

摘 要:命名实体识别(NER)是自然语言处理(NLP)领域的重要任务。量化梳理NER的文献进程,有助于未来NER乃至NLP技术的突破发展。目前已有大量学者对NER任务进行了综述回顾。但是这些基于传统文献计量学的回顾方式,既过于依赖专家经验,又无法直观呈现知识变迁。因此,文章以知网中文核心文献为驱动,基于CiteSpace工具,对国内NER技术进行了知识图谱展示和数据挖掘分析。分析结果显示:以2016年为界,国内已形成基于数据驱动的两个快速发展期;“当地高校+省立实验室”的形式已成为国内机构合作的主流;“深度学习”“知识图谱”“实体识别”“信息抽取”“神经网络”和“词向量”是国内NER领域的研究热点;未来对NER的研究倾向于应用落地、数据增强和知识抽取。
关键词:命名实体识别;CiteSpace;知识图谱;中国知网
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)15-0124-06
Knowledge Graph Analysis of Domestic Named Entity Recognition Based on CiteSpace
LI Yuan, CAI Zhongxiang, LI Na, HUANG Ziming
(Faculty of Information Engineering, Xinyang Agriculture and Forestry University, Xinyang 464000, China)
Abstract: Named Entity Recognition (NER) is an important task in the field of Natural Language Processing (NLP). Quantitative review of the literature process of NER technology is conducive to the breakthrough development of NER and even NLP technology in the future. At present, a large number of scholars have reviewed the NER tasks. However, these review methods based on traditional bibliometrics not only rely too much on expert experience, but also can not directly present the change of knowledge