
摘" 要:针对上市公司财务造假预测问题,采用结合了LightGBM与递归特征消除法(RFE)的方法进行数据建模。LightGBM以其超参数量少、强大的稳健性及对不平衡数据的高敏感性等特点著称。RFE作为一种封装式特征选择方法,能高度匹配所用预测模型,并通过设定特征子集评价函数作为停止条件,自动确定最优特征数量,这在特征选择领域具有较大优势。此外,选用平衡精度(BAcc)作为模型预测性能的评估指标,并通过调整LightGBM的分类权重参数来解决样本不平衡的问题。在5个不同行业财务数据集上的实验结果表明,所提出的RFE-LGB模型在上市公司财务造假预测任务中表现出良好的平衡性、稳健性和泛化性。该模型能有效识别与财务造假相关的关键指标,且仅使用较少的核心特征即可达到较高的预测精度。
关键词:上市公司;财务造假;LightGBM;递归特征消除;特征选择
中图分类号:TP39;TP183" 文献标识码:A 文章编号:2096-4706(2024)11-0145-08
Analysis and Prediction of Financial Fraud in Listed Companies Based on
RFE-LGB Algorithm
CHEN Mengyuan, NAN Jiaqi, WANG Jingsai
(School of Finance, Henan Finance University, Zhengzhou" 450046, China)
Abstract: To address the issue of financial fraud prediction in listed companies, a method combining LightGBM and Recursive Feature Elimination (RFE) is adopted for data modeling. LightGBM is known for its low number of hyper parameter, strong robustness, and high sensitivity to imbalanced data. RFE, as an encapsulated feature selection method, can highly match the prediction model used and automatically determine the optimal number of features by setting a feature subset evaluation function as a stopping condition, which has significant advantages in the field of feature selection. In addition, the balanced accuracy (BAcc) is selected as the evaluation index for the predictive performance of the model, and the problem of sample imbalance is solved by adjusting the classification weight parameters of LightGBM. The experimental results on five different