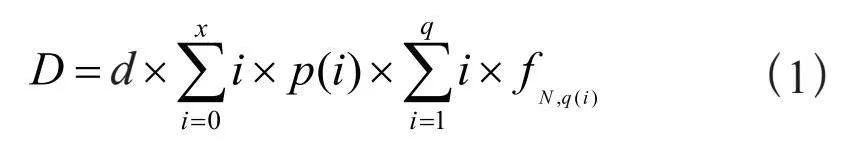
摘 要:近年来,随着数字化和信息化的快速发展,越来越多的人开始使用智能手机。文章基于某公司某年连续21天4万多位智能手机用户的监测数据,通过逻辑回归模型对智能手机用户的监测数据进行挖掘和分析,有效地统计和归纳了用户对于A类APP的使用情况,模型准确度达到了98.06%,同时对于智能手机APP的开发和使用提出了相应的建议。该研究的数据驱动的分析和决策,有助于精准了解用户的行为和需求,可为推荐系统的智能推荐和个性化营销等提供重要的决策依据,有力地促进了我国智能手机市场的持续健康发展。
关键词:智能手机用户;APP;监测数据;逻辑回归
中图分类号:TP311.1;TN929.53 文献标识码:A 文章编号:2096-4706(2024)08-0036-04
DOI:10.19850/j.cnki.2096-4706.2024.08.009
0 引 言
近年来,随着中国创造的不断崛起,中国智能手机发展迅猛,成为全球最大的智能手机市场[1]。与此同时,伴随着在技术创新、产品质量和市场营销等方面所取得的显著进步[2,3],智能手机软件也得到了很好的发展,就目前来讲,智能手机APP涵盖社交、出行、资讯、购物、理财、娱乐、游戏等方方面面,给人们的生活带来了极大的便利和丰富的趣味。研究智能手机用户的监测数据(包括APP的使用情况、点击偏好、停留时间等),有助于精准了解用户的行为、偏好和需求,从而优化产品设计、改进所需服务和制定营销策略,给人们带来更好的体验并提升用户满意度,进一步促进智能手机市场的繁荣发展。
1 问题描述
本研究收集了某公司某年连续21天4万多位智能手机用户的监测数据[4,5],共包含两个数据集:手机使用数据和手机类别数据。对于手机使用数据,每天的数据为1个txt文件,包含uid、appid、app_type、start_day、start_time、end_day、end_time、duration、up_flow和down_flow十列,其中,uid为用户的ID,appid为APP的ID,app_type为APP的类型,start_day为使用起始日期,start_time为使用起始时间,end_day为使用结束日期,end_time为使用结束时间,duration为使用时长,up_flow为上行流量,down_flow为下行流量。对于手机类别数据app_class.csv,其包含appid和app_class两列,其中,appid依然为APP的ID,app_class为APP的所属类别,如社交类、影视类、教育类、出行类等,并采用英文字母A-T来表示,共20个常用的所属类别。
