



摘 要:糖尿病是一种无法根治的慢性疾病,早发现、早干预、早治疗能够延缓病情进展,提高患者的治疗效率。构建基于决策树、逻辑回归、XGBoost等六种机器学习分类算法的预测模型,实现糖尿病风险预测。该模型以皮马印第安人糖尿病数据集为研究对象,通过数据预处理、数据特征分析构建有效数据集,采用网格搜索方法进行交叉验证寻找算法的最佳参数组合,构建超参数及基于超参数的分类模型,并对模型的预测性能进行评价。实验结果表明,该模型拥有良好的糖尿病风险预测性能。
关键词:糖尿病预测;分类算法;网格搜索;模型评价
中图分类号:TP18 文献标识码:A 文章编号:2096-4706(2024)14-0059-06
Prediction of Diabetes Based on Machine Learning Algorithm
LING Xiongjuan, WANG Junjie
(Foshan Polytechnic, Foshan 528137, China)
Abstract: Diabetes is an incurable chronic disease. Early detection, early intervention, and early treatment can delay the progression of the disease and improve the treatment efficiency of patients. A prediction model based on six Machine Learning classification algorithms, such as Decision Tree, Logical Regression and XGBoost, is constructed to predict the risk of diabetes. The model takes the Pima Indian diabetes dataset as the research object, builds an effective dataset through data pre-processing and data feature analysis, uses grid search method to cross verify and find the optimal parameter combination of the algorithm, builds a super parameter