





摘" 要:2023年广东省大学生计算机设计大赛大数据专题赛提供了9份收集自国家统计局的数据,该研究根据9份数据中包含的20类指标数据分析各省市城乡建设发展情况。分别使用Python语言机器学习中的K-means和GMM聚类模型,并结合PCA主成分分析、构建自编码器、构造特征工程三种方式进行特征降维,对我国大陆31个省市自治区进行大数据分析,把各省市按城乡建设发展程度聚类为发达、中等、一般3类。聚类模型分析的结果与当前我国城乡发展实际高度契合。
关键词:大数据;城乡发展;聚类;K-means;GMM
中图分类号:TP391" 文献标识码:A" 文章编号:2096-4706(2024)23-0110-06
Clustering Analysis of Urban and Rural Construction Development and Planning from the Perspective of Big Data
HUANG Jiesheng, LI Xiaoqiang
(School of Artificial Intelligence, Guangdong Open University, Guangzhou" 510091, China)
Abstract: The 2023 Guangdong University Student Computer Design Competition Big Data Special Competition provided nine data collected from the National Bureau of Statistics. This paper analyzes the urban and rural construction development situation in various provinces and cities based on 20 types of indicators included in the nine data. This paper uses the K-means and GMM clustering model in Machine Learning of Python language respectively, and combines three