

摘 要:为提高地质灾害预警的准确性和效率,提出了一种基于K-means聚类和长短期记忆网络(LSTM)的地质灾害监测设备故障排查模型。通过对地质监测数据的聚类分析,该模型能有效区分正常和异常运行状态的设备,为后续的深度学习分析提供了精准的数据基础。LSTM时序分析部分利用聚类结果,深入挖掘时间序列数据中的潜在模式和趋势,实现对设备故障类型及其发展趋势的准确预测。实验验证表明,该组合模型在地质灾害监测领域具有良好的应用潜力,能够为灾害预防和减灾提供有力的技术支持。未来研究将集中于进一步提升模型的准确性和泛化能力,探索更多算法组合和数据处理方法,以适应更加复杂的监测环境,推进监测系统的自动化和智能化。
关键词:K-means聚类算法;长短期记忆网络(LSTM);地质灾害监测;设备故障排查;时间序列分析;自动化监测;智能化监测
中图分类号:TP277;TP311 文献标识码:A 文章编号:2096-4706(2024)20-0061-07
Design of Fault Diagnosis Model for Geological Disaster Monitoring Equipment Based on K-means-LSTM Combination Algorithm
WANG Yajie1,2,3, ZHANG Chengmei1,2,3, YANG Xin2,3, QIN Meiyuan2,3
(1.Guizhou Academy of Testing and Analysis, Guiyang 550000, China;
2.Guizhou Guike Big Data Co., Ltd., Guiyang 550008, China; 3.Guizhou Academy of Sciences, Guiyang 550001, China)
Abstract: To improve the accuracy and efficiency of geological hazard early warning, this paper proposes a geological disaster monitoring equipment fault diagnosis model based on K-means clustering and LSTM. Through cluster analysis of geological monitoring data, the model can effectively distinguish equipment in normal and abnormal operating conditions, providing an accurate data basis for subsequent Deep Learning analysis. The LSTM Time Series Analysis part uses clustering results to deeply explore potential patterns and trends in time series data to achieve accurate predictions of equipment fault types and their development trends. Experimental verification shows that the combined model has