摘" 要:学生课堂行为识别能够有效提升课堂教学效果,是智慧教育不可或缺的一环。鉴于缺乏相关研究数据,文章首先构建了学生课堂行为数据集。在特殊的课堂环境中,学生数量众多且常相互遮挡,后排学生目标体积较小,所以在复杂多变的环境下,难以将学生行为与周围背景区分开来。因此,文章提出一种基于改进YOLOv7目标检测算法的学生行为识别方法(YL7CA),将CA注意力机制嵌入到YOLOv7中,以便更准确地检测学生行为。该方法在自建数据集上获得了92.6%的检测精度,能有效检测出抬头、低头、转头、玩手机、读写、睡觉这六类常见的学生课堂行为。
关键词:YOLOv7;行为识别;注意力机制;目标检测
中图分类号:TP183;TP391.4" 文献标识码:A" 文章编号:2096-4706(2025)04-0069-05
Research on Student Classroom Behavior Recognition Based on the Improved YOLOv7 Algorithm
ZHANG Xiaoni, YANG Mengmeng, ZHANG Junfeng, SU Liping
(Henan Vocational College of Water Conservancy and Environment, Zhengzhou" 450008, China)
Abstract: Student classroom behavior recognition can effectively improve the effect of classroom teaching, which is an indispensable part of smart education. In view of the lack of relevant research data, this paper first constructs a dataset of student classroom behavior. In the special classroom environment, there are a large number of students and they often block each other, and the volume of the rear student target is small. Therefore, in the complex and changeable environment, it is difficult to distinguish the student behavior from the surrounding background. Therefore, this paper proposes a student behavior recognition method based on the improved YOLOv7 object detection algorithm (YL7CA), which embeds CA Attention Mechanism into YOLOv7 to detect student behavior more accurately. This method obtains a detection accuracy