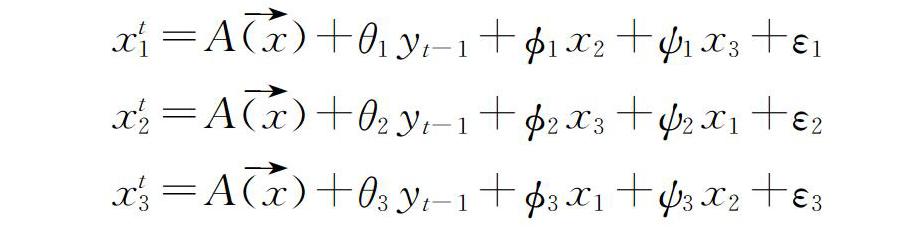
摘" 要:对于现有跌倒行为识别算法在复杂的居家环境条件下,出现算法精度低、实时性差等问题,文章提出一种基于YOLOv8的居家环境跌倒行为识别方法。该方法通过网络摄像头获取视频图像,使用基于YOLOv8的目标检测算法识别监控视频中每一帧画面的人体与跌倒特征,再结合时序状态特征处理,设定规则判别跌倒行为,并进行跌倒预警。实验证明,改进的方法精确率达94.9%,召回率达95.7%,FPS为40,算法识别准确率高、实时性强,为跌倒行为识别提供了一种简单而有效的方法。
关键词:YOLOv8;居家环境;目标检测;跌倒特征;跌倒行为识别
中图分类号:TP391.4" " 文献标识码:A" 文章编号:2096-4706(2024)21-0029-06
Fall Behavior Recognition in Home Environment Based on YOLOv8
YUE Liyun, OU Jiangang, CHEN Guohao, FANG Sixue, SHI Chenguang
(Guangdong Branch of China United Network Communications Co., Ltd., Guangzhou" 510627, China)
Abstract: For the algorithm problems of low accuracy and poor real-time performance of existing fall behavior recognition algorithms in the complex home environment conditions, this paper proposes a fall behavior recognition method in home environment based on YOLOv8. This method obtains video images from webcams, uses object detection algorithm based on YOLOv8 to identify the human body and fall features in each frame of surveillance video, and then combines the processing of sequential state features to set rules to identify fall behaviors and conduct fall warning. The experimental results show that the precision rate of the improved method is 94.9%, the recall rate is 95.7%, and the FPS is 40. The algorithm has high recognition accuracy and strong real-time performance, which provides a simple and effective method for fall behavior recognition.
Keywords: YOLOv8; home environment; object detection; fall feature; fall behavior recognition
0" 引" 言
