
摘" 要:随着汽车行业向智能化和网联化转型,智能座舱体验已成为中高端车型的核心竞争力。传统的推送功能研发方法受限于人工配置的随意性,导致触发成功率低、触达精准性差等问题,为了解决这些问题,提出了一种基于车联网数据的智能座舱场景推送模型。该模型通过深入分析功能数据特征,运用监督学习技术训练多个算法,采用半监督学习方法克服数据标签不足的挑战,利用终端数据埋点技术,对模型进行精细优化,以提高推送的准确性和效率。实验结果表明,与传统方法相比,该模型在触发成功率和触达精准性上取得了显著提升。这一成果不仅为智能座舱技术的发展提供了有力支持,也为用户带来了更加个性化、高品质的座舱体验。
关键词:数据挖掘;车联网;车载智能座舱;单一决策树;梯度提升决策树;随机森林;半监督学习;数据埋点
中图分类号:TP391" " 文献标识码:A" 文章编号:2096-4706(2024)18-0162-05
Research on Improving the Trigger Success Rate of Automobile Cockpit Push Products Based on Data Mining
RONG Da1, ZHANG Lian2, CHEN Xiyuan3
(1.Faculty of Big Data and Computing, Guangdong Baiyun University, Guangzhou" 510450, China;
2.Internet of Things Technology Application Teaching and Research Office, Guangdong Polytechnic of Science and Trade, Guangzhou" 510651, China; 3.Runsheng Software Development (Guangdong) Co., Ltd., Guangzhou" 511457, China)
Abstract: With the transformation of the automotive industry to intelligence and networking, the intelligent cockpit experience has become the core competitiveness