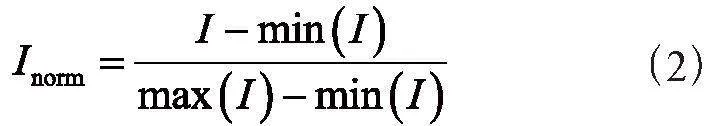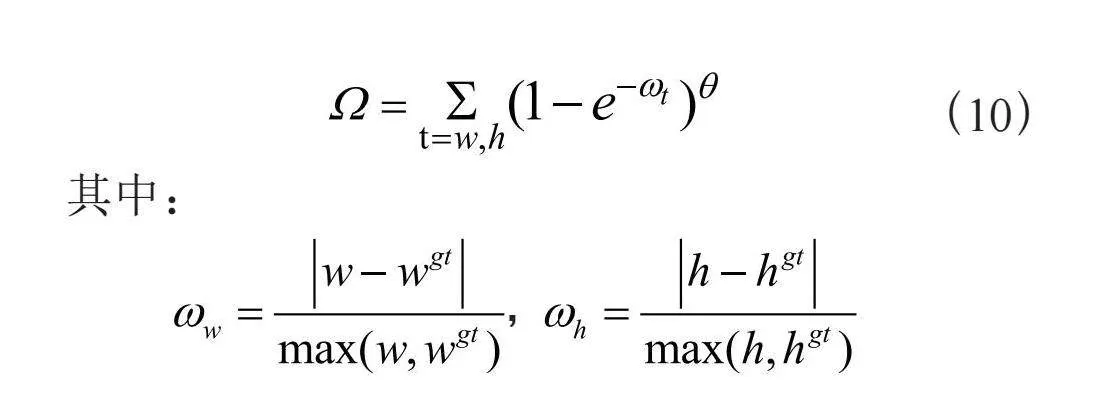









摘 要:球类运动是传统体育竞技中受关注度最高的一类运动,球类的目标检测可以用于提高体育比赛的分析、监控系统的安全性以及虚拟现实体验的真实感。YOLOv5作为优秀的单阶段检测算法,因其平台移植方便与检测步骤简易,是计算机视觉领域近年来使用频率最高的目标检测算法之一。但是YOLOv5模型参数量较大,为了减少参数量以便更快地移植到其他平台上,文章提出一种轻量化的改进YOLOv5算法,该算法以YOLOv5s为基础模型,通过将主干网络替换为改进的MobileNetv3、在颈部引入CBAM注意力机制并改进C3模块等方法,减少计算量并提升精度。对训练完成后的改进模型进行验证,实验结果表明改进后的检测算法参数量大致下降了65%,平均精度提升了0.5%,满足乒乓球实际应用场景的精度要求和实时性。
关键词:目标检测;YOLOv5;轻量化;CBAM
中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2024)15-0028-08
Lightweight Network Detection Model for Table Tennis Balls Based on Improved YOLOv5
SHI Bokai, ZHANG Xin, QIU Tian, ZHANG Zhipeng
(Joint Laboratory of Digital Optical Chips of Institute of Semiconductors, Chinese Academy of Sciences, Wuyi University, Jiangmen 529020, China)
Abstract: Ball games are the most popular sports in traditional sports competitions, and the target detection of balls can be used to improve the analysis of sports games, the security of surveillance systems, and the realism of Virtual Reality experiences. YOLOv5, as an excellent single-stage detection algorithm, is one of the most frequently used target detection algorithms in the field of computer vision in recent years due to its easy platform portability and simple detection steps. However, the YOLOv5 model has a large number of parameters. In order to reduce the number of parameters so that it can be ported to other platforms faster, this paper proposes a lightweight and improved YOLOv5 algorithm, which takes YOLOv52395b4ddc55a28d19b6190958f5a446bcbfcd3a5259b578efb97ce1a4a0f23e0s as the base model, and reduces the amount of computation and improves the accuracy by the methods of replacing the backbone network