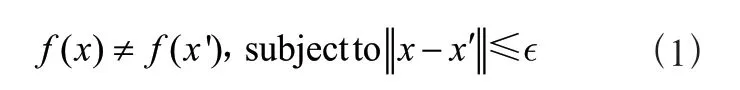



摘 要:针对智能信息推送管理者的多标签新闻文本分类任务,提出了基于ALBERT-CNN模型的解决方案。利用ALBERT预训练模型和TextCNN卷积神经网络,充分进行语义理解和特征提取。通过ALBERT模型进行语义筛选,精准把握新闻文本内容和主题,再传递给TextCNN模型进行分类和标签预测。采用Sigmoid函数输出每个标签的概率,实现精准的多标签分类。实验验证382 688条来自今日头条客户端的数据,ALBERT-CNN模型的F1-Score达到92.05%,召回率达到96.8%,精确率达到90%,相比于优于传统的ALBERT和ALBERT-Denses模型的F1-Score和召回率有所提升。在精确率上略低于AlBERT-Dense。该研究为提高信息推送效率和降低误导性信息的传播提供了一个新的解决方案。
关键词:多标签分类;ALBERT;TextCNN;自然语言处理
中图分类号:T391.1 文献标识码:A 文章编号:2096-4706(2024)20-0031-06
Multi-label News Text Classification Based on AlBERT-TextCNN Model
MAI Yongxin, LIN Zhihao, XI Juanxia
(School of Information Management and Engineering, Neusoft Institute Guangdong, Foshan 528225, China)
Abstract: Aiming at the multi-label news text classification task of intelligent information push managers, a solution based on ALBERT-CNN model is proposed. The ALBERT pre-trained model and TextCNN Convolutional Neural Network are employed to comprehensively understand semantics and extract features. Semantic filtering is performed through the ALBERT model to accurately grasp the contAZ6CqoBAwzn42GewLMeHwX0fKKEGlJ6FoIH9+AxHSGU=ent and themes of news texts, which are then passed to the TextCNN model for classification and label prediction. The sigmoid function is utilized to output the probability of each label, achieving precise