


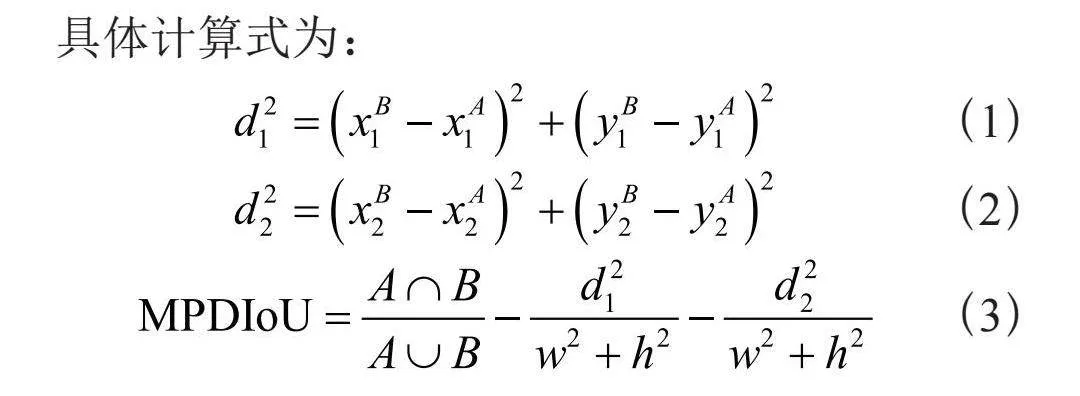

摘" 要:现有的目标检测网络往往存在结构复杂、参数量巨大的问题。因此,研究结构简单、参数量少的高精度目标检测算法,其重要性和价值不言而喻。YOLO系列算法作为深度学习时代具有代表性的单阶段目标检测算法,具有准确、高效和易于部署等特点,为目标检测提供了非常好的理论及技术基础。因此,文章在YOLOv8的基础上对其卷积网络进行改进,实验结果证明,改进算法成功提升了检测精度。
关键词:目标检测;高精度;YOLOv8;卷积网络
中图分类号:TP391.4" " 文献标识码:A" " " 文章编号:2096-4706(2024)18-0052-07
Research on the Improvement of Target Detection Algorithm Based on YOLOv8
XIAO Fukun
(Shenyang Aerospace University, Shenyang" 110136, China)
Abstract: The existing target detection network often has the problems of complex structure and huge parameters. Therefore, it is difficult to study the high-precision target detection algorithm with simple structure and a few parameters. As a representative single-stage target detection algorithm in the era of Deep Learning, YOLO series algorithms have the characteristics of accuracy, high efficiency and easy deployment, which provides a very good theoretical and technical basis for target detection. Therefore, this paper improves its convolutional network based on YOLOv8 and successfully improves the detection accuracy.
