






摘" 要:针对当前主流的车辆驾驶辅助算法对硬件算力依赖较强的问题,提出了一种基于轻量型YOLOv5和DeepSort的车辆跟车辅助预警算法。该算法模型包括目标检测、目标追踪和跟车预警三个模块,能够实时检测道路前方的车辆、追踪并测量车距和车速,根据前车的车距和车速情况判断风险等级并做出预警。该算法在耗时最长的目标检测模块部分选择检测速度和精度都很优秀的YOLOv5s并对其做轻量化处理,以Mobilenetv3代替原YOLOv5s的backbone骨架并在特征融合层引入GSConv卷积,此外针对原CIoU损失函数在该算法中收敛效果不理想的问题,引入了WIoU损失函数。实验结果表明,与直接使用YOLOv5s作为检测模块相比,算法的参数量下降了37%,权重文件大小下降36.1%,检测速度提升了23.8%,mAP值仅下降0.3%。
关键词:车辆检测;目标追踪;神经网络
中图分类号:TP183;TP391.4" 文献标识码:A" 文章编号:2096-4706(2024)18-0059-07
Vehicle Tracking Assisted Warning Algorithm Based on Lightweight YOLOv5 and DeepSort
ZHANG Haichuan
(School of Electronic and Electrical Engineering, Chongqing University of Science and Technology, Chongqingnbsp; 401331, China)
Abstract: In view of the problem that the current mainstream vehicle driving assisted algorithm has strong dependence on hardware computing power, a vehicle tracking assisted warning algorithm based on lightweight YOLOv5 and DeepSort is proposed. The algorithm model includes three modules of target detection, target tracking and vehicle tracking warning. It could detect the vehicles ahead of the road in real time, track and measure the distance and speed, and judge the risk level according to the front car distance and speed and make early warning. The algorithm selects YOLOv5s with excellent detection speed and accuracy in the longest time-consuming target detection module and makes lightweight processing, replaces Mobilenetv3 with the backbone skeleton of the original YOLOv5s and introduces GSConv convolution in the feature fusion