
摘" 要:在对话系统中,对话情感识别旨在预测对话中每个语句的情感标签,这个任务受多种因素的影响,如对话的主题、情感标签信息等。为了解决上述问题,提出了一个新的主题标签感知的图网络(TLGN)框架。该模型首先利用主题模型提取与情感相关的语义主题分布和学习标签指导的文本表示。然后,融合两种不同粒度的表示,作为文本的语义输入,输入到分类模型中,进行对话语句的情感预测。最后,在四个公开数据集上的实验结果表明,该模型的方法优于基准方法。
关键词:主题模型;对话系统;情感分类;标签指导
中图分类号:TP391" 文献标识码:A" 文章编号:2096-4706(2024)11-0016-06
Dialogue Emotional Recognition Based on Comparative Topic Model and Label Guidance
ZHU Ling
(Chongqing Vocational Institute of Safety and Technology, Chongqing" 404020, China)
Abstract: In a dialogue system, dialogue emotion recognition aims to predict the emotional labels for each statement in a conversation. This task is influenced by various factors such as the topic of the dialogue, emotional label information and so on. To address this issue, a new framework called Topic-aware Label Graph Network (TLGN) has been proposed. This model uses topic model to extract semantic topic distributions related to emotions and learns label-guided text representations firstly. Then, it fuses two representations of different granularity, used as semantic input to the text and input into the classification model for emotional prediction of dialogue statements. Finally, experimental results on four publicly available datasets show that the model method outperforms the benchmark methods.
Keywords: topic model; dialogue system; emotional classification; label guidance
0" 引" 言
情感识别一直是自然语言处理中一个重要而有挑战性的研究课题。而对话情感识别作为人们日常生活的主要交流方式之一,回话里传递着说话者的需求、情感等,因此使用人工智能去理解、识别对话是非常有必要的。近几年,随着智能对话机器人的引入,对话情感识别(ERC)也持续得到各大学者的关注,简而言之,ERC就是识别对话中每句话的情感,在客户系统[1]、社交媒体分析[2]、心理健康辅助[3]等方面都有应用。