of middle and high-end models. The traditional push function development method is limited by the randomness of manual configuration, resulting in low trigger success rate and poor touch accuracy. In order to solve these problems, an intelligent cockpit scene push model based on Internet of Vehicles data is proposed. Through in-depth analysis of the characteristics of functional data, the model uses Supervised Learning technology to train multiple algorithms, uses Semi-Supervised Learning method to overcome the challenge of insufficient data labels, and uses terminal data event tracking technology to finely optimize the model to improve the accuracy and efficiency of push. The experimental results show that compared with the traditional method, the model has achieved significant improvement in trigger success rate and touch accuracy. This achievement not only provides strong support for the development of intelligent cockpit technology but also brings more personalized and high-quality cockpit experience to users.
Keywords: data mining; Internet of Vehicles; vehicle intelligent cockpit; single Decision Tree; gradient boosting Decision Tree; Random Forest; Semi-Supervised Learning; data event tracking
0" 引" 言
智能汽车产业快速发展推动了对车联网技术和智能座舱的高需求。为满足这些需求,国内车企提出了基于场景、交互和服务三元结构的座舱智能化服务产品方案,包括一种低代码开发工具,以加快研发并降低成本。然而,仅靠开发工具并不能确保产品体验,因产品体验还取决于场景触发的准确性和及时性。
以车内温度提醒为例:假设需实现一个需求“车内自动感知温度,当车内温度高于舒适温度5 ℃[1-3](有研究结论:夏季,人感舒适温度均值是24 ℃),则提示是否需要降温至舒适温度”。在此需求中,车内温度高于舒适温度“5 ℃”这个数值是按人为经验设定的,是没有科学依据的,且对于不同的地域、性别、年龄、车型空间情况,该值应是不同的。总而言之:人为设定的阈值缺乏科学依据,导致触发率和体验效果受限。当前,优化智能座舱产品触发成功率和用户体验的主要方法依赖个人经验,而利用大数据和数据挖掘技术进行科学配置的研究尚处于空白状态。
针对上述问题,本文提出了一种针对车载智能座舱功能产品的模型构建方法。首先,提取了具有高业务相关性的场景信号值作为特征,并进行了预处理。接着,利用产品冷启动阶段的数据作为训练集,通过单一决策树[4]、随机森林[5]和梯度提升决策树[6]等算法进行模型训练,并选择最佳算法。针对初期数据标签稀缺或质量不高的问题,采用了半监督学习[7-10]方法,并结合终端数据埋点技术实现自动标签标记,以优化模型训练。最后,将模型应用于功能配置,提高了触发成功率和用户体验。研究表明,该系统具有创新性和实用性,能够提升车载智能座舱[11]场景推送类产品的开发质量和应用效果。
1" 系统整体方案设计
对于汽车智能座舱场景推送类产品,具备监听特点,即产品结构类似“当X场景发生,则触发Y交互/服务”,图1给出了该类产品的结构特征。
汽车智能座舱类产品具有以下特征:
1)触发信号通常是线性的,例如车速或车内温度。