Keywords: target detection; high accuracy; YOLOv8; convolutional network
0" 引" 言
目标检测是计算机视觉领域中的重要任务之一,它旨在从图像或视频中准确识别和定位多个目标。该技术的广泛应用包括智能交通系统、行人检测、视频监控、无人驾驶和机器人导航等领域。然而,传统的目标检测算法在处理复杂背景[1]、遮挡[2]和不同尺度目标[3-4]等方面存在一定的困难。
近年来,基于深度学习的目标检测算法取得了显著的突破,其中以YOLO系列算法最为知名。YOLO算法通过将目标检测任务转化为一个回归问题,将目标位置及其相关特征直接从输入图像中预测出来,实现了实时目标检测。然而,YOLO算法中存在精度和速度之间的权衡,难以同时满足高精度和实时性的需求。
因此,在本文中,我们提出了一种基于YOLOv8的改进目标检测算法,旨在提高目标检测算法的精度和实时性。该改进算法主要包括以下几个方面的改进:首先,我们采用了更深、更宽的YOLOv8网络结构,以提高特征提取和表示能力;其次,我们引入了多尺度特征融合机制[5],通过融合不同层次的特征信息,提高目标检测的准确性和鲁棒性;此外,我们针对目标边界框定位不准确的问题,提出了一种基于回归和分类的改进策略,以提高目标定位的精确性。
为了验证我们算法的有效性,我们在公开数据集上进行了大量实验。实验结果表明,我们的算法在目标检测的精度和实时性上取得了显著的提升。与传统的目标检测算法相比,我们的算法在保持高精度的同时,大大缩短了目标检测的时间开销。此外,我们的算法还在复杂背景、遮挡和不同尺度目标等方面展示了更好的鲁棒性和适应性。
1" YOLOv8目标检测算法
1.1" 经典的YOLOv8目标检测算法
经典的YOLOv8目标检测算法是YOLO系列的最新版本,在目标检测领域取得了巨大的成功。相比于以往的版本,YOLOv8算法在检测精度和速度方面都有显著的提升。本节将介绍YOLOv8算法的原理、网络结构和关键技术。
原理:YOLOv8算法采用了单阶段检测的思想,将目标检测任务转化为一个回归问题。它将图像分割为多个网格,每个网格预测一个或多个目标的边界框和类别概率。与其他目标检测算法相比,YOLOv8能够实现实时的目标检测,因为它将检测任务简化为一个单一的前向传播过程。
网络结构:YOLOv8网络结构由主干网络和检测头组成。主干网络通常使用Darknet-53或Darknet-19,它们采用预训练的卷积神经网络(CNN)作为特征提取器。检测头则负责根据主干网络提取的特征进行目标位置和类别的预测。