and a classification model based on super parameters, and evaluates the prediction performance of the model. The experimental results show that the model has good risk prediction performance for diabetes.
Keywords: diabetes prediction; classification algorithm; grid search; model evaluation
DOI:10.19850/j.cnki.2096-4706.2024.14.012
0 引 言
糖尿病是一种无法根治的慢性内分泌疾病,根据国际糖尿病联盟(IDF)的最新数据显示,全球糖尿病患者的人数已经达到4.66亿,并且这个数字仍在持续增长。中国是世界糖尿病人口数最多和患病率最高的国家,患病率达到了11.2%,相当于每100人就有11人得糖尿病,且未被诊断的糖尿病人数所占比例较高,中国糖尿病防治指南[1]显示,糖尿病知晓率仅有36.5%,相当于11个患者中仅有4人被确诊糖尿病,有7个人不知道自己血糖高。糖尿病无法根治,且容易引发各种并发症,对个人、家庭和社会造成巨大的经济负担。目前糖尿病已严重影响居民的健康与经济发展,糖尿病预测问题亟待解决。
现今,在人工智能及大数据技术高速发展下,越来越多的机器学习被运用到糖尿病研究之中。在糖尿病分类预测研究中[2-5],张玉玺和贺松等分别采用KNN、支持向量机、逻辑回归等单一算法及随机森林和投票法等复杂分析模型对糖尿病数据进行预测。他们的研究结果表明,选择准确率最高、AUC值最大的集成模型Voting作为最终的糖尿病数据预测模型。前人的研究为当下的研究提供了理论基础和先验知识,也为进一步的研究工作奠定了重要的前提条件。目前尚未发现一种普适的预测方法和理论,并且在将预测模型应用到系统研究方面的研究仍相对较少,因此它具有巨大的研究潜力。
本文以皮马印第安人糖尿病数据集为研究对象,结合机器学习算法的计算能力和预测优势,建立基于机器学习分类算法的预测模型,对糖尿病发病风险进行预测,为高危人群提供提前预警,辅助医生进行早期干预、诊断,从而降低糖尿病发病风险。
1 机器学习分类算法在糖尿病预测中的应用