2)产品体验因用户和情境差异而异。
3)设计者难以仅凭直觉设定最佳触发信号。
4)需要专家提供多组信号设置以适应不同环境。
本模型实现步骤包括:
1)处理线性场景信号。
2)收集数据作为训练集。
3)使用监督学习选择最优模型。
4)应用最优模型优化产品场景信号。
5)利用埋点和半监督学习算法迭代优化模型。
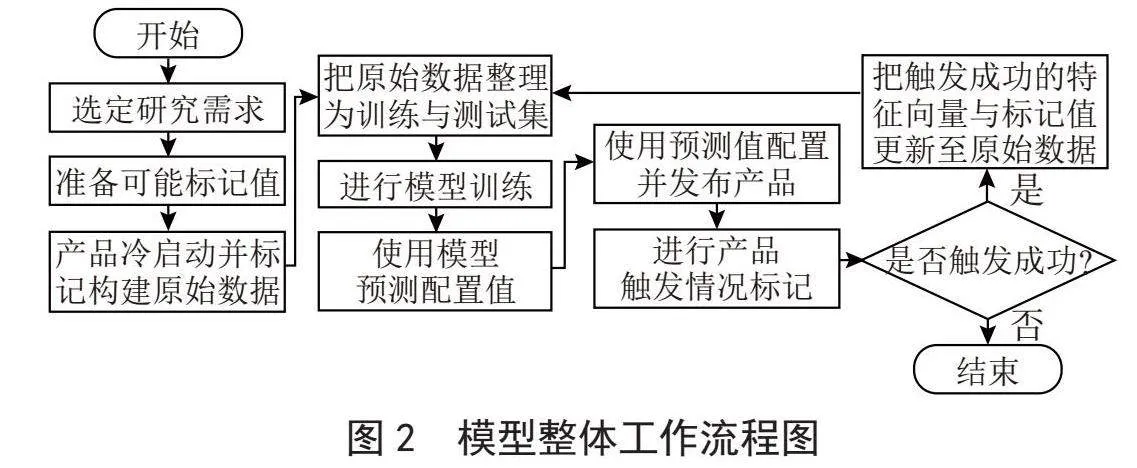
综上所述,以下为本模型的整体工作流程图如图2所示。
2" 模型系统的详细设计
2.1" 选定研究需求及分析
在考虑车载智能座舱的高频需求和痛点后,我们选择了以下需求来实现产品冷启动:“感知车内温度,若超出舒适范围0~5 ℃,提示驾驶者是否需自动调节至舒适温度(针对高温情况)”。
本文研究核心原因在于汽车座舱舒适温度的重要性和个性化调节需求。智能控制座舱温度可提高舒适度、个性化服务、节能减排和驾驶安全性。
使用本文提出的模型对所选定研究需求的适用性分析:
1)模型适用于线性型触发信号的产品,如车速和车内温度。
2)模型考虑了不同人群和环境下的体验差异。
3)模型帮助解决设计运营者难以准确设定触发信号数值的难题。
4)模型支持根据不同环境设定多套信号数值,适应性强。
2.2" 预准备可能标记值
行业研究表明,夏季车载座舱最舒适温度为24 ℃,能耗最低。温度在27.5~37 ℃时,乘客易感到热。因此,车内温度与24 ℃的差值可作为产品功能触发值。考虑不同场景,温差标记方法为10个摄氏度内均匀取值,每隔0.5 ℃取一值,区间从3.5 ℃到13 ℃,共得到20个训练标记值。当实际温度与舒适温度差值等于某设定值时,触发相应人机交互服务。
2.3" 产品冷启动并标记构成训练集
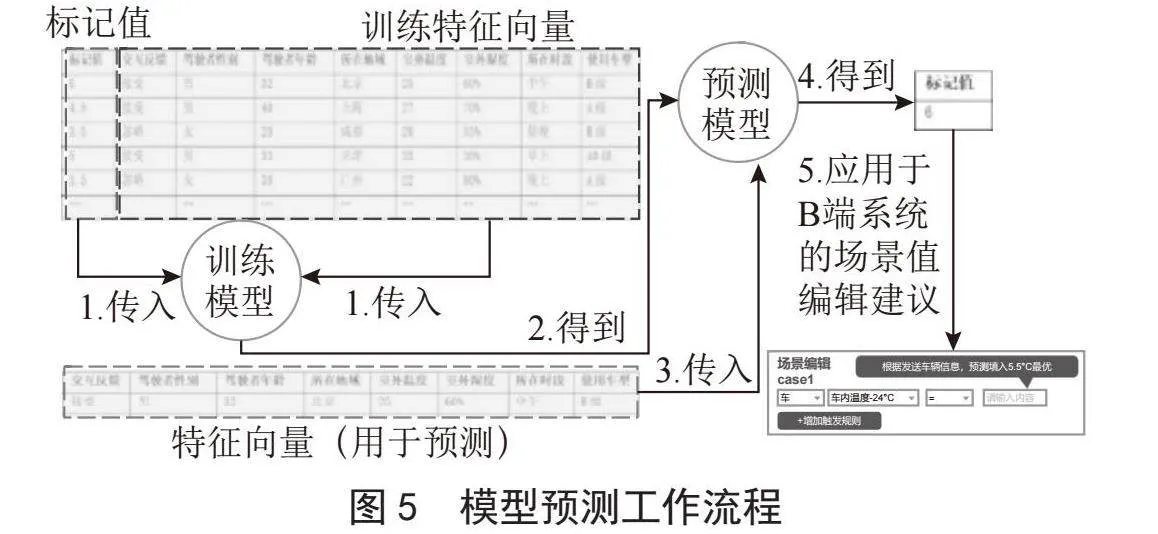
在产品的冷启动阶段,需要将预定义的标记值,按照一定规则分配到不同特征场景下的产品中。通过监测产品在这些场景下的触发行为,可以建立特征向量与标记值之间的映射关系。这样的数据收集过程是为了构建监督学习算法的训练集,以便进一步训练模型以预测未来的触发情况。
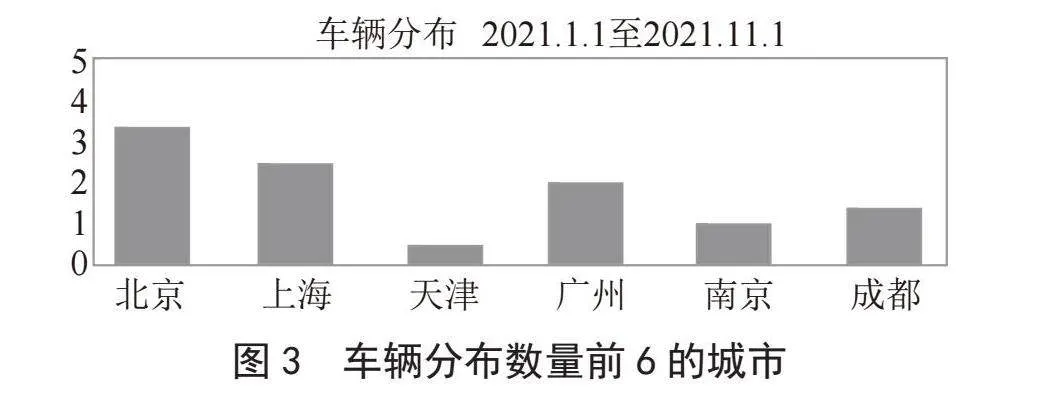
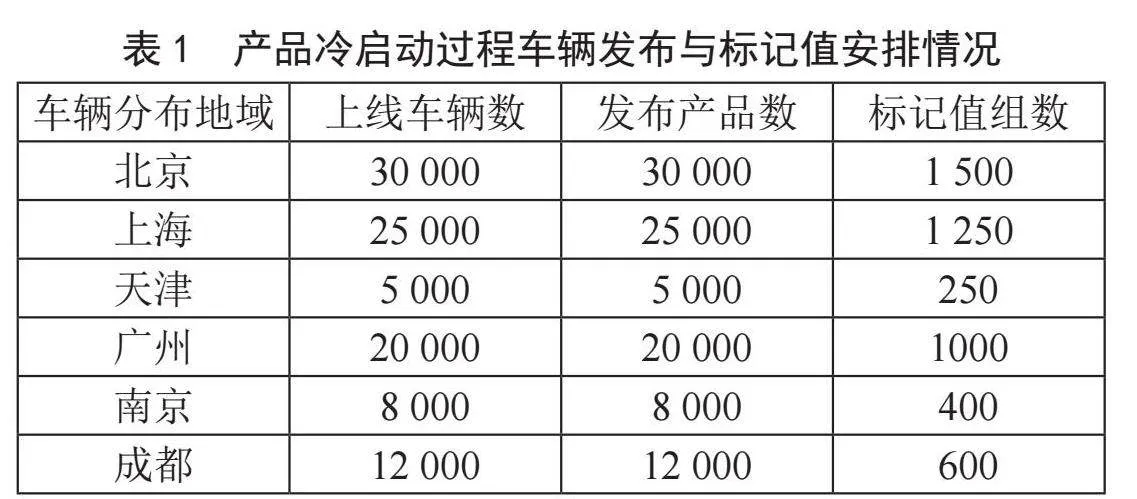
