



摘" 要:近年来,计算机视觉快速发展,其中图像分割在计算机视觉中也举足轻重,在城市现代化建设,智能驾驶,地理勘测等方面都得到了充分应用。但是,大多数分割方法只关注图像特征的纵向深层特征与浅层特征的简单融合,而忽略了同一层图像特征的横向远程关系。针对此问题,基于DeepLabV3+框架,加入Swin-Transformer block,利用其自注意力机制特点,进行网络特征提取,以提高图像分割的全局和细节优化。其次,改进DeepLabV3+中上采样方法,利用CARAFE上采样模块取代简单的双线性插值法。实验表明,改进后的模型相较于基线模型MIoU提升2%,ACC提升1%。
关键词:图像分割;深度学习;自注意力机制;上采样方法;卷积神经网络
中图分类号:TP391.4 文献标识码:A" 文章编号:2096-4706(2024)19-0039-05
Research on Improved Image Segmentation Method Based on DeepLabV3 + Model
LI Wupan, LIANG Yuqi
(Key Lab of Opt-Electronic Technology and Intelligent Control of Ministry of Education, Lanzhou Jiaotong University, Lanzhou" 730070, China)
Abstract: In recent years, Computer Vision has developed rapidly, in which image segmentation also plays a decisive role in Computer Vision, and has been fully applied in urban modernization construction, intelligent driving, geographic survey, and so on. However, most segmentation methods only focus on the simple fusion of vertical deep features and shallow features of image features, while ignoring the horizontal remote relationship of image features in the same layer. To address this problem, based on the DeepLabV3 + framework, the Swin-Transformer block is added, and its Self-Attention Mechanism feature is utilized for network feature extraction in order to improve the global and detailed optimization of image segmentation. Secondly, the up-sampling method in DeepLabV3+ is improved, and CARAFE up-sampling module is utilized to replace the simple Bilinear Interpolation method. Experiments show that the improved model increases MIoU by 2% and ACC by 1% compared with the baseline model.
Keywords: image segmentation; Deep Learning; Self-Attention Mechanism; up-sampling method; Convolutional Neural Network
0" 引" 言
在当前社会快速发展的时代,中国经济也实现了快速腾飞,作为基建大国,修建的公路里程越来越长;城乡发展也纳入国家发展战略,城市化速度越来越快,建筑物区域变化越来越快;中国拥有着世界第三的国土面积,地大物博,在全世界土地荒漠化肆虐局势下,中国积极进行植树造林,战胜了沙漠,沙漠面积越来越小;森林作为地球的肺,担负这地球大气的循环工作,对人类的生存而言至关重要;水资源作为地球的血液,是生命之源;耕地,中国作为拥有世界上最多人口国家之一,保证耕地面积,以满足人民对粮食的需求是民生大计。对上述资源的检测是保护资源的第一步,而中国地大物博,对上述资源的监测更加困难,需要投入巨大的人力物力,且效率较低,数据处理结果存在滞后性,难以满足快速监测变化情况,从而作出积极应对的要求。综上所述,如何快速地对地理变化进行监测是当今社会的重中之重。