对话系统是一个多轮交互的过程,在每个对话阶段中,情感的表达可能会受到上下文的影响。因此,准确理解对话中的上下文信息,包括对话历史和当前对话回合的内容,是对话情感识别的关键挑战之一[4,5]。同时情感表达往往不仅仅依赖于直接表述的词语或短语,还会涉及隐含信息、语调、语速、肢体语言等非语言性的特征。理解这些隐含信息和非语言性的特征对于准确识别对话情感至关重要,但也是一个难点。情感是一个复杂和主观的概念,不同的人在不同的语境下可能对同一情感有不同的表达方式。因此,对话情感识别需要考虑到情感的多样性和主观性,既要能够捕捉情感的普遍模式,也要适应个体差异和特殊情况。
早期基于深度学习的对话情感识别模型主要是基于循环神经网络(Recurrent Neural Networks, RNN [4,5])模型。这些工作将对话里的每句话语视为一个整体,将一个对话视为一个上下文序列,充分利用了对话中语境的信息,并通过注意力机制去关注对情感有贡献的关键句子,以提高对话情感的分类性能。随着图神经网络的兴起,引入了结构信息增强文本的表示,具体而言,将每个话语视为一个节点,一个对话视为一个图,通过图卷积网络去学习文本的结构表示。
虽然这些工作取得了显著的成效,但是却没有考虑对话的主题信息,不同的主题氛围带给人的情感倾向会不一样,比如“春节”和“葬礼”。除此之外,没有考虑到说话者的情感稳定性,对于大多数人来说,在一段对话里的情感不会浮动太大。最后,由于有些情感标签描述存在相似性,如“愤怒”和“厌恶”,因此,生成一个情感标签描述去指导话语表示有助于提高识别的准确性。
针对以上不足,构建了一个主题模型和标签指导的多粒度对话情感识别模型,利用主题模型分析对话的上下文语义,以及标签指导表示学习语句含义的表示,并将二者表示拼接后输入到分类模型中,以提升对话情感识别的效果。主题模型从全局观点分析对话主题,表示模块编码语句语义,分类器组合二者进行情感判断。在四个公开的数据集上进行的实验表明,与只使用单一模块相比,多模块融合框架具有显著优势,提高了F1。这表明了主题表示和标签指导的表示学习融合能提升对话理解力,主要贡献在于:
1)构建了基于主题模型和标签指导的多粒度对话情感识别模型。
2)设计了新的对话情感识别框架。
3)在四个公开的数据集上进行的实验验证了其有效性。
1" 方法介绍
1.1" 问题定义
给定一个由N个语句组成的对话U,U = {u1, u2, …, uN},其中N表示语句的数量。对于每个语句,原始输入是一个单词序列,即ui={wi,1, wi,2, …, wi,n},其中n表示语句的长度。 表示对话U对应的情感标签序列,其中" 表示语句ui的情感标签,γs表示情感标签集。模型的目标是根据对话的上下文信息及说话者信息从预先定义的情绪标签集合中预测每个语句的情绪标签,模型图如图1所示。
1.2" 对话语句编码层
在这一节里,通过对比主题模型提取了每个对话的主题表示,通过RoBERTa模型得到了上下文无关的句子级别的特征向量表示,通过标签指导模型为每个情感标签生成了描述,并得到了情感标签的特征表示。
1.2.1" 对比主题模型
这里通过对数据集的统计,发现同一对话内的情感氛围会尽可能的一致(统计一个数据表出来),比如说谈到春节这个主题,大多数的情感是偏向正向的,因此这里把主题建模进来,更好地学习每个对话的表示。传统的神经主题模型在训练过程中使用了大量无标签的文本数据,但其效果往往受到训练样本质量和数量的限制。对比学习可以通过从无标签数据中学习到的相似性信息来提高模型的性能。具体而言,Nguyen等人[6]提出了一种改进的神经主题模型训练框架,其中使用对比学习来学习用于话题建模的表示。该方法通过将同一篇文档中的不同片段进行对比,使得模型能够捕捉到文档的多样性和丰富的话题信息。通过最大化相似片段的相似性,同时最小化不同片段的相似性,模型可以更好地区分文档中的话题,并生成更准确的主题表示,这里得到的是每个对话的主题表示T。
