


摘 要:阐述了一种基于用户行为数据的学术用户画像构建方法,包括标记用户行为数据并按照三个维度标记用户身份;收集、清洗用户行为数据、用户访问过的学术资源的特征信息;构建用户兴趣领域和每个兴趣领域的关键词向量表达;结合用户账号相关信息构建学术用户画像。能够基于用户IP、账号、终端标识三个维度的历史行为数据,通过挖掘分析相关学术资源特征信息,构建学术用户画像。其中基于终端的学术用户画像不依赖于用户账号体系,为后续的机构读者个性化知识推荐服务提供支撑。
关键词:用户画像;个性化推荐;知识服务;学术资源;用户行为
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)15-0119-05
Research on the Construction Method of Academic User Profile Based on
User Behavior Data
ZHANG Liang, XIAO Yintao
(Tongfang Knowledge Network Digital Publishing Technology Co., Ltd., Beijing 100192, China)
Abstract: This paper elaborates a method for constructing academic user profiles based on user behavior data, including labeling user behavior data and labeling user identity according to three dimensions. It collects and clean user behavior data and characteristic information of academic resources accessed by users, constructs vector representations of user interest domains and key words of each interest domain, and constructs an academic user profile based on user account related information. Based on historical behavioral data from three dimensions of user IP, account, and terminal identification, academic user profiles can be constructed by mining and analyzing relevant academic resource characteristic information. The academic user profile based on terminals does not rely on the user account system, providing support for personalized knowledge recommendation services for institutional readers in the future.
Keywords: user profile; personalized recommendation; knowledge service; academic resource; user behavior