good application potential in the field of geological disaster monitoring and can provide strong technical support for disaster prevention and reduction. Future research will focus on further improving the accuracy and generalization ability of the model, exploring more algorithm combinations and data processing methods to adapt to more complex monitoring environments, and promoting the automation and intelligence of the monitoring system.
Keywords: K-means clustering algorithm; LSTM; geological disaster monitoring; equipment fault diagnosis; Time Series Analysis; automated monitoring; intelligent monitoring
0 引 言
地质灾害作为自然灾害的重要组成部分,对人类社会和经济发展造成了严重影响[1]。特别是在我国西南地区,由于地形地貌复杂、雨源性水系发育等因素的影响,地质灾害频发,给人民生命财产安全和社会经济发展带来了巨大挑战。贵州省作为地质灾害较为严重的地区之一[2],地质灾害的防治工作显得尤为重要。
贵州省地质地理条件特殊,位于我国西南地区,地形地貌复杂、雨源性水系发育。加之水利工程、城市建设、矿山开采等促进经济发展的工程项目日趋增多,在自然和人为因素的双重影响下,地质灾害频繁发生,给当地民众生命财产安全和社会经济带来了巨大的压力。贵州省以矿业资源开发为主,因此矿山地质灾害成为主要的灾害类型,包括滑坡、崩塌、泥石流等,给当地民众带来了巨大的损失和威胁。在《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》[3]以及国务院《“十四五”国家应急体系规划》[4]的指导下,贵州省对地质灾害的防治工作高度重视。在完善国家应急管理体系、增强公共设施抵御风暴、干旱和地质灾害能力的框架下,贵州省提出了深入贯彻《国务院关于加强地质灾害防治工作的决定》[5],进一步完善调查评价、监测预警、综合治理、应急防治四大体系,充分依靠科技进步和管理创新,加强统筹协调,提高防治效率,全面提升基层地质灾害防治能力的重要任务,最大限度地避免和减少地质灾害造成的人员伤亡和财产损失。
然而,随着监测设备的普及和使用,监测设备异常故障成为地质灾害防治工作中的一个重要问题。据相关数据显示,贵州省地灾设备超过2.8万台,如果采用传统的人工排查方法,每日全覆盖排查至少需要135人。这种方式存在着工作量大、精确度低、标准不统一等问题,无法满足实际需求,因此迫切需要一种高效精准的故障排查模型来提升地质灾害监测系统的准确性和可靠性。为了解决这一问题,本研究提出了一种基于K-means-LSTM组合算法的故障排查模型。该模型通过聚类分析K-means[6]和长短期记忆网络(LSTM)[7]相结合,能够自动识别和排查监测设备异常数据,从而提高了排查效率和准确性。通过将聚类分析和长短期记忆网络相结合,该模型能够自动识别和排查监测设备异常数据,显著提升了排查效率和准确性。该研究旨在为贵州省地质灾害监测系统构建一种可靠的故障排查模型,以减少人工排查成本、提高排查效率、并精准定位故障设备,从而增强地质灾害监测系统的可靠性和可持续性。经过对贵州省地质灾害监测系统的实际应用验证,证实了该模型的可行性和有效性,为地质灾害防治工作提供了重要的技术支持和决策参考。