of 92.6% on the self-built dataset, and can effectively detect six common types of student classroom behaviors, including looking up, looking down, turning around, playing on mobile phones, reading and writing, and sleeping.
Keywords: YOLOv7; behavior recognition; Attention Mechanism; object detection
0" 引" 言
随着信息技术和人工智能的快速发展,学生课堂行为识别已成为智慧教育[1]的热点之一。课堂行为识别旨在通过计算机视觉技术,对学生在课堂上的各种行为进行自动检测和分类,从而为教师提供实时、客观的反馈,帮助教师更好地了解学生的学习状态和行为习惯,优化教学策略,提升教学质量。然而,传统的课堂行为识别方法往往存在精度不高、响应迟缓等问题,限制了其在现实教育场景中的应用和普及。因此,结合计算机技术研究一种高效、准确的学生课堂行为识别算法,具有重要的理论意义和实践价值[2]。
目前,学生行为识别方法大多基于深度学习技术。黄勇康等人[3]设计了一种基于学生课堂行为的智能教学评估系统,从空间和时间的维度提出了深度时空残差卷积神经网络,并使用该网络学习学生行为的时空特征,最终对学生行为的识别取得了较高的准确率。张小妮等人[4]提出了一种基于YOLOv5目标检测算法的多尺度特征融合的学生行为识别方法,提高了各类行为的识别率。沈西挺等人[5]采用稠密光流的方法处理数据,结合2DCNN、3DCNN和LSTM提取人体动作特征,采用Softmax分类器对捕捉到的人体行为进行分类,其识别率显著提升。姜权晏等人[6]基于骨架行为识别提出多维特征嵌合注意力机制的方法,利用时空建模和通道之间的相对性捕获动作信息,通过嵌合全局特征和局部特征获取多尺度动态信息,得到较好的识别效果。
本文聚焦于学生课堂行为,构建学生课堂行为数据集,克服数据稀缺难题。随后,致力于优化模型设计,强化其捕捉学生行为特征的能力,结合注意力机制,关注更重要的学生行为特征信息,从而构建出一种高效的学生课堂行为识别模型。此模型旨在显著提升行为识别的准确性,为教育评估与个性化教学提供有力支持。
1" 相关技术
1.1" YOLOv7目标检测
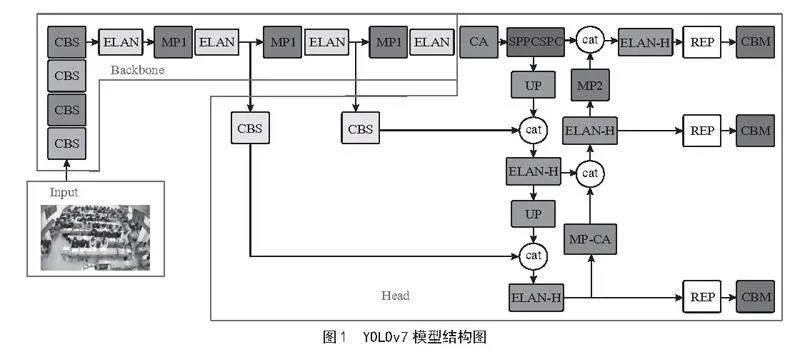
YOLOv7[7]于2022年被提出,是YOLO系列较新的目标检测算法。其在速度、精度以及多尺度检测等方面的优势,使其在各种实际应用场景中都能发挥出色的作用。YOLOv7的结构主要分为输入端、主干网络(Backbone)和头部(Head)三个部分,其模型结构如图1所示。这种结构使YOLOv7能够高效地进行目标检测。YOLOv7还采用了一些创新的策略和技术来提升其性能。例如,它引入了模型重参数化思想,将重参数化引入到网络架构中,以优化模型的性能和训练速度。同时,YOLOv7融合跨网格搜索与YOLOX匹配策略,创新标签分配,优化识别效果。
1.2" 注意力机制
注意力机制模拟人类视觉系统的工作方式,使模型智能筛选信息,重视关键内容而忽略冗余。通过分配注意力权重,引导模型深度挖掘重要细节,从而显著提升处理精度与效率,优化整体性能。