为实现产品冷启动运行,首先需选定搭载产品的六个车流量大的城市,假设这些城市具有相似的环境与场景。在这六个城市中随机选取100 000辆车,每车分配一个预置的可能标记值,并在车内启动产品。产品运行期间,监控触发条件,一旦产品触发且司机接受服务,就将场景特征与标记值关联并记录。若司机拒绝服务,标记值将递增0.5 ℃(上限为13 ℃),然后继续监听,直至触发成功。图3为基于云平台导出的车辆分布数量前6位的城市。
表1为各个实行产品冷启动运行的城市的上线车辆数、发布产品数、标记值组数情况。
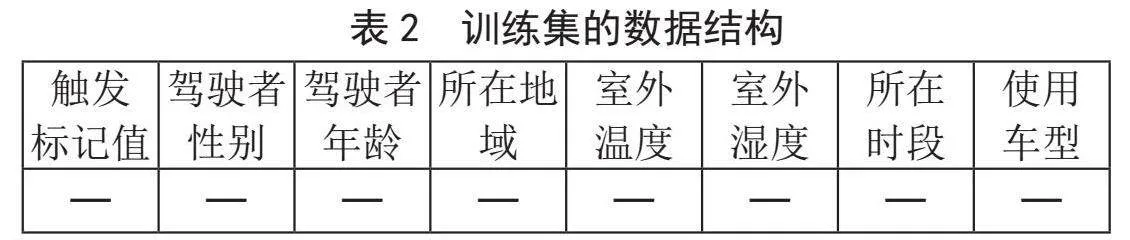
按照产品冷启动过程中特征向量与标记值关联方法进行发布,运行一段时间后,对触发情况进行数据收集,形成监督学习算法模型训练集,该训练集的数据结构如表2所示。
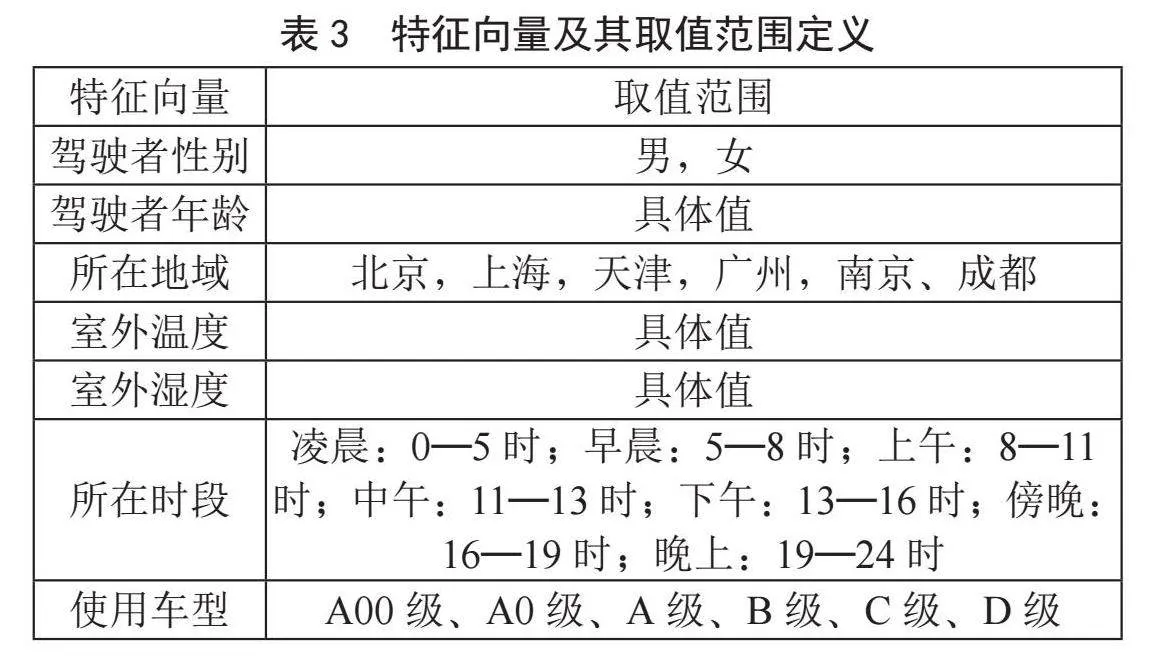
训练集中的特征向量及其取值范围需要在构建训练集时完成定义。表3为所有特征向量内容及其取值范围定义情况。
2.4" 进行模型训练
模型训练是本系统的核心。系统通过埋点收集用户反馈,构建特征向量与标记值的映射关系作为训练集。鉴于训练集的可信度可能有限,初期将使用监督学习算法进行训练。产品上线后,将采用半监督学习算法持续优化模型,以提高预测准确性,弥补初始标记值不精确带来的影响。
监督学习是利用既有数据集训练模型,以预测未知样本。本研究通过向测试车辆批量发送带有标记值的产品,记录触发数据,生成标记与特征向量的训练集,输入多个训练模型,最终得到预测模型。
本文采用了集成学习策略,结合了单一决策树、随机森林和梯度提升决策树三种经典模型。通过这种集成方式,综合各模型的预测性能,以提高决策的准确性。
在训练算法模型阶段,首先对产品冷启动收集的数据进行特征向量和标记值的划分,并存储以供后续使用。随后,根据80/20法则,将数据集划分为训练集(80%)和验证集(20%)。之后,从训练集中提取特征值,并将其与相应的标记值一起输入模型中进行拟合。最后,运用选定的算法对模型进行训练,并用测试集的特征向量对模型进行预测,分析不同模型的预测性能。
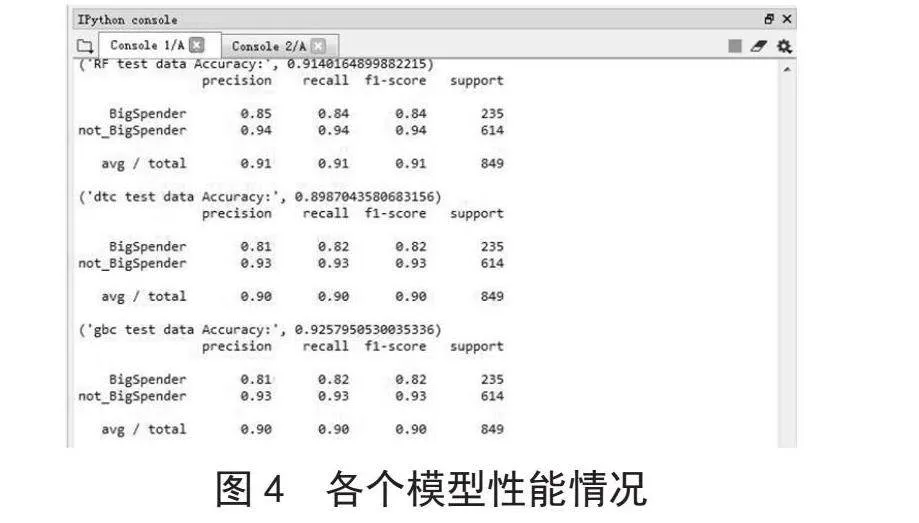
经过各个模型的性能计算,得到各模型的性能情况如图4所示。
在评估不同模型性能后,随机森林和梯度提升决策树展现出较优的性能,其中梯度提升决策树不仅准确度更高,而且稳定性更强。基于这些发现,本文选择梯度提升决策树模型作为分析工具。