机器学习分类算法在糖尿病风险预测中有着广泛的应用。这些算法可以通过分析患者的生理特征和病史等数据来建立糖尿病预测模型,实现对糖尿病的早期预测和筛查。常用的机器学习分类算法包括决策树、逻辑回归、XGBoost等。这些算法可以根据患者的年龄、性别、身体质量指数(BMI)、血压、血清化验数据等特征,预测患者罹患糖尿病的风险。
2 试验与检验
2.1 糖尿病数据集
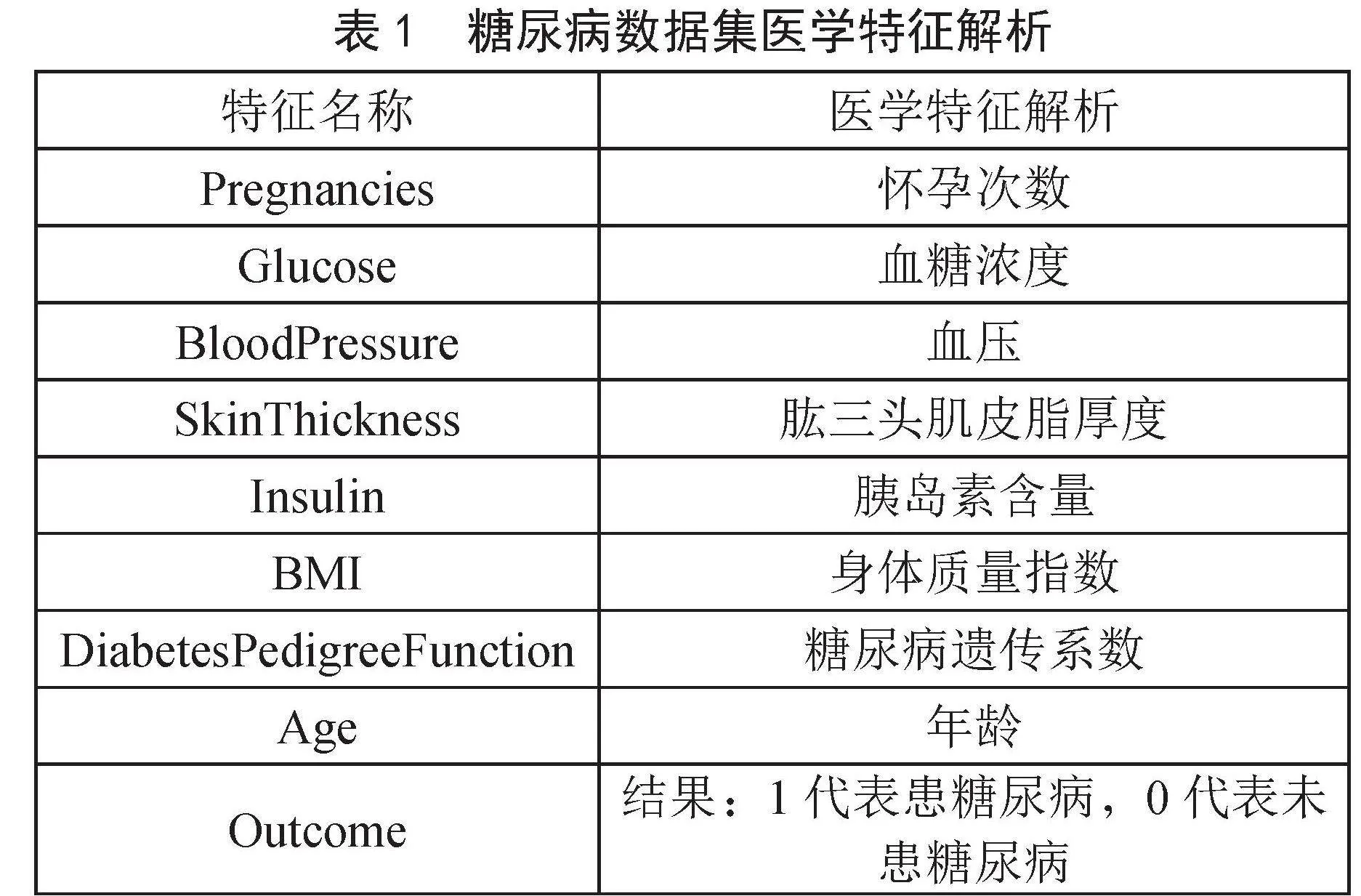
本研究选取在众多研究中被广泛使用的皮马印第安人糖尿病数据集(Pima Indians Diabetes Datasets, PIDD)[6]为研究对象,此数据集来源于美国国立糖尿病与消化及肾脏疾病研究所,这是一个权威的医学研究机构,所提供的数据具有很高的可靠性和可信度。糖尿病数据集共有768条数据项,包含8个医学预测变量和1个结果变量,其具体的医学特征属性如表1所示。
2.2 特征工程
特征工程是指利用领域知识从原始数据中提取特征的过程,目的是提高机器学习过程的结果质量。通过特征工程,可以从原始数据中提取出更具代表性和预测性的特征,从而提高模型预测的准确性和稳定性。本研究主要的特征工程有数据预处理和数据特征分析。
2.2.1 数据预处理
为提高糖尿病预测模型的性能和效果,需要对原始数据进行预处理,对不适合模型的数据或不准确的数据进行修改或删除,最终使得预处理完的数据符合模型的需求。数据预处理方式如下:
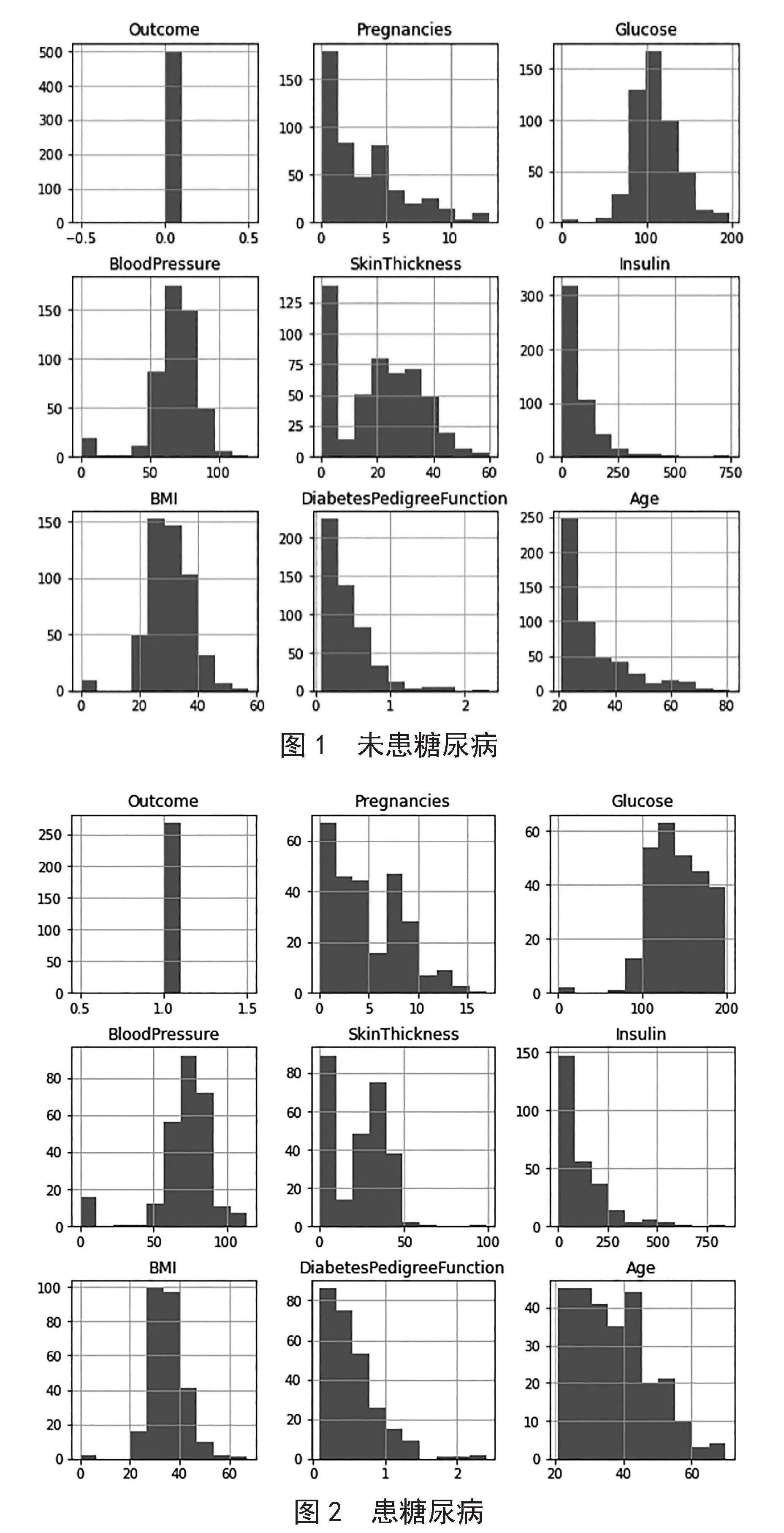
1)异常值处理。异常值是指数据集中与其他数值明显不同的数值,它们可能是因测量误差、数据录入错误造成的,也可能代表了真实但罕见的情况。处理异常值的目的是确保数据分析的准确性和可靠性,避免异常值对分析结果产生误导性影响。先通过pandas库中的groupby()函数对数据的分布特征进行分组,再通过Matplotlib库中的hist()函数绘制直方图进行数据可视化分析,如图1、图2所示。
通过图1和图2中的分布特征可以发现,血糖浓度和年龄对患糖尿病的影响比较大,而且可以发现一些异常值的存在,充分吸收医学知识后得知,血糖浓度、血压、BMI在正常情况下不会为0。因此将血糖浓度、血压及BMI中的异常值予以删除,去除掉异常数据后,数据集的总样本数为724条。
2)缺失值处理。缺失值处理是数据预处理的重要环节,对保证数据的完整性、准确性和可靠性至关重要。通过pandas库的read.csv()方法将数据导入,并打印出所有数据记录。在查看结果的过程中发现,Glucose、BloodPressure、SkinThickness、Insulin、BMI五个维度存在缺失现象,这显然是不符合实际情况的。设计使用pandas库的median()函数通过中值补全的方式将数据的缺失值补全。