1.2.2" RoBERTa模型
与之前的基准方法类似[7],TLGN(Topic-aware Label Graph Network)继续使用RoBERTa-Large来提取与对话上下文无关的会话级别的特征向量表示。假设一个话语表示ui = {wi1,wi2,…,win},首先,在话语开始处附加一个特殊的标记CLS,以创建模型的输入序列{CLS,wi1,wi2,…,win},然后,将附加了CLS特殊标记的语句送入基于RoBERTa的预训练语言模型,使用CLS在最后一层的池嵌入作为句子ui的特征表示,记为hi。
1.2.3" 标签指导的模型
对于标签指导模型,继续沿用Liu等人的方法[8],首先,把训练集分为n个标签文档,这里的n代表此类数据所具有的情感标签总数,然后,计算每个词的TF-IDF值,按照这个值从大到小排序,选取前500个词作为这类情感标签的描述,最后,通过GloVe模型得到每类情感标签300维向量表示。
1.3" 信息融合层
对于上节得到的三种特征表示,尝试了三种融合方式,分别为拼接、相加、相乘。发现拼接的效果是最好的,这也说明这三种特征是不同的。具体而言,先将RoBERTa的话语表示拼接对应的主题表示,接着,将话语表示映射到标签的维度,再与标签的特征表示相乘得到基于情感标签的特征向量表示,最后,将其拼接到话语表示后面。
1.4" DAG图传播层
1.4.1" 构建有向无环图
与之前的工作类似[9],为每个对话构造一个有向无环图,具体而言,对话中每个话语是一个节点,按照对话进行的时间先后顺序进行连边,而且这个边是有方向的,上一句是箭尾,紧挨着的下一句话是箭头。同时,同一说话者的话语也要按照时间先后顺序连接起来,从而获取话语间的结构表示。
假设DAG图用G = (V,E,R)表示,其中图的节点是会话中的话语,即V = {xi,…,xn},r ∈ R表示边的关系类型。边的关系类型集合R = {0,1},包含两种关系类型:1表示对话里面是同一说话人,0则表示不是同一说话人。边(i,j,ri, j) ∈ E表示从句子xi传播到句子xj的信息。在DAG图中,首先,由于DAG图是有向无环图,所以信息传递是有方向的,例如,第一个话语接收不到第二个话语的信息,也就是不能反向传递,只能是第二个话语接收第一话语的信息,也就是向前传递信息;其次,在一个对话里面会出现至少两位不同的说话者,对于同一说话者,也沿用时间先后顺序进行传递,也就是同一说话者的前一句话语和后一句话语之间有连边,且这个连边也是有方向的,从前一句开始到后一句结束,不能跨级。这样构图既获取了同一说话者之间的信息,又获取了小范围内的局部信息。
1.4.2" DAG传播层
与之前的工作类似[9],对于DAG-ERC的每一层,由于这里的信息流是随着时间进行流动的,因此对话里面所有话语的隐藏状态需要从第一个话语到最后一个话语重复循环计算。对于每个话语ui,使用ui在(l-1)层的隐藏状态和ui在l层的前驱uj的隐藏状态来计算ui与其前驱uj之间第l层的注意力权重 :
(1)
其中, 表示可训练参数, 表示拼接操作。使用hi来初始化第0层每句话的表示 。
除此之外,还引入了关系感知特征转换来建模同一说话者和不同说话者之间话语连接的差异性:
(2)
其中, 表示关系转换的可训练参数,去学习不同边类型的特征。
