摘" 要:针对恐怖袭击事件文本语料库匮乏的问题,文章制定了恐怖袭击事件的实体标注规范,通过对全球恐怖主义数据库(GTD)的数据进行实体标注,构建了恐怖袭击事件的实体语料库。同时,针对数据标注工作的高人力和高时间成本问题,由于百度通用信息抽取(Universal Information Extraction, UIE)模型在极小样本上具有较强的泛化能力,采用UIE模型进行辅助标注。实验结果证明了标注方案的有效性,并在一定程度上减少了标注时间。
关键词:恐怖袭击事件;实体语料库;通用信息抽取;全球恐怖主义数据库;命名实体识别
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)19-0044-05
Construction of Entity Corpus for Terrorist Attack Event
LI Linying, WANG Sunhe, QU Yunping
(School of Software, Dalian University of Foreign Languages, Dalian" 116044, China)
Abstract: In views of the scarcity problem of terrorist attack event text corpus, a standard for entity annotation of terrorist attack event is established in this paper. Through entity annotation of data from the Global Terrorism Database (GTD), an entity corpus for terrorist attack events is constructed. At the same time, for the problems of high human power and high time cost of data annotation work, the Baidu Universal Information Extraction (UIE) model is used for the auxiliary annotation because of its strong generalization ability on small samples. The experimental results demonstrate that the annotation scheme is effective and it reduces the annotation time to some extent.
Keywords: terrorist attack event; entity corpus; universal information extraction; Global Terrorism Database; Named Entity Recognition
0" 引" 言