industry financial datasets show that the proposed RFE-LGB model exhibits good balance, robustness, and generalization in predicting financial fraud in listed companies. This model can effectively identify key indicators related to financial fraud, and can achieve high prediction accuracy with only a few core features.
Keywords: listed company; financial fraud; LightGBM; recursive feature elimination; feature selection
0" 引" 言
近年来,市场上屡见上市企业财务造假及爆雷事件,2020年更是出现了流动性困境和信用债违约等现象。这一系列事件凸显了监管部门严格监管上市公司的重要性。监管部门已进一步强化了对上市公司的监管措施,对于那些存在严重财务数据造假行为或已丧失持续经营能力的企业,强制其退市成为必要的手段。然而,这样的退市必然会给投资者带来经济上的损失。因此,投资者只有在对上市公司的财务数据进行了全面深入的分析和研究后,才能做出投资与否的决策,以此确保投资的安全性。作为专业投资者,研究一家上市公司的财务数据是否稳健,实质上是对该公司的信用风险进行评估预测。信用风险评估的关键在于检测出公司财务造假的财务指标,这些风险因素可能存在于各种难以察觉的细微之处。鉴于此,人们开始借助一些数理统计方法来建立风控模型,筛选关键指标对上市公司多年的财务数据进行跟踪分析和研究,识别真伪,避免投资踩雷。
随着数据科学的快速发展,机器学习技术开始应用到不同的领域。由于机器学习方法具有无须严格假设,擅长处理非线性数据等优势,该类方法广泛运用于金融风控(建模)领域,包括支持向量机、决策树及神经网络等。尤其是基于决策树构建的模型具有解释性强、超参数少、模型复杂度小、易于训练等优点,表现得更加突出[1],典型代表如随机森林、梯度提升决策树(Gradient Boost Decision Tree, GBDT)等,其中的GBDT及其改进算法如Chen [2]提出的极端梯度提升算法XGBoost,Ke等[3]提出的轻量级梯度提升机(LightGBM)等,无论在理论研究还是工业应用层面都表现出优良的性能。然而,众多财务指标之间往往存在着较强的相关性和冗余性,如果将这些指标直接用于建模,将会极大地影响模型的效果。此外,数据采集成本也会大幅提升。因此,许多研究中都采用特征选择方法对数据进行预处理,旨在剔除一些无关的冗余指标,以较少的指标来刻画反映风险的主要特征,使得所构建的模型简洁、稳健,最终达到既提高模型预测准确性,又能清晰反映信用风险与其主要影响因素之间联系的目的,同时还降低了数据采集的成本。显然,特征选择已成为影响风控建模效果的关键一环。
特征选择方法主要分为过滤式(Filter)、封装式(Wrapper)和嵌入式(Embedded)三大类。其中,封装式方法特别注重特征选择与学习器的结合。这种方法将学习器的预测效果作为特征子集的评价标准,实现了对学习器的优化,因此预测效果往往更好[4]。其中递归特征消除法(Recurisive Feature Elimination, RFE)是现在较为常用的封装式方法,其思想是对于含有特征权重的学习器,每训练一次便剔除权重绝对值最小的特征,依此准则不断循环递归直至模型在验证集上的某个评估指标达到最优。吴辰文等[5]采用基于随机森林的RFE方法对乳腺癌相关数据进行特征选择,实验结果表明该方法在剔除无关变量的同时还提高了模型的性能,取得了较为理想的效果。
