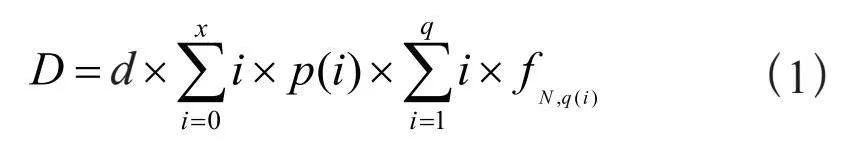



摘 要:我国正在步入人口老龄化社会,政府为保障老人的每日三餐,在各地购买养老助餐服务,服务过程中出现虚假服务、盗用冒用等问题,威胁到政府和老人的财产安全,故提出E-ARLL算法对数据异常进行检测。该方法使用Pearson相关系数和ANOVA(方差分析)对原始数据集进行划分特征训练集和特征验证集,然后,将特征训练集输入到E-ARLL算法模型中,基于集成学习(Ensemble Method)思路,根据划分好数据集的线性关系选择适合的算法进行异常检测。实验结果表明,提出的方法对养老助餐服务数据异常检测表现出良好的性能,最终异常数据识别率为99.4%,为政府购买服务的可信性带来了新的验证方法,具有深远的意义。
关键词:异常检测;集成算法;养老服务
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)08-0171-06
DOI:10.19850/j.cnki.2096-4706.2024.08.037
0 引 言
随着人口老龄化的加深,老年人“吃饭难”的矛盾日渐突出,为解决老年人“用餐难”问题,中国各地纷纷出实招,通过社区自办、和企业餐馆合作等方式探索社区老人助餐服务模式[1],通过这种服务模式给社区老人带来暖心的餐饮供应。然而在服务过程中,存在着一些养老服务数据可信问题,如老人助餐卡盗刷、代刷,服务机构虚假服务、谎报服务数量等问题。这些问题的存在不仅会影响老年人的生活质量,还对社会养老服务稳定发展造成不良影响。因此,解决数据可信问题对提高养老服务质量、促进社会发展具有重要意义。
当前对于异常检测的分类主要分为三种:单点异常、上下文异常、集体异常。对于单点数据检测,使用较多的方法是随机森林(Random Forest, RF)算法,如Zhang [2]等学者提出随机森林结合极端梯度提升,建立风电机组故障检测框架,提高检测精确度;Sadaf [3]等学者采用自编码器结合孤立森林对雾计算环境下数据包进行二进制分类;Xu [4]等学者提出改进孤立森林算法(SA-iForest),在UCI数据集中验证该算法的准确性和效率。这些方法对于异常点与其他数据点有明显差异能有效分类,而养老服务数据中数据特征存在多种异常数据,也包含时序特征数据,该部分需要采用上下文异常检测方法进行识别。
