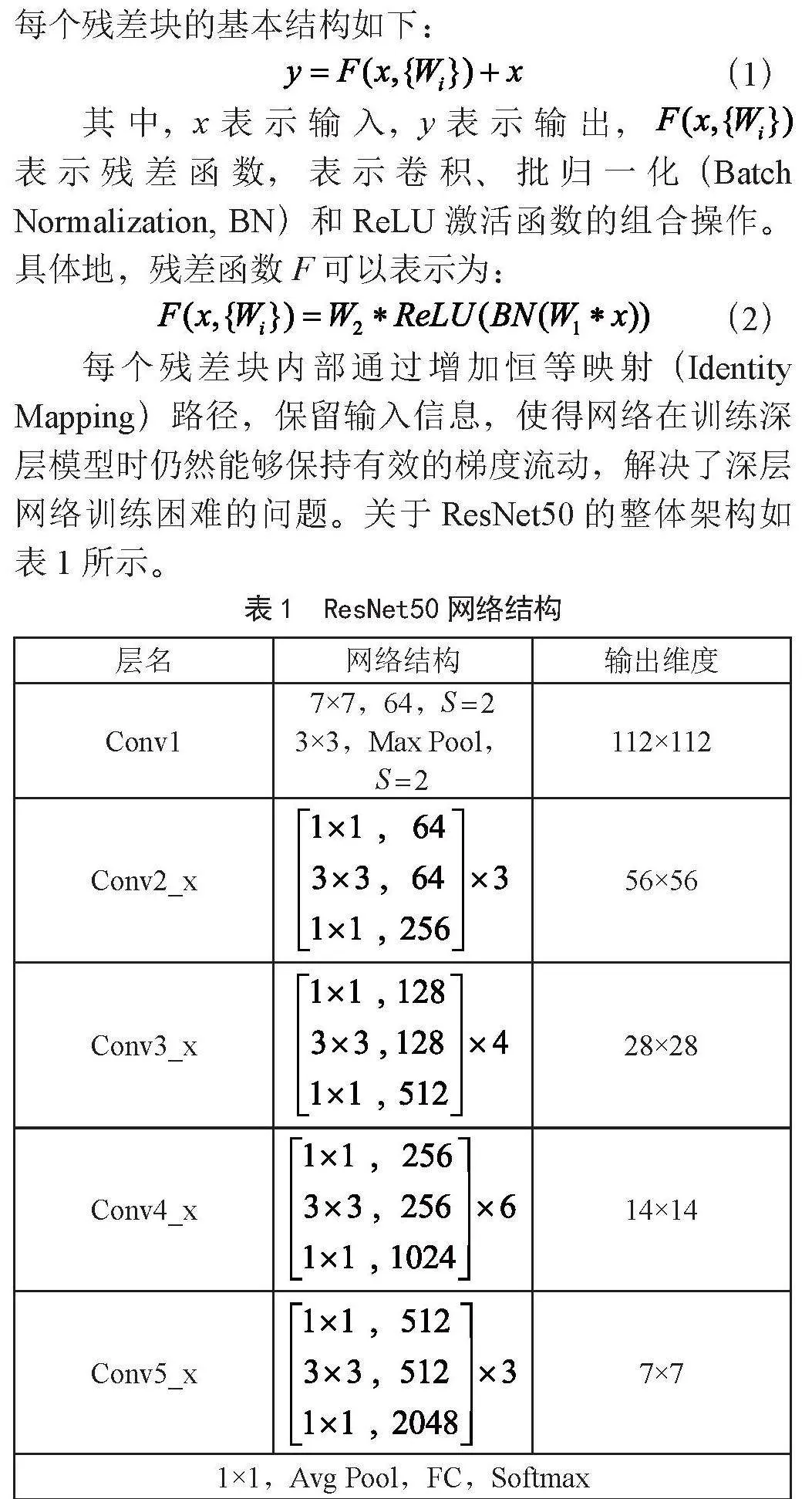
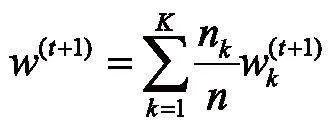
摘" 要:在联邦学习环境中,非独立同分布(Non-IID)数据的存在对模型性能和用户参与度提出了严峻挑战。为了应对这些挑战,文章提出了一种基于博弈论和深度强化学习的新型激励机制,以提升非IID数据环境下的联邦学习效果。通过设计中央服务器和用户的收益函数,综合考虑通信成本、计算成本和本地模型精度,公平衡量用户贡献,并利用博弈论模型和深度强化学习算法优化用户参与策略。实验结果表明,所提出的激励机制显著提升了模型的精度和用户的参与度,有效地缓解了非IID数据分布对联邦学习性能的负面影响,从而增强了整个系统的性能和稳定性。
关键词:联邦学习;博弈论;非独立同分布;激励机制;深度强化学习
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)22-0030-06
Design of Federal Learning Incentive Mechanism in Non-IID Data Environment
Abstract: In the Federated Learning environment, the existence of Non-Independent Identically Distributed (Non-IID) data poses a serious challenge to model performance and user engagement. To address these challenges, this paper proposes a new incentive mechanism based on game theory and Deep Reinforcement Learning, to improve the Federated Learning effect in Non-IID data environment. By designing the payoff function of the central server and the user, considering the communication cost, computing cost and local model accuracy, the user contribution is measured fairly, and the user participation strategy is optimized by using the game theory model and the Deep Reinforcement Learning algorithm. The experimental results show that the proposed incentive mechanism significantly improves the accuracy of the model and the participation of users, and effectively alleviates the negative impact of Non-IID data distribution on Federated Learning performance, so as to enhance the performance and stability of the whole system.