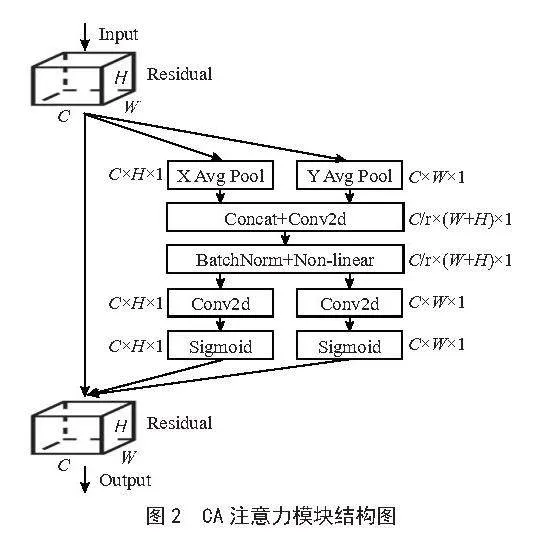
CA(Coordinate Attention)注意力机制[8]是一种深度学习中的创新技术,旨在提升模型对输入数据的空间结构理解。它通过将精确的位置信息编码到神经网络中,使模型能够更好地捕捉输入特征图的空间关系,并强化对通道依赖性的建模。CA注意力机制的关键理念是把通道的注意力分解为两个1D特征编码过程,按照两个不同的空间方向聚合特征,从而有效整合空间坐标信息到生成的注意力图中。通过这种方式,模型可以更加关注关键区域,提高特征表示能力,进而提升目标检测、图像分类等任务的性能。CA注意力模块如图2所示。
教室环境具有较强的复杂性,背景复杂、遮挡严重、小目标占比高,不同行为之间存在相似性和差异性,使得YOLOv7检测识别学生课堂行为的能力有限。由于YOLOv7的网格划分策略,小目标的特征信息容易被背景噪声淹没,导致检测不稳定甚至漏检。CA注意力机制可以帮助模型更好地理解输入数据的关联性和重要性,从而提高模型的性能。通过加权处理输入数据,模型能够更精准地关注与当前任务相关的信息。将CA注意力机制引入YOLOv7可以弥补其在复杂背景下对小目标检测的不足,进一步提升模型的整体性能和适用性。
2" 基于注意力机制的学生课堂行为识别
2.1" 学生课堂行为数据集
目前并无可用的学生课堂行为公开数据集。本文通过参考经典行为数据集及他人对学生课堂行为的研究[9-10],构建了一个适用于教学场景目标和学生课堂行为研究的数据集。
1)数据采集。数据源自真实课堂环境,全面覆盖了不同学生在各类课程中的行为状态变迁。通过考虑人数、学科及教室布局的差异,实施多次拍摄,旨在广泛捕捉学生行为的多样性。同时,针对人数密度、遮挡程度及拍摄时段的变化,进行重复数据采集,确保样本的丰富性与代表性,从而更加精准地反映学生课堂行为的全貌。
2)数据处理。处理学生行为数据时,精选高质量图像以表征典型行为。鉴于行为连续性,相邻帧差异细微,故采取每5秒一帧的采样策略,减少冗余,确保图像样本的多样性和代表性。然后清洗数据,去除已损坏图像、模糊图像以及相似图像。
3)数据标注。将学生行为划分为raise_head(抬头)、bow_head(低头)、turn_head(转头)、play_phone(玩手机)、read_write(读写)、sleep(睡觉)。按照各类行为的标准,使用图像标注工具LabelImg对课堂图像进行标注。
该数据集共包含1 903张课堂图像,并按照3:1:1 的比例划分训练集、验证集和测试集,分别包含1 146张、379张、378张图像。其中,训练集用于训练模型,以拟合数据特征;验证集用于优化模型配置,包括调整超参数,并快速反馈训练过程中的潜在问题;而测试集独立存在,专门用于评估训练完成的模型在未见数据上的泛化效果。
2.2" 实验环境
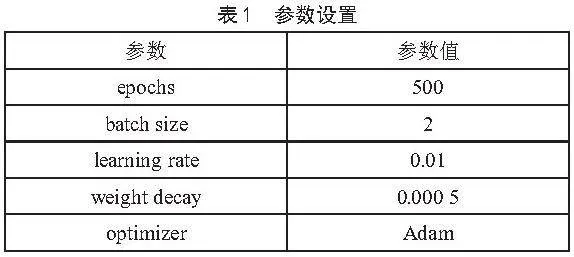
实验过程中,严格控制实验条件,确保所有对比实验均在相同参数设置下进行,以消除外部变量对结果的干扰。所有实验依托Windows 10操作系统,以Python 3.9作为编程语言,框架技术为PyTorch,加速环境为CUDA 11.3,GPU为NVIDIA GeForce RTX 3060,显存大小为6 GB。模型参数如表1所示。