而具有时序特征的数据现有的长短期记忆算法(Long Short Term Memory, LSTM)[5]算法和Prophet算法各有优劣。如Nabipour [6]等学者对于股票走势进行预测,使用RNN结合LSTM算法对比其他算法预测精度更高;Fan [7]等学者对于快速固化炉热过程的数据使用MLP-LSTM混合算法进行分析,验证了算法的可靠性;ChikkaKrishna [8]等学者基于Fb-Prophet和Neural-Prophet开发了STTP模型,进行对道路车流量的预测;赵英[9]等学者结合LSTM算法和Prophet算法对机房温度进行建模,通过对两种算法模型进行非线性组合得出较好的预测结果;还有一些采用机器学习的方法来实现异常数据的检测,如Nikravesh [10]等学者对商业试验移动网络进行预测未需求,采用SVM、MLP、MLPWD算法进行试验验证。上述方法对于具有长期时序性特征的数据具有很好的识别效果,但上述方法对于不同的异常情况鲁棒性较弱,和特征训练集之间拟合度不佳。
为了解决这一问题,董红瑶等[11]提出引入领域容差关系选择集成分类算法,此方法构建多个基分类器进行加权集成最终预测分类结果,复杂度较高。在养老助餐服务领域助餐点设备算力有限,需要减少模型复杂度。
本文的数据集中包括时序特征,也有非线性特征等,因此对单点异常采用随机森林和逻辑回归进行分类,对上下文异常采用长短期记忆进行识别,能针对性地检测出特征训练集中的异常,再将检测结果进行集合,提高模型检测精确度,更具可靠性。
1 系统模型构建与方法设计
1.1 相关工作
本文收集了从2022年6月1日到2023年4月16日某市124个助餐点每日的用餐数据,涵盖了凤阳县、琅琊区、明光市、南谯区、天长市下的39个街道,数据总量是303 828条。数据特征包括:姓名、类别、助餐点名称、用餐类型、就餐方式、录入方式、套餐价格、补贴金额、自付金额、创建日期、创建时间、区和街道,共计13个特征。通过对数据的分析,发现主要存在三种异常:
1)助餐点异常。若一个老人在一段时间内频繁切换助餐点用餐,那么可能存在异常情况,比如身份冒用或者错误输入数据。