multi-label classification. The experiment verifies 382 688 data from the Toutiao client. The F1-Score of ALBERT-CNN model reaches 92.05%, the Recall reaches 96.8%, and the Precision reaches 90%. Compared with the traditional ALBERT and ALBERT-Dense models, it has improved in F1-Score and Recall. It is slightly lower than ALBERT-Dense model in Precision. This study provides a new solution for enhancing information push efficiency and reducing the spread of misleading information.
Keywords: multi-label classification; ALBERT; TextCNN; NLP
0 引 言
在信息爆炸的时代,面对信息过载、信息准确性和时效性的问题,5G技术的普及为智能信息推送管理带来了新机遇[1]。然而,目前市场上缺乏能够精准投递用户自定义标签信息的软件,现有通知权限开关也难以满足用户个性化需求[2]。因此,本研究选择关注该领域,提出了一种基于ALBERT-CNN模型的新闻文本分类方法,结合了ALBERT预训练模型、CNN和中文文本分类技术,以应对“知趣”软件中的多标签文本分类任务,提供更加个性化、精准的信息推送服务[3]。通过用户标签化设计和个性化选择,用户可以根据个人兴趣和需求定制信息推送,从而提高了信息查看的效率,避免错过重要通知,并减少了无用消息的干扰,进而提升使用体验[4]。本研究将详细介绍ALBERT-CNN模型的设计和实现,并对实验设置和结果进行分析,以验证方法的有效性和性能,并期望通过本研究为智能信息推送管理领域的发展做出贡献,提升信息获取体验和效率,降低虚假信息获取的概率[5]。
最终通过实时数据库中的数据,加载模型进行分类,并将最终的分类结果进行可视化呈现。这种可视化方式能够让用户直观地了解信息分类的结果,帮助他们更好地理解和利用推荐的内容。通过将分类结果以图表或其他形式展示,我们可以为用户提供直观、易于理解的信息服务,从而提高用户体验和信息获取效率。同时根据数据库不断新增的数据量,在一定增加阈值后进行模型续练。
1 系统模型构建
1.1 AlBERT模型
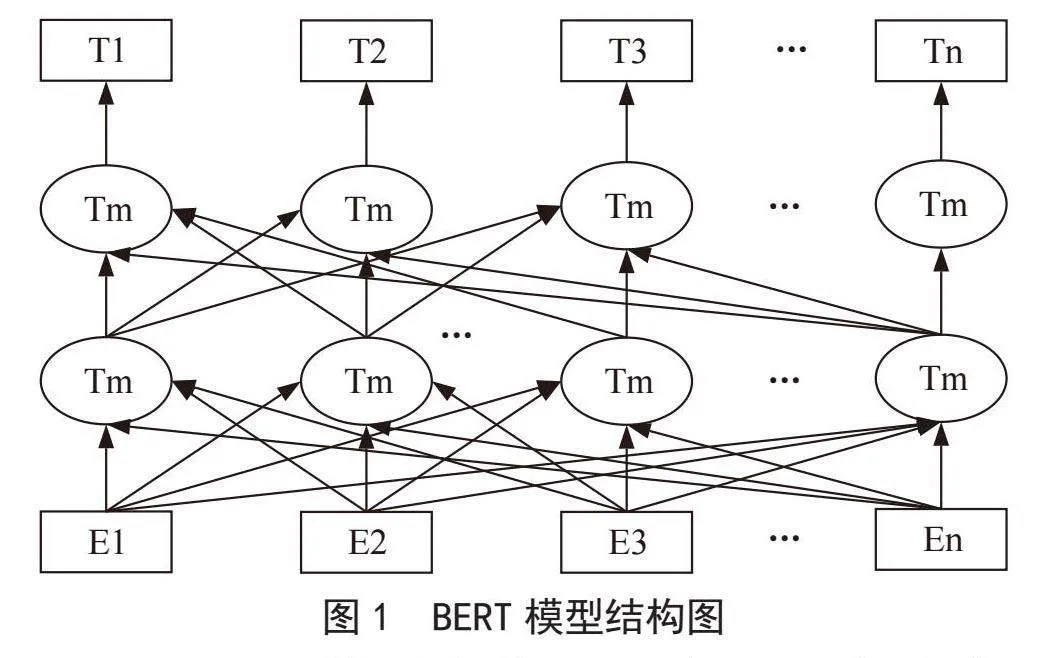
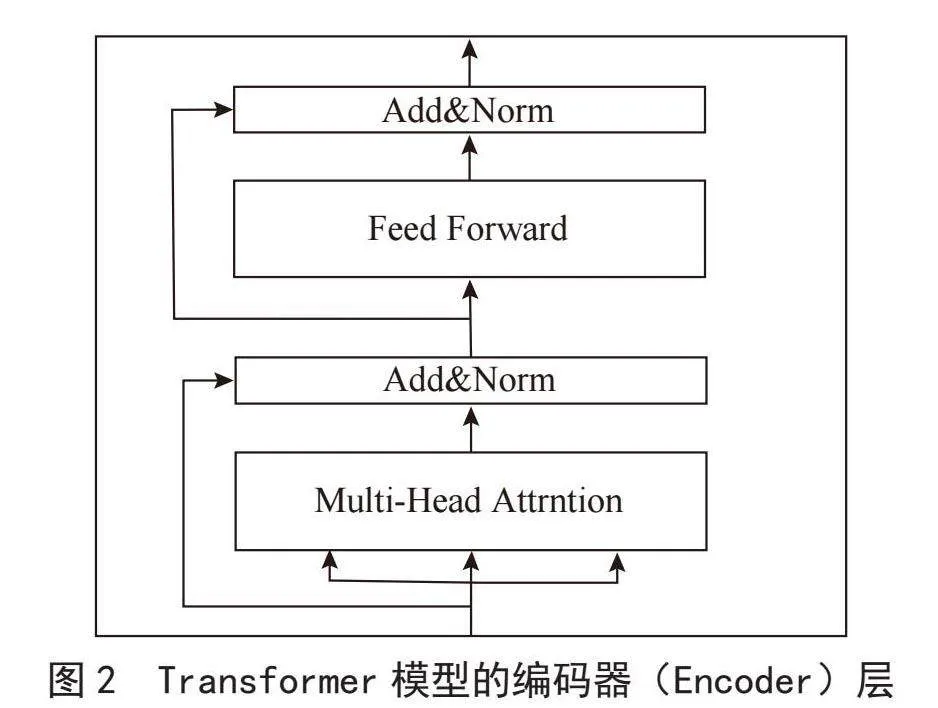
随着深度学习的发展,Google AI Language团队提出了基于Transformer的双向编码器BERT(Bidirectional Encoder Representations from Tranformers)模型,该模型由多个相同的Transformer编码器堆叠而成,BERT模型结构如图1所示。