本研究旨在预测用户对A类APP的使用情况,通过分析用户在第1天至第11天对A类APP的使用数据,来预测用户在第12天至第21天是否会继续使用该类APP,并且计算预测结果与真实结果相比的准确率。通过这种方法,更好地理解用户的行为模式和轨迹趋势,为手机APP的未来优化和市场营销提供有力的决策依据和有效建议。
2 问题分析
由于用户在第12天至第21天是否使用A类APP的结果只有使用与不使用两种情况,这是机器学习中典型的二分类问题[6]。因此,本研究使用逻辑回归模型[7]进行问题求解。众所周知,逻辑回归是一种用于解决分类问题的有监督学习算法,其在线性回归模型的基础上,通过Sigmoid函数将回归结果转换为0和1两种类别,在机器学习算法中,其包括数据预处理[8]、模型训练、模型评估和模型预测四个过程[9]。因此在本研究中,第一,对所提供的数据进行预处理,包括重复值检测和处理、缺失值检测和处理、异常值检测和处理、数据离散化等。第二,需要将所提供的第1天至第11天的数据和app_class.csv合并为merged_data1,同时将第12天至第21天的数据和app_class.csv合并为merged_data2。第三,调用sklearn库中的train_test_split函数,将merged_data1划分为训练集和测试集,并调用LogisticRegression模型使训练集进行学习,使用测试集对模型精度进行验证。第四,使用学习后的模型对merged_data2进行预测,并得到是否使用A类APP的预测结果。最后,使用评估分类模型的指标(准确度、精确度、召回率、ROC曲线和混淆矩阵等)对预测结果的性能进行评估。具体来说,基于预测结果和真实监测数据,使用混淆矩阵得到模型在测试集上的预测结果与实际结果之间的对应关系,并计算预测结果和真实结果相比的准确率,同时,可以根据预测结果来计算假阳率(FPR)和真阳率(TPR),并将其绘制成ROC曲线图形进行解读[10]。
3 模型求解
3.1 数据预处理
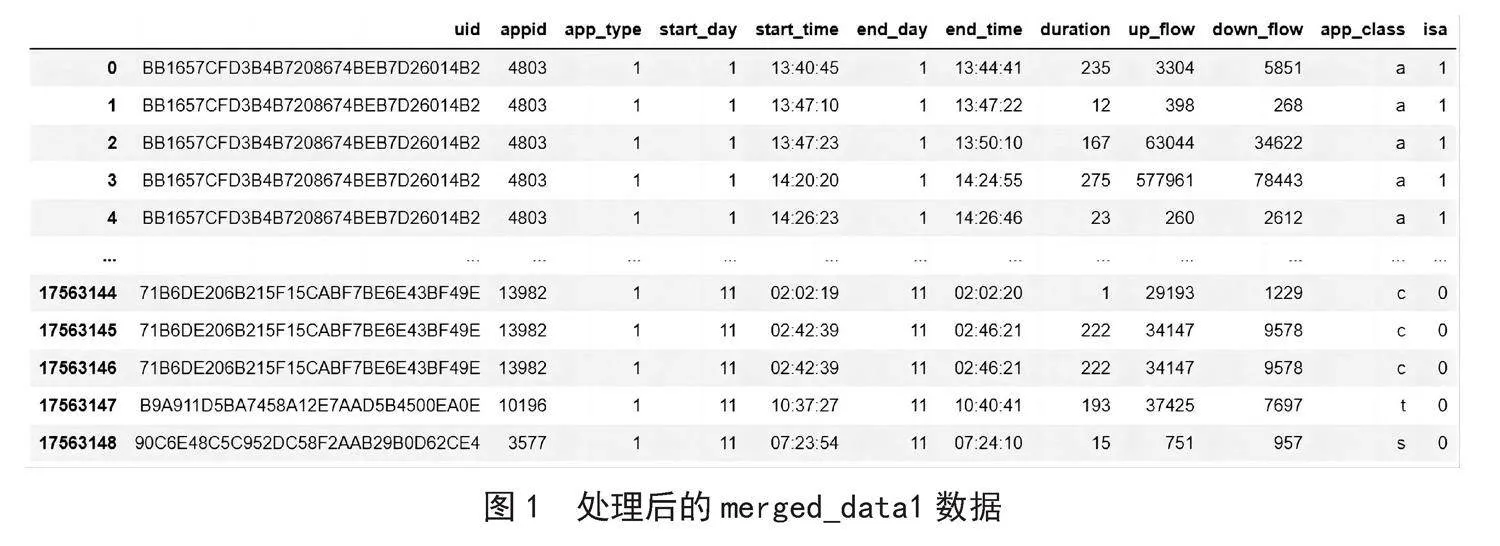
首先,将第1天至第11天的智能手机用户监测数据进行逐一合并,合并后的数据为data1,同时,为每一列添加标题uid、appid、app_type、start_day、start_time、end_day、end_time、duration、up_flow和down_flow。其次,将data1数据的appid列与app_class数据的appid列进行合并,合并后的数据为merged_data1。最后,将app_type里面的用户、usr和sys分别转换成数字1、1和0。分别剔除start_day、duration、up_flow和down_flow中为0的数据,并在data数据最末处新增app_class和isa两列,其中app_class与appid一一对应,isa列用于标记用户是否使用A类APP,如果使用为1,否则为0。具体操作如下:
merged_data1[isa][merged_data1[app_class]==a]=1
merged_data1[isa][merged_data1[app_class]!=a]=0
经过以上处理,得到的数据如图1所示。
与之对应,完成第12天至第21天数据和app_class.csv的合并,合并后的数据为merged_data2。
3.2 模型建立
在问题分析中已经指出,本研究需要通过逻辑回归模型进行问题求解,即导入sklearn中的LogisticRegression模型。具体操作如下:
from sklearn.linear_model import LogisticRegression as LR
Lr=LR( )
在此之前,需要筛选自变量和因变量,根据本研究的问题,筛选appid、app_type、duration、up_flow和down_flow五列作为自变量x,isa列作为因变量y。具体操作如下:
x=merged_data1[[appid,app_type,duration,up_flow,down_flow]]
y=merged_data1[[isa]]
接下来,使用train_test_split函数生成训练集和测试集。具体操作如下:
x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.8)
然后,通过fit方法拟合训练集数据,并通过score方法对测试集数据进行打分。具体操作如下:
lr.fit(x_train,y_train)
lr.score(x_test,y_test)
最后,使用训练后模型的predict方法对merged_data2数据中的待预测数据test_x进行预测,并得到预测结果pre_y。具体操作如下:
test_x=merged_data2[[appid,app_type,duration,
up_flow, down_flow]]
pre_y=lr.predict(test_x)
3.3 模型评估
首先,介绍常见的评估指标。
TP(True Positive):预测为1,实际为1,预测正确。
FP(False Positive):预测为1,实际为0,预测错误。
FN(False Negative):预测为0,实际为1,预测错误。
TN(True Negative):预测为0,实际为0,预测正确。
同时,基于TP、FP、FN和TN得到混淆矩阵,如表1所示。
根据混淆矩阵得到评价分类模型的指标如下:
1)准确率(Accuracy):预测正确的结果占总样本的百分比,计算式为:
(1)
2)召回率(Precision):在实际为正的样本中被预测为正样本的概率,计算式为:
(2)
3)精确率(Recall):在所有预测为正的样本中实际为正样本的概率,计算式为:
(3)
