
摘 要:为实现全面准确地评估个人信贷风险,首先,研究了借贷人的各项个人信息指标在信用风险评估中的重要性;接着,基于Python编程语言采用XGBoost集成学习方法搭建了一套个人贷款信用评估模型;随后,结合SHAP方法筛选出合理的信用评估指标,完善了评估模型;最后,基于LabVIEW平台开发个人贷款信用评估系统。研究结果表明:最终筛选的指标能更有效地评估个人信贷风险,可以为金融行业提供一个更有效的个人信贷风险评估系统。
关键词:信贷风险;XGBoost算法;SHAP;信用评估;Python
中图分类号:TP39;TP181 文献标识码:A 文章编号:2096-4706(2024)08-0146-06
DOI:10.19850/j.cnki.2096-4706.2024.08.032
0 引 言
随着我国经济的快速发展和国民超前消费理念的产生,个人贷款成为人民日常生活中的一个重要组成部分,涵盖了个人购房贷款、个人汽车贷款、个人助学贷款、个人留学贷款、个人消费贷款、个人经营贷款等。银行或金融服务公司在决策客户个人贷款时,涉及两类风险:一是客户有偿还贷款的能力,不批准贷款将导致业务丢失;二是客户无偿还贷款的能力,批准贷款则有可能客户违约导致经济损失。截至2020年第三季度末,全国银行卡授信总额达18.59万亿,授信使用率达41.78%,信用卡逾期半年未偿信贷总额达906.63亿元,占信用卡应偿信贷余额的1.17% [1]。原有的个人信贷风险评估系统已经无法满足现阶段金融行业的需求,金融机构为了增加收益,在开发金融产品的同时,也需要使用科学、严谨的分析方法进行个人信用评估,避免带来不可估量的经济损失。因此,构建一个更加全面的风险评估系统对信用贷款市场的发展具有重要的意义。
随机森林、神经网络、支持向量机和XGBoost模型等是目前个人信用贷款风险评估中最常用的统计学习模型[2,3]。李奕蒙[4]对银行个人贷款信用风险的相关问题进行了分析研究,为了提高个人信贷风险的预测率,构建了BP神经网络模型,采用遗传算法对神经网络进行了优化。严亦宽等[5]采用决策树、人工神经网络、支持向量机这三类非线性算法对企业信用评级调整情况进行数据挖掘,构建的模型具有很高的预测准确率。张丽颖等[6]采用机器学习的方法构建个人贷款违约预测模型,采用Stacking方式综合利用随机森林、XGBoost和K近邻模型的优点,提高模型预测的效果。周永圣等[7]采用改进的随机森林模型评估个人信用风险,通过优化特征选择从而降低指标维数,最终提高了分类准确率。