layer. In addition, aiming at the problem that the convergence effect of the original CIoU loss function is not ideal in the algorithm, the WIoU loss function is introduced. The experimental results show that the number of parameters of the algorithm has decreased by 37%, the weight file size has decreased by 36.1%, the detection speed has increased by 23.8% and the mAP value has decreased by only 0.3% compared with directly using YOLOv5s as the detection module.
Keywords: vehicle detection; target tracking; neural network
0" 引" 言
随着我国汽车保有量的激增,驾驶安全问题也变得越来越重要,各种以提升车辆安全性能为目的的技术也在不断发展,这其中就包括基于深度学习的目标检测神经网络算法[1],这种算法根据视觉传感器获取的图像信息进行目标检测,它们可以分为单阶段和双阶段两类。单阶段算法速度快但精度相对较低,其代表算法有单阶段多盒检测器(Single Shot MultiBox Detector, SSD)[2]算法和YOLO[3]系列算法等;双阶段算法精度更高但速度较慢且对硬件设备算力要求较高,因而不适合用作实时检测,其代表算法有R-CNN(Regions with Convolutional Neural Networks) [4]等。显然,车辆的安全驾驶辅助技术需要目标检测算法具备较强的实时检测能力,且整体算法需要搭载在移动端硬件平台,YOLO系列算法是上述目标检测算法中最适合用于对实时性要求较高的车辆辅助驾驶。
虽然YOLO系列相比其他目标检测神经网络具有较快的检测速度,但是将其部署在一些嵌入式设备上仍然十分吃力,因此如何进一步减少其参数,降低其计算的复杂程度成为一个热门问题,例如符惠桐等人针对上述问题,将Ghost模块引入YOLOv4并对通道剪枝,提出了GS-YOLO算法,有效地减少了模型的计算量[5]。Wang等通过修改网络的深度、宽度、分辨率和网络结构提出了YOLOv4-tiny模型[6],极大地降低了网络的参数量,提升了检测速度,但其检测精度也明显低于YOLO系列的其他算法。
结合实际驾驶辅助需求与深度学习技术的发展现状,本文就实际驾驶中的跟车场景出发,选择最适合该场景的YOLOv5神经网络结合Deepsort目标跟踪模型[7]初步设计出了一个车辆跟车辅助预警算法模型,其已经具备,单目测距、前车车速测量和碰撞预警的功能[8-10],为了进一步提升算法的运算速度以及降低算法模型的大小,本文对运算量最大的YOLOv5模型做了轻量化处理,包括引入Mobilenetv3网络[11]、引入GSConv卷积[12],此外引入了对于本文算法效果更好的Wise-IoU[13]损失函数,极大地提升了原跟车辅助预警算法的性能。
1" 跟车辅助预警算法