恐怖主义是全世界的公害,严重影响人民群众的生命和财产安全,影响地区稳定和国家安全,因此反恐成为各国的普遍共识。在反恐的技术打防中,对涉恐文本信息进行挖掘是研究热点任务之一。恐怖主义袭击事件文本中含有大量涉恐实体,如涉恐人物、恐怖袭击目标、恐怖袭击组织等,从中识别出涉恐关键实体,是反恐领域信息抽取、反恐知识图谱构建等任务的重要基础工作。语料库(Corpus)是自然语言处理(NLP)领域所需的大量文本集合,基于深度学习方法的涉恐文本分析需要以标注完成的语料作为模型训练的基础,因此反恐语料库的建设必不可少。
本文构建的恐怖袭击领域语料库收集自国家恐怖主义与反恐研究联盟(The Study of Terrorism and Responses to Terrorism, START)的资料,本文对其中的文本进行了清洗处理。以人工标注出恐怖袭击领域的术语和实体,并由行业专家进行审核,形成了1 500条用于恐怖袭击领域命名实体识别的语料库"资源。
1" 相关工作
语料库作为信息抽取的基础,其质量直接影响实体识别和关系抽取的结果。现有的语料库构建方法分为手动构建和自动构建两种,在公安[1]、军事[2]、医学[3]等领域均已出现公开构建且广泛应用的语料库。叶娅娟等[4]从糖尿病电子病历文本入手,建立了糖尿病电子病历实体及实体关系分类体系,并制定了标注规范。孔芳等[5]基于篇章视角的汉语零指代表示体系,选取汉语树库、Onto Notes语料中重叠的325篇文本进行了汉语零指代的标注,构建了服务于篇章分析的汉语零指代语料库。
曹文斌等[6]以西北政法大学数据库构建了涉恐新闻数据集,并使用正则表达式和CRF++上进行恐怖事件攻击手段、发生时间、地点、伤亡、武器等6类实体属性的识别。黄炜等以西北政法大学数据库为来源的自建数据集上,并通过BERT-BiLSTM-CRF模型对人名、地名、组织机构名进行识别,庄云行等[7]爬取裁判文书网的涉恐类刑事案件,并构建了实体识别数据集。焦凯楠等[8]通过爬取涉恐信息建立了反恐语料库,提出了MacBERT-BiLSTM-CRF模型,证明了该模型在反恐语料库上拥有优秀的性能。
虽然面向通用领域和部分专业领域的语料库已经较为丰富,但由于专用于反恐领域的命名实体识别的研究较少,因此该领域仍然欠缺专门的语料资源,没有可直接应用于此类研究的公开语料库资源。为顺利推进恐怖袭击事件命名实体识别的研究,本文以恐怖袭击领域语料库建设为目标,重点进行了恐怖袭击领域语料库的收集,构建语料标注体系,构建了一个具有一定规模、标注类型丰富的恐怖袭击领域实体语料库,为恐怖袭击领域命名实体识别的研究提供了前期基础。
2" 语料收集与标注流程
2.1" 数据来源
全球恐怖主义数据库(Global Terrorism Database, GTD)(https://www.start.umd.edu/gtd/)是由马里兰大学国家恐怖主义与反恐研究联盟收集和整理的一个开源数据库,其中包含了全世界范围内发生于1970年至2020年间的超过20万件的恐怖袭击事件信息。GTD中的每个事件信息都至少包含了袭击发生的事件和地点、使用的武器、伤亡人数等45个变量信息。
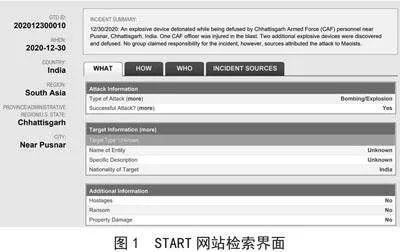
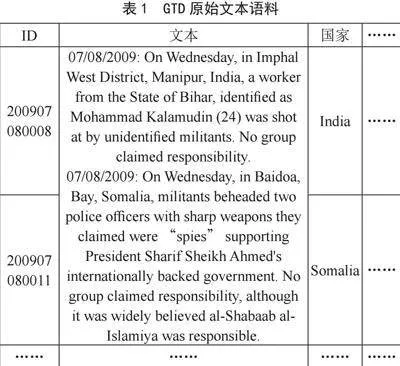