综上分析可知,关于个人信贷风险预测的模型研究日益丰富,但现有的评估模型已经不能满足目前信贷市场的需求。尽管收集更多的个人信息有利于提高个人信用评估的准确性,但给客户带来了很多不便,加重了授信审批人员信息核实的工作量,因此,设计基于XGBoost和SHAP方法的个人贷款信用评估模型是极其必要和重要的。
1 基础理论
1.1 XGBoost集成学习方法
XGBoost全称是极度提升树(eXtreme Gradient Boosting)是一种高效的Boosting集成学习模型框架,它通过集成多个基学习器形成一个强学习器,得到强大的预测结果和十分高效的运算效率。近年来,XGBoost因其学习效果好,训练速度快而受到了广泛的关注。本文仅对基于分类决策树的XGBoost集成算法展开讨论。
XGBoost的基本思想是:
1)许多弱分类器的组合就是一个强分类器,最终预测值为所有决策树预测值的加权和。
2)不断在错误中学习,用迭代来降低犯错的概率。
XGBoost模型由目标函数、分类回归树、梯度提升和预测函数组成[8]。
目标函数的公式是:
(1)
式中: 为所有基分类器中的损失函数之和; 为预测值" 和真实值nbsp; 之间的误差。
(2)
式中:Ω( f )为模型的正则化项,用来降低模型的过拟合问题和复杂度;T为叶子子节点的个数;λ为惩罚的力度;w为叶子节点的输出分数;1/2 为w的L2模平方。
若模型的目标函数越小,则模型的预测效果就越好。
XGBoost的基分类器是分类回归树,即CART。XGBoost算法是利用一种加法模型将CART组合起来,每一棵CART的建立都会拟合上一棵CART预测的误差。所以,随着CART的添加,基本分类器的损失函数也会逐渐地降低。
提升过程方面,迭代表达式如式(3):
(3)
将式(3)近似地用二阶泰勒展开为式(4):
(4)
式中:gi为一阶导;hi为二阶导。
通过消除常数项 ,得到t迭代的简化目标方程为:
(5)
定义" 为叶子节点j的样本集合,将正则项扩展为:
(6)
定义 ,,式(6)可以化简为:
(7)
在上述式子中,每一个wj是相互独立的,那么针对一元二次方程 1/2 而言,当新增的这棵树的结构q(x)已知的情况下,目标函数最小值下的wj:
(8)
将" 代入式(7)可得:
(9)
式(9)是t次循环迭代后的最优目标函数值。所以树结构q的评分函数是:
(10)
XGBoost的预测函数是:
(11)
式中:fk(xi)为样本xi来自第k个基本分类器的输出值; 为K个基本分类器给出的样本xi的输出值之和。
1.2 SHAP解释XGBoost模型
为了进一步明确各指标相对于目标变量的正/负关系,需使用一种方法对XGBoost模型进行解释分析。SHAP(Shapley Additive Explanations)解释法是Lundberg等人[9]提出的一种机器学习模型解释方法。SHAP具备输出结果的可加一致性,对于每个预测样本,模型都出现一个预测值,SHAP值是该样本中每个特征所分配到的数值,其中SHAP值是Shapley [10]基于合作博弈理论首次提出的。
假设第i个样本为xi,第i个样本的第j个特征为xij,模型对第i个样本的预测值为yi,所有样本预测均值为ybase,那么xij的SHAP值服从以下等式:
(12)
式中:f (xi, j)为xij的SHAP值。这一特质确保了贡献值的加和等于最终输出,使得这种解释方法消除了各个模型间结构差异带来的解释性差异。
不同于以往的线性模型使用参数的大小或正负衡量某一指标对于模型的贡献,SHAP方法将每个样本的指标组合贡献通过SHAP值计算出来,可以反映出每个样本中的特征的影响力,同时还能表现出该特征影响的正负性。当SHAP值小于零时,表示该特征使得预测值降低,有负向作用;当SHAP值大于零时,表示该特征使得预测值升高,有正向作用。若SHAP值的绝对值越大,说明其对结果的影响越大。
通过SHAP方法最终将会得到在每个样本中各个指标的贡献度SHAP值,从而反映出该指标在模型中的重要性,如果某指标在大多数样本上表现出了一致的趋势,那么说明模型认定这一指标具有重要的正向或者负向作用,因此,可以利用SHAP方法来解释XGBoost模型中各指标对结果作用的正负性及大小。
2 个人信贷风险评估系统的构建
2.1 系统构成
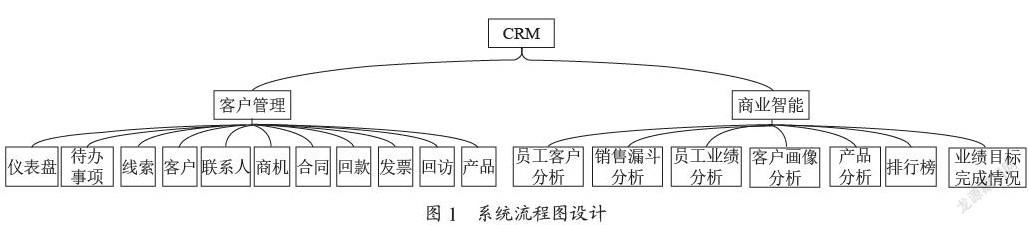
