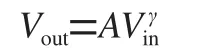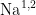
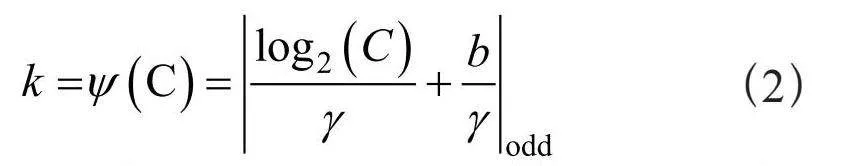

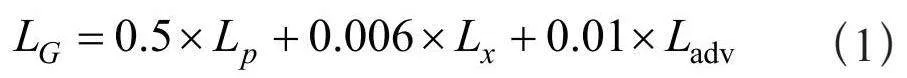

摘 要:为解决汽车运动过快产生模糊导致车牌识别算法失效的问题,对深度学习的生成对抗网络去模糊方法进行了研究,提出了一种基于生成对抗网络的模糊车牌图像复原方法。主要思路为使用图像复原网络NAFNet中的NAFBlock替换DeblurGAN-v2生成器中的基本卷积块,并在特征提取网络中加入了高效通道注意力机制。对于原模型和修改后的模型,设计了四组不同模型消融实验。实验结果表明,提出方法在复原模糊车辆图像复原任务数据上,峰值信噪比为21.262 4,结构相似度为0.643 1,较好地解决了模糊车牌复原的问题。
关键词:运动模糊;图像处理;生成对抗网络;图像复原
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)20-0153-06
A Method for Restoring Motion-Blurred License Plate Images Based on Generative Adversarial Network
ZHA Anqin, Yang Bin
(Software Engineering Institute of Guangzhou, Guangzhou 510990, China)
Abstract: To solve the problem of license plate recognition algorithms failing due to blurriness caused by fast-moving vehicles, this paper studies the Generative Adversarial Network deblurring method of Deep Learning, and proposes a fuzzy license plate image restoration method based on Generative Adversarial Network. The main idea is to use the NAFBlock in the image restoration network NAFNet to replace the basic convolution block in the DeblurGAN-v2 generator, and an Efficient Channel Attention mechanism is added to the feature extraction network. For the original model and the modified model, four groups of different model ablation experiments are designed. The experiment results show that the