2)补贴金额异常:每人每天的补贴金额是有上限的,若老人在一天内补贴金额超过上限,或者补贴金额数值不对,那么可能存在异常情况,比如系统故障或者老人信息录入异常。
3)用餐类型异常。不同助餐点对于用餐类型的时间判断标准不同,若存在数据用餐类型与时间对应不上,那么可能存在异常情况,比如系统延迟。
针对以上三种异常情况,本文提出多模型集成的异常点检测方法,采用RF、LR和LSTM算法对数据进行分类,并将其预测结果和预测概率输出。下一步将三种异常检测的预测概率作为新的特征输入到神经网络中,调整模型参数,目的是找到最优的检测结果。
1.2 数据预处理
对各124个助餐点收集到的数据进行分析发现其中含有重复值、数据格式不一致等情况,为确保数据的准确性、一致性和可靠性,本文对数据进行数据清洗、特征选择和特征转换等操作,得到更有利于分析建模的数据集。
1.2.1 数据清洗
对数据集特征值为文本信息时,以部分老人在类别(A类、B类、C类、C1类、…、C4类、D类)特征是空值为例,类别和补贴金额存在着相关性,计算相同补贴金额对应的类别的众数填充到类别特征,以下是算式描述:
(1)
其中xb表示类别,xh表示补贴金额,Mode表示补贴金额对应类别的众数,xbempty表示需要填充的空值。
对于特征训练集的特征为数值信息时,以创建时间为空值为例,数据集是按照数据上传采集顺序排序的,存在数据为一天第一条或者最后一条,单以上下条数据的均值是无法合理填充的,将用餐类型作为条件,进行缺失值填充,以下是算式描述:
(2)
其中xq表示创建时间,xd表示用餐类型,ξ表示随机数(ξ取10分钟以内),若xd(j-1) ≠ xdj ≠ xd(j+1)时选取该用餐类型合理的时间范围内随机时间进行填充,如图1所示填充空值。
1.2.2 特征编码
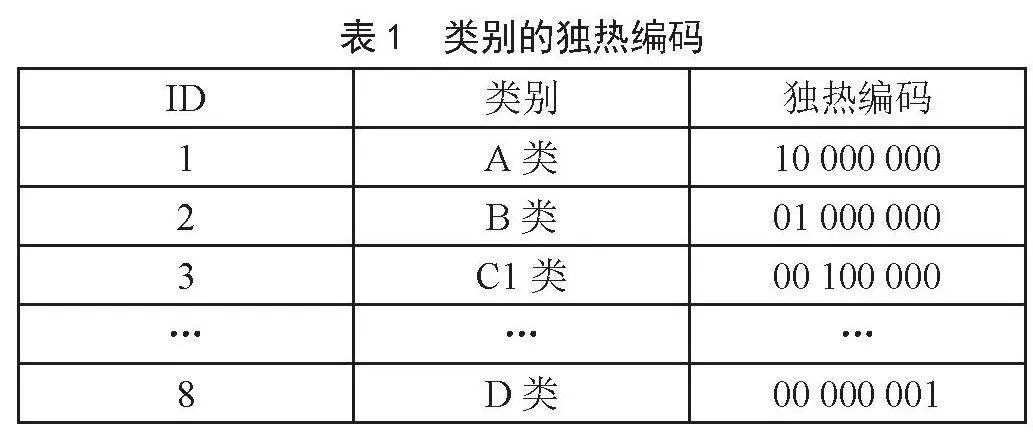
数据集中存在较多的非数值型特征,其姓名特征包含的特征值种类较多,采用标签编码,降低空间开销,例如:[“张三”“李四”“王五”]编码为[1,2,3]。其他非数值型特征采用独热编码,如表1所示,类型分为8种,根据每个类别的序列ID,只有唯一独热编码与其对应。
通过数据预处理,得到完整且易于机器识别的数据集,易于后续的算法分析和建模。