该个人贷款信用风险评估系统是基于LabVIEW平台开发的,分为服务器端和客户端系统。其中服务器端系统主要通过基于XGBoost集成学习方法结合SHAP的Python编程语言来实现个人贷款信用风险评估模型的训练、更新和评估;客户端系统主要分为四大模块:用户管理模块、信用风险评估模块、风险预警管理模块、客户风险跟踪模块,具体内容如下:
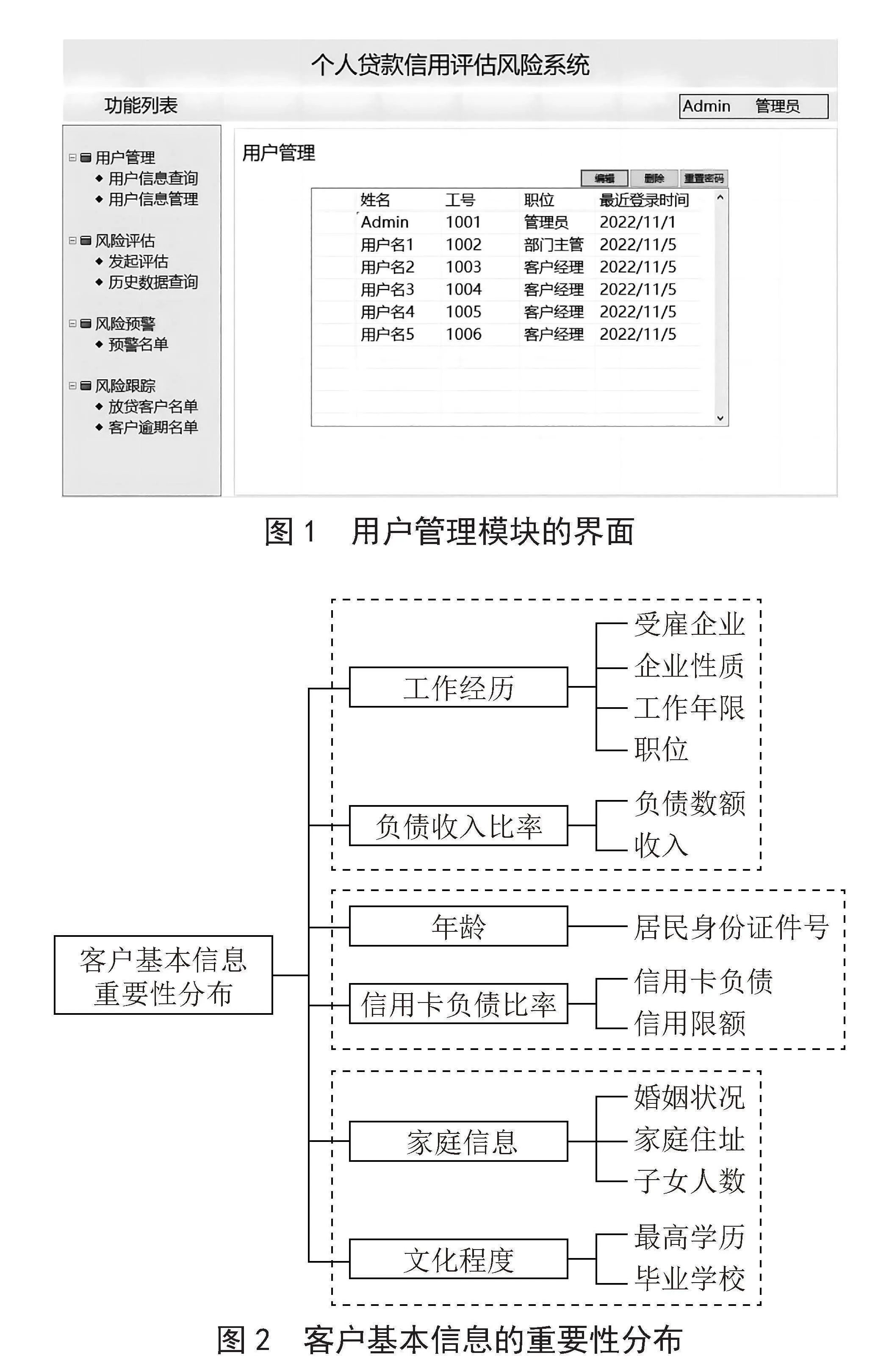
1)用户管理模块。该模块主要包括对用户信息的查询、修改和权限设置。用户的角色分为三种:管理员、客户经理和部门主管。管理员具有查询、编辑、删除用户的权限;客户经理具有发起信用风险评估、维护和查看自己名下客户信息、跟踪已发放贷款客户信用情况的权限;部门主管具有查看所有客户经理信息和查看所有客户信用评估的权限,用户管理模块的某一界面(用户信息由管理员导入)如图1所示。
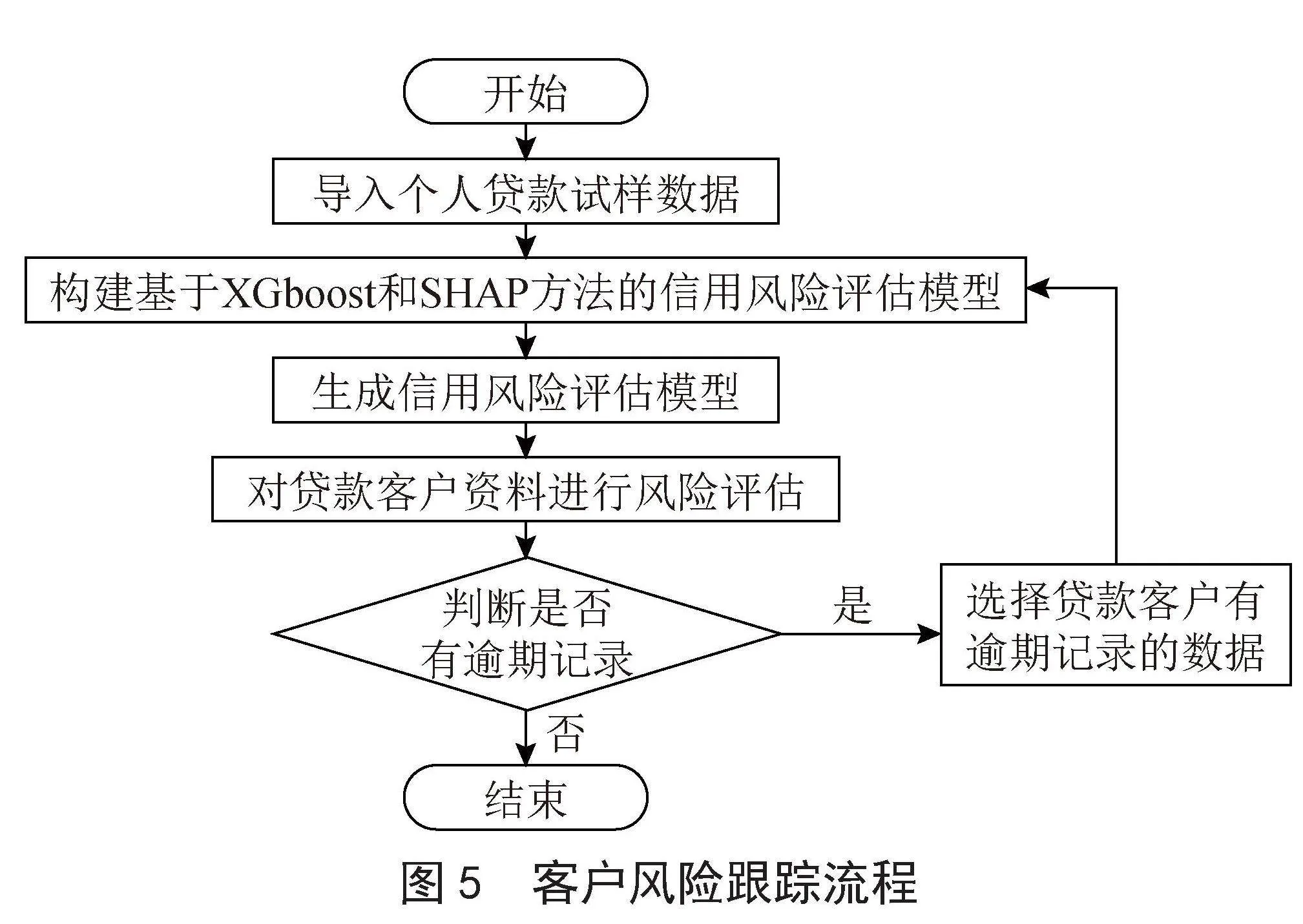
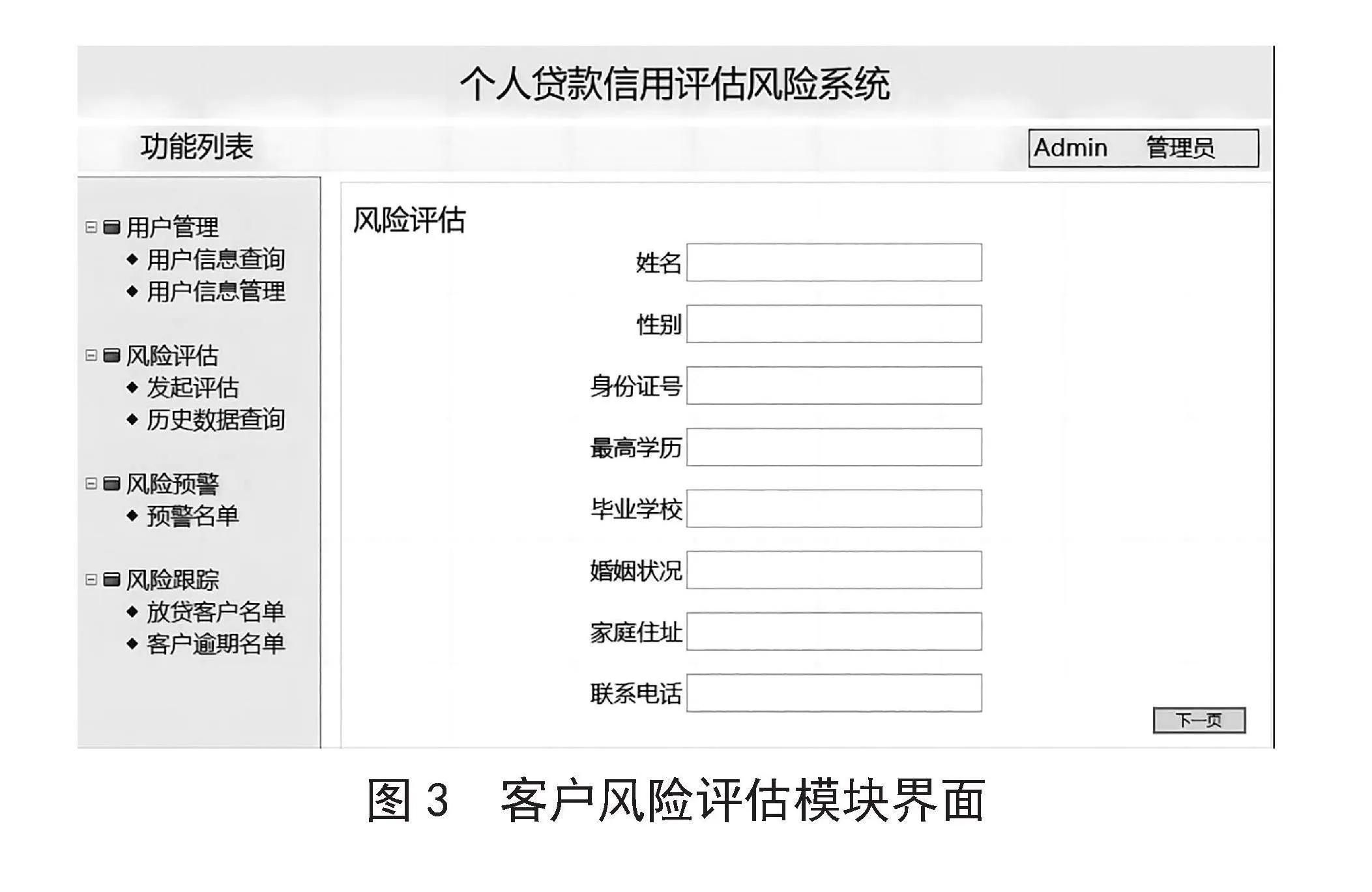
2)信用风险评估模块。信用风险评估模块主要包含发起风险评估和历史评估数据查询功能。发起风险评估功能会根据录入的客户基本信息,结合训练好的基于XGBoost和SHAP的个人贷款风险评估模型,对客户风险进行评估,最终优化后的客户基本信息重要性分布如图2所示。
客户信息按照重要性分成三级,其中最重要的第一级有工作经历和负债收入比率信息;第二级有年龄和信用卡负债率信息;第三级有家庭信息和受教育程度等信息。综合这些客户信息的重要程度,客户经理在人工核实信息时,可以知道哪些信息是起决定性作用的,避免重要信息的遗漏。
进入风险评估模块,点击发起评估功能,按照相应操作准确填写相关客户基本信息,系统便会对客户风险进行评估,客户风险评估模块的某一界面如图3所示。
3)风险预警管理模块。风险预警管理模块主要针对已放贷客户,客户经理在客户信息有变化后,重新对其进行风险评估,筛选出可能有风险的客户,客户经理可以重点跟踪并给出贷款还款提醒,模块界面如图4所示。
4)客户风险跟踪模块。该模块主要针对已放款客户,在有逾期记录时,及时维护和更新该客户的数据,并将该数据作为新的已打标签的测试样本。这样定期更新风险评估系统,有助于提高评估系统的准确度,流程如图5所示。
打开风险跟踪模块,即可快速查看客户的最新数据,该模块含有放贷客户名单和客户逾期名单两个功能,客户风险跟踪模块某一界面图如图6所示。