0 引 言
20世纪90年代,库帕[1]提出用户画像的概念,用户画像是对用户各种行为、特征的总结,是建立在用户数据基础之上的模型,通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,对用户或产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出用户的信息全貌[2]。用户画像技术的本质工作就是用户信息标签化[3]。
用户画像可看作应用大数据的根基,是个性化推荐的前置条件,为数据驱动运营奠定了基础[2]。国内学者引入用户画像的思想或方法[4-5],广泛应用于电子商务、公共图书馆和卫生健康等领域[6-8]。在用户画像的设计与构建方法上,陈晶等[9]提出了基于联邦学习的多源数据用户画像设计方案,利用联邦学习的计算机制和隐私求交算法实现了多源数据共享。房志明等[10]利用用户的静态属性和动态属性进行评审专家画像建模。吴迪等[11]提出一种微博用户行为影响力计算方法,构建热点话题下的用户画像。李帅等[12]提出一种基于实时用户画像的军事情报推荐技术。该技术通过收集用户的自然标签和行为标签等信息,并结合时间上下文,生成动态实时用户画像。
用户画像已得到部分学者的关注,但鲜少有针对学术用户画像的领域细分研究。如何构建学术用户画像,动态地将个体读者多个兴趣领域与学术资源分类体系深度结合并表达出来,是学术类数字资源提供者为读者提供精准个性化知识服务的前提。本文所述数据来源于知网学术资源和用户行为数据,提出一种基于用户行为数据的学术用户画像构建方案,能够基于用户IP、账号、终端标识三个维度的历史行为数据,通过挖掘分析相关学术资源特征信息,构建学术用户画像。
1 学术画像构建总体流程
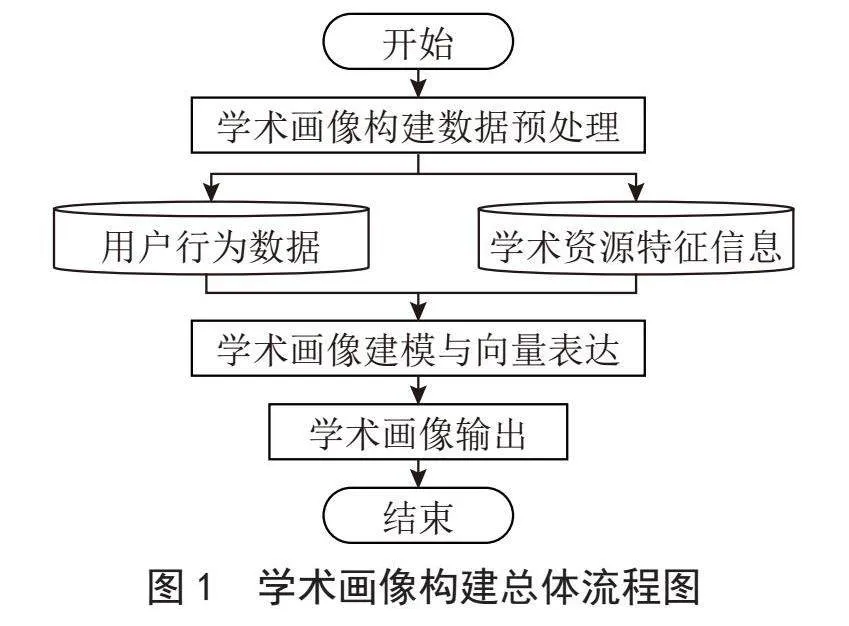
学术画像构建方案总体分为数据预处理、画像建模与向量表达、画像输出三个模块。其中,数据预处理模块负责标记用户身份,收集、清洗用户行为数据和用户访问过的学术资源,输出规范化的用户行为数据和学术资源特征信息。画像建模与向量表达模块利用数据预处理模块产生的数据构建用户兴趣领域和每个兴趣领域的关键词向量表达,需综合考虑用户行为类型、行为时间、资源特征等多个因素。画像数据模块结合用户单位、学历、研究领域等基本信息,以JSON格式描述用户画像。总体流程如图1所示。
2 学术画像构建数据预处理
2.1 标记用户行为数据并从三个维度标记用户身份
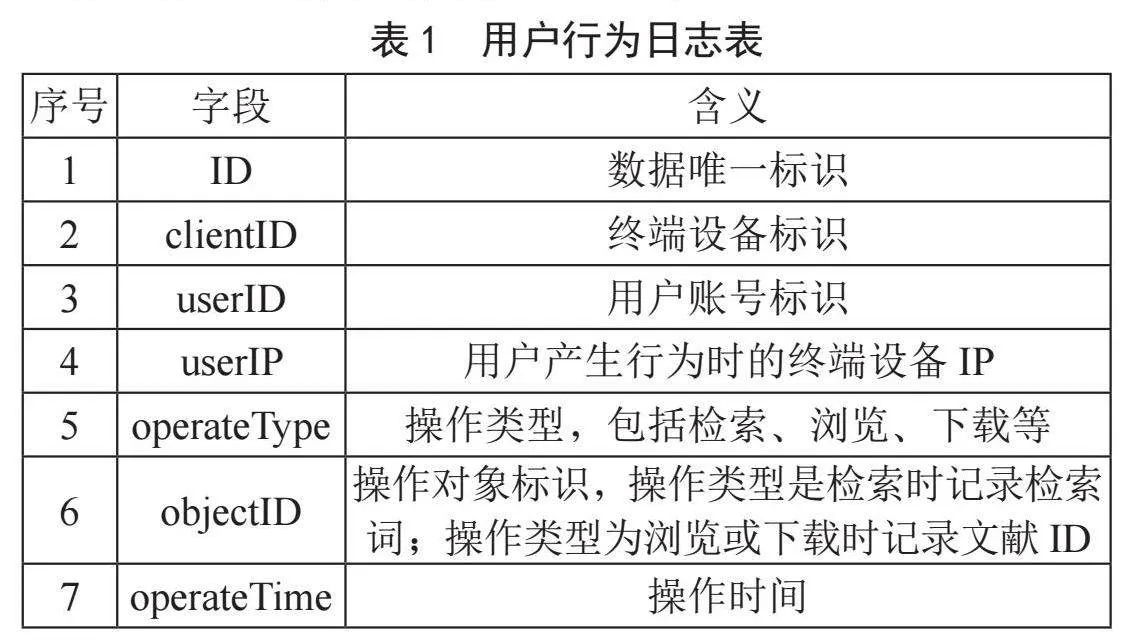
业务系统记录用户登录、检索、浏览、收藏、关注、在线阅读及下载的行为日志,内容包括用户IP、账号、终端标识、操作时间、检索词、浏览或下载的文献等字段信息,如表1所示。其中,IP是用户产生行为时的终端设备IP;账号是用户产生行为时使用的账号,匿名操作时记录匿名账号标识;终端标识是用户产生行为时的终端设备标识,是系统为每一个终端设备生成存储在终端设备中的ID,当新的终端访问系统时,由系统自动生成并存储在终端设备中。
通过用户IP、账号、终端标识三个维度的标记以及行为分析对常用账号和常用终端建立关联,可以在用户未登录、登录个人账号、登录机构账号等多种使用场景下记录用户行为数据。在确保读者数据和隐私安全的前提下,用户行为数据成为构建读者学术用户画像的重要依据。
具体步骤包括:
1)在用户产生行为时记录用户的IP。
2)在用户产生行为时,判断用户是否是登录状态,如果是,记录用户账号;如果未登录,记录匿名账号标识。
3)在用户产生行为时记录用户的终端标识。从用户终端设备中获取用户终端标识时,若不存在,系统生成终端标识并存储在终端设备中;若存在,则直接获取使用。
