与趋势 [J].计算机科学,2018,45(1):1-13.
[17] CHEN C L P,ZHANG C-Y. Data-intensive Applications, Challenges, Techniques and Technologies: A Survey on Big Data [J].Information Sciences,2014,275:314-347.
[18] WU X D,ZHU X Q,WU G-Q,et al. Data Mining with Big Data [J].IEEE Transactions on Knowledge and Data Engineering,2014,26(1):97-107.
[19] 唐杰,陈文光.面向大社交数据的深度分析与挖掘 [J].科学通报,2015,60(Z1):509-519.
[20] 王曰芬,谢清楠,宋小康.国外数据科学研究的回顾与展望 [J].图书情报工作,2016,60(14):5-14.
作者简介:张锦佺(2002—),男,汉族,湖南长沙人,本科在读,研究方向:数据科学与大数据、深度学习、信息化应用。