另外,用于建模的二分类数据具有高度的样本不平衡性,即财务造假的公司在整个样本集中占比很小。针对这一问题,李豫等采用SMOTE算法对上市公司数据进行过采样,以此解决数据不平衡的问题,然后结合BP神经网络进行财务造假分析[6]。代价敏感学习是另外一种应对上述问题的常用方法[7]。对于样本类别不平衡的问题,可通过调整分类权重(Class Weight)的方式来削弱其影响。通过对误判代价大的类施加更高分类权重的方式来放大该类的损失,这样在训练过程中学习器就会更加偏重样本数较少的一类,从而提高该类的识别率。张悦等通过构建基于成因理论的财务造假因子库和代价敏感的轻型梯度提升决策树模型,有效提升了对2015年中国上市公司财务造假的识别准确率[8]。
在模型预测性能评估方面,许多研究都是以分类精度(Accuracy, Acc)作为模型效果评判标准,而Dushimimana等[9]指出,分类精度并不是一个合适的模型评价指标,对风险检测任务而言,预测潜在造假公司是最为重要的。因此,有学者选取平衡精度(Balanced Accuracy, BAcc)作为模型评价标准[10],BAcc是测试集两类查全率(Recall)的平均值,它可以很好地反映出分类模型预测的均衡性。
综上所述,本文将LightGBM(LGB)和RFE方法相结合,以BAcc作为模型评估指标构建了RFE-LGB模型,该模型可以有效识别出存在财务造假的公司以及造假相关的数据指标。
1" 相关理论介绍
1.1" 递归特征消除法
递归特征消除(RFE)的核心思想是不断迭代模型以识别并保留有效特征,通过逐一剔除不重要特征的方式来实现,直至所有特征均已被评估。在这一过程中,特征的去除顺序形成一个特征重要性的排列,这个策略基本上是一种以贪心算法寻求最理想特征子集的手段。
此外,确立模型选择特征的准确性的验证机制也是必不可少的一步。采用交叉验证作为验证机制,可以在RFE流程内部对不同的特征集进行验证,以确定各个特征对目标变量的贡献程度,并据此挑选出最佳特征集,上述方法被称为RFECV(Recursive Feature Elimination with Cross-Validation),是递归特征消除法(RFE)的一个扩展,它结合交叉验证寻找模型性能最优的特征数量。通过使用交叉验证,RFECV能够更加稳健地评估每个特征子集的性能,从而选择出最佳的特征集合。
RFECV的基本步骤如下:
1)选择模型和交叉验证策略。首先确定一个基本的机器学习模型和适用的交叉验证策略(如K折交叉验证)。
2)训练模型并评估特征。RFECV会训练模型并根据模型的特征重要性指标来评估每个特征的重要性。
3)移除特征和交叉验证。移除一个或多个重要性较低的特征,然后基于剩余的特征通过交叉验证来评估模型性能。
4)记录性能和重复。记录每次交叉验证后的模型性能,并重复特征移除和模型评估的过程。
5)确定最优特征数量。在所有的特征子集中,找到交叉验证评估中性能最优的特征集合。
RFECV的优势在于它能自动调整特征的数量,找到一个在交叉验证下表现最佳的特征子集,这有助于提高模型的稳健性并减少过拟合的风险。但是,由于需要多次进行交叉验证和模型训练,RFECV的计算成本比单纯的RFE要高。
