摘要
文生视频大模型 Sora的问世,意味着 AI正式叩响“影像制作”的大门,既有的传媒业态、社会生态亦会由此迎接新的场景,强大的生产效率、持续的学习能力、复杂的数据来源将会对传播的内容、通道甚至模式产生深远影响。由此,探讨 Sora 的技术框架及其可能带来的机遇与挑战是目前学界亟待探索的热门话题,本文旨在深入解析 Sora 的技术框架,探讨其内部逻辑如何实现对物理世界的模拟与再现,并进一步分析其为传播生态带来的革新与危机。
关键词
Sora 技术框架 传播生态
一、从深度学习到技术融合:“视频世界模拟器”创新影像技术
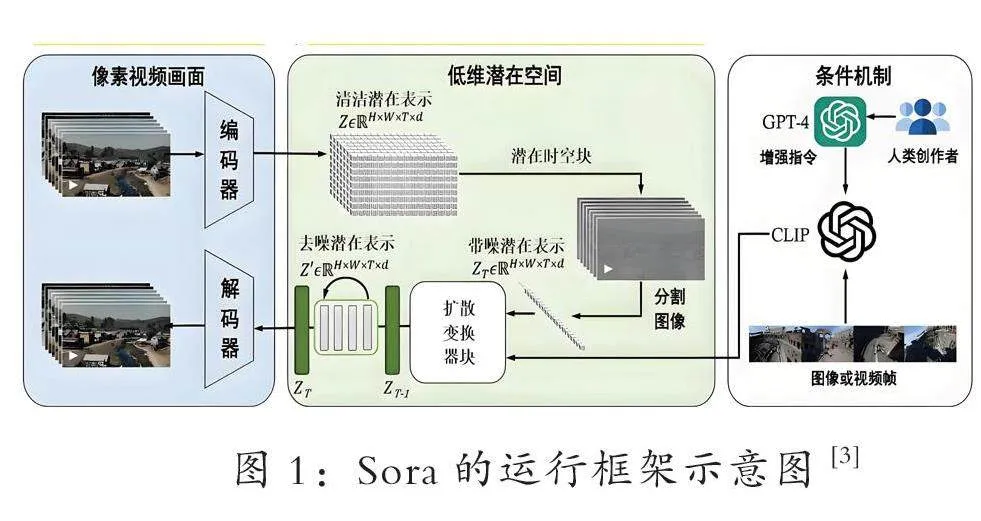
从技术的底层逻辑出发,Sora程序的核心是一个经过预先训练的扩散转换器(Diffusion Transformer)[1]。具体拆解来看,这一程序可以被拆分为两个核心板块,其一为负责像素视频编码与解码的生成板块,其二为负责解析用户需求的语义匹配板块。因此,Sora的出现汇聚了目前关于图像生成与语义解读的多类深度学习模型的技术成果,其工程与逻辑方面的创新与兼容促使其能够更好地完成从“理解”到“产出”的生产过程,而创造力的极大释放也开始让AI影像制作不再是简单的“科技玩具”。
(一)人工智能影像的生成逻辑
在Sora程序正式发布之前,AGI(通用人工智能)领域经历了从生成式文本到生成式图像的演进与发展,诸如 ChatGPT、DeepArt、Midjourney 等多种程序的陆续登场展示了 AI 在创作型文本与图像方面的潜力。直观来看,影像视频就是对“图像”的时空延伸与扩展,其基本原理更像是对前有理论与模型的一种集成和加强[2]。
从生成逻辑来看,Sora等AI影像生成程序需要以人类创作者的要求为描述性指令(prompt),通过自有的模型生成出多帧图像,并将其通过时间逻辑串联成为可播送的视频。这样的流程首先需要依托于生成对抗网络(Generative Adversarial Networks)等常见的深度学习模型,保证AI能够不断通过自主学习来扩充其数据库和完善“模仿”能力,从而提升其生成视频对于现实世界的仿真度;其次,由于影像解析与生成的复杂性,为了提升 AI 的承载能力,程序还需要一个“降维空间”来对视频素材进行编码与解码。而由于生成式程序服务于人类创作者的要求,程序也需要搭载大型语言模型(Large Language Model)以完成对自然语言的处理。
(二)人工智能影像的技术路径
从逆向分析内部结构的角度来看,Sora程序通过三个具体的结构串联起了视频生成与语义匹配两个核心板块,其中低维潜在空间与编码解码器共同组成了生成部分,而条件机制则单独为语义部分服务。在运行过程中,Sora会预先经过编码的形式将原始的素材库进行降维,将像素画面以“潜在表示”的形式进入作为信息枢纽的低维空间,随后在进行除噪后保留关键信息,以供模仿学习。而此时,如果人类创作者输入了有关的指令,解码器就会开始工作,进行语义匹配后通过“扩散”的形式逐步将潜在表示输出为若干个视频帧,并通过一定的逻辑排列后抵达创作者端。由此在生成板块与语义板块的配合之下,一个精准且具有逻辑的视频即可完成产出。
Sora的运行模式集结了图像处理与模仿以及语义匹配两类不同的AIGC 技术,具有一种“兼容”的天然优势。比如,在模仿与扩散阶段,潜在空间能够保证其更为高效地处理素材,避免由于视频文件的复杂度而影响生存效率;同时,对抗网络的存在也能够不断帮助AI更好地“欺骗”监视器,从而让其生成的内容更具仿真度;语义匹配在语言模型的基础上也能够确保生成的内容符合于创作者的需求,避免无效的冗余信息。因此,Sora对于视频智能生成领域的技术革新是基于已有基础模型的,亦是极其有效的。
二、从效率升级到智慧融通:“视频世界模拟器”重塑传播生态