Transformer模型由编码器(Encoder)和解码器(Decoder)两部分组成,由于在ALBERT以及BERT中仅关注Transformer模型的编码器(Encoder)部分,故本文不对解码器(Decoder)进行具体阐述。编码器部分由6个相同的编码器层组成,输入文本首先通过词嵌入得到位置编码后进入Transformer模块,首先通过多头自注意力机制(Multi-Head Self-Attention)在自注意力机制中,模型可以同时关注输入序列中的所有位置,并计算每个位置的注意力权重。多头自注意力机制允许模型使用多组注意力权重来学习不同类型的语义信息。通过这种方式,模型可以更好地理解输入序列的全局信息和局部信息,从而更好地捕捉上下文之间的依赖关系。
在多头自注意力机制之后,编码器层还包含一个前馈神经网络(Feedforward Neural Network),用于对自注意力机制的输出进行进一步的非线性变换。前馈神经网络通常是一个两层的全连接神经网络,其中包含一个隐藏层和一个激活函数,如ReLU。这个前馈神经网络在每个位置上独立地应用,使得模型可以学习到位置特定的特征表示。
在每个编码器层的两个主要组件(多头自注意力机制和前馈神经网络)之间,采用了残差连接。残差连接将编码器层的输入直接添加到其输出中,从而允许信息直接流经网络层,避免了梯度消失和梯度爆炸问题。在残差连接之后,每个子层的输出会应用层标准化。层标准化有助于确保数据在每一层的流动稳定性,并且可以加速模型的训练过程。编码器层的结构如图2所示。
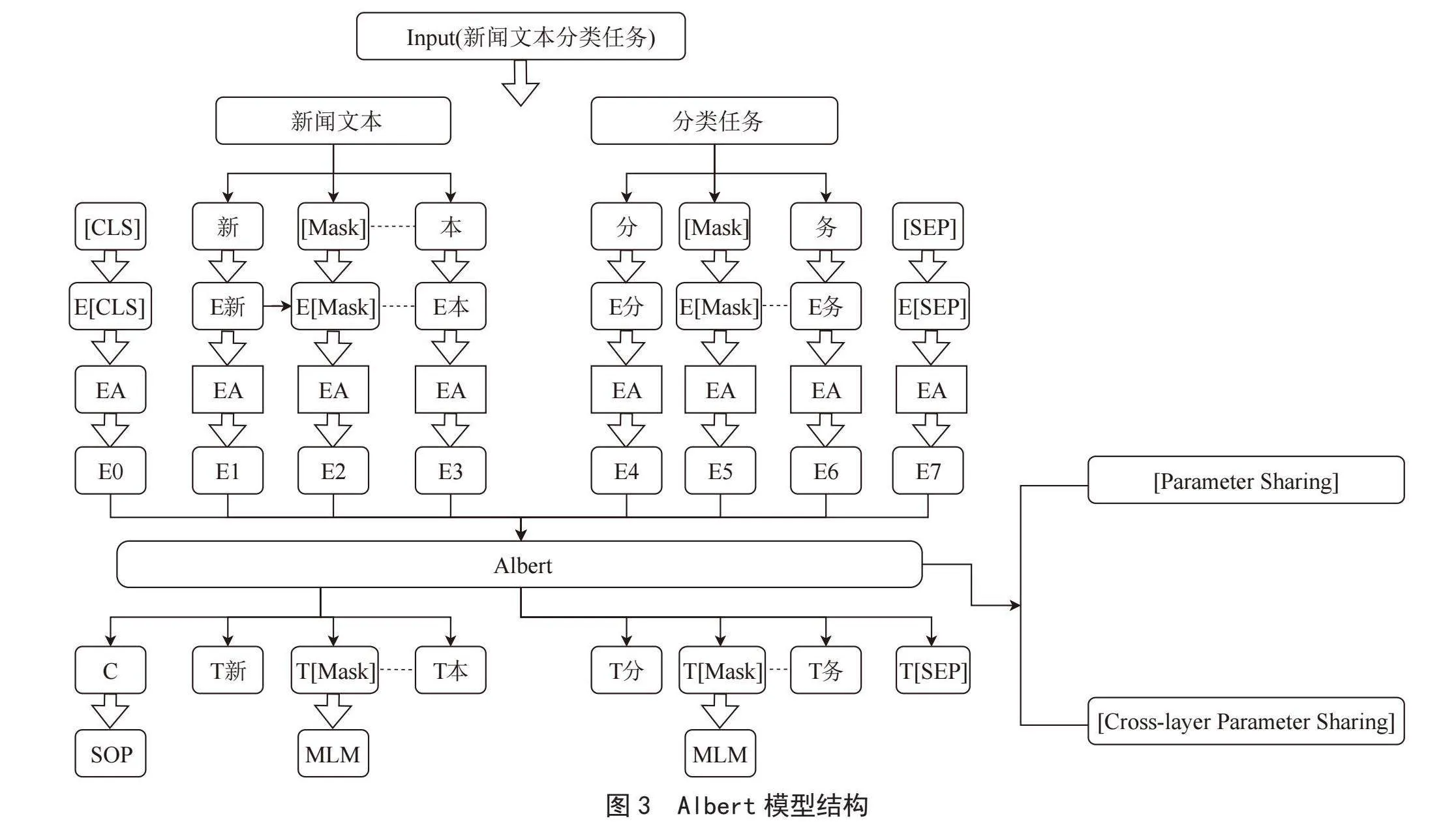
而AlBERT模型是在BERT模型的基础上设计的一个精简模型。它通过参数共享、矩阵分解等技术来减少BERT参数过大的缺点。AlBERT使用了SOP(Sentence Order Prediction)代替了NSP(Next Sentence Prediction)作为损失函数,这一变化提升了下游任务的性能表现。虽然AlBERT的层数并未减少,导致在模型推理时间上相对于BERT并没有改进,但由于参数量的减少使得模型的训练速度变快。因此,在相同的训练时间下,AlBERT的训练效果会优于BERT模型[6]。AlBERT模型结构中采用了Transformer和GELU激活函数[7]。其创新主要体现在三点,首先ABERT将输入文本的词嵌入表示(E)和模型中用于处理和学习文本特征的隐藏层(H)进行解绑,通过加入一个矩阵进行维度变换。这样的做法将原本的参数数量从VH降低为VE+E×H,在隐藏层增大时能够显著降低参数数量。其次是传统的Transformer每一层参数都是独立的,包括各层的Self-Attention和全连接。而AlBERT尝试将所有层的参数进行共享,之后的所有层都重复使用第一层的参数,而不是每一层都学习不同的参数。最后AlBERT将NSP任务转变为SOP(句子词序趋势预测)任务,更加注重句子顺序的语义关系而不是简单地判断两个句子之间是否相邻。