paradigm. Therefore, this paper, driven by the Chinese core literature of CNKI and based on CiteSpace, presents the Knowledge Graph display and data mining analysis of domestic NER technology. The analysis results show that the domestic research on NER has formed two rapid development periods based on data drive from 2016. The form of “local university + provincial laboratory” has become the mainstream of domestic institutional cooperation. “Deep Learning” “Knowledge Graph” “entity recognition” “information extraction” “Neural Network” and “word vector” are the hot spots of domestic NER research. Future research on NER tends to apply landing, data enhancement and knowledge extraction.
Keywords: Named Entity Recognition; CiteSpace; Knowledge Graph; CNKI
0 引 言
命名实体识别(Named Entity Recognition, NER)技术是自然语言处理(Natural Language Processing, NLP)领域的一个重要且基础的前置任务[1],影响着诸多下游NLP子任务的性能,如信息检索、机器翻译、舆情检测等。
自21世纪起,国内就有研究者陆续对实体的高精度识别和提取进行研究,目前在知网上已经积累了数以千计的相关文献资料,并仍在快速增加中。文献回顾工作是一个长期的、烦琐的但是又极其重要的工作。目前国内已有学者在不同时期论述了NER技术在不同阶段的变迁情况。如,张晓艳等[2]回顾了从1985年到2005年间NER技术的由来脉络、识别方法和评测指标;刘浏等[3]指出目前的主流NER方法仍然是基于规则和统计机器学习的方法;赵继贵等[4]在回顾传统的NER任务同时,又补充了当前基于深度学习的方法,并对未来中文NER任务的发展进行了展望。