本文提出的基于轻量型YOLOv5和DeepSort的车辆跟车辅助预警算法包括目标检测、目标追踪和跟车预警三个模块,其中目标检测模块搭载轻量型YOLOv5算法,对道路前方车辆进行检测,目标追踪模块用DeepSort算法对检测到的目标持续追踪,跟车预警模块以单目测距的方式对检测到的目标测距并计算车速,根据前车的车距和车速情况判断风险等级并做出预警。
1.1" 目标检测模块
跟车辅助算法的应用场景对实时性要求较高,在众多基于深度学习的目标检测神经网络中,本文根据检测速度和精度的综合考量,选择YOLOv5算法作为目标检测模块的支撑算法,并且在其基础上进行了轻量化处理和损失函数改进。
YOLOv5算法是YOLO系列算法的第五代,其作者是Glenn Jocher及其团队,但是其作者没有发表相关论文。与YOLO的前四个版本相比,YOLOv5无疑是一个更为成熟的目标检测算法,无论是在检测精度上还是检测速度上都明显优于之前版本,而对比与Glenn Jocher的团队后来提出的YOLOv8,YOLOv5在精度上弱于YOLOv8,但是在检测速度上表现更好。
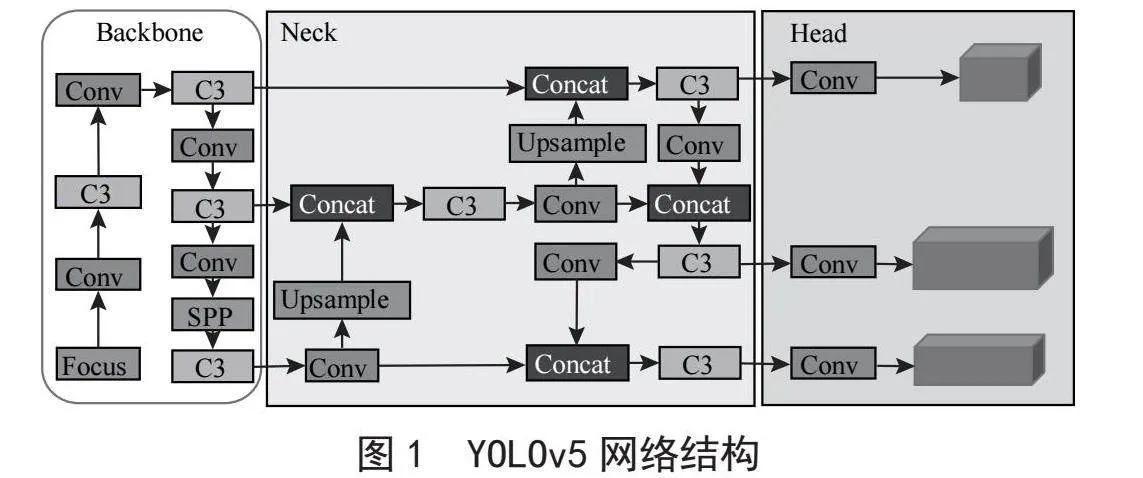
YOLOv5网络模型具有YOLOv5m、YOLOv5l、YOLOv5x、YOLOv5s四种结构,其中YOLOv5s的深度、宽度和参数量均是最小,是最轻量的模型。YOLOv5s的网络结构可以分为输入端预处理部分、backbone主干网络、Neck特征融合网络(也叫特征金字塔)和Head检测端四个部分。其中输入端预处理部分能够在训练时对数据集作Mosaic增强[14],以及对训练图像作裁剪、填充、拼接等预处理。Backbone主干网络的作用是提取图像特征,将输入图像转换成多层次的特征图,其主要结构有Conv模块、C3模块和SPP模块,如图1所示;Neck特征融合网络主要作用是通过上下采样的方式将不同层次的特征图结合起来,生成具有多尺度信息的特征图;Head检测端主要包括Anchors、Classification和Regression三个部分,其作用是对特征融合网络进行目标检测。
1.2" 目标追踪模块
目标追踪模块能够对目标检测模块所检测出的目标持续追踪,设计这一模块的目的在于为之后的跟车预警模块中测量车速的环节提供前提条件,若没有实现目标追踪,则检测到的图像只是孤立的每一帧检测结果,而相邻帧所检测到的目标不能确定是否是同一个目标,也就无法测量相邻两帧某一目标的像素位移,自然就不能对车速进行计算。
本文选择具有参数量小,稳定性高以及计算速度快等优点的DeepSort算法作为目标追踪模块的支撑算法。DeepSort算法是Sort算法上改进而来,它们都是用rRCNN做探测,用Kalman滤波[15]和匈牙利算法做跟踪,与Sort算法相比,DeepSort算法减少了身份切换的数量,缓解了重识别的问题。
DeepSort算法可以对目标检测模块所检测到的目标信息(包括类别、置信度和位置信息)进行进一步的处理,即根据余弦公式计算出被检测目标的距离,结合Kalman滤波以及加权马氏距离[16]对比,若是两种距离相匹配,则可以推算出目标轨迹,再利用匈牙利算法可得到目标追踪轨迹。
1.3" 跟车预警模块
跟车预警模块是跟车辅助算法功能的实现,该模块主要有车辆测距、车辆测速和车辆预警三个部分。
1.3.1" 车辆测距
目前基于图像视觉的目标测距方法主要有单目和双目两种形式,但是由于双目测距的计算量太大,对硬件的计算能力要求太高,不符合本文实时测距的需求,而单目测距算法结构简单、便于标定,计算量对比双目算法也要小很多,因此本文选择单目测距算法。