proposed method has a peak signal-to-noise ratio of 21.262 4 and a structural similarity index of 0.643 1 on the task data of restoring blurred vehicle image restoration, which better solves the problem of blurred license plate restoration.
Keywords: motion blur; image processing; Generative Adversarial Network; image restoration
0 引 言
车牌识别是一项计算机视觉领域的任务,旨在指定的图像上自动识别和提取车辆上的车牌号码。在车牌识别任务中,由于摄像机抖动,车速过快等因素导致车辆图像产生运动模糊,从而影响识别算法的性能。近年来,随着神经网络版本的迭代,从清晰图像中识别出车牌号码的准确率已经大大提高。但在模糊图像上,传统的识别算法和现有的神经网络模型往往表现不佳,难以达到令人满意的效果。因此,使用生成对抗网络去除运动模糊,对提升识别算法模型准确率有着一定的潜力。
在图像产生模糊时,模糊模型可被建模为模糊图像与模糊核的卷积过程。模糊核已知时,去模糊任务被称为非盲去模糊,模糊核未知时,去模糊任务被称为盲去模糊。现实场景下的大多数去模糊场景属于后者。现有的模糊图像复原方法分为传统的去模糊方法和基于神经网络的去模糊方法,传统方法在去模糊的研究重点在于先估计模糊核,再将问题转变为非盲图像去模糊问题。然而,传统方法更适用于均匀模糊,对于物体运动模糊环境下的非均匀模糊效果不佳[1]。近年来,基于深度学习的去模糊方法涌现迅速,基于深度学习的去模糊方法能更好地捕捉到图像中的复杂特征,且具有高效的非线性表示能力,对于去模糊任务有着一定的泛化能力。常见基于深度学习的去模糊方法有基于卷积神经网络的去模糊方法,基于循环神经网络的去模糊方法以及基于生成对抗网络的去模糊方法。其中,生成对抗网络拥有着较强的功能与优势,对图像修复的研究起到了巨大的推荐作用。生成对抗网络最早由Goodfellow等[2]提出,从此生成对抗网络的基本主体结构,以及博弈训练的思想被确立下来。早期的生成对抗网络在训练时会出现诸多问题,如稳定性和收敛性难以保证,或者出现模式崩溃与模式崩塌的问题。对生成的样本也无法随机调控。为了解决这一问题,许多生成对抗网络的变体被提出,如深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network, DCGAN),条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)和Wasserstein生成对抗网络等,这些网络将生成对抗网络生成样本难以控制和容易出现模式崩溃和模式崩塌的问题一一避免[3]。2018年,Kupyn等[4]提出了用于去模糊的生成对抗网络Deblur-GAN,其生成器中包含两个步幅为1/2的卷积块,9个残差块以及2个转置卷积块,并在模型中引入了全局跳跃连接,使得训练过程更快,模型的泛化性更好。但存在着只修复了局部模糊,而未修复全局模糊的情况。