但是这些基于传统文献计量方式进行文献回顾的方法,往往过度依赖于外部专家的学习经验,从而可能造成对某些关键研究文献的忽略。此外,这种基于传统文献计量方式也难以直观呈现与NER相关的研究范式的产生、发展、变迁乃至消亡的过程。如何在海量的文献中快速、准确、直观的发现关键信息一直是人们关注的焦点。CiteSpace[5]是一种能直观展现知识点间联系、发展、变化的文献可视化工具。因此,本文基于CiteSpace对国内的NER技术研究进行了可视化分析,旨在展示发展脉络,探索合作模式,挖掘知识范式,厘定前沿热点。
本文其他部分的结构如下:第1部分介绍本文使用的数据来源和进行数据处理的手段,第2部分使用CiteSpace工具对知网数据进行可视化展示和数据分析,最后总结国内NER领域的研究方法并在此基础上展望了未来。
1 数据采集与处理
1.1 数据来源
受到布拉德福文献离散定律的启发,本文在CNKI中选取高质量的、有影响力的北大核心和CSSCI检索期刊作为数据的分析来源。为提高文献查全率,本文使用了高级检索设置,设置检索条件为主题=(*命名实体识别*)NOT 主题=(*综述*)NOT主题=(*进展*),并剔除了新闻、书籍介绍、广告等无关数据,共获得数据948条。
1.2 数据处理
为进一步提高主题精准度,本文使用了CiteSpace 6.2.R6进行数据预处理和可视化操作,最终获得去重的期刊文章884条。
2 研究现状与分析
2.1 文献随年代分布情况
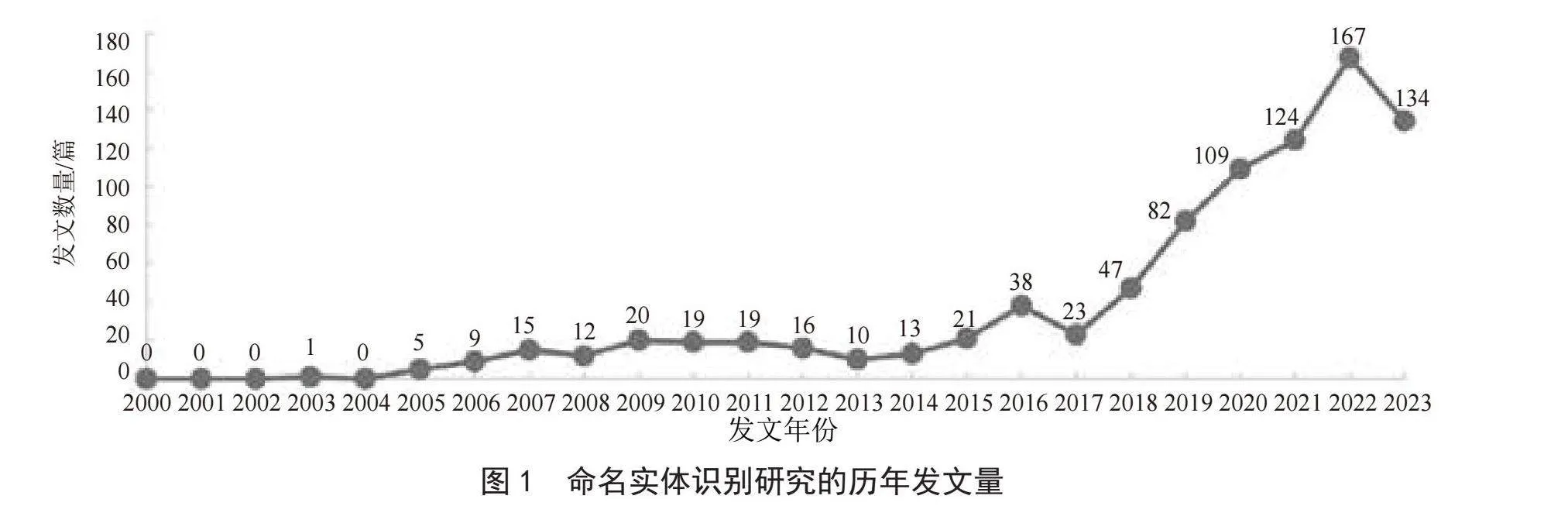
文献的发表年代可以反映出总体研究的发展脉络及其受到关注的情况。本节以1年为时间间隔,分组统计并绘制出了国内进行命名实体识别研究的历年发文量。如图1所示,可知2000—2004年的发文量较低,仅有1篇应用型论文[6],整体处于发文短缺期。此时国内尚未形成完整的理论体系研究,仍处于跟跑英文NER研究和探索中文NER理论阶段,因此少有高水平中文论文产出。
2004年之后,随着数据的不断积累,基于数据驱动的方法逐渐引起了相关学者的关注并成为研究的重点。基于数据驱动的发展可分为两个时期:第一次快速发展期(2005—2015年),基于统计机器学习的方法占据了研究的主流,整体发文呈现先快递增长后平稳波动的趋势。2005年和2006年的发文量分别为5篇和9篇,同2000—2004年相比,发文数量快速上升,基于隐马尔可夫(Hidden Markov Model, HMM)[7-8]的实体抽取模型在国内得到了广泛的应用。