with the improved MobileNetv3, introducing the CBAM Attention Mechanism in the neck, and improving the C3 module. The improved model is verified after the training, and the experimental results show that the number of parameters of the improved detection algorithm roughly decreases by 65%, and the average accuracy improves by 0.5%, which meets the accuracy requirements and real-time performance of practical application scenarios for table tennis.
Keywords: target detection; YOLOv5; lightweight; CBAM
0 引 言
YOLO作为第一个基于深度学习的单阶段检测方法,其采取与两阶段算法截然不同的检测方式:将单个神经网络应用于完整图像,该网络将图像划分为多个区域,并预测每个区域的边界框和目标分类。虽然与两阶段算法相比定位精度有所下降,但是原作者在基础上做了一系列改进,先后提出了YOLO9000[1]、YOLOv3[2],增加了FPN等结构来改进损失函数。随后提出的YOLOv4整合了计算机视觉领域的多种数据增强方法,并尝试了各种新的主干网络组合,在速度和准确性方面优于大多数先有的目标检测方法[3]。近年来由于YOLO系列算法的快速发展与广泛应用,越来越多的学者在目标检测方面的研究进展集中在YOLO算法的改进优化上,例如文献[4]在YOLOv4算法的基础上改进损失函数并使用快速NMS算法从而进行对乒乓球的检测,平均精度达到94.12%,但帧率仅为39.34;文献[5]使用改进的YOLOv4算法,采用加强特征提取网络的方法,使乒乓球的平均精度达到94%,而帧率提升到95。
上述提及的YOLOv4改进算法虽然实现了乒乓球检测,但实验场景较为单一,在实际应用中需要全面考虑精度与处理速度。YOLOv5是YOLO系列中综合性能较为优秀的一个目标检测模型,广泛应用于诸如自动驾驶、智能监控、医学图像等[6-8]领域。本文以YOLOv5s算法为基础,提出一种轻量化的乒乓球检测算法,大幅度降低参数量,有效地提升平均精度和检测帧率。
1 YOLOv5s模型
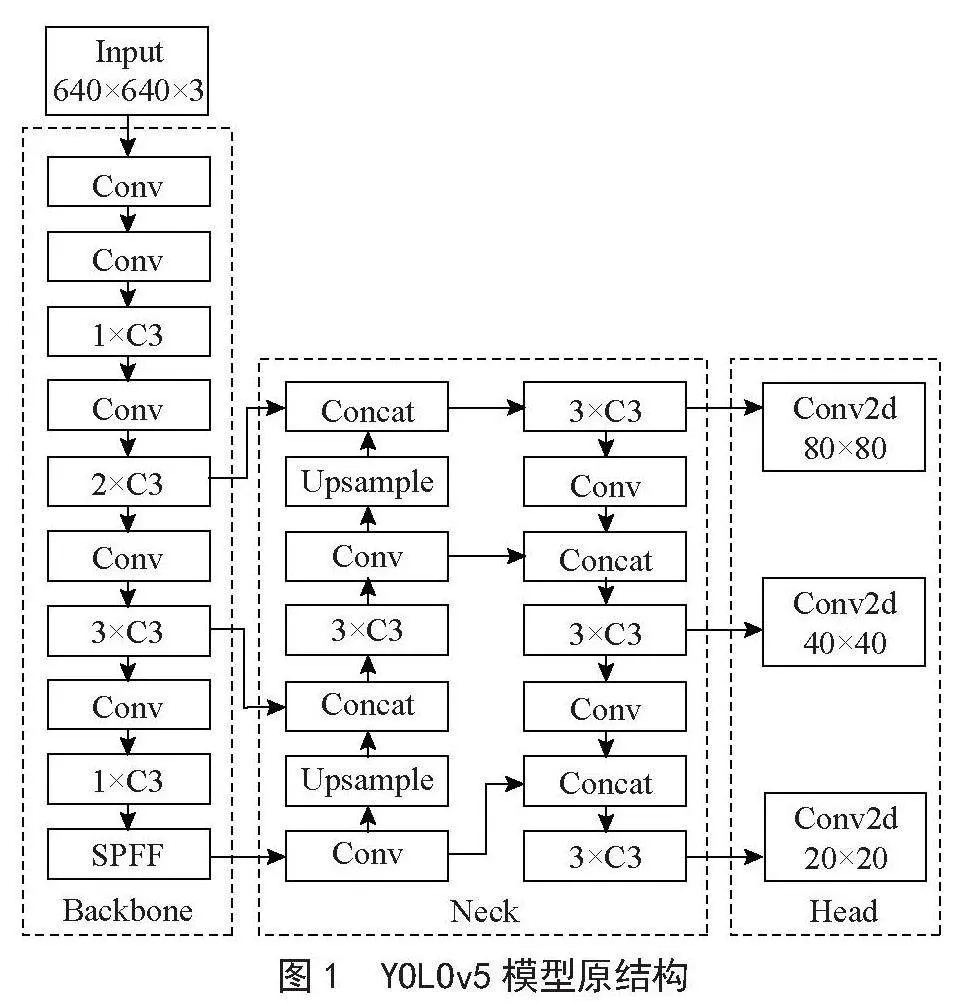
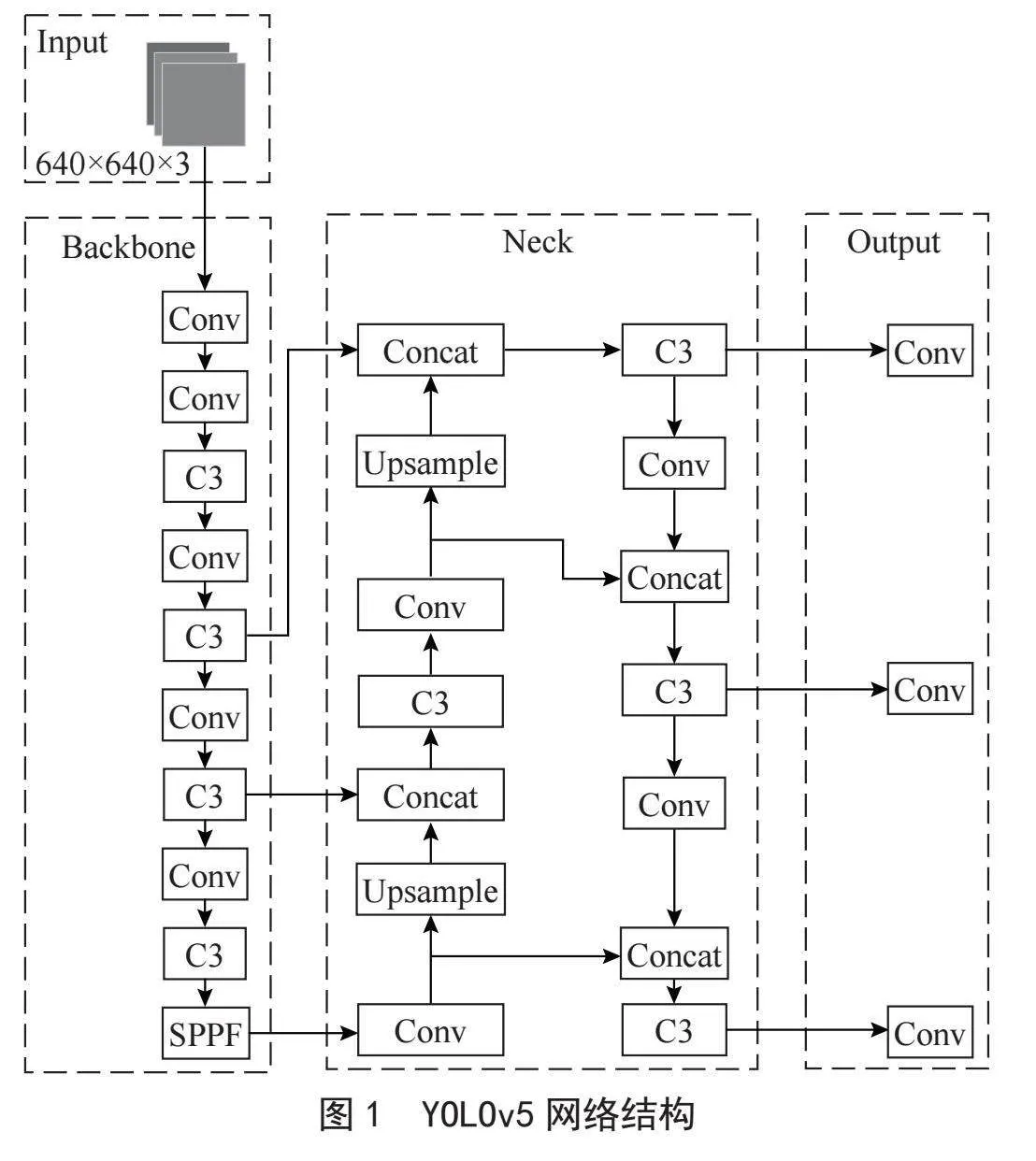
YOLOv5的网络结构如图1所示,分为输入端(Input)、主干网络(Backbone)、颈部网络(Neck)、头部网络(Head)。相比于YOLOv4,YOLOv5在输入端提出了一些改进思路,主要包括自适应锚框计算、Mosaic数据增强机制、自适应图片缩放等方法;Backbone为主干网络,由Downsample Conv、C3、SPPF三种模块堆叠而成,特征图经过卷积层,通过C3模块生成不同尺寸的特征图,之后通过SPPF融合不同感受野的特征图,此部分网络主要负责特征提取;Neck部分参考PANet网络[9],采用FPN+PAN结构,FPN[10]结构通过自顶向下进行上采样,使得底层特征图包含图像强语义信息,PAN[11]结构自底向上进行下采样,使顶层特征包含图像强定位信息,两个特征最后进行融合,使不同尺寸的特征图都包含图像语义信息和图像定位信息,提升网络特征的融合能力。Head部分由三个不同特征尺度的预测层组成,分别为80×80、40×40、20×20,用于预测大型、中型、小型目标。
2 改进的YOLOv5s检测算法
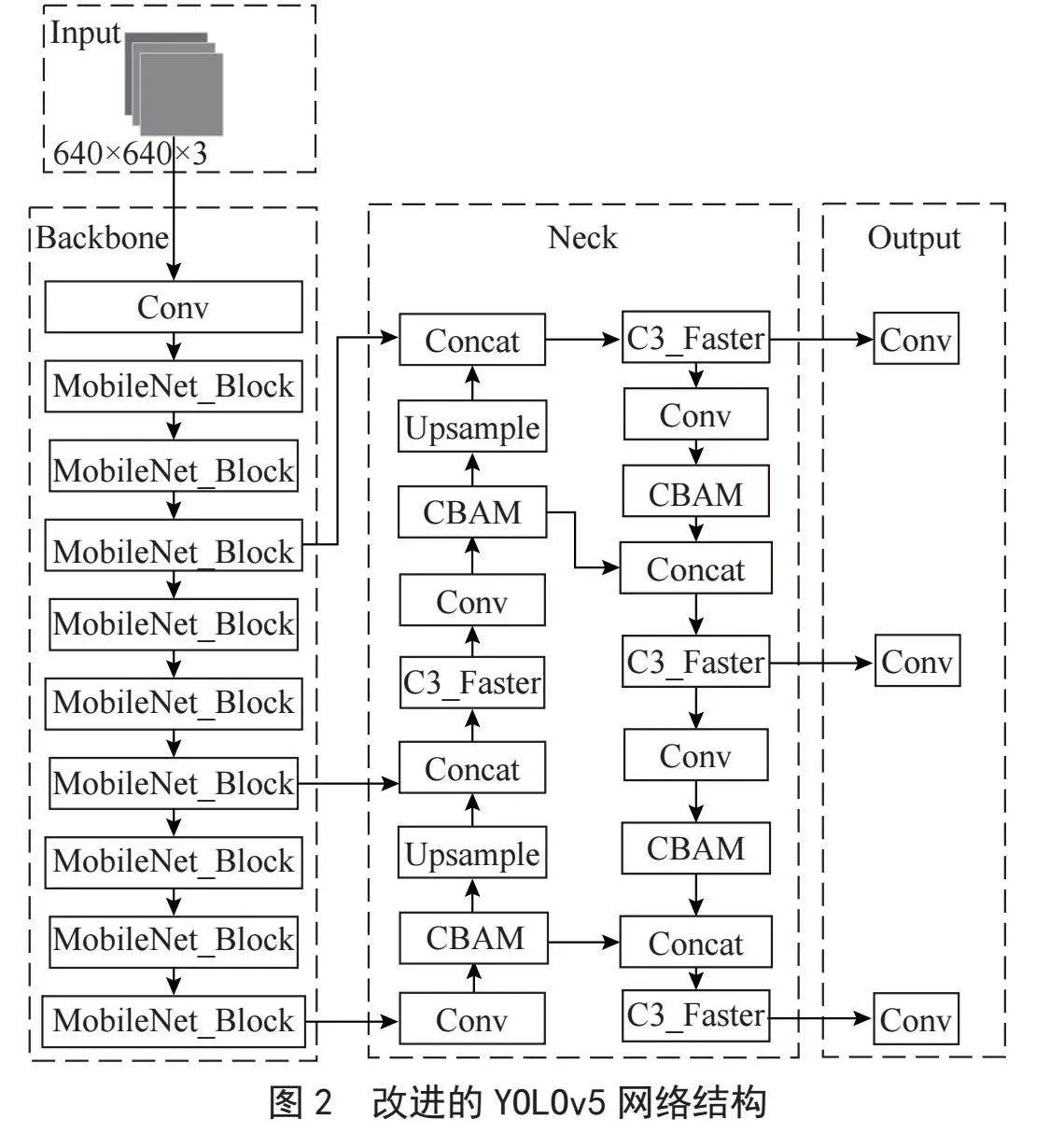