1.2.3 特征选择
数据特征中包含多种类型的特征,对于数字特征之间采用Pearson相关系数来衡量连续变量之间的线性关系,如补贴金额和套餐价格等数字特征。对于一些非数字特征对其进行编码,转换成适合模型使用的数字形式,采用ANOVA(方差分析)比较多个组的均值是否相等,如类别和补贴金额等。对三种异常情况选定好相关特征后,重新构建子数据集D1、D2和D3,以供研究使用。
2 E-ARLL算法
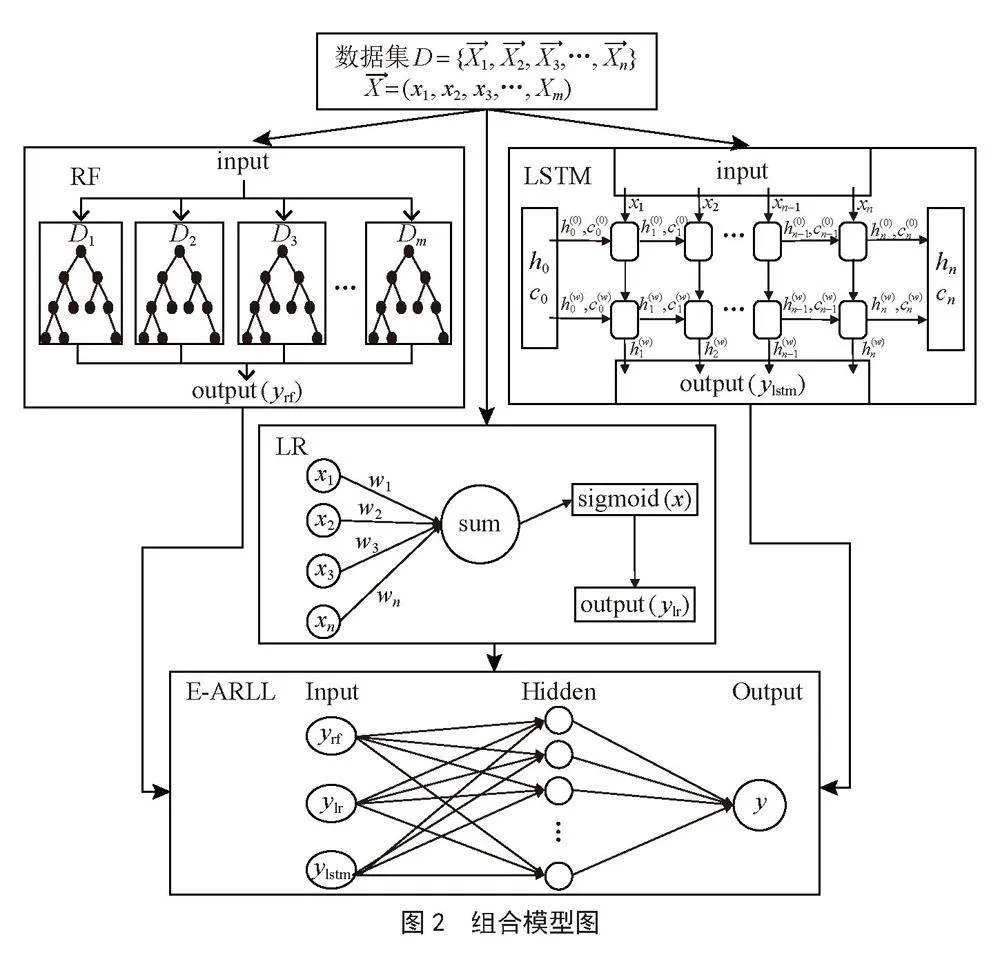
本文提出E-ARLL(Ensemble Method-Artificial Neural Network Integration Logistic Regression, Random Forest and Long Short Term Memory)算法对数据异常进行检测。研究针对三种异常情况将数据集拆分为三个子数据集D1、D2和D3,补贴金额异常为非线性数据集,同时特征较多数据量大,选择随机森林算法处理,能够有着精度高、抗拟合能力强的优点;用餐类型异常为线性数据集,采用逻辑回归算法更大程度的拟合数据;助餐点异常为时序性相关数据集,选取长短期记忆算法挖掘数据中存在的时序信息。将三种算法的预测概率作为人工神经网络算法的输入,在隐藏层对该三维数据映射到高纬空间,再输出新的预测值进行评估,组合模型图如图2所示。
2.1 随机森林分类器
以决策树作为基学习器,在每一轮决策树训练过程中加入随机特征选择,对于每个决策树节点随机选择一个包含k个特征的子集,,k表示整数,然后再选择一个最优划分属性。通过每个特征的信息增益来确定最佳的分裂点。设有R个类Cr,r = (1, 2, 3, …, K), Cr 表示属于类Cr的样本个数,,设特征X有m个不同的取值{x1, x2, x3, …, xm},根据特征X的取值,将D1划分为m个子集D11, D12, D13, …, D1m, Dli 表示Dli个数据集样本的个数,Dir表示记子集Dli中属于Cr的样本集合, Dir 表示Dir的样本个数,信息增益算法如下:
1)计算数据集D1的经验熵H(D1):
(3)
2)计算特征X对数据集D1的经验熵H(D1 A):
(4)