但齐次马尔科夫假设和观测独立假设也极大地限制了基于HMM模型的捕获更多和更长远上下文的能力,因此在2007年之后,基于线性链的条件随机场(Liner Conditional Random Field, CRF)[9-12]的NER模型获得了更多的关注;第二次快速发展期(2016—2023年),随着数据和软硬资源的完善,能够提取自动深度语义特征的神经网络模型进入人们的视野,基于深度学习的方法成为后续研究的主流。典型的算法包括循环神经网络(Recurrent Neural Network, RNN)[13-16]、卷积神经网络(Convolutional Neural Network, CNN)[17-18]及预训练语言模型(Pretrained Language Model, PLM)[19-22]等。
2.2 作者合作分析
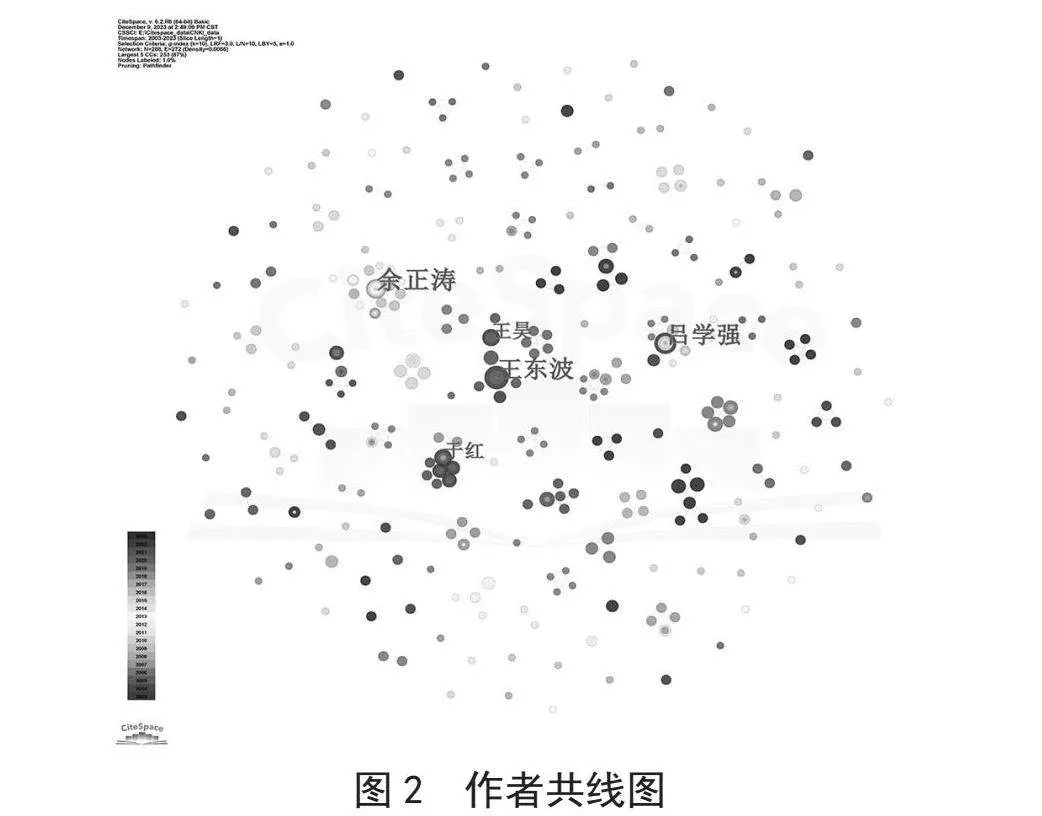
作者共线图能够反应不同作者间的发文合作情况以及研究内容的变化情况。其中,节点的大小表示作者发文的数量。节点的色系对应发文的时间早晚,发文越早,节点的颜色越接近紫色,发文越新,节点颜色越接近红色。节点间的线条粗细则表示不同作者间的合作紧密情况。
图2中存在288个节点,272条连线,并形成了以余正涛(12篇)、王东波(11篇)、吕学强(10篇)和于红(6篇)为首的4大核心作者群体研究组。通过查看核心作者的节点详情可知:李桂兰等主要研究与旅游领域8[23]相关的文本任务,并形成以柬埔寨语[24]和越南语[25-26]为主的小语种处理队伍;崔竞烽等团队擅长于对中华典籍进行数字化处理和识别,并在古诗词[27]、引书[28]、史记[29]、医书[30]等中文历史文本上进行了深远的尝试;刘殷等团队则紧跟时代理论前沿,分别研究了HMM7、CRF[31]以及神经网络[32]等模型在中文NER任务上的应用;任媛等团队主要基于深度学习技术深入研究了神经网络在识别水产类文本[33-35]上的效用。
但是这些大型研究组之间并没有直接连线,而且图中也存在大量无连线的其他小型作者研究群体。这一现象在一方面表明现阶段各个研究群体间的合作较为局限,但也在另一方面表明命名实体识别技术的适用范围广,尚有极大的发展空间。
2.3 机构合作分析
为了进一步分析各个研究群体间的合作,本节绘制了机构共线关系图。图3中共有298个节点,134条边。结合机构分析,发文机构常以“当地高校+省立实验室”的形式进行合作,如“昆明理工大学信息工程与自动化学院+云南省计算机技术应用重点实验室智能信息处理研究所”等。整体上各个研究机构主要以高校的二级学院为依托,同一个单位内的作者合作发文较多。这一现象也进一步显现各个研究群体间的合作较为局限,尚有极大的发展空间的推论。
2.4 研究热点分析
高频的关键词通常能够表示一个研究的热点[36]。为了直观分析研究热点的发展变化,本节按照文章的关键词进行了关键词共线分析。具体操作如下:
1)首先将经过去重处理的文献以CSSCI格式导入CiteSpace。
2)设置时间切片间隔为每年。
3)为了减少低频数据的影响,使用了Pathfinder选项进行网络裁剪。
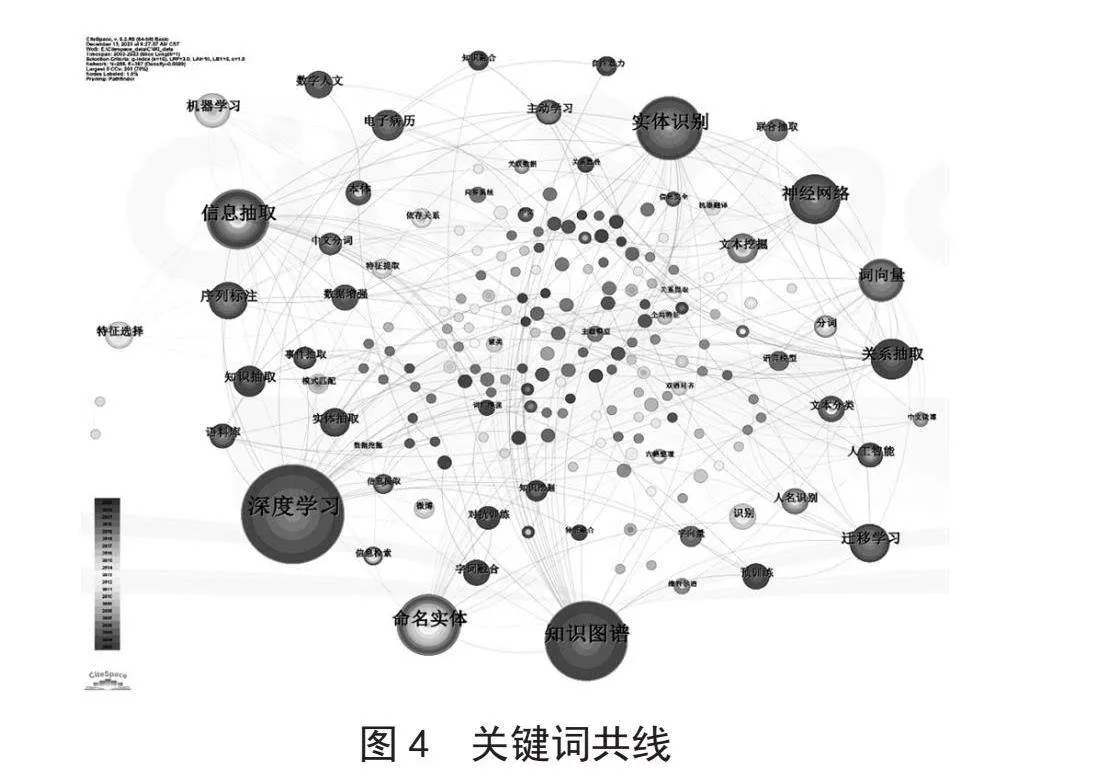
4)以频率为分类标准,筛选出现频次高于5次的节点信息。最终得到关键词共线图,如图4所示。
图4中包含288个节点,和367条边。节点上的圆环颜色的种类对应关键词的出现频率,关键词的频率越高,则对应的圆环和字体越大,该关键词也就越重要。据图可知,目前“深度学习”“知识图谱”“实体识别”“信息抽取”“神经网络”“词向量”等关键词字号较大、圆环颜色种类多且与其他节点之间具有较多的连线。这一现象说明这些高频关键词在多个时期内都是研究的主要对象,彼此相互交织,联系紧密,但难以区分各个时期的主要研究热点。为此,本节在关键词共线的基础上进行了聚类分析,并按时间顺序进行结果展示,其结果如图5所示。
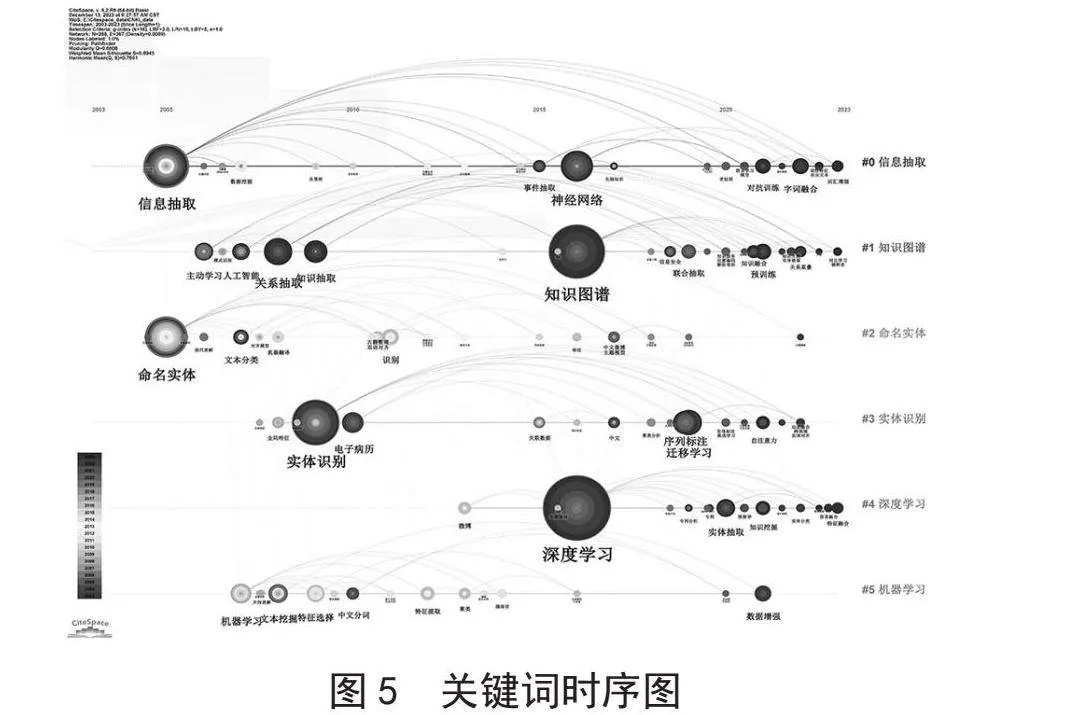
通过LLR聚类算法,CiteSpace形成了85个具有288个节点和367条边的关键词聚类结果(Q值为0.660 8,S值为0.894 5)。本节筛选了前6个最大的聚类规模进行研究热点变化分析。该时序图的横轴表示时间的变化,纵轴的每一条线则对应一组聚类的结果,而线上的每一个圆环都对应一个关键词。
由图5可知目前对命名实体识别的研究主要集中在“信息抽取”“知识图谱”“命名实体”“实体识别”“深度学习”以及“机器学习”这6个方面。继续分析每一组聚类的结果可得到以下结论:
#0信息抽取的聚类结果主要包括“数据挖掘[37]”“决策树[38]”“神经网络[39]”“对抗学习[40]”“字词融合[41]”。这些研究者采用了经典的决策树或神经网络等数据挖掘算法完成了NER。造成这一现象的原因可能是NER是信息抽取[42]的子任务,相关研究者会尝试将之前解决其他类似任务的方法应用到同一个领域的其他问题上来。
#1知识图谱的聚类结果主要包括“关系抽取[43]”“人工智能[44]”“知识抽取[45]”“知识融合[46]”等。知识图谱是包含事实、实体、关系以及语义表述的大规模结构化表示的语义网络[47]。在一方面知识图谱的形成需要使用NER术进行知识实体抽取,在另一方面NER的性能又会受到对外部背景知识理解程度的影响,二者相辅相成,联系密切。
#2命名实体和#3实体识别则分被对应NER任务的用途和对象。命名实体是自然语言处理的一项重要基础任务,能够为信息检索、机器翻译[48-49]、情感分析[50]等一系列下游任务提供丰富的实体级别语义信息。
#4深度学习和#5机器学习则对应进行NER的技术手段。结合时间线的变化,目前基于深度学习的自动融合多种深层特征的方法已经取代基于机器学习的提取浅层的方法,并成为新的完成NER的基线方法。