1 模型概述与设计
地质灾害监测设备的排查方式是地质灾害防治工作中的重要环节[8]。目前,针对地质灾害监测设备的排查方式主要包括人工排查[9]和基于算法的自动排查[10]两种方式。人工排查是传统的方式,通常由专业人员通过视觉和经验判断监测设备的运行情况,然后逐一检查和排查异常设备。这种方式的优点是直观、灵活,但存在工作量大、精确度低、标准不统一等问题。随着技术的发展,基于算法的自动排查方式逐渐受到关注。这种方式利用聚类分析、机器学习等技术,对监测数据进行分析和处理,自动识别和排查异常设备,从而提高排查效率和准确性。虽然自动排查方式需要依赖一定的算法和技术支持,但在提高排查效率和准确性方面具有明显的优势。
贵州省目前拥有超过2.8万台地质灾害专业监测设备,这些设备主要用于监测气温、沉降、振动、斜角、测距、深部位移、缝位移等参数。这些设备被部署在全省各地,通过地质灾害防控指挥平台进行数据采样监测,将时序数据传输至数据仓库的时序数据库中进行存储,并进行预警分析。然而,目前部分设备存在一些问题,如供电不足、采样误差等,导致监测数据质量不可靠,预警模型长期出现不实预警情况。为解决这些问题,需要对历史数据进行质量分析,提取异常数据设备清单,并推送给设备厂家进行升级维护,以确保系统平台预警模型分析的可靠性,为宏观指挥决策提供依据。因此,本研究提出了一种基于K-means-LSTM组合算法的故障排查模型,旨在提高监测设备故障排查的效率和精度。
在地质灾害监测设备的故障排查工作中,本研究设计并提出了一种融合了K-means聚类和长短期记忆网络(LSTM)的混合型分析模型。针对现场传感器(如:三维地表位移传感器、倾角传感器、加速度计和地震波速度传感器等)捕获的多维监测数据,如三维空间的位移(x、y、z方向)、倾斜角度、加速度以及振动频率等,我们面临的挑战是如何从这些维度繁杂而信息量庞大的数据中提炼出有用的知识。这些数据的维度之高使得直接分析带来了计算上的不便和结果解释上的困难。为了解决这个问题,我们在K-means聚类分析之前,首先采取了降维策略。降维是指在尽可能少地丢失信息的前提下,将高维度数据映射到低维度空间的过程。在众多的降维技术中,主成分分析(PCA)是一种经典且广泛应用的方法。PCA通过线性变换将原始数据转换到一个新的坐标系统中,使得转换后的第一坐标轴上的数据方差最大(即信息量最丰富),第二坐标轴次之,以此类推,这就意味着我们可以选择前几个包含最主要信息的主成分,以简化后续处理流程。通过主成分分析(PCA)降维后[11],我们得以在保留监测数据核心特性的同时,显著降低数据的复杂度。这不仅加快了计算速度,还改善了数据处理的可操作性,为聚类分析奠定了基础。而在K-means聚类之后,利用LSTM网络深入分析每个聚类或降维后的时间序列数据,可以准确地学习并预测设备的运行趋势和潜在故障,进一步提高故障预测的准确性和实时性。
1.1 地质灾害数据K-means聚类预处理