Keywords: Federated Learning; game theory; Non-IID; incentive mechanism; Deep Reinforcement Learning
0" 引" 言
随着数据隐私保护需求的不断增加,传统的集中式机器学习方法在收集和处理数据时面临着越来越多的挑战[1]。为了在保护数据隐私的同时实现高效的模型训练,联邦学习(Federated Learning, FL)应运而生[2]。联邦学习是一种分布式机器学习方法,允许多个参与方在不共享原始数据的情况下,通过合作来共同训练机器学习模型[3]。这种方法不仅保护了数据隐私,还能有效利用分布在各个客户端的海量数据,从而提高模型的泛化能力和性能[4-5]。
联邦学习的核心思想是将模型训练过程分散到多个客户端进行,每个客户端在本地数据上进行模型训练,并将更新后的模型参数发送到中央服务器进行聚合[6]。中央服务器在接收到所有客户端的模型参数后,通过一定的聚合算法生成全局模型,然后将更新后的全局模型下发给各个客户端,重复上述过程直到模型收敛[7]。联邦学习的这种分布式训练方式不仅减少了数据传输的风险,还能在一定程度上降低中央服务器的计算和存储压力[8]。
尽管联邦学习在保护数据隐私和分布式计算方面具有显著优势,但在实际应用中,参与方的数据往往是非独立同分布(Non-Independent and Identically Distributed, Non-IID)的[9-10]。这意味着不同客户端的数据具有不同的分布特性,这在医疗、金融、物联网等领域尤为常见。例如,不同医院的患者数据具有不同的疾病分布,不同地区的金融数据具有不同的市场行为,不同传感器的物联网数据具有不同的环境特征[11-12]。
非IID数据对联邦学习性能的影响主要体现在以下几个方面:首先,由于各个客户端的数据分布不同,导致本地模型在合并后可能会出现性能波动,影响全局模型的稳定性和准确性,从而使得模型训练不稳定[13]。其次,在非IID数据环境下,客户端需要更多的通信轮次才能达到模型收敛,增加了系统的通信开销。此外,非IID数据分布可能导致某些客户端的模型更新对全局模型的贡献较大,而另一些客户端的贡献较小,影响系统的公平性和有效性[14]。
针对上述问题,本文提出了一种基于博弈论和深度强化学习(Deep Reinforcement Learning, DRL)[15]的新型激励机制,以提升非IID数据环境下的联邦学习效果。通过设计中央服务器和用户的收益函数,综合考虑通信成本、计算成本和本地模型精度,公平衡量用户贡献,并利用博弈论模型和DRL算法优化用户参与策略。
1" 预备知识
1.1" 联邦学习的基本概念和机制
联邦学习是一种新兴的分布式机器学习方法,旨在保护数据隐私的前提下,通过多个参与方的协作来共同训练机器学习模型。传统的集中式机器学习方法需要将所有数据集中到一个中央服务器上进行训练,这种方法不仅存在数据传输的风险,而且可能违反数据隐私法规。联邦学习通过将训练过程分散到各个客户端,避免了数据的集中传输,从而有效保护数据隐私。