为了更好地适用于特定文本领域的任务,AlBERT进行了两个预训练任务:MLM(Masked LM)和SOP。在Masked LM任务中,模型的输入文本中的一些单词会被随机遮盖,然后模型需要预测这些被遮盖的单词。这个任务旨在让模型学会理解上下文,并预测缺失的单词,从而提高模型对语言的理解能力。具体流程如下:输入文本中的部分单词被随机遮盖,用[MASK]符号表示。遮盖后的文本作为模型的输入。模型通过编码器将输入文本转换成隐藏层表示。使用一个全连接层将隐藏层的表示映射到词汇表大小的输出向量。对于被遮盖的单词位置,模型在输出向量中选择相应的位置作为预测结果。计算损失函数并更新模型参数。在SOP任务中,模型会接收一对句子作为输入,并预测这两个句子是否按照自然语言的逻辑顺序排列。这个任务旨在让模型学习捕捉句子之间的语义关系和逻辑连贯性。具体流程如下:输入为一对句子,例如句子1和句子2。模型通过编码器将两个句子分别转换成隐藏层表示。将隐藏层表示通过一些全连接层和激活函数进行处理。处理后的表示输入到一个二元分类器中,预测两个句子的顺序是否正确[8]。计算损失函数并更新模型参数。具体流程如图3所示。
1.2 TextCNN模型
TextCNN是一种用于文本分类的卷积神经网络模型,其灵感源自传统的计算机视觉领域中的卷积神经网络。该模型由Yoon于2014年的论文《Convolutional Neural Networks for Sentence Classification》中首次提出。TextCNN利用不同大小的kernel能够捕捉文本中的局部特征,并通过卷积操作将这些特征提取出来,从而进行分类[9]。TextCNN主要由四个部分组成[10],其中第一层为输入层(嵌入层)。输入层的任务是对输入的文本进行分词,通常采用词嵌入技术(如Word2Vec、GloVe等)将输入的单词映射到连续的向量空间中。这样做的目的是为了能够将单词的语义信息纳入模型中。只有将文本进行向量化后,才能进行后续的卷积和池化等操作。具体来说,文本向量化包括以下几个步骤:文本分词、词向量矩阵初始化[11]、输入文本向量化。文本分词是将输入文本分割为若干个词语,将其转换为一个词语列表。词向量矩阵包含所有单词向量所表示的矩阵,通常以JSON格式存在,通过字典的形式存储单词与键的映射,根据词向量文件找到对应的词向量。词向量矩阵的初始化有随机初始化和预训练两种方法。在预训练的情况下,使用预先训练好的词向量文件初始化词向量矩阵,可以获取到富含语义信息的词向量。输入文本向量化根据文本分词的结果以及词向量文件的键,找出每个单词所对应的向量,按照文本中原有的顺序将这些向量组合起来,形成输入文本的向量表示。
在完成文本向量化后进入第二层进行卷积操作,卷积操作用于从文本中提取重要的局部特征,通过使用多个不同大小的卷积核来捕获不同长度的特征,举例来说特征Ci是由高度H的窗口为产生的,对于输入矩阵,可以通过卷积操作计算特征图:
其中,f表示激活函数,ωi表示卷积和,bi表示偏置项,卷积操作的最终结果是一组特征图,每个特征图运用于一个卷积核[12]。在此之后通过滑动窗口的方式在文本序列上移,针对每个窗口应用卷积和,然后对于每个窗口,一般通过一个非线性函数,例如ReLU(Rectified Linear Unit)来激活卷积的结果:
在卷积操作完成后,通过应用池化层[13]来进行池化操作从而对特征进行降维的同时保留最重要的特征,在TextCNN中通常采用最大池化,例如,对于大小为3×300的特征图,我们从中选择每个通道的最大值,得到一个长度为300的特征向量。上述操作可以得知当值越大的时候代表越重要,同时另一个好处是可以处理长度浮动的句子(由于最后仍然是取最大值作为结果,所以最终仅有一个输出)。之后,将所有池化后的特征连接起来,并通过一个或多个全连接层将其映射到输出类别上。全连接层通常包括一个或多个隐藏层,每个隐藏层都使用激活函数(如ReLU)来引入非线性。最终,将通过带Dropout[14]的全连接层的输出通过Softmax函数进行归一化,得到每个类别的概率分布。模型预测的类别是具有最高概率的类别。在此过程中引入了正则化的过程来避免模型过拟合的问题,在倒数第二层网络中,加上Dropout可以在一定概率下使得神经元不工作,以此来增加模型的泛化能力。
1.3 Sigmoid函数
在多分类的情况下,Sigmoid允许处理非独占标签(也称为多标签)[15],而Softmax处理独占类。本文中需要对新闻文本进行分类,而一则文章中可能不仅仅只有一种标签。使用了Sigmoid函数进行处理,Sigmoid是一种具有S型曲线的数学函数,常被用作激活函数:
该函数将输出限制在0与1之间,具有单调性和可导性,使得其在概率预测中起到较大的作用。Sigmoid函数在原点的导数最大,而在两端逐渐趋近于零。这意味着在反向传播过程中,通过Sigmoid函数传播的梯度可以保持一定的大小,从而减少了梯度消失的可能。
1.4 ALBERT-TextCNN模型的构建
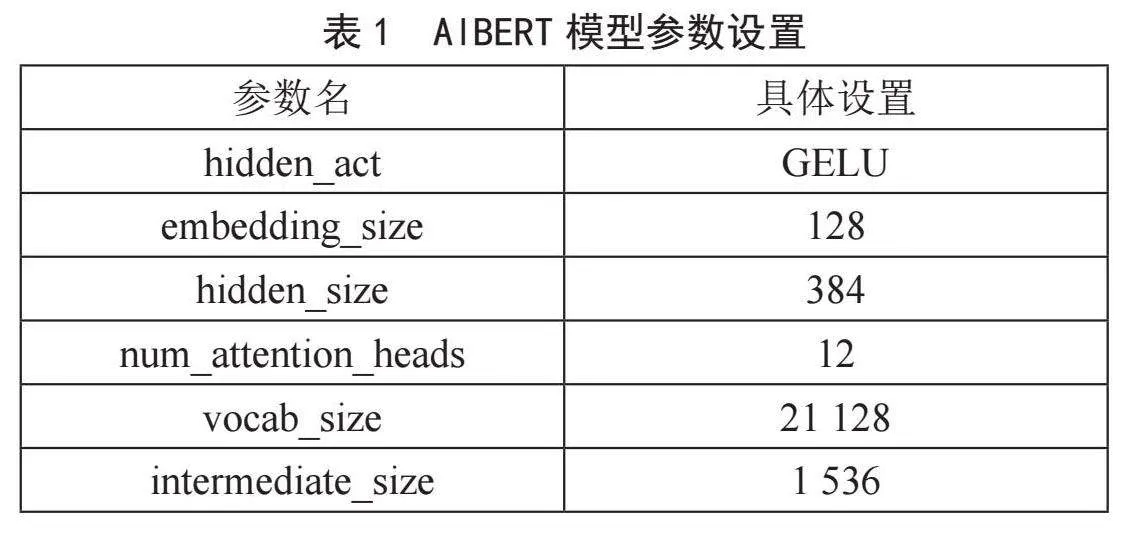
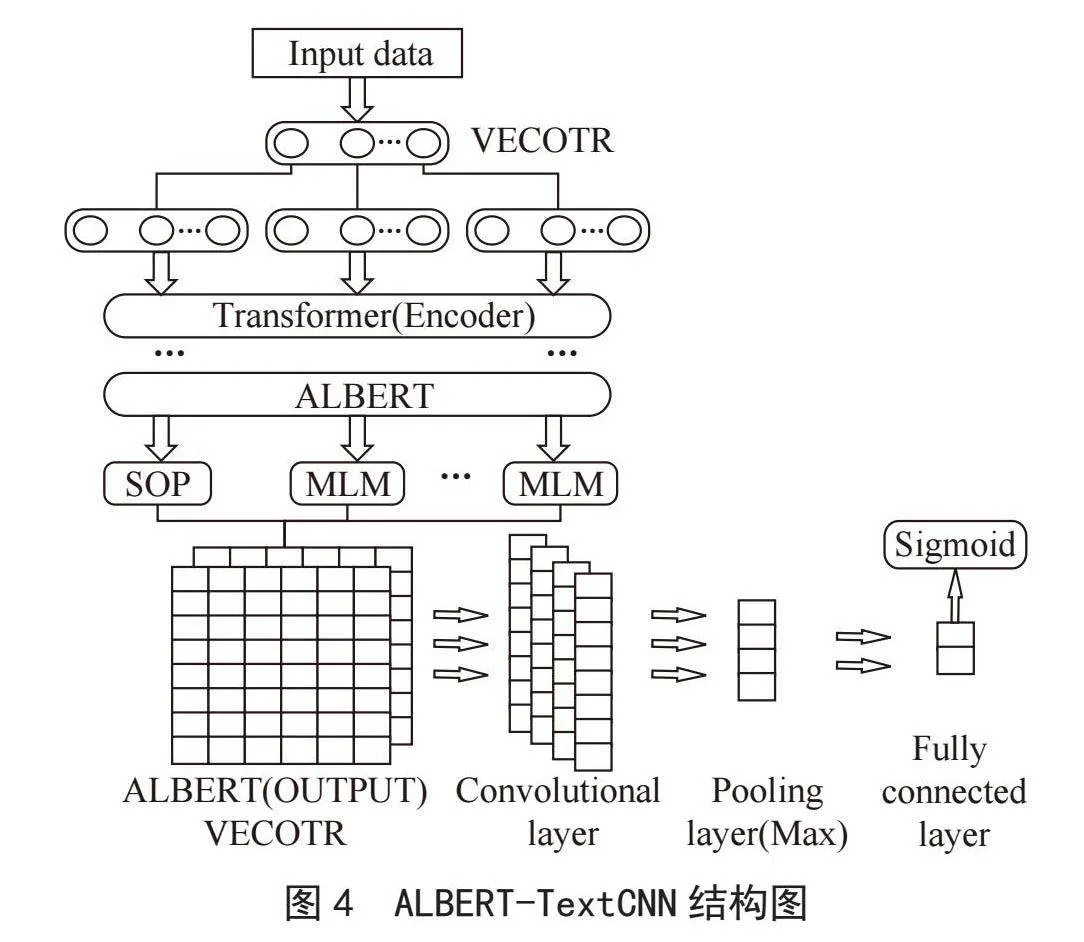
本文将数据集文本先经过将AlBERT模型所传出的三维向量output_layer_init:(batch_size,sequence_length,hidden_size)传入TextCNN中,最后通过全连接层将TextCNN的输出映射到标签结果上。其中AlBERT和TextCNN的具体参数设置如表1、表2所示。
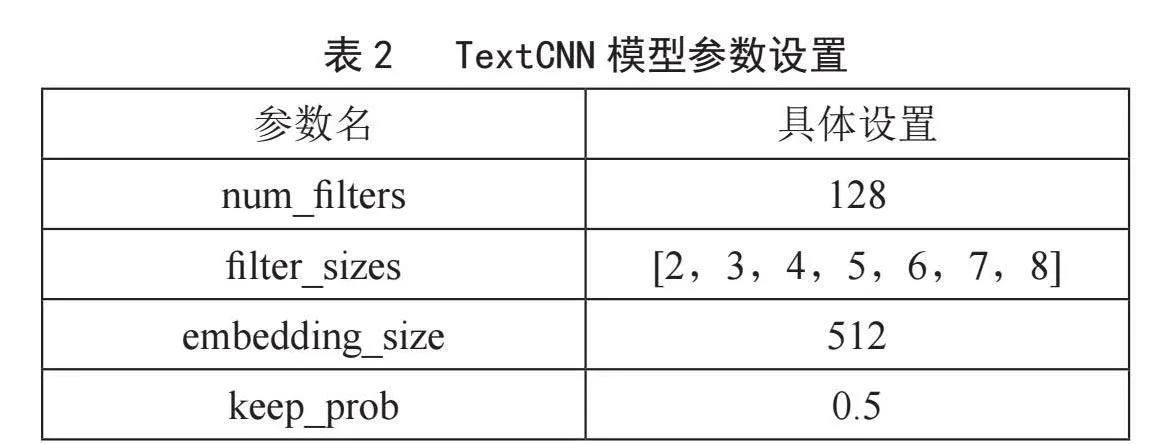
其中表1中的hidden_act表示隐藏层中应用的激活函数,hidden_size表示隐藏层的大小,决定了隐藏层的神经元数量。embedding_size表示词嵌入的维度大小。num_attention_heads表示注意力头的数量(在transformer模型中的自注意力机制可以分为多个头进行计算),有助于模型学习多种不同的特征表示,vocab_size表示词汇表大小,intermediate_size表示中间层的大小。表2中的num_filters表示卷积层中过滤器的数量,filter_sizes表示卷积核的大小,由于中文词汇中可能存在5个字、6个字、7个字和8个字的短语以及诗词,所以在原ixW51xbIOtVl5Swrsm89Hw==本提供的2、3、4的卷积核大小下增加了新高度的卷积核,keep_prob表示Dropout层的保留概率,模型的具体结构如图4所示。