4)若同一账号在同一终端多次使用,则认为该终端是用户的常用设备,为用户建立账号和设备之间的关联关系。在后续收集、清洗用户行为数据时,终端设备上产生的行为数据,在匿名状态下也能选择性地视为关联账号的行为数据。
2.2 收集、清洗用户行为数据
收集用户行为数据的内容包括线下定时从业务系统收集的用户行为数据以及线上通过分布式消息系统收集的在线用户即时产生的行为数据。所述用户行为数据主要包括登录、检索、浏览、收藏、关注、在线阅读及下载的操作日志,主要数据字段包括用户IP、账号、终端标识、操作时间、检索词、浏览或下载的文献ID等。为保证数据一致性、删除重复信息、纠正存在的错误,对所收集的行为数据进行数据清洗。主要是根据每个变量的合理取值范围和相互关系对数据进行一致性检查,去除有缺失或格式错误的数据,去除有逻辑错误和不需要的数据,对短时高频行为进行过滤或采样(例如,按照国际在线电子资源使用统计标准COUNTER的规定,对同一个会话30秒内的重复行为数据进行去重[13]),对用户敏感信息进行脱敏等处理,确保数据的有效性,确保用户隐私安全。
2.3 收集、清洗用户访问过的学术资源的特征信息
用户行为数据包含用户浏览、下载、阅读、收藏、关注的文献ID。系统根据这些文献ID从学术资源题录库中检索获取相关的资源特征信息,这些特征信息已经过预处理,具体包括篇名、作者、单位、所属学科、所属刊物、关键词、机标关键词、描述文献的VSM向量信息、期刊指数、机构指数、作者指数、被引量、被下载量、页数等。其中,文献的VSM向量信息是通过TF-IDF算法把一篇文章抽象成一个多维向量,每一个维度的向量由特征词和权重组成,权重结合了词频TF和逆文档频率IDF,代表了该词在文章中的重要程度,排在前列的即为本文的关键词。
3 学术画像建模与向量表达
3.1 构建用户兴趣领域的向量表达
从用户IP、账号、终端标识三个维度分析如何构建用户兴趣领域的向量表达。该向量表达兼顾用户的长期兴趣和短期兴趣,具备明显的学术化特征。综合考虑用户行为类型、行为时间、资源特征等多个因素,对不同特征赋予不同权重,通过聚类分析或分类算法分析,对用户兴趣进行动态、多领域、定量的描述。
具体步骤包括:
1)收集该用户近期的行为数据以及相关文献的资源特征信息。获取该用户最近N天浏览、下载、阅读、收藏、关注的行为数据,根据行为数据涉及的文献信息,获取相关的资源特征信息。
2)构建该用户使用文献与兴趣领域的关系列表。用户最终的兴趣领域使用学术文献的学科分类体系表达。分类体系可以是中图分类法,也可以是其他学科分类体系。收集、清洗文献与所属学科的关系数据,针对用户使用文献所属学科数据可能存在重复或错误的“脏数据”情况,进行去重和数据一致性检查。文献对兴趣领域的贡献值与该文献的被引量、被下载量、期刊指数、机构指数、作者指数以及文献的页数有关系。计算式如下:
其中,C(i)表示第i篇文献对所属学科的贡献值;K1、K2表示调节参数,一般K1 = 0.9,K2 = 0,n表示文献所属学科的数量;文献属于多个学科分类时,文献的贡献值要平均分配到各个所属学科分类中。M表示影响贡献值因素的数量,这里包括被引量、被下载量、期刊指数、机构指数、作者指数以及文献的页数,因此m = 6。α表示各因素的影响系数,可结合具体的影响因素和资源类型进行设定。F(i, j)表示第i篇文献从学术资源题录库中获取的被引量、被下载量、期刊指数、机构指数、作者指数以及文献页数中的第j个影响因素。
构建完的用户使用文献与兴趣领域的关系列表包含行为类型、文献、所属学科、贡献值、行为时间。其中,行为类型就是浏览、下载、阅读、收藏、关注;文献有多个所属学科时,应存储多行,确保每行记录的所属学科只有一个值。