3)数据规范化。由于糖尿病数据集中不同的特征具有不同的尺度和范围,为了使数据更适用于机器学习模型,需要对数据进行规范化。本研究中使用了Sklearn中的StandardScaler函数对数据进行标准化处理,最后对清洗后的数据进行保存。
2.2.2 数据特征分析
特征选择分析有助于挖掘特征之间的相关性和相互作用。本研究通过观察选定的特征集合来推断特征之间的关联性和相互影响程度,从而更好地理解数据的结构和模式。通过对特征选择的特征进行分析可以提供有关特征的重要信息,帮助优化模型、改善特征工程、提高模型的准确性和解释性,以及简化模型的复杂性。
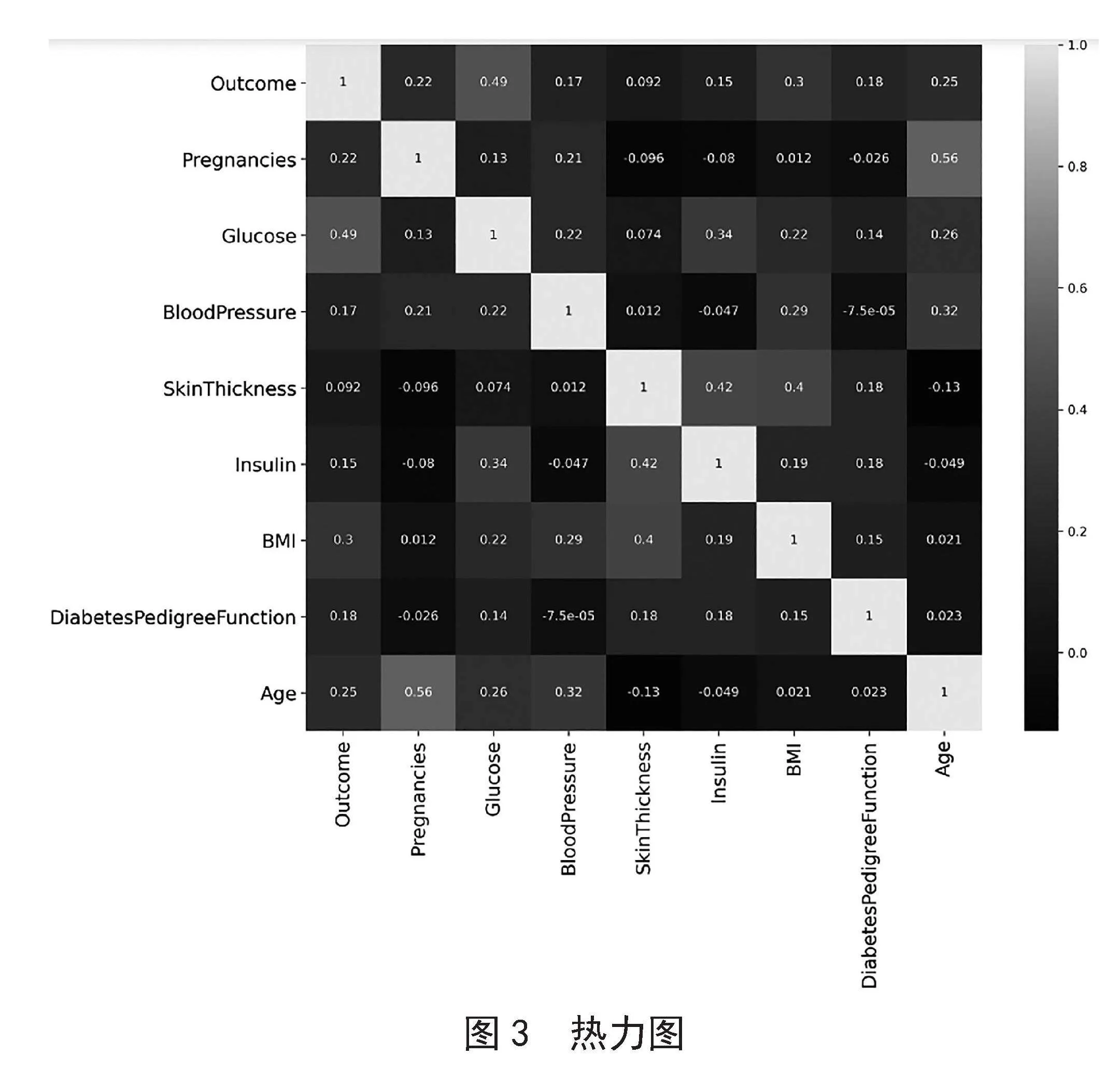
特征选择分析有助于分析糖尿病特征之间的相关性。分别使用Matplotlib库以及Seaborn库的figure()函数和heatmap()函数来创建一个热力图,以观察糖尿病影响因素之间的相关性,如图3所示。
从图3中可以看出,糖尿病患病率与血糖浓度的相关性最大,与皮肤厚度不相关;相关性排在其次的是年龄与怀孕次数。值得关注的是,糖尿病患病率与年龄的相关性并不是很大,甚至低于BMI,由此可以总结出健康饮食、适度运动的重要性。
2.3 糖尿病预测模型创建与效果评价
本研究使用糖尿病原始数据集经过预处理的724条样本数据,进行训练集和测试集的划分,采用网格搜索方法GridSearchCV进行交叉验证,寻找算法的最佳参数组合来构建超参数,使用决策树、逻辑回归、XGBoost等六种算法建立基于训练集的糖尿病风险预测模型,进而通过测试集来计算准确率、精准率、召回率、F1-score和AUC值这五个指标,以此验证六种算法模型的效果,最后通过实验结果对比分析来预测模型效能。
2.3.1 建立训练集和测试集
建立训练集和测试集是机器学习和数据挖掘中的一种常用技术,它的主要目的是评估和验证模型的性能以及避免过拟合。它可以帮助我们选择最佳模型,避免过拟合,以及进行参数调优。
本文使用Python的Sklearn库的train_test_split()函数来将75%的数据划分作为训练集,剩下25%的数据作为测试集。
2.3.2 网格搜索方法
网格搜索(GridSearchCV)是一种常用的调参手段,是一种穷举方法[7]。它是通过交叉验证的方法来对估计函数的参数进行优化得到最优的学习算法。由于糖尿病原始数据集经过处理后的糖尿病最终数据集的样本量不多,而且特征维度也不高,故本文采用网格搜索方法在预测模型的训练集上使用交叉验证,遍历所有可能的参数组合,寻找最佳的参数组合,得到算法的超参数,使用超参数训练模型,提升糖尿病预测模型的分类性能。