得到每个句子ui所需要的聚合信息之后,应用GRU单元来聚合获得ui在第l层的节点特征表示 :
(3)
与传统GRU不同的是,将" 视作隐藏状态,使用" 来控制" 的传播,此时重点关注的是每个话语节点上一层的信息,称之为节点特征表示。
类似地[9],逆转" 和" 的位置,使用" 来控制" 的传播,此时更多关注的是每个节点的前驱的信息流动,因此将其称之为上下文特征表示 :
(4)
最后,将每个节点ui每一层的两种信息通过加和和拼接进行融合,得到最后每个话语节点的最后表示hi:
(5)
(6)
1.5" 模型训练
对于模型训练的损失,这里计算了两个损失,即传统用于文本分类的交叉熵损失,还有一个用于标签不平衡的对比学习损失。通过这两个损失来对训练模型进行约束。传统的交叉熵损失函数主要用于评估分类模型预测结果的准确性,但它忽略了样本标签之间的区分度以及标签之间的关联关系。而分析数据集发现,有些情感标签之间比较相似,例如,“愤怒”和“厌恶”。但传统的交叉熵损失函数没有考虑这些关系,仅仅将每个标签视为相互独立的,这可能导致模型无法充分利用标签之间的信息,从而影响模型的性能。因此,为了充分挖掘标签之间的信息,采用了监督对比学习(SCL)[4]来缓解类似情感标签分类困难的问题,它通过比较同类样本和不同类样本之间的差异来学习特征表示。
监督对比学习的损失函数通常包括两个主要部分:正样本对比损失和负样本对比损失。正样本对比损失用于比较同一类别样本之间的相似性,它通过将同类别的样本嵌入空间拉近来鼓励模型学习到更具区分度的特征表示。负样本对比损失用于比较不同类别的样本之间的差异,它通过将不同类别的样本嵌入空间推开来鼓励模型学习到更具区分度的特征表示。通过结合正样本对比和负样本对比损失,监督对比学习能够使得模型学习到更具区分度的特征表示,从而提升模型在分类、检索等任务上的性能。
2" 实验及结果分析
2.1" 实施细节
对于TLGN模型,使用RoBERTa预训练提取上下文的话语表示,维度为1 024,提取的主题表示为300维,情感标签表示也为300维,使用Adam作为优化器,学习率为0.003。L2正则化系数为10×5,batch size为16。
2.2" 数据集
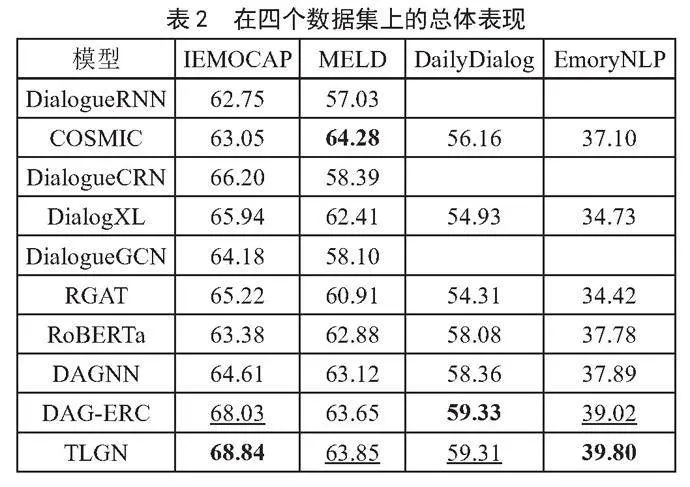
TLGN模型验证是在四个公开数据集上进行的,这四个公开数据集分别是IEMOCAP [10]、MELD [11]、DailyDialog [12]和EmoryNLP [13],有关数据集的统计信息显示在表1中。
与基准模型DAG-ERC一样,仅仅使用这四个数据集的文本数据进行实验,对于评估指标,遵循以前工作[7,9],对于DailyDialog数据集选择微平均F1,排除DailyDialog的多数类别(中性),对于其他数据集采用加权平均F1。
2.3" 实验对比模型
将TLGN模型与几个最先进的基线进行比较,如下所示:
1)DialogueRNN [14]。它引入了递归神经网络(RNN)来对对话历史进行建模。通过利用递归结构,它能够捕捉到上下文的长期依赖关系,提高情感识别的准确性。
2)DialogueCRN [15]。它提出了一种基于文本和情感的上下文推理的网络模型,该模型通过考虑前文、后文和当前文本的相互关系,可以在理解当前文本表达的同时,将其上下文信息结合起来进行情感分类。
3)COSMIC [5]。它提出了一种结合常识知识的方法,以帮助在对话中进行情感识别。通过利用广泛的常识知识,模型可以更好地理解对话中的情感表达,提高情感识别的准确性。