随后,Gong等[5]提出了将图像的清晰部分与模糊部分分开,并利用清晰部分知道模糊部分的复原过程,优化了图像局部去模糊的清晰度,但依旧存在着模型只修复局部模糊的问题。Zhang等[6]提出了训练两个生成对抗网络模型,使用学习模糊的BGAN(leaning-to-Blur GAN)和学习去模糊的DBGAN(learning-to-DeBlur GAN)来解决合成模糊图像不能充分模拟现实场景中模糊过程问题。但使用两个GAN也让图像的复原速度较慢。Zhao等[7]提出了一种轻量级域转换单元和无参数频域对比单元,解决了GAN修复模糊图像速度慢的问题。但其网络FCL-GAN(Termed Frequency-domain Contrastive Loss Constrained Lightweight CycleGAN)对带有纹理内容的运动模糊复原效果较差。
本文在参考以上网络实现思路的基础上,尝试使用了DeblurGAN-v2算法对运动模糊车牌进行图像复原,然而其复原效果不是很好。结合近期较常使用的模型改进思路。提出了一种基于生成对抗网络DeblurGAN-v2的改进架构,改进后的DeblurGAN-v2的去模糊效果有明显提升,在一定程度上解决了运动模糊车牌图像复原问题。
1 网络设计
1.1 生成对抗网络工作原理
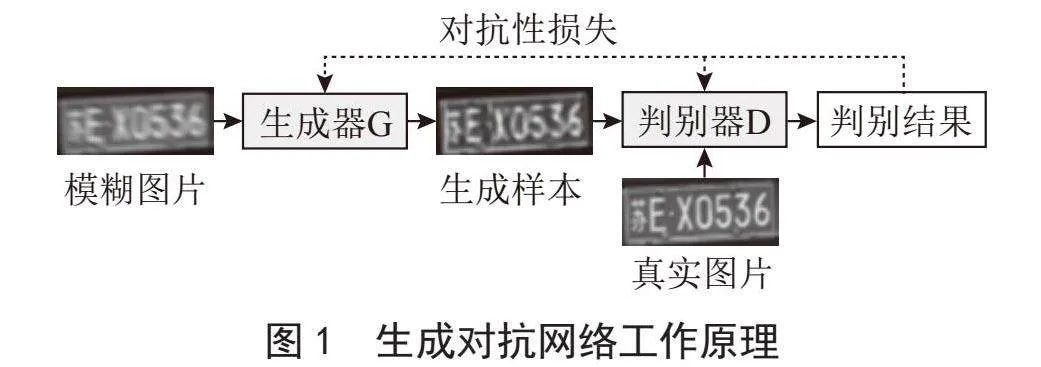
本文使用了生成对抗网络进行运动模糊图像复原任务,生成对抗网络由生成器G和判别器D组成。生成器用于接收模糊图片,提取模糊图片的语义特征来生成清晰图片样本,以欺骗判别器。而判别器的任务为区分输入图像来源于真实图像还是来源于生成器生成的虚假清晰图像,判别器得到的损失为对抗性损失,该损失被用于直接训练判别器,以提高其判别能力。此外,判别器的损失也会被用于计算生成器的损失,通过这种方式来间接训练生成器。经过多次训练迭代后,生成器生成的数据会越来越趋近真实图像,而判别器的辨别能力也会增强。理论上,生成器与判别器最终会达到纳什均衡状态,此时生成器的生成图像已经跟真实的清晰图像没有差别,无法被判别器轻易区分[2]。生成对抗网络的原理如图1所示。
1.2 主体网络DeblurGAN-v2架构
1.2.1 生成器
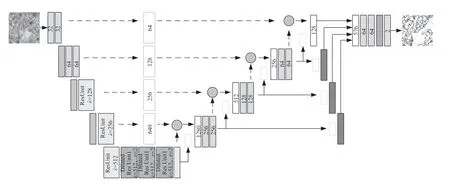
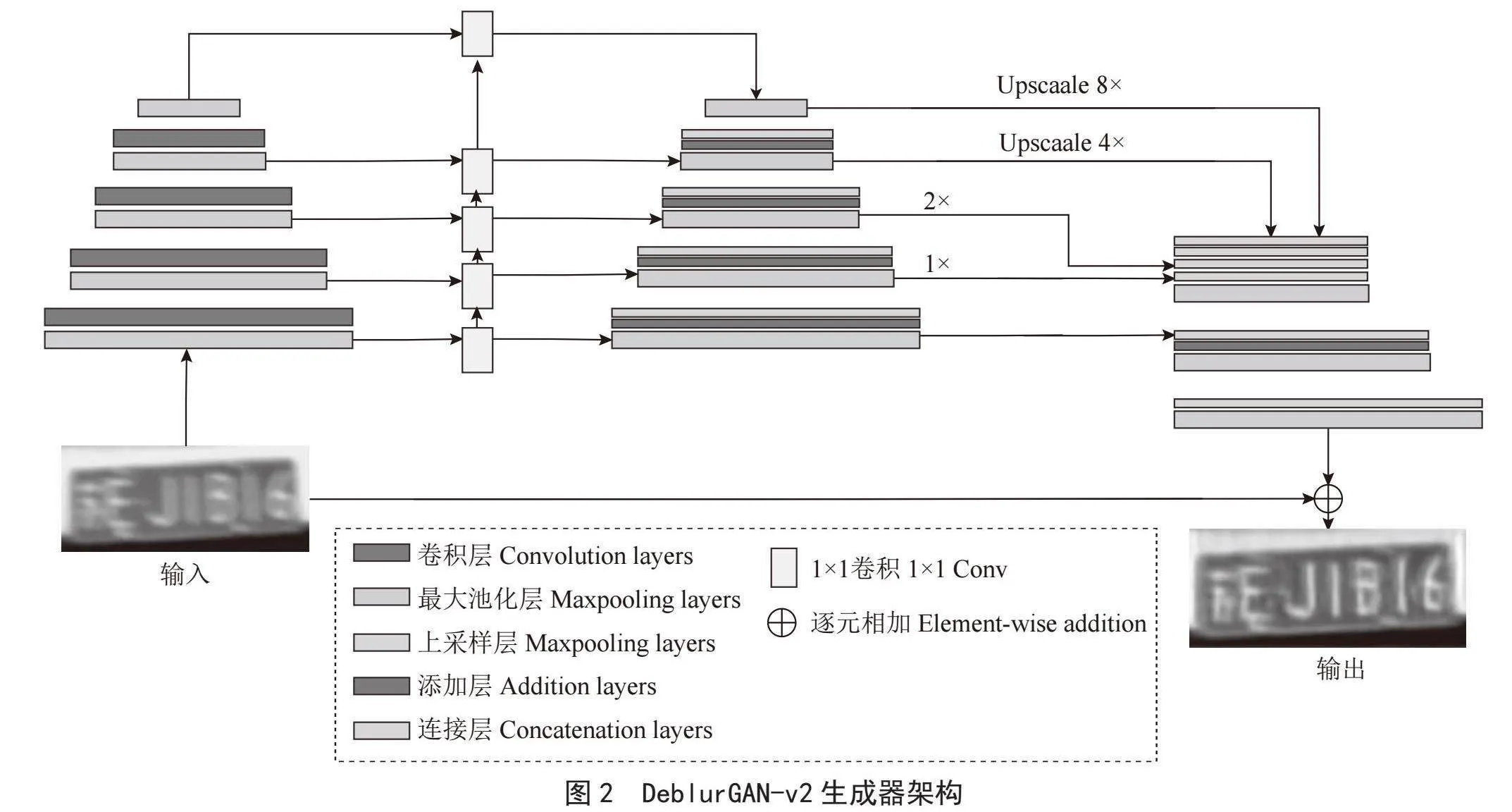
如图2所示,DeblurGAN-v2的生成器使用了原本用于目标检测的特征金字塔网络(Feature Pyramid Network, FPN)来进行特征融合,FPN包含一个自下而上的特征提取网络和一个自上而下的特征重建网络。特征提取网络由卷积层和池化层组合而成,用于接收模糊图像并压缩图像的语义信息。对于特征提取主干网络,DeblurGAN-v2提供了三个选择,Inception-ResNet-v2、MobileNetV2和MobileNet-DSC。
Inception-ResNet-v2作为模型框架效果最好,但相对的参数量较大。MobileNetV2较为轻量,适用于移动设备,而MobileNet-DSC在MobileNetV2的基础上进一步简化,将所有常规卷积层替换为深度可分离卷积层,参数量较小,训练时间较短,但效果不如Inception-ResNet-v2。为了获得更好的实验结果,本文选用了Inception-ResNet-v2作为主干网络。