ways of PCA, constructing autoencoder and constructing feature engineering to carry out feature dimensionality reduction. Big Data analysis is conducted on 31 provinces, cities and autonomous regions in mainland China, and provinces and cities are clustered into developed, moderate and average three categories according to the degree of urban and rural construction development. The results of clustering model analysis are highly consistent with the actual reality of urban and rural development in China.
Keywords: Big Data; urban and rural development; clustering; K-means; GMM
0" 引nbsp; 言
在当前的信息化时代,数据分析已经成为一种新的生产力和发展方式。随着大数据的发展,可以通过收集、分析和理解大量数据来更好地理解和预测社会经济发展趋势,以及城乡建设的需求和潜力。在这个背景下,广东省教育厅在2023年6月举行了的“广东省大学生计算机设计大赛大数据专题之大数据视角下的城乡建设发展与规划赛”(简称“大数据应用赛”),该赛题的目标是通过对我国各省发展情况的深入分析,找出各地的发展情况,从而为城乡建设和规划提供数据支持,推动全国范围内的平衡发展。通过对数据的研究分析,将有助于政策制定者更好地了解城乡发展的实际情况,从而制定出更有针对性的发展策略,提高国家分配效率、人民生活水平,实现城乡区域的协调发展[1]。
该赛题提供了9份收集自国家统计局的数据[2],分别是:各地区历年生产总值数据、城乡人口统计数据、2021各省按行业分城镇就业人员、普通高等学校情况、房地产开发企业个数、房地产开发企业经营情况、2021分省房屋平均销售价格数据、城乡居民社会养老保险情况数据、2021市政公用设施水平,共9份数据文件。