综上所述:个人贷款信用评估风险系统能通过借贷人的主要信息指标来预测客户的借贷风险,能随时跟踪更新客户的个人信息,提高系统的评估准确度,大大减少了银行授信审批人员的信息核实工作量,降低了银行借贷风险,同时也可以避免客户出现违约的情况。
2.2 基于XGBoost和SHAP的风险评估模型
为了测试模型预测结果的准确性,对评估模型进行了训练测试,实验训练模型的数据来源于Kaggle机器学习竞赛中的发放银行贷款的信用风险分析数据集。该数据集共有1 150条客户数据。包含客户年龄、教育水平、工作经历、客户住址、客户年收入、负债收入比率、信用卡负债率、其他债务和历史违约记录。
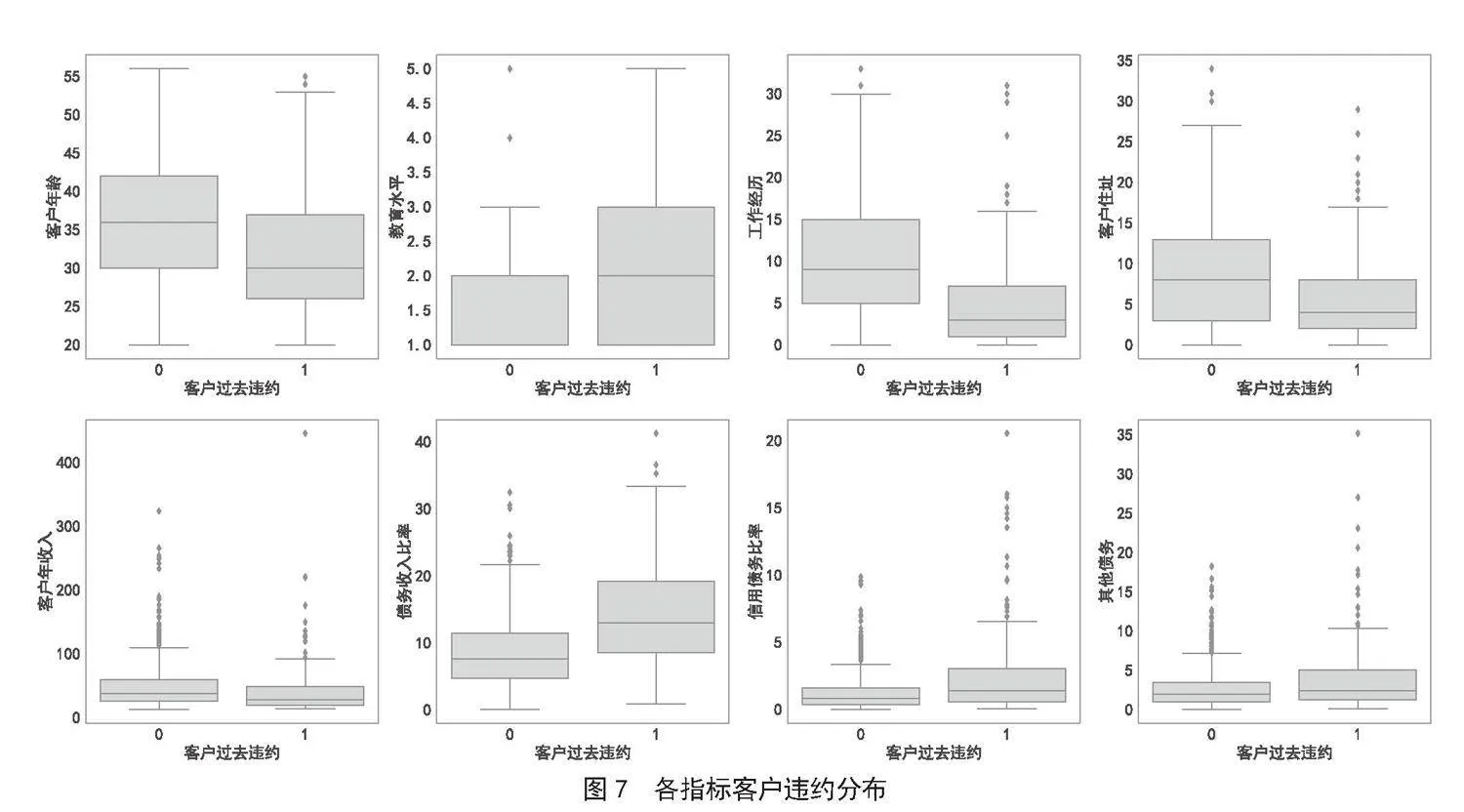
根据训练样本中的数据整理出各指标中客户是否违约的分布情况,其中0表示未违约,1表示违约,各项指标的违约分布情况如图7所示。
从图7中可以看出,未违约与违约两种情况下,每一项指标都存在比较多的交叉区域,难以从单一指标去判断是否违约。但是可以从中找到一些分布规律,例如,年龄小的客户违约的可能性更大,银行在贷款授信审批时应该更加警惕;债务收入比率高的客户违约的可能性明显偏大,银行应对这类客户重点关注;工作年限长的客户违约的可能性更小,银行可以对这类客户给予充足的信任。
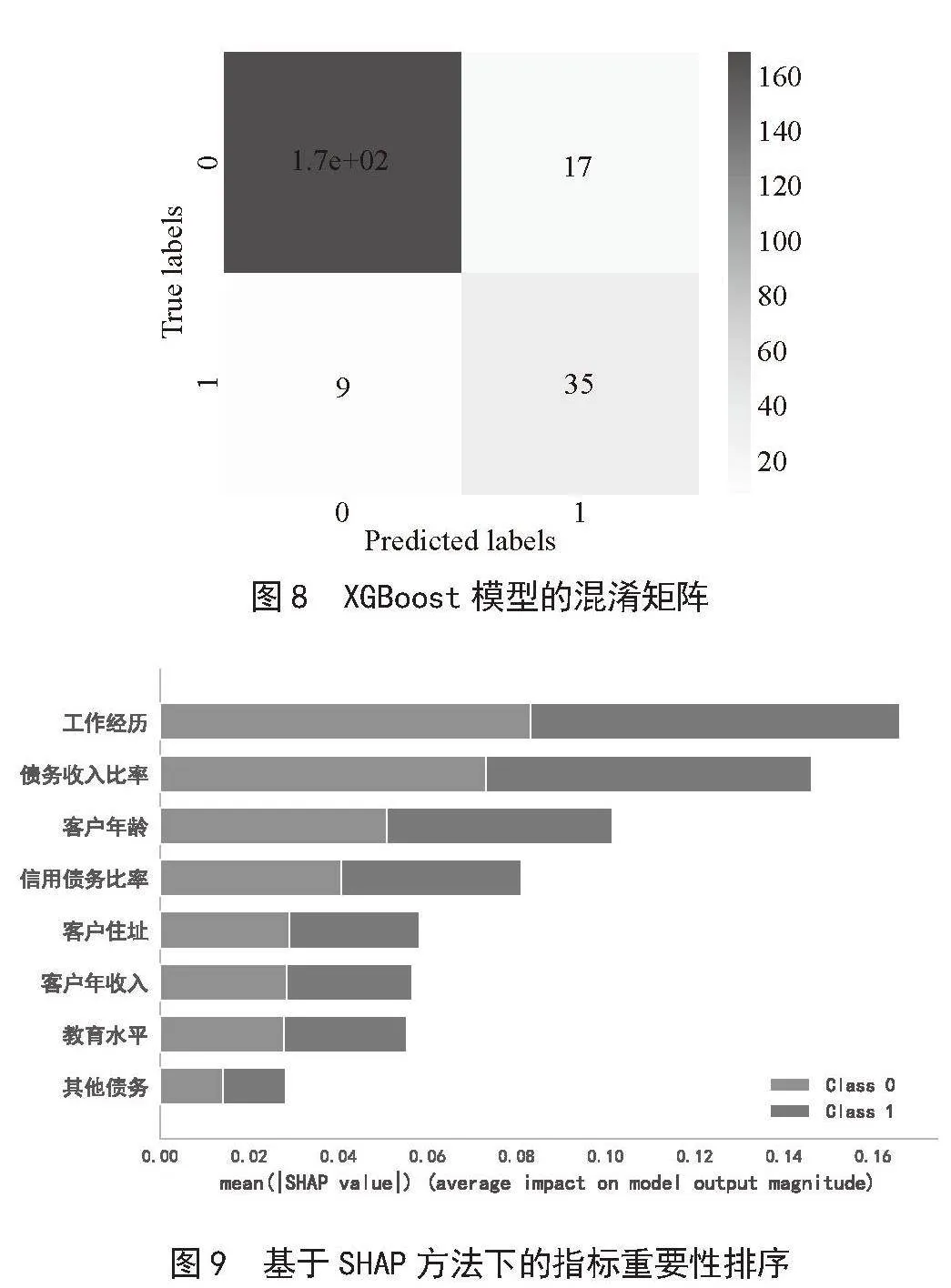
分析了客户违约分布情况,现将利用该数据对模型进行训练测试,从数据集中随机选择920条数据作为训练样本,230条数据作为测试样本,XGBoost模型的混淆矩阵如图8所示,基于SHAP方法下的指标重要性排序如图9所示。
由图8的混淆矩阵可知,检测样本为230个时,预测正确的个数为204个,预测准确度为88.7%,预测精度较好。但由于神经网络训练时需要较多样本,而测试时训练数据存在限制,所以精度不是很高,若数据量增加会使预测正确率有一定的上升。
图9的指标重要性排序可以发现,工作经历对违约情况预测的重要性最大,可以大致将客户信息按照重要性分成三级,其中最重要的第一级有工作经历和负债收入比率信息;第二级有年龄和信用卡负债率信息;第三级有家庭信息和受教育程度等信息。根据这些指标的分级情况。客户经理在采集客户信息时可以从以下两个方面优化工作:
1)重点关注第一级和第二级信息的真实性。