国家统计局数据显示,60岁以上老年人口占比从21年底的18.9%骤升到23年底的21.1%,并且有相关研究表明,老年人一年中至少发生一次跌倒的概率大约在20%,需要就医的比例大约也在20%,且超过一半以上的跌倒发生在居家环境中[1]。老年人的身体机能随着年龄增长而下降,很容易因为跌倒而导致轻者骨折、残疾或活动受限等身心健康影响,重者甚至危及生命,存在较大的安全风险[2]。庞大的人口基数,叠加较高的发生概率和容易出现严重安全风险,老年人在居家环境中跌倒的问题更加引起人们的广泛关注。因此,开发一种准确而高效的居家环境跌倒行为识别方法,从而实现跌倒识别与及时救助报警,对于更好保障老年人的生命健康,降低跌倒带来的危害具有重要意义。
跌倒检测的常见方法主要包括基于物理传感器检测和基于视觉分析识别两种[3],考虑近些年深度学习技术的高速发展,基于深度卷积神经网络的视觉识别技术性能实现了质的提升,同时考虑物理传感器易受干扰和便利性方面的不足,本文主要考虑基于视觉特征分析的识别技术实现跌倒行为识别。而在基于视觉特征的跌倒识别技术中,又包括通过图像分类[4-5]、目标检测[6]、人体骨架[7-8]、多特征融合[9-10]、及视频分析和多算法融合[11]等多种方法。单纯的多特征融合方法、图片分类、目标检测和人体骨架方法虽然在单图识别上取得了良好的识别效果,但进行视频跌倒行为识别时并没有利用到时序特征,且因为识别图像数量大,整体识别准确率相对过低。而基于视频分析和多算法融合是当前使用最为广泛的跌倒行为视频分析方法,在具备跌倒行为识别能力且比较热门的开源模型中,包括通过目标检测、目标追踪和视频目标行为分类的YOLO-slowfast[12]实时动作(含跌倒)检测模型,以及通过目标检测、目标追踪、关键点识别和时空特征动作识别实现的HumanFallDetection[13]跌倒检测模型和PaddleDetection的PP-Humanv2[14]摔倒检测模型。这些模型经过了多步算法串联融合,每一步算法都存在一定的精度损失,导致不但整体跌倒行为识别的计算量巨大,难以达到实时,且识别精度相对较低。
本文方法综合了单纯的图像识别算法与基于视频分析和多算法融合的方法两种不同视觉算法的优缺点,并根据自定义的目标检测方法以及时序特征处理与分析方法,提出一种使用基于目标检测模型YOLOv8的跌倒行为识别算法。该算法相对单纯的图像识别方法增加了全局空间跌倒特征,以及时间域特征处理用于跌倒判别;而相对基于视频分析和多算法融合的方法在目标检测阶段增加了全局空间跌倒特征,并只保留了目标检测与时空特征跌倒行为识别两个步骤,精简了算法的流程复杂度。特别是,人体局部特征与全局空间跌倒特征的特征提取与组合分析处理,使得跌倒行为识别不完全依赖人体识别的准确性,考虑在一定程度上减少复杂居家场景下目标检测阶段人体的误检和漏检对后续跌倒行为识别带来的严重不良影响。本文方法通过对网络摄像头视频图像帧进行目标检测识别,提取视频帧中的跌倒相关特征,进而通过时序特征分析判断是否出现跌倒事件,实现实时的跌倒识别与及时救助报警,从而为居家环境中的老年人生命健康提供更好的保障。
1" 跌倒行为识别算法
1.1" 算法流程
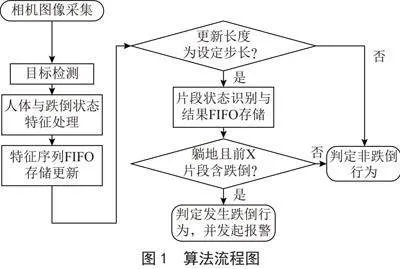
本文提出一种基于网络摄像头视频图像识别分析的跌倒行为识别算法,算法主要包括图像YOLOv8目标检测和视频统计特征分析判别两个部分,整体算法实现的流程如图1所示。
具体的跌倒行为识别算法流程为:
1)定义YOLOv8目标检测的任务为识别图像中的人体及确认画面是否存在人体躺下状态,使用目标检测算法提取人体目标特征与人体躺下状态特征;
2)对视频帧中的目标人体特征与跌倒状态特征进行特征处理,然后按时间顺序设置数帧为一段视频段,分段存储视频段特征,并根据经验参数对视频片段进行状态分类识别;
3)根据视频片段分类结果中的邻近历史片段状态变化特性设定识别规则,判定当前片段是否存在跌倒行为。
1.2" 目标检测算法YOLOv8