2.3.3 机器学习模型的建立和分析
决策树是一种非参数的有监督学习方法[8],较常应用于分类和回归问题。决策树算法之所以广泛应用于糖尿病风险预测,是因为它能够根据不同的特征点信息对数据集进行划分,最终得到一棵树形的分类模型。本文通过Python中Sklearn库的tree模块中的DecisionTreeClassifier模型进行数据集的训练和测试。采用网格搜索方法计算决策树预测模型主要参数的最佳数据值组合,程序如下所示:
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
param_grid = {
criterion: [gini, entropy],
max_depth: [3, 5, 7, 10],
min_weight_fraction_leaf: [0.01, 0.02, 0.03]
}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("Best parameters found: ", grid_search.best_params_)
print("Best accuracy: ", grid_search.best_score_)
程序运行结果为模型最优超参数,具体指标如下:
1)criterion。这个参数指定了用来衡量特征重要性的标准,Sklearn提供两种选择方式,分别是基尼系数(gini)和信息熵(entropy)。本研究设置为entropy。
2)max_depth。这个参数指定了树的最大深度,即决策树允许生长的最大层数。将其设置为10时模型表现最佳。
3)min_weight_fraction_leaf。这个参数指定了叶子节点中样本权重的最小加权和。将其设置为0.03时模型表现最佳。
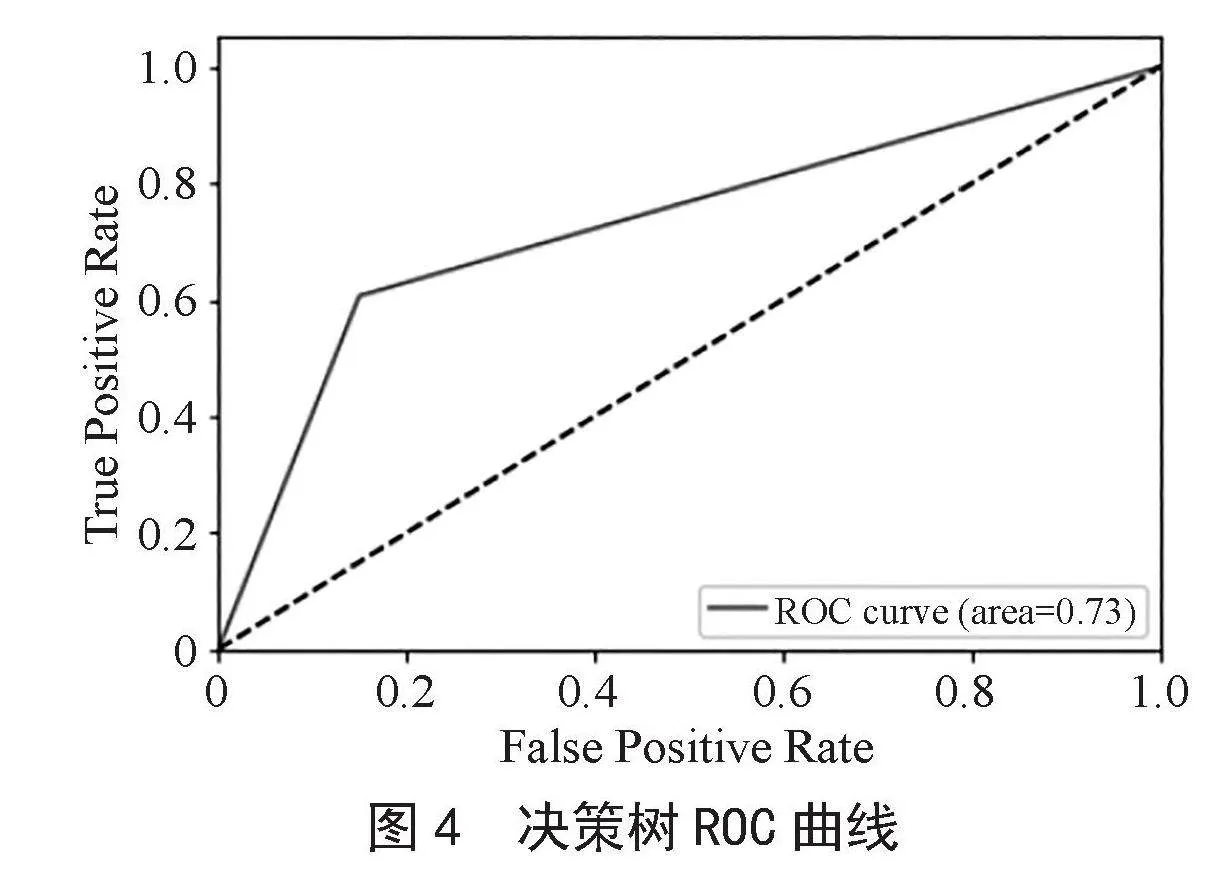
经调参后,使用最优超参数重新训练决策树模型,并对模型的准确率、精准率、召回率、F1-score和AUC值进行计算评价并绘制ROC曲线。决策树评估指标表如表2所示。
由表2可知,决策树模型在测试集上的F1-score值为0.637 9,AUC值为0.728 2,说明决策树模型的分类能力和泛化能力良好。ROC曲线(Receiver Operating Characteristic Curve)是二分类模型性能评估的常用工具。模型的性能越好,ROC曲线越靠近左上角。由图4可以看出,ROC曲线较靠近左上角,决策树模型的性能良好。