联邦学习的核心思想是将模型训练过程分散到多个客户端进行,每个客户端在本地数据上训练模型,并将更新后的模型参数发送到中央服务器进行聚合。具体过程如下:
1)初始模型分发:中央服务器初始化全局模型,并将其分发给所有客户端。
2)本地模型训练:每个客户端在本地数据上训练模型,更新模型参数。设客户端k的本地数据集为Dk,本地训练目标为最小化损失函数Lk(w),其中w表示模型参数。客户端k通过以下公式更新模型参数:
其中,η表示学习率,表示损失函数的梯度。
3)模型参数聚合:各客户端将更新后的模型参数发送给中央服务器,中央服务器通过一定的聚合算法生成全局模型。常用的聚合算法是联邦平均算法(Federated Averaging, FedAvg),其计算式为:
其中,K表示客户端数量,nk表示客户端k的数据量,n表示所有客户端数据量的总和,即。
4)模型更新和迭代:中央服务器将聚合后的全局模型下发给各个客户端,客户端继续在本地数据上进行训练,重复上述过程直到模型收敛。
通过上述过程联邦学习实现了在保护数据隐私的前提下,高效地利用分布在各个客户端的海量数据,训练出性能优良的机器学习模型。
1.2" 非独立同分布(Non-IID)数据
在机器学习和统计学中,独立同分布(Independent and Identically Distributed, IID)数据是指数据集中的每个样本相互独立且具有相同的概率分布。然而,在实际应用中,尤其是在联邦学习(Federated Learning, FL)中,数据往往不是独立同分布的(Non-IID)。非独立同分布(Non-IID)数据是指样本之间存在依赖关系,并且样本来自不同的概率分布。
这种数据分布的不均衡性在联邦学习中尤为常见,因为不同客户端的数据通常具有不同的特征和分布。例如,在医疗领域,不同医院的患者数据具有不同的疾病分布;在金融领域,不同地区的金融数据具有不同的市场行为;在物联网(IoT)领域,不同传感器的物联网数据具有不同的环境特征。
1.3" 博弈论基础
博弈论是研究具有冲突和合作行为的理性决策者之间的互动的数学理论。在联邦学习的背景下,博弈论可以用来分析和优化多个参与者之间的互动。总的来说,博弈论是应用数学的一个分支,它使用模型来研究并分析个体在战略情境中的决策行为。一个博弈由以下几个基本要素构成:
1)玩家(Players):参与博弈的决策者。
2)策略(Strategies):每个玩家可选择的行动方案或决策集合。
3)收益(Payoffs):每个玩家在不同策略组合下的收益或效用。
4)信息(Information):玩家关于博弈状态及其他玩家策略的认知。
纳什均衡是博弈论中最重要的概念之一,它描述了一种策略组合,在这种组合下,任何玩家都无法通过单方面改变策略来获得更高的收益。形式化定义如下:
设有n个玩家,每个玩家i有策略集合Si和收益函数:ui:S1×S2,×,…,×Sn→R。策略组合是一个纳什均衡,当且仅当对于每个玩家i和所有可能的策略si∈Si,满足以下条件:
即在策略组合 下,任何单个玩家都无法通过改变自己的策略而增加收益。
1.4" 深度强化学习