在完成了对地质灾害监测数据主成分分析降维之后,我们采用K-means算法对处理过的数据进行进一步聚类分析,以便有效地从简化的数据集中识别出潜在的异常模式。我们采用该算法对地质监测数据进行初始分类,基于特征相似性将数据划分为不同的群组。这一过程的理论基础在于,通过识别监测数据中的自然分组,可以更准确地反映设备的运行状况。我们假设数据具有固定数量的潜在群集,并且每个群集中的数据点在特征空间中彼此接近,这有助于识别正常和异常运行状态的设备。通过这种聚类方法,将数据点根据其特征的相似度分组,将设备的运行状态分类为多个群体,每个群体代表着不同的运行特性,如正常运行、维护需要、以及可能的故障等。聚类过程中辨识出的异常群组,如那些具有不寻常高的采样值、不正常低的采样频率、数据时间戳的异常或数据突然重置的情况,均提示监测设备可能存在特定问题。特别是对于监测数据稳定性的分析,我们特别关注那些表现出异常波动或偏离预期模式的设备,这通常是故障预警的信号。这些聚类结果为随后的LSTM模型提供了关键的训练标签,确保时序分析的针对性和准确性,显著提升了故障排查的效率和系统的预警能力。通过此策略,K-means聚类不仅提升了数据分析的可解释性,也为地质灾害监测系统在动态、复杂环境中的可靠运行提供了坚实的数据支撑。
1.2 LSTM模型构建
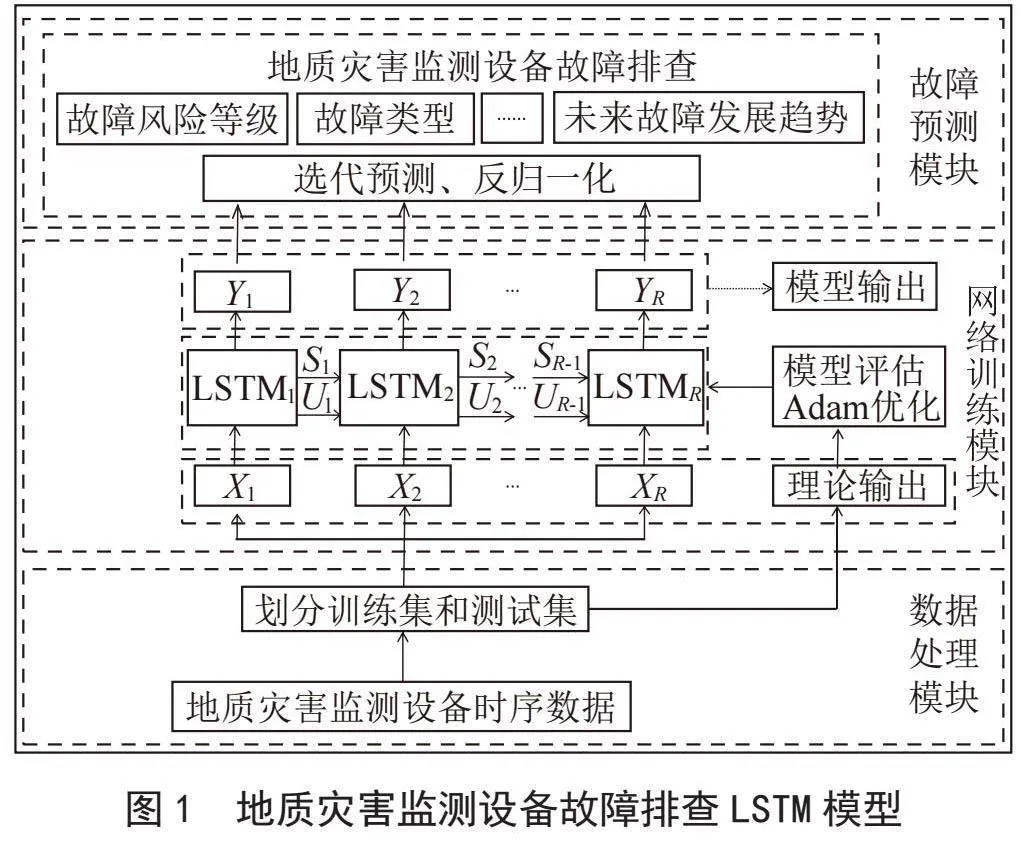
在通过K-means算法有效地识别了运行状态异常的设备之后,本研究接着对这些异常数据进行了更为精细化的分析,旨在揭示潜在的故障类型及其严重性。此阶段,长短期记忆网络(LSTM)的时序分析模型扮演了核心角色,它的高效处理能力对于理解和预测设备故障状态至关重要。LSTM模型以其在处理长序列数据中显示出的卓越性能而被广泛应用于时间序列分析任务中,特别是在需要捕捉长期依赖关系时。我们利用LSTM网络进行深度时间序列分析,以预测设备的故障发展趋势。LSTM网络是一种特殊的递归神经网络,能够处理和预测长序列数据中的时间依赖性,这对于捕捉设备故障状态的动态变化尤为关键。我们的假设是,设备的监测数据中存在时间相关的模式,这些模式可以通过LSTM网络的长短期记忆能力被有效学习和识别。在我们的案例中,已经从常态数据中分离出的异常设备数据集成了LSTM模型的训练基础。在此基础上,LSTM模型被精心训练,以辨识和学习异常数据中隐含的复杂模式和趋势,其训练目标是将这些模式映射到预定义的故障类别。本研究的关键贡献之一是开发出一个能够自动从海量监测数据中提取出关键异常特征,并对其进行准确分类的智能系统。通过LSTM模型的深入分析,我们不仅仅是在进行简单的异常检测,更是在推进向自动故障诊断和健康管理系统的重要一步。这一系统的成功实施,将极大提高地质灾害监测网络的响应速度和预警精准度,为地质灾害防控领域带来创新的技术方法和理念。本文所设计的地质灾害监测设备故障排查LSTM模型如图1所示。
2 实验与分析
2.1 地质灾害数据K-means聚类
我们详细记录了利用K-means聚类算法对降维后的地质灾害监测数据进行分析的结果。数据来源于地质灾害监测设备,涵盖了位移、倾角、加速度等多维度信息。数据在使用主成分分析(PCA)进行降维之后,我们选用K-means算法对其进行分类,主要基于算法的高效性和在处理大数据集时的可伸缩性。聚类分析的过程中,我们首先确定了聚类数目K的值,这一值的选择基于多次迭代实验和内部评估指标,如肘部法则图的拐点,以确保最终聚类能够有效地代表数据的潜在结构。在确定了聚类数目之后,算法通过迭代优化聚类中心,直至收敛到稳定的聚类结果。在本研究中,确定K-means聚类算法中的最佳聚类数(k值)是一个关键步骤,我们采取了多种方法来估计最佳的k值。其中包括肘部法则(Elbow Method),它是通过计算不同k值的聚类成本函数(如平均距离或方差)并寻找“肘部”点,即成本函数开始急剧下降的点。此外,我们也考虑了轮廓系数(Silhouette Coefficient)等其他内部评估指标,这些指标可以帮助评估聚类的密集和分离程度,从而确定一个合适的k值。