3)计算信息增益:
(5)
不同的特征具有不同的信息增益,信息增益大的特征具有更强的分类能力,如下所示:
(6)
yrf表示RF(Random Forest)算法的预测值,RF表示预测模型。
2.2 逻辑回归分类器
选择sigmoid函数作为激活函数,对D2数据集进行分析,采用随机梯度下降法对随机产生的一个初始值ω0进行不断的迭代,得到最终的ω*,以下是逻辑回归模型:
(7)
(8)
ylr表示LR(Logistic Regression)算法的预测值。
2.3 长短期记忆网络分类器
对D3数据集进行分析,通过输入门、输出门和遗忘门来影响数据模型,最终决定每一个时间点,要忘记多少,记住多少,输出多少,保障核心要素会随着时间不停改变但是又能一直传播下去。
(9)
ylstm表示LSTM(Long Short Term Memory)算法的预测值,LSTM表示预测模型。
2.4 神经网络分类器
神经网络(Artificial Neural Network, ANN)分为输入层(Input Layer)、隐藏层(Hidden Layer)和输出层(Output Layer)。本研究输入层节点为x = [ yrf, ylr, ylstm],经过隐藏层处理,将输出结果表示为:
(10)
其中θ表示节点之间的权重值,y表示预测结果。
2.5 模型评估
设用餐数据集" 表示训练的数据集, 表示对应的标签,其中 ,数据集中包含n个样本,将每条数据表示为 ,每条数据具有m个特征,其中i ∈ [1, m],将一个数据经过不同模型后产生的结果为:
(11)
在本研究中,最终分类的结果会出现以下四种情况:
若yi == 1,则为真正类(True Positive, TP),该类样本数为:
(12)
若yi = 0,= 1,则为假负类(False Negative, FN),该类样本数为:
(13)
若yi = 1,= 0,则为假正类(False Positive, FP),该类样本数为:
(14)
若yi = 0,= 0,则为真负类(True Negative, TN),该类样本数为:
(15)
准确率(Accuracy):准确率是真正类和真负类数量占总样本数的比例,算式表示为:
(16)