2.3.4 逻辑回归的构建和分析
逻辑回归算法适用于二分类和多分类问题,它具有模型简单、易于实现和解释的特点,同时也可以处理大规模数据集[9]。本文通过Python的Sklearn库的linear_model模块中的LogisticRegression模型进行数据集的训练和测试。采用网格搜索方法计算逻辑回归预测模型主要参数的最佳值组合,关键程序如下所示:
classifier =LogisticRegression(random_state=0)
param_grid = {
max_iter:[1000,10000],
C: [0.01, 0.2, 1, 10]}
grid_search = GridSearchCV(estimator=classifier, param_grid=param_grid, cv=5, scoring=acckTscns/5aqhsKcaYSlWGJw==uracy)
grid_search.fit(X_train, y_train)
程序运行结果为逻辑回归预测模型优化后的超参数,具体参数及意义如表3所示。
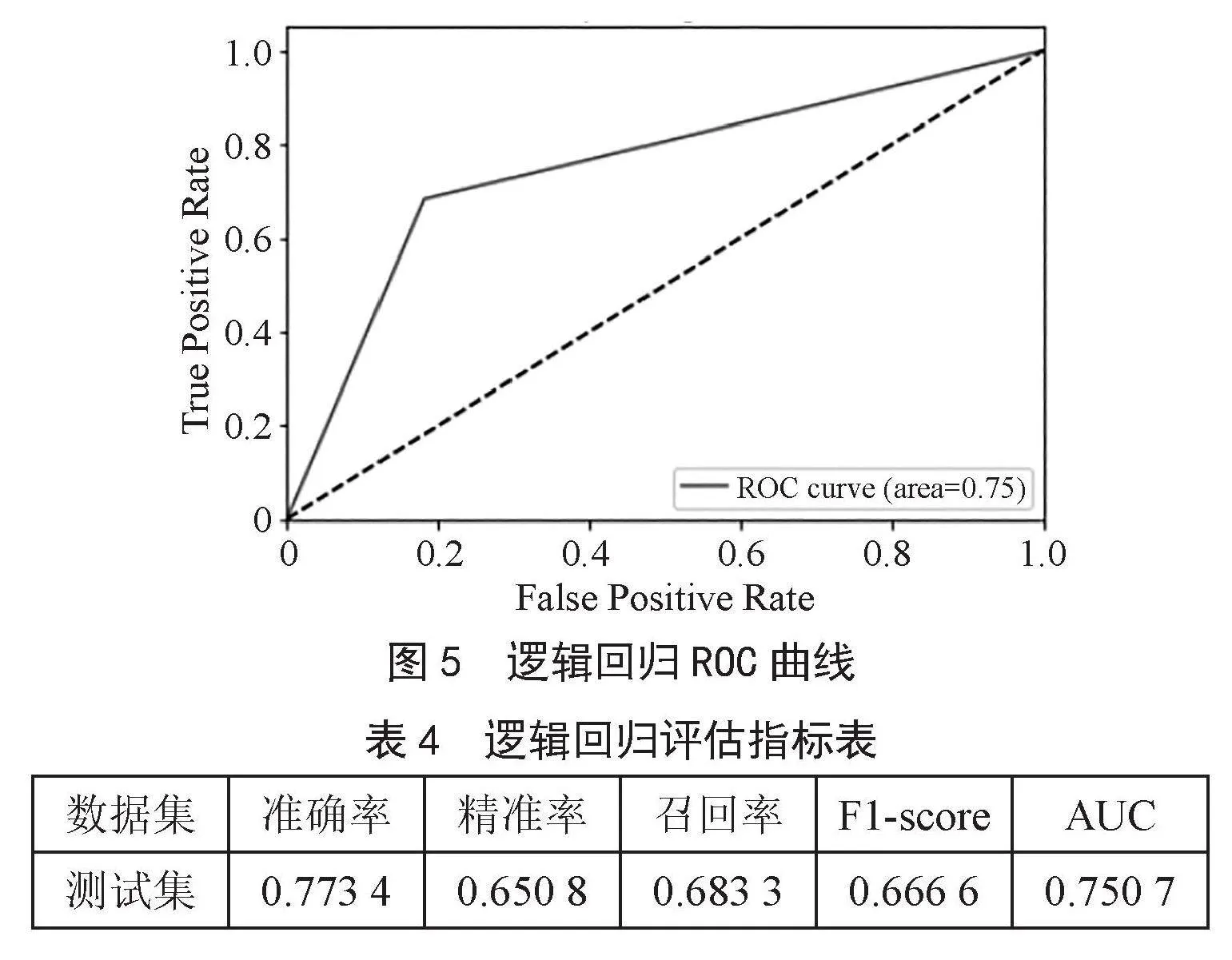
经调参后,使用最优超参数重新训练逻辑回归模型,对逻辑回归模型的准确率、精准率、召回率、F1-score和AUC值进行计算评价并绘制ROC曲线,如图5所示。逻辑回归评估指标表如表4所示。
由表4可知,逻辑回归模型在测试集上的准确率达到0.773 4,AUC在测试集上的准确率达到了0.750 7,相较于决策模型略有提升,说明逻辑回归模型有较好的分类效果和泛化能力。由逻辑回归模型的ROC曲线可知,逻辑回归模型性能良好,较为稳定。
2.3.5 XGBoost的构建和分析
XGBoost(eXtreme Gradient Boosting)是一种基于决策树模型的集成学习算法,它在Kaggle等数据科学竞赛中表现出色,并且在实际应用中也取得了不错的效果。其核心思想是利用损失函数的负梯度值作为当前拟合模型的残差近似值来实现精准的分类效果[10]。
本文使用XGBoost库中的XGBClassifier模型进行数据集的训练和测试。采用网格搜索方法计算XGBoost预测模型主要参数的最佳值组合,关键程序如下所示:
classifier = XGBClassifier()
param_grid = {
