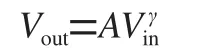






摘" 要:盲人读物稀缺,数字化阅读技术展现出巨大潜力以解决这一难题。基于Tesseract-OCR技术,设计了一款盲文阅读器,其操作简便,部署于树莓派平台。系统先通过摄像头捕捉书籍图像,再执行边缘检测、图像预处理、文字识别以及语音合成等步骤,最终通过蓝牙音箱输出语音,使盲人用户得以通过听觉进行阅读。针对图像像素对识别准确率的影响问题,在图像预处理阶段引入了一种文本图像超分辨率技术。实验结果证明,应用该超分辨率技术显著提升了文本图像的质量并有效提高了Tesseract的文字识别准确性。
关键词:Tesseract文字识别;文本图像超分辨率;语音合成;边缘检测
中图分类号:TP311;TP391.4 文献标识码:A" 文章编号:2096-4706(2024)19-0034-06
Design and Implement of Reading System for the Blind
YU Canchen, QIAN Zewen, ZHANG Yuqing, WU Jiarui
(Nanjing Institute of Technology, Nanjing" 211167, China)
Abstract: Reading materials for the blind are scarce, and digital reading technology shows great potential to solve this problem. Based on Tesseract-OCR technology, a braille reader is designed, which is easy to operate and deployed on Raspberry Pi platform. The system firstly captures book images through a camera, then performs edge detection, image preprocessing, text recognition, speech synthesis and other steps, and finally outputs speech through a bluetooth speaker so that blind users can read by hearing. Aiming at the problem of the influence of image pixels on recognition accuracy, a text image super-resolution technology is introduced in the image preprocessing stage. The experimental results demonstrate that the application of this super-resolution technology significantly improves the quality of text images and effectively improves the text recognition accuracy of Tesseract.
Keywords: Tesseract text recognition; text image super-resolution; speech synthesis; edge detection
0" 引" 言
随着信息技术的迅猛发展,中国在数字化转型的道路上步伐加速。身为全球盲人人口最多的国家之一,中国的盲人阅读问题尤为突出,成为社会关注的焦点。面对盲人群体对于丰富多样和个性化阅读内容的渴望,传统的盲文出版物显然已不能满足其需求。高昂的制作与出版成本,加之每年仅有限的新书出版,导致品种单一且数量稀缺,进一步加剧了视障读者阅读资源的匮乏。在此背景下,数字化阅读技术的发展显现出了其解决盲人阅读难题的巨大潜力[1]。