关键技术:YOLOv8引入了一系列关键技术来提高检测的精度和速度。其中包括:特征金字塔网络(FPN):为了解决不同尺度目标的检测问题,YOLOv8使用了FPN技术,通过在不同层级的特征图上进行目标检测,并通过特征融合来提高检测的精度。
网络设计优化:YOLOv8通过调整网络结构和参数优化来提高目标检测的精度和速度。例如,引入了残差连接和多尺度预测等技术来加强网络的非线性表示能力和目标分辨率。
损失函数设计:为了提高目标检测的准确性,YOLOv8采用了一种综合的损失函数,既考虑边界框的位置准确性,又考虑类别预测的准确性。这样可以使网络更好地同时预测目标的位置和类别,从而提高检测的精度。
1.2" YOLOv8目标检测算法存在的问题
尽管YOLOv8目标检测算法在精度和速度方面取得了显著的提升,但仍然存在一些问题和挑战需要解决。以下是目前该算法存在的一些主要问题:
1)难以检测小目标。由于YOLOv8算法将图像分成固定大小的网格,在网格大小较小时,算法难以检测小目标。这是因为小目标的特征信息可能在低分辨率的网格中丢失,导致检测精度下降。
2)多尺度目标检测效果有限。虽然YOLOv8算法引入了特征金字塔网络(FPN),但仍然存在多尺度目标检测效果有限的问题。当目标出现尺度变化较大或在不同层级的特征图中时,算法可能无法准确地检测到目标。对密集目标的处理不佳:YOLOv8算法在处理密集目标的能力上仍有待改进。当目标之间存在重叠或密集分布时,算法可能会出现目标漏检或误检的情况。
3)背景干扰敏感。YOLOv8算法对于复杂背景和遮挡等情况比较敏感。在存在大量背景干扰或目标被遮挡的情况下,算法可能会产生误检测或错误的定位结果。
4)目标定位不准确。虽然YOLOv8算法通过引入回归和分类的策略来改进目标的定位精度,但仍然存在一定程度的位置偏差问题。在目标边界框的定位精度方面,YOLOv8算法可以进一步提高。
2" 基于YOLOv8的改进目标检测算法
2.1" 动态蛇形卷积
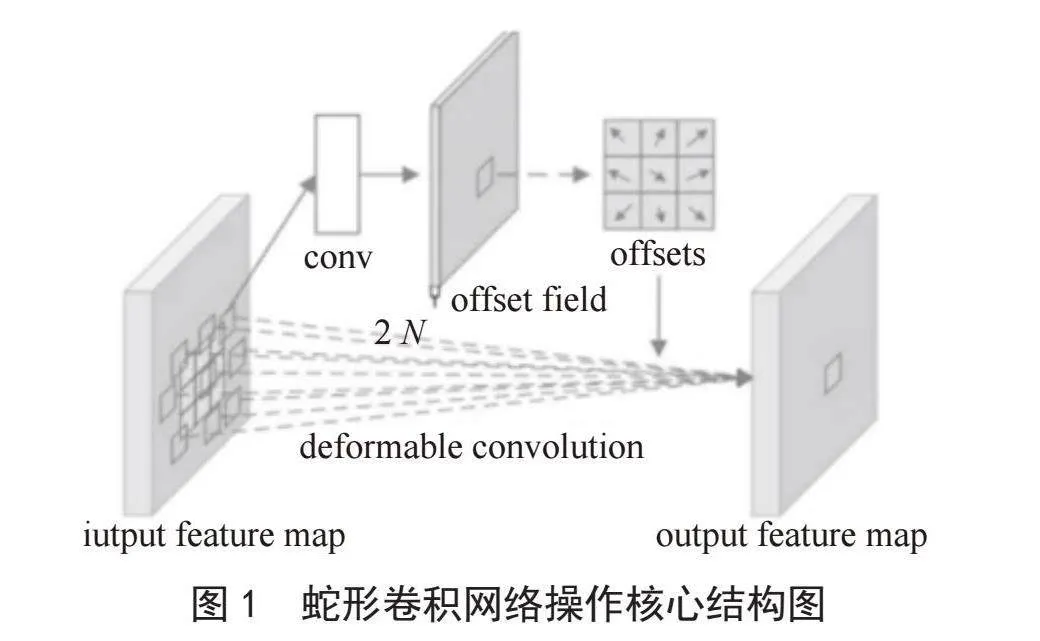
在分析了YOLOv8原有的卷积结构后,我们尝试使用动态蛇形卷积网络[6]来代替原有的卷积网络以提高检测精度。动态蛇形卷积模块可以关注到管状结构细长连续的特点,并利用这一信息在以下3个阶段同时增强感知:特征提取、特征融合和损失约束。我们希望卷积核一方面能够自由地贴合结构学习特征,另一方面能够在约束条件下不偏离目标结构太远。蛇形卷积的操作核心图如图1所示。