4)F1分数(F1-score):同时考虑精确率和召回率,让两者同时达到最高,取得平衡,计算式为:
(4)
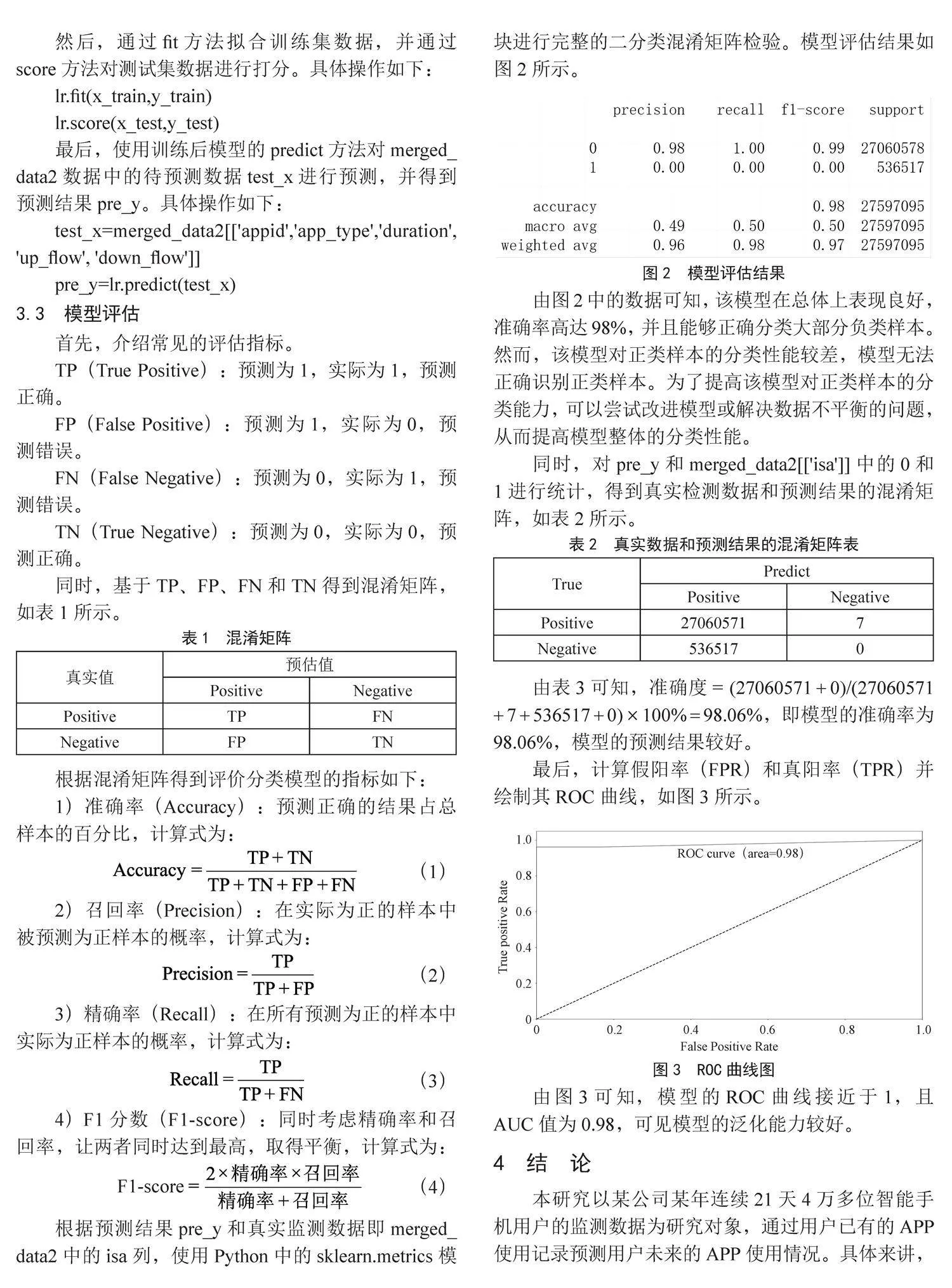
根据预测结果pre_y和真实监测数据即merged_data2中的isa列,使用Python中的sklearn.metrics模块进行完整的二分类混淆矩阵检验。模型评估结果如图2所示。
由图2中的数据可知,该模型在总体上表现良好,准确率高达98%,并且能够正确分类大部分负类样本。然而,该模型对正类样本的分类性能较差,模型无法正确识别正类样本。为了提高该模型对正类样本的分类能力,可以尝试改进模型或解决数据不平衡的问题,从而提高模型整体的分类性能。
同时,对pre_y和merged_data2[[isa]]中的0和1进行统计,得到真实检测数据和预测结果的混淆矩阵,如表2所示。
由表3可知,准确度= (27060571 + 0)/(27060571 + 7 + 536517 + 0)×100% = 98.06%,即模型的准确率为98.06%,模型的预测结果较好。
最后,计算假阳率(FPR)和真阳率(TPR)并绘制其ROC曲线,如图3所示。
由图3可知,模型的ROC曲线接近于1,且AUC值为0.98,可见模型的泛化能力较好。
4 结 论
本研究以某公司某年连续21天4万多位智能手机用户的监测数据为研究对象,通过用户已有的APP使用记录预测用户未来的APP使用情况。具体来讲,通过用户第1天至第11天对A类APP的使用记录数据,预测用户在第12天至第21天是否使用A类APP。由于是否使用A类APP只有使用与不使用两种情况,是一个典型的二分类问题。因此,本研究选用机器学习中的逻辑回归模型,筛选用户在第1天至第11天对A类APP使用记录中的可量化数据进行学习,并根据用户在第12天至第21天的监测数据对其是否使用A类APP进行预测。同时,将预测结果和真实监测数据进行比较,通过计算准确率来评估模型的性能。结果表明,模型预测结果的准确度高达98.06%。
综上,对用户各类APP的使用情况进行精准的分析和预测,不仅能够帮助了解用户的行为和需求,还能为用户画像、推荐系统、个性化营销等提供决策依据。这样的数据驱动决策能够进一步优化用户体验和品牌竞争力,推动我国信息产业的建设和发展。另一方面,通过深入挖掘用户数据,可以更好地了解用户的偏好和习惯,为用户量身定制个性化的服务和推荐,提升用户满意度和忠诚度。与此同时,有效的数据分析和预测也可以帮助企业更好地把握市场趋势,及时调整产品策略和营销策略,增强市场竞争力,实现可持续发展。
参考文献:
[1] 朱祖平,娄小亭,张宇航.数字经济背景下创新驱动发展的路径研究——基于智能手机行业的实证分析 [J].福州大学学报:哲学社会科学版,2023,37(3):39-52+170-171.