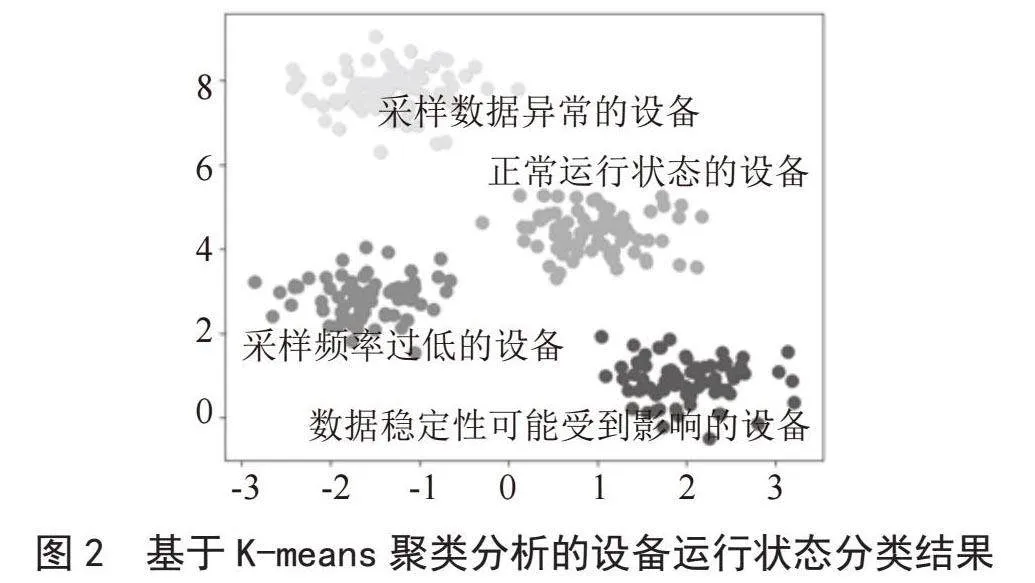
在多次实验和评估后,k值设为4被证明能够有效地区分出不同的设备运行状态,并在实验中显示出较高的聚类性能和较好的内部评估指标得分。这个k值允许我们将设备划分为四种主要的运行状态:正常运行、数据采样异常、采样频率异常,以及数据稳定性受影响的状态。
聚类结果揭示了设备运行状态的多个独特模式,其中每个颜色的点群代表一个聚类,反映了不同的设备运行状态。如图2所示,绿色点群代表常态运行的设备,而黄色点群则表示存在采样数据异常的设备,这可能暗示设备的故障或配置问题;蓝色点群揭示了采样频率过低的异常状态;紫色点群则可能表明设备数据稳定性受到了影响。这种分类对于后续的监测和故障诊断至关重要,因为它帮助我们快速识别出哪些设备需要进一步分析或维护。
最后,我们通过与地质灾害监测系统中已知的设备故障记录进行对比,验证了聚类结果的准确性和实用性,如表1所示。这一步不仅证实了聚类分析的有效性,还强化了该方法在未来地质灾害监测设备故障排查中的应用潜力。通过这种方法,我们可以显著提高监测系统识别故障设备的效率和准确性,为防灾减灾提供有力的技术支持。
2.2 LSTM模型实验
在地质灾害监测设备故障排查的研究过程中,我们的目标是开发一个能够准确预测设备故障的高效模型。通过结合K-means聚类算法和长短期记忆网络(LSTM),本研究提出了一个创新的方法,旨在利用监测数据中的模式和趋势来识别潜在的故障。K-means聚类算法首先被用于处理和分类监测数据,将数据分为多个簇,每个簇代表一种特定的运行状态。这一步骤不仅帮助我们识别出异常数据,还为深度学习分析提供了清晰的数据基础。
训练阶段:在聚类分析之后,我们利用LSTM模型深入分析了这些数据。LSTM的能力在于其处理时间序列数据的861c8cc38adc7f366653180a8e0a38cae286547040597b008112fa8ea5fc9f07高效性,特别是它能够捕捉到数据中的长期依赖关系,这对于预测设备的故障状态及其发展趋势至关重要。我们将K-means识别出的异常设备数据作为训练集输入到LSTM模型中。在进行地质灾害监测设备故障排查LSTM模型的实验时,我们对数据集进行了细致的划分,以确保模型训练的准确性和泛化能力。具体来说,我们从监测设备中收集了总共10 000条数据作为整体数据集。为了有效地训练、验证和测试模型,我们按照70%、15%、15%的比例将数据集分为三部分:训练集、验证集和测试集。
训练集(70%):选取7 000条数据作为训练集,用于LSTM模型的学习和训练。通过这部分数据,模型能够学习到设备运行中的各种正常与异常模式,如突然的数据峰值、频繁的数据波动等。
验证集(15%):选取1 500条数据作为验证集,用于模型训练过程中的性能评估。利用这部分数据,可以调整模型参数,优化模型结构,以提高模型的预测准确率和泛化能力。