如图1所示,我们会发现,操控单个卷积核形变的所有偏置(offset),是在网络中一次性全部学到的,并且对于这一个偏置只有一个范围的约束,即感受野范围(extend)。控制所有的卷积发生形变,是依赖于整个网络最终的损失约束回传,这个变化过程是相当自由的。
在目标检测过程中,有两个巨大的挑战,即目标模型细长且脆弱的局部结构,以及复杂且多变的全局形态。细长的结构仅占整个图像的一小部分,像素的组成有限。此外,这些结构容易受到复杂背景的干扰,因此模型很难精确分辨目标的细微变化,从而导致分割出现破碎与断裂。位于不同区域的目标的形态变化取决于分支的数量、分叉的位置,路径长度以及其在图像中的位置。因此当数据表现出未曾见过的形态特征时,模型倾向于过拟合到已见过的特征,无法识别未见过的特征形态,从而导致泛化性较弱。考虑到结构的走向与视角从来不是单一的,因此融合多视角特征也是必然的选择。然而,融合更多的特征带来的必然结果,就是更大的网络负载,且如此多的特征难免会出现冗余,因此动态蛇形卷积模块在特征融合的训练过程中加入了分组与随机丢弃的策略,一定程度上缓解了网络内内存的压力并避免模型陷入过拟合。
动态蛇形卷积通过在卷积过程中能够自适应地调整感受野的形状和大小,从而能够更好地适应不同尺度和形状的目标。动态蛇形卷积可以捕捉更丰富的空间信息,并减少目标形状变化时的信息损失。它在处理小目标、长条状目标和遮挡目标等情况下表现出了更强的适应性和鲁棒性。
2.2" MPDIoU损失回归函数
YOLOv8目标检测算法中使用的传统IoU只考虑了目标框的一个点,这大大限制了目标检测的精度。我们使用能够考虑目标框周围多个点的MPDIoU[7]去替换传统的IoU。相比于传统的IoU,MPDIoU可以提供更准确的交并比度量[8],从而提高了目标检测算法的精度。
具体计算式为:
(1)
(2)
(3)
其中,A、B分别表示两个任意凸形;w、h分别表示输入图像的宽度、高度;、分别表示A的左上和右下点坐标;、分别表示B的左上和右下点坐标;、分别表示是A、B左上角点间距和右下角点间距的平方。
MPDIoU简化了两个边界框之间的相似性比较,帮助算法选择最合适的边界框来准确定位目标。特别是在目标形状复杂、目标之间存在部分重合或遮挡的情况下,MPDIoU函数能够更好地捕捉目标框之间的重叠信息,提高目标检测的准确性,降低目标的漏检率。
2.3" SCConv卷积
由于卷积层提取冗余特征,其计算资源需求巨大。虽然过去用于改善网络效率的各种模型压缩策略和网络设计,包括网络剪枝、权重量化、低秩分解和知识蒸馏[9]等。然而,这些方法都被视为后处理步骤,因此它们的性能通常受到给定初始模型的上限约束。而SCConv卷积网络[10]解决了这一问题,SCConv卷积利用了两个组件,分别是空间重建单元(SRU)和通道重建单元(CRU)。