START网站检索画面如图1所示,表1是GTD原始文本语料信息。本文先对数据库数据去除空值以及乱码的操作,再将文本、目标类型、武器类型以及袭击类型4个内容抽出并组合成用于第四章多标签文本分类的数据集,最后对数据集中的文本单独进行标注,并构建恐怖袭击事件语料库。
2.2" 标注流程
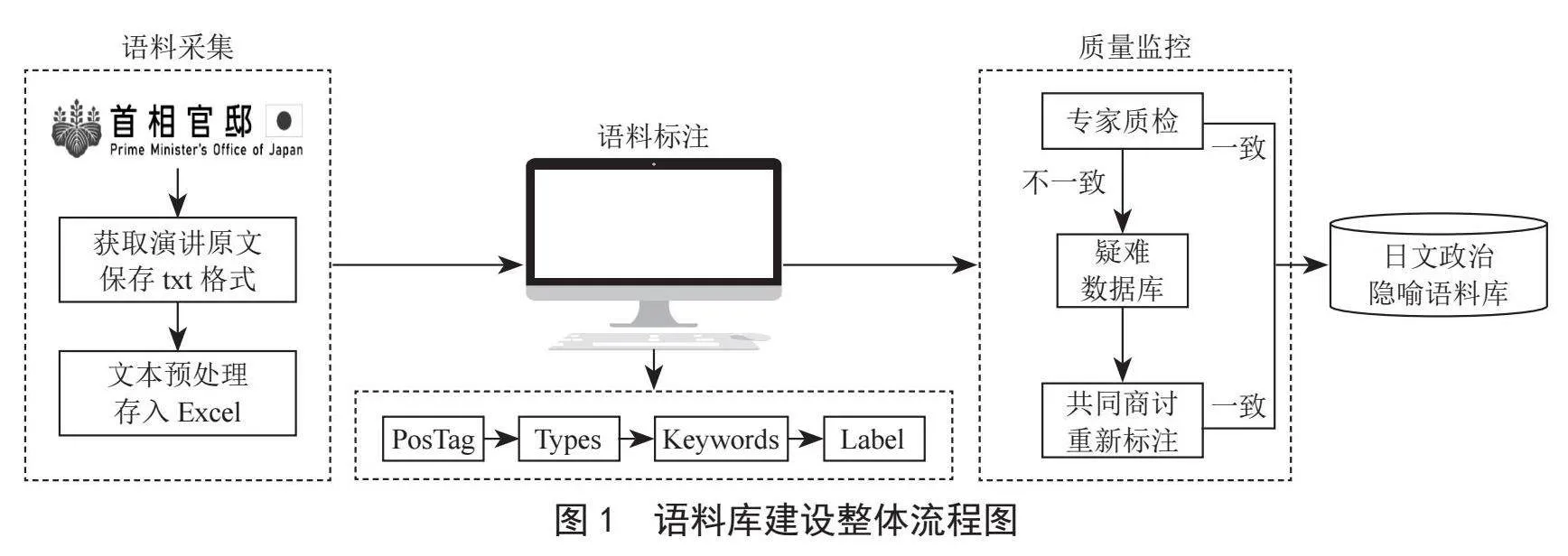
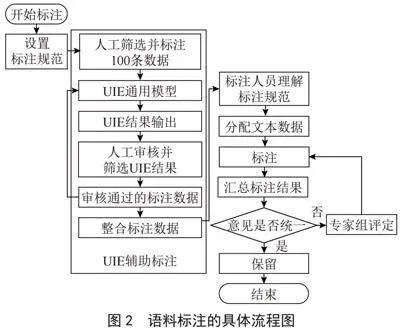
语料标注是一项耗时且需要细致处理的任务,为防止在此过程中出现实体概念漂移、标注错误等问题,有必要在标注前确定标注规范及标注流程,标注规范的详细程度也会影响标注的准确性和标注效率。实体标注作为恐怖事件语料库建设的重要组成部分,标注过程需要充分结合涉恐领域的特点。本文参照标注的5个基本原则:强制性、选择性、准确性、一致性和折衷性。语料标注的具体流程如图2所示。
本文将2万份涉恐文本信息无内容损失地转换为可标注的TXT文件,安装和使用开源标注工具Doccano(https://doccano.github.io/doccano/)对文本中的实体进行人工标注。为确保标注工作的顺利进行,标注过程参考国内外数据标注工作的研究进展。由3名学生组成参与标注小组,另外邀请3名业内专家对标注规范及标注过程中的异议问题提供支持和建议。数据标注规范根据《中华人民共和国反恐怖法》和实际业务需求,以及专家团队的专业知识共同参考制订。
标注规范的制定共分为两个阶段。第一阶段通过UIE模型进行辅助标注,由人工手动标注出100条数据作为微调UIE模型的数据集,再由UIE标注新的数据,在经过初步审查后用于训练第二轮的UIE模型,循环往复直至所有数据形成初步的标注结果。第二阶段是对初步的标注结果进行人工标注和审查,参与标注的人员根据标注规范进行标注检查和校正,将有异议的部分交由专家组评定,最终完成标注工作。
此外为保证标注的准确性,本文在数据标注过程中对标注内容进行定期抽样检查,正确率稳定在95%以上。数据标注工作共持续约6个月,最终构建出语料TerrorismCorpus。其中,文本类型包括攻击类型、袭击目标类型、武器类型。实体类型包括恐怖袭击发生的时间(Time)、恐怖袭击的目标(Target)、该恐怖袭击事件造成的受伤情况(Wounded)、该恐怖袭击事件造成的死亡情况(Killed)、制造该恐怖袭击的组织或人群(Organization)、恐怖袭击发生地点(Location)。
3" 事件实体语料库构建
如前所述,本文对恐怖袭击事件文本的命名实体识别的首要工作是构建一个涉恐领域的语料库。在对GTD文本进行分析后,定义了6个涉恐领域的实体类别,并对这些实体的标注工作制定了标注规范。
3.1" 实体类型定义
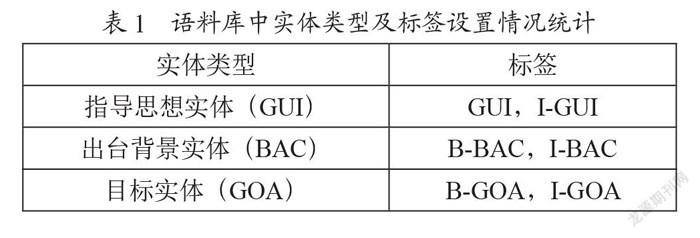
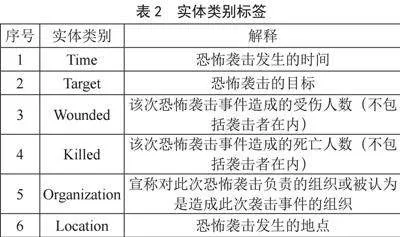
在恐怖袭击事件语料库中,对命名实体识别任务设置以下六个实体标签:恐怖袭击发生的时间(Time)、恐怖袭击的目标(Target)、该恐怖袭击事件造成的受伤情况(Wounded)、该恐怖袭击事件造成的死亡情况(Killed)、制造该恐怖袭击的组织或人群(Organization)和恐怖袭击发生地点(Location)。