2.5" 进行模型预测与实际配置应用
得到预测模型后,部署模型于车云平台,收集车辆数据作为特征向量,输入模型以预测座舱场景推送产品的信号配置值。整体工作过程如图5所示。
2.6" 模型预测性能调优
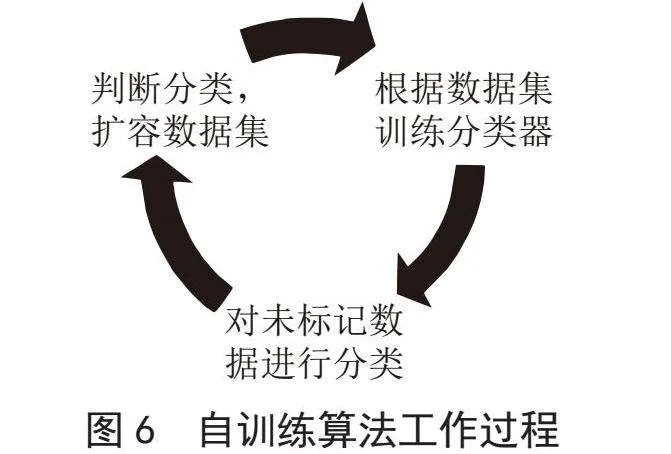
由于产品冷启动导致训练数据稀缺且特征标记质量不佳,系统采用半监督学习的自训练算法持续优化模型性能。具体过程为:首先用带标签数据训练分类器,然后利用该分类器预测未标记的数据,筛选出可信度高的数据及其预测标签,纳入训练集,再训练新分类器。图6展示了自训练算法的流程。
半监督学习是一种结合监督学习和无监督学习的方法,旨在利用大量无标记数据和有限的标记数据提高模型性能。在工业实践中,直接标记数据往往会影响用户体验,因此获取大量标记样本代价高昂。半监督学习通过引入大量无标记数据,可以显著减少对标记数据的依赖,有效解决标记数据稀缺的问题,提高分类器的泛化能力。
在半监督学习领域中,自训练算法(Self-training)因其简便性和无须额外假设而备受推崇,特别适合于本文模型的需求。Self-training算法通过迭代过程,使用初始分类器对无标记数据进行预测,选取置信度高的样本作为伪标签,不断扩充训练集,以提升模型性能。以下为Self-training的算法流程:
算法1自我训练:
1)初始化。
2)给定(Xtrain,ytrain)=(Xj,yi)。
3)循环直至满足停止条件。
4)使用已标记数据(Xtrain,ytrain)训练分类器Cint。
5)用Cint预测Xu的类标签yu。
6)选择置信样本
(Xconf,Yconf);(Xconf,Yconf)∈(Xu,yu)。
7)移除选定的未标记数据Xu←Xu-Xconf。
8)组合新标记数据
(Xtrain,ytrain)←(Xj,yi)U(Xconf,Yconf)。
9)结束循环。
自训练算法(Self-training)的演算过程如下:
1)将初始带有标记的数据集作为前期的训练集,即:(Xtrain,ytrain)=(Xj,yi)
经过训练后得到一个分类器,即:Cint。
2)利用初始训练得到的分类器,使用无标记数据集Xu进行分类,并选取出最有把握度的样本(Xconf,Yconf)。
3)在Xu中,将(Xconf,Yconf)去掉.