任何新技术的出现,除了代表一种可供使用的“新型工具”,还反映着技术演变的某些规律[4]。Sora的诞生让AI生成的视频时长扩充至1分钟,为视频内容创作者们提供了一件更为趁手的工具,也必然在一定程度上对人类的传播思维、模式、结构产生重塑,并从不同的角度直接影响和改变着现有的传播业态。而值得关注的是,Sora 的探索绝非独立于使用者,也就是人类之外,它所产生的无限可能反而预示着人人可参与、智慧可融通的未来,它也为我们观察人在智能机器时代的角色与定位提供了新的视角。
(一)超低门槛:产能释放再造全新起点
Sora程序的出现极大缩减了微视频影像的制作流程,让曾经的“脚本编写、分镜设计、拍摄布景、现场录制、后期剪辑”等复杂庞大的团队作业浓缩入了能够通过模拟不断学习的“黑箱”装置之中,其化繁为简的能力,以及生成式人工智能共有的“高效”优势成为其吸引更多人尝试的关键因素。与此同时,流程简化带来的成本锐减更是AI生产的又一“刺点”,少则一天多则半月的时间成本也压缩至了分钟单位,传统拍摄中需要累加的人力物力几乎可以实现倍数级缩减,内容创作者的试错机会也随之增多。可以说,在Sora的助力和加持之下,尝试成为“视频制作者”对于具备在聊天框输入信息指令能力的庞大互联网用户群体而言,已经变得仿若一场游戏,而游戏式的传播与生产代表的正是对抗权利分层固化的“大众力量”。
威廉·弗卢塞尔(Vilém Flusser)曾在《技术图像的宇宙》中预言,借由技术生产的加持,人们会近乎狂热地利用键盘制作出难以磨灭的信息,享受成为创作者的游戏[5]。一方面,AI技术在用户操作层面的超低门槛抹去了繁琐的条件限制,提供了一个相对更为平等与自由的生产空间,固有的话语权力分配体系在技术的赋能下再次松动,容许部分曾被拒之门外的“普通网民”参与其中,进而探索新的分配规则;另一方面,这种无需太多成本的创作模式也降低了尝试的“心理准入阀”,游戏式轻松愉快的参与让用户们脱离了传统评价标准的凝视与束缚,敢于进行一些“天马行空”的创作,从而挑战由专业者制定的审判规则,达成相对自由与无拘无束的创作氛围。总的来说,在AI带来的对话式生产游戏中,大众群体得到了抹去其技能亏欠与心理负担的配平砝码,视频生产者被不同程度地拖拽到了新的起跑线上,期许更加公平、多元的话语空间,并由此促进传播交往的繁荣。
(二)超大承载:持续模仿集结人类智慧
尽管视频创作者通过输入指令文本,并借助对抗式模拟的创作模式,似乎赋予了AI极大的创作空间与“自主权利”[6],但深入分析便可发现,所有生成式作品的真实源头始终是人类创作的已有成品集合。学界关于其版权争端话题的讨论,也恰恰揭示了优质生成式影像内容的本质——它们并非个体所有,而是代表了被纳入数据库和模仿库中的所有人类作品的精粹。从群体智慧的角度来看,生成式AI已超越了单纯物体的范畴,它成为人类在知识获取、保留和分享过程中认知能力的重要延伸[7]。换言之,它是人类整体智慧的集结与再调配的载体。生成式人工智能技术,作为集结人类智慧的新新媒介,利用其远超普通人的学习能力,集纳海量资源,并对这些原始智慧进行再理解和深度挖掘,从而实现传承与提升。在此基础上,视频创作领域或将迎来前所未有的发展通路,实现崭新的飞跃。
而将“内容”元素置于传播过程链中作为传播的一个关键要素后,这种飞跃就不仅停留于内容创作的水准和质量之上,更是影响到了智慧的播撒与扩散进程。生成式AI在吸纳人类的“智慧”的同时,也为加速“智”的传播提供了强大的动力。同时,Sora程序对生产效率的提升除了客观上能够将凝结“群体智慧”的产品推广到更多更广泛的受众节点,帮助更多人接受智的“教育”之外,还足以利用自身强大的学习模拟能力实现对人类的反哺,从而延伸人的认知范畴。这种双向互动的模式,使得“人类在机器的帮助下更加聪慧”的愿望在螺旋上升的循环中逐渐变为现实。特别是在跨文化交流领域,生成式AI的多语言能力和强接收模仿能力还能发挥出一些缩减文化折扣的作用,减轻由于文化语境、地理区隔、政治观念等构筑出的“智”的传播壁垒,助力智慧的跨“边界”扩散,亦提升人类智慧集合圈的包容性与囊括范围。
三、从机器宰制到真实幻灭:“视频世界模拟器”引发交往危机