单目测距算法的原理是根据检测到的目标在图像中的大小估算目标的距离,至于具体的估算方法,一般来说有基于几何图形的计算、基于格角点标定(包括传统相机标定和Low-rank Textures标定[17-18]等)等方法,如Simonelli等人[19]就利用了格角点标定法中3D投影成像及坐标系转换的原理估算距离。本文使用的是格角点标定法中的传统相加标定原理。
根据投影几何学原理可以得到待测距离D的计算公式如式(1)所示:
(1)
式中:D为待测距离;F为摄像机焦距;W为被测目标的实际高度;P为被测目标的y轴像素高度。
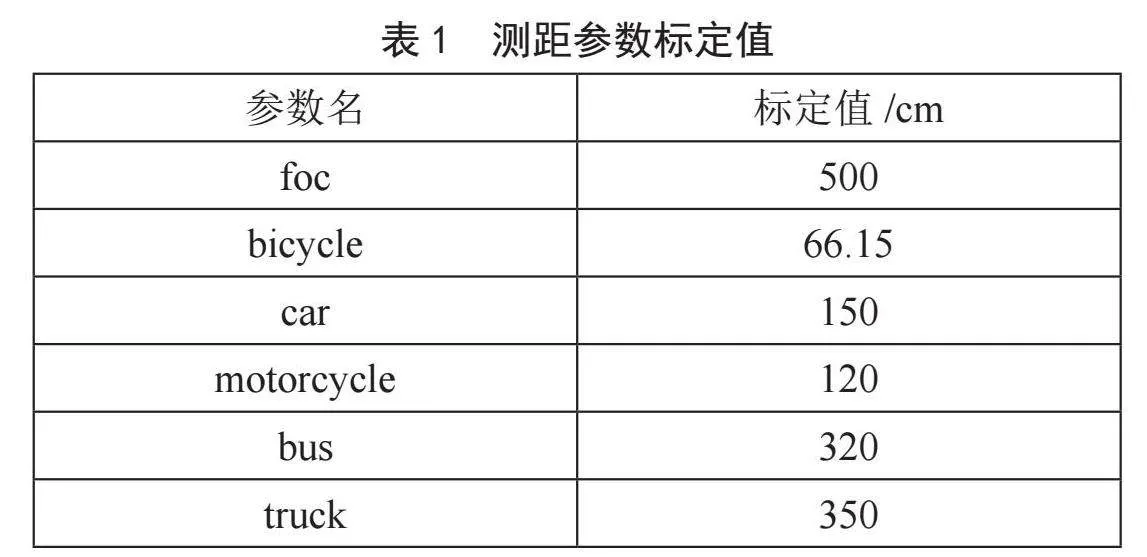
其中P是通过YOLOv5的检测结果直接获取,F根据具体使用摄像机的焦距作为参数输入,W则是根据目标分类,取每个类别的平均高度作为参数输入,这里F和W都是需要提前给定的初始测距参数。不同类别的平均高度是不一样的,这里在算法中定义了bicycle、car、motorcycle、bus和truck五个参数来保存对应五个类别的车辆平均高度,此外定义foc为保存焦距的参数。具体的五个车辆类别高度平均值和摄像机焦距的参数值如表1所示。
1.3.2" 车辆测速
测得车辆距离后,只需要根据相邻两帧同一目标在图像中检测框中心坐标变化(目标的坐标由前文提到的DeepSort算法得到)可以得出像素位移的距离,再通过表1中的标定值和像素距离比值做映射计算即可求出两帧间目标的真实移动距离。求得距离后,再根据检测的FPS可以反推两帧之间的时间间隔,由此便可进一步计算出目标的速度,这里的速度为瞬时速度,逐帧变化。需要注意的是,这里的速度是指与第一行车视角之间的相对速度,如果知道当前行车速度,将其输入进算法可以进一步得到被测车辆的绝对速度。此外,该算法还记录了目标车辆的速度变化和中心坐标变化,如图2所示,在需要时可以以此来绘制车辆行驶轨迹,其中,id值用于区分记录的目标车辆,frame则是视频帧数的编号。
具体的车速计算公式如式(2)所示:
(2)
式中:LX2为框中心点x轴坐标;LY2为框中心点y轴坐标;W为被测目标的实际高度;P为被测目标的y轴像素高度;FPS为检测帧率;K为km/h单位转换系数。
1.3.3" 车辆预警
完成车辆测距和测速的功能算法后,便可进一步根据前车距离和车速进行预警。这里,提前向算法输入一个人脑反应时间参数TR,它的含义是司机发现危险开始计时到踩下刹车刹停结束计时,这个参数和司机自身车辆车速有关,在实际应用中可以将自身实时车速作为参数输入进算法影响TR。根据测得前车的相对车速和车距计算危险时间TD,设置预警判断,若TD<0.5TR,判定为高风险,检测框标为红色,若0.5TR<TD<TR,判定为中风险,检测框标为黄色,若TD>TR,判定为无风险,检测框标为绿色。
完整的跟车辅助预警算法和仅具备检测功能的YOLOv5算法的效果对比如图3所示,其中(a)和(b)是跟车辅助算法的显示效果,(c)和(d)是YOLOv5算法的显示效果,可以看到,YOLOv5算法仅仅是对检测到的目标识别分类,框的颜色随检测类别变化,而跟车辅助预警算法对车距车速均有显示且以红、黄、绿三种不同的颜色预警。
2" 对目标检测模块的轻量化处理
原YOLOv5模型,即使是选用其较为轻量的YOLOv5s模型,也有超过七百万的参数量,以及16.5 B/G的计算量,而若选取模型最小的YOLOv5n模型,虽然参数量和计算量骤降至两百万和4.5 G/B,但是检测精度下降也特别明显,其mAP值在coco数据集上的表现甚至下降超过10%。为了减少车辆预警算法的计算量,确保检测的实时性,本文在YOLOv5s算法基础上做出轻量化处理,使用Mobilenetv3主干网络替换原YOLOv5s的backbone骨架,并且在特征融合层,引入GSConv卷积,进一步减轻了模型的复杂度,最后将损失函数改为WIoU,提升了检测精度。