2.3" 评价指标
目标检测任务中,常用准确率(Accuracy)、精确率(Precision)、查全率(Recall)、F1分数(F1-score)、AP(Average Precision)、mAP(mean Average Precision)等作为评价指标。其中,AP是不同Recall下Precision的均值,能够有效评价模型对数据集中每一类的检测效果;mAP则是AP的平均值,用于评估模型在图像中识别和定位特定类别对象的能力。AP是针对单一类别计算得出,而mAP是所有类别AP的平均值。mAP值越高,表明模型在所有类别上的平均性能越好,本文采用mAP作为主要评价指标。
2.4" 实验结果和分析
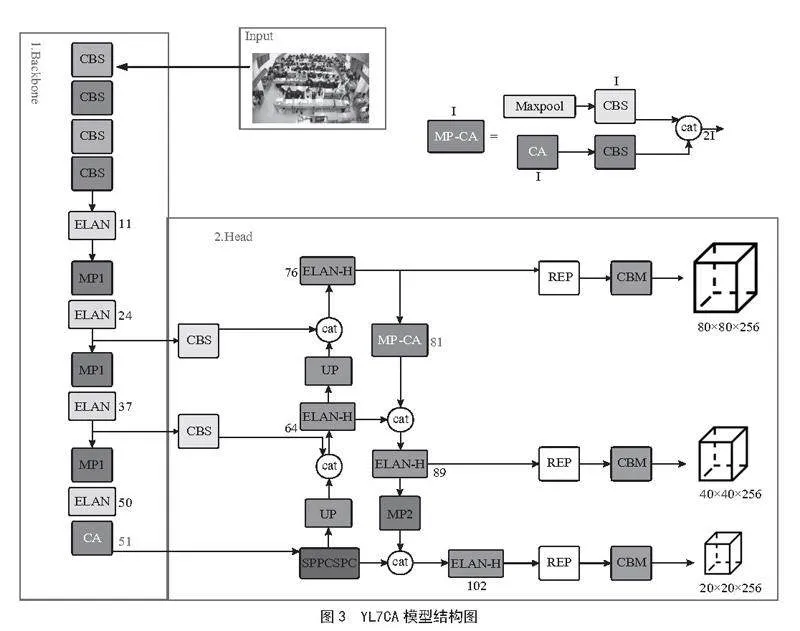
本文将CA注意力模块与目标检测模型YOLOv7相结合,构建了新的学生行为识别模型——YL7CA。该模型充分利用YOLOv7快速检测的特点与优势,在保证对学生行为进行实时检测的同时,进一步提升了模型对学生行为重要特征的关注度,增强了模型在复杂环境下提取目标特征的能力。此外,CA注意力模块通过捕获长距离依赖性和有效整合空间坐标信息,增强了特征表示能力,提高了模型对关键信息的敏感度,能够捕捉到学生行为中的细微差异和变化,从而提升了学生课堂行为识别的准确性和效率。YL7CA模型结构如图3所示。
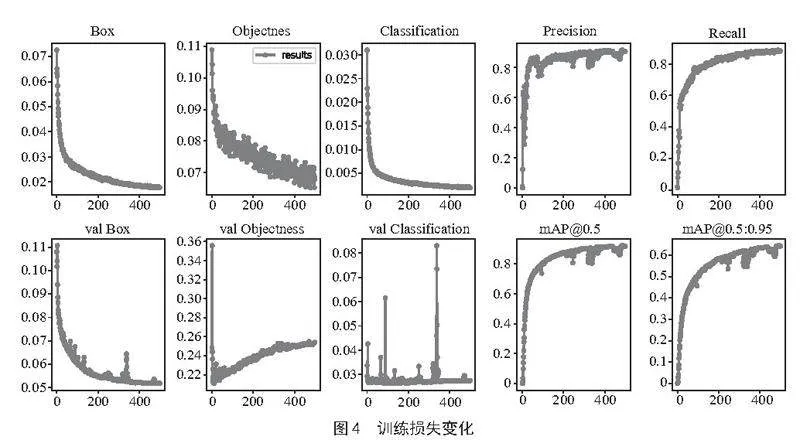
为使模型充分学习学生课堂的各类行为特征,以适应复杂多变的课堂环境,在模型训练阶段,将训练迭代次数设置为500次。图4直观展示了引入CA注意力模块后,模型训练过程中几个关键性能指标的变化趋势。
随着训练迭代的不断推进,边框回归损失(Bounding Box Regression Loss)显著下降,这意味着模型在逐步优化其预测边界框与目标真实边界框之间的匹配程度,使预测结果更加精准。同时,定位损失(Objectness Loss)也呈稳步减少趋势,反映出模型区分和定位不同课堂行为区域的能力在不断增强。分类损失(Classification Loss)同样显著下降,标志着模型识别不同类别课堂行为的性能在持续改善。
综上所述,图4所示的模型损失变化趋势,不仅验证了CA注意力模块在提升学生课堂行为识别模型性能方面的有效性,还表明通过增加训练迭代次数、优化模型结构等方式,可以显著提升模型的学习能力和泛化能力。
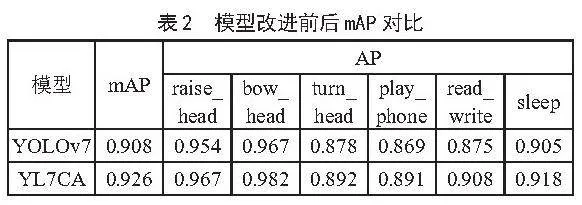
本文深入探究了模型优化后对学生课堂行为识别精度的提升效果,尤其是在多样化教室环境背景下,优化后的模型对学生课堂行为识别的影响。系统评估了YOLOv7和YL7CA两种模型在不同课堂场景下的行为识别性能,模型改进前后的实验结果如表2所示。
由表2可知,原模型YOLOv7对raise_head、bow_head、turn_head、play_phone、read_write、sleep的检测精度分别为95.4%、96.7%、87.8%、86.9%、87.5%和90.5%;YL7CA对这六类学生课堂行为的检测精度分别为96.7%、98.2%、89.2%、89.1%、90.8%和91.8%,YL7CA对每类学生课堂行为的检测效果均优于YOLOv7。