测试集(15%):选取1 500条数据作为测试集,用于模型训练完成后的最终性能测试。测试集数据在模型训练过程中未被使用,因此能够公正地评估模型在未知数据上的预测能力和稳定性。
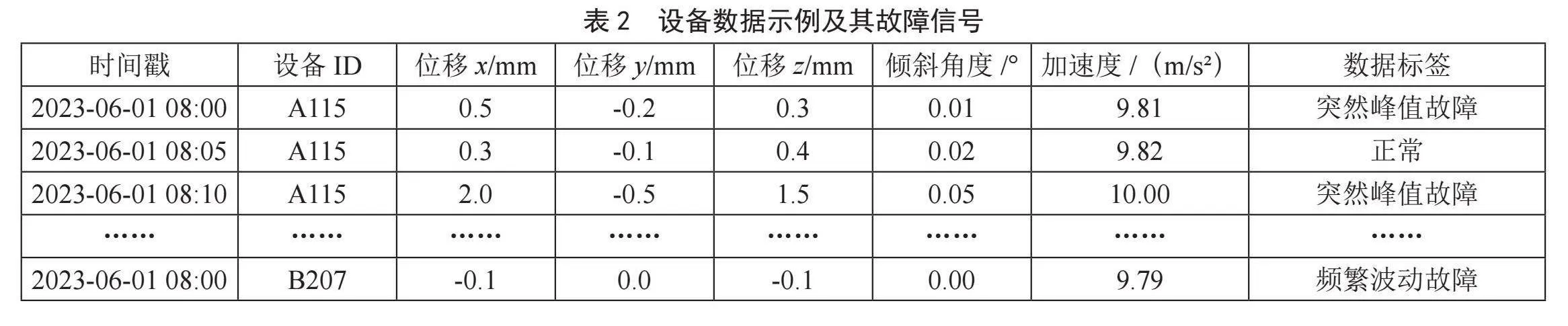
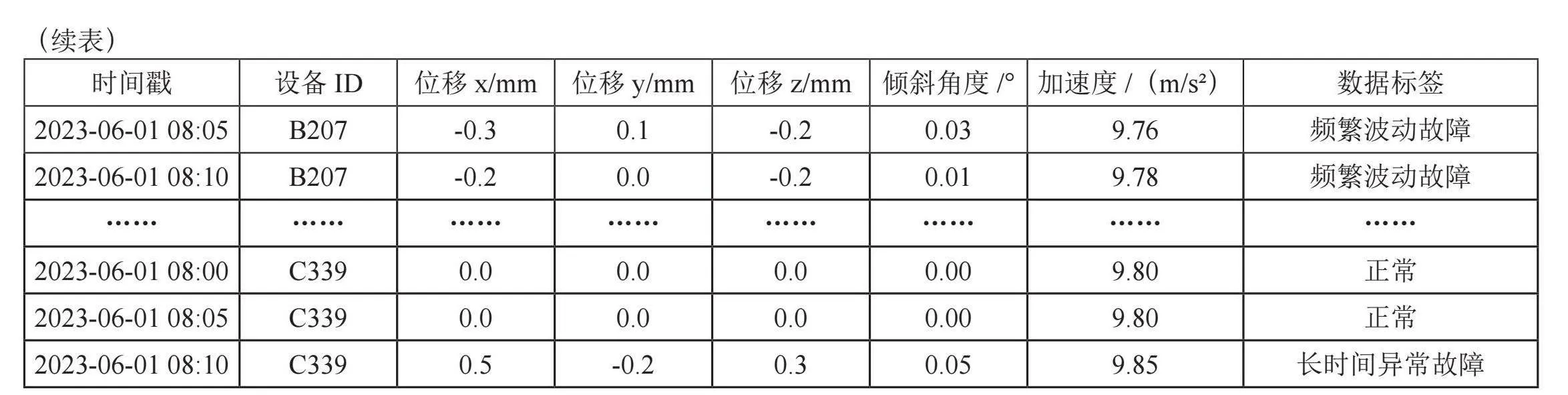
这些数据是根据时间顺序整理的设备监测数据,包含了各种可能指示设备故障的信号,例如突然的数据峰值、数据的频繁波动,或是数据值的长时间异常等。在训练阶段,模型通过学习这些异常数据背后的时间模式来识别不同类型的故障状态。表2展示了三个不同设备的监测数据示例,并将这些数据作为LSTM模型训练的输入。
在LSTM模型训练过程中,我们调整了网络的各项参数,确保模型能够有效学习并预测地质灾害监测数据的时间序列特征。具体的参数设置如下:学习率设为0.001,以促进模型在训练过程中权重更新的稳定性,避免因步长过大导致的最优解跳跃;隐藏层单元数定为128个,这样的单元数量既能够捕捉到数据中的复杂特征,又能避免不必要的计算资源消耗;批处理大小设置为每批100(batch size = 100)条数据,保证了每次迭代的计算效率与模型训练的性能;迭代次数为30(epoch = 30),足够模型在各种数据批次中进行深入学习,直至性能达到稳定。这些参数经过多次实验和调整,是根据模型在验证集上的表现以及最终在测试集上的准确性和泛化能力来确定的。通过这些精心调整的参数,我们的模型在实际应用中表现出了较好的预测准确率和稳定性。
训练目标:在LSTM时序分析模型的训练过程中,我们的主要目标是让模型能够有效地从异常设备的时间序列数据中学习并识别出潜在的故障模式。通过对K-means聚类分析所识别的异常数据进行进一步的时序分析,LSTM模型旨在掌握这些数据背后的复杂动态行为和潜在的故障模式。为了实现这一目标,我们将训练过程中的分类依据划分为三个主要的故障类型,即轻微故障、中度故障和重大故障。这种分类方法基于先前通过专家知识和历史故障数据定义的故障严重程度标准,使得LSTM模型不仅能够识别出设备是否存在故障,而且还能够根据故障的严重程度进行精准分类。通过这样的训练目标设置,我们期望LSTM模型在完成训练后,能够对实时监测到的设备数据进行有效的故障预测和分类,从而为地质灾害监测设备的故障排查和维修决策提供强有力的技术支持。
输出结果:在经过K-means算法精准地区分出异常设备后,我们利用LSTM时序分析模型对这些设备的故障状态进行更深入的分析和预测。LSTM模型的输出结果主要涵盖以下三个方面:1)当前故障类型的识别:基于K-means聚类结果及LSTM模型分析,每个设备被精确标记为具体的故障类型,这包括但不限于突然的数据峰值、数据的频繁波动,或是数据值的长时间异常等。这一步骤帮助我们理解设备当前面临的具体问题。2)故障风险等级评估:LSTM模型进一步对每种故障类型进行风险等级的评估,分为轻微故障、中度故障和重大故障。这一评估基于模型对时间序列数据的深入学习,考虑了故障发生的频率、严重性以及可能的发展趋势。经过训练的LSTM模型可以对新的时间序列数据进行精确分类,其输出是一个概率分布向量,表示该时间序列数据属于每种故障类型的概率。例如,模型可能输出一个向量[0.1,0.2,0.7],表明相比轻微故障(10%的概率)或中度故障(20%的概率),这个设备有更高的概率(70%)正处于重大故障状态。此模型的输出结果不仅为故障诊断提供了定量依据,还能够帮助维护团队优先处理那些处于更严重故障状态的设备,从而有效提升了维护效率和设备运行的稳定性。3)未来故障发展趋势的预测:除了对当前状态的分析和风险评估,LSTM模型还能预测故障可能的发展趋势,尤其是在未来24小时内故障升级的概率。这包括从轻微故障升级到中度故障,或从中度故障升级到重大故障的概率。这种预测对于采取预防措施、规划维护工作以及避免潜在的设备停机具有重要意义。表3展示了LSTM模型的输出示例,可用作地质灾害监测设备的综合故障预测及风险评估。