4)DialogXL [16]。它将XLNet模型应用于多轮对话情感识别任务。XLNet是一种基于自回归和自编码的转换器模型,具有强大的语言建模能力和上下文理解能力。
5)DialogurGCN [17]。为了更好地利用对话结构和历史信息,构建了一个基于图的对话建模方法。在该方法中,每个对话参与者和每个话语被表示为一个节点,并利用图的方式来表示它们之间的相互作用。这种基于图的对话建模方法可以更好地捕捉对话中的语言和上下文依赖关系。
6)RGAT [18]。它提出了一种新的神经网络模型,即关系感知的图注意力网络(RGA),用于情感识别任务。该模型采用图的结构将对话中的语言表示为节点,并使用注意力机制捕捉不同节点之间的互动关系。
7)RoBERTa [19]。通过从不同的语料库中收集大量的未标记文本数据,RoBERTa模型得到了更广泛的上下文信息,从而提升了模型的自然语言理解能力。
8)DAGNN [7]。它提出了一种新的神经网络结构——有向无环图(Directed Acyclic Graph, DAG)。这种结构通过有向边连接节点,可以灵活地捕捉节点之间的依赖关系。相比于不具有依赖关系的节点,DAG结构可以更准确地表示复杂的关系网络。
9)DAG-ERC [9]。它提出了一种使用有向无环图(DAG)结构来表示对话情感的模型。DAG可以更好地捕捉对话中节点之间的依赖关系,从而更准确地分析情感变化。此外,该模型还引入了循环DAG结构,通过隐式地处理节点序列,更好地表示对话情感的动态演变。
2.4" 结果对比和分析
2.4.1" 总体性能实验
在四个公开的数据集上进行实验,表2报告了TLGN与所有比较方法对比的总体结果。其中最好的结果用粗体标出,第二好的结果用下划线标出。从表2可以看出,DialogueRNN在IEMOCAP和MELD上取得了最差的结果,说明单纯对话语进行建模而不考虑时间流的上下文关系是不利于提高多轮对话情感分类识别任务性能的,COSMIC模型之所以实现了更好的性能,在于引入了外部知识。DialogXL模型比前面两个模型实现的性能更有提升,在于使用了预训练模型可以更好地获得基于上下文的话语表示。DAGNN模型首次在多轮对话中引入有向无环图,更好地引入了文本的结构信息,因此获得了不错的性能。DAG-ERC模型改进了DAGNN方法,引入了循环DAG结构,通过隐式地处理节点序列,更好地表示对话情感的动态演变。
与上述所有基线模型相比,提出的方法TLGN在IEMOCAP和EmoryNLP实现了最佳效果,在DailyDialog和MELD实现了次佳效果。主要原因是TLGN模型引入文本的多个特征,第一,对比主题模型可以丰富话语的主题表示;第二,标签指导模型可以更好地区别相似的标签。将两种特征拼接到现有的话语表示里面,可以更好地实现分类效果。
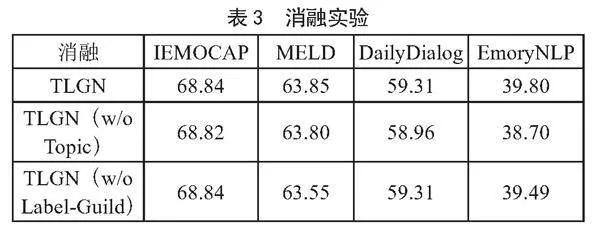
2.4.2" 消融实验
在本小节中,进行了一项消融实验,验证提出的组件对整体模型的影响。将完整模型TLGN与其两个变体进行比较,一是TLGN(w/o Topic),即从完整模型中移除对比主题模块;二是TLGN(w/o Label-Guild),即从完整模型中移除标签指导的模块。
从表3中,可以观察到从主题模型和标签指导的多粒度对话情感识别模型(即TLGN (w/o Topic))删除对比主题模型会导致所有数据集的分类性能下降,它验证了多轮对话中引入主题表示的重要性。同样的,TLGN模型删除标签指导的模型,所有数据集的性能也会下降,说明标签指导的模型得到的特征表示是不重复的,对分类是重要的。
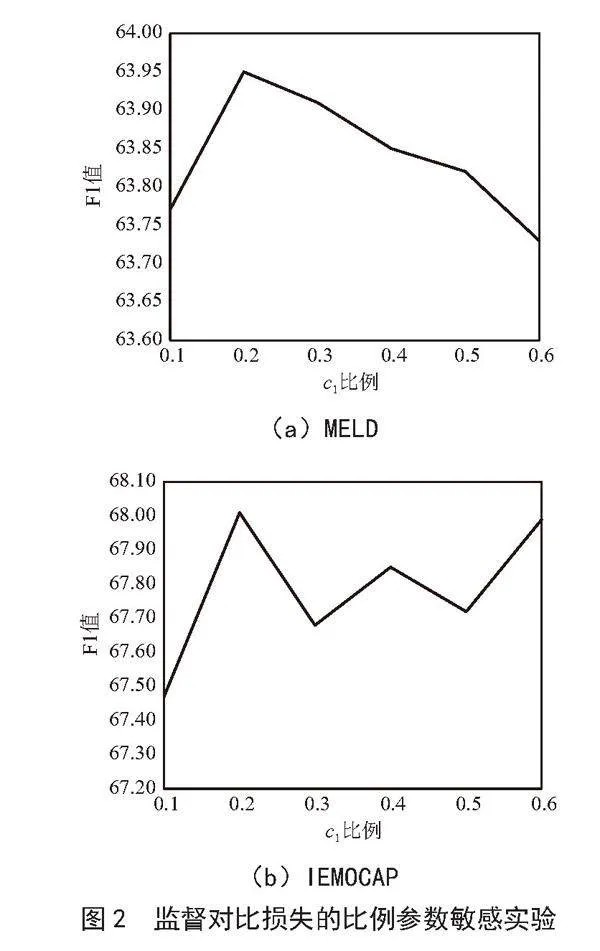