2.1" Mobilenetv3替换YOLOv5s主干网络。
Mobilenet系列网络是由Google公司提出的轻量化网络,它的特点是参数量对比如今主流单阶段网络而言非常小,同时精确度接近主流单阶段网络。Mobilenetv3网络在Mobilenetv1网络[20]的深度可分离卷积以及Mobilenetv2网络[21]的残差连接思想的基础上引入了SE注意力机制[22],对特征层进行了压缩处理,对比前两个版本,其速度和精度均具有明显的优势。
2.1.1" 深度可分离卷积
在YOLO系列的神经网络中,卷积层是非常核心的模块,用于从输入的图像中提取特征。Mobilenet网络最明显的特点就是引入的深度可分离卷积,大幅降低了传统卷积因升维和降维带来的参数量。
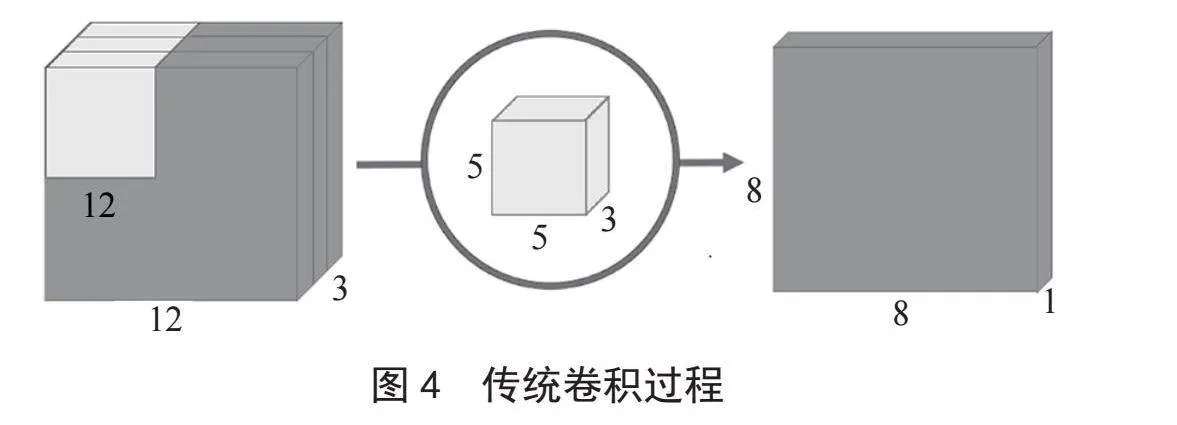
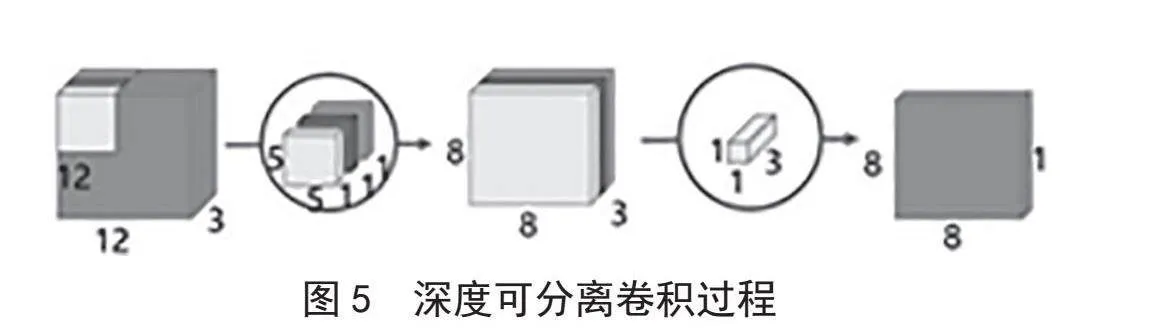
传统卷积的过程如图4所示,假设输入图像是12×12的二维图像,而彩色图像均为RGB格式,有R(红)、绿(G)和蓝(B)三层通道,因此图片的大小是12×12×3(宽、高、通道),其卷积核大小为5×5×3,经过卷积后得到8×8×1的输出层。而卷积核的个数等于最终输出层的通道数,每一个卷积核只能提取图片的一个特征属性,若需要对输入图像提取512个属性时,则需要512个卷积核,最终会得到一个8×8×512的输出层。
深度可分离卷积过程如图5所示,其首先对输入图像三个通道做逐通道卷积,依旧以12×12的输入图像为例,深度可分离卷积用三个5×5×1的卷积核分别对每个通道卷积,堆叠在一起得到8×8×3的图层,下一步进行逐点卷积,用一个1×1×3的卷积核卷积得到8×8×1的输出图像,此时输出的结果和传统卷积一样。
深度可分离卷积的输出结果和传统卷积一样,但中间的参数量和计算量大大减少,需要提取的特征属性数量越多,深度可分离卷积能够节省的参数和计算量越多。
2.1.2" h-swish函数和SE模块
Mobilenetv3对比V1和V2版本,主要的变化是其将V2中的ReLU6激活函数替换成了h-swish激活函数以及在V2翻转残差块基础上加入的SE模块。
原ReLU6函数对低纬特征的提取经常出现提取信息不完整的情况,Google团队原计划用sigmoid函数代替ReLU6,但是由于sigmoid函数计算效率较低,最终以h-swish函数作为激活函数以提高模型性能。ReLU6、sigmoid和h-swish三者的关系如式(3)和式(4)所示。
(3)
(4)
式中:x为函数输入值;β为可训练参数。
SE模块又称SE注意力机制,它的核心部分在于squeeze(压缩)和excitation(激励)两个操作。以一个1×1×C的输入为例,SE模块首先对输入进行一次全连接和激活操作,将输出通道数压缩,这里初始压缩值ratio设置为0.25,即通道数压缩至0.25C,之后再进行一次全连接和激活,再将输出通道数重新扩张为C。SE模块对输入通道先压缩,进过处理后再扩张的操作,能够弱化不重要特征的影响,从而能尽可能多地提取到更需要的特征。
2.2" 特征融合层引入GSConv卷积
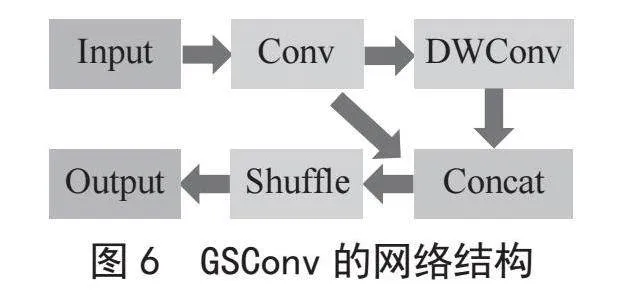