2)由于债务收入比、年龄、信用卡负债率、家庭信息和受教育程度比较容易量化,而工作经历的量化可以从个人和单位多维度进行评价,从而确保强相关指标评价的合理性。
3 结 论
针对银行和金融服务行业在发放客户个人贷款时会遇到的各种风险,深入研究客户个人贷款信用风险评估的影响因素指标,构建了较为全面的个人贷款信用风险评估系统。该系统运用XGBoost和SHAP方法,利用银行贷款的信用风险分析数据集来实现个人贷款信用风险评估模型的训练、更新和评估。该评估系统主要分为四大模块:用户管理模块、信用风险评估模块、风险预警管理模块、客户风险跟踪模块。该系统是一个动态的跟踪系统,可以记录客户的基本个人信息,同时还能及时更新客户贷款信息,从而快速准确地跟踪出具有信贷风险的客户名单,更为严谨地评估了客户的个人信贷风险,让银行管理者及时了解到自己客户的最新信息,避免客户出现违约的情况,降低信贷风险。
根据以上分析,得到启示:
1)针对所选样本数据集对模型进行测试,得到了较为准确的预测结果,有力地验证了评估系统的有效性与合理性。
2)构建的个人贷款信用风险评估模型可以帮助银行管理者根据自己客户所处的不同信用风险级别是否存在违约风险,及时、有效地制定解决方案,有利于降低个人贷款风险。
3)进一步丰富了征信建设,提高了银行的业务效率,保持了风险和效益的平衡发展,提高贷款的经济效益,对整个信贷行业的发展具有重要意义。
参考文献:
[1] MARQUÉS A I,GARCÍA V,SÁNCHEZ J S,et al. A Literature Review on the Application of Evolutionary Computing to Credit Scoring [J].Journal of the Operational Research Society,2013,64(9):1384-1399.
[2] NISHA A,DEEP KAUR P. A Bolasso Based Consistent Feature Selection Enabled Random Forest Classification Algorithm: An Application to Credit Risk Assessment [J].Applied Soft Computing,2020,86:1-15.