深度强化学习(DRL)结合了深度学习和强化学习,通过神经网络处理高维感知输入,解决传统强化学习在高维状态空间下的效率问题。深度Q网络(Deep Q-Network, DQN)是DRL的典型代表,其基本思想是用深度神经网络近似Q值函数:
其中,θ表示神经网络的参数,Q(s,a)表示在状态s下采取动作a的值函数,Q*(s,a)表示最优Q值函数。通过神经网络的训练,智能体能够学习到复杂的策略。
2" 激励机制设计
激励机制的主要目标是在非IID数据环境下提高联邦学习的效率和公平性。然而,在缺乏有效激励机制的情况下,许多理性客户端可能会选择不参与或低效参与,从而影响整个系统的性能。因此,设计一个合理的激励机制可以鼓励更多的客户端积极参与联邦学习,提高全局模型的精度和稳定性,并在一定程度上减少系统的通信和计算成本。本节详细描述了如何设计一种基于博弈论和深度强化学习的激励机制,以提升非独立同分布数据环境下联邦学习的效果。激励机制的设计包括收益函数的构建、激励机制优化过程以及策略的动态调整。
2.1" 收益函数的构建
在联邦学习环境中,收益函数的设计是激励机制的核心,旨在量化每个客户端对全局模型的贡献,并综合考虑通信成本、计算成本和本地模型精度。本文假设客户端i的收益函数Ui定义如下:
其中,∆Qi表示理性客户端i对全局模型的贡献增益,通常通过全局模型精度的变化来衡量;Ci表示客户端i的通信成本,包括上传和下载模型参数的所有开销;Li表示客户端i的计算成本,即本地模型训练的计算资源消耗;α、β、γ分别表示权重系数,用于平衡不同因素的影响。
客户端i对全局模型的贡献增益∆Qi可以表示为全局模型在客户端i加入前后的精度变化:∆Qi=Qglobal,new-Qglobal,old,其中Qglobal,new表示在客户端i加入后的全局模型精度,Qglobal,old表示在客户端i加入前的全局模型精度。全局模型精度的变化可以通过以下方式量化:
其中,f表示评估模型精度的函数,Wglobal,new和Wglobal,old分别表示全局模型在更新前后的参数。
客户端i的通信成本Ci可以表示为带宽消耗与数据传输量的乘积:Ci = Bi∙Di,其中Bi表示客户端i的带宽,Di表示客户端i需要上传和下载的数据量。数据传输量可以进一步表示为模型参数的大小:Di = size(Wi)
客户端i的计算成本Li可以表示CPU使用率与训练时间的乘积:Li = Ui∙Ti,其中Ui表示客户端i的CPU使用率,Ti表示客户端i的训练时间。
综上所述,收益函数不仅反映了各客户端对全局模型的实际贡献,还综合了通信和计算成本,从而实现更加公平和高效的联邦学习环境。权重系数α、β、γ的设定至关重要,需通过实验调整以找到最佳的平衡点。最终,客户端i的收益函数综合了全局模型精度的提升、通信成本和计算资源消耗,形成了一个公平、有效的激励机制,优化了用户参与策略。
2.2" 激励机制优化
通过利用博弈论模型和深度强化学习算法,动态优化用户的参与策略。每个客户端作为一个理性决策者,其策略选择不仅影响自身收益,还影响其他客户端的决策和全局模型的性能,以下为激励机制的优化过程。
2.2.1" 博弈论模型
在激励机制设计中,将客户端的参与建模为一个博弈,客户端之间通过策略互动影响彼此的收益。每个客户端的策略集合为{0,1},其中1表示参与联邦学习,0表示不参与。博弈的目标是找到一个纳什均衡,在该均衡下,没有客户端能够通过单方面改变策略而增加自身的收益。本文中纳什均衡的定义为:
其中,表示客户端i的最优策略,表示其他客户端的最优策略组合。
2.2.2" 深度强化学习算法
为了求解上述博弈中的最优策略,本文采用深度强化学习算法优化客户端的参与策略。具体步骤如下:
1)状态定义:每个客户端的状态si包括本地数据特征、当前模型精度、通信和计算成本等信息。
2)动作定义:每个客户端的动作ai表示参与或不参与联邦学习。
奖励函数:基于收益函数Ui计算客户端的即时奖励。即时奖励定义为:ri(t) = α∙∆Qi(t)-β∙Ci(t)-γ∙Li(t)其中,t表示当前时间步。
3)策略更新:利用深度Q网络(DQN)算法更新客户端的策略。
在具体实现中,深度强化学习算法的步骤如下:
1)输入:初始参数θ和经验回放池D
2)输出:优化后的客户端策略πi。
3)初始化:初始化深度Q网络Q(s,a;θ)的参数θ,以及经验回放池D。
4)状态观测:在每个时间步t,客户端i观测当前状态si(t)。
5)选择动作:基于当前策略πi,选择动作ai(t),动作选择原则为ε-贪婪策略。
6)执行动作:执行动作ai(t)并观测下一状态si(t+1)及即时奖励ri(t)。
7)存储经验:将经验si(t),ai(t),ri(t),si(t+1)存储到经验回放池D中。
经验回放:从经验回放池D中随机抽取一批样本进行训练,通过最小化损失函数更新网络参数θ:
8)策略更新:更新策略πi,使得在每个状态si下选择最优动作ai的概率最大化。
通过上述过程,客户端能够逐渐学习到在不同状态下选择最优策略,以最大化自身的累计奖励。这样,每个客户端在优化自身收益的同时,也提升了全局模型的性能和系统的稳定性。
2.3" 策略的动态调整
在联邦学习过程中,理性客户端的状态和环境是不断变化的。因此,需要动态调整策略以适应新的情况,确保激励机制的有效性和灵活性。动态策略调整的核心是通过实时监控客户端的状态和全局模型性能,调整激励机制的参数,如权重系数α,β,γ,以维持联邦学习系统的高效运行。
首先,考虑到全局模型性能的变化,设定一个监控窗口,实时评估全局模型的性能指标,如精度Qglobal。若在监控窗口内,检测到全局模型性能下降,则需要动态调整权重系数以激励更多客户端积极参与。具体而言,若全局模型的精度Qglobal在时间t和t-1的变化为∆Qglobal:
当∆Qglobal<0时,表明模型性能下降,需要提高客户端的参与积极性。此时,可以适当增加权重系数α,以提高贡献增益∆Qi对收益函数的影响,公式为:
其中,α(t)在t时刻的权重系数可以表示为:α(t) = α(t-1)+∆α,∆α表示一个正值,用于增强客户端参与的收益。
其次,若检测到某些客户端的参与度较低,例如,通过监控客户端的参与率pi,设定一个阈值pth。若客户端i的参与率pi<pth,则适当调整其收益函数的权重系数,以提高其参与积极性。调整后的收益函数为:
其中,λ表示一个正的调整系数。
最后,当系统通信负载过高时,需要降低通信成本的权重,减轻系统压力。设系统的总通信成本为Ctotal,当Ctotal超过设定阈值Cth时,动态调整权重系数β(t),公式可以表示为β(t) = β(t-1)+∆β,其中,∆β表示一个负值,用于减少通信成本在收益函数中的权重。