时间、组织和地点是统计及概括恐怖袭击事件的主要维度,能简单描述某组织在某一时间、某一地点制造了恐怖袭击事件。受伤及死亡能最直观地反映出该恐怖袭击所造成的伤亡情况,以及该恐怖袭击事件的影响大小。时间、组织、地点、伤亡、目标构成了袭击事件的大部分叙事逻辑,遂采用上述6个实体类别制定恐怖袭击事件的命名实体标签,如表2所示。
3.2" UIE辅助标注
信息抽取包括实体识别、关系抽取、事件抽取、情感分析和评论提取等多个任务。信息抽取的挑战在于需要在不同领域和任务之间进行知识迁移,但通用领域的知识难以应用于特定领域。因此,每个信息抽取任务都需要定制化的模型,这会增加开发成本和对机器资源的需求。最后,训练数据通常很有限,特别是在专业领域,这会增加数据标注的复杂性。
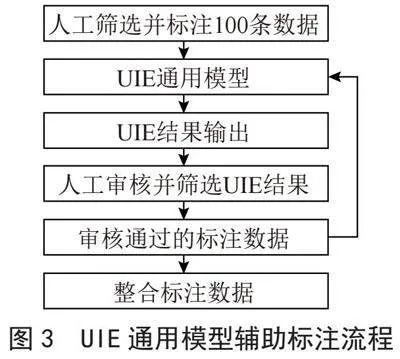
Lu等[9]在ACL-2022中提出了通用信息抽取通用框架UIE,该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。百度飞桨使用ERNIE3.0并基于上述方法,训练并开源了第一个中文的通用信息抽取模型UIE。此模型可以在任意领域中通过小批量数据或零数据在本地部署和优化,其具有极强的小批量数据的微调的能力,快速优化抽取目标。数据集借助UIE通用模型进行标注,具体流程见图3所示。
首先从GTD数据库中随机拉取一部分数据,在这部分数据中筛选出100条,尽可能选择具有全部标签信息的数据进行人工标注。标注完成后作为UIE通用模型的训练集用于微调UIE通用模型,当UIE通用模型训练完成后让其预测未进行标注的GTD数据。由人工筛选并审查UIE的预测结果,选出200条数据,作为第二轮UIE的训练集并进行第二轮训练,循环该步骤。最终合并所有标注过的数据并再次进行人工审查,防止数据或实体概念发生偏移。
3.3" 实体标注规范
多人标注方法有助于缩短标注时间,提高效率,但可能因不同人主观因素导致标注结果的不一致,增加数据集误差。在长时间的数据标注过程中,由于文本格式和内容的变化,可能出现标注数据偏移或实体概念偏移的情况,导致不同批次标注实体的不一致性。
为了应对可能出现的问题,在标注之前,需要初步审查所有待标注的数据,并制定涵盖所有标注条目的规则。对于出现的小概率问题和不确定问题,应记录数据ID,并进行整理,随后集中讨论这些数据的实体标注方案。
因为部分文本长度过短或者含有的标签类目过少,造成语料库标签数量不均衡的问题,在实际的标注过程中删去此类数据。设该条恐怖袭击事件文本中所有标签的数量为n,UIE已完成标注的标签数量为m。
以下为本文数据集的标注规范:
一是在进行UIE标注时,若某条数据中已标注的标签数量不超过2个,则决定放弃对该条数据的标注,以提高标注效率。
二是当已标注的标签数量超过2个时,具体的处理方式取决于文本中的情况:
1)如果文本中存在已被UIE标注或未被标注的目标、死亡或受伤,那么将保留该条数据,以达到平衡各个标签数量的效果。
2)对于已标注数量大于2且文本中还存在未被标注的标签的情况,则继续进行标注。
3)若UIE标注结果达到4个或以上,会保留该数据并检查标注的合理性,若标签数量减少则按照前述规则处理。