Inception-ResNet-v2是一个结合了InceptionV3和ResNet网络优点的混合型卷积神经网络架构。该架构使用多尺度处理来捕捉图像的各种特征,每个模块中存在并行的卷积层,能够并行处理数据,并将结果合并至下一层。这样做能在增加网络表示能力和特征提取能力的同时,确保模型不会因为过深而产生梯度消失或过拟合,产生的代价是网络的运算量会不可避免地增大。为了降低运算量,Inception-ResNet-v2的每个模块间都插入了1×1的卷积块进行降维。此外,ResNet中的残差连接也使得梯度更容易反向传播,从而加快了网络的收敛速度,提高了网络的训练效率。
DeblurGAN-v2的特征重建网络由池化层,添加层和上采样层组成。负责对特征提取网络提取出来的图像语义信息进行重建与复原。两个网络间通过一个1×1的卷积块连接,这使得提取出的每层图像特征细节都得以在重建中被使用。特征重建网络的最终输出为五个不同尺寸的特征图,这些特征图会被统一转换为原图1/4大小,并串联成一个张量,代表着不同层次的语义信息。合成后的张量经过上采样和卷积层处理,恢复成原图大小,从而得到生成的清晰图片。
1.2.2 判别器
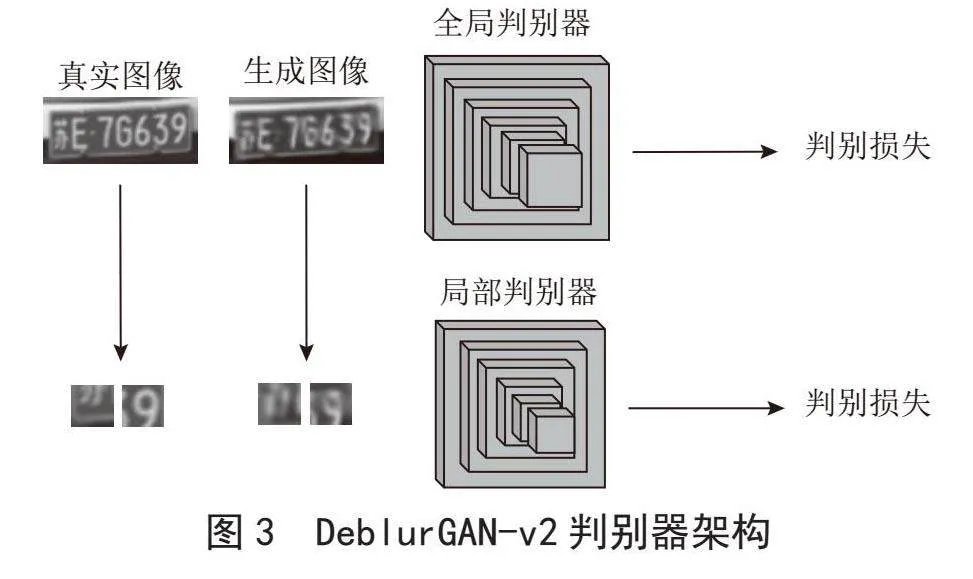
与早期生成对抗网络的标准架构不同,图3所示的DeblurGAN-v2使用了全局判别器和局部判别器两个判别器来判断图片是否由生成器生成。全局判别器用于评估完整的图像,其拥有更大的感受野,能够理解图片的全局上下文信息,用于保证图像整体的结构的合理性,例如图像的布局,几何形状等,以增强生成图像与真实图像的结构相似度。而局部的判别器用于接收被随机裁切后的图像小块,相比全局判别器更加关注小尺度特征的真实性,如图像的局部细节与纹理。通过同时使用全局判别器与局部判别器,DeblurGAN-v2能在不同的尺度下提升生成图像的质量,不仅在宏观上保证了生成图像的结构合理,也在微观上保持了生成图像的细节。全局判别器与局部判别器在对图像进行判别时输出的对抗性损失,被整合进DeblurGAN-v2的生成器损失函数用于训练。DeblurGAN-v2 判别器架构如图3所示。
1.2.3 损失函数
DeblurGAN-v2所使用的损失函数如式(1)所示:
(1)
其中Ladv包含了全局判别器和局部判别器的损失,Lp为使用均方误差(Mean Square Error,MSE)计算的像素空间损失,即直接在原始图像和生成器生成的重建图像的像素层面计算它们差异平方的平均值,用于评估生成图像与目标图像之间的差异。Lx为感知损失,其通过将生成图像与模糊图像放入预训练的深度卷积神经网络模型VGG19(Visual Geometry Group 19-layer Network),提取特征映射后计算特征得出,负责捕捉图像更高层次的语义信息,比如物体的结构特征,从而生成更逼真、更具细节的图像[8]。相比起像素空间损失,感知损失更注重于图像的感官质量,确保生成的图像在视觉上更为自然。这种多重损失函数的设计,使得DeblurGAN-v2能够在不同层次上优化生成图像的质量,使其在模糊图像复原任务中的性能提升。
1.3 基于DeblurGAN-v2网络架构的改进