纵观技术的发展历程不难发现,智能技术的介入往往拥有“利于”人类的出发点,它们由人创造而来用以协助工作的工具。“视频世界模拟器”的诞生从这种意义上说也是人在创造一个可以更好地用动态画面存续和表达现实世界的工具,逐步接近于马歇尔·麦克卢汉(Marshall Mcluhan)所说的“人类延伸的最后一环”[8],实现感知能力的无限延展。但是,这种“工具”也往往附带着对人某种“缺点”的包容,并能够利用它们逐步反客为主,侵袭传播伦理甚至异化人与社会。就像智能分发在包容人的“选择性心理”时引发“信息茧房”的猜想一样,智能生成亦会在包容人的“惰性”的同时导向“媒介依赖”“单向度的人”等危机,提醒人们在为 Sora的技术突破喝彩的同时也不能不警惕可能伴随而至的负面影响与异化效果。
(一)依赖与驯化:个体用户服从机器思维
Sora 等生成式 AI 的运行逻辑让作为用户的创作者拿起了发布指令的“指挥棒”,成为AI的“命令者”,可以借由算力的支撑以极低的代价完成视频作品的制作。这种低操作门槛极大地提升了创作的效率与便捷度,然而,与之相伴的却是技术依赖的悄然滋生。在这种技术的纵容之下,过往需要从现实社会生活中汲取经验性材料,并通过“灵感”将其串联出个性作品的创作模式被创作者们放弃,置换成一种抛却“思考”、立等可取[9]的简单途径。但是,在看不见的装置黑箱中,“人类创作者”的角色却在逐渐边缘化,成为长串流程中的一个初始环节。这种边缘化不仅削弱了创作者的主体地位,更使得他们在享受快捷生成的同时面临着“不思进取”的风险,个人价值在机器的高效运作下被工具价值所取代, “创作”的灵韵在机械的复制中被消磨。
更为危险的是,使用机器、依赖机器的过程中还暗含着对机器思维上的迎合。人们为了达成“让AI理解指令从而生成出正确的作品”的目的,必须不断学习与机器沟通的技巧,而由于人与工具的差异性,这一过程中不乏需要让渡自身的思维观念以达成与机器的精准配对。人们意愿上的配合开始潜移默化地让机器加入以往由人与人组成的传播与交往链条,而 AI 强大的工具属性会逐步展现出将他人取而代之的能力,将“人-人”改写为“人-机器”,形成一个新的闭环。在这样的闭环之中,机器反而成为规则的制定者,人看似拥有发布号令的指挥权,实际上却遵从于AI程序的思维方式和交往条件,异化成了被机器宰制的“单向度的人”,甚至逐渐丧失保持自我思考的能力。
(二)仿真与篡改:拟态环境的再拟态化
多模态技术的发展以及对抗式学习模型的进步,让Sora程序生成的作品不仅拥有复杂的元素堆叠和场景切换,还能够极大程度上还原现实景观,甚至让虚构出的环境与物逃过人类的常识性判断,不断贴近“世界模拟器”的构想。高度的仿真能力持续吞噬着虚拟与真实的边界,也让人们对于真实的信任更加岌岌可危。20世纪 20 年代,美国着名新闻学者沃尔特·李普曼( WalterLippmann)曾提出“拟态环境”说,指出人们通过媒介认识的世界不等于现实,而只是叙事修饰过的“拟态”真实[10]。而在智能技术的发展之下,媒介建构的拟态世界不仅在构筑人们对世界的认知,也成了生成式 AI 抓取形成数据库的素材。这意味着AI生成的所有内容本质上是对“媒介叙事”的再塑和模仿,它们仅仅能够代表对人类观念的表征而非对现实的表征[11],只是对媒介构筑的“拟态环境”的再拟态化。
斯帕罗(Sparrow)等人在《科学》杂志上提出并论证“谷歌效应”指出,人们对互联网的记忆依赖能够消除人与人之间分享记忆信息的需要,并瓦解将重要信息存入生物式记忆系统的冲动[12]。这意味着仿真的生成式内容虽然无法成为“真实”,但能够填充入人的记忆之中,且可能不会在与他人的交谈中被证伪和甄别,乃至因其在网络空间中的长期停驻而成为多年之后群体的集体记忆。而集体记忆除了在传播的仪式观中承担“赋予仪式感”的角色之外,也会在时间的推移之下成为“历史”的一部分感性记录,那么,如果 AI 创作的虚构内容在无意之间携带了偏见与倾向,这些错误的讯息就可能形象被留驻在记忆之中,成为历史中的共识。而就世界格局而言,先进的智能技术只会发源于发达的少数国家,这些模型也优先被技术资源更强的数据与场景投喂,在高度仿真与强感染力的加持下,实现文化和意识形态入侵将变得简单轻易,传递歧视与偏见也会变得更根深蒂固和难以察觉。