#6词向量的聚类结果则主要包括“语料库[51]”“字向量[52]”“语言模型[53]”。字词数值化的效果好坏能够极大的影响下游自然语言处理任务的性能,对自然语言处理研究者来说,如何在计算机中合适的表达字词语言一直是一个关键的问题。目前基于BERT等预训练语言模型获得的字词向量已经成为完成NER任务的主要范式。
随着理论的丰富和技术的不断发展,对NER的研究也出现了新的方向。由图6的关键词突变图可以展望:未来国内对NER的研究将聚焦在对“电子病历”和“数字人文”等重点领域的项目落地上;使用“数据增强”的方式解决低资源场景下的NER任务将会是一个新的方向;使用NER技术进行“知识抽取”以及结合外部知识提高NER模型的可解释性将得到更多NER研究者的重视。
3 结 论
本文以知网最近23年的核心文献为数据,通过CiteSpace可视化工具,量化并分析了国内对NER任务研究的变化趋势,并得到以下结论:对NER的研究以2016年为界,分为两个发展时间。这两阶段又分别以统计机器学习和深度学习为研究的重点;目前至少已经形成四大核心作者研究群体,但这些研究群体之间合作较为局限,通常依靠所在单位进行研究,并形成“当地高校+省立实验室”的合作模型,但跨院校之间的合作较少,未来仍有较大的深度合作空间;近23年来的研究重点主要集中于“信息抽取”“知识图谱”“命名实体”“实体识别”“深度学习”以及“机器学习”这6个方面。结合深度学习和知识图谱等相关技术进行实体识别的范式依然会持续较长的一段时间。
参考文献:
[1] 杨锦锋,于秋滨,关毅,等.电子病历命名实体识别和实体关系抽取研究综述 [J].自动化学报,2014,40(8):1537-1562.
[2] 张晓艳,王挺,陈火旺.命名实体识别研究 [J].计算机科学,2005(4):44-48.
[3] 刘浏,王东波.命名实体识别研究综述 [J].情报学报,2018,37(3):329-340.
[4]赵继贵,钱育蓉,王魁,等.中文命名实体识别研究综述 [J].计算机工程与应用,2024,60(1):15-27.
[5] CHEN C. Science Mapping: A Systematic Review of the Literature [J].Journal of Data and Information Science,2017,2(2):1-40.
[6] 昝红英,苏玉梅,孙斌,等.名人网页的相关度评价 [J].中文信息学报,2003(5):27-33.
[7] 俞鸿魁,张华平,刘群,等.基于层叠隐马尔可夫模型的中文命名实体识别 [J].通信学报,2006(2):87-94.