GSConv是一种轻量级卷积,它相比于传统卷积层Conv,计算量更低且精度也不会有明显下降。GSConv的网络结构如图6所示,首先进行一个普通卷积Conv下采样,然后用DWConv做深度卷积,再将Conv直接卷积的结果和DWConv深度卷积的结果进行Concat拼接,最后进行Shuffle[23-24]操作得到最终输出。
由于本文已将YOLOv5s的boneback替换成Mobilenetv3网络,因此仅将neck部分的普通Conv卷积替换成GSConv卷积,这样能够有效地降低模型neck部分的网络复杂度。
2.3" 损失函数改进
YOLOv5的损失函数包括坐标损失、置信度损失和类别损失三部分。YOLOv5原本的坐标损失函数GIoU和CIoU都还存在一些问题,前者不能处理目标框包含预测框的情况,后者没有考虑到边界框宽高分别与其置信度的真实差异。针对这些问题,本文经过对比实验后最终采用Wise-IoU作为改进模型的损失函数,其计算公式如式(5)所示。
(5)
式中:n为目标框的数量;bi为第i个目标框的坐
标;gi为第i个目标的真实标注框坐标;IoU(bi,gi)为第i个目标框与真实标注框之间的IoU值;ωi为权重值。
Wise-IoU考虑了预测框与真实框之间的区域进行IoU加权,对传统IoU评估结果时可能存在的偏差问题进行了很好的改善。后续的实验也证明了Wise-IoU对于本文的应用场景相比于其他损失函数具有明显的优越性。
3" 实验结果与分析
3.1" 实验平台
本文实验环境基于Ubuntu 20.04操作系统,GPU为NVIDIA GeForce RTX3080,10 GB显存,CPU为Intel Xeon Platinum 8255C,开发框架为PyTorch,以Python为编程语言,CUDA版本为11.8。
3.2" 数据集
由于本文算法是针对道路车辆的跟车辅助算法,检测对象为和驾驶车辆同向行驶的各种道路车辆,因此本文将需要检测的目标分为bicycle、car、motorcycle、bus和truck五个类别,为了提升训练效果,本文将全部以第一行车视角的画面作为数据集,且画面中的车辆目标应是背朝驾驶车辆才符合跟车场景,而目前的公开数据集大多不能满足上述全部要求,因此,本文决定专门收集制作符合本文条件的数据集。
本文以行车记录仪的方式获取了10段超过两小时的第一行车视角视频,其中涵盖了早中晚三个时段。为避免数据集相邻图片过于相似,以10 s为间隔截取视频图片,截取的大小为1 920×1 080,标注的标签为bicycle、car、motorcycle、bus和truck五个类别。该数据集共包含5 600张图片,其中随机选择4 480张(80%)作为训练集,560张(10%)作为验证集,560张(10%)作为测试集。
3.3" 实验结果与分析
3.3.1" 网络结构消融实验对比
本文对YOLOv5s神经网络模型做了主干网络改为Mobilenetv3和特征融合层引入GSConv卷积这两种网络结构的轻量化设计,为了验证这两种网络结构设计的效果,本文做了相应的消融实验,实验结果如表2所示。
表2中,用“√”标记则表示实验采取了该方法。从表2中可以看出,和YOLOv5s原主干网络相比,Mobilenetv3网络虽会使mAP值略微下降,但在仅仅下降0.6%的情况下,其参数量下降了约29%,权重文件大小下降了约27.8%,在原YOLOv5s特征融合层(即Neck部分)引入GSConv卷积后效果与主干替换为Mobilenetv3的效果类似,参数量和权重文件大小对比原YOLOv5s模型都有一定程度的下降,mAP值也存在微小下降,其下降幅度都小于Mobilenetv3方法。从表2的实验4可以看出,Mobilenetv3和GSConv方法的轻量化效果可以叠加,这两种方法同时采用时,mAP值仅下降0.8%,而参数量和权重文件大小分别下降了37%和36.1%。实验证明,Mobilenetv3和GSConv改进方法在确保检测准确率对比原YOLOv5s算法几乎不下降的情况下,模型体积大幅减小,这一改进使得检测速度在YOLOv5s的基础上提升了23.8%。