learning_rate: [0.01, 0.1, 0.5],
max_depth: [5, 10, 15],
n_estimators: [100, 500, 1000],
reg_alpha: [0, 1, 3],
reg_lambda: [1, 3, 6]}
grid_search = GridSearchCV(estimator=classifier, param_grid=param_grid, cv=5, scoring=accuracy)
grid_search.fit(X_train, y_train)
程序运行结果为XGBoost预测模型优化后的超参数,具体参数及意义如表5所示。
经调参后,使用最优超参数重新训练XGBoost模型,对模型的准确率、精准率、召回率、F1-score和AUC值进行计算评价并绘制ROC曲线。XGBoost模型评估指标表如表6所示。
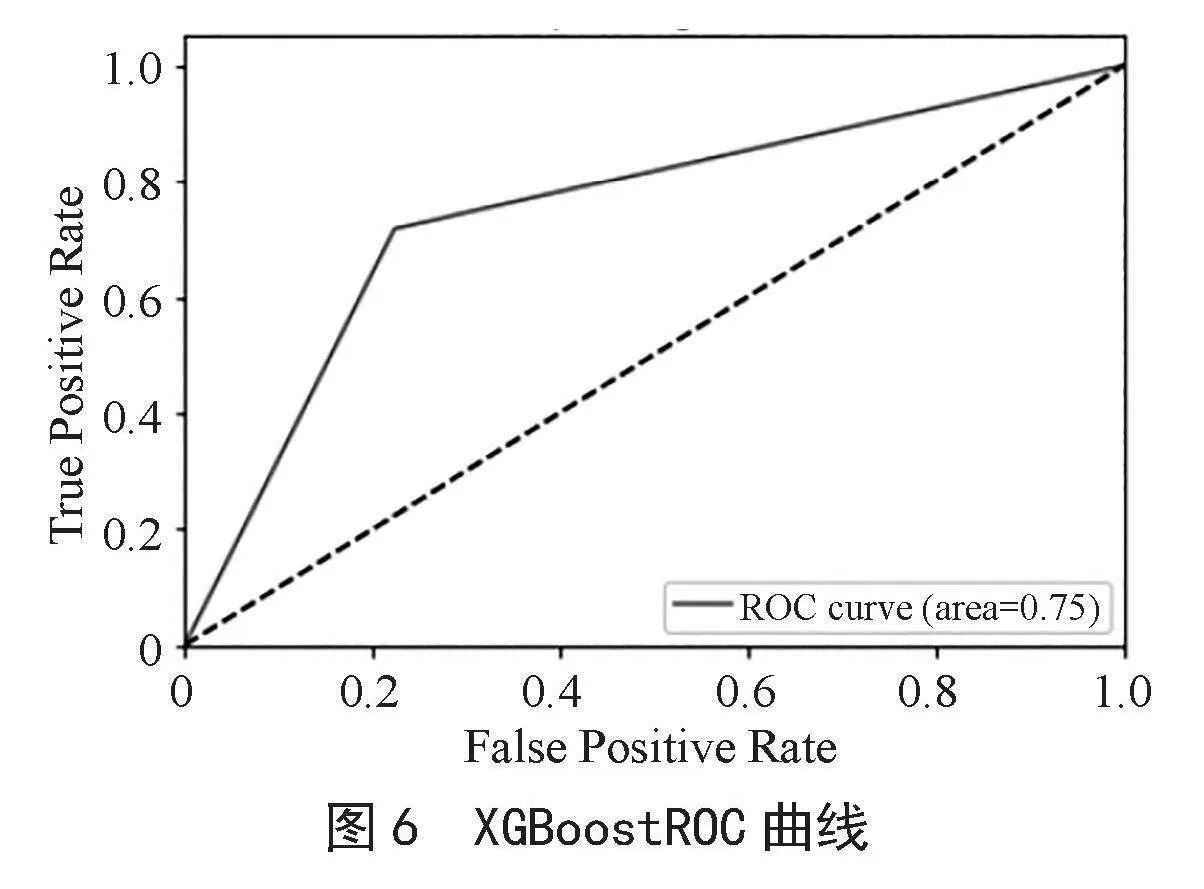
由表6可知,XGBoost模型测试集的召回率为0.716 6,比逻辑回归模型的0.683 3略有提升,而且测试集上的AUC值达到了0.746 7,说明XGBoost模型有较好的分类效果和泛化能力。由如图6所示XGBoost模型的ROC曲线图可以看出,XGBoost模型的性能良好,较为稳定。
以同样的方法构建随机森林模型、K最近邻模型、神经网络模型等模型,得到六种糖尿病预测模型的性能指标。
3 实验结果分析
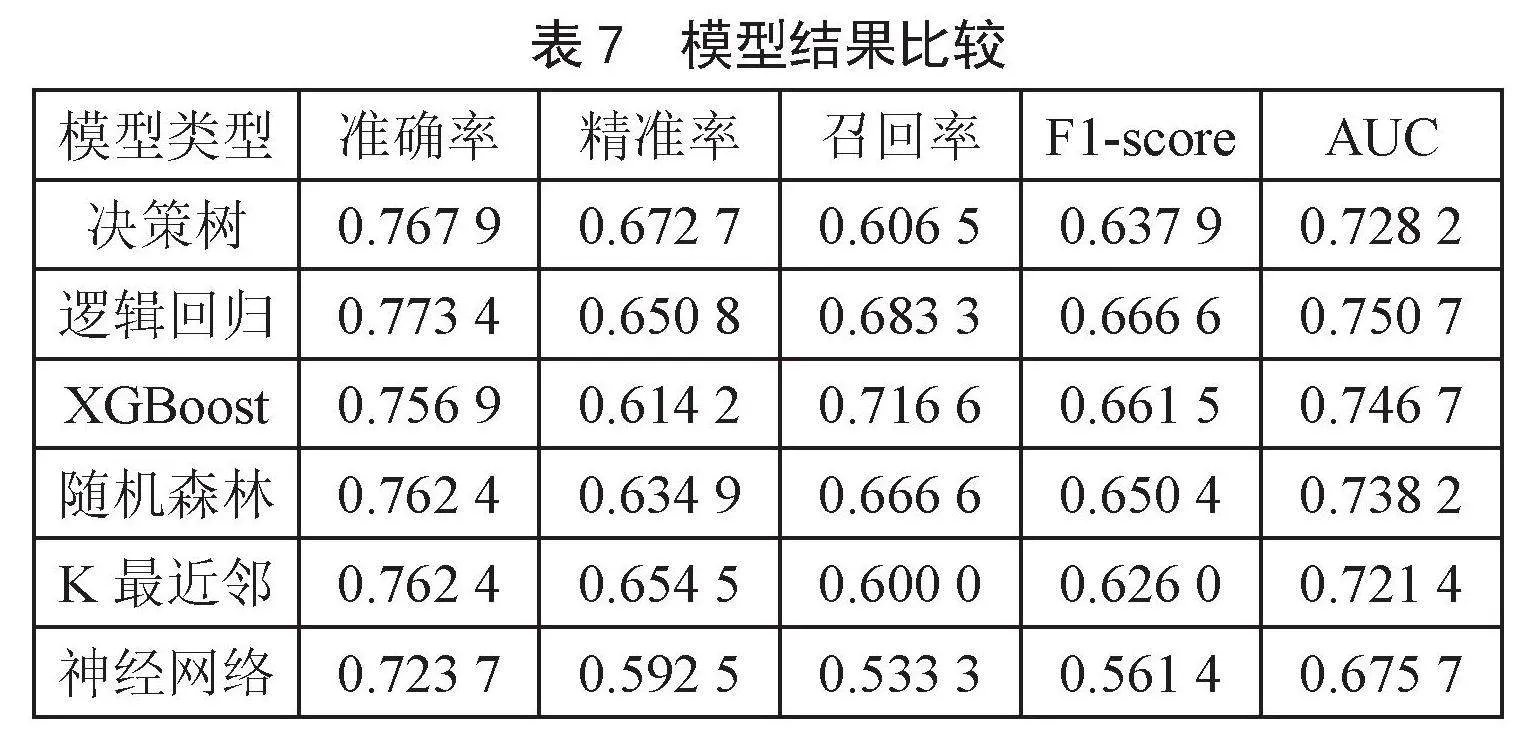
通过决策树模型、逻辑回归模型、XGBoost模型、随机森林模型、K最近邻模型、神经网络模型对测试集进行糖尿病风险预测,本研究中的测试集占原始数据的25%,运行得到的结果如表7所示。
由表7可以看出,在测试集上的预测结果分析对比发现,在模型的准确率、F1-score、AUC三个方面,逻辑回归模型均高于其他五个模型,说明逻辑回归模型在糖尿病预测的二分类问题上具有较高的稳定性和准确率,分类能力较好;决策树模型的准确率和精准率均优于其他五个模型;XGBoost模型的召回率均优于其他五个模型。
4 结 论