1.2" LightGBM算法
GBDT是一种以分类和回归树(CART)为基学习器的加性集成模型,LightGBM是GBDT框架下的一种改良算法。设学习器 = f(X), 表示对目标值y的预测值,分类任务的损失函数为L(Y,F(X)),假设迭代次数为T,用ft(X)表示第t次迭代的基学习器,用Ft(X)表示第t次迭代的强学习器(t = 0,1,2,…,T),则上一次迭代得到的强学习器为Ft-1(X),对应的损失函数为L(y,Ft-1(X)),第t次迭代的目标是找到最优的基学习器ft*(X),令损失函数L(y,Ft(X))达到最小值。第t次迭代的目标函数可由式(1)表示:
(1)
由于是加性组合模型,第t次迭代得到的强学习器Ft(X)可由式(2)表示:
(2)
故式(1)也可写为式(3):
(3)
最优化的方法为:第t次迭代使用的目标变量数据不再是原始目标变量y的样本值,而是第t-1次迭代的损失函数的负梯度值,即式(4):
(4)
通过上述方法可以找到每次迭代的最优基学习器ft*(X),t = 1,2,…,T。将这些基学习器相加就得到如式(5)所示的最终强学习器:
(5)
由于GBDT在评估每个特征的所有潜在分割点的信息增益时需要遍历所有样本,因此在处理高维度和大数据量情况下,其训练效率较低。为了解决这个问题,LightGBM通过引入两种创新方法来降低计算成本:基于梯度的单侧采样(GOSS)和排他性特征打包(EFB)。GOSS的核心思想是,在计算信息增益时梯度较大的样本更为重要,因此,在进行下采样时应优先保留这部分样本,而对梯度较小的样本进行随机采样,这样既减少了计算负担,又保持了估算精度。EFB的策略基于一种现象:在高维数据中,很多特征是稀疏且互斥的,即它们不会同时是非零值。LightGBM通过将这些互斥特征合并为单一特征,有效降低了特征的维度,进而在不牺牲模型准确度的前提下显著提升了训练速度。
另外,LightGBM在决策树生长策略方面也有所改进,决策树学习算法一般是按层分裂,即每次不加区分地分裂同一层的全部节点,这种方法被称为“level-wise树生长策略”,如图1所示。实际上,很多节点的分裂增益较低,没有必要进行分裂。
LightGBM实施的是如图2所示的基于叶子的生长策略(即leaf-wise方法),它在所有当前层的节点中选择具有最高分裂增益的节点进行扩展。这种策略倾向于创建较深的树结构,可能导致过拟合,故有必要控制树的最大深度。与传统的按层生长(level-wise策略)对比,leaf-wise在相同的分裂次数下能够大幅减少损失,提高模型的效率和精度。leaf-wise树生长策略如图2所示。
1.3" 网格搜索参数优化
在机器学习中,“学习算法”通过学习“训练数据”自动确定“模型参数”。而算法本身也有一些参数,这些参数无法通过训练数据学得,算法的参数被称为“超参数”,如神经网络中的连接权重是模型参数,而神经网络的层数和每层神经元个数就是超参数。确定超参数的方式有两种:人工设定和自动搜索,人工设定超参数需要由调参者对当前建模任务或同类型任务有足够丰富的实践经验,并且需要花费相当长的时间。自动搜索只需设置一定的参数范围,然后让计算机根据某种策略进行参数选择。自动搜索超参数从本质上来说是一种优化过程:我们以某个模型评估指标为目标函数,通过搜索策略尝试进行各种超参数的组合,目的是寻求使目标函数在验证集上达到极值的参数组合。当学习算法的超参数较少时,一种常用的搜索策略是网格搜索法(Grid Search)。为每一个超参数设定一个离散的有限值集,对这些超参数集合进行笛卡尔乘积运算后就得到一个个的超参数组合,网格搜索遍历每组超参数训练模型,最终选择验证集效果最好的超参数组合[11]。