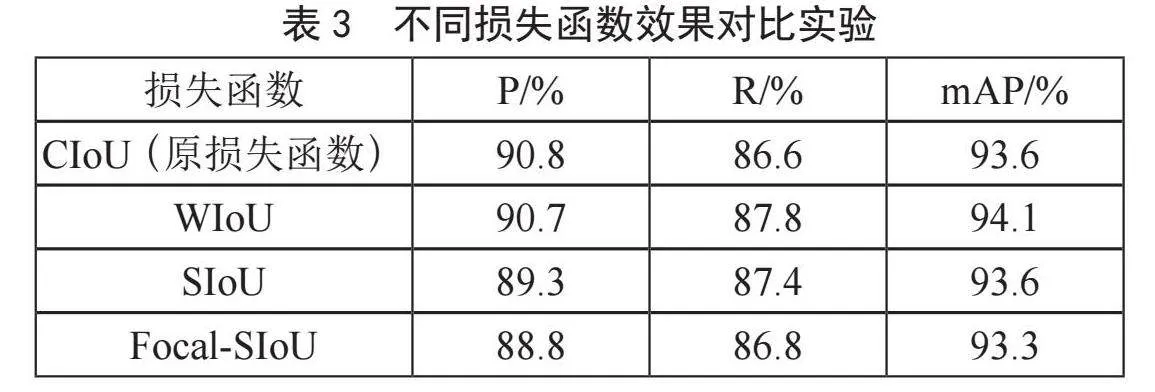
3.3.2" 几种损失函数实验对比
本文在确定Mobilenetv3和GSConv的模型改进的有效性后,考虑到原本YOLOv5的损失函数仍存在些许问题,决定分别采用当下理论上效果较好的几种损失函数WIoU、SIoU、Focal-SIoU应用到本文算法进行对比,对比实验除了损失函数不同其余部分均相同(以表2中4号实验即Mobilenetv3和GSConv的模型作为基础更换损失函数),对比实验的结果如表3所示。
由于损失函数的改变不会影响模型的结构,也不会造成参数量和权重文件的改变,因此仅从精确度、召回率和mAP值这三个指标对比。从表3可以看出,在当前应用场景下,WIoU相比原损失函数(CIoU)性能有所提升,SIoU性能和原损失函数大致相同,Focal-SIoU性能则弱于原损失函数。基于上述实验结果,本文最终确定了Mobilenetv3替换主干,GSConv卷积引入特征提取层以及WIoU替换原CIoU损失函数的改进模型。
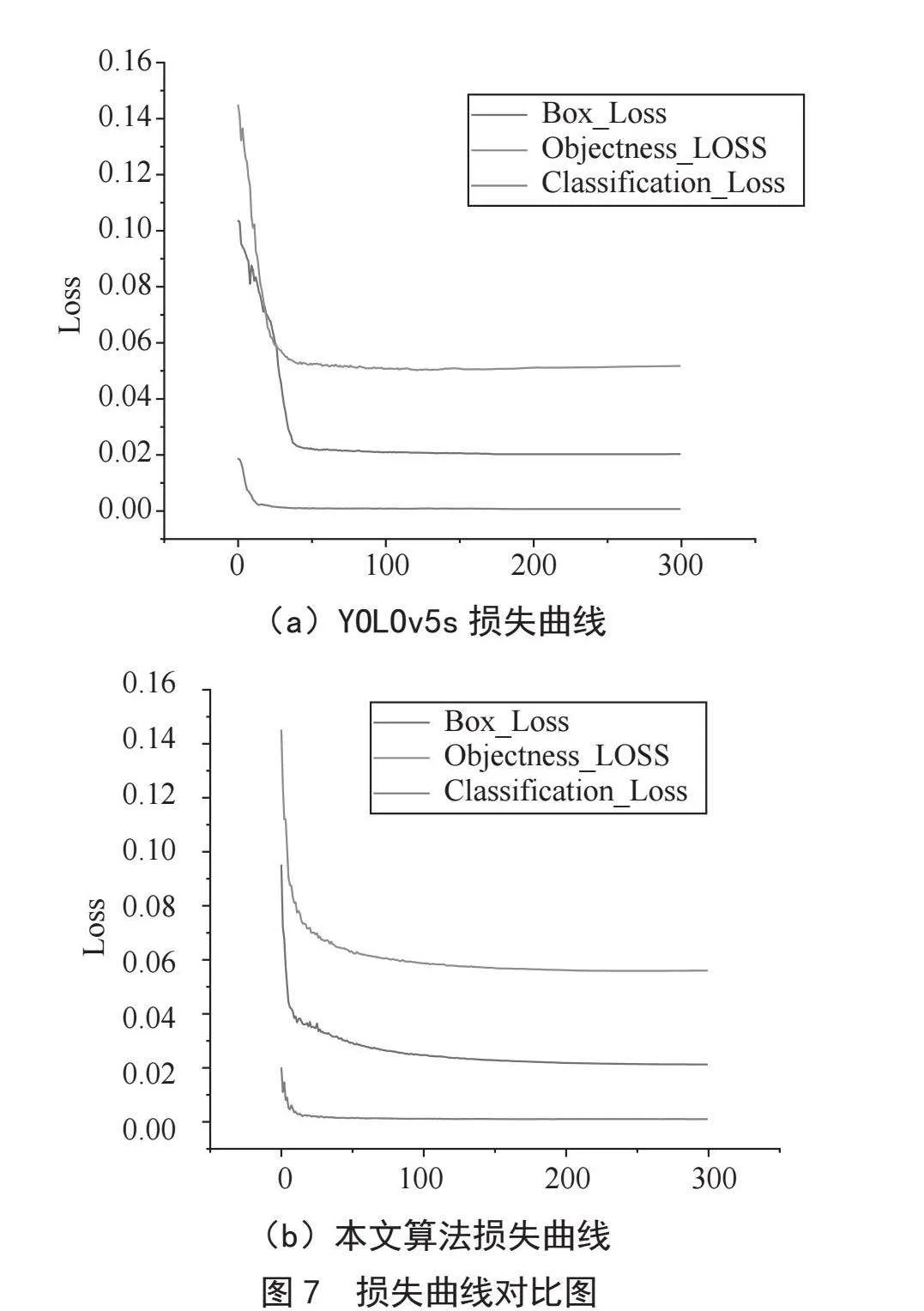
图7给出了本文算法与原YOLOv5s模型的损失曲线对比,其中(a)是YOLOv5s的损失曲线,(b)是本文算法的损失曲线。从图7中可以看出本文算法收敛得更快、更平稳,尤其是Box Loss曲线和Objectness Loss曲线,本文算法在前10轮就已经开始收敛,之后损失曲线趋于平稳,而原YOLOv5s算法的Box Loss曲线和Objectness Loss曲线在第50轮左右才开始收敛,且Objectness Loss曲线后期还出现回升的情况,收敛性并不理想。这一结果也证明了本文算法对图像处理速度相较于原YOLOv5s模型更快。
3.3.3" 不同网络模型在本文场景的检测效果对比
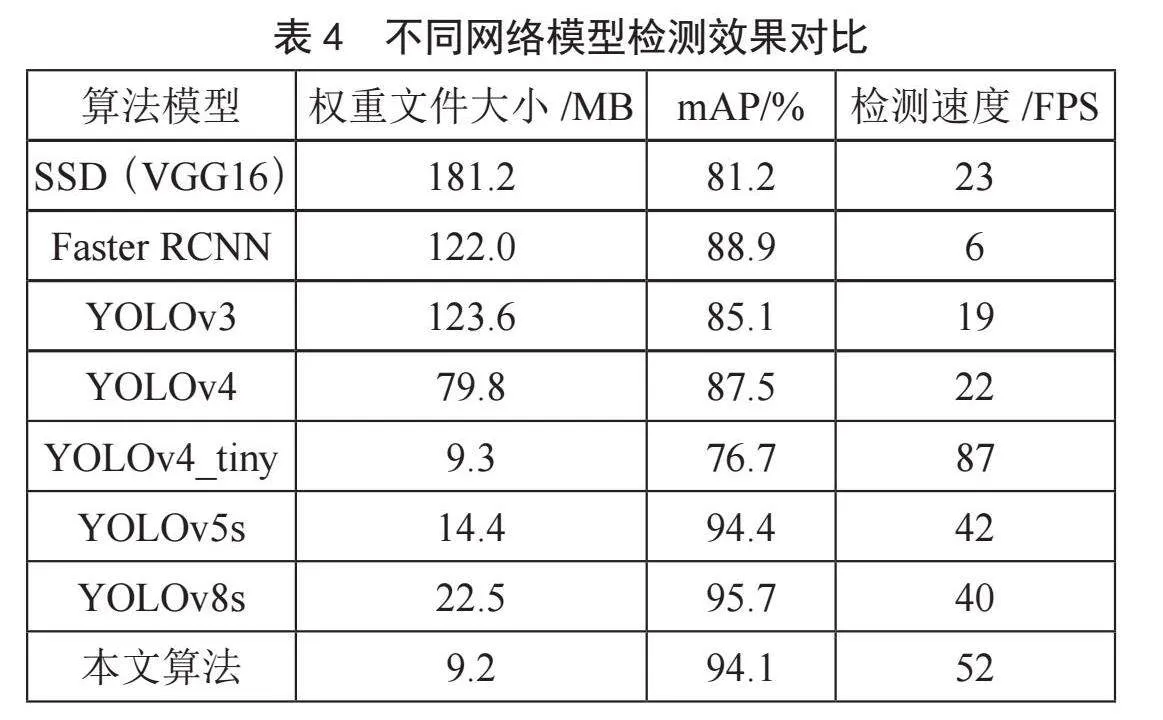
为了进一步验证本文算法的可行性,将本文算法和目前其他较为先进的目标检测算法进行对比实验分析,主要从模型大小、mAP值和检测速度三个方面对比。实验结果如表4所示。
由表4可以看出,在道路跟车场景中,本文的改进算法对比目前其他主要的目标检测算法明显的优越性,其权重文件在表4所有模型中是最小的,检测速度仅次于YOLOv4_tiny,mAP值虽然略低于YOLOv5s和YOLOv8算法,但是差距并不大,且其准确度已经基本满足当前场景的要求。本文算法较好地平衡了检测速度和检测精度,在确保检测精度足够高的同时将模型优化得更加轻量化,即做到了更快速的检测也降低了算法对硬件平台的依赖性。
4" 结" 论
本文提出的基于轻量型YOLOv5和Deeepsort的跟车辅助预警算法具有很高的实用价值,算法所改进的轻量型YOLOv5模型对比目前其他目标检测的神经网络模型,在检测精度、检测速度和模型参数大小上做到了很好的平衡,在保证高检测精度的同时具备了较快的检测速度,且其轻量高效的模型能更好地应用于移动端硬件设备,具有明显的优越性。
参考文献:
[1] 范佳琦,李鑫,霍天娇,等.基于单阶段算法的智能汽车跨域检测研究 [J].中国公路学报,2022,35(3):249-262.