为了实现高实时性的乒乓球目标检测,本文对YOLOv5s检测算法进行优化改进,如图2所示,改进方法分别为:
1)采用MobileNetv3[12]网络替换主干网络,并将其中的SE注意力模块替换为ECA注意力模块,降低参数量,增强网络对局部特征的关注。
2)为了减少计算冗余和内存访问,将颈部的C3模块融合FasterNet[13]网络,使用FasterNet中的PConv替换普通卷积层。
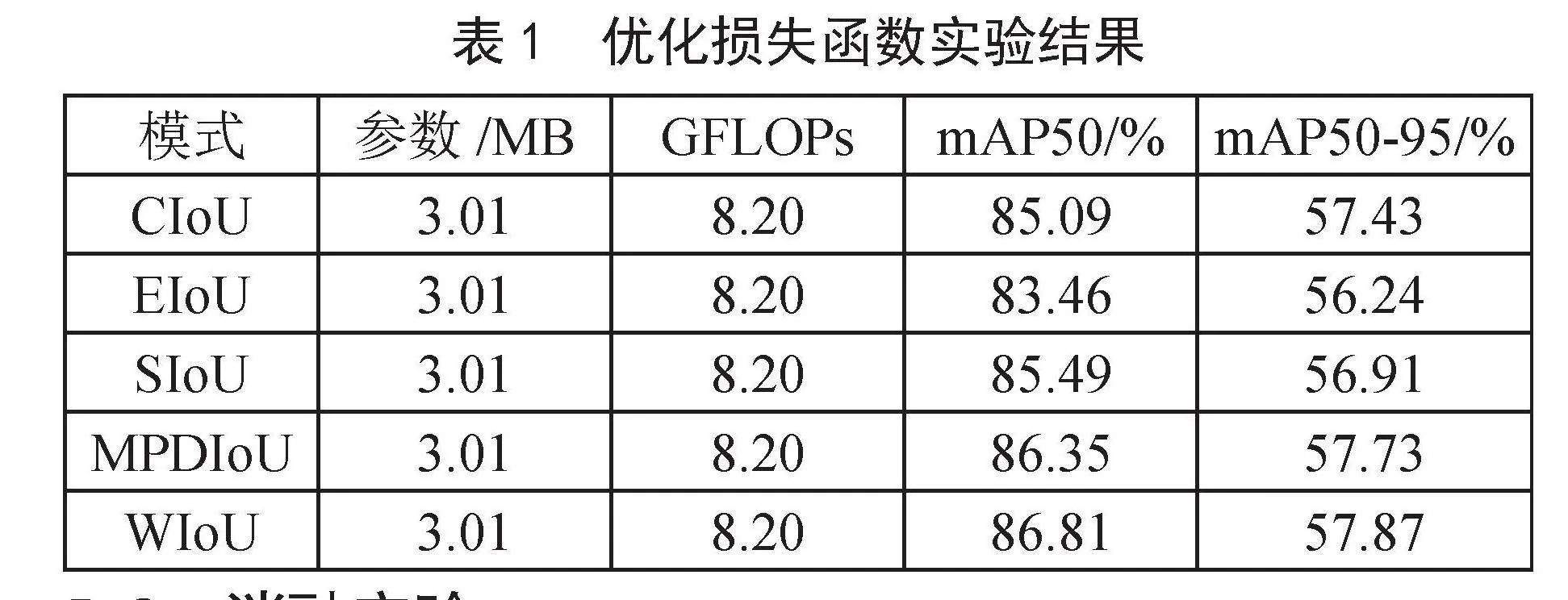
3)选择SIoU替换YOLOv5s的CIoU,提升精度。
4)引入CBAM注意力机制,通过加强对输入特征图中的重要特征进行更优秀的表示,通过全局池化操作获得了整体描述信息,从而增强了对整体信息的识别和理解能力。
2.1 MobileNetv3
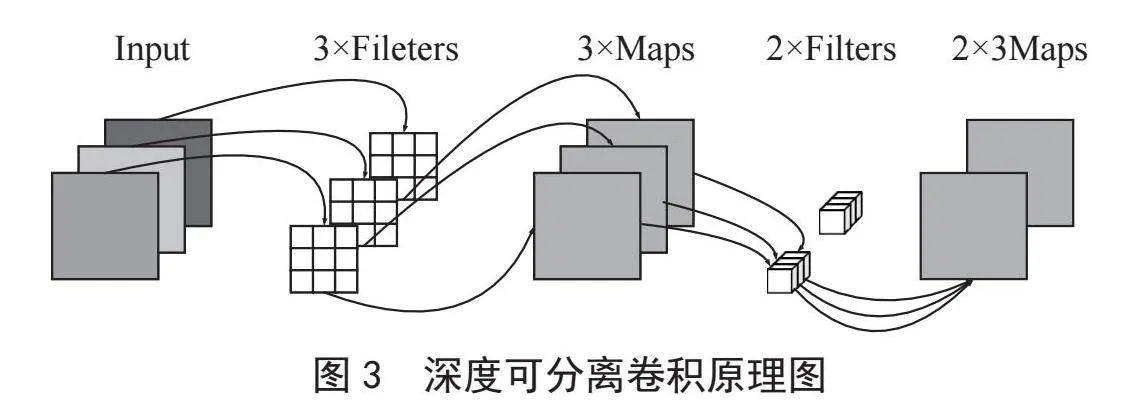
为了降低YOLOv5s检测算法的复杂度并减少参数量,提升模型的检测速度与性能,本文选择MobileNetv3网络替换主干网络,并使用ECA注意力机制替换MobileNetv3的SE[14]模块。MobileNetV1[15]引入了深度可分离卷积(Depthwise Separable Convolution)替代标准卷积,通过深度卷积(Depthwise Convolution, DWConv)和逐点卷积(Pointwise Convolution, PWConv)的结合减少了模型的参数量,如图3所示。
MobileNetV3网络继承了MobileNetV1[15]的深度可分离卷积和MobileNetV2[16]的线性瓶颈逆残差结构的特点,且在MobileNetV2的基础上引入了SE[14]模块,使用改进的Hard-swish激活函数代替原来的Swish函数升级非线性层,并利用NetAdapt算法搜索和优化卷积内核和通道的数量。
2.2 ECA注意力机制
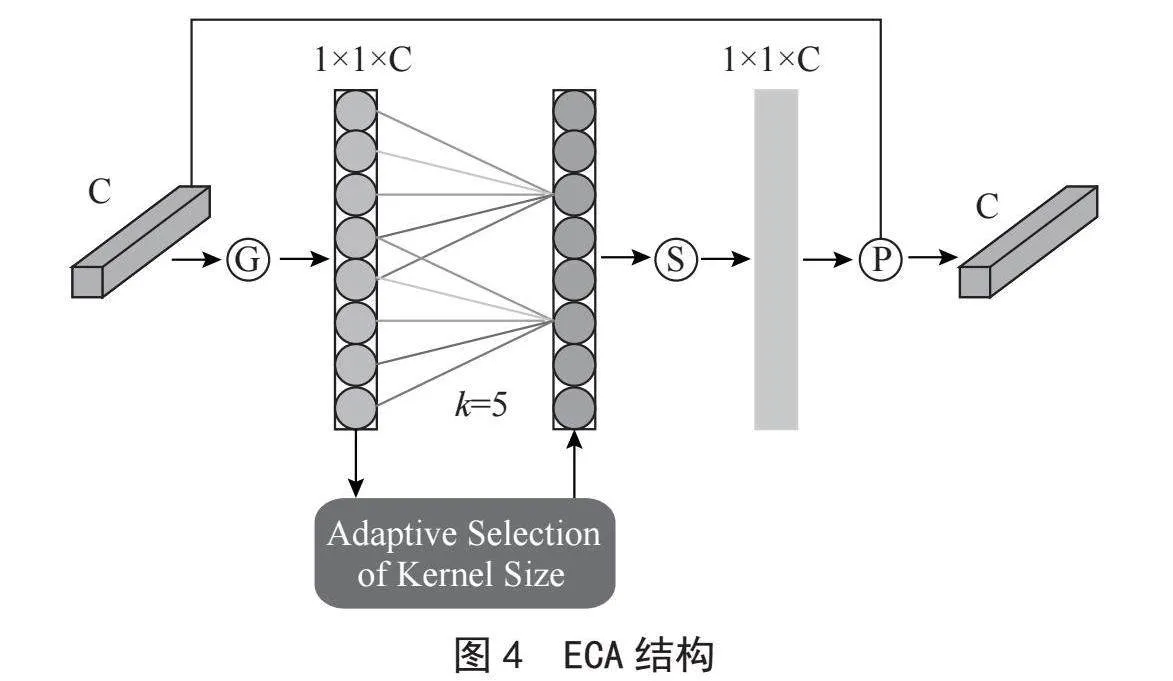
注意力机制是深度学习中的一种关键技术,用于模型处理输入数据时,选择性地偏向于某一部分,它模拟了人在处理信息时的注意力分配方式。ECA注意力机制[17]通过获取跨通道交互的信息,即通道之间的依赖关系,并获得明显的性能提升。ECA使用卷积核大小为k的一维卷积代替全连接层对k个近邻范围进行通道加权,实现局部交叉和通道交互,从而增强网络对局部特征的关注。ECA的结构如图4所示,其中,G表示全局平均池化(Global Average Pooling),S表示Sigmoid激活函数,P表示点乘(Position-wise Dot Product)。给定单个输入图像I(C,H,W),其中C表示通道数,H表示特征图的高度,W表示特征图的宽度,将输入特征图进行全局平均池化操作,以获取每个通道的全局上下文信息,如式(1)所示:
(1)
上式中,Icij表示特征图I中通道C的第(i,j)个元素,式(1)的输出是一个C维度的向量,反映每个通道的平均响应。
在ECA中,卷积核的大小k是自适应确定的,这种特性使得能够适应不同数量的通道,更有效地获取通道间的局部依赖关系,卷积核大小k的计算方式如下:
(2)
式(2)中,todd表示距离k最近的奇数,γ表示控制局部依赖关系范围的参数,γ越小则卷积核k越大,b、γ通常设置为1和2,用于改变卷积核大小和C之间的比例。
通过一维快速卷积获取通道间的局部依赖关系,一维卷积的输出设为y,将一维卷积操作记为Tconv1D。公式如下:
(3)
一维卷积的输出经过Sigmoid激活函数记性非线性变换以提升通道间相关性的自适应学习,得到各个通道的权重ω,计算方式如下:
(4)
最后,将式(4)所得权重与原始输入特征图I,得到最终输出特征图,将结果记为Zcij,如式(5)所示:
(5)
ECA注意力机制通过获取通道间的依赖关系来增强卷积神经网络的特征表示,避免特征完全独立,以高效率与低参数量的特性,使其在目标检测和图像分割任务中被研究人员广泛应用,在本文中用于替换MobileNetV3网络中的SE注意力模块。