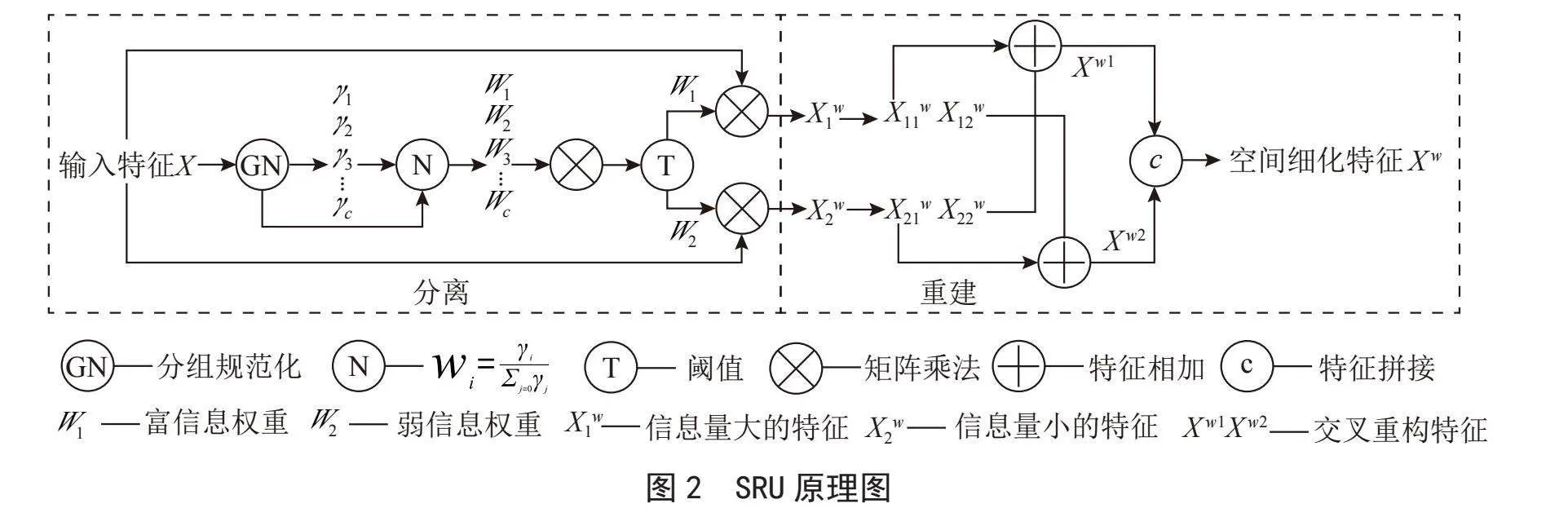
SRU通过一种分离-重建的方法抑制空间冗余,获得空间细化特征X w。其原理图如图2所示。
首先将输入特征X进行归一化GN得到输出特征Xout:
(4)
将随机初始化参数γ归一化后得到通道权重Wγ:
(5)
将Wγ与Xout相乘的值映射到(0,1)之间,使用阈值进行门控。大于阈值的Wγ视为有用特征设置为W1,小于阈值的Wγ视为无用特征设置为W2,通过式(6)计算可同时得到权重W1及W2,用W表示:
(6)
最后式(4)至(8)中使用交叉重建[11]的方法在空间维度上增强有用特征抑制冗余特征,获得空间细化特征X w:
(7)
(8)
(9)
(10)
(11)
其中,X表示任意给定的中间映射;u表示X的均值;σ表示X的标注差;ε表示一个常数;γ和β表示可训练的仿射变换;W表示通过门控同时得到的富信息权重W 1和弱信息权重W 2。
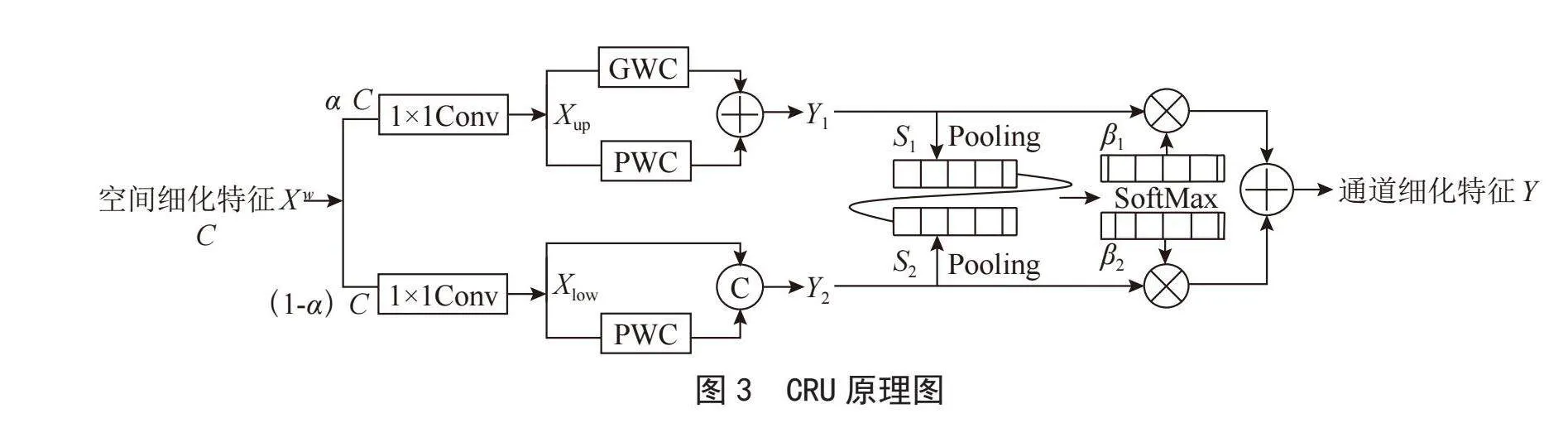
通过SRU得到的空间细化特征X w实际在通道上仍有冗余,这时则需要CRU来清除通道冗余。CRU采用的是分割—转换—融合的策略来减少通道冗余。图3为CRU原理图。
如图3所示,CRU先分割空间细化特征X w将其分为富特征提取器Xup和浅特征提取器Xlow。Xup采用的是GWC(Group-wise Convolution)和PWC(Point-Wise Convolution)[12]卷积运算来替换掉标准卷积,以更少的计算时间来提取出代表性特征Y 1,Xlow则使用更简单的1×1PWC运算生成浅特征映射得到Y 2作为对Xup的补充。最后,将Y 1与Y 2融合即可得到具有更多有效特征信息的通道细化特征Y,这样就能够既减少了信息冗余又提取出了有效信息。
此外,SCConv是一个即插即用的架构单元,可以直接替换各种卷积神经网络中的标准卷积。
SCConv模块旨在有效地限制特征冗余,不仅减少了模型参数和Flops的数量,而且增强了特征表示的能力。实际上,SCConv模块提供了一种新的视角来看待CNNs的特征提取过程,提出了一种更有效地利用空间和通道冗余的方法,从而在减少冗余特征的同时提高模型性能。实验结果显示,嵌入了SCConv模块的模型能够通过显著降低复杂性和计算成本,减少冗余特征,从而达到更好的性能。
3" 实验结果及分析
3.1" 实验数据集