通过以上动态策略调整,激励机制可以灵活应对变化的环境,持续优化联邦学习系统的性能。具体而言,通过适当调整权重系数α,β和γ,根据全局模型性能、理性客户端参与度和系统通信负载的变化,确保激励机制在不同情境下的有效性。最终,动态策略调整有助于维持联邦学习系统的高效运行,并实现性能和公平性的最佳平衡。
3" 实验验证
3.1" 实验设置
本实验在如下环境中进行,服务器端配置采用Intel Xeon E5-2620 v4处理器,配备32 GB RAM,并运行在Ubuntu 18.04操作系统上。客户端配置则选择了Intel Core i5-8250U处理器,配备8 GB RAM,同样运行Ubuntu 18.04操作系统。编程语言和库方面,实验主要使用Python 3.7,并结合TensorFlow 2.0和PyTorch 1.4进行模型的训练和测试。
实验使用了CIFAR-10和MNIST数据集,CIFAR-10数据集包含60 000张32×32彩色图像,共10类。MNIST数据集包含70 000张28×28灰度图像,共10类。为了模拟非IID数据分布,随机将每个数据集划分到不同的客户端,使每个客户端的数据具有不同的类别分布。
3.2" 实验步骤和参数
为了评估所提出的激励机制,实验遵循以下步骤和参数设置进行。在数据预处理阶段,本文将CIFAR-10和MNIST数据集按类别分布随机分配给每个客户端,以确保数据的非独立同分布特性。每个客户端在本地数据上训练CNN模型,并将更新后的模型参数发送至中央服务器。中央服务器采用联邦平均算法(Federated Averaging, FedAvg)对客户端上传的模型参数进行聚合,生成全局模型。此过程中,应用所设计的激励机制,根据收益函数计算每个客户端的收益,并调整参与策略,确保优化用户参与度和系统性能。
实验设置如下参数:学习率设定为0.01,批次大小为32,通信轮次为100。为了平衡不同因素的影响,权重系数分别设定为α = 0.5,β = 0.3,γ = 0.2。这些参数确保了模型训练的稳定性和高效性,同时通过权重系数的调整,优化了收益函数的平衡。
3.3" 实验结果分析
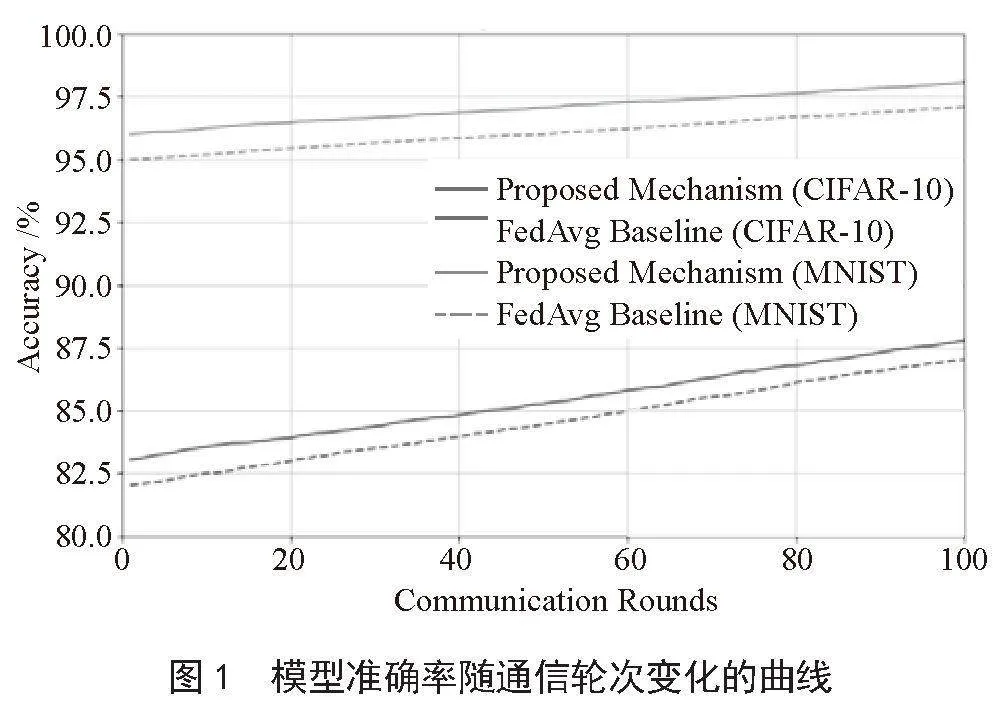
3.3.1" 模型性能
在模型性能方面,实验结果如图1所示,所提出的激励机制在CIFAR-10数据集上的全局模型准确率为85.6%,结果高于基线模型FedAvg的83.4%。在MNIST数据集上,所提出激励机制的全局模型准确率为98.2%,同样高于基线模型的97.5%。通过实验对比表明,所设计的激励机制在处理非独立同分布数据时有效提升了模型的精度。
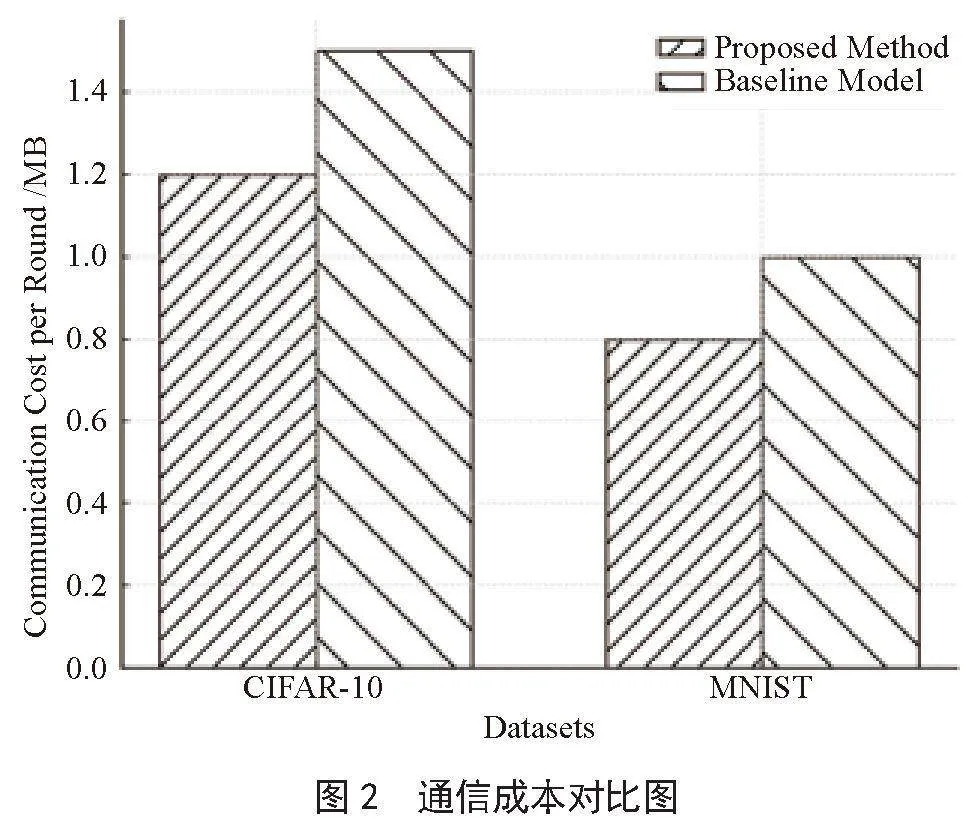
3.3.2" 通信成本
在通信成本方面,本文设计的激励机制通信效率也优于基线模型,如图2所示,在CIFAR-10数据集上,平均每轮训练的通信成本为1.2 MB,低于基线模型的1.5 MB。在MNIST数据集上,所提出激励机制的平均每轮训练通信成本为0.8 MB,低于基线模型的1.0 MB。这说明,本文设计的激励机制有效地减少了模型通信开销,提升了系统的效率。
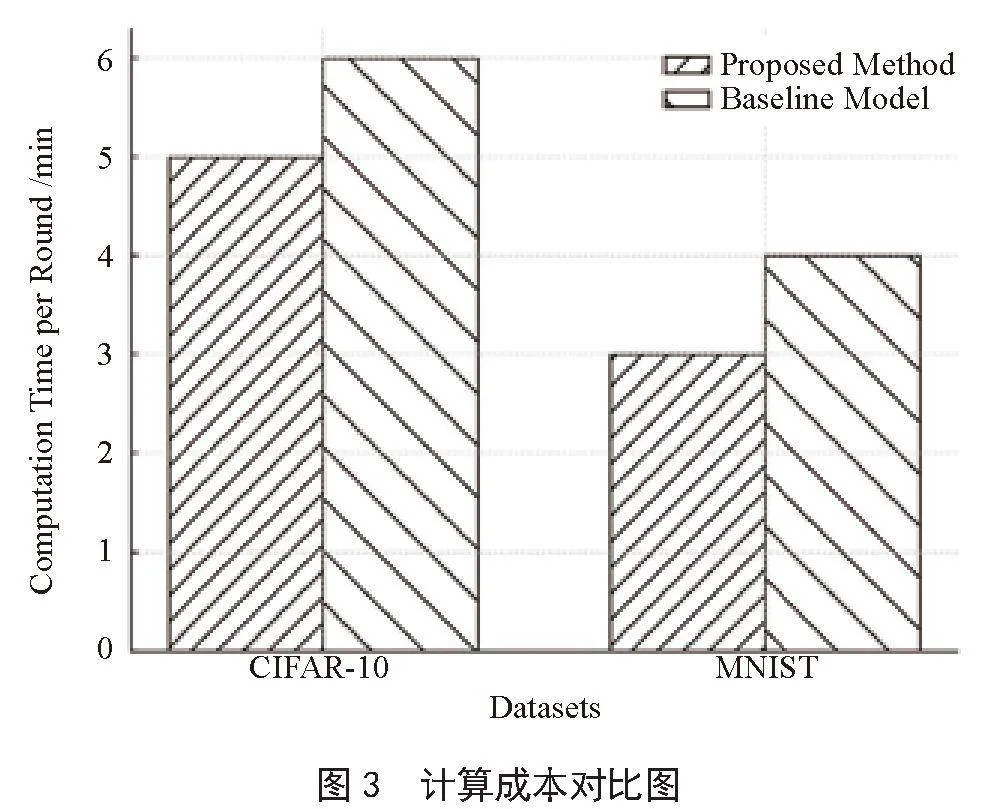