召回率(Recall):召回率(也被称为真阳性率或灵敏度)是真正类的数量占实际为正类的比例,算式表示为:
(17)
精确率(Precision):精确率是真正类的数量占所有被预测为正类的比例,算式表示为:
(18)
F1值(F1 Score):F1值是精确度和召回率的调和平均数,同时考虑召回率和精确率两个因素,算式如下:
(19)
ROC(Receiver Operating Characteristic curve):ROC曲线评估模型分类准确率,它显示在不同阈值下的真阳性率(True Positive Rate, TPR)与假阳性率(False Positive Rate, FPR)之间的关系,算式如下:
(20)
(21)
本文目标是找到一个综合评估指标最高的模型,令M表示模型的集合,m表示选择的模型,目标函数为:
(22)
3 仿真实验与结果分析
养老助餐服务切实保障老人的就餐安全及便利,为独居老人提供热乎饭,为社会增添人文关怀。本研究对象为某市助餐点的用餐数据,检测异常数据,为老人提供安全可靠的服务。传统算法进行异常检测只考虑了部分相关特征,不具备完整性,无法对数据集进行全面分析,导致部分异常难以检测出来,本实验对数据集特征,通过不同的相关性进行特征分类,将数据集划分成三个子数据集,对三个子数据集中存在的异常分别进行检测,再运用集成学习的思想,用神经网络对结果再次检测,以获得更好的性能和泛化能力,实验环境如表2所示。
3.1 单异常点检测
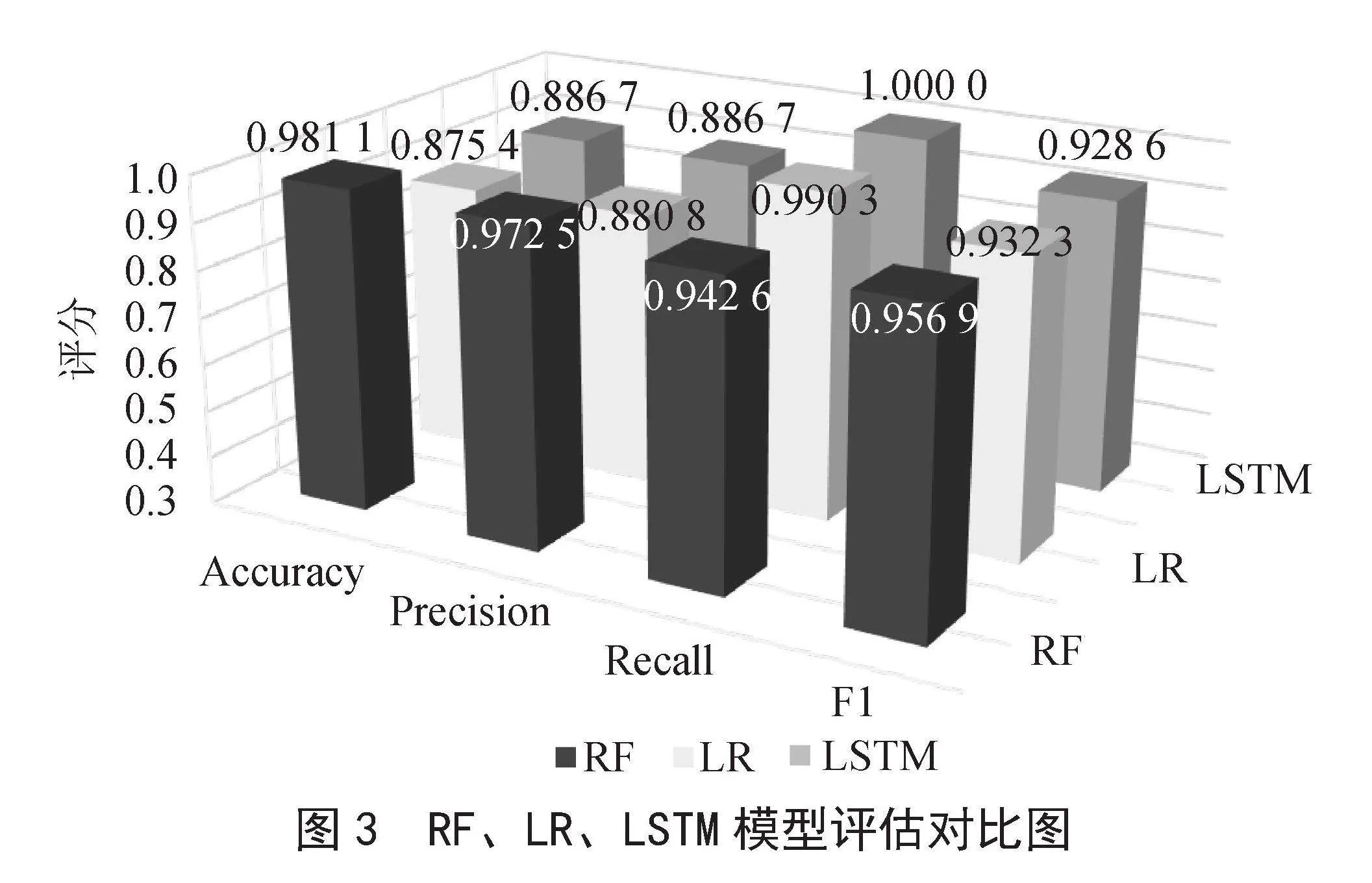
本文通过124个助餐点收集到的大量数据 ,训练适合数据特征的机器学习模型,优化参数提高各个模型的分类准确率,实验结果如图3所示。
图3主要是描述RF、LR和LSTM算法在准确性、召回率、精确率和F1值的性能,RF算法根据六个特征,包括:姓名、类别、用餐类型、创建日期、创建时间和补贴金额。决策树选择10棵,进行预测,结果表明RF算法在负样本(真实样本为负类)的分类上表现较好,但在正类样本(真实样本为正类)的识别上存在问题,可能是因为数据中负样本较少,导致模型将样本预测为多数类(正类),以最大程度提高Accuracy,但是降低了Recall。LR和LSTM算法在正类样本(真实为正类)的识别上表现较好,可能因为模型过于“宽容”对于较多样本都倾向于预测为正类,从而提高Recall。总体数据在预测的F1值上都达到93%以上。