2.3 MobileNetV3的改进
MobileNetV3网络结构的Bneck模块中引入了SE注意力机制,这个注意力机制强调降维的关键性,因为它对于有效学习通道注意力至关重要。SE模块的全连接降维虽然有助于减少模型的复杂性,但它会破坏通道和权重之间的直接对应关系。通过先降维后升维,导致权重和通道之间的对应关系变得间接化。
在降低模型复杂度的同时,必须确保进行适当的跨通道交互,以保持性能水平的提高。本文采用不降维的局部跨通道交互策略ECA模块,替换原网络Bneck中的SE模块。ECA模块的优点在于它可以保持通道维度不变,同时引入逐通道全局平均池化,这样就能够捕获局部跨通道的信息交互,而无须增加通道的数量。这种方法允许每个通道考虑其相邻的K个通道,从而避免了特征之间完全独立的情况,确保权重与通道之间的关系保持直接的关联,维护模型性能的同时,减少了冗余的复杂性。
2.4 损失函数的改进
YOLOv5的损失函数包括分类损失、定位损失、置信度损失。在定位损失方面,YOLOv5s选择CIoU[18]作为定位损失函数。相比于传统的IoU,CIoU考虑了两框之间的中心点距离、宽度和高度差、重叠面积,使其对于边界框位置的变化不敏感。传统IoU对于位置稍有不同的边界框可能会导致显著不同的IoU值,而CIoU能够提供更稳定的度量。虽然CIoU在IoU的基础上更关注两框之间的中心点距离、重叠区域和纵横比等参数,但是没有考虑期望的两框之间不匹配的方向,导致效率低且收敛速度慢,因为预测框在训练过程中可能会存在“漂移”现象,结果产生一个不理想的模型。SIoU[19]提出了一种新的损失函数,重新定义了惩罚系数,考虑了两框之间的向量夹角,进一步减小了边界框大小的影响,从而提高了对不同尺度目标的检测性能。
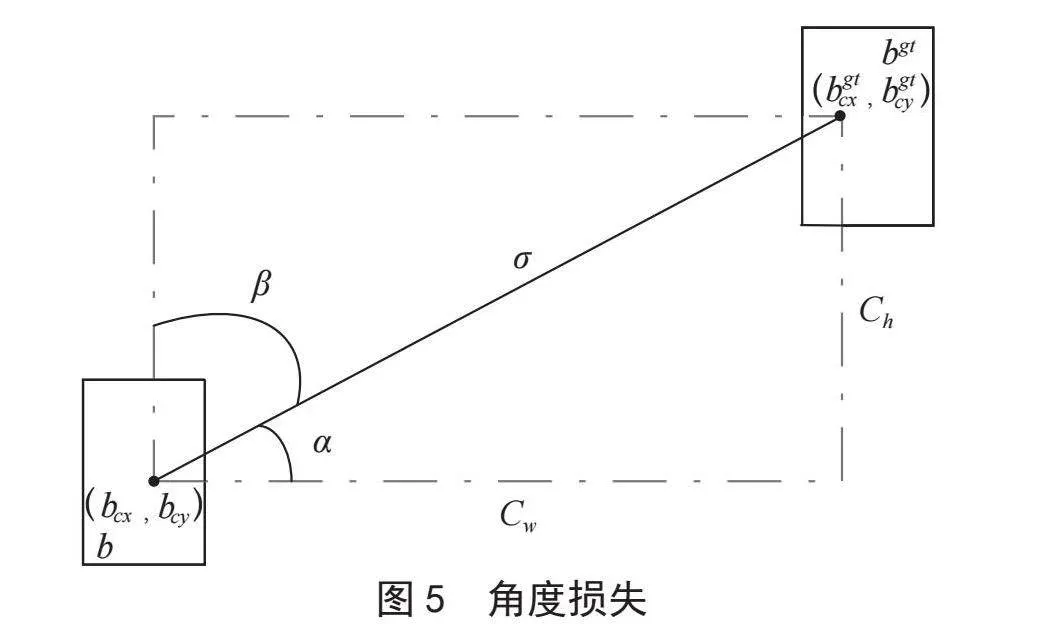
SIoU损失函数由四个成本函数组成:角度损失、距离损失、形状损失、交并比损失。角度损失的计算过程如图5所示。
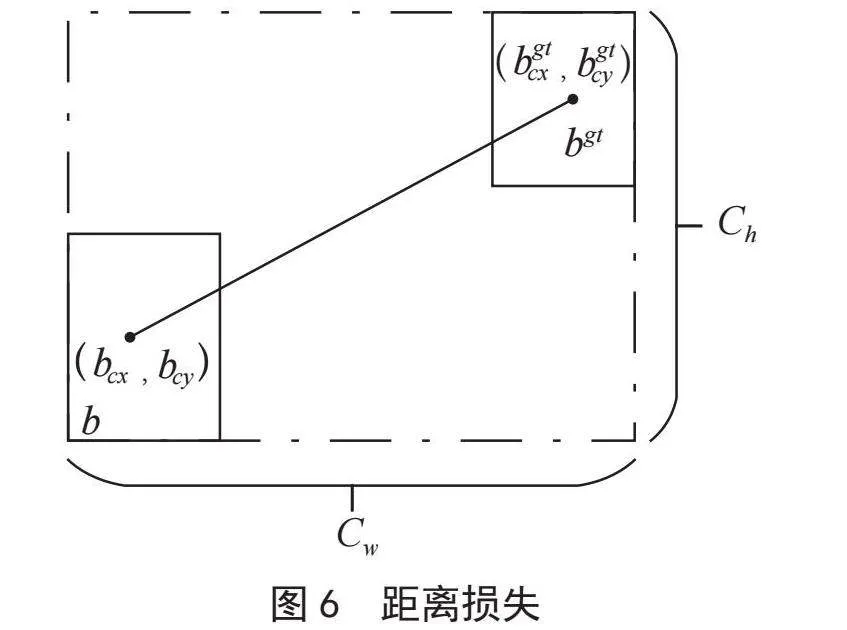
图5中,σ表示两框中心点的距离,Ch表示真实框和预测框中心点的高度差,Cw表示真实框与预测框中心点的宽度差,bgt表示真实框的中心点,b表示预测框的中心点。角度损失函数如下式所示。
(6)
式(6)中,x=Ch/σ=sinα,σ与Ch的计算方式为:
(7)
(8)
式(8)中,,表示真实框中心坐标,, 表示预测框中心坐标,SIoU先尝试在X或Y轴做预测,然后沿着相关轴继续逼近,若α≤π/4,收敛过程将首先尝试最小化α,否则最小化β=(π/4)-α。基于对角度损失的考虑,SIoU重新定义了距离损失,如图6所示。
计算过程如式(9)所示:
(9)
其中,,,,由公式可得:当α趋近于0时,距离成本的贡献大幅度降低;相反,α越接近π/4,Δ越大。SIoU的形状损失如式(10)所示:
(10)
其中:
,
θ用于定义形状损失,θ的值在上式中是十分重要的一个变量,它决定了形状损失需要多少注意力。若值为1,即立刻优化形状,从而影响形状的自由运动,其定义范围在[2,6],在本文所做实验中取θ=4。最后一项为传统的交并比损失,综上可得SIoU的最终损失函数LSIoU如式(11)所示:
(11)
至此,为了提高将主干网络替换为改进MobileNetV3下降的检测精度,本文采用SIoU替换CIoU,提高检测精度。
2.5 FasterNet
为了实现更快的检测,FasterNet[13]提出了一种新的部分卷积(Partial Convolution, PConv),可以同时减少冗余计算和内存访问,冗余计算是指在数据传输或存储中引入额外的冗余信息,以增强数据的可信度。延迟、FLOPs、FLOPS之间的关系如式(12)所示:
(12)
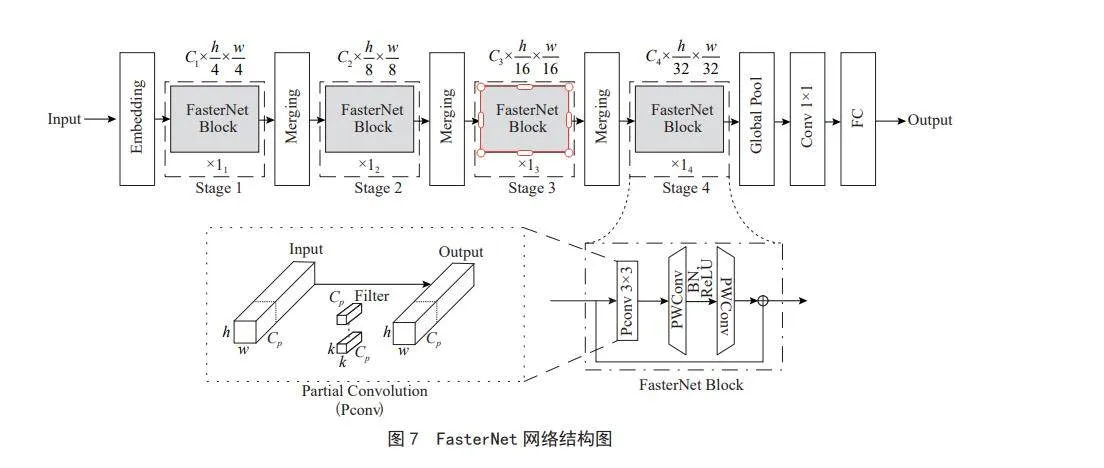