2.4.3" 参数敏感实验
为了探究模型训练时设置c1(监督对比损失的比例)对整个模型F1分数的影响,我们在MELD、IEMOCAP这两个数据集上进行了参数敏感性实验,其他两个数据集也有同样的倾向。这里取c1的值为0.1、0.2、0.3、0.4、0.5、0.6,也就是在整个模型训练损失中,监督对比所占的比例,实验结果如图2所示。如果将监督对比损失的比例设置得过低,例如设置为0.1或接近0,模型将会更加侧重于交叉熵损失,这可能导致模型对于样本的区分度较低,特征表示相对较弱,从而影响模型的准确性和分类性能;如果将监督对比损失的比例设置得过高,例如接近0.6或等于1,模型将会更加侧重于监督对比损失,这可能导致模型过于关注样本之间的相似性,而忽略了类别之间的区分度,从而降低模型的准确性和分类性能。只有合适的比例设置才能使监督对比损失和交叉熵损失在训练过程中起到协同作用。较合理的比例可能会增强模型对于样本之间关系的学习,提高特征的区分度,这可以帮助模型更好地区分不同的对话情感类别,从而提高模型的准确性。
3" 结" 论
在这项研究中,提出了一种新型的对话情感识别方法,通过融合主题模型和标签指导表示,实现了对话文本不同粒度的语义建模。首先,主题模型从全局的视角分析文本的上下文主题信息。然后,标签指导表示学习语句的具体语义。最后,将两种互补的表示拼接后输入到分类模型,进行情感判断。在四个公开的数据集上的实验表明,与仅使用单一模块相比,TLGN模型取得了显著提升,增强了对话的理解力。
TLGN模型为从全新的角度改进对话情感识别提供了启发。主题模型为对话提供了上下文支撑,表示了编码语义细节,两者的配合超越了各自的局限。此外,TLGN模型框架的模块化设计也方便今后的改进和扩展。一方面,主题模型和表示学习本身还在不断发展,可期待其带来的进一步优化;另一方面,分类模型也可换用更强大的结构。
尽管取得了一定的进展,对话情感识别任务仍面临许多挑战。今后工作可考虑融入更多情感相关的外部知识,以及多模态的声音和视觉信息。还可探索端到端的训练方式,实现不同模块的联合优化。相信随着表示学习和对话系统的进步,基于主题和语义表示的对话理解技术必将取得新的突破,使得人机交互更加智能化。
参考文献:
[1] FENG S T,LUBIS N,GEISHAUSER C,et al. EmoWOZ: A Large-scale Corpus and Labelling Scheme for Emotion Recognition in Task-oriented Dialogue Systems [J/OL].arXiv:2109.04919 [cs.CL].(2021-09-10).https://arxiv.org/abs/2109.04919.
[2] CHOWANDA A,SUTOYO R,TANACHUTIWAT S. Exploring Text-based Emotions Recognition Machine Learning Techniques on Social Media Conversation [J].Procedia Computer Science,2021,179(1):821-828.
[3] TU G,WEN J T,LIU C,et al. Context-and Sentiment-aware Networks for Emotion Recognition in Conversation [J].IEEE Transactions on Artificial Intelligence,2022,3(5):699-708.