4)将(Xconf,Yconf)添加到带有标记的数据集中,即:
(Xtrain,ytrain)←(Xj,yi)U(Xconf,Yconf)。
5)使用新的训练集训练输出新的分类器,并重复步骤2~5,直到满足停止条件(如所有没有标记的样本数据都已被标记完成)
6)得到最终调优完成的分类器。
模型实际应用效果分析
本研究致力于利用数据挖掘技术优化车联网智能座舱场景推送产品的触发效率,进而改善用户体验。研究起因于国内一家知名汽车研究院的技术创新项目需求,并在项目完成后成功集成至新型车辆中实现大规模生产应用。研究成果在实践中显示出显著的应用价值,体现在以下几个关键方面:
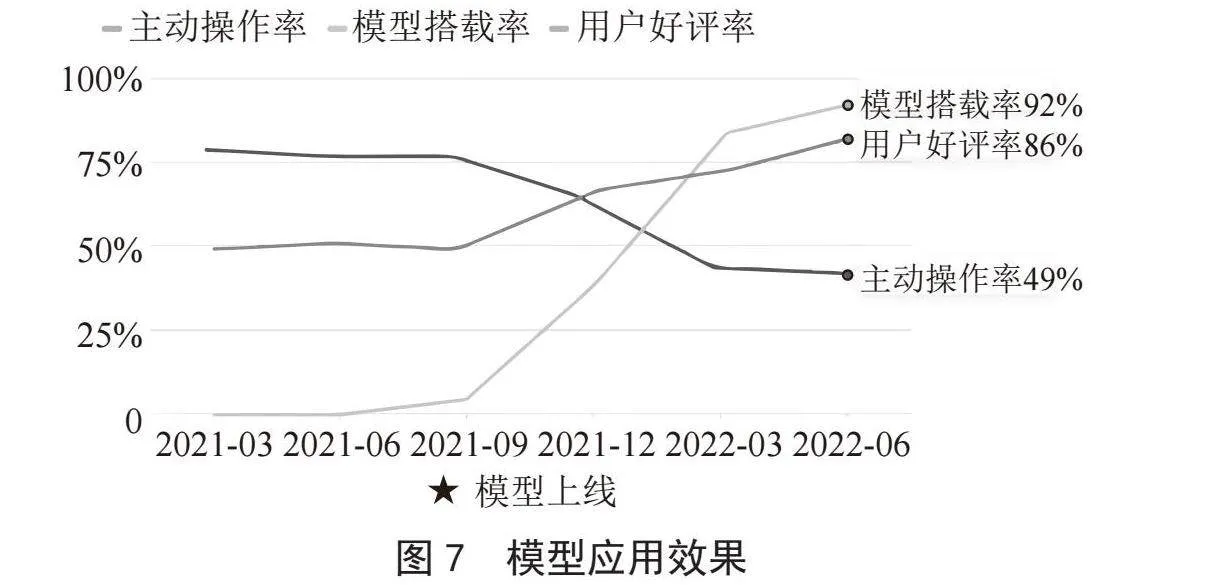
首先,驾驶者对车端系统的主动干预次数减少,服务推送的响应率显著提升。以自动空调功能为例,通过对比模型上线前后半年的数据,我们观察到,在100 000辆车辆中,手动调整空调的频率下降了约30%。这一结果验证了模型的有效性,并表明它能有效提高产品的触发成功率。
其次,搭载了该模型的量产车型的功能搭载率显著提高。在汽车研究院的工作流程中,OEM厂商需为搭载智能网联功能的车辆支付费用。通过分析模型上线后的车辆支付情况,我们可以推断出模型在量产车辆中的应用率。数据显示,在2021至2022年度上市的车型中,搭载率达到了92%,这一数据从另一个角度证明了模型在OEM厂商和市场用户中的高认可度及良好的应用效果。
最后,用户对功能的评价整体积极,普遍认为产品智能且便捷。产品发布后的一年时间里,通过持续收集用户反馈,并据此优化产品功能,我们发现86%用户给予了正面评价。模型上线前后的整体应用效果变化趋势图如图7所示。
综上所述,本研究成果不仅在理论上具有创新意义,而且在实际应用中展现出了良好的效果。
3" 结" 论
本文旨在解决国内车企在车联网智能座舱场景推送产品开发中遇到的触发成功率低和用户体验不佳问题。通过数据挖掘方法,提出了一种提升触发成功率的模型,并详述了其构建和应用流程。首先,通过筛选和分析,确定了“车内适宜温度推送”作为研究案例,并验证了该需求适合模型训练。然后,通过产品冷启动收集带标签的样本数据,为模型训练提供了充足的数据。接着,采用多个监督学习算法进行训练,选取最优算法以提升预测准确性。将模型应用于产品配置,并通过半监督学习进行持续优化,以适应长周期的车辆使用和系统升级。虽然模型已实现一定效果,但仍需改进,特别是在处理特征向量准确度问题上,如驾驶者性别数据的准确获取。未来将结合更多特征数据,如人脸识别和驾驶者登录信息,进一步优化模型,以更好地服务于驾驶者并提升用户体验。