如图4所示,本次实验采用的数据集是经典的VOC数据集[13]。为验证改进算法的有效性,选用深度学习框架。该数据集包含8个种类,一共有19 000多张图片,验证集有4 942张图片。本文把学习率改为0.001,衰减因子为0.1,然后进行迭代训练。
3.2" 训练过程
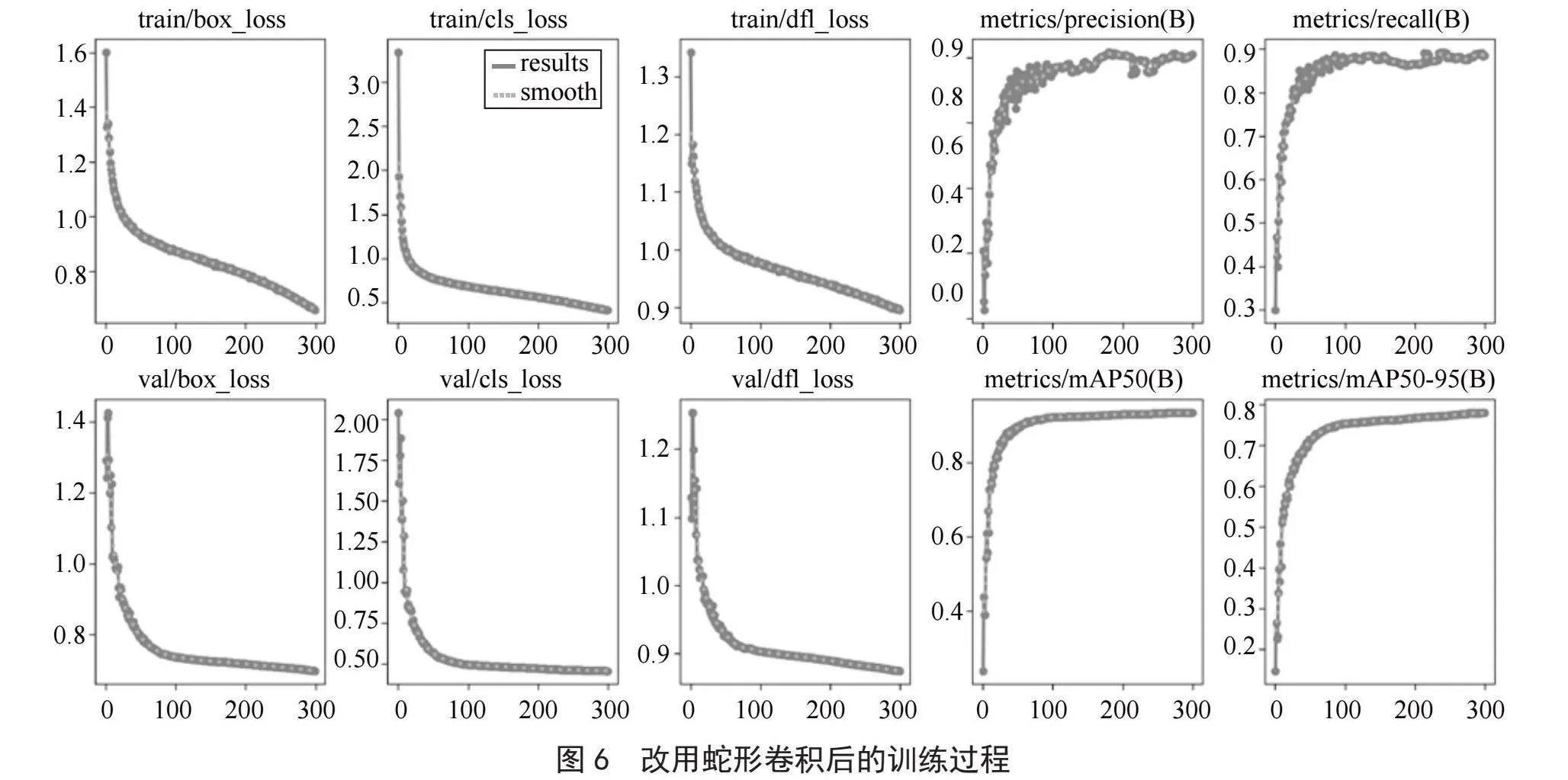
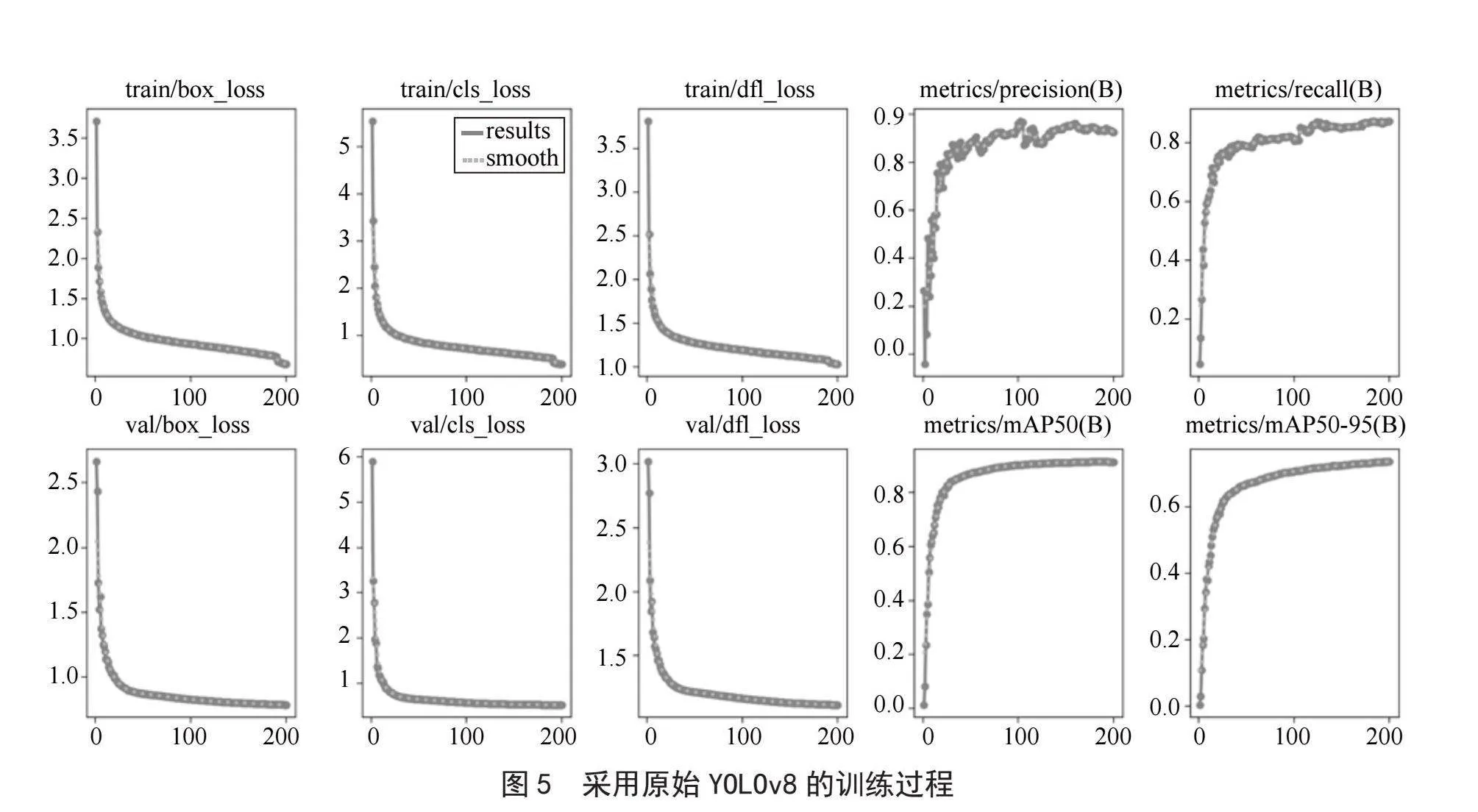
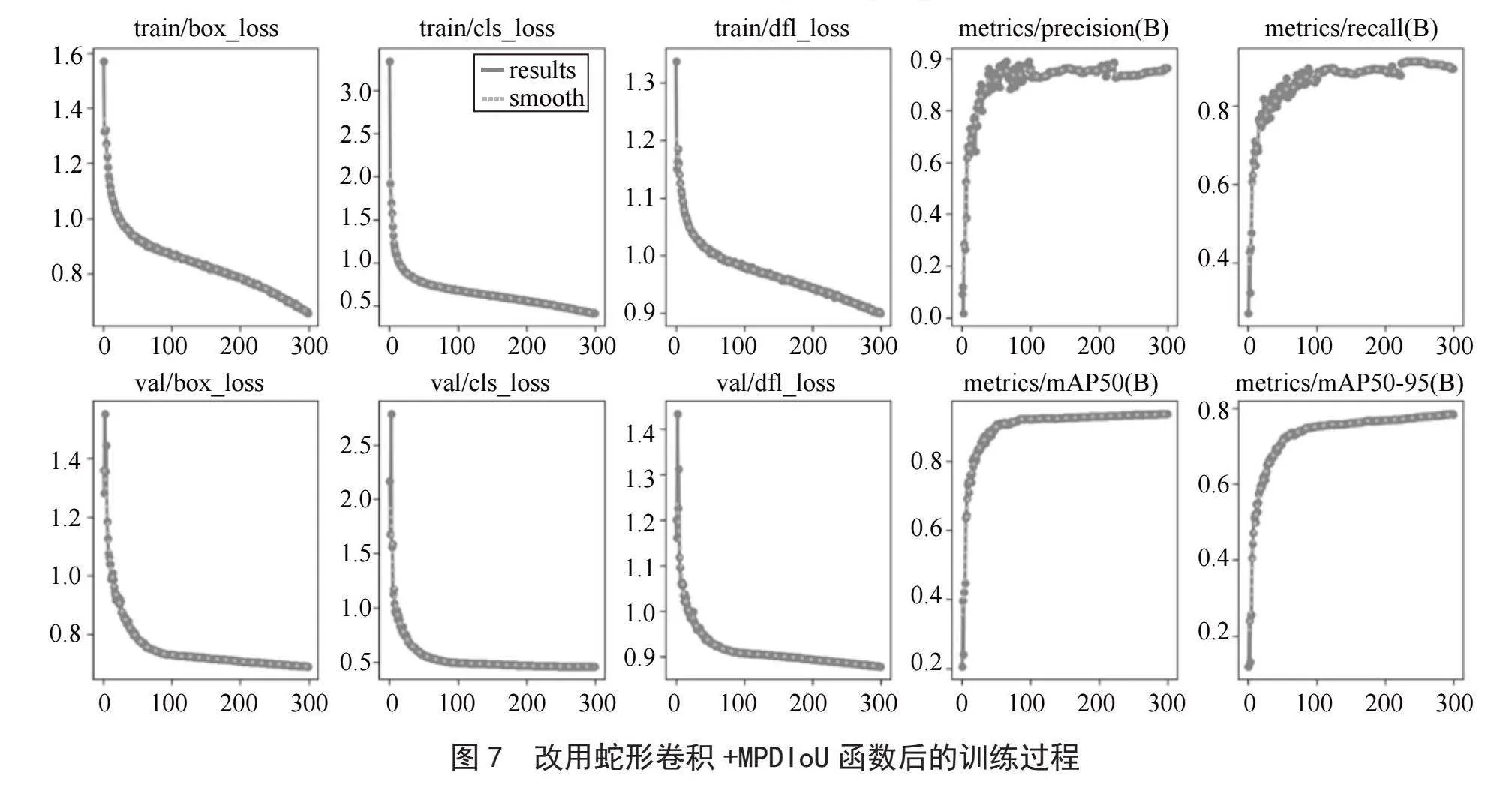
选择Windows环境下的Visual Studio Code[14]作为实验平台。训练过程一共训练4次,每次300轮。分别使用的是原始的YOLOv8算法、改用蛇形卷积后的算法、改用蛇形卷积再用MPDIoU替换IoU后的算法、改用SCConv卷积后的算法。本次实验实现了本文预期的提高目标检测精度的目标。
如图5至图7所示,对比于原始的YOLOv8,我们可以清晰地看到通过蛇形卷积网络模块和MPDIoU函数改进后的YOLO算法极大地降低了目标检测的损失率。这是由于改进后的算法对于有遮挡的目标、有重合的目标以及目标形状变化时的各种情况下有着更为高效的检测能力。
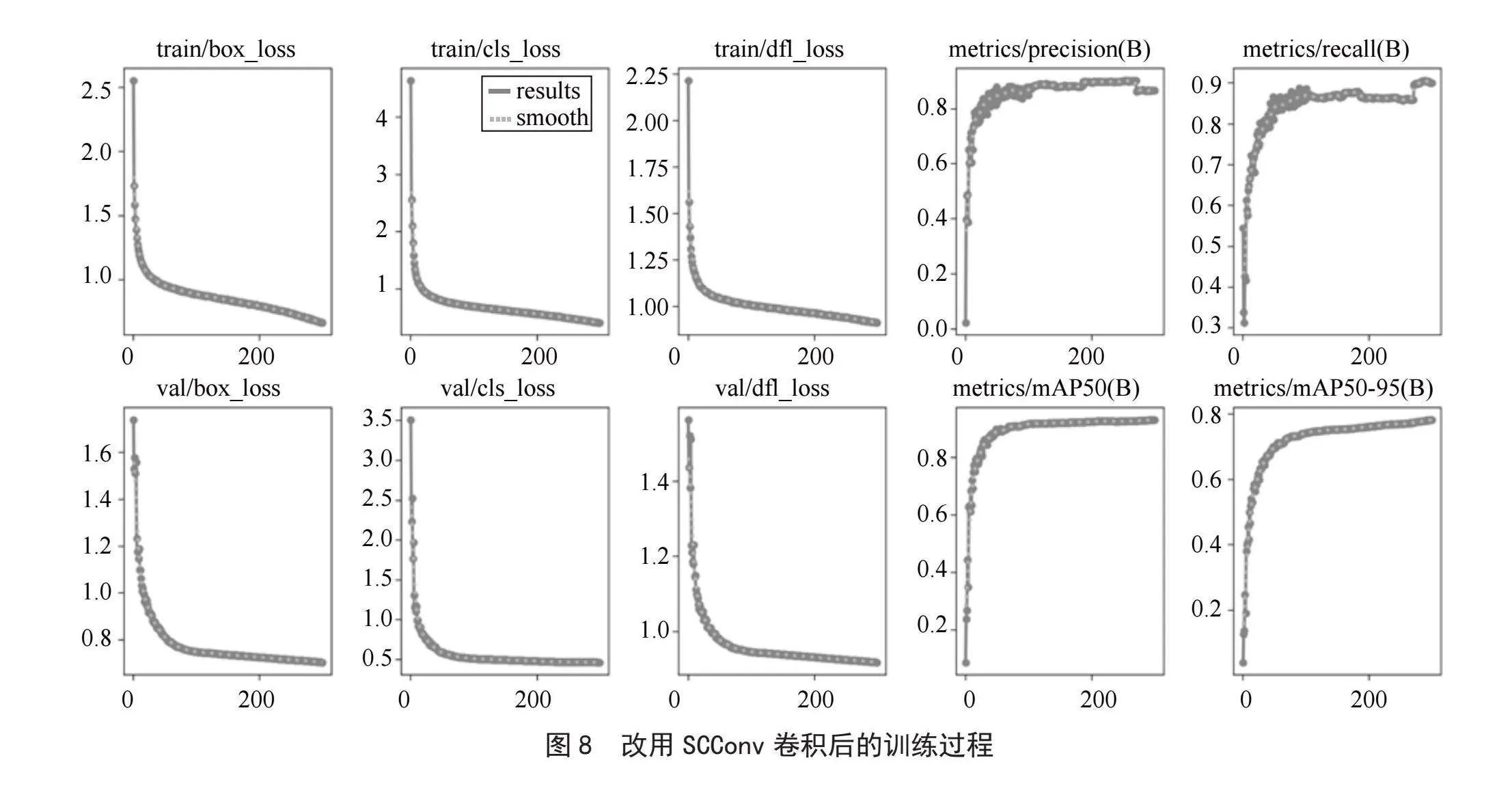
如图8所示,改进了SCConv卷积网络后的算法,极大地提升了检测速度,在训练了50轮之后就已经能够达到高精度的目标检测能力。这是由于SCConv卷积网络消除特征冗余的特性,这显著地降低了检测的复杂性。
3.3" 算法精度评价
通过本次试验结果可以明显地看出改进的网络结构在目标检测的精度上有非常明显的提高,在损失函数方面,改进后的算法极大地减少了目标形状变化时的信息损失。
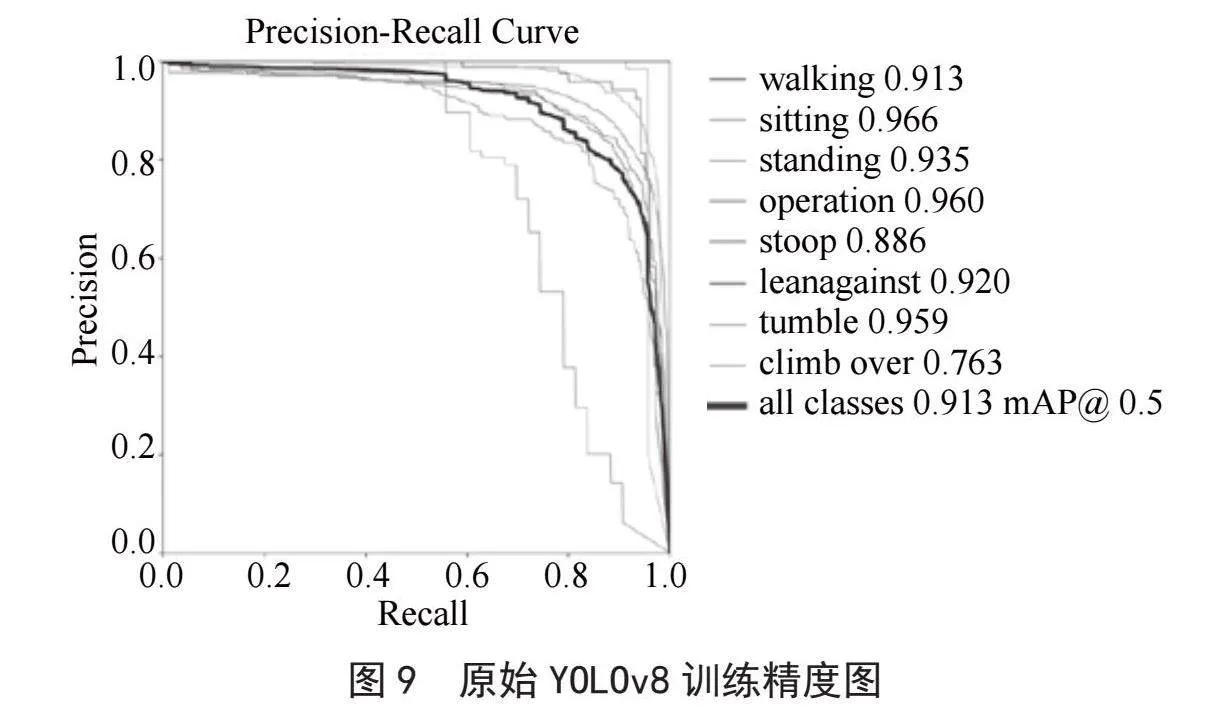
如图9所示,使用原始YOLOv8模型训练后的平均mAP为0.913。
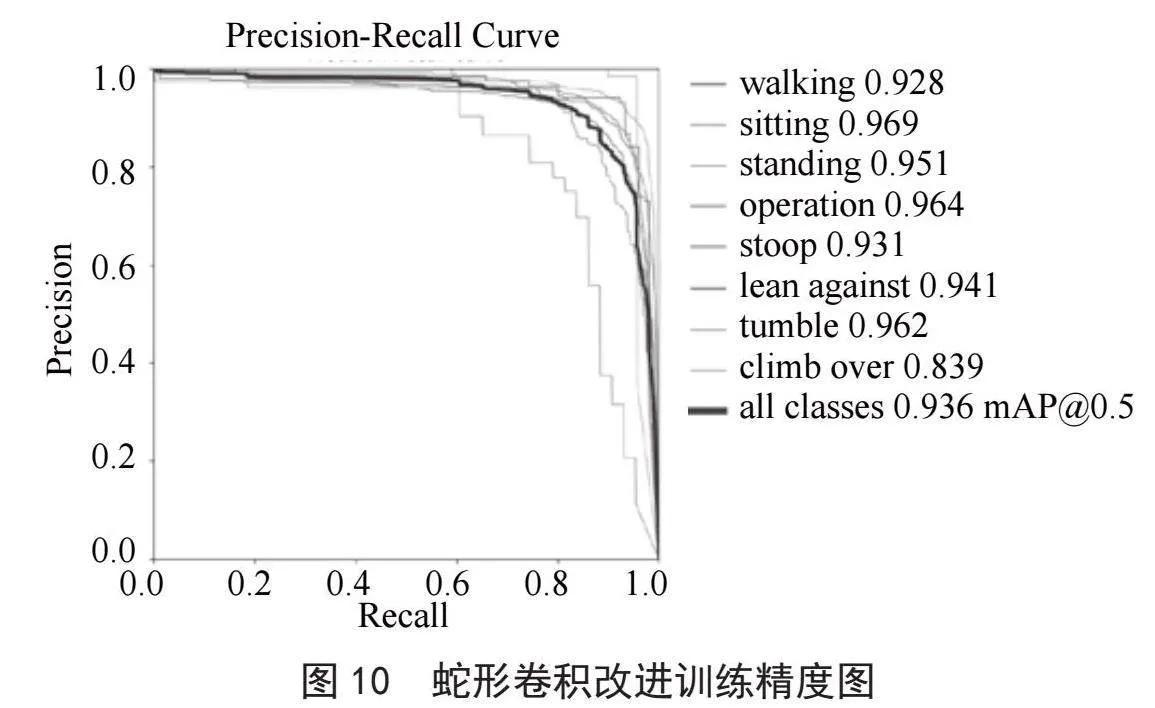
如图10所示,使用蛇形卷积改进算法后的平均mAP为0.936。
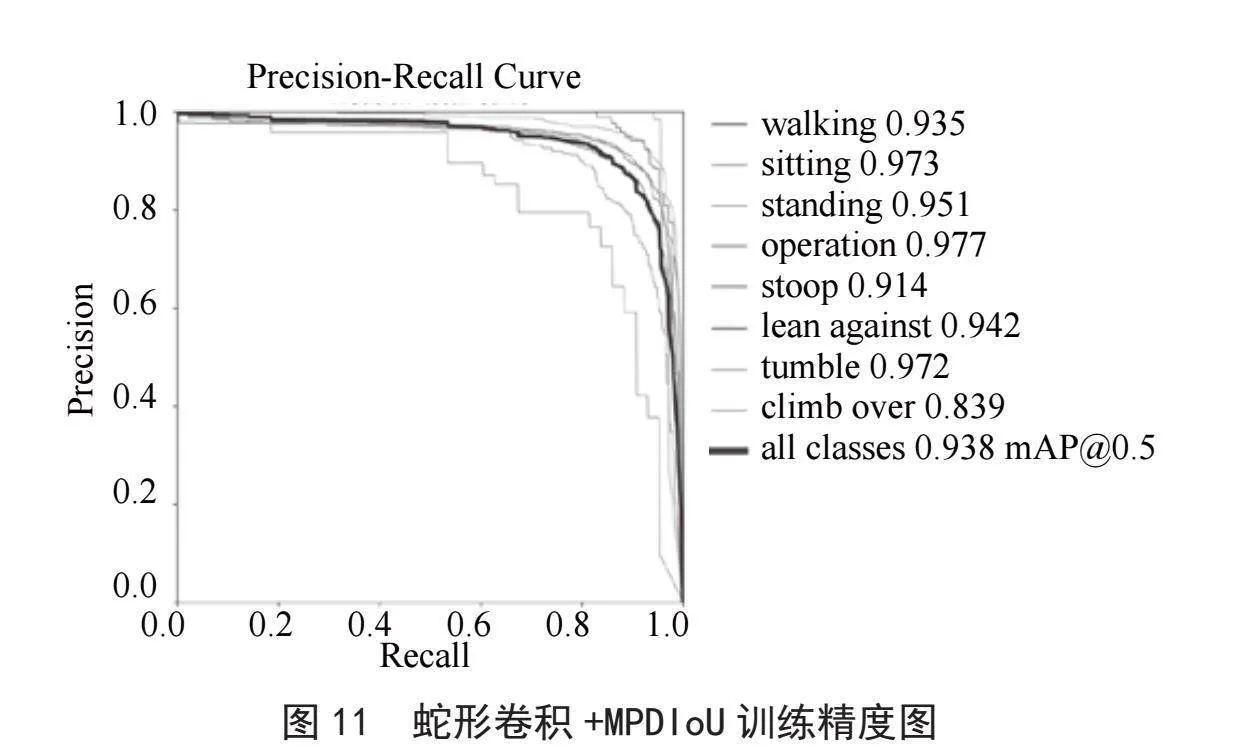
如图11所示,使用蛇形卷积和MPDIoU改进算法后的平均mAP为0.938。
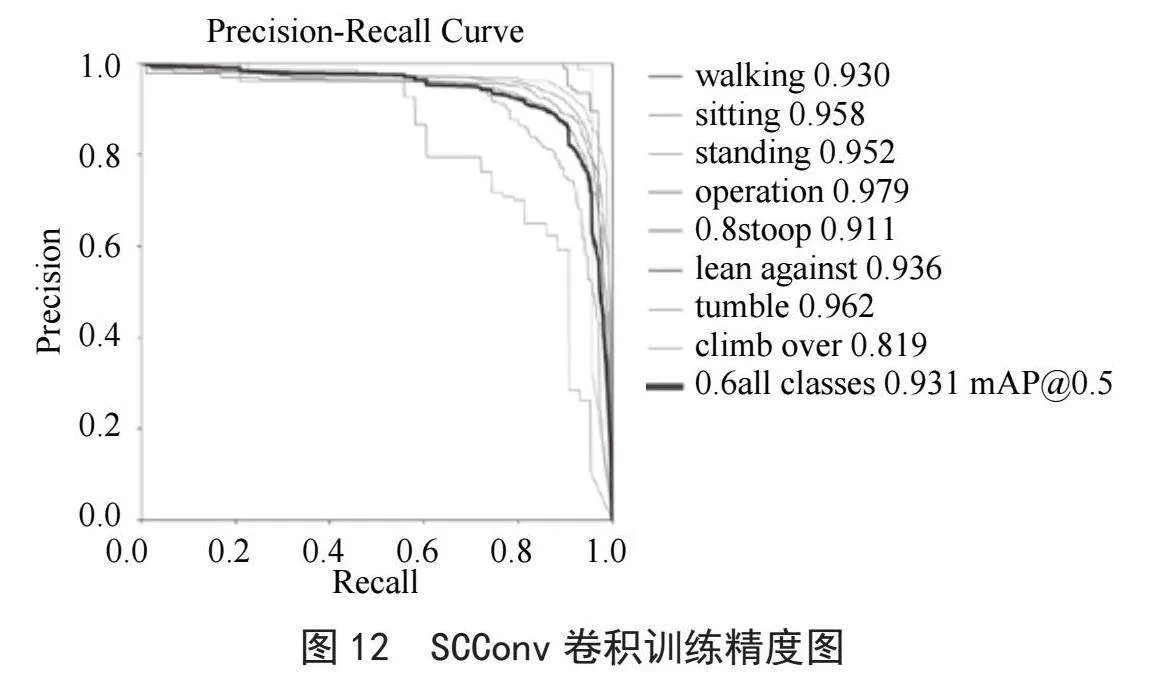
如图12所示,使用SCConv卷积改进算法后的平均mAP为0.931。