显然,网格搜索的关键在于对目标函数的选择,以不同的模型评估指标作为目标函数将得到不同的最优超参数。
2" 模型构建
2.1" 模型性能度量指标
在预测任务中,给定样本集D = {(x1,y1),(x2,y2),…,(xm,ym)},其中yi表示特征样本xi的真实标签,二分类任务中通常取yi为0或1,本文中0代表不存在财务造假,1代表存在财务造假。若要对模型f的预测性能进行评估,需要将f的预测结果f(x)与真实标签y进行比较。精度(Acc)是分类任务中较为常用的性能度量指标之一,精度是指分类正确的样本数占总样本数的比例,对于样本集D,分类精度可由式(6)表示:
(6)
其中,I(·)表示示性函数,,对于类别不平衡的样本集,精度并不能真实反映出模型的预测效果。假定一个样本容量为100的样本集,其中有95个样本的真实标签为0,其余5个样本的真实标签为1,假定模型f的预测结果f(x)全部取值为0,此时的预测精度为95%,单从精度的数值来看,模型的性能好像还不错,但是仅有的5个真实标签为1的样本全部被错误地预测为标签为0的这一类。具体到上市公司财务造假预测任务中,就意味着要把所有的“造假”预测为“未造假”,这种误判会导致投资者踩雷,从而造成巨大的损失。
平衡精度(BAcc)是对精度的一种改进,它特别适用于处理类别不平衡的数据集。
二分类任务的预测结果与真实情况对比可由表1的混淆矩阵来表示。其中TP(True Positive)、FP(False Positive)、TN(True Negative)、FN(False Negative)分别表示真正例、假正例、真负例、假负例的数目(本文中0代表正例,1代表负例)。
好样本和坏样本的查全率(Recall)分别为Recall0(R0)、Recall1(R1),具体定义如下:
(7)
(8)
它们表示的是真实的好样本和坏样本中分别被预测正确的比例。基于Recall0和Recall1可以构造平衡精度,其定义为:
(9)
显然,在数据类别不平衡的情况下,BAcc相较于Acc更具公平性。因此,以BAcc为优化目标所生成的模型更加符合财务造假预测任务的实际需求。
2.2" RFE-LGB模型理论构建
基于RFE方法的特征选择效果极大依赖于循环中所用机器学习算法的稳定性。同时,该特征选择方法的计算成本高,尤其是在特征数量非常多的情况下,它需要多次训练模型。因此,我们采用了集稳定性与速度于一身的集成学习算法LightGBM与RFE相结合,构建RFE-LGB模型。
建模步骤为:
1)将清洗过的全特征训练数据输入LGB学习器,并以BAcc为目标函数进行网格搜索参数优化,得到全特征对应的最优LGB超参数。
2)以BAcc为特征子集评价函数,通过RFECV方法与全特征最优LGB相结合的方式进行特征选择,得到最优特征子集。
3)将最优特征子集数据输入LGB,以BAcc为目标函数进行网格搜索参数优化,得到最终的LGB模型。
4)从测试集中挑选出第二步给出的最优特征数据,输入第三步得到的LGB模型进行预测。
RFE-LGB具体建模过程如图3所示。
3" 实证研究
3.1" 实验数据
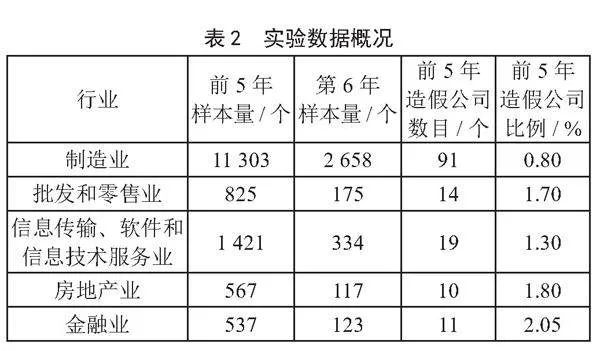
本文选取了5个行业上市公司的财务数据进行对比试验,数据来源于第九届“泰迪杯”数据挖掘挑战赛A题的数据文件[12]。这5个行业分别是制造业,批发和零售业,信息传输、软件和信息技术服务业,房地产业,金融业。每个行业的数据概况如表2所示。