FasterNet网络通过增加FLOPS的同时有效减少FLOPs来提高检测速度,从而在不影响精度的情况下减少延迟并提高计算速度。在PConv的基础上,作者提出了FasterNet,FasterNet结合了PConv和逐点卷积,工作原理如图7所示,PConv在进行空间特征提取时,只对输入数据的一部分通道进行卷积操作,而保持其他通道不变。这种方法采用了一种连续的内存访问,以选择第一个或最后一个连续通道来代表整个特征图进行计算。这样,输入和输出特征图的通道数量保持一致,不会损失通用性。因此,PConv的内存访问要比传统卷积方法更小。
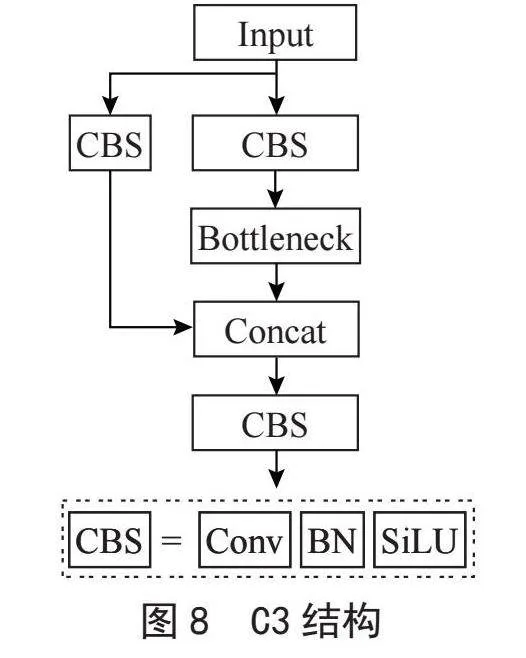
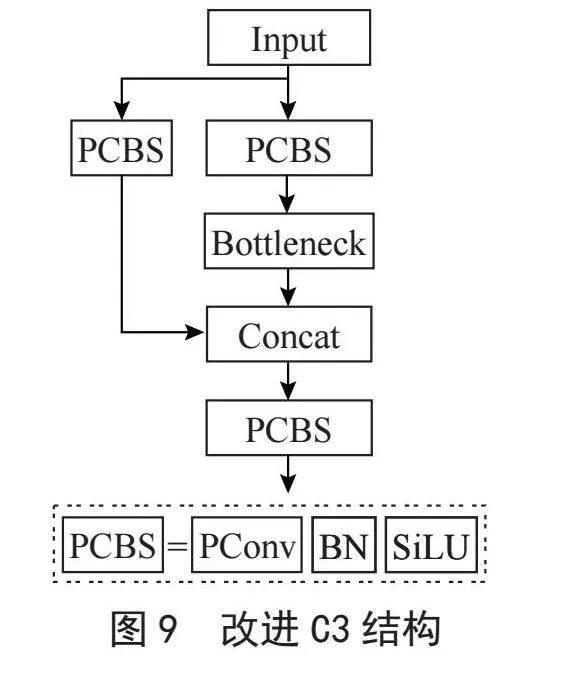
在YOLOv5网络中,C3模块扮演着关键的角色,它的结构如图8所示,主要任务是增加网络的深度和感受野,以提高特征提取的性能。神经网络的高计算复杂性和延迟可能会导致性能下降。为了解决这个问题,本文用PConv替代C3的普通卷积层,结构如图9所示,通过减少FLOPs,实现C3模块的轻量化,并减少计算冗余,这样做可以在不过度增加计算负担的情况下,提高网络的性能,有助于在实际应用中获得更高的效率。用FasterNet融合YOLOv5颈部的C3模块,有效减少模型参数量,降低FLOPs数量,增加了FLOPS数量,进而减少了内存访问和延迟。
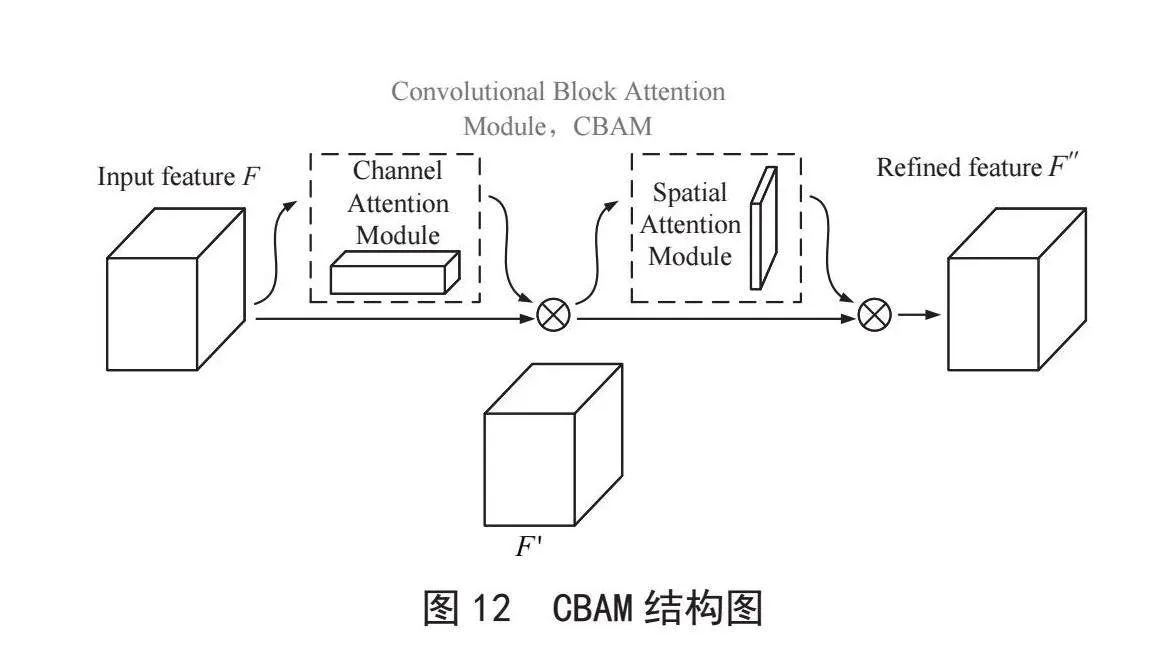
2.6 CBAM
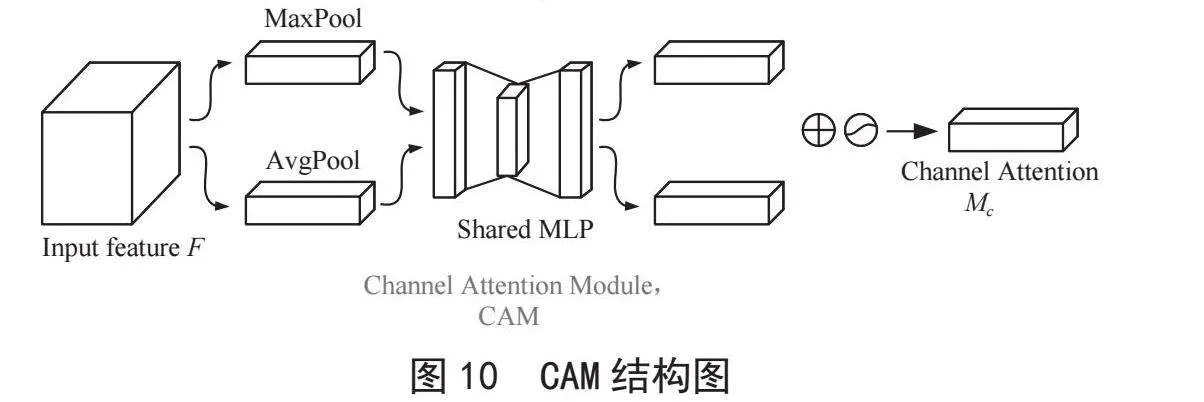
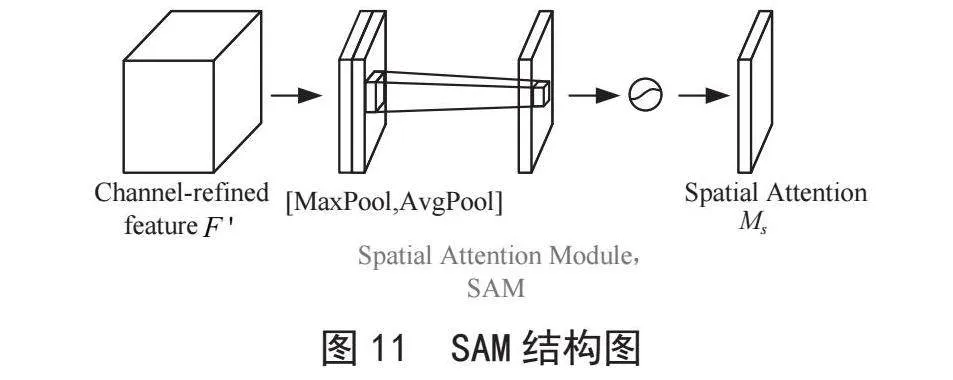
CBAM是一种融合了通道注意力(Channel Atten-tion Module, CAM)和空间注意力(Spatial Attention Module, SAM)的注意力结构。CAM模块将输入特征图分别进行最大池化和平均池化处理,并考虑其宽度和高度,随后这些处理的结果进入到多层感知器(Multi-Layer Perception, MLP),MLP输出的两个特征图经过逐像素求和运算和Sigmoid激活操作以产生通道特征权重Mc,由CAM模块产生的Mc与原始输入特征图进行逐像素相乘,以输出后续SAM模块需要的特征图F′,CAM的结构如图10所示;SAM模块将前面CAM模块生成的F′作为输入特征图,通过全局最大池化和全局平均池化层处理后形成的两个特征图,将它们进行全连接,之后卷积降维并通过Sigmoid激活函数生成空间特征权重Ms,SAM的结构如图11所示。之后将Ms与F′逐像素相乘,最终产生了CBAM注意力输出的最终融合特征图F″,整个过程可用数学表达式描述,如式(13)、式(14)所示:
结合CAM和SAM机制,CBAM结构如图12所示。CBAM模块提高了输入特征图中关键特征的表示能力,通过全局池化操作获取全局描述信息,从而增强对全局信息的感知能力。在本文中,将CBAM模块添加到YOLOv5颈部网络的每一层卷积层之后。
3 实验结果分析
3.1 实验环境设备
本实验使用的软、硬件设备参数以及训练神经网络的加速环境如表1所示,使用PyTorch深度学习框架部署目标检测算法。
3.2 数据集采集
因为目前缺少开源的乒乓球专用数据集,所以本实验所使用的数据集来源为网络收集,通过互联网下载2 148张图片,使用Labelimg软件将这些得到的图片进行数据标注,格式为适合YOLO算法训练的txt标签文件,部分图片如图13所示,并将这些图片分成训练集1 963张,验证集185张,其中包含无目标的背景图片,使用这些图片训练可以帮助实现数据均衡,提高模型的泛化能力和鲁棒性。
3.3 评估指标
为了让实验结果有个评判指标,本文设置的算法检测性能评估指标有:精确率(P)、召回率(R)、浮点计算量(Giga Floating-point Operations Per Second, GFLOPs)、参数量(Parameter)、平均精度(Average Precision, AP)、平均精度均值(mean Average Precision, mAP)。
精确率P表示预测正确的正样本数量与所有预测为正样本数量的比值;召回率R表示预测正确的正样本与所有正样本的比值,计算方式为:
(15)
(16)
其中,TP(True Positive)表示预测值与真实值均为正的样本,FP(False Positives)表示预测值为正但真实值为负的样本,FN(False Negatives)表示预测值为负但真实值为正的样本。
GFLOPs用于衡量算法的复杂度,Parameters表示算法包含参数的数量。AP是对不同召回率点上的准确率求平均,AP值表示模型的平均准确率。本文仅对乒乓球进行检测,所以AP与mAP数值相等,mAP根据IoU值可以分为mAP@0.5与mAP@0.5:0.95,由于mAP@0.5计算简单,适合快速检测,本文使用mAP@0.5作为评估目标检测算法精度的指标。
3.4 实验结果与数据分析
3.4.1 改进算法与YOLOv5检测算法对比
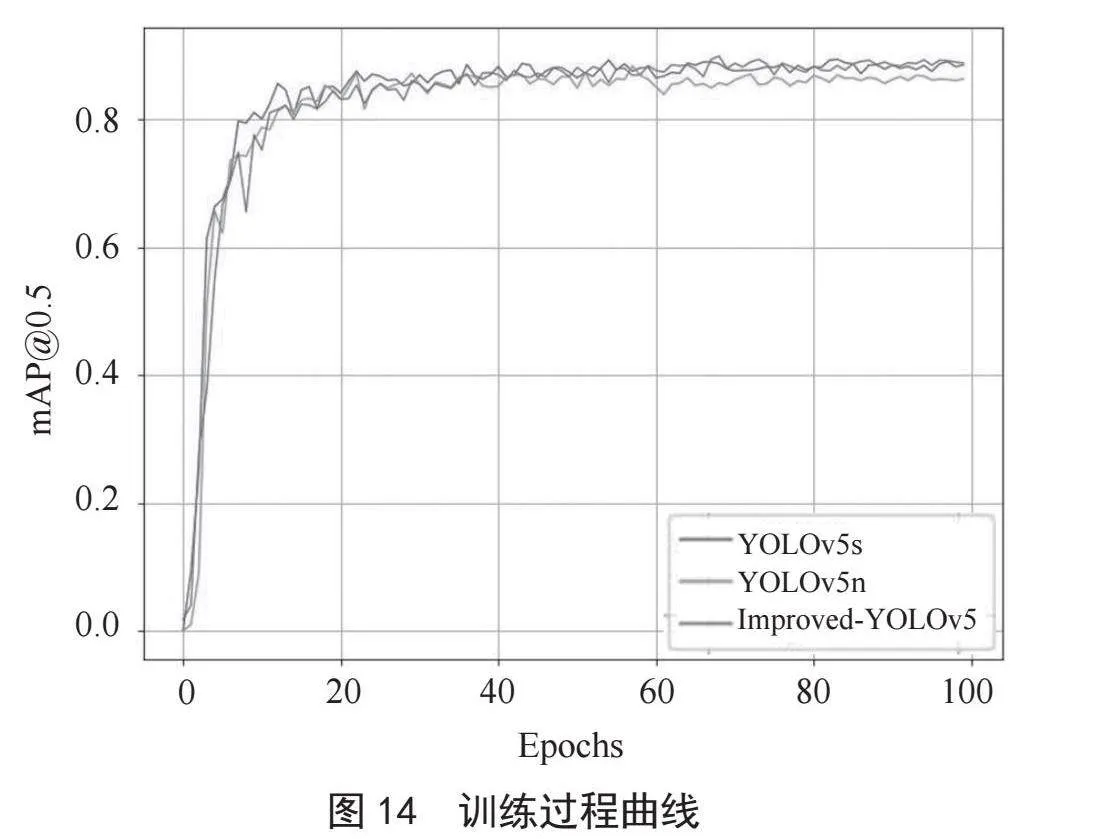
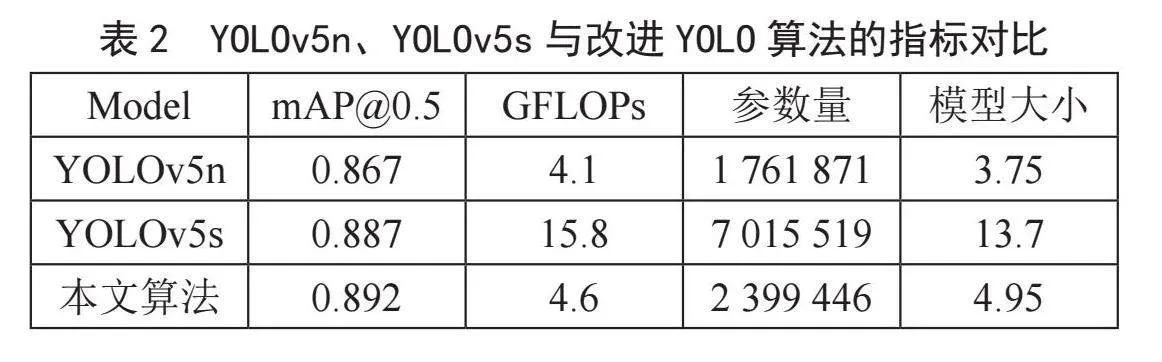
为了体现改进算法在精度方面与参数量方面的性能指标,将本文提出的改进算法与YOLOv5s、YOLOv5n分别在相同实验环境和参数设定下使用所采集的数据集进行训练,将它们的训练结果随轮次变化绘制成曲线,如图14所示,将实验结果绘制成表,如表2所示。
由表2可知,改进算法的GFLOPs为4.6,与YOLOv5n相比,虽然GFLOPs提高了0.5,但是mAP提升了2.5%;与YOLOv5s相比,虽然mAP只提升了0.5%,但是GFLOPs下降了11.2,参数量大致下降了65%,整体表现良好。
3.4.2 消融实验
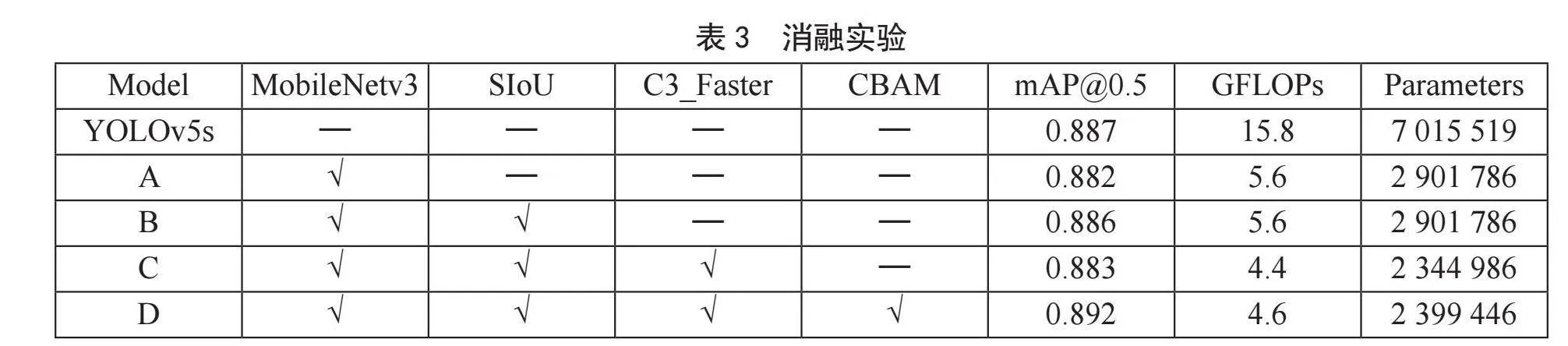
为进一步验证改进模型的性能表现,本文进行了消融实验,将实验结果绘制成表,如表3所示,其中“—”表示没有进行相对应的改进,“√”则表示进行相应的改进,评价指标包括mAP@0.5、GFLOPs、Parameters。
在上述实验结果中,A模型表示YOLOv5s+Mob-ileNetv3,B模型表示YOLOv5s+MobileNetv3+SIoU,C模型表示YOLOv5s+MobileNetv3+SIoU+C3_Faster,D模型表示YOLOv5s+MobileNetv3+SIoU+C3_Faster+CBAM。本文以YOLOv5s为基线(baseline),首先在YOLOv5s的基础上将主干网络替换成改进后的MobileNetv3网络,以此作为轻量化模型,在此基础上分别将CIoU替换为SIoU,将颈部的C3模块融合FasterNet,并在颈部每层卷积层后面添加CBAM注意力机制,分别观测它们的指标差异。
由表3可知,在替换主干网络之后,模型整体的参数量减少了58%左右,检测速度提高,在精度方面有小幅下降;对颈部C3模块做改进,将C3模块CBS中的普通卷积层替换为PConv,有效降低参数量与GLOPs,减少计算冗余;最后在前面所做改进的基础上于颈部网络每层卷积层后面引入CBAM注意力机制,用少许的参数代价换取精度提升。相较于原始YOLOv5s模型,本文的改进算法在同一个数据集上表现良好,上述实验结果表明本文提出算法在轻量化方面取得优秀的效果。
3.4.3 对比实验
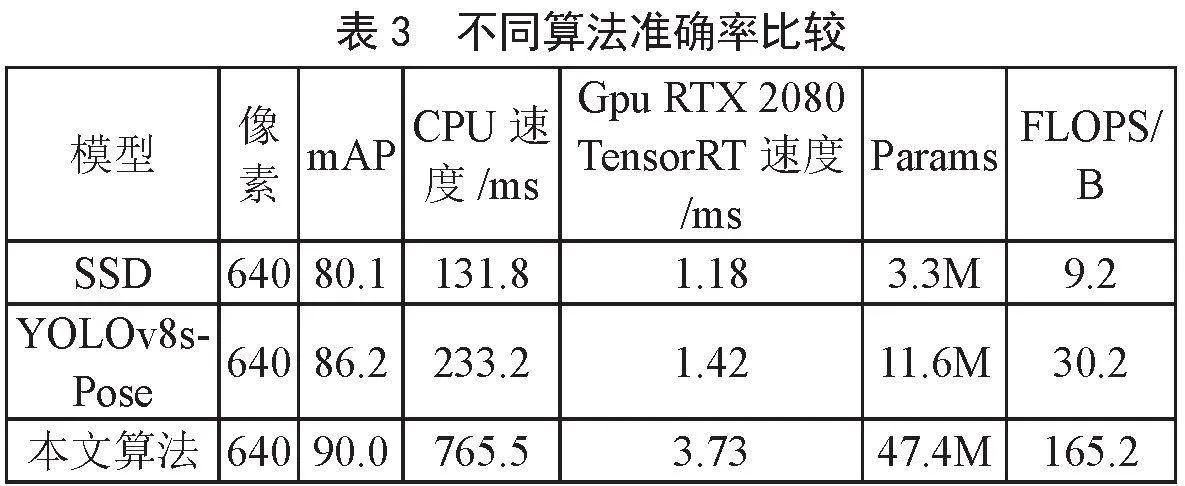
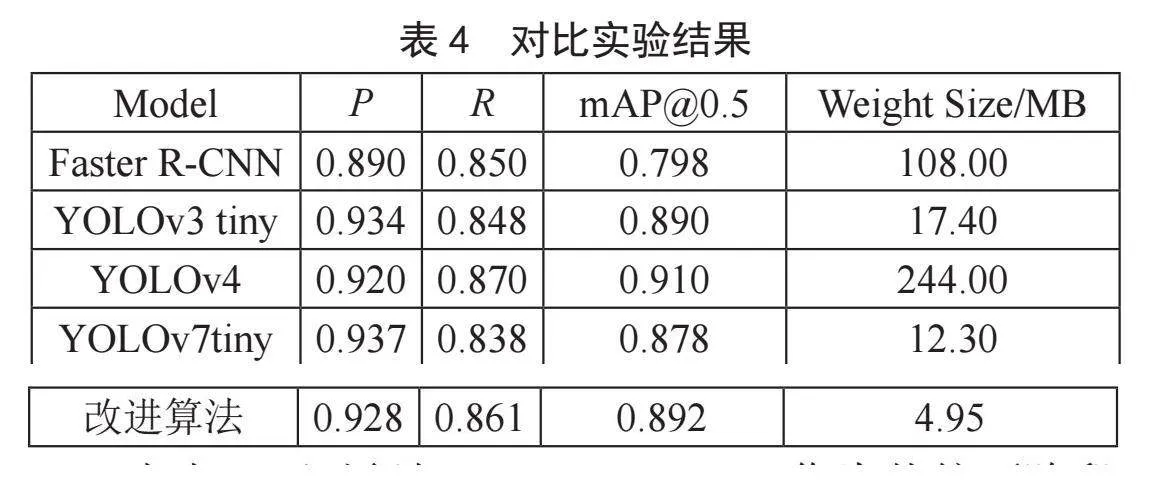
为了进一步验证本文提出改进算法的性能,将其与目前主流的目标检测算法进行对比,包括Faster R-CNN、YOLOv3 tiny、YOLOv4、YOLOv7tiny,保持相同参数,并在同一数据集上进行训练,将训练完成的模型在验证集上进行验证,实验结果如表4所示。