基于深度学习的图像分割技术发展已久,FCN网络最先将深度学习神经网络应用与图像语义分割领域。再到后来由Ronneberger等人提出的轻量型网络U-Net,多用于医学领域小目标的分割。随后又有诸如PSPNet,Deeplab等网络用于多尺度的图像语义分割。Bai等人又基于U-Net网络提出了CASPP和CASPP+模块,进行多尺度的特征提取[1]。除了基于U-Net网络模型改进的网络外,基于注意力机制的网络模型也在发展,Ding等人提出LANet,提出了分块注意力模块PAM和注意力嵌入模块AEM[2]。Xu提出的HRCNet使用注意力模块得到全局信息,并改进了特征融合技术[3]。Yang提出了可变的空间注意力模块,在提取空间特征中有更好的效果[4]。Mei等人提出了一种基于复合注意力网络的分割算法CoANe,将注意力模块与空洞卷积相结合,在编码器和解码器之间形成一个新的中心区域,以提高图像语义分割的精度[5]。高宇等人改进的多尺度融合特征网络[6]。岳志远等人改进了基于编码-解码器的网络[7]。黄恒青等人提出基于ResNet上多尺度逐层注意力机制特征融合网络图像建筑物语义分割的方法[8]。罗咏潭等人基于多尺度网络的模型,将传统上采样使用的反卷积替换成双线性插值,降低了模型的参数量[9]。刘泽等人提出的Swin Transformer模型,通过可移动窗口实现自注意力机制在不同窗口之间的计算,实现了跨窗口信息交流,增加图像特征的很响联系。受此启发,使用Swin Transformer改进DeepLabV3+的特征提取方法。且在DeepLabV3+网络模型中在深层特征上采样操作中用的是双线性插值法,只是以像素点的空间位置确定上采样核,未用到特征图的语义信息,感知域小。受罗咏潭等人对上采样方法改变的启发,提出加入CARAFE上采样方法。改进后方法在Pascal VOC数据集与遥感数据集上取得了很好的效果,在相同参数设置下,改进后的模型MIoU,ACC分别达到79.34%,94.60%,相较于ResNet结构MIoU提升2%,ACC提升1%。
1" 相关工作
1.1" CNN模型方法
CNN发展已久,U-Net提出一种编码器-解码器结构,在医学领域分隔小目标取得了很大成功。同时,更深的网络提取特征的思想也被提出,诸如VGG,ResNet等网络被相继提出,且都取得了不错的效果。其中ResNet网络中的残差结构作为一种思想已经被应用于计算机视觉中很多具体任务中,其在不断加深网络层次的过程中,能够最大限度地提取特征,从而也被应用于图像分割领域各个下游任务中。在分割模型DeepLabV3+框架中便使用其作为主干网络,且在后续加入编码器-解码器结构,融合不同尺度的深层特征和浅层特征,很好的解决了图像分割的细节和全局信息结合问题,但是缺少同一层次中图像特征的信息关联。
1.2" 注意力机制
2015年首次提出STN,利用空间注意力,通过不断地选择重点区域,从而提高分割精度;2017年通道注意力模型SE-Net提出,由不同的任务决定去抑制或者增强某些通道,实现了性能的提升。在这之后,2018年文献提出CBAM注意力模块能够自适应地将特征进行细化并映射到通道和空间两个模块中,再用两个分支进行特征提取和融合,得到更多的特征[10]。
自注意力机制,2017年首次在自然语言处理领域应用自注意力机制,并将其成功引入计算机视觉领域中,展现出自注意力模型的巨大潜力,随后提出了多头注意力机制(MHSA),通过多尺度融合,提高了模型的泛化能力[11]。继而Swin Transformer模型被提出,其中的SW-MSA模块,在计算多头注意力的基础上计算了各个窗口中信息的关联信息,且通过滑动窗口实现全局信息的自注意力计算,增加了图像同一层次特征横向关联。
本文模型实现了以下改进:
1)提出嵌入Swin Transformer block的ResNet特征提取主干网络。
2)提出嵌入CARAFE上采样方法的DeepLabV3+架构。
2" 模型介绍
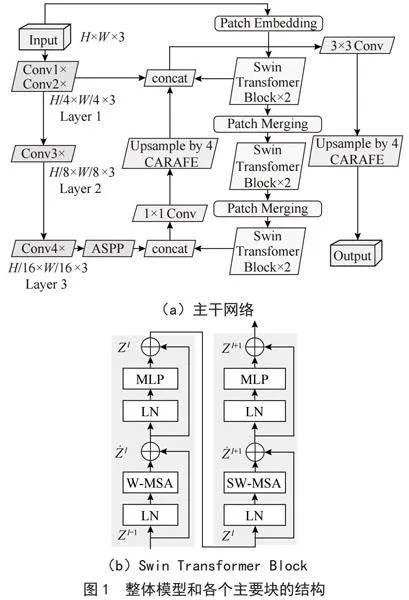
在本章,将具体介绍模型和其中最主要的两个模块:SW-MSA模块和CARAFE上采样方法。这两个模块被作用于模型,进一步提高了分割精度和分割细节。模型结构如图1所示。
2.1" 主干网络
主干网络是结合了Swin Transformer Block的ResNet101,如图1(a)所示,首先利用ResNet101和Swin Transformer Block分别提取深层和浅层图像特征,并分别进行融合,增加横向连系特征,最后再对深层和浅层特征融合,增加全局信息和局部细节特征。
2.2" Swin Transformer Block