本文构建了基于多种机器学习算法的预测模型,可应用于根据用户输入的特征数据进行糖尿病风险预测。该模型以皮马印第安人糖尿病数据集为研究对象,通过数据预处理技术得到724条有效数据集,通过数据特征分析得出糖尿病患病率与血糖浓度的相关性最大,与皮肤厚度不相关,相关性排在其次的是年龄与怀孕次数。采用网格搜索方法进行交叉验证以寻找算法的最佳参数组合超参数,使用超参数建立基于决策树、逻辑回归、XGBoost等六种分类算法的预测模型。最后使用测试集进行预测模型的预测性能评价,通过对模型准确率、精准率、召回率、F1-score、AUC等指标的分析,发现使用决策树算法构建的模型取得的预测结果准确率最高,使用逻辑回归模型预测糖尿病则有较好的分类能力和较高的稳定性。
参考文献:
[1] 王富军,王文琦.《中国2型糖尿病防治指南(2020年版)》解读 [J].河北医科大学学报,2021,42(12):1365-1371.
[2] 张玉玺,贺松,尤思梦.集成学习糖尿病预测中的应用 [J].智能计算机与应用,2019,9(5):176-179.
[3] 欧阳平,李小溪,冷芬,等.机器学习算法在体检人群糖尿病风险预测中的应用 [J].中华疾病控制杂志,2021,25(7):849-853+868.
[4] 王鑫,廖彬,李敏,等.融合LightGBM与SHAP的糖尿病预测及其特征分析方法 [J].小型微型计算机系统,2022,43(9):1877-1885.
[5] 刘睿懿,曲翌敏,刘璇,等.集成学习和决策树在2型糖尿病前瞻性风险评估中的应用 [J].中国慢性病预防与控制,2023,31(4):278-283+288.
[6] 柴鑫,王雅晨,王金平,等.糖尿病预防研究的创举:大庆糖尿病预防研究36年回顾 [J].科学通报,2023,68(Z2):3834-3845.
[7] 马良玉,于世磊,赵尚羽,等.基于随机搜索算法优化XGBoost的过热汽温预测模型 [J].华北电力大学学报:自然科学版,2021,48(4):99-105.
[8] 蒲海坤,高鑫,桑鑫.基于C4.5数据挖掘算法研究与实现 [J].科学技术创新,2021(23):55-56.
[9] 张小雪,张祖婷,刘莉,等.基于决策树和逻辑回归算法的辅具适配模型研究与实现 [J].中国康复医学杂志,2023,38(8):1108-1113.
[10] 张春富,王松,吴亚东,等.基于GA_Xgboost模型的糖尿病风险预测 [J].计算机工程,2020,46(3):315-320.
作者简介:凌雄娟(1980—),女,汉族,广东廉江人,高级工程师,硕士,研究方向:人工智能、数据分析与应用。
收稿日期:2024-01-22
基金项目:广东省普通高校创新团队项目(2022KCXTD060);佛山市教育局2021年高校教师特色创新研究项目(2021DZXX02);佛山职业技术学院2023年质量工程项目(2023SZTD-004)