YOLO系列算法[15-22]以高效的一阶段目标检测机制著称,由于省去了区域推荐生成步骤,直接在图像特征图上进行密集的区域边界框和类别预测,因此速度极快,而YOLOv8是在2023年由Ultralytics平台发布的YOLO系列算法。YOLOv8主要基于YOLOv5,同时参考了YOLOX[19]、YOLOv6[21]和YOLOv7[22]等算法,在融合多种数据增强、训练方式提升、网络结构优化、损失函数改进等多方面策略加持下,算法的速度和精度性能也有了大幅度的提升。并且,由于引入了一些列新的改进,使得YOLOv8在目标检测之外的图像分类、实例分割和姿态估计等任务上同样展现出卓越的性能。
本文使用YOLOv8实现人体目标与人体躺下状态目标检测,实现跌倒行为相关特征提取。目标检测任务定义为人体局部区域,以及存在人体躺下行为全局区域的目标检测,从而提取局部和全局空间的跌倒相关特征。
令目标包围框使用VOC格式[x_min,y_min,x_max,y_max]进行标注,视频图像尺寸大小为宽度W高度H,则人体目标包围框Pi定义为[x1_i,y1_i,x2_i,y2_i],其中,x1_i lt; x2_i且x1_i,x2_i ∈[0,W-1];y1_i lt; y2_i 且y1_i,y2_i ∈[0,H-1]。而图片中可能存在唯一的人体躺下目标对应的包围框Ld定义为定值 [0,0,W-1,H-1]。
如图2所示,分别选取只包含背景的图片,只存在人体目标的图片,以及包含人体目标和人体躺下目标的图片,三类图片共同组成数据集,按照本文设定的包围框定义方法进行数据标注和处理,然后进行YOLOv8模型训练与调优,得到用于人体目标与人体躺下状态特征提取的YOLOv8目标检测模型。
1.3" 视频片段状态识别
视频片段状态识别依据YOLOv8目标检测得到的特征序列进行特征处理和判断识别。具体的操作流程是:
1)按FIFO方式存储每一帧图像识别结果,得到人体目标特征序列与人体躺下状态特征序列,存储容量总为L。
2)每当序列更新长度达到N(N<L,且N的常数a倍约等于L,即a×N≈L),且如果序列总长度为L,则进行一次视频片段识别。
3)长度为L的视频片段识别的流程包括,使用窗宽为Wd的滑窗对人体目标特征序列人体有无的状态进行滑动窗口滤波,再根据视频帧中人体目标有无进行人体躺下特征序列的状态确认,进而对序列中人体目标有无情况与人体躺下状态的变化情况进行分段统计。
4)当长度为N的序列分段中,人体目标出现帧计数Pm与人体目标出现的帧频率Pr满足Pr = Pm/N>α,α∈[0.5,1),且人体目标出现帧计数Lm与人体躺下出现的帧频率Lr满足Lr = Lm/N>β,β∈[0.5,1),则该分段标志为1,否则为0。
5)统计视频片段序列中各个分段的标志特征,具体为,统计分段标志0~1或1~0变化的次数Cm,及根据分段标志的头标志值Sx和尾标志值Sy,确认当前视频片段状态识别结果,具体的识别判断如式(1)所示。
(1)
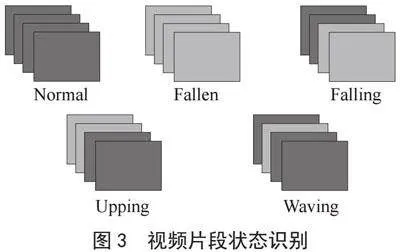
由此,得到视频片段识别结果,分为正常(Normal),躺地(Fallen),跌倒瞬间(Falling),站起(Upping),波动(Waving)五种视频片段识别结果,片段识别示例如图3所示。
如图3,每一个矩形表示分段视频帧集合,时间顺序为从左到右,从后到前。其中,绿色表示分段标志为0,红色表示分段标志为1,按照式(1),根据分段标志变化次数和头尾分段标志值对视频片段进行识别并得到五种识别结果之一。
1.4" 跌倒行为识别
跌倒行为识别依据视频片段状态识别与片段间状态关系进行经验判断实现。保存1.2得到视频片段识别结果,得到片段识别结果时间序列,根据该序列与跌倒强相关的状态转移关系进行跌倒行为识别。由1.2,与跌倒强相关的片段识别结果是躺地(Fallen)和跌倒瞬间(Falling),由此,本文使用简单的逻辑判断躺地片段前记录的X个状态中,是否存在跌倒瞬间来确定是否存在跌倒行为,如当前Fallen片段的前X个状态中存在Falling则判定为跌倒行为,否则判定为非跌倒行为。