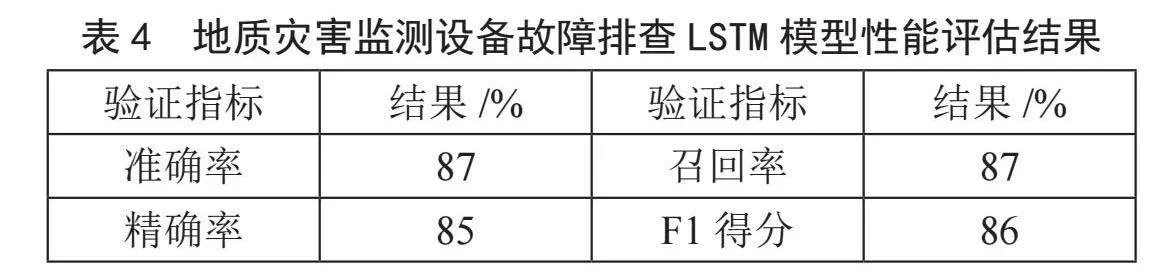
在完成了数据集的划分和模型的训练之后,我们对本文设计的地质灾害监测设备故障排查模型进行了全面的性能评估。评估指标主要包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1得分(F1-Score)。其中,准确率反映了模型在所有测试数据上的正确预测的比例,精确率评估了模型预测为故障的设备中,实际上确实存在故障的设备的比例,召回率衡量了模型能够识别出的实际故障设备中,正确预测出的比例,F1得分是精确率和召回率的调和平均数,用于在精确率和召回率之间取得平衡。这些指标能够全面反映模型在故障排查任务上的表现。实验结果如表4所示。
实验结果表明,我们构建的地质灾害监测设备故障排查LSTM模型具有较高的准确性和可靠性,能够有效识别和预测设备的故障状态,为地质灾害监测提供了有力的技术支持。未来,我们将继续优化模型结构和算法,进一步提升模型的性能,以适应更加复杂多变的监测环境。这种LSTM时序分析模型的应用,能够让运维团队快速识别并响应监测设备的异常状态,采取针对性的维修或预防措施,从而避免可能发生的地质灾害。与K-means聚类分析相结合,LSTM时序分析提高了对地质灾害预警系统的综合分析能力,对于提升系统的预测精度和可靠性具有重要意义。通过这样的深度学习分析流程,我们不仅能够处理即时数据,还可以根据模型预测制定长期的维护计划,对系统的管理和维护提供了强有力的技术支持。
3 模型设计理念与应用分析
本文提出的结合K-means聚类算法和长短期记忆(LSTM)网络的地质灾害监测模型,着重于通过技术创新提升地质灾害预测的准确性和效率。模型背后的核心思想是利用K-means算法对大规模地质灾害设备监测数据进行有效聚类,随后借助LSTM网络深入挖掘聚类后的时间序列数据特征,实现对地质灾害发展趋势的精准预测。
3.1 模型设计理念与创新点
模型创新地将聚类算法[12]与深度学习技术[13]相结合,以K-means算法为基础对地质监测数据进行初步的预处理和分类,有效地将具有相似特性的数据点聚集,从而减轻了时间序列分析中的噪声干扰,并为LSTM网络处理数据奠定了基础。这种预处理步骤不仅提高了数据处理的效率,还提高了模型对未来地质灾害发展趋势预测的准确性。LSTM网络的引入,进一步增强了模型对时间序列数据长期依赖关系的捕捉能力,使其能够有效预测具有复杂时间属性的地质灾害事件。
3.2 应用场景与潜在价值
该模型在地质灾害监测的多个场景下都显示出极大的应用潜力,尤其适用于通过监测地表变化来预测滑坡、地面沉降等灾害的场景。利用实时地质监测数据,模型能够为可能的灾害风险提供及时的预警,有效地支持灾害预防和应对措施的制定。模型的实施不仅能显著提升地质灾害预警的准确度和时效性,降低因灾害造成的人员伤亡和经济损失,还能减少对人工巡检的依赖,推动监测系统向自动化和智能化方向发展,为地质灾害监测和管理领域带来深刻的影响。
4 结 论