3.2 组合模型对比
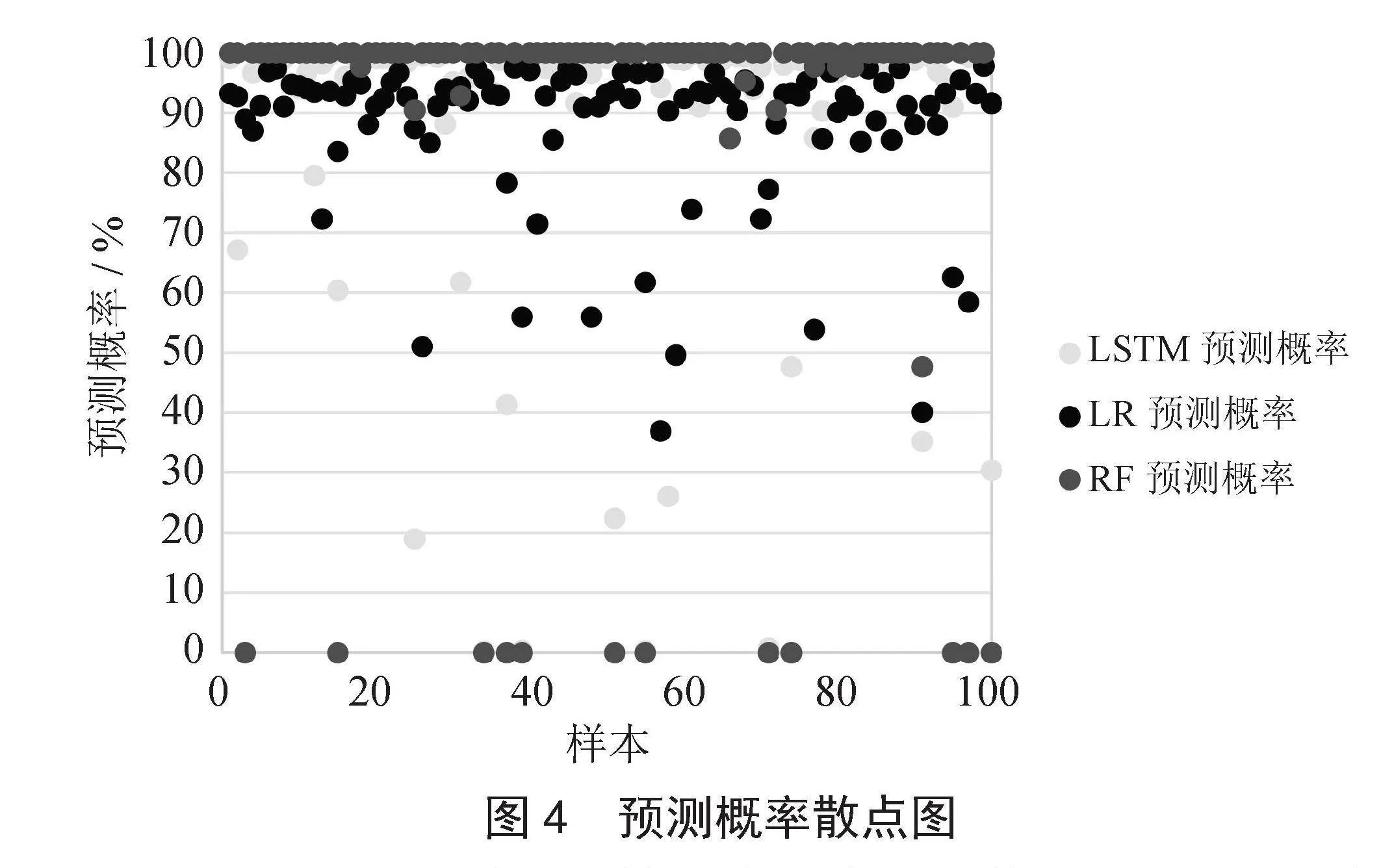
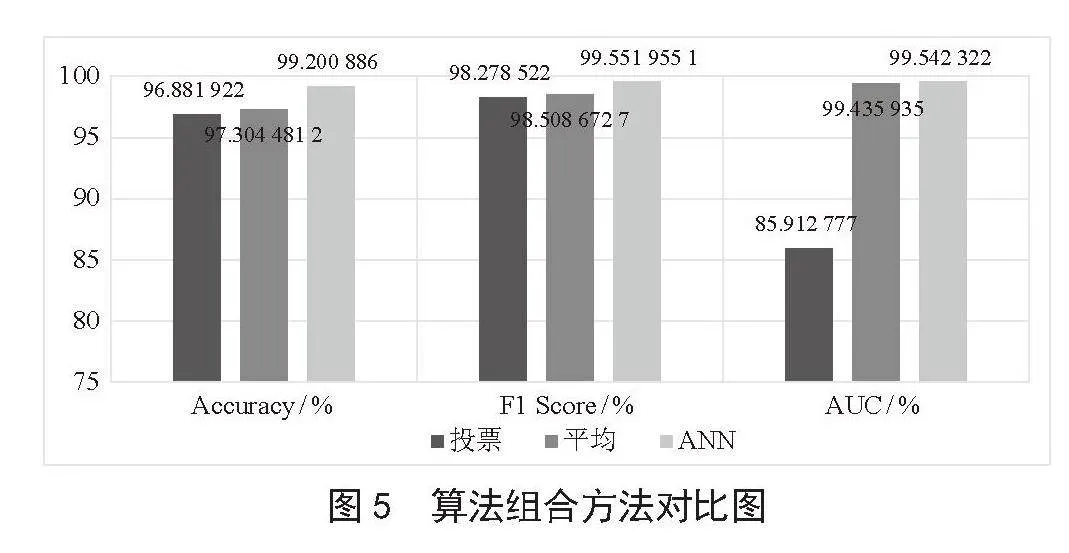
图4为验证数据集前100条数据的三种算法预测概率,可以看出对负类的判别上RF算法检测值更多,LR算法更偏向于将数据判别为正类。本文通过ANN对三种算法的预测概率进行加权平均的方法,不断地调整权重,达到最优的模型分类性能。对比投票和平均的方法分别进行实验检测。
图5主要比较了基于投票、平均和ANN三种算法组合方法在准确性、召回率、精确率、F1值和RUC方面的性能,实验结果表明,采用ANN进行加权平均的方法在本项目中取得了最佳的预测性能,各方面性能都较于另两种方法更优秀,预测F1值高达99.6%,对比投票和平均的方法提高1%,同时由图5看出在ROC曲线中ANN和平均的方法AUC值是相似的,对于分类的预测性能表现较好。实验表明ANN方法对于预测任务具有较好的泛化能力和分类性能。
4 结 论
本文提出了基于某市助餐点收集到的用餐数据,采用集成学习的思路设计一种E-ARLL异常检测模型。所提出的异常检测方法主要分为两个部分,首先采用RF、LR和LSTM对原始数据集进行分析,得到不同特征下对数据分类的预测概率,最后利用ANN对得到的预测概率进行训练,获得最终的预测结果,并计算评估指标,该模型F1值达到99.6%,这个结果表明本文的算法在该数据集上表现出非常出色的分类性能,能够准确地将样本分类为正类和负类,并且能够捕捉到大部分正类样本,同时尽可能地避免将负样本错误地预测为正类,证明了模型的稳健性和优越性。
然而该数据集正负样本不均衡,导致准确率和精确率较低,召回率较高,对于负样本的预测不够准确,后续的研究会针对该方面,采用类别平衡技术、权重调整等方法,提高对负样本的识别率,提高模型的整体效果。在应用该算法到实际应用场景时,还需要对数据和模型进一步验证和优化,以确保该模型的可靠性和稳定性。
参考文献:
[1] 李盈盈,刘奕.智慧养老背景下社区养老服务优化研究 [J].社会科学前沿,2023,12(10):5866-5873.