3)计算该用户使用过的文献在兴趣领域中的权重,构建用户兴趣领域文献权重列表。在用户使用文献与兴趣领域的关系列表中,影响权重的因素包括行为类型、行为时间、贡献值。根据用户的行为时间和操作类型进行时间衰减和行为加权。时间衰减规则是,越早的行为权重越低,越新的行为权重越高。行为加权的规则是下载、关注、收藏、浏览。计算式如下:
其中,FW(i)表示列表第i条记录中的文献在对应兴趣领域中的权重;T(i)表示第i条记录的行为时间;T1表示列表中的最早行为时间;T2表示列表中的最新行为时间;S(i)表示行为类型的评分值,按照下载、关注、收藏、浏览设定;C(i)表示文献对所属学科的贡献值。计算后,用户使用文献与兴趣领域的关系列表增加了文献权重一列,构成用户兴趣领域文献权重列表,包括行为类型、文献、所属学科、贡献值、行为时间、文献权重。
4)计算该用户各兴趣领域权重。对用户兴趣领域文献权重列表进行分析,使用所属学科维度进行聚类,得到每个所属学科的权重汇总:
其中,DW( j)表示该用户第j个兴趣领域的权重汇总;FW( j)表示该用户第j个兴趣领域下n篇文献中第i个文献的权重值。
5)对该用户所有兴趣领域的权重进行归一化处理、降序排列后,得到最终的用户兴趣领域的向量表达。
3.2 构建用户每个兴趣领域的关键词向量表达
根据用户兴趣领域文献权重列表,从学术资源题录库中提取相关学术资源的特征信息,构建用户兴趣领域关键词权重列表;从账号信息库中提取用户编辑的兴趣领域、兴趣词,从行为数据中提取用户近期使用的检索词信息,补充完善用户兴趣领域关键词权重列表;根据业务处理关键词重复的记录,最终得到用户该兴趣领域的关键词向量表达。
具体步骤包括:
1)根据用户兴趣领域文献权重列表,提取相关文献的资源特征信息。提取后的数据包含行为类型、文献、所属学科、贡献值、行为时间、文献权重、所属刊物、关键词、机标关键词、描述文献的VSM向量信息、期刊指数、机构指数及作者指数。
2)构建用户兴趣领域关键词权重列表。根据用户兴趣领域涉及的文献,提取关键词信息并计算权重值,构建用户兴趣领域关键词权重列表。关键词主要来源于描述文献的VSM向量信息,没有该字段的文献则使用关键词或机标关键词来替代。为了描述关键词在用户兴趣领域的重要程度,每个关键词需要设置一个权重值。因为VSM向量中关键词的权重值指的是该词在这篇文献中的重要程度,不能直接拿来描述关键词在用户兴趣领域中的权重。此处,我们将用户兴趣领域文献权重列表中文献的权重值按照VSM向量中关键词权重的比例进行分配。这样既考虑了单篇文献对用户兴趣领域影响的最大值,又兼顾了文献中关键词重要程度的区分。用户兴趣领域关键词的权重值计算式如下:
其中,DWW(i)表示用户某个兴趣领域第i个关键词的权重;FWW(j)表示用户某个兴趣领域n篇文献中第j篇文献的VSM向量中对应关键词的权重值; 表示用户某个兴趣领域中第j篇文献VSM向量中所有m个词权重的累加值;FW(j)表示用户某个兴趣领域中第j篇文献的权重。
经过该步骤处理后,将得到用户兴趣领域关键词列表,包含用户兴趣领域、兴趣领域权重、关键词、关键词权重。
3)补充完善用户兴趣领域关键词权重列表。补充关键词是为了更准确地描述用户的兴趣领域。主要是通过用户输入的检索词或主动编辑兴趣词来实现。用户输入的检索词,可根据用户检索后访问的文献所属分类确定检索词所属的用户兴趣领域;权重值可参考该兴趣领域关键词的权重值进行设置,无论与已有关键词重复与否,均应将该检索词赋以较高的权重值,比如前5位。系统提2sMtV5UWqc+SfDCCtXzBHSyh7RXScdp3/MNz1DAUFJ4=供用户主动编辑兴趣词的功能,用户输入的兴趣词将取代原兴趣词,权重值不变。删除权重值较低的重复词。