[3] 逯瑶瑶.基于机器学习分类算法的贷款违约预测研究 [D].兰州:兰州大学,2021.
[4] 李奕蒙.基于神经网络的中小商业银行个人贷款违约风险研究 [D].成都:西南财经大学,2019.
[5] 严亦宽,薛巍立.基于机器学习的信用评级调整研究 [J].南大商学评论,2018(3):88-100.
[6] 张丽颖,杨若瑾.基于机器学习的个人贷款违约预测模型的应用研究 [J].金融监管研究,2022(6):46-59.
[7] 周永圣,崔佳丽,周琳云,等.基于改进的随机森林模型的个人信用风险评估研究 [J].征信,2020,38(1):28-32.
[8] 牛彩芳.基于XGBoost算法的信用评级系统设计与实现 [D].武汉:中南财经政法大学,2020.
[9] LUNDBERG S,LEE S-I. A Unified Approach to Interpreting Model Predictions [J/OL].arXiv:1705.07874 [cs.AI].(2017-05-22).https://arxiv.org/abs/1705.07874.
[10] SHAPLEY L S. A Value for N-person Games [J].Technical Report, Santa Monica: Rand Corporation,1952,295:1-13.
作者简介:伍洁(2003—),女,汉族,湖北黄冈人,本科在读,研究方向:金融数学;通讯作者:陈迪芳(1986—),女,汉族,湖北十堰人,副教授,博士,研究方向:金融统计、数字经济与绿色金融;李瑞彤(2003—),女,汉族,湖北荆州人,本科在读,研究方向:金融数学;石景阳(2003—),男,汉族,湖北随州人,本科在读,研究方向:金融数学。
收稿日期:2023-08-19
基金项目:湖北省大学生创新创业训练计划项目(S202210525055);教育部产学合作协同育人项目(202101087049);湖北省大学生创新创业训练计划项目(S202210525056)
Research on the Personal Credit Risk Assessment Based on XGBoost and SHAP Methods
WU Jie, CHEN Difang, LI Ruitong, SHI Jingyang
(School of Mathematics, Physics and Optoelectronic Engineering, Hubei University of Automotive Technology, Shiyan 442002, China)
Abstract: To achieve a comprehensive and accurate assessment of personal credit risk, firstly, the importance of various personal information indicators of borrowers in credit risk assessment is studied. Next, based on Python programming language and XGBoost integrated learning method, a personal loan credit assessment model is constructed. Subsequently, reasonable credit assessment indicators are selected by using the SHAP method to improve the assessment model. Finally, it develops a personal loan credit evaluation system based on the LabVIEW platform. The research results indicate that the final selected indicators can more effectively evaluate personal credit risk, and can provide a more effective personal credit risk assessment system for the financial industry.
Keywords: credit risk; XGBoost algorithm; SHAP; credit evaluation; Python