由表4可以得知:Faster R-CNN作为传统两阶段目标检测算法的代表,其检测精度与权重大小均难以满足乒乓球检测任务需求;在召回率与精确率方面表现良好的检测算法为YOLOv3 tiny和YOLOv4,其中YOLOv3 tiny在mAP@0.5表现虽然接近改进算法,但是权重大小相比超出了300%,而YOLOv4算法虽然在mAP@0.5表现最好,但由于其平台移植性差以及过于巨大的权重大小,无法部署在计算资源吃紧的平台;虽然本文的平均精度表现不是最好的,但在轻量化方面取得最好的效果,原因在于改进了主干网络,并在特征融合部分对C3模块进行了改进,大大降低了模型参数与计算冗余,十分适用于实际生产场景。
3.4.4 改进检测算法结果对比
改进前后算法的检测效果如图15、图16所示,图15为YOLOv5s算法的检测结果,图16为改进算法的检测结果。可以看出改进后的算法在不同场景、不同亮度下不仅提升了精度,更减少了误检率。
由以上结果可知,本文提出的基于改进YOLOv5s的乒乓球轻量化网络检测模型在乒乓球检测任务上具有优秀的检测效果,不仅大幅降低了YOLOv5s的参数量与权重大小,也减少了使用目标检测算法的误检率,可以更好地应用于乒乓球检测。
4 结 论
本文通过将主干网络替换成MobileNetv3并进行改进、将CIoU替换成SIoU、在颈部引入CBAM注意力机制并对C3模块的DWConv进行替换,减少了网络冗余和内存访问。大量的实验结果表明,改进的检测算法在mAP、参数量、模型大小综合指标表现最好,跟YOLOv5s算法对比,mAP虽然只提升了0.5%,但参数量下降了65%左右,在轻量化方面表现优秀,更适合部署在嵌入式平台上。
虽然改进后的算法在参数量和权重大小上取得了良好的效果,但是在检测精度指标上并没有显著的提升,后续需要进一步优化。
参考文献:
[1] REDMON J,FARHADI A. YOLO9000: Better, Faster, Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:6517-6525.
[2] REDMON J,FARHADI A. YOLOv3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-08).https://arxiv.org/abs/1804.02767.
[3] ZOU Z X,CHEN K Y,SHI Z W,et al. Object Detection in 20 Years: A Survey [J].Proceedings of the IEEE,2023,111(3):257-276.
[4] 谈小峰,王直杰.基于YOLOv4改进算法的乒乓球识别 [J].科技创新与应用,2020(27):74-76.
[5] LI W J,TAN X F,WANG Z J. Small Object Detection of Table Tennis Based on Deep Learning Network [C]//2020 International Conference on Computer Science and Management Technology (ICCSMT).Shanghai:IEEE,2020:149-152.
[6] DONG X D,YAN S,DUAN C Q. A Lightweight Vehicles Detection Network Model Based on YOLOv5 [J].Engineering Applications of Artificial Intelligence,2022,113:104914.
[7] MANTAU A J,WIDAYAT I W,LEU J-S,et al. A Human-detection Method Based on YOLOv5 and Transfer Learning Using Thermal Image Data from UAV Perspective for Surveillance System [J].Drones,2022,6(10):290.