1.3.1 使用NAFBlock替换常规卷积块
在DeblurGAN-v2的生成器中,部分特征图的提取由常规卷积块进行,这些常规卷积块包含一个二维卷积层,一个归一化层和一个ReLU激活函数。这样的卷积块的设计较为简单,可能无法应对实际应用中的复杂场景。为了优化生成器的性能,本文考虑了加入近年来在图像处理中应用较为广泛的先进技术,如残差连接或注意力机制,来替换这些常规的卷积块,以提升特征的重用性和传递性,并增强特征的表达能力,从而捕捉到更加细致和有意义的图像信息。
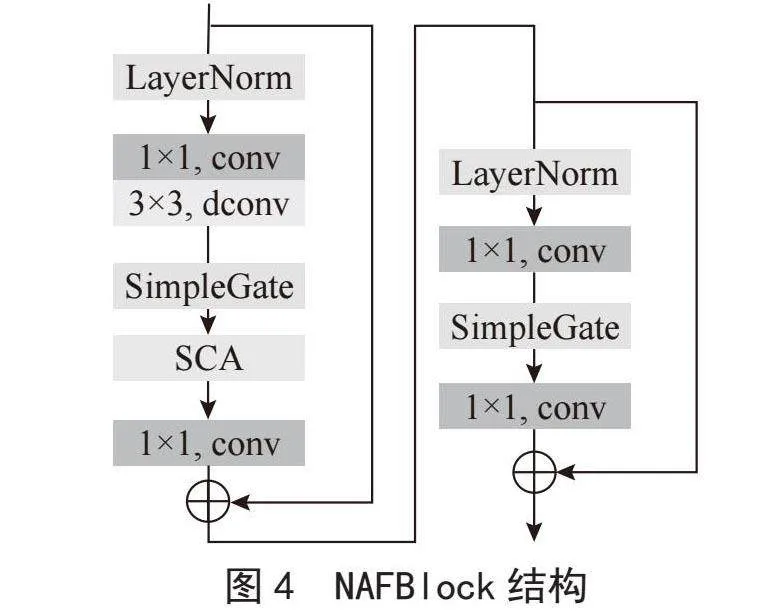
本文借鉴了NAFNet(Nonlinear Activation Free Network)[9]网络架构,使用了NAFNet中的核心结构NAFBlock替代了DeblurGAN-v2中的常规卷积块,以增强神经网络对模糊图像特征的提取能力。NAFNet是一种用于图像恢复任务的神经网络结构,其设计重点在于简化其他在图像恢复领域上表现优异的模型,同时保持或提升这些模型的性能。NAFNet采用了经典包含跳跃连接的单段U形架构,从而简化了块间复杂性,并替换掉了块内的非线性激活函数,降低了块内复杂性。NAFNet在拥有低块间复杂性和低块内复杂性的同时,保持着较高的图像复原水平。NAFBlock是NAFNet的核心组成部分,其内部包含归一层,卷积层,深度可分离卷积层(Depth-wise Convolution),由逐元素相乘法实现的SimpleGate,以及简化过后的通道注意力机制。NAFBlock的结构如图4所示。
与DeblurGAN-v2原有的常规卷积块相比,NAFBlock包含以下两点优势:第一,NAFBlock中相对原有的卷积块引入了残差边,当训练过程中发生了梯度消失,或神经网络层训练效果不佳时,残差边可将前一层提取的特征直接传递到下一层,忽略发生梯度消失的神经网络层,使得网络训练更加顺畅。同时,由于跳跃连接的存在,原始的输入的特征可以直接传递到后续层次,保持了特征的完整性。虽然残差边的存在会额外增加一些运算量,但主要的运算仍然集中在卷积层,因此残差边的存在并未显著增加计算复杂度。第二,NAFBlock引入了深度可分离卷积,并且整个块中没有非线性激活函数,减少了相应的参数,降低了模型的存储需求以及过拟合的风险,同时保持了卷积的表达能力。
综上所述,本文通过在DeblurGAN-v2中引入NAFNet的NAFBlock,不仅提升了网络的训练效率,还在保持高复原水平的同时,简化了模型结构。这种改进有助于在实际应用中更有效地处理模糊图像,提高图像恢复的整体性能。
1.3.2 高效通道注意力机制
注意力机制是一种模拟人类在处理大量信息时专注于其中某些重要部分的技术,也是近期深度学习的核心组件之一,该机制的主要思想是让模型在提取特征时,不必平均地关注所有信息,而是根据当前任务的需要,对重要的信息给予更多关注。注意力机制已在许多图像复原的模型中被广泛应用,并被证实其有效性。为使神经网络在提取特征时更关注图像的细节特征,本文在DeblurGAN-v2的特征提取网络中插入了高效通道注意力机制来改进DeblurGAN-v2。