为了解决这个问题,盲人阅读器作为一种辅助工具应运而生,它旨在通过技术手段将文字信息转化为盲人能够理解和感知的形式。近年来,OCR技术取得了显著的进步,为盲人阅读器的研发提供了强有力的技术支持。其中,Tesseract- OCR技术以其高效、准确的文字识别能力受到了关注[2]。
而在文本图像中,字体、字号的千变万化无疑增加了识别的难度。在采集过程中,光照不足、噪声干扰、拍摄角度的倾斜等因素亦可能给识别工作带来困扰。此外,文本内容本身的繁杂性也是一大障碍。这些因素相互交织,对文字识别的准确性和效率构成了严峻考验。为攻克这些难题,研究者主要从两个方向展开研究[3]:一方面,对输入的文字图像进行预处理,包括二值化、灰度化、去噪以及倾斜校正等操作,以提升图像质量;另一方面,对文字识别系统进行深度优化,利用深度学习技术构建更为复杂的神经网络模型,或调整系统结构,以更好地适应图像中的多样性和复杂性。本系统主要从第一个方面进行研究。
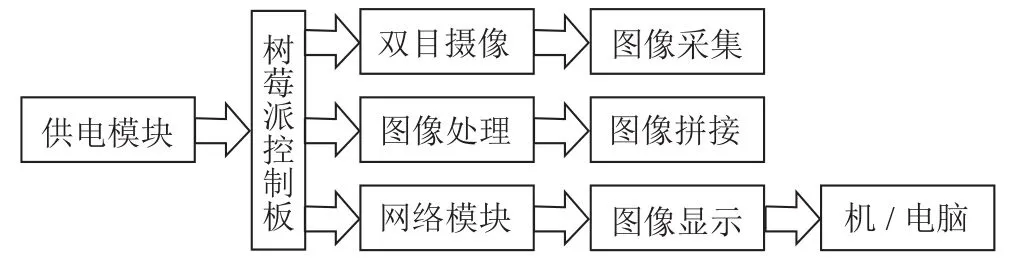
为了实现盲人阅读器的一体化流程,本系统采用了树莓派硬件[4]作为核心控制单元,并搭配蓝牙音箱进行语音播报。通过树莓派硬件的图像采集功能,使系统能实时获取书籍图像;然后,通过图片预处理和Tesseract-OCR技术进行文字识别;最后,将识别结果通过蓝牙音箱以语音的形式播放出来,实现了文字信息的无障碍传递。
整个系统的设计简便易用,适合盲人使用。同时,本研究注重系统的稳定性和可靠性,确保在长时间使用过程中能够保持高效的文字识别能力和稳定的语音播报功能。
此项研究不仅对于拓宽盲文阅读器的应用领域具有重要意义,同时也为视障人士提供了一种新的、便捷的阅读方式,有望极大地丰富他们的文化生活。
1" 系统总体设计
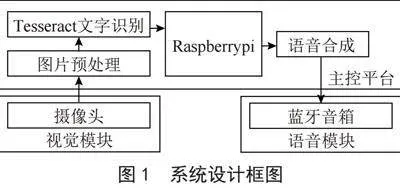
该系统的设计初衷是为视障用户打造一个简单易用的阅读解决方案,设计框图如图1所示。系统的核心环节是图片预处理部分。系统选择便携强大的树莓派作为硬件平台,外接摄像头用于图像数据的捕获。然而,摄像头采集得到的图片往往因为分辨率和其他因素影响而质量不佳,这会直接影响到文字识别的效果和准确性。为此,系统引入了文本图像超分辨率技术以改善图像清晰度,同时进行边缘检测以精确定位书本内容区域。
在图像被处理和优化后,系统通过Pytesseract文字识别分析和转化文本内容。得到的识别文本被传送到语音合成模块,使用Edge-TTS将文字转换为口语化的声音。利用蓝牙技术,将语音信号传输到蓝牙音响设备并播放出来。此一系列操作被高度集成和自动化,确保了视障用户能够通过简单的指令就能使用这一系统,无须复杂设置即可聆听书籍内容,达到了高效、直观的阅读效果。
系统在设计时考虑了用户的易用性和阅读效率,求打造一个完整易用的盲文阅读方案,不仅提高了视障人群的阅读体验,也为其学习和生活增加了便捷。
2" 基于OpenCv的图片预处理研究
2.1" 边缘检测
本系统需要对摄像头采集的图片进行裁剪,从图像中精确提取书本的部分。为达成这一目标,本系统运用Canny算子实施边缘检测[5],这是一种在图像处理领域广受赞誉的算法。它能够有效识别图像中灰度强度变化最显著的位置,进而界定边缘。
随后,利用cv2.findContours()函数,进一步提取图像中的轮廓信息。通过遍历并计算各轮廓的面积,本系统筛选出面积最大且折线数为四的轮廓,假定其为包含目标处理区域的轮廓,并在原始图像上描绘出此最大轮廓及其四条边界线。
在确定最大轮廓后,本系统进一步分析并定位其顶点坐标。通过对四个顶点坐标进行加减运算,能够确定目标区域的精确位置,即其左上角的起始坐标和右下角的终止坐标。通过cv2.getPerspectiveTransform()函数获取透视变换矩阵,并使用cv2.warpPerspective()函数进行透视变换,实现了对目标区域的剪裁与尺寸调整。在剪裁完成后,对图像进行边界的精确裁剪和尺寸的微调,最终返回处理后的图像,如图2所示。
2.2" 文本图像超分辨率处理
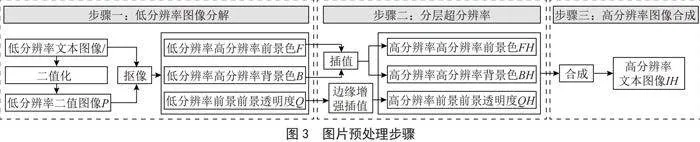