对于算法的整体实现,此处以一个视频中的跌倒行为识别为例,展示视频识别中的视频片段行为状态变化过程,对跌倒行为识别算法的实现过程进行说明。
如图4所示,使用目标检测算法对每一帧图像进行识别,提取图像中的人体目标和跌倒状态目标,当视频帧数量更新长度达到指定长度N时,对视频分段进行分段标志0/1判断,图中所示每一张图像画面代表一个分段标志,绿色代表0,黄色代表1;当前分段与前面数个分段共同组成长度为L的视频帧构成视频片段,对该视频片段进行一次片段状态识别,得到当前视频片段的行为状态,如图4(a)、图4(b)和图4(c)所示,若当前视频片段状态为Fallen,则判断前X历史状态中是否存在Falling状态,若存在,则确认存在跌倒行为,向外部发起一次报警,并在接下来的一个视频片段范围内结果均展示为确认跌倒,即跌倒状态框使用红色展示,如图4(d),直至新的视频片段识别中,确认存在跌倒行为的条件判断不成立,则重新展示分段标志及其对应画面结果颜色。
2" 实验分析
2.1" 数据集处理
数据主要包含两部分,分别是YOLOv8目标检测训练与验证数据集,及跌倒行为识别视频数据集。本文跌倒行为识别主要应用于居家环境,适应于目标任务,跌倒目标检测数据主要为基于室内场景图片数据,跌倒行为识别评估也主要为基于室内场景视频数据。
目标检测数据集中包含各种姿态的人体躺下、其他常规人体行为、以及背景图三类。首先进行数据收集与预处理,数据主要来源于Multiple Cameras Fall Dataset[23],FallDataset[24],COCO[25]数据集及其他网络数据。其中,COCO数据集主要用于补充人物多样性与误识别对象及其他背景,如补充猫和狗这些可能会识别成人体的目标,而网络图片主要补充人体躺地数据集。
数据处理过程分为对视频数据集的处理和对图片数据集的处理。在Multiple Cameras Fall Dataset和FallDataset的视频数据集处理中,先把数据集中的视频数据对非跌倒片段以较大间隔随机采样,对跌倒片段进行较小间隔随机采样,并使用图像相似性过滤相似过高的图片,得到数量较少的图片数据集。把视频统一转换成图片数据集后,再对所有图片进一步筛选,最终得到目标检测数据集,目标检测数据集的样例如图5所示。
按1.2节所描述的方法,及图2所示方式进行数据标注和处理。其中,人体躺地的标签定义为人体躯干贴近地面,而滤除存在歧义的跌倒过程躯干未贴近地面的过程图。最终得到一个总量为2 269张图片的数据集,数据集划分后得到训练集1 928张和测试集341张。考虑背景图只训练分类分支,主要用于降低误检率,控制比例在10%以内。而具体到各类别的数据中,训练集的人体躺下图片1 082张、其他常规人体行为656张、背景图190张;测试集的人体躺下图片182张、其他常规人体行为123张、背景图36张。最后经过转换后把标注好的VOC格式目标检测数据集转换成YOLO格式,用于YOLOv8训练。
而对于跌倒行为识别测试数据集,主要使用自行拍摄的视频小片段,另外包含少量网络视频进行跌倒行为评估。其中,各种方式的跌倒行为视频共349个,包括但不限于行走、扫地、拿东西、坐起、弯腰或蹲下捡东西等各种非跌倒行为视频共396个,视频平均时长为8.7秒,平均帧率为28.8FPS,平均帧数为252帧。
2.2" 评估指标
本文主要考量跌倒行为识别的视频分类效果评估,主要使用的评估指标包括精确率、召回率和F2-Score[26],用于全面客观地了解视频跌倒行为识别模型的性能,具体指标定义如下。