2 实验设置以及结果与分析
2.1 实验数据集
本文中所用到的实验数据来源于今日头条客户端所提取的382 688条数据,训练集与验证集的比例设置为8:2。每一条标签样本数据都带有各自的文本类别标签。其中数据集中共有15个类别标签,数据集中采用了one-hot独热编码方式[16]对数据进行排布,具体的样本标签种类包括:民生、体育、汽车、军事、证券、文化、财经、教育、旅游、农业、娱乐、房产、科技、国际、电竞等。
2.2 实验环境
在此实验中,关键硬件采用了i7-12700H处理器,16 GB内存以及3070显卡。在软件环境方面,我们选择了基于Windows平台的Python 3.7.0版本进行程序开发。主要依赖的第三方库是TensorFlow 1.15.4+nv,这是针对英伟达30系显卡特别编译的版本,利用CUDA 11.2.2实现了GPU加速,从而提升了训练效率。
2.3 实验评估标准与对比
2.3.1 评估指标
在分类问题中,为了更加方便地查看模型的性能,通过会采用精确率(P)、召回率(R)和F1-Score(F)来进行模型评估,然而在多标签分类中,上述指标的计算标准可能并不合适,但是仍然可以将标签的类别划分为正样本和负样本,在给出的多标签中,模型本身关注的对象标签即为正样本,其余则为负样本。则针对多标签分类模型采用上述指标模型的精度进行评估。对于精确率来说,其具体的计算公式为:
其中,SFNi表示把应有标签的位置预测为无标签,或者无法正确预测有标签位置。对于F1-Score来说,其具体的计算公式为:
2.3.2 对比算法
为了验证ALBERT-TextCNN模型能够提升在多标签任务场景下对新闻文本的分类性能,在实验中,本文设计ALBERT和ALBERT-Denses两个模型作为对比实验。ALBERT文本分类模型,通过ALBERT预训练好的模型进行词向量提取,利用一个神经元,实现文本多标签分类。ALBERT-Denses模型采用ALBERT预训练语言模型进行词向量提取后,通过多个二分类[17](全连接层)来解决多标签文本的分类问题的二元分类预测。
2.3.3 AlBERT-TextCNN实验结果分析
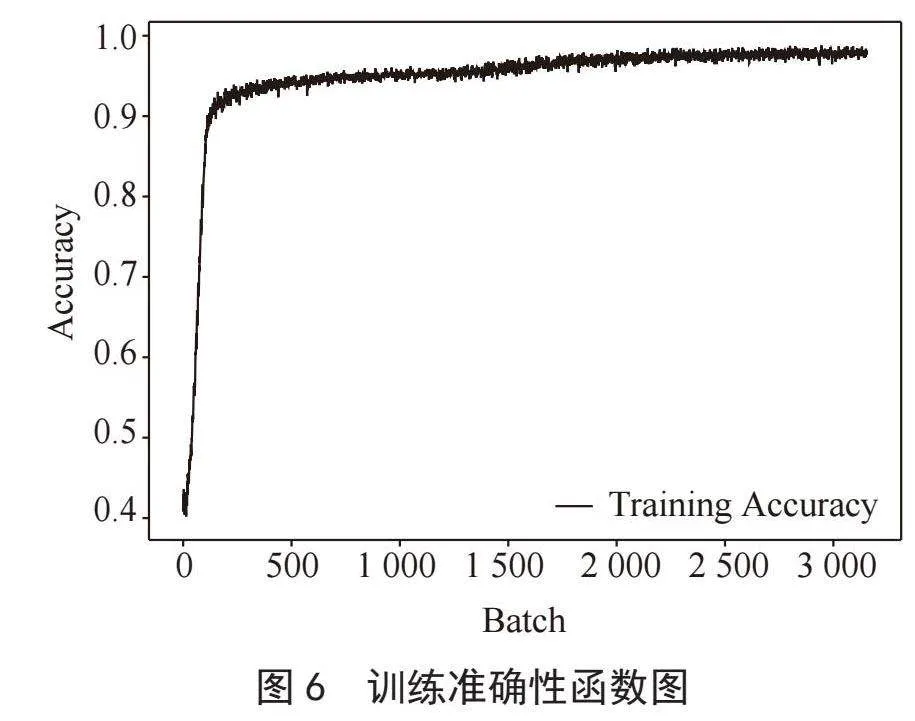
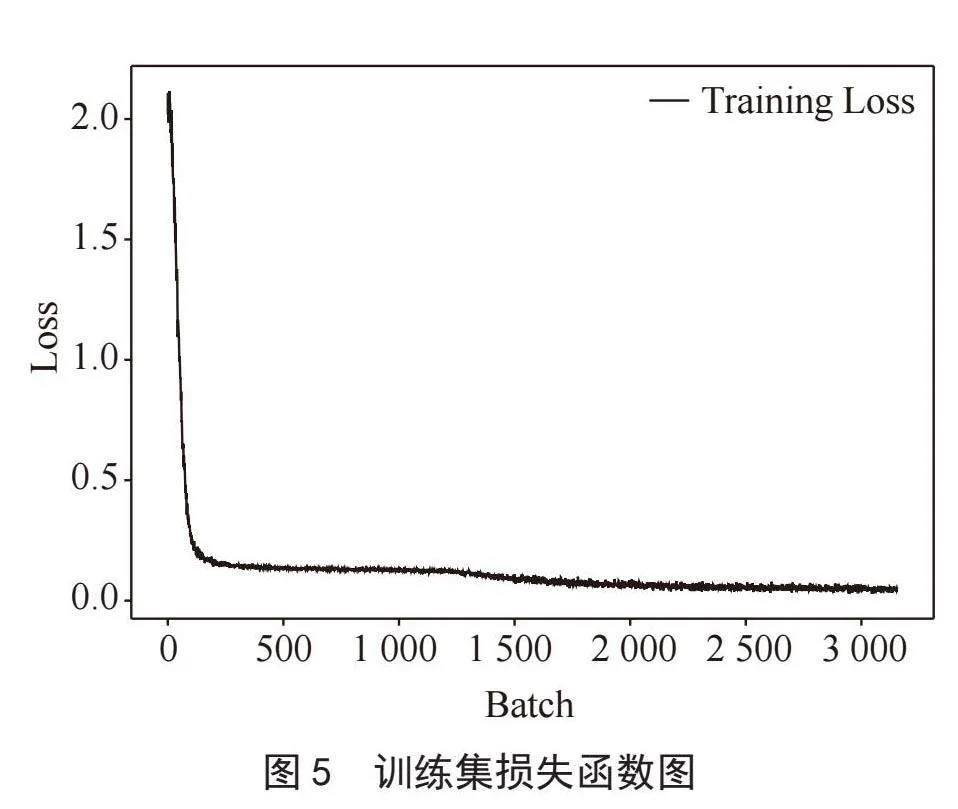
针对模型收敛效果,对AlBERT-TextCNN的损失(Loss)以及精确率(Accuracy)进行了图形绘制,具体结果如图5、图6所示。
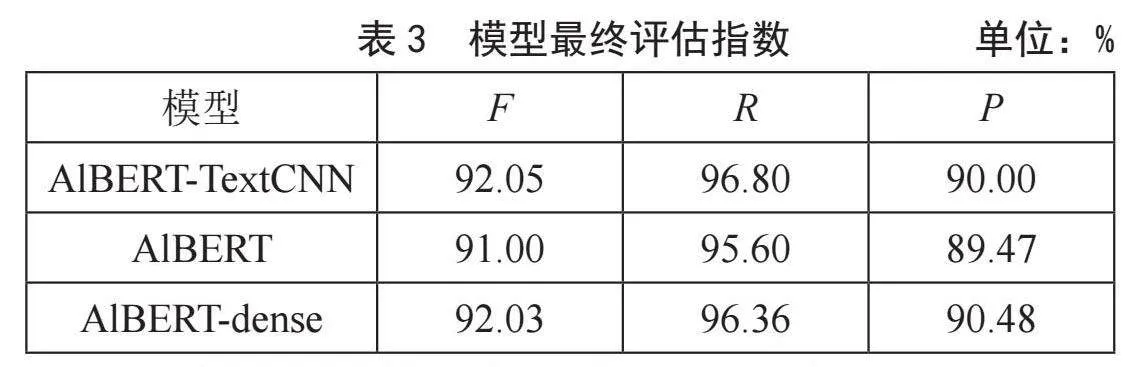