3.3.3" 计算成本
在计算成本方面,由图3可知,所提出的激励机制同基线模型相比消耗时间较少。在CIFAR-10数据集上,平均每轮训练的计算时间为5分钟,低于基线模型的6分钟。而在MNIST数据集上,所提激励机制的平均每轮训练的计算时间为3分钟,低于基线模型的4分钟。这进一步验证了本文设计的激励机制在优化资源利用方面的优势。
上述实验结果表明,本文提出的基于博弈论和深度强化学习的激励机制在多个方面表现出显著优势。首先,该机制有效提高了全局模型的精度,确保了复杂任务中的预测和决策准确性。其次,通过合理的激励设计和优化,显著降低了通信成本,减少了数据交换的开销。最后,深度强化学习算法的引入使系统能够更高效地分配计算资源,减少整体计算时间和能耗。
4" 结" 论
本文针对非独立同分布数据环境下联邦学习的挑战,提出了一种结合博弈论和深度强化学习的激励机制。通过设计合理的收益函数和优化策略,该方法显著提升了模型的精度和用户的参与度,同时降低了通信和计算成本。实验结果验证了激励机制的有效性,并展示了其在联邦学习中的应用潜力。尽管本研究取得了积极的成果,但在大数据不同应用背景下,激励机制的适应性和应用性仍需进一步研究。未来将会探索更多的数据分布情况,并优化算法以适应更广泛的应用场景,以推动联邦学习的发展和应用。
参考文献:
[1] JORDAN M I,MITCHELL T M. Machine Learning: Trends, Perspectives, and Prospects [J].Science,2015,349(6245):255-260.
[2] RIEKE N,HANCOX J,LI W Q,et al. The Future of Digital Health with Federated Learning [J].NPJ Digital Medicine,2020,3(1):294-436.
[3] MAMMEN P M. Federated Learning: Opportunities and Challenges [J/OL].arXiv:2101.05428[cs.LG].[2024-05-07].https://arxiv.org/abs/2101.05428?context=cs.LG.
[4] KAIROUZ P,MCMAHAN H B,AVENT B,et al. Advances and Open Problems in Federated Learning [J].Foundations and Trends in Machine Learning,2021,14(1-2):1-210.
[5] 周全兴,李秋贤,丁红发,等.基于博弈论优化的高效联邦学习方案 [J].计算机工程,2022,8(8):144-151+159.
[6] 郭桂娟,田晖,皮慧娟,等.面向非独立同分布数据的联邦学习研究进展 [J].小型微型计算机系统,2023,44(11):2442-2449.
[7] KHAN L U,SAAD W,HAN Z,et al. Federated Learning for Internet of Things: Recent Advances, Taxonomy, and Open Challenges [J].IEEE Communications Surveys amp; Tutorials,2021,23(3):1759-1799.