3.2" 实验过程
本文基于Python 3.7进行实验。首先对实验数据集进行数据清洗,使用Pandas的dropna函数删除了缺失值占比80%的列,并用中位数填充剩余缺失值。由于建模使用的LightGBM是树基模型,它不受数据量纲的影响,因此不必进行数据标准化处理。
以金融业为例,展示RFE-LGB实际建模过程,步骤如下:
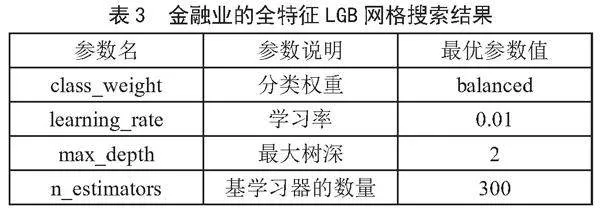
1)将清洗后的金融业数据输入LGB进行网格搜索超参数优化,结果如表3所示。
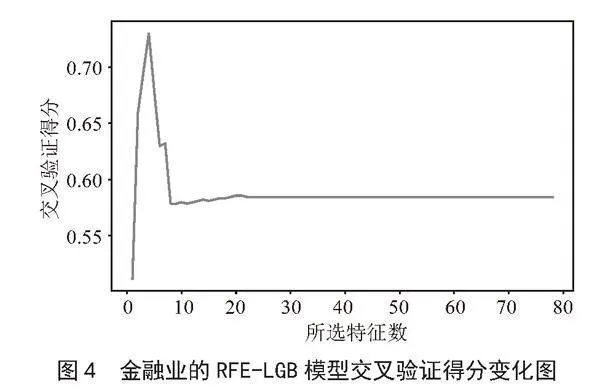
2)基于设定了如表3所示最优超参数的LGB模型进行RFECV特征选择,将RFECV的特征剔除步长设定为1,即每次只剔除一个最不重要的特征。在整个RFECV过程中,LGB模型的交叉验证得分(BAcc)变化如图4所示。
图4中交叉验证得分最高点对应的特征子集就是RFECV筛选出的最优特征子集。
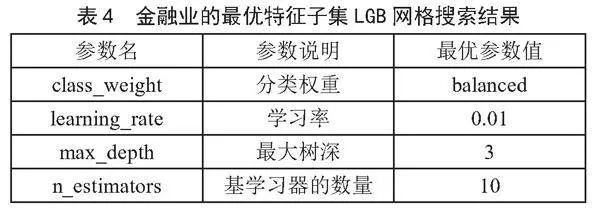
3)将RFECV筛选出的最优特征子集数据输入LGB并再次进行网格搜索超参数优化,得到最优特征子集的LGB最佳参数,如表4所示。
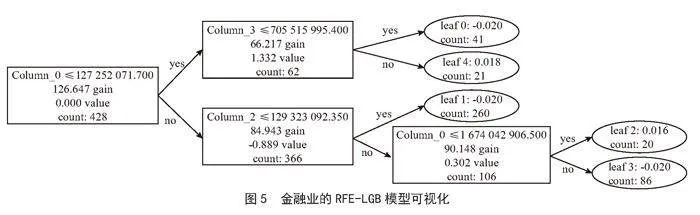
基于表4的超参数设定和第二步得到的最优特征,我们就可以训练出最终用于预测的LGB模型。图5是对模型中单棵决策树的可视化。
4)依据第二步的特征选择结果,将测试集的最优特征子集数据输入第三步得到的最终LGB模型,进行财务造假预测。
3.3" 实验结果分析
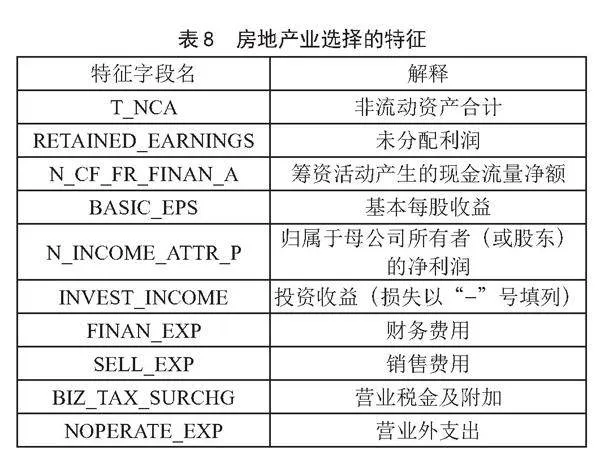
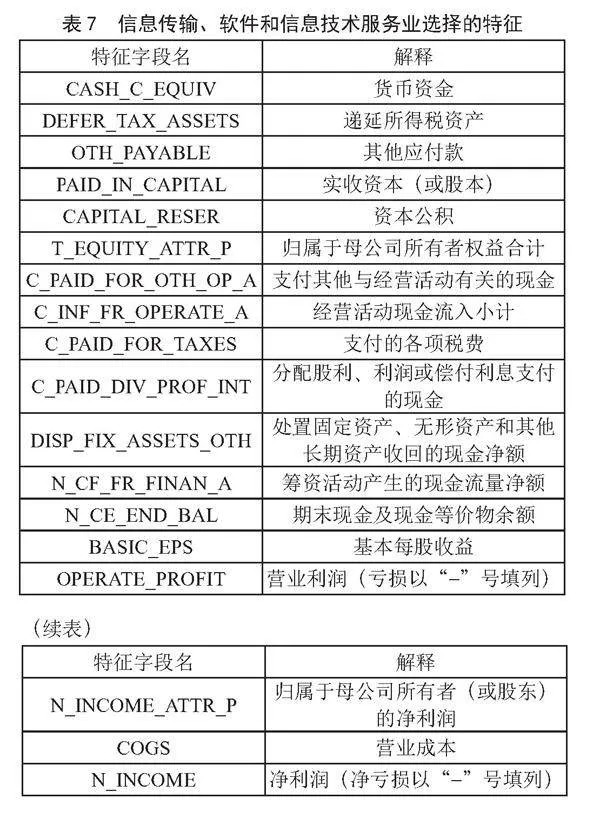
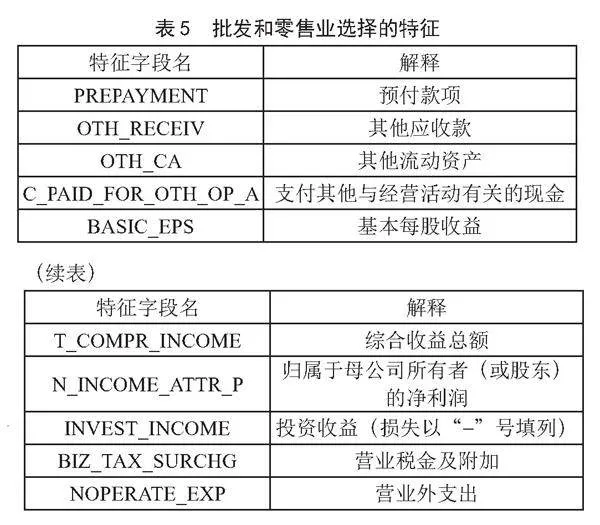
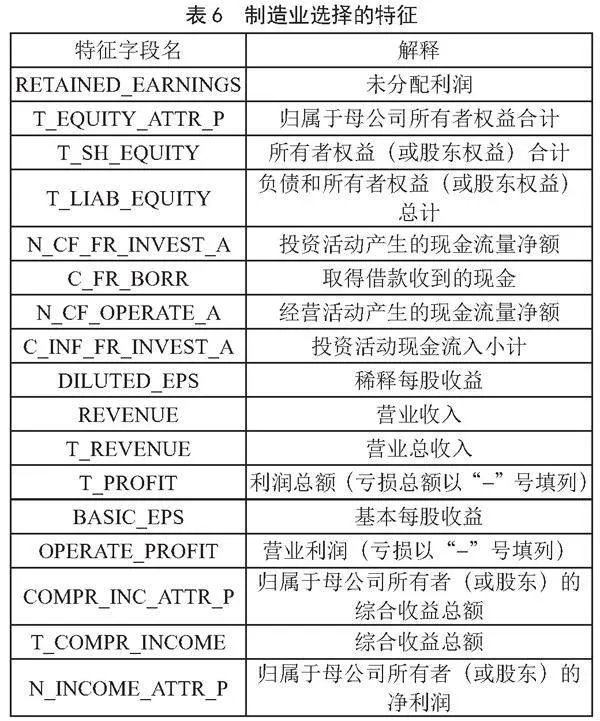
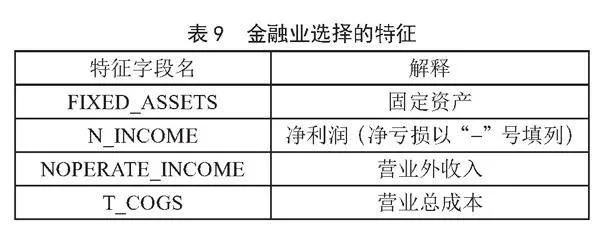
依据图3的建模流程,得到5个行业的最优特征子集如表5至表9所示。
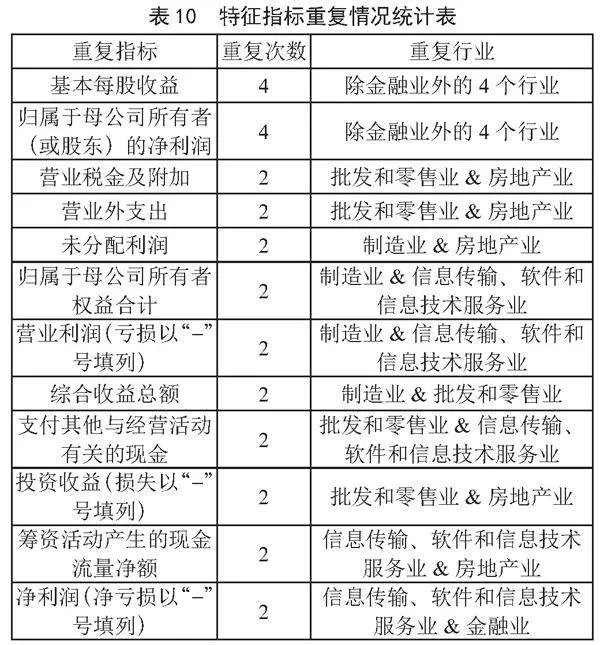
对上面5个行业的财务造假特征指标进行对比,可以得到如表10所示的特征指标重复情况统计表。
由表10可以看出,基本每股收益在除金融业之外的4个行业均有记录,强调了其在非金融行业中的普遍性及作为操纵目标的吸引力。归属于母公司所有者的净利润在4个行业中也广泛被操作,凸显了其作为核心盈利指标的敏感性。此外,一些指标在特定行业组合中重复出现,如营业税金及附加、营业外支出在批发和零售业与房地产业中重复,未分配利润在制造业与房地产业中重复等。这显示出不同行业在财务造假手段上可能存在行业特性,造假者可能更倾向于利用行业特定的财务指标进行操纵。
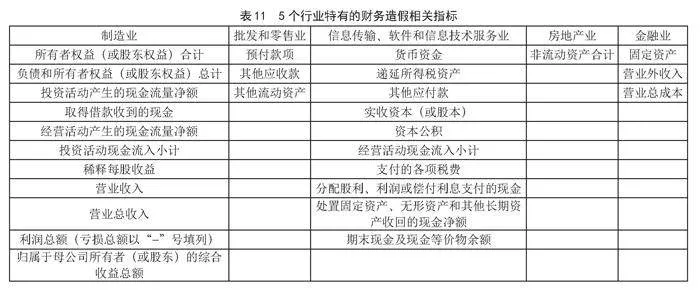
每个行业特有的造假相关指标如表11所示。
以上结果提示监管机构和投资者应对这些常被操纵的指标保持警觉,并采取相应的审查和验证措施,以有效防范财务风险。
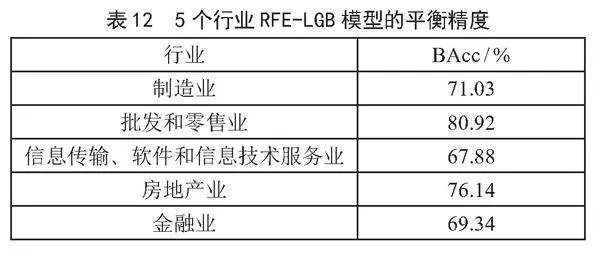
各行业数据以各自最优特征子集建立的LGB分类模型的5折交叉验证平衡精度(BAcc),如表12所示。