[2] 王福祥.创新生态系统视角下华为智能手机技术创新赶超路径研究 [D].哈尔滨:哈尔滨理工大学,2021.
[3] 朱健珣.公司智能手机产品精准营销策略研究 [D].苏州:苏州大学,2022.
[4] 凌宝慧.基于数据挖掘技术的智能手机用户行为分析 [J].科技信息,2012(36):306.
[5] 刘新帅,林强,曹永春,等.基于智能手机使用数据的用户行为提取与分析 [J].西北民族大学学报:自然科学版,2019,40(3):26-33+43.
[6] 代雯月,王玲玲.基于分类技术的信用评分模型研究 [J].自动化应用,2023,64(12):180-183.
[7] 张侠.基于SVM和逻辑回归的糖尿病数据分析与研究 [J].沧州师范学院学报,2023,39(1):19-23+84.
[8] 李小聪.基于机器学习的数据预处理框架研究 [J].中国信息化,2023(7):67-68.
[9] 阿布,胥嘉幸.机器学习之路 [M].北京:电子工业出版社,2017.
[10] 潘锡龙,陈丽,梁利斯.基于Logistic回归和ROC曲线评价外周血PCT,CRP,NEU%和PLT水平在血流感染中的联合预测价值 [J].现代检验医学杂志,2020,35(6):119-124.
作者简介:戴道成(1995.08—),男,汉族,陕西西安人,讲师,硕士研究生,研究方向:数据挖掘和机器学习;于琛洋(2003.08—),女,汉族,陕西咸阳人,本科在读,研究方向:数据分析;宋吉昊(2003.03—),男,汉族,陕西宝鸡人,本科在读,研究方向:数据分析;郭小亮(2007.06—),男,汉族,河南南阳人,本科在读,研究方向:数据分析。
收稿日期:2023-10-16
Analysis of Smartphone User Monitoring Data Based on Logistic Regression
DAI Daocheng, YU Chenyang, SONG Jihao, GUO Xiaoliang
(School of Finance and Data Science, Xian Eurasia University, Xian 710065, China)
Abstract: In recent years, with the rapid development of digitization and informatization, more and more people have started to use smartphones. This article is based on the monitoring data of over 40000 smartphone users in a certain company for 21 consecutive days in a certain year. By using a logistic regression model to mine and analyze the monitoring data of smartphone users, the usage of Class A apps by users is effectively calculated and summarized. The accuracy of the model reaches 98.06%, and corresponding suggestions are proposed for the development and use of smartphone apps. The data-driven analysis and decision-making in this study contribute to a precise understanding of user behavior and needs, providing important decision-making basis for intelligent recommendations and personalized marketing in recommendation systems, and effectively promoting the sustained and healthy development of Chinas smartphone market.
Keywords: smartphone user; APP; monitoring data; logistic regression