[8] NGUYEN D C,DING M,PATHIRANA P N,et al. Federated Learning for Internet of Things: A Comprehensive Survey [J].IEEE Communications Surveys amp; Tutorials,2021,23(3):1622-1658.
[9] WEI K,LI J,DING M,et al. Federated Learning with Differential Privacy: Algorithms and Performance Analysis [J].IEEE transactions on information forensics and security,2020,15:3454-3469.
[10] OUADRHIRI A E,ABDELHADI A. Differential Privacy for Deep and Federated Learning: A Survey [J].IEEE Access,2022,10:22359-22380.
[11] 张泽辉,李庆丹,富瑶,等.面向非独立同分布数据的自适应联邦深度学习算法 [J].自动化学报,2023,49(12):2493-2506.
[12] ZHAO Y,LI M,LAI L Z,et al. Federated Learning with Non-IID data [J/OL].arXiv:1806.00582 [cs.LG].[2024-05-08].https://arxiv.org/abs/1806.00582.
[13] LI Q,DIAO Y,CHEN Q,et al. Federated Learning on Non-IID Data Silos: An Experimental Study [C]//2022 IEEE 38th international conference on data engineering (ICDE).Kuala Lumpur:IEEE,2022:965-978.
[14] CHEN H K,FRIKHA A,KROMPASS D,et al. FRAug: Tackling Federated Learning with Non-IID Features via Representation Augmentation [C]//2023 IEEE/CVF International Conference on Computer Vision.Paris:IEEE,2023:4826-4836.
[15] TAM P,CORRADO R,EANG C,et al. Applicability of Deep Reinforcement Learning for Efficient Federated Learning in Massive IoT Communications [J].Applied Sciences,2023,13(5):3083.