由表12可以看出,RFE-LGB模型对批发和零售业的财务造假预测表现最佳,预测结果的平衡精度达到了80.92%。这种高效率的表现可能是因为该行业具有较为一致和可预测的财务模式,易于模型通过特定特征进行学习和预测。
相比之下,信息传输、软件和信息技术服务业的平衡精度最低,仅为67.88%。这一行业的数据复杂度和专业性较高,涉及的业务模式和收入来源多样,估值和收入确认标准相对来说具有更多的灵活性和解释空间,导致模型难以从中提取出稳定且有效的预测特征,从而影响了精度表现。
制造业和金融业的平衡精度分别为71.03%和69.34%,显示出中等水平的模型表现。这可能与这些行业内部财务活动的多样性和外部经济环境的变化有关,这些因素增加了财务数据的波动性和不确定性,相应地也增加了模型识别财务造假的难度。
房地产业的模型平衡精度为76.14%,相对较高。这可能是由于房地产业的财务数据在一些关键特征(如资本密集度和固定资产占比)上更为明显和一致,使得模型能够较好地进行学习和预测。
总体而言,这些结果表明了不同行业的数据特性和模型适应性的差异。因此,我们在使用机器学习模型进行跨行业财务造假检测时,需要将各行业的具体情况和挑战考虑在内。同时也暗示了优化模型性能、提高检测精度需要针对具体行业特点采取定制化的策略和方法。
4" 结" 论
由于上市公司财务数据指标众多,其与公司财务造假之间的关系复杂,本文选取树基集成模型LgihtGBM结合递归特征消除法(RFE)进行数据建模,选用平衡精度进行模型预测性能度量。采用RFE方法可以根据指定的目标函数来确定最优特征组合,在筛选核心特征方面效果显著;LightGBM作为树基集成模型,其超参数较少,易于调参且训练效率高,同时训练出的模型稳健性强。本文将从两个方面解决样本不平衡的问题:第一,在模型评估指标上选择平衡精度,无论是超参数优化阶段还是特征选择阶段,平衡精度(BAcc)都比常用的精度(Accuracy)更具客观性,以BAcc为目标得到的最优超参数和最优特征子集都不会过度偏向对多数类的预测;第二,将LightGBM中的分类权重参数calss_weight设为“balanced”,这可以有效对抗样本类别不平衡的问题。上述两种处理方法确保了最终模型的均衡性,使模型针对造假和未造假公司的区分能力更强。从所选取5个行业数据的实验结果可以看出,RFE-LGB模型能够在仅使用少量特征的情况下,依然取得出色的预测效果。
尽管如此,本文的研究仍有改进空间。特别是,模型的泛化能力需要通过增强数据集的多样性和代表性来提升,模型的解释性可以通过引入更先进的解释性技术来提高,以便专家更好地理解模型预测的原因。此外,通过探索更复杂的特征工程技术,引用较高级的超参数优化策略,采用更广泛的样本不平衡处理方法,可以进一步提升模型的性能。最后,定期更新模型以适应新的数据模式,进行更全面的实验验证和与其他模型的比较分析,都是确保研究成果实用性和有效性的关键步骤。
参考文献:
[1] ZHOU Z H,FENG J. Deep forest [J].National Science Review,2019,136(1):74-86.
[2] CHEN T Q,GUESTRIN C. XGBoost: A Scalable Tree Boosting System [J/OL].arXiv:1603.02754v2 [cs.LG].[2024-02-12].https://arxiv.org/abs/1603.02754v2.