由于Tesseract识别率与图像质量有关,本系统采用一种基于抠像和边缘增强的快速文本图像超分辨率方法[6]提高图像质量,步骤如图3所示。此技术借助引导滤波的抠除工艺,将低分辨率的文本图像分割成前景色、背景色以及前景透明度三个独立的部分。接下来,通过使用快速插值和边缘增强插值技术,对文本的前景色、背景色和前景透明度进行单独的超分辨率处理。最终,通过这些经超分辨率处理的组件,重组出清晰度更高的高分辨率文本图像。
2.2.1" OTSU算法
在图像二值化的处理阶段,本系统选用了OTSU算法。OTSU算法以其在最大化类间方差方面的优越性而广受认可,是统计判别分析中一种知名的度量方式。这一方法的核心理念在于,通过适当的阈值处理,可以明显区分不同类别的像素灰度值,从而找到能最优分离各类别的灰度阈值。OTSU算法的一个显著特点是其完全依赖于图像直方图计算[7],不仅保证了处理效率,也确保了阈值选取的最优化。
OTSU算法基本实现步骤:
1)计算图像归一化直方图pi(i = 0,1,2,…,L-1)。
2)初始化一个阈值t,按此阈值进行初步分割,获得背景与目标。
3)分别计算目标与背景的占比:
(1)
4)分别计算目标与背景的均值:
(2)
5)取类间方差最大时对应的T值,即为OTSU最佳全局阈值t*,若最大值不唯一,则取平均值。
(3)
最终根据阈值t*可得原文本图像I经过二值化后的文本图像P为:
(4)
2.2.2" 引导滤波
在通常的线性旋转变化滤波过程中,某像素点的输出为:
(5)
Wij为权重,在双边滤波中,其权重函数表示为:
(6)
而引导滤波某像素点的输出结果为:
(7)
其中,qi为输出图像,Ii为自引导图像,ak和bk为窗口中心位于k时该线性函数的不变系数。该方法的假设是:qi与Ii在以像素k为中心的窗口中存在局部线性关系。对式(7)求导(即表示边缘)可以看出,只有当引导图像存在边缘时,输出结果才会出现边缘[8]。为了求解式(7)中的系数ak和bk,假设Pi是qi滤波前的结果,并满足qi与Pi的差别最小的要求,根据无约束图像复原的方法,可以将其转化为求最优化问题,其价值函数为(8):
(8)
限制i在窗口ω中,这样ak值就不会出现太大的情况了(在本方法中窗口半径r = 2,ε = 0.13)。类似于最下二乘法求解,式(8)的解为:
," " (9)
其中,μk和分别为Ii在局部窗口ω中的均值和方差。ω为窗口内的像素个数。然后,在整幅图像内采取窗口操作,最后取均值可以得到式(7)的结果为:
(10)
其中:
,
由此得到文本图像的前景透明度Q,并根据前景透明度Q与文本图像I计算前景图像If = Iq和背景图像Ib = I(1-q)。
2.2.3" 膨胀与腐蚀
得到文本图像的前景图像If和背景图像Ib后,本系统采用膨胀与腐蚀[9]操作估计文本图像的前景色F和背景色V。采用3×3内核H与前景图像If进行腐蚀操作得到前景色F,与背景图像Ib进行膨胀操作得到背景色B。
2.2.4" 双三次插值
本系统采用双三次插值法对2.2.3节得到的前景色F与背景色B分别进行超分辨率得到高分辨率的前景色FH与背景色BH。
双三次插值法与双线性插值法相同,也是通过映射,在映射点的邻域内通过加权来得到放大图像中的像素值。不同的是,双三次插值法需要待插值点近邻的16个点来加权[10]。
首先构造一个Bicubic()函数,它是用来根据近邻点与待插值点的相对位置来计算该点前的权值的一个函数:
(11)
这里a取-0.5。得到权值后,只需要将这16个点的像素值加权起来即可,插值计算的公式如下:
(12)
2.2.5" 边缘增强插值
本系统采用边缘增强插值方法对前景透明度Q进行超分辨率得到高分辨前景透明度QH。
定义一个边缘增强插值函数Enhance(I) = I-I*O,其中I为待增强图像,*为卷积运算,O为式(13)所示的卷积核:
(13)
具体步骤如下:
1)对前景透明度Q先进行双三次线性插值后进行边缘增强插值得:
(14)
2)对前景透明度Q先进行边缘增强插值后进行双三次线性插值得:
(15)
3)将QH1与QH2以一种线性关性结合得到高分辨前景透明度QH:
(16)
其中λ取值为[0,1],本系统采用λ = 0.5,Bicubic()为双三次插值。