[2] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot Multibox Detector [C]//Computer Vision-ECCV 2016.Amsterdam:Springer,2016:21-37.
[3] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[4] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] 符惠桐,王鹏,李晓艳,等.面向移动目标识别的轻量化网络模型 [J].西安交通大学学报,2021,55(7):124-131.
[6] WANG C Y,BOCHKOVSKIY A,LIAO H Y M. Scaled-YOLOv4: Scaling Cross Stage Partial Network [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:13029-13038.
[7] WOJKE N,BEWLEY A,PAULUS D. Simple Online and Realtime Tracking with a Deep Association Metric [C]//2017 IEEE International Conference on Image Processing (ICIP).Beijing:IEEE,2017:3645-3649.
[8] STEIN G P,MANO O,SHASHUA A. Vision-based ACC with a Single Camera: Bounds on Range and Range Rate Accuracy [C]//IEEE IV2003 Intelligent Vehicles Symposium Proceedings(Cat.No.03TH8683).Columbus:IEEE,2003:120-125.
[9] RAJKUMAR R I,SUNDARI G. Intelligent Computing Hardware for Collision Avoidance and Warning in High Speed Rail Networks [J/OL].Journal of Ambient Intelligence and Humanized Computing,2020:1-13(2020-01-04).https://doi.org/10.1007/s12652-019-01661-z.
[10] ZHE T,HUANG L Q,WU Q,et al. Inter-Vehicle Distance Estimation Method based on Monocular Vision Using 3D Detection [J].IEEE Transactions on Vehicular Technology,2020,69(5):4907-4919.
[11] HOWARD A,SANDLER M,CHEN B,et al. Searching for MobileNetV3 [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2020:1314-1324.
[12] LI H L,LI J,WEI H B,et al. Slim-neck by GSConv: A Better Design Paradigm of Detector Architectures for Autonomous Vehicles[J/OL].arXiv:2206.02424 [cs.CV].(2022-06-06).https://arxiv.org/abs/2206.02424.
[13] TONG Z J,CHEN Y H,XU Z W,et al. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism [J/OL].arXiv:2301.10051 [cs.CV].https://arxiv.org/abs/2301.10051.
[14] ZHENG Z H,WANG P,LIU W,et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression [J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):12993-13000.
[15] KALMAN R E. A New Approach to Linear Filtering and Prediction Problems [J].Journal of Basic Engineering,1960,82(1):35-45.
[16] WANG D,YEUNG D S,TSANG E C C. Weighted Mahalanobis Distance Kernels for Support Vector Machines [J].IEEE Transactions on Neural Networks,2007,18(5):1453-1462.
[17] ZHANG Z D,GANESH A,LIANG X,et al. TILT: Transform Invariant Low-Rank Textures [J].International Journal of Computer Vision,2012,99:1-24.
[18] DING Y Y,XIAO Y H. Symmetric Gauss-Seidel Technique-Based Alternating Direction Methods of Multipliers for Transform Invariant Low-Rank Textures Problem [J].Journal of Mathematical lmaging and Vision,2018,60:1220-1230.
[19] SIMONELLI A,BULO S R,PORZI L,et al. Towards Generalization Across Depth for Monocular 3D Object Detection [C]//Computer Vision-ECCV 2020.Glasgow:Springer International Publishing,2020:767-782.
[20] HOWARD A G,ZHU M,CHEN B,et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications [J].arXiv:1704.04861 [cs.CV].http://www.arxiv.org/abs/1704.04861.
[21] SANDLER M,HOWARD A,ZHU M,et al. Mobilenetv2: Inverted Residuals and Linear Bottlenecks [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.IEEE,2018:4510-4520.
[22] HU J,SHEN L,SUN G. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[23] ZHANG X Y,ZHOU X Y,LIN M X,et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:6848-6856.
[24] MA N N,ZHANG X Y,ZHENG H T,et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design [C]//Computer Vision-ECCV 2018.Munich:Springer,2018:122-138.
作者简介:张海川(1998—),男,汉族,四川江油人,硕士在读,研究方向:智能驾驶领域中的目标检测。