另外,在处理文本时,若文本存在乱码或中文,删除这些乱码或中文后对文本进行规整。如果文本中包含多个标签,则记录该条数据的ID,统一整理后再清洗乱码和中文。此外,时间标签只在文本开头以阿拉伯数字组成的月/日/年形式出现,其他时间不再另外标注。死亡及受伤的标签要求最后一个字符应在“were”之前,并应完整包括人名或描述数字的副词如“at least”。
3.4" 数据标注过程
数据标注工作采用开源文本标注工具Doccano来进行,该工具为文本分类、序列标记和序列到序列任务提供标注功能。可以创建用于情感分析、命名实体识别、文本摘要等的标记数据,只需创建一个项目,上传数据便可开始进行标注。对于序列标注的任务,Doccano导入的数据集需要先转换成特定的JSONL格式后再上传。具体格式如下:
{\"text\": \"EU rejects German call to boycott British lamb.\", \"label\": [[0, 2, \"ORG\"]]}
Doccano标注界面可以通过不同颜色区分不同实体,方便标注人员进行标注和检查标注信息。在其后台能实时显示每个实体标签在该数据集中的数量,可以随时查看从而在实体标注过程中调整各个标签的数量,以达到各实体标签数量尽量平衡的目的。
3.5" 人工标注事件实例
人工标注的恐怖袭击事件实例说明如下:
事件句:{\"id\":13762,\"text\":\"08\/18\/2001: Islamic militants launched a failed attack on the Nowhatta police station in downtown Srinagar, Jammu and Kashmir, India. Militants hurled a grenade towards the police station. However, the grenade fell short of the target and exploded on the road without causing any casualties or damage.\",\"Comments\":[],\"label\":[[0,10,\"Time\"],[12,29,\"Organization\"],[58,85,\"Target\"],[98,132,\"Location\"]]}
说明:“id”表示该条数据的序号,“text”是数据文本,“Comments”表示标注人员对该条文本的批注,“label”表示标注出的各个实体标签,每个标签前的两个数字分别代表实体的第一个和最后一个字符在原文中的位置序号。
4" 实验结果及分析
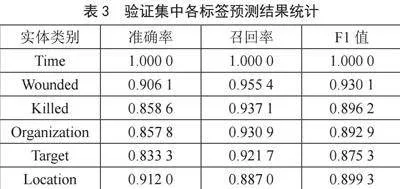
为了分析语料库对模型性能的影响,对本文构建的语料库进行命名实体的统计初步实验,使用序列标注模型BERT-BiLSTM-GlobalPointer并根据实验结果对所构建的语料库进行详细评估。命名实体识别模型所需的训练数据格式为BIO[10],所以语料库中的语料还需要借助Python批量处理成BIO的格式。语料库按照8:2的比例分割成训练集和验证集。整个网络初始的学习率为3×10-3,字向量维度为768,批量的大小为16,Dropout比率为0.5,采用Adam优化算法进行20轮训练。表3为语料库中各类实体的实体识别结果。