2.2.6" 合成高分辨率文本图像
本系统将上述小节得到的前景色FH、背景色BH和前景透明度QH按式(17)进行线性组合可得:
(17)
其中(x,y)为像素坐标,IH为最终合成的高分辨率文本图像,如图4所示。
3" 基于Pytesseract的文字识别
本系统采取使用Pytesseract来进行文本识别。Pytesseract是一个基于Python的开源OCR(光学字符识别)工具,它利用了Google的Tesseract-OCR引擎来执行文字的检测和识别任务[11]。在OCR的处理过程中,主要经过以下几个阶段:图像的预处理、文本的定位、字符的分割、字符的识别,以及最后的后处理工作。
值得注意的是,基于系统对于识别结果准确性的追求,研究发现Pytesseract默认的图像预处理方案未能完全达到研究的预期效果。因此,本研究根据第2.2节提出的方法对图像进行了分辨率的提升,从而有效地增强了文字识别的准确率。
为了在程序中利用Pytesseract库进行文字识别,首先需要通过import pytesseract语句将其引入。随后,利用pytesseract.image_to_string()函数即可执行对图像中文字的识别操作。示例如下:
pytesseract.image_to_string(imgWarped_Gray,lang=eng+chi_sim)
在此代码片段中,imgWarped_Gray代表经过预处理并转换成二值化图像的变量,而lang参数则用于指定识别过程中所使用的语言,本示例中设置为同时支持英文和简体中文。
4" 基于Edge-TTS的语音合成
本系统采用Edge-TTS进行语音合成,其主要任务是将第3节中识别出的文本内容转化为语音,并通过蓝牙音箱播放出来[12]。Edge-TTS是一个基于Python的库,它使得系统能够直接从Python代码中调用Microsoft Edge的在线文本到语音(TTS)服务。这一服务背后的支持是微软的Azure Cognitive Services,它提供了文本到语音转换的能力。Edge-TTS提供了一个简洁的API接口,允许用户将文本内容转换成语音输出,同时支持多种不同的语言和声音选项,其输出的语音品质更加贴近真实人类的发音。相关代码如下:
tts=edge_tts.Communicate(text=TEXT,voice=voice,rate=rate,volume=volume)
参数说明:
text [参数] 指明要保存的MP3的文本。
voice [参数]指明了使用哪种语音和风格的发音人,例如zh-CN-YunjianOnlineNatural。系统中可以通过edge-tts --list-voices 查看更多的语音和风格。
rate [参数] 调整语速,例如-50%,慢速了50%。
volume [参数] 调整音量 例如+10%,声音提高了10%。
5" 实验与结果分析
5.1" 数据集及实验环境
本研究采用了两个不同来源的数据集以验证所提出方法的性能。
在基于综合性数据集的Pytesseract与OCR API文字识别性能对比实验中,主要使用了一个包含约360万张中文图像的综合性数据集。该数据集涵盖了中文新闻和文学语料生成的图像,通过模拟真实场景中的多样性,对图像进行了字体、字号、灰度等级、模糊度、透视变化以及拉伸等多种变换。为了训练与验证模型,将数据集按照99:1的比例划分为训练集和验证集。每张图像均包含10个字符,这些字符是从语料库中的句子随机截取的,并统一调整至280×32像素的分辨率。该实验数据集的样例图像如图5所示。
在图像预处理对Pytesseract文字识别性能影响的实验探究中,使用的数据集则是通过本系统配置的1080P摄像头在实际环境中拍摄的100张具有不同程度模糊的文本图片。这些图像同样被统一调整至280×32像素的分辨率,并涵盖了顺光、逆光、背光等多种光线条件下的采集场景。实验二数据集的样例图像如图6所示。
5.2" 实验过程
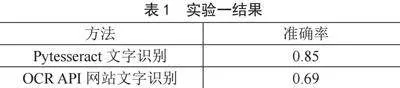