[2] ZHANG D H,QIAN L Y,MAO B J,et al. A Data-driven Design for Fault Detection of Wind Turbines Using Random Forests and XGBoost [J].IEEE Access,2018,6:21020-21031.
[3] SADAF K,SULTANA J. Intrusion Detection Based on Autoencoder and Isolation Forest in Fog Computing [J].IEEE Access,2020,8:167059-167068.
[4] XU D,WANG Y J,MENG Y L,et al. An Improved Data Anomaly Detection Method Based on Isolation Forest [C]//2017 10th International Symposium on Computational Intelligence and Design (ISCID).Hangzhou:IEEE,2017:287-291.
[5] YU Y,SI X S,HU C H,et al. A Review of Recurrent Neural Networks:LSTM Cells and Network Architectures [J]. Neural computation,2019,31(7):1235-1270.
[6] NABIPOUR M,NAYYERI P,JABANI H,et al. Predicting Stock Market Trends Using Machine Learning and Deep Learning Algorithms Via Continuous and Binary Data;a Comparative Analysis [J].IEEE Access,2020,8:150199-150212.
[7] FAN Y J,XU K K,WU H,et al. Spatiotemporal Modeling for Nonlinear Distributed Thermal Processes Based on KL Decomposition, MLP and LSTM Network [J].IEEE Access,2020,8:25111-25121.
[8] CHIKKAKRISHNA N K,RACHAKONDA P,TALLAM T. Short-Term Traffic Prediction Using Fb-PROPHET and Neural-PROPHET [C]//2022 IEEE Delhi Section Conference (DELCON).New Delhi:IEEE,2022:1-4.
[9] 赵英,翟源伟,陈骏君,等.基于LSTM-Prophet非线性组合的时间序列预测模型 [J].计算机与现代化,2020(9):6-11+18.
[10] NIKRAVESH A Y,AJILA S A,LUNG C-H. Mobile Network Traffic Prediction Using MLP,MLPWD,and SVM [C]//2016 IEEE International Congress on Big Data (BigData Congress).San Francisco:IEEE,2016:402-409.
[11] 董红瑶,申成奥,李丽红.基于邻域容差熵选择集成分类算法 [J].郑州大学学报:理学版,2023,55(6):15-21.
作者简介:胡俊杰(1997—),男,汉族,安徽合肥人,硕士研究生,研究方向:深度学习。
收稿日期:2024-01-23
基金项目:滁州学院校级重点科研项目(2022XJZD09);安徽省高校自然科学研究重大项目(2022AH040149)
Abnormal Detection Method of Pension Meal Service Data Based on E-ARLL Algorithm
HU Junjie, HUANG Meng
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan 232001, China)
Abstract: China is entering an aging society. In order to ensure the three meals a day for the elderly, the government purchases pension meal services in various places. The 1 services, embezzlement, 1ly use and other problems in the service process threaten the property security of government and the elderly, so this paper proposes E-ARLL algorithm to detect abnormal data. This method uses Pearson correlation coefficient and ANOVA to divide the original dataset into the feature training set and the feature verification set, and then the feature training set is input into the E-ARLL algorithm model. Based on the thinking of Ensemble Method, the suitable algorithm is selected for abnormal detection according to the linear relationship of the divided dataset. The experimental results show that the proposed method shows good performance on the abnormal detection of pension meal service data, and the final abnormal data identification rate is 99.4%. It brings new verification methods to the credibility of government purchasing services, which has profound significance.
Keywords: abnormal detection; integrated algorithm; pension service