高效通道注意力机制(Efficient Channel Attention, ECA)是基于经典通道注意力网络(Squeeze-and-Excitation Networks, SENet)改进而成的注意力机制,SENet主要通过压缩(Squeeze)和激励(Excitation)来提升重要特征的表达能力。压缩操作通过全局平均池化(Global Average Pooling)将每个通道的特征图压缩成一个单独的标量,这相当于对每个通道信息的全局总结。这一步骤的特征图会由H×W×C降维为一个1×1×C的向量。激励操作则通过两个全连接层,将每个通道的权重进行重新校准,在这个过程中,输入的C维向量在第一个全连接层根据缩减比例r被降维到C/r维,再在第二个全连接层扩展至C维。经过这一步骤,对于当前任务重要的特征得以被凸显出来,不重要的特征被抑制下去。最后,这些权重系数与原始特征图的每个通道相乘,来对原始特征图的每个通道的重要性进行重新校准。尽管SENet提升了许多计算机视觉相关的网络模型,然而两个全连接层使得计算量较大,在其间发生的降维操作可能会使得网络无法完全捕捉通道间的重要信息[10]。
为了克服这些局限性,高效通道注意力机制主要针对SENet的显著降维操作进行了改进,在得到一个1×1×C的向量后,ECA使用了一个带有自适应核大小的1×1卷积来直接捕获通道间的交互关系。其通过一个一维的卷积层来实现通道注意力,避免了维度减少步骤带来的复杂度和信息丢失问题,以及降低了计算复杂度。ECA的卷积核大小取决于通道数C,具体公式如式(2)所示:
(2)
其中,todd说明k的值只能取奇数。b与γ为参数,可以在程序中自行定义,本文沿用了高效注意力机制原论文[10]的取值,设定γ为1,b为2。
通过在DeblurGAN-v2中引入ECA机制,模型在处理模糊图像复原任务时,能够更好地关注到图像的细节特征,从而生成更加清晰,更加真实的图像。ECA不仅在计算上的效率更高,在保留通道间的信息方面表现优异,为图像复原任务提供了有力支持。
2 实验分析
2.1 实验数据
本实验的数据源自混合互联网上分享的车牌数据集,对于部分只有清晰图像的车牌,通过运动模糊核在原图上进行卷积运算来退化原清晰图像,使得清晰图像变为运动模糊图像,并与原本的清晰图像组成图片对,所使用的图像的退化模型如式(3)所示:
(3)
其中g(x,y)为退化后的运动模糊图像,f(x,y)为清晰图像,h(x,y)为卷积核,*为卷积操作,为图像加入运动模糊的过程中,没有加入噪声。本文使用了3 000个车牌的清晰/模糊图片对,共6 000张图像。并抽取其中的2 700对图片用作训练集,剩下的300对图像对用作测试集。
2.2 实验配置
本文在深度学习云环境中进行了模型训练与测试,在基于Ubuntu 22.04,Python 3.10和PyTorch 2.1.2的环境下编写代码运行实验。所用的CPU型号为Xeon(R) Platinum 8255C,并通过显存为11 GB的RTX 2080 Ti显卡进行加速训练,加速训练所使用的CUDA版本为11.8。训练轮数为200,使用的优化器为Adam,学习率为0.001。
2.3 实验结果与评价
本文使用了常规的峰值信噪比PSNR和结构相似性SSIM来评价算法。PSNR是衡量图像质量的标准指标,用于评估生成器生成图像与真实图像之间的相似程度。PSNR越高,说明模型生成器生成的图像与原始图像差异越小,这意味着生成器生成的去模糊效果较好。