1)精确率Precision。精确率指模型预测结果是正例的所有样本中,实际标签也是正例的样本比例。令TP是准确预测的正样本,FP是错误预测成正例的样本,则精确率公式表示为:
(2)
2)召回率Recall。召回率指实际标签是正例的所有样本中,模型预测结果也是正例的样本比例。令FN是实际标签为正例,但模型预测误识别成负例的样本,则召回率公式表示为:
(3)
3)F2-Score。指标F-Score是用于综合评估模型性能的精确率和召回率调和值。F-Score公式为:
(4)
对于本文跌倒识别任务,期望最大程度识别出跌倒行为,即使会导致更多的误识别,所以召回率相对精确率更为重要,本文使用F2-Score作为综合衡量分类模型性能的指标。令γ = 2,则有F2-Score计算公式为:
(5)
2.3" 实验与结果分析
模型的训练与评估实验均基于Windows系统,在一张RTX 3080显卡上进行。
在YOLOv8实验中,尝试了不同大小的YOLOv8模型,综合考虑本文数据集对应模型精度、模型大小和推理速度等情况,本文使用YOLOv8n作为跌倒行为识别的目标检测特征提取模型。按Ultralytics库规范处理好已标注完成的目标检测数据集,并对应写好模型训练配置文件,取模型为YOLOv8n,设置好训练参数,训练轮数为150,批处理数量为16,图像尺寸为640,其他模型超参数、训练超参数和数据增强超参数使用默认配置,对模型进行训练和评估,得到最优的图像目标检测模型。
基于最优YOLOv8n目标检测模型,串行构建跌倒行为识别算法模型,设置视频片段识别和跌倒行为识别的对应参数。按照本文模型设计,每L/4片段,即一个分段视频帧长度N(即0.5秒)识别一次,需要参考历史片段长度为X = 3,即视频总共需要大于总长度L(即2秒)才能正确实现跌倒行为识别,本文使用的跌倒识别视频测试集均满足要求。其中,在视频段状态识别中,设置总长度L = 2FPS,片段更新长度N = round(L/4)≈L/4,人体目标序列滤波窗宽Wd = 3,取人体目标帧频率和人体躺下帧频率α = β = 0.75;在跌倒行为识别中,记录片段识别状态X = 3,而后进行模型跌倒识别评估。
由于基于单图识别的算法用在视频行为识别中效果欠佳,且本文算法属于对基于视频分析和多算法融合的视频行为识别方法的一种简化处理,本文也只选取了基于视频分析和多算法融合的跌倒行为识别算法作为算法评估对照。本文选取前文提及的YOLO-slowfast、HumanFallDetection和PP-Humanv2,这几个可用于跌倒检测且质量相对优质的开源模型进行实验比较。其中,YOLO-slowfast实时动作检测的算法实现则基于视频序列识别,具体包括目标检测、目标跟踪、视频行为识别;而HumanFallDetection和PP-Humanv2跌倒检测的算法实现主要为基于关键点的行为识别,具体包括目标检测、目标跟踪、关键点识别、时序特征行为识别,而本文算法只包含了其中的目标检测和时序特征行为识别两个步骤。在实验测试中,由于对照实验的三个模型识别结果均以视频帧为识别单位,本文选取连续检测到跌倒的最大帧次数中,各个模型对应的最优参数作为视频识别的判别阈值,即片段中连续识别为跌倒的帧数为大于等于阈值则判断存在跌倒行为。在不同模型的最大连续跌倒帧数判别对应的最优阈值中,对于YOLO-slowfast跌倒识别的最优阈值为1,对于HumanFallDetection跌倒识别的最优阈值为5,对于PP-Humanv2摔倒检测的最优阈值为20,分别进行实验用于跌倒识别评估。
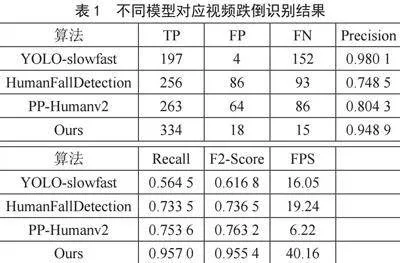
跌倒行为识别视频分类实验的评估指标包括Precision、Recall、F2-Score,以及视频识别速度指标FPS(Frames Per Second),各模型的视频跌倒识别结果如表1所示。