通过上图可以看出,改进后的YOLOv8算法在精度上全面领先于原始算法,分别比原始的YOLOv8算法提高了2.3%、2.5%、1.8%,其中在工人的附身姿态检测上,精度分别提高了4.5%、2.8%、2.5%,在攀越姿态检测上,精度分别提高了6.6%、6.6%、4.6%。如图10和图11所示,改进了蛇形卷积后的算法在检测效果上有着明显的改善。而图10所示的由SCConv卷积改进的算法精度上不如前两种改进算法,这是由于SCConv卷积以牺牲了一部分检测精度为代价,从而显著地减少了计算时间。
4" 结" 论
本文从三个方面对传统的YOLOv8算法进行了改进,均达到了提高检测精度的目标。在使用改进蛇形卷积及MPDIoU函数后的改进效果最为明显,这种改进方式在处理小目标、长条状目标和遮挡目标识别上和传统的YOLOv8有着很大的优势。在以后的研究中,应立足于实际场景中的密集物体识别,进一步实现算法的优化。
参考文献:
[1] 李柯泉,陈燕,刘佳晨,等.基于深度学习的目标检测算法综述 [J].计算机工程,2022,48(7):1-12.
[2] 刘彦清.基于YOLO系列的目标检测改进算法 [D].长春:吉林大学,2021.
[3] 邱天衡,王玲,王鹏,等.基于改进YOLOv5的目标检测算法研究 [J].计算机工程与应用,2022,58(13):63-73.
[4] 钟伟.基于稀疏表示的目标跟踪算法 [D].大连:大连理工大学,2013.
[5] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[6] BELL S,ZITNICK C L,BALA K,et al. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:2874-2883.
[7] CHEN L C,PAPANDREOU G,KOKKINOS I,et al. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs [J/OL].arXiv:1412.7062 [cs.CV].[2024-02-12].https://arxiv.org/abs/1412.7062.
[8] LIU W,RABINOVICH A,BERG A C. ParseNet: Looking Wider to See Better [J/OL].arXiv:1506.04579 [cs.CV].[2024-02-16].https://arxiv.org/abs/1506.04579.
[9] ZHANG S F,CHI C,YAO Y Q,et al. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:9756-9765.