Swin Transformer Block主要由一个W-MSA模块和SW-MSA模块组成。SW-MSA模块通过移位窗口实现窗口间信息交互。W-MSA模块,SW-MSA模块与MLP模块前面添加LN 层,并在每个MSA模块之后连接MLP层。该模块实现了不同窗口之间的信息交流,建立同层次图像的特征横向联系。Swin Transformer Block结构如图1(b)所示。
2.3" CARAFE方法
CARAFE上采样方法主要以内核预测模块与特征重组模块组成,给定上采样倍率σ和大小为C×H×W的特征图,CARAFE将生成大小为C×H×σW的特征图。第一步,上采样核预测模块根据每个目标位置的内容预测一个重组内核;第二步,上采样预测模块对Xi的邻居们进行重组,如式(1)所示:
(1)
2.3.1" 内核预测模块
内核预测模块(Kernel Prediction Module)利用内容感知的方式来实现重组内核的生成。X上的每一个原始位置与于X´上的σ2个目标位置相对应。任意的目标位置都必须有一个kup×kup大小的重组内核,其中的kup表示重组内核的大小。该模块最终会输出一个Cup×H×W的重组核,其中Cup=σ2k 2up。而核预测模块则由信道压缩器、内容编码器与内核标准化器三个子模块组成。通道压缩器减少输入特征映射的通道。然后,内容编码器将压缩的特征映射作为输入,并对内容进行编码以生成重组内核。最后,内核规范化对每个重组内核应用一个Softmax函数。下面将详细解释这三个子模块。
1)通道压缩机。采用1×1的卷积层将输入特征图通道从C压缩到Cm。减少输入特征图通道,可以减少后续步骤的参数和计算成本,提高CARAFE的效率。在相同的预算下,也可以为内容编码器使用更大的内核大小。
2)内容编码器。基于输入特征的内容,使用核大小为kencoder的卷积层来生成重组核。编码器的参数为kencoder×kencoder×Cm×Cup。简单来说,通过增加kencoder,便能够扩大编码器的接受域,从而实现在更广的区域内使用上下文的信息,但是,计算复杂度会随着内核大小的平方而增长,更大的内核大小并不会带来太大的提升,kencoder=kup−2是性能和效率之间的良好权衡。
3)内核标准化。在应用于输入特征图之前,每个kup×kup重组核在空间上使用Softmax函数进行归一化,规范化步骤强制内核权重和为1。由于内核归一化,CARAFE没有重新缩放和改变特征图的平均值的操作。
2.3.2" 内容感知重组模块
对于每个重组内核Wl,内容感知重组模块(Content-aware Reassembly Module)将通过函数φ重新组装局部区域内的特征。采用φ的一个简单形式,它只是一个加权和算子。对于目标位置l´和以l=(i,j)为中心的对应方形区域N(Xl,kup),重组后如式(2)所示:
(2)
式中,r=⌊kup/2⌋。
在重组核中,N(Xl,kup)区域内的每个像素对上采样像素l´的贡献是不同的,基于特征的内容而不是位置的距离。经过重组后的特征图语义信息比原始特征图的更强,因为其对局部区域中相关点的信息做到了更多的关注。
3" 实验设计与结果分析
3.1" 数据集
Pascal VOC该数据集由一个世界级的计算机视觉挑战赛提供。PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification)等。在Pascal VOC数据集中主要包含20个目标类别,其中用于语义分割任务的rain和val中的图片一共2 913张。
遥感影像地块分割数据集:该数据集是由中国计算机协会提供的用于比赛的数据集。拥有超14万张遥感图像数据,包括建筑、耕地、林地、水体、道路等6种类别。实验选取13 000张图片作为训练和测试集,以验证实验结果。
3.2" 训练细节于环境
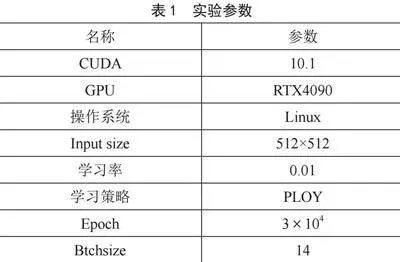
模型在ImageNet数据集的预训练权重基础上,初始学习率设置为0.01学习策略设置为Poly策略,Poly的权重参数设置为0.9。损失函数选择cross_entropy。数据批量大小设施为14。对于数据输入,图像经过裁剪旋转等数据增强后,大小设置为512×512输入网络。具体参数如表1所示。
3.3 评价指标
3.3.1" 平均交并比
IoU表示该类的真实标签和预测值的交和并的比值,计算方式为:
(3)
式中,TP表示正例预测正确的个数;FP表示负例预测错误的个数;TN表示负例预测正确的个数;FN表示正例预测错误的个数,而MIoU(Mean Intersection over Union)就是所有类别平均交并比。
3.3.2" 准确率
准确率(ACC)表示分对的样本数和所有样本数的比值:
(4)
3.4 对比实验
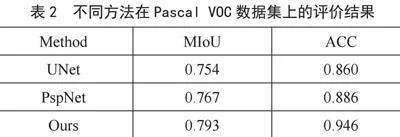