参考文献:
[1] 王国华,桑国辉,张英朝,等.汽车乘员舱热舒适性影响因素多参数优化分析 [J].汽车工程,2023,45(11):2023-2033+2057.
[2] 陈芬,刘何清,朱凯颖,等.以有效温度为基础的人体舒适度评价模型的发展概述 [J].采矿技术,2019,19(5):106-111.
[3] 章明超,邹佳庆,周健,等.汽车驾驶员热感觉预测及其影响因素分析 [J].建筑热能通风空调,2022,41(8):37-41.
[4] PALUSZEK M,THOMAS S. Data Classification with Decision Trees [J].MATLAB Machine Learning Recipes,2019:147-169.
[5] NIU Q N,SHI W,XU Y T,et al. High-Accuracy NLOS Identification Based on Random Forest and High-Precision Positioning on 60 GHz Millimeter Wave [J].China Communications,2023,20(12):96-110.
[6] ISRAELI A,ROKACH L,SHABTAI A. Constraint Learning Based Gradient Boosting Trees [J].Expert Systems with Applications,2019,128:287-300
[7] 李永国,徐彩银,汤璇,等.半监督学习方法研究综述 [J].世界科技研究与发展,2023,45(1):26-40.
[8] 何玉林,陈佳琪,黄启航,等.自训练新类探测半监督学习算法 [J].计算机科学与探索,2023,17(9):2184-2197.
[9] TETTEY N O,YANG G W,WU J Z,et al. Semi-Supervised Learning for Fine-Grained Classification With Self-Training [J].IEEE Access,2020,8:2109-2121.
[10] 蔡萌亚,王文丽.汽车智能座舱交互设计研究综述 [J].包装工程,2023,44(6):430-440.
作者简介:容达(1990—),男,汉族,广东广州人,大数据专业教师,车联网自主研发企业主管工程师,中级工程师,硕士研究生,研究方向:研究车联网智能网联技术、车载智能座舱、AI智能推送。