[10] LAW H,DENG J. CornerNet: Detecting Objects as Paired Keypoints [J].International Journal of Computer Vision,2019,128:642-656.
[11] LEE C J,YANG M D,TSENG H H,et al. Single-Plant Broccoli Growth Monitoring Using Deep Learning With UAV Imagery [J/OL].Computers and Electronics in Agriculture,2023,207:107739[2024-02-16].https://doi.org/10.1016/j.compag.2023.107739.
[12] CHEN J,CHEN J X,ZHANG D F,et al. Using Deep Transfer Learning for Image-Based Plant Disease Identification [J].Computers and Electronics in Agriculture. 2020,173:105393[2024-02-16].https://doi.org/10.1016/j.compag.2020.105393.
[13] CONG P H,LI S D,ZHOU J C,et al. Research on Instance Segmentation Algorithm of Greenhouse Sweet Pepper Detection Based on Improved Mask RCNN [J/OL].Agronomy,2023,13(1):196[2024-02-20].https://doi.org/10.3390/agronomy13010196.
[14] WOJKE N,BEWLEY A,PAULUS D. Simple Online and Realtime Tracking with a Deep Association Metric [C]//2017 IEEE International Conference on Image Processing (ICIP).Beijing:IEEE,2017:3645-3649.
作者简介:肖富坤(1999—),男,回族,辽宁抚顺人,硕士研究生在读,研究方向:目标识别与图像处理。