通过表3可以看出,时间的识别属于通用领域的命名实体识别任务,识别效果最好,其次是地点、受伤人数的识别,因为这三类实体的实体边界相对确定,而死亡人数、组织机构、攻击目标的识别效果较差,这与标注语料时的情况相似,死亡人数和目标的数量较少,标注时容易漏标,而恐怖组织名称不太容易区分而被误标。
5" 结" 论
针对恐怖袭击事件文本语料库匮乏的问题,制定了恐怖袭击事件的实体标注规范,以全球恐怖主义数据库(GTD)为对象,通过对GTD数据进行实体标注,构建了一个关于恐怖袭击事件的语料库。但是数据标注往往需要耗费大量人力和时间成本,因此利用UIE模型在极小样本上具有的很强的泛化能力,采用UIE模型辅助标注以提高标注效率,再由标注人员根据标注规范修改模型标注结果。实验结果证明了该标注方式的有效性,并在较大程度上减少了标注时间。
参考文献:
[1] 曹若麟,杜渂.面向实体标注的公安警情领域语料库的构建 [J].电信快报,2021(3):20-24.
[2] 杜晓明,袁清波,杨帆,等.军事指控保障领域命名实体识别语料库的构建 [J].计算机科学,2022,49(S1):133-139.
[3] 昝红英,刘涛,牛常勇,等.面向儿科疾病的命名实体及实体关系标注语料库构建及应用 [J].中文信息学报,2020,34(5):19-26.
[4] 叶娅娟,胡斌,张坤丽,等.糖尿病电子病历实体及关系标注语料库构建 [J].中文信息学报,2023,37(12):17-25.
[5] 孔芳,葛海柱,周国栋.篇章视角的汉语零指代语料库构建 [J].软件学报,2021,32(12):3782-3801.
[6] 曹文斌,武卓峰,杨涛,等.基于文本语料的涉恐事件实体属性抽取 [J].工程科学学报,2020,42(4):500-508.
[7] 庄云行,季铎,马尧,等.基于Bi-LSTM的涉恐类案件法律文书的命名实体识别研究 [J].网络安全技术与应用,2023(7):36-39.
[8] 焦凯楠,李欣,叶瀚,等.基于MacBERT-BiLSTM-CRF的反恐领域细粒度实体识别 [J].科学技术与工程,2021,21(29):12638-12648.
[9] LU Y J,LIU Q,DAI D,et al. Unified Structure Generation for Universal Information Extraction [J/OL]. arXiv:2203.12277 [cs.CL].[2024-05-26].https://doi.org/10.48550/arXiv.2203.12277.
[10] REIMERS N,GUREVYCH I. Optimal Hyperparameters for Deep LSTM-Networks for Sequence Labeling Tasks [J/OL].arXiv:1707.06799 [cs.CL].[2024-05-17].https://doi.org/10.48550/arXiv.1707.06799.
作者简介:李林瑛(1975—),男,汉族,辽宁大连人,教授,博士,研究方向:自然语言处理的研究和教学。
基金项目:2022年辽宁省研究生教育教学改革研究项目(LNYJG2022423);辽宁省教育厅高等学校基本科研项目(LJKMZ20221549)