通过图表分析可得,在多标签文本训练的过程中,Loss的下降幅度非常快,但此时并不代表模型已经收敛,当Loss到达0.000 1~0.000 2区间时,模型的Loss以及Accuracy变化浮动较小,故认为模型在Loss值置于0.000 1~0.000 2区间时,模型已经达到收敛。最终模型的F1-Score、召回率以及精确率分别为92.05%、96.80%、90.00%。
2.4 对比算法结果分析
最终三个模型的F1-Score、召回率以及精确率如表3所示。
通过上述表格分析我们可以观察到,AlBERT-TextCNN在F1-Score上略高于ALBERT和ALBERT-dense,但三者之间的差距不大,说明它们在模型的整体性能上基本持平。AlBERT-TextCNN的准确率稍高于其他两个模型,这可能意味着它在正确分类样本方面稍微更加出色。而AlBERT-dense在精确率上略高于其他两个模型,这表明它在避免误分类负面样本方面表现会更好一些。通过叠加TextCNN的模型结构通常能够更加有效地捕获局部特征和模式,使其适用于文本分类等任务。
3 结 论
本论文提出了一种基于ALBERT-CNN模型的多标签新闻文本分类方法,旨在应对智能信息推送管理者领域的挑战。通过结合ALBERT预训练模型和卷积神经网络(TextCNN),以及特定于中文文本分类的技术,实现了对新闻文本的多标签分类。实验结果表明,本文提出的ALBERT-TextCNN模型在F1-Score、召回率以及精确率等评估指标上均取得了较好的效果,其中F1-Score和召回率在该模型在上表现出了较高的效率。但Precision相较于AlBERT-dense略有下降,后续将对数据集以及模型进行进一步优化,并最终将模型与实际应用结合起来,通过与数据库建立连接,将实时数据进行分类。通过上述流程实现了新闻舆情监测功能。通过这些工作,我们期望能够提高信息推送的个性化和精准度,为用户提供更好的信息服务。未来的工作将继续完善数据集,优化模型性能,挖掘数据集中标签更深层次的信息,考虑标签之间的关联性,使其更加适用于实际场景。
参考文献:
[1] LI T,DONG Y,ZHANG B. Algorithm Based Personalized Push Research on “Information Cocoon Room” [C]//2023 8th International Conference on Information Systems Engineering (ICISE).Dalian:IEEE,2023:286-289.
[2] KUANG A H. Construction of Personalized Advertising Accuracy Model Based on Artificial Intelligence [C]//2022 International Conference on Artificial Intelligence and Autonomous Robot Systems (AIARS).Bristol:IEEE,2022:395-398.
[3] 陈敏,王雷春,徐瑞,等.基于XLNet和多粒度对比学习的新闻主题文本分类方法 [J/OL].郑州大学学报:理学版,2024:1-8.https://doi.org/10.13705/ j.issn.1671-6841.2023164.