本文使用的PSNR计算式如式(4)所示:
(4)
其中,MSE为原始图像I与重建图像的均方误差,其计算式如式(5)所示:
(5)
由于PSNR只考虑了生成图像与原图像相似间的差异,未考虑人眼对图像结构内容的感知,因此本文同时使用了结构相似性SSIM来计算相似度。SSIM的计算式如式(6)所示:
(6)
式(6)中的,,分别为生成器的重建图像与原本真实图像的亮度差异,对比度差异以及结构差异。
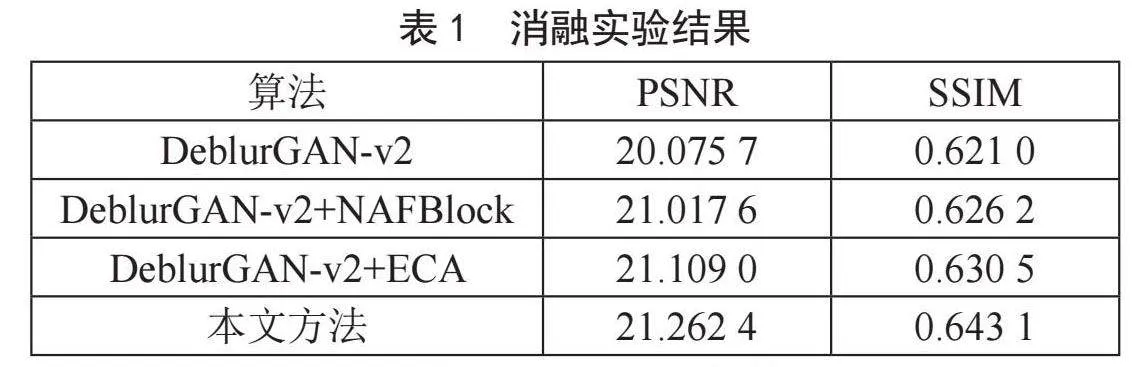
本文基于在DeblurGAN-v2上的两个改进策略,设计了四组不同模型消融实验,并取得每次训练在测试集上PSNR与SSIM得分最高的模型作为最终模型。实验结果如表1所示。
由表1可知,将常规卷积块替换成NAFBlock后的神经网络模型的PSNR比基准网络DeblurGAN-v2高出4.2%,SSIM高出了0.8%,说明了NAFBlock加强了生成器的特征图提取能力,另一方面,在特征提取网络中加入高效通道注意力机制使得PSNR增加了5.1%,SSIM增加了1.5%,说明高效通道注意力机制增强了生成器对模糊图像细节特征的提取能力。当两种方法结合时,网络的性能得到了进一步的提升,所得出的最终模型PSNR比原本提高了5.9%,SSIM比原本提高了3.6%,说明了本文方法的有效性。除此之外,在训练过程中,原本的DeblurGAN-v2模型每个Epoch的平均训练时长为3分16秒,而改进后的DeblurGAN-v2模型每个epoch的平均训练时长为3分28秒,说明模型的计算复杂度并未显著增加。
本文选取了测试集中的300张模糊车牌图像进行复原,使用DeblurGAN-v2以及改进后的DeblurGAN-v2的复原图像对比如图5所示。由对比结果可知,改进后的DeblurGAN-v2算法相较于原算法,复原图像的质量相较于原算法更高。
3 结 论
针对现实场景中的车牌运动模糊,导致识别算法失效的问题,本文提出了一种基于改进DeblurGAN-v2的图像复原模型,并通过实验与基准模型进行了对比分析,验证了改进算法的有效性。通过将特征图提取的普通卷积块替换成NAFBlock,以及在特征提取网络中加入ECA高效通道注意力机制,提升了DeblurGAN-v2生成器的特征提取能力,较好地解决了运动模糊车牌复原的问题,为现实场景中运动模糊的车牌图像复原提供了有效手段。为满足现实中模糊车牌的鉴别问题,未来进一步需将本模型与其他车牌识别算法进行整合,进行端对端的训练,以进一步增强模型的实用性。
参考文献:
[1]胡张颖,周全,陈明举,等.图像去模糊研究综述 [J].中国图象图形学报,2024,29(4):841-861.
[2] GOODFELLOW I,POUGET-ABADIE J,MIRZA M,et al. Generative Adversarial Nets [C]//Proceedings of the 27th International Conference on Neural Information Processing Systems.Cambridge:MIT Press,2014:2672-2680.
[3] 龚颖,许文韬,赵策,等.生成对抗网络在图像修复中的应用综述 [J].计算机科学与探索,2024,18(3):553-573.