[8] 薛征山,郭剑毅,余正涛,等.基于HMM的中文旅游景点的识别 [J].昆明理工大学学报:理工版,2009,34(6):44-48.
[9] 刘非凡,赵军,徐波.实体提及的多层嵌套识别方法研究 [J].中文信息学报,2007(2):14-21.
[10] 郭剑毅,薛征山,余正涛,等.基于层叠条件随机场的旅游领域命名实体识别 [J].中文信息学报,2009,23(5):47-52.
[11] 邹俊杰,余正涛,刘跃红,等.融合领域命名实体识别的查询扩展方法研究 [J].计算机工程与设计,2012,33(3):1229-1233+1250.
[12] 潘清清,周枫,余正涛,等.基于条件随机场的越南语命名实体识别方法 [J].山东大学学报:理学版,2014,49(1):76-79.
[13] 朱丹浩,杨蕾,王东波.基于深度学习的中文机构名识别研究——一种汉字级别的循环神经网络方法 [J].现代图书情报技术,2016(12):36-43.
[14] 赵青,王丹,徐书世,等.中文医疗实体的弱监督识别方法 [J].哈尔滨工程大学学报,2020,41(3):425-432.
[15] 宋佳芮,陈艳平,王凯,等.基于Affix-Attention的命名实体识别语义补充方法 [J].山东大学学报:工学版,2023,53(2):70-76.
[16]李源,马磊,邵党国,等.用于社交媒体的中文命名实体识别 [J].中文信息学报,2020,34(8):61-69.
[17] 许浩亮,李雁群,何云琪,等.中文嵌套命名实体关系抽取研究 [J].北京大学学报:自然科学版,2019,55(1):8-14.
[18] 于祥钦,王香,李智强,等.基于字符级特征自适应的生物医学命名实体识别 [J].小型微型计算机系统,2023,44(9):1876-1883.
[19] 陈剑,何涛,闻英友,等.基于BERT模型的司法文书实体识别方法 [J].东北大学学报:自然科学版,2020,41(10):1382-1387.
[20] 游乐圻,裴忠民,罗章凯.融合自注意力的ALBERT中文命名实体识别方法 [J].计算机工程与设计,2023,44(2):605-611.
[21] 贾李睿智,刘胜全,刘源,等.基于分层ERNIE模型的中文嵌套命名实体识别 [J].东北师大学报:自然科学版,2023,55(1):97-103.
[22] 余克健,张程,乐毅,等.基于GPT修正农业病虫害命名实体识别方法 [J].内蒙古农业大学学报:自然科学版,2023,44(5):34-43.
[23] 李桂兰,余正涛,毛存礼,等.旅游领域实体答案的抽取 [J].广西师范大学学报:自然科学版,2009,27(1):181-184.
[24] 徐广义,严馨,余正涛,等.融合跨语言特征的柬埔寨语命名实体识别方法 [J].云南大学学报:自然科学版,2018,40(5):865-871.
[25] 潘华山,严馨,余正涛,等.基于支持向量机的越语新闻文本分类方法 [J].山西大学学报:自然科学版,2013,36(4):505-509.
[26] 刘艳超,郭剑毅,余正涛,等.融合实体特性识别越南语复杂命名实体的混合方法 [J].智能系统学报,2016,11(4):503-512.
[27] 崔竞烽,郑德俊,王东波,等.基于深度学习模型的菊花古典诗词命名实体识别 [J].情报理论与实践,2020,43(11):150-155.
[28] 黄水清,周好,彭秋茹,等.引书的自动识别及文献计量学分析 [J].情报学报,2021,40(12):1325-1337.
[29] 刘江峰,冯钰童,王东波,等.数字人文视域下SikuBERT增强的史籍实体识别研究 [J].图书馆论坛,2022,42(10):61-72.
[30] 谢靖,刘江峰,王东波.古代中国医学文献的命名实体识别研究——以Flat-lattice增强的SikuBERT预训练模型为例 [J].图书馆论坛,2022,42(10):51-60.
[31] 刘殷,吕学强,刘坤.条件随机场与多层算法模型的实体自动识别 [J].计算机工程与应用,2016,52(11):141-147.
[32] 罗艺雄,吕学强,游新冬.融合多特征的专利功效短语识别 [J].中文信息学报,2022,36(12):139-148.