4)处理用户兴趣领域关键词权重列表中重复的关键词。从学术用户画像整体描述考虑,重复的关键词是冗余的,应该进行排重处理;但从用户兴趣领域描述来考虑,则不应进行排重处理。因此,该步骤可根据应用场景做选择性处理。处理方法是根据用户兴趣领域的关键词权重列表,对于重复的关键词信息,保留关键词权重高的记录;权重值相同时保留兴趣领域权重较高的记录。
5)对用户每个兴趣领域的关键词权重进行归一化处理、降序排列后得到用户该兴趣领域的关键词向量表达。
4 学术画像输出
学术画像输出以JSON格式描述,可直接应用于产品或为推荐系统提供基础数据支撑。学术画像主要是对用户兴趣领域及权重、兴趣词及权重的描述,另外也对用户基本信息(如用户标识、研究领域、我的兴趣词等)的描述做了定义,形成一个完整的学术用户画像体系。其中,用户基本信息数据来源于用户在知网“我的账户”产品中自填的信息,如图2所示。学术画像的JSON格式表达如图3所示。
学术画像已应用于知网“我的CNKI”产品,为读者提供个性化知识推荐服务,如图4所示。
5 结 论
针对基于用户行为的学术用户画像构建问题,本文提出从用户IP、账号、终端标识三个维度对历史行为数据进行标识的方法,并通过学术画像建模对用户的兴趣领域及每个兴趣领域的兴趣词进行向量表达。最后,结合账号其他信息一起构建学术用户画像,并以JSON格式进行完整描述,为后续个性化知识推荐服务提供支撑。
参考文献:
[1] 库帕.交互设计之路 [M].北京:电子工业出版社,2006.
[2] 赵宏田.用户画像:方法论与工程化解决方案 [M].北京:机械工业出版社,2020.
[3] 黄志杨.基于K-means++的大学生就业画像构建 [J].现代信息科技,2023,7(10):109-112.
[4] 刁雪桦,朱学芳.基于用户群体画像分析的慕课平台知识服务策略研究 [J].数字图书馆论坛,2023,19(12):11-20.
[5] 王世奇,刘智锋,王继民.学者画像研究综述 [J].图书情报工作,2022,66(20):73-81.
[6] 李松,王磊,王千羽.基于评论信息的网络购物用户兴趣画像研究 [J].情报科学,2023,41(11):128-133.
[7] 刘一鸣,徐春霞.基于用户画像的公共图书馆健康信息精准服务路径研究 [J].图书馆,2023(9):53-59.
[8] 刘乐洋,刘维维.用户画像在卫生健康领域应用中的研究进展 [J].中国健康教育,2023,39(9):826-831.
[9] 陈晶,彭长根,谭伟杰.基于联邦学习的多源数据用户画像设计方案 [J].南京邮电大学学报:自然科学版,2023,43(5):83-91.
[10] 房志明,吴鑫卓,林原,等.基于用户画像的高校采购评审专家推荐算法 [J].实验技术与管理,2024,41(4):228-237.
[11] 吴迪,马文莉,杨利君.遗忘曲线和BTM词频双层加权微博用户画像 [J].计算机工程与设计,2023,44(12):3800-3808.
[12] 李帅,李海霞,金山,等.基于用户画像的军事情报推荐技术 [J].火力与指挥控制,2023,48(4):122-129.
[13] 杨巍,叶仁杰,吴元业,等.COUNTER Release 5的新特征及其应用研究 [J].大学图书馆学报,2020,38(1):18-25+41.
作者简介:张良(1977—),男,汉族,山东济宁人,高级工程师,硕士,研究方向:信息系统研发与管理;肖银涛(1985—),男,汉族,河北保定人,项目经理,硕士,研究方向:用户画像与推荐系统。