结语
人工智能介入到视频影像内容的生产领域,存在于过往科幻小说中的“虚拟世界”,拥有了一个更具光环的名字,“模拟现实”“虚拟生存”成为AI发展的重要方向。尽管在目前看来,元宇宙依然是遥不可及的想象,与之伴生的概念炒作也消耗了不少科技魅力,甚至被人评价为引人眼球的“商务噱头”,但为这一构想服务的通用人工智能技术却始终在以迅猛的速度发展进步。从ChatGPT到DeepArt到Sora,从文本到静态图像再到活动影像,生成式人工智能仅用不到两年时间已经到达了足以让部分人类无法识别其内容生产的程度,并且持续引发着诸如“人是否会被AI替代”的讨论。本文从技术框架的角度入手,通过分析Sora对传播生态的影响,阐述其可能带来的机遇与危机,回应了这一问题。Sora的诞生是人类在技术领域丰碑式的成果,其初衷一定是用以提高生产效率、提高内容真实度与质量,从而服务于人类的视频创作工作,从目的上而言是无意于“取代”人类的;而从结果上来讲,即使强大的模仿能力和巧妙的降维能力已经可以让不少AI生成作品做到高度还原“以假乱真”,但其依然会出现思维逻辑方面的错误,让AI在时空维度完全等同于人类在现阶段并不可能,因此从结果论上直接判定其能够取代传统视频生产亦是杞人忧天。人类不断求证AI是否会取代自己更多展现的是一种居安思危式的心理诉求,就像笔者担忧Sora的出现可能会异化人的思维、割裂人的交往,其本质是期望应用技术的人能够不完全被“懒惰”操纵,不断提醒自己动用主观能动性避免成为技术的劳工,而非真的担心人已经完全沦为技术的奴仆。
在人与机器的和谐共生道路上,机器是高效的工具,亦是提醒人拔高“技术素养”与“媒介素养”的钟鸣,闻其声就会反复自省回归理性,就不会完全为“智能”所替代。
参考文献:
[1]W.Peebles and S.Xie,Scalable diffusion models"with transformers[C].IEEE/CVF International Conferenceon Computer Vision,2023:4195-4205.
[2]郭全中,张金熠.作为视频世界模拟器的Sora:通向 AGI 的重要里程碑[J].新闻爱好者,2024(04):9-14.
[3]Yixin Liu,Kai Zhang,Yuan Li et al.Sora:A Review on Background,Technology,Limitations,and Opportunities"of Large Vision Models[EB/OL].(2024-02-27)[2024-03-10].https://arxiv.org/pdf/2402.17177v1.pdf
[4]彭兰.从ChatGPT透视智能传播与人机关系的全景及前景[J].新闻大学,2023(4):1-16.
[5][巴西]威廉·弗卢塞尔.技术图像的宇宙[M].李一君,译.上海:复旦大学出版社,2021:73.
[6]高永杰,吕欣.生成式AI技术进化与图像艺术生产范式革新[J].现代传播,2023(9):159-168.
[7]喻国明,滕文强.生成式AI对短视频的生态赋能与价值迭代[J].学术探索,2023(7):43-48.
[8][加]马歇尔·麦克卢汉.理解媒介:论人的延伸[M].何道宽,译.北京:商务印书馆,2000:5.
[9]黄旦.作为人类文明进程动因的媒介[J].新闻记者,2023(6):3-10.
[10][美]沃尔特·李普曼.舆论学[M].林珊,译.北京:华夏出版社,1989:240.
[11]陈露菡.作为技术图像的AI绘图:本质与未来走向[J].青年记者,2023(11):89-91.
[12]Sparrow,B.,Liu,J.Wegner,D.M.(2011).Googleeffects on memory:Cognitive consequences ofhavinginformation at our fingertips[J].Science,333(6043):776-778..