[4] KUPYN O,BUDZAN V,MYKHAILYCH M,et al. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks [C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8183-8192.
[5] GONG G,ZHANG K. Local Blurred Natural Image Restoration based on Self-Reference Deblurring Generative Adversarial Networks [C]//Proceedings of the 2019 IEEE International Conference on Signal and Image Processing Applications. Piscataway:IEEE,2019:231-235.
[6] ZHANG K,LUO W,ZHONG Y,et al. Deblurring by Realistic Blurring [C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle.Piscataway:IEEE,2020:2737-2746.
[7] ZHAO S,ZHANG Z,HONG R,et al. FCL-GAN: A Lightweight and Real-time Baseline for Unsupervised Blind Image Deblurring [C]//Proceedings of the 30th ACM International Conference on Multimedia.New York:ACM,2022:6220-6229.
[8] KUPYN O,MARTYNIUK T,WU J,et al. DeblurGAN-v2: Deblurring (Orders-of-magnitude) Faster and Better [C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:8877-8886.
[9] CHEN L,CHU X,ZHANG X,et al. Simple Baselines for Image Restoration [C]//European Conference on Computer Vision. Cham:Springer Nature Switzerland,2022:17-33.
[10] WANG Q,WU B,ZHU P,et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks [C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New York:IEEE,2020:11534-11542.
作者简介:查安秦(1997—),男,汉族,广东肇庆人,助教,硕士,研究方向:深度学习;杨斌(1985—),男,汉族,湖北孝感人,助教,硕士,研究方向:智能制造、计算机应用。