从实验结果来看,添加CA注意力模块的YL7CA模型检测效果更佳。YOLOv7的检测精度为90.8%,YL7CA的检测精度达到92.6%,其平均精度比原模型高出1.8%,且对各类学生课堂行为的检测效果均有提升,其中,bow_head、play_phone、read_write的精度分别提升1.5%、2.2%、3.3%。由此可见,YL7CA模型能够有效检测学生在课堂上的各类行为,验证了CA注意力机制在处理复杂背景噪声、增强特征表达能力方面的有效性,在提升学生课堂行为识别任务中具有显著成效。
3" 结" 论
本文首先构建了相关数据集,解决了数据难题;其次,在YOLOv7的基础上提出了新的学生课堂行为识别模型——YL7CA。该模型融合了CA注意力模块,探究了注意力机制在复杂环境下提升学生课堂行为识别精度的有效性。实验结果表明,YL7CA对学生课堂行为的识别效果最优,与YOLOv7相比,mAP提升1.8%,且对各类学生课堂行为的检测效果均有提升。
参考文献:
[1] 中共中央国务院印发《中国教育现代化2035》 [N].人民日报,2019-02-24(001).
[2] 舒杭,顾小清.数智时代的教育数字化转型:基于社会变迁和组织变革的视角 [J].远程教育杂志,2023,41(2):25-35.
[3] 黄勇康,梁美玉,王笑笑,等.基于深度时空残差卷积神经网络的课堂教学视频中多人课堂行为识别 [J].计算机应用,2022,42(3):736-742.
[4] 张小妮,张真真.基于YOLOv5和多尺度特征融合的学生行为研究 [J].现代信息科技,2023,7(8):96-98+102.
[5] 沈西挺,于晟,董瑶,等.基于深度学习的人体动作识别方法 [J].计算机工程与设计,2020,41(4):1153-1157.
[6] 姜权晏,吴小俊,徐天阳.用于骨架行为识别的多维特征嵌合注意力机制 [J].中国图象图形学报,2022,27(8):2391-2403.
[7] WANG C Y,BOCHKOVSKIY A,LIAO H Y M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors [J/OL].arXiv:2207.02696 [cs.CV].[2024-07-25].https://arxiv.org/abs/2207.02696.
[8] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attention for Efficient Mobile Network Design [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:13708-13717.
[9] 白捷,高海力,王永众,等.基于多路特征融合的Faster R-CNN与迁移学习的学生课堂行为检测 [J].广西师范大学学报:自然科学版,2020,38(5):1-11.
[10] 张小妮.基于深度学习的课堂环境下学生行为检测与分析 [D].郑州:华北水利水电大学,2023.
作者简介:张小妮(1996-),女,汉族,河南周口人,硕士研究生,研究方向:大数据与云计算。
收稿日期:2024-08-16
基金项目:河南省科技攻关(242102211054)