综上所述,本文提出的基于K-means聚类和LSTM网络的组合模型,在地质灾害设备监测领域展现出良好的应用前景。该模型通过精确处理时间序列数据,能够有效预测地质灾害的发展趋势,为灾害预警和控制提供了一种新的技术路径。尽管在实际应用中仍面临诸多挑战,如数据收集的难度、模型的泛化能力等,但随着技术的不断进步和数据资源的丰富,相信这些问题将得到有效解决。未来的研究将集中在进一步提高模型的准确性和实用性上,探索更多的算法组合和数据处理方法,以适应更加复杂多变的监测环境。同时,也将致力于模型的实际部署,实现地质灾害监测的自动化和智能化,为保护人民生命财产安全做出更大的贡献。
参考文献:
[1] 刘传正,陈春利.中国地质灾害防治成效与问题对策 [J].工程地质学报,2020,28(2):375-383.
[2] 范强,巨能攀,向喜琼,等.证据权法在区域滑坡危险性评价中的应用——以贵州省为例 [J].工程地质学报,2014,22(3):474-481.
[3] 中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要 [J].中国水利,2021(6):1-38.
[4] 李雪峰.落实《“十四五”国家应急体系规划》之解析 [J].劳动保护,2022(4):30-32.
[5] 国务院关于加强地质灾害防治工作的决定 [J].国土资源通讯,2011(12):5-7.
[6] HAMERLY G,ELKAN C. Learning the K in K-means [C]//NIPS03: Proceedings of the 16th International Conference on Neural Information Processing Systems,MIT Press:Cambridge,2003:281-288.
[7] YONG Y,SI X S,HU C H,et al. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures [J].Neural computation,2019,31(7):1235-1270.
[8] 汪民.关于地质灾害防治需要关注的几个问题 [J].中国地质灾害与防治学报,2022,33(1):1-5.
[9] 许强.对地质灾害隐患早期识别相关问题的认识与思考 [J].武汉大学学报:信息科学版,2020,45(11):1651-1659.
[10] 隋嘉,孙皓,张丽华,等.青海省地质灾害监测预警信息化平台建设与实现 [J].中国地质灾害与防治学报,2023,34(2):92-101.
[11] 李玉,俞志明,宋秀贤.运用主成分分析(PCA)评价海洋沉积物中重金属污染来源 [J].环境科学,2006(1):137-141.
[12] 孙吉贵,刘杰,赵连宇.聚类算法研究 [J].软件学报,2008(1):48-61.
[13] 孙志军,薛磊,许阳明,等.深度学习研究综述 [J].计算机应用研究,2012,29(8):2806-2810.
作者简介:王雅洁(1990—),女,穿青人,贵州贵阳人,高级工程师,硕士研究生,研究方向:大数据应用、人工智能、地质灾害模型设计;通信作者:张成梅(1991—),女,汉族,贵州六盘水人,工程师,硕士研究生,研究方向:大数据、地质灾害防控;杨鑫(1997—),男,穿青人,贵州织金人,助理工程师,本科,研究方向:大数据、地质灾害模型设计;秦梅元(1992—),女,侗族,贵州天柱人,助理工程师,本科,研究方向:大数据。