[3] KE G L,MENG Q,FINLEY T,et al. LightGBM: A Highly Efficient Gradient Boosting Decision Tree [C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]:Curran Associates Inc,2017:3149-3157.
[4] 周志华.机器学习 [M].北京:清华大学出版社,2016.
[5] 吴辰文,梁靖涵,王伟,等.基于递归特征消除方法的随机森林算法 [J].统计与决策,2017(21):60-63.
[6] 李豫,方子强,黄敏婷.基于BP-神经网络与SMOTE算法的上市公司财务数据造假分析 [J].现代信息科技,2021,5(4):121-125.
[7] ALMHAITHAWI D,JAFAR A,ALJNIDI M. Correction to: Example-dependent cost-sensitive credit cards fraud detection using SMOTE and Bayes minimum risk [J/OL].SN Applied Sciences,2020,2(12)[2024-02-16].https://link.springer.com/article/10.1007/s42452-020-03810-y.
[8] 张悦,宋海涛.基于代价敏感学习的财务造假识别研究 [J].财会研究,2022(2):22-29.
[9] DUSHIMIMANA B,WAMBUI Y,LUBEGA T,et al. Use of Machine Learning Techniques to Create a Credit Score Model for Airtime Loans [J].Journal of Risk and Financial Management,2020,13(8):1-11.
[10] JUNIOR L M,NARDINI F M,RENSO C,et al. A Novel Approach to Define the Local Region of Dynamic Selection Techniques in Imbalanced Credit Scoring Problems [J/OL].Expert Systems with Applications,2020,152.[2024-02-09].https://doi.org/10.1016/j.eswa.2020.113351.
[11] GOODFELLOW L,BENGIO Y,COURVILLE A. 深度学习 [M].北京:人民邮电出版社,2017.
[12] 数睿思.2021年(第9届)“泰迪杯”数据挖掘挑战赛 [EB/OL].https://www.tipdm.org:10010/#/competition/
1354705811842195456/question.
作者简介:陈梦媛(2001.07—),女,汉族,河南驻
马店人,本科在读,研究方向:金融数据挖掘;南嘉琦(1995.
09—),女,汉族,河南洛阳人,助教,硕士研究生,研究方向:公司金融、金融计量;通讯作者:王静赛(1997.01—),男,汉族,河南南阳人,助教,硕士研究生,研究方向:数据科学、统计机器学习与金融数学交叉。
收稿日期:2024-04-09
基金项目:河南财政金融学院2023年大学生创新训练计划项目(202311652029)