在基于综合性数据集的Pytesseract与OCR API文字识别性能对比实验中,实验随机抽取了测试集中的1 000张图片,并分别使用Pytesseract和OCR API网站进行文字识别。实验结果如表1所示。
从表1中可以看出,Pytesseract在该实验中展现了较高的文字识别准确率,达到了0.85。相比之下,OCR API网站的识别准确率略低,为0.69。这一结果表明,Pytesseract更适合作为本系统的文字识别工具,能够有效地从图像中提取出文本信息。
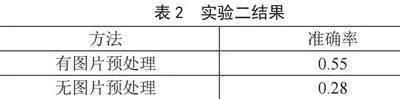
在图像预处理对Pytesseract文字识别性能影响的实验探究中,研究对比了有图片预处理和无图片预处理情况下Pytesseract的文字识别准确率。实验结果如表2所示。
从表2中可以看出,经过图片预处理后,Pytesseract的文字识别准确率从0.28提升至0.55,有了显著的提高。这一结果证明了图像预处理对于提升该系统文字识别性能的重要性。通过对图像进行超分辨率处理,可以有效地改善图像质量,从而提高文字识别的准确性。
5.3" 实验总结
综合两个实验的结果,得出以下结论:
1)Pytesseract在中文图像文字识别任务中表现出色,具有较高的识别准确率,适合作为本系统的文字识别工具。
2)本系统采用的图像预处理操作对于提升文字识别性能具有显著影响,通过改善图像质量可以有效提高识别准确率,有效克服了由系统所用摄像头质量或环境光线变化引致的图像质量下降,从而确保了文字识别的准确性不受这些因素的不利影响。
6" 结" 论
本文设计并开发了一款专为盲人设计的阅读器,该阅读器采用基于Tesseract-OCR的文字识别技术,并结合了文本图像超分辨率算法进行图片预处理,显著提升了Pytesseract的文字识别精度。该系统操作流程简化,使得盲人用户通过简单地按压按钮即可完成图像采集、文字识别到语音播报的整个过程,极大地促进了其阅读信息的便捷性和准确性。
参考文献:
[1] 王海歌,付正兴.数字化时代我国盲人阅读服务研究 [J].传媒,2022(10):79-81.
[2] 张华萍,黄辰.文字识别技术研究 [J].物联网技术,2018,8(8):17-19.
[3] 郭仲.基于改进的二值化算法与Tesseract-OCR引擎文本图像识别 [D].杭州:浙江理工大学,2023.
[4] 蔡玉树,卢仕,毛林聪,等.基于改进YOLOv5的盲人阅读辅助系统 [J].计算机时代,2023(10):94-99.
[5] 陈利利,李斌,梁晓晴.基于Canny边缘检测的红枣识别算法研究 [J].信息技术与信息化,2024(3):25-28.
[6] 李树涛,康旭东,孙斌,等.一种基于抠像和边缘增强的快速文本图像超分辨率方法:CN102842119A [P].2012-12-26.
[7] 李浩然,田秀霞,卢官宇,等.基于OSTU的光照不均匀图像自适应增强算法 [J].计算机仿真,2022,39(2):315-321+386.
[8] 张万绪,史剑雄,陈晓璇,等.基于稀疏表示与引导滤波的图像超分辨率重建 [J].计算机工程,2018,44(9):212-217.
[9] 高薪,胡月,杜威,等.腐蚀膨胀算法对灰度图像去噪的应用 [J].北京印刷学院学报,2014,22(4):63-65.
[10] 张文翔,董宏林.基于OTSU的图像插值算法 [J].计算机与数字工程,2022,50(1):186-189.
[11] 郭室驿.基于OpenCV和Tesseract-OCR的英文字符算法研究 [J].电脑编程技巧与维护,2019(6):45-49.
[12] 洪涛龙.基于Android平台的图像文字识别及语音播放系统 [D].南京:南京邮电大学,2017.
作者简介:余璨辰(2003—),女,汉族,江苏徐州人,本科在读,研究方向:人工智能;钱泽文(2004—),男,汉族,江苏徐州人,本科在读,研究方向:人工智能;张宇晴(2003—),女,汉族,江苏南通人,本科在读,研究方向:电子信息;吴佳瑞(2003—),女,汉族,江苏泰州人,本科在读,研究方向:人工智能。
基金项目:江苏省大学生创新创业训练计划项目(202311276101Y)