[8] CHEN S N,DUAN J F,WANG H,et al. Automatic Detection of Stroke Lesion from Diffusion-weighted Imaging via the Improved YOLOv5 [J].Computers in Biology and Medicine,2022,150:106120.
[9] LIU S,QI L,QIN H F,et al. Path Aggregation Network for Instance Segmentation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8759-8768.
[10] LIN T Y,DOLLáR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:936-944.
[11] LI H C,XIONG P F,AN J,et al. Pyramid Attention Network for Semantic Segmentation [J/OL].arXiv:1805.10180 [cs.CV].(2018-05-25).https://arxiv.org/abs/1805.10180v1.
[12] HOWARD A,SANDLER M,CHEN B,et al. Searching for MobileNetV3 [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2019:1314-1324.
[13] CHEN J R,KAO S-H,HE H,et al. Run, Dont Walk: Chasing Higher FLOPS for Faster Neural Networks [C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Vancouver:IEEE,2023:12021-12031.
[14] HU J,SHEN L,ALBANIE S. Squeeze-and-excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[15] HOWARD A G,ZHU M L,CHEN B,et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications [J/OL].arXiv:1704.04861 [cs.CV].(2017-04-17).https://arxiv.org/abs/1704.04861.
[16] SANDLER M,HOWARD A,ZHU M,et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4510-4520.
[17] WANG Q L,WU B G,ZHU P F,et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Seattle:IEEE,2020:11531-11539.
[18] ZHENG Z H,WANG P,LIU W,et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression [J/OL].arXiv:1911.08287 [cs.CV].(2019-11-19).https://arxiv.org/abs/1911.08287v1.
[19] GEVORGYAN Z. SIoU Loss: More Powerful Learning for Bounding Box Regression [J/OL].arXiv:2205.12740 [cs.CV].(2022-05-25).https://arxiv.org/abs/2205.12740.
作者简介:施博凯(1998—),男,汉族,广东汕尾人,硕士在读,研究方向:图像处理;通讯作者:邱天(1977—),男,汉族,河南周口人,副教授,博士,研究方向:图像处理、集成电路设计及智能设备研发。