根据实验结果,在识别速度表现方面,PP-Humanv2识别速度最慢,而YOLO-slowfast和HumanFallDetection接近实时,本文算法则完全达到实时速率。在识别精度方面,YOLO-slowfast由于不是主要用于跌倒行为识别,所以对跌倒行为的召回率很低,而精确率为最高,但F2-Score为最低;HumanFallDetection和PP-Humanv2都是为跌倒行为识别而设计,但考虑跌倒行为识别又多个模型串联构建,同时需要保证一定的实时性,整体算法精度本身相对弱一些,并且使用的训练数据集相对单一,模型泛化能力也不够好,F2-Score评分为一般;而本文所提出的基于目标检测的视频跌倒行为识别算法在精确率、召回率和F2-Score等方面均表现优异,尤其是具有较高的召回率和F2-Score评分。本文算法在识别速度和精度方面均表现出色,切合跌倒行为识别的目标任务需求。
3" 结" 论
本文提出一种基于目标检测算法YOLOv8的居家环境跌倒行为识别方法,通过YOLOv8目标检测识别图像空间域的跌倒相关全局与局部特征,进行时间域序列特征处理,进一步实现跌倒行为视频阈值分类,从而综合跌倒行为的时间和空间特征构建了一个高效且准确的跌倒行为识别系统,实现对监控视频中的跌倒行为识别和进行预警。
实验证明,相对其他已有算法,本文方法具有明显更高的跌倒行为识别速度和精度,证明了本文使用局部与全局空间跌倒特征提取及时间域跌倒特征的处理组合实现跌倒行为识别的有效性。并且,由于本文方法主要基于YOLOv8目标检测算法,整体算法逻辑简单,能达到较高的识别速度和精度性能的同时,需要的算力很小,具有更低的硬件要求,易于部署到嵌入式AI摄像头中,从而有效解决算法部署与应用中的算力资源欠缺问题,也使得本文方法具有更广泛的居家场景适用性。
本文方法为居家环境下视频跌倒行为识别提供了一种可用新的思路,为跌倒行为的发生提供及时有效的救助报警,给老年人居家生活安全添置了一份重要保障。而与此同时,当前跌倒行为识别技术仍面临很多不同的挑战,如遮挡等复杂场景下的识别准确性、跌倒形式的多样性、及与其他特殊角度下蹲等生活行为存在高度相似性,等等。
因此,在未来的研究中,有待进一步深化对跌倒行为的特性理解,提取和融合更多的行为特征,以及采用更多不同的形式探索与构建更加先进的识别模型,以进一步提高跌倒行为识别系统的识别精度和泛化能力。
参考文献:
[1] 刘悦,米红.居住环境对老年人跌倒风险的影响分析——基于中国城乡老年人生活状况抽样调查2015年数据 [J].人口与发展,2021,27(3):123-132+109.
[2] 王志灼,谷莉,周谋望.中国老年人跌倒风险因素识别及评估工具应用的研究进展 [J].中国康复医学杂志,2021,36(11):1440-1444.
[3] 高青,陈洪波,冯涛,等.老年人跌倒检测系统的研究现状与发展趋势 [J].医疗卫生装备,2015,36(12):102-105.
[4] 汪大峰,刘勇奎,刘爽,等.视频监控中跌倒行为识别 [J].电子设计工程,2016,24(22):122-126.
[5] 罗海峰,佐研.基于VGG16Net的人体跌倒识别研究 [J].山西电子技术,2022(2):68-70.
[6] 雷亮,尹衍伟,梁明辉,等.基于改进YOLOv5s的老人跌倒识别算法研究 [J].重庆科技学院学报:自然科学版,2023,25(1):85-90.
[7] 韩锟,黄泽帆.基于人体姿态动态特征的跌倒行为识别方法 [J].湖南大学学报:自然科学版,2020,47(12):69-76.
[8] 张程,祝凯,赵德鹏,等.基于人体骨架的跌倒行为识别研究 [J].电子技术与软件工程,2020(23):85-86.
[9] 张涵,欧阳俊斌,郑荣佳,等.基于多特征学习融合级联分类的跌倒识别 [J].华南师范大学学报:自然科学版,2023,55(3):110-118.