[4] 郝超,裘杭萍,孙毅,等.多标签文本分类研究进展 [J].计算机工程与应用,2021,57(10):48-56.
[5] 刘超民.生成式人工智能场景下虚假信息风险特殊性透视及应对 [J].中国海洋大学学报:社会科学版,2024(2):112-121.
[6] LAN Z Z,CHEN M D,GOODMAN S,et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations [J/OL].arXiv:1909.11942[cs.CL].(2019-09-26).https://arxiv.org/abs/1909.11942.
[7] 高玮军,赵华洋,李磊,等.基于ALBERT-HACNN-TUP模型的文本情感分析 [J].计算机仿真,2023,40(5):491-496.
[8] 刘晓明,李丞正旭,吴少聪,等.文本分类算法及其应用场景研究综述 [J].计算机学报,2024,47(6):1244-1287.
[9] KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL].arXiv:1408.5882[cs.CL].(2014-08-25).https://arxiv.org/abs/1408.5882v2.
[10] 万铮,王芳,黄树成.基于权重词向量与改进TextCNN的中文新闻分类 [J].软件导刊,2023,22(9):59-64.
[11] 张超轶,陈媛,张聚伟.融合术语信息的神经机器翻译参数初始化研究 [J].河南科技大学学报:自然科学版,2022,43(4):61-66+75+7.
[12] 钱华,祁枢杰,顾涔,等.基于近邻卷积神经网络的油画分类方法研究 [J].苏州科技大学学报:自然科学版,2024,41(1):69-75.
[13] 郭锐,熊风光,谢剑斌,等.基于改进残差池化层的纹理识别 [J].计算机技术与发展,2023,33(9):37-44.
[14] 齐悦,谢泰,沙琨.基于Grid-Search的Dropout-LSTM模型在新冠肺炎预测中的应用 [J].微型电脑应用,2024,40(2):211-216.
[15] 潘兵宏,章泽龙,周干,等.基于sigmoid换道模型的匝道连续分流间距 [J].长安大学学报:自然科学版,2023,43(6):37-48.
[16] 姚佼,吴秀荣,李皓,等.基于改进K-means算法的物流配送中心选址研究 [J].物流科技,2024,47(5):10-13+19.
[17] 周慧颖,汪廷华,张代俐.多标签特征选择研究进展 [J].计算机工程与应用,2022,58(15):52-67.
作者简介:麦咏欣(2002—),女,汉族,广东江门人,本科在读,研究方向:大健康数据处理与机器学习;林志豪(2004—),男,汉族,福建福清人,本科在读,研究方向:机器学习;蕙娟霞(1992—),女,汉族,甘肃白银人,助教,硕士,研究方向:机器学习智能信息处理。