[33] 任媛,于红,杨鹤,等.融合注意力机制与BERT+BiLSTM+CRF模型的渔业标准定量指标识别 [J].农业工程学报,2021,37(10):135-141.
[34] 刘巨升,杨惠宁,孙哲涛,等.面向知识图谱构建的水产动物疾病诊治命名实体识别 [J].农业工程学报,2022,38(7):210-217.
[35] 刘巨升,于红,杨惠宁,等.基于多核卷积神经网络(BERT+Multi-CNN+CRF)的水产医学嵌套命名实体识别 [J].大连海洋大学学报,2022,37(3):524-530.
[36] 林德明,陈超美,刘则渊.共被引网络中介中心性的Zipf—Pareto分布研究 [J].情报学报,2011,30(1):76-82.
[37] 李中言,李普跃.信息抽取技术在数字图书馆中的应用 [J].现代情报,2007(10):96-97.
[38] 栗伟,赵大哲,李博,等.CRF与规则相结合的医学病历实体识别 [J].计算机应用研究,2015,32(4):1082-1086.
[39] 朱娜娜,景东,薛涵.基于深度神经网络的微博图书名识别研究 [J].图书情报工作,2016,60(4):102-106+141.
[40] 董哲,邵若琦,陈玉梁,等.基于BERT和对抗训练的食品领域命名实体识别 [J].计算机科学,2021,48(5):247-253.
[41] 宋旭晖,于洪涛,李邵梅.基于图注意力网络字词融合的中文命名实体识别 [J].计算机工程,2022,48(10):298-305.
[42] GRISHMAN R,SUNDHEIM B M. Message Understanding Conference-6: A Brief History [C]//COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics.Stroudsburg:Association for Computational Linguistics,1996:466-471.
[43] 谢雨希,杨江平,孙知建,等.雷达装备故障原因知识图谱构建研究 [J].现代防御技术,2022,50(5):114-121.
[44] 李振,周东岱,王勇.“人工智能+”视域下的教育知识图谱:内涵、技术框架与应用研究 [J].远程教育杂志,2019,37(4):42-53.
[45] 邓智嘉.基于人工智能的知识图谱构建技术及应用 [J].无线电工程,2022,52(5):766-774.
[46] 杨波,廖怡茗.面向企业动态风险的知识图谱构建与应用研究 [J].现代情报,2021,41(3):110-120.
[47] JI S,PAN S,CAMBRIA E,et al. A Survey on Knowledge Graphs: Representation, Acquisition, a/g9VFipM+7qN44POqbpTiw==nd Applications [J].IEEE Transactions on Neural Networks and Learning Systems,2021,33(2):494-514.
[48] 王东明,徐金安,陈钰枫,等.基于单语语料的面向日语假名的日汉人名翻译对抽取方法 [J].中文信息学报,2015,29(5):84-90.
[49] 尹存燕,黄书剑,戴新宇,等.面向新闻语料的中日命名实体翻译抽取 [J].小型微型计算机系统,2015,36(6):1393-1397.
[50] 潘正高,侯传宇,谈成访.基于命名实体的Web新闻文本分类方法 [J].合肥工业大学学报:自然科学版,2011,34(8):1178-1182.
[51] 冯鸾鸾,李军辉,李培峰,等.面向国防科技领域的技术和术语语料库构建方法 [J].中文信息学报,2020,34(8):41-50.
[52] 单义栋,王衡军,黄河,等.基于注意力机制的命名实体识别模型研究——以军事文本为例 [J].计算机科学,2019,46(S1):111-114+119.
[53] 陈蕾,郑伟彦,余慧华,等.基于BERT的电网调度语音识别语言模型研究 [J].电网技术,2021,45(8):2955-2961.
作者简介:李源(1995—),男,汉族,河南信阳人,助教,硕士,研究方向:实体抽取、自然语言处理、数据挖掘;蔡忠祥(1996—),男,汉族,河南信阳人,助教,硕士,研究方向:计算机应用;李娜(2003—),女,汉族,河南三门峡人,本科在读,研究方向:数据可视化;黄子鸣(2003—),男,汉族,河南信阳人,本科在读,研究方向:数据可视化。