[4] KHOSLA P,TETERWAK P,WANG C,et al. Supervised Contrastive Learning [J/OL].arXiv:2004.11362 [cs.LG].(2020-04-23).https://arxiv.org/abs/2004.11362v5.
[5] GHOSAL D,MAJUMDER N,GELBUKH A,et al. COSMIC: CommonSense Knowledge for Emotion Identification in Conversations [J/OL].arXiv:2010.02795 [cs.CL].(2020-10-06).https://arxiv.org/abs/2010.02795.
[6] NGUYEN T,LUU A T. Contrastive Learning for Neural Topic Model [J/OL].arXiv:2110.12764 [cs.CL].(2021-10-25).https://arxiv.org/abs/2110.12764v1.
[7] THOST V,CHEN J. Directed Acyclic Graph Neural Networks [J/OL].arXiv:2101.07965 [cs.LG].(2021-01-20).https://arxiv.org/abs/2101.07965.
[8] LIU X N,WANG S,ZHANG X,et al. Label-guided Learning for Text Classification [J/OL].arXiv:2002.10772 [cs.CL].(2020-02-25).https://arxiv.org/abs/2002.10772.
[9] SHEN W Z,WU S Y,YANG Y Y,et al. Directed Acyclic Graph Network for Conversational Emotion Recognition [J/OL].arXiv:2105.12907 [cs.CL].(2021-05-27).https://arxiv.org/abs/2105.12907.
[10] BUSSO C,BULUT M,LEE C-C,et al. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database [J].Language Resources and Evaluation,2008,42:335-359.
[11] PORIA S,HAZARIKA D,MAJUMDER N,et al. A Multimodal Multi-party Dataset for Emotion Recognition in Conversations [J/OL].arXiv:1810.02508 [cs.CL].(2018-10-05).https://arxiv.org/abs/1810.02508?context=cs.CL.
[12] LI Y R,SU H,SHEN X Y,et al. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset [J/OL].arXiv:1710.03957 [cs.CL].(2017-10-11).https://arxiv.org/abs/1710.03957v1.
[13] ZAHIRI S M,CHOI J D. Emotion Detection on TV Show Transcripts with Sequence-based Convolutional Neural Networks [J/OL].arXiv:1708.04299 [cs.CL].(2017-08-14).https://arxiv.org/abs/1708.04299.
[14] MAJUMDER N,PORIA S,HAZARIKA D,et al. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations [J/OL].arXiv:1811.00405 [cs.CL].(2018-11-01).https://arxiv.org/abs/1811.00405v4.
[15] HU D,WEI L W,HUAI X Y. DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations [J/OL].arXiv:2106.01978 [cs.CL].(2021-06-03).https://arxiv.org/abs/2106.01978v1.
[16] SHEN W Z,CHEN J Q,QUAN X J,et al. DialogXL: All-in-one XLNet for Multi-party Conversation Emotion Recognition [J/OL].arXiv:2012.08695 [cs.CL].(2020-12-16).https://arxiv.org/abs/2012.08695.
[17] GHOSAL D,MAJUMDER N,PORIA S,et al. DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation [J/OL].arXiv:1908.11540 [cs.CL].(2019-08-30).https://arxiv.org/abs/1908.11540.
[18] ISHIWATARI T,YASUDA Y,MIYAZAKI T,et al. Relation-aware Graph Attention Networks with Relational Position Encodings for Emotion Recognition in Conversations [C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).Stroudsburg:ACL,2020:7360-7370.
[19] LIU Y H,OTT M,GOYAL N,et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach [J/OL].arXiv:1907.11692 [cs.CL].(2019-07-26).https://arxiv.org/abs/1907.11692.
作者简介:朱玲(1990—),女,汉族,重庆人,助教,硕士,研究方向:人工智能自然语言处理。
收稿日期:2023-11-07
基金项目:2022年重庆安全技术职业学院科学技术研究项目(AQJS22-09)