改进后的模型与原始模型分别在Pascal VOC 数据集上进行训练和预测,并在Cityscapes 数据集上进行鲁棒性测试,实验结果表明,改进后的模型在预测准确率较原始模型相较有很大提升,MIoU 提升2%~3%,ACC 提升1%,分别达到79.34%,94.60%。并与UNet、PspNet做对比实验,实验结果如图2、表2所示,改进后的模型相较于其他模型,预测准确率更高,图像边缘更加细节。
3.5" 消融实验
为了检测网络中不同模块对分割效果的影响,定性的比较各个模块的有效性,在遥感数据集上进行消融实验。
使用DeepLabV3+模型的实验结果作为基线,然后通过以下模型进行消融实验:1)为了探索Swin Transformer Block对预测的影响,模型A表示模型使用Swin Transformer Block;2)为了探索所提的CARAFE上采样方法对预测的影响,模型B表示使用CARAFE上采样方法;3)为了探索Swin Transformer Block和CARAFE模块同时对模型的影响,模型C表示同时使用两种方法,实验结果如图3与表3所示。
通过图3可以看出,在加入Swin Transformer Block和 CARAFE模块后的模型在小目标物体的分割效果上有明显提升,在相关评价指标MIoU上提升3%,ACC提升1%,性能超过了基线模型,证明了改进算法的优越性和有效性。
4" 结" 论
提出结合Swin Transformer Block特征融合方法和CARAFE上采样算法的Deeplabv3+模型,用于解决图像分割精度问题,最后通过实验在Pascal VOC数据集和遥感数据集上证明了所提出算法可以提高分割精度并细化分割边界,分割结果更加精确细节。算法的不足在于对于某些细小的物体的边缘细节有错误分割情况。未来的算法会尝试加入边缘检测算法来更加准确的分割小目标物体的边缘,以提升分割精确度,达到更好的效果。
参考文献:
[1] BAI H,CHENG J,HUANG X,et al. HCANet: A Hierarchical Context Aggregation Network for Semantic Segmentation of High-resolution Remote Sensing Images [J].IEEE Geoscience and Remote Sensing Letters,2021(19):1-5.
[2] DING L,TANG H,BRUZZONE L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images [J].IEEE Transactions on Geoscience and Remote Sensing,2020,59(1):426-435.
[3] XU Z,ZHANG W,ZHANG T,et al. HRCNet: High-resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images [J].Remote Sensing,2020,13(1):71.
[4] YANG X,LI S,CHEN Z,et al. An Attention-fused Network for Semantic Segmentation of Very-high Resolution Remote Sensing Imagery [J].ISPRS Journal of Photogrammetry and Remote Sensing,2021(177):238-262.
[5] MEI J,LI R J,GAO W,et al. CoANet: Connectivity Attention Network for Road Extraction From Satellite Imagery [J].IEEE Transactions on Image Processing,2021(30):8540-8552.
[6] 高宇.基于深度学习的遥感图像分割算法研究 [D].郑州:郑州大学,2020.
[7] 岳志远.基于深度卷积网络的遥感图像分割算法研究 [D].南京:南京信息工程大学,2022.
[8] 朱蓉蓉.基于深度学习的遥感影像林地检测算法研究 [D].南京:南京信息工程大学,2021.
[9] 黄恒青.基于深度学习的高分辨率遥感图像建筑物分割方法研究 [D].南宁:广西大学,2020.
[10] 张哲晗.基于编解码卷积神经网络的遥感图像分割研究 [D].合肥:中国科学技术大学,2020.
[11] 张彦.遥感图像中建筑物分割方法研究 [D].天津:河北工业大学,2012.
作者简介:李武攀(1996—),男,汉族,甘肃庆阳人,硕士研究生在读,研究方向:计算机视觉;梁玉琦(1967—),男,汉族,甘肃兰州人,教授级高工,学士,研究方向:交通信息工程及控制。