[10] 彭玉青,高晴晴,刘楠楠,等.基于多特征融合的跌倒行为识别与研究 [J].数据采集与处理,2016,31(5):890-902.
[11] 程淑红,谢文锐,张典范,等.基于多算法融合的跌倒行为识别 [J].计量学报,2022,43(1):107-113.
[12] WU F. A Realtime Action Detection Frame Work Based on Pytorch Video [EB/OL].(2021-12-27).https://github.com/wufan-tb/yolo_slowfast.
[13] TAUFEEQUE M,KOITA S,SPICHER N,et al. Multi-camera, Multi-person, and Real-time Fall Detection Using Long Short Term Memory [C]//Bildverarbeitung für die Medizin 2021.Regensburg:Springer,2021:124.
[14] PaddlePaddle. PaddleDetection, Object Detection and Instance Segmentation Toolkit based on PaddlePaddle [EB/OL].[2024-06-25].https://github.com/PaddlePaddle/PaddleDetection.
[15] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//Computer Vision amp; Pattern Recognition.Las Vegas:IEEE,2016:779-788.
[16] REDMON J,FARHADI A. YOLO9000: Better, Faster, Stronger [C]//IEEE Conference on Computer Vision amp; Pattern Recognition.Honolulu:IEEE,2017:6517-6525.
[17] REDMON J,FARHADI A. YOLOv3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-08).https://arxiv.org/abs/1804.02767.
[18] BOCHKOVSKIY A,WANG C Y ,LIAO H Y M .YOLOv4: Optimal Speed and Accuracy of Object Detection [J/OL].arXiv:2004.10934 [cs.CV].(2020-04-23).https://arxiv.org/abs/2004.10934.
[19] GE Z,LIU S,WANG F,et al. YOLOX: Exceeding YOLO Series in 2021 [J/OL].arXiv:2107.08430 [cs.CV].(2021-07-18).https: //arxiv.org/abs/2107.08430.
[20] XU S,WANG X,LV W,et al. PP-YOLOE: An Evolved Version of YOLO [J/OL].arXiv:2203.16250 [cs.CV].(2022-05-30).https: //arxiv.org/abs/2203.16250.
[21] LI C Y,LI L L,JIANG H L,et al.YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications [J]. arXiv:2209.02976 [cs.CV].(2022-09-07).DOI:10.48550/arXiv.2209.02976.
[22] WANG C Y ,BOCHKOVSKIY A ,LIAO H Y M .YOLOv7: Trainable Bag-of-freebies Sets New State-of-the-art for Real-time Object Detectors [J/OL].arXiv:2209.02976 [cs.CV].(2022-07-06).https://arxiv.org/abs/2207.02696.
[23] AUVINET E,ROUGIER C,MEUNIER J,et al. Multiple Cameras Fall Dataset [R/OL].(2010-07-08).https://www.researchgate.net/publication/267693256_Multiple_cameras_fall_data_set.
[24] CHARFI I,MITERAN J,DUBOIS J,et al. Optimized Spatio-temporal Descriptors for Real-time Fall Detection: Comparison of Support Vector Machine and Adaboost-based Classification [J/OL].Journal of Electronic Imaging,2013,22(4):041106(2013-07-22).https://doi.org/10.1117/1.JEI.22.4.041106.
[25] LIN T Y,MAIRE M,BELONGIE S,et al. Microsoft COCO: Common Objects in Context [J/OL].arXiv:1405.0312 [cs.CV].(2014-05-01).https://arxiv.org/abs/1405.0312?context=cs.
[26] GOUTTE C,GAUSSIER E. A Probabilistic Interpretation of Precision, Recall and F-Score,with Implication for Evaluation [C]//27th European Conference on IR Research,ECIR 2005.Santiago de Compostela:Springer,2005:345-359.
作者简介:岳丽云(1972—),女,汉族,四川内江人,工程师,硕士研究生,研究方向:图像处理及大数据应用;通信作者:欧剑港(1996—),男,汉族,广东肇庆人,工程师,硕士研究生,研究方向:计算机视觉。