大数据应用赛要求从数据文件中,合并2021年我国大陆31个省市自治区的“地区生产总值(亿元)、城镇人口(万人)、乡村人口(万人)、第一产业就业人员、第二产业就业人员、第三产业就业人员、普通高等学校数(所)、房地产开发企业个数、房地产开发企业营业利润(亿元)、住宅商品房平均销售价格(元/平方米)、城乡居民社会养老保险参保人数(万人)、城乡居民社会养老保险基金收入(亿元)、城市的供水普及率、城市的燃气普及率、城市的污水处理率、城市的人均公园绿地面积、乡市的供水普及率、乡市的燃气普及率、乡市的污水处理率、乡市的人均公园绿地面积”共20类指标数据。目标是使用Python语言构建聚类模型,将各省市按城乡建设发展程度聚类为发达、中等、一般3类。
1" 研究思路
1.1" 数据预处理
为找出9份数据中数据间的关联性,首先把相同含义的列重命名为相同的列名,如“地区”,然后使用“地区”字段作为连接列,使用Pandas库中的merge方法,按地区把所有相关信息合并为一份综合的数据集,最后利用Sklearn中的StandardScaler类对数据集进行标准化处理。
1.2" K-means聚类模型
构建聚类模型分为以下4步[3]:
1)模型选择,由于数据中各省份的发展类别并未标注,属于无监督类型问题,因此首先考虑选择K-means聚类模型。
2)参数设置:根据题目要求将数据分为三个类别,即n_clusters=3,其他参数默认。
3)模型训练:使用fit方法进行训练,并可以通过模型的labels_属性可以获取聚类结果,通过模型的cluster_centers_属性可以返回聚类中心。
4)模型评估:利用sklearn 中的silhouette_score轮廓系数计算得到的结果来评估模型好坏,取值范围在-1到1之间,值越接近1表示聚类效果越好。
1.3" 评估发展程度
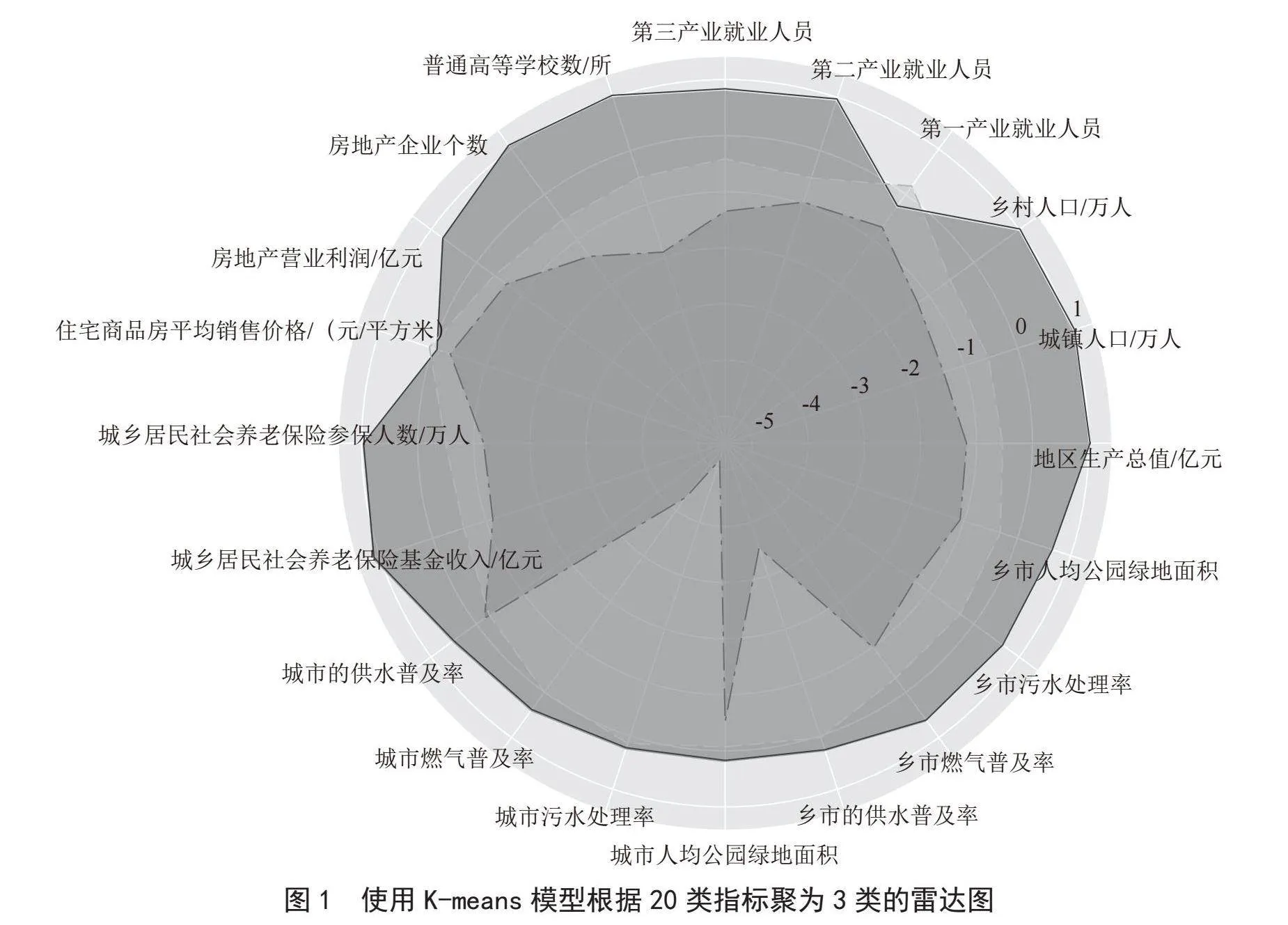
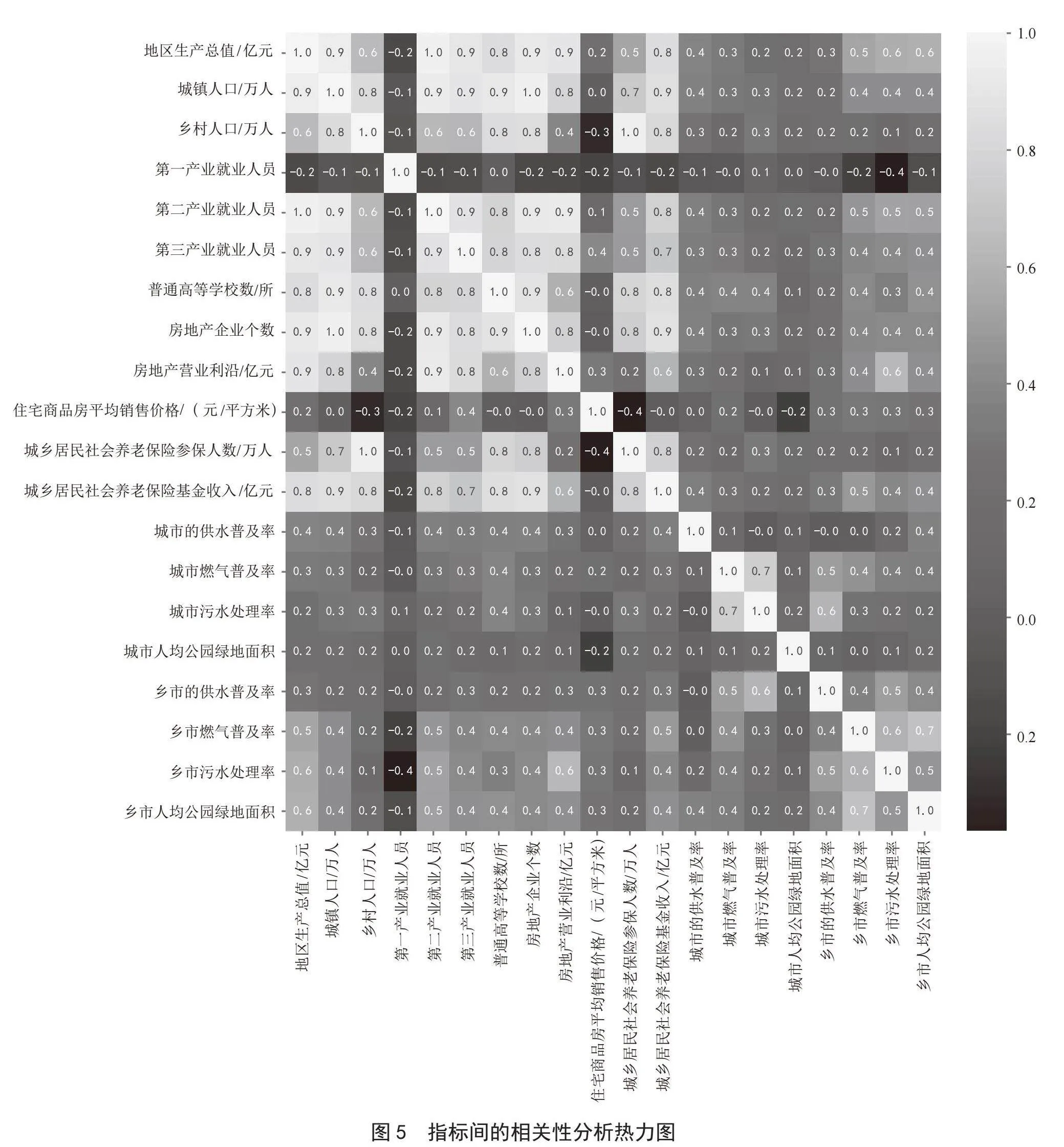
通过K-means模型进行聚类,并将各类指标绘制成雷达图,如图1所示。
从图1可以看出最外层实线为发达类别,所有指标发展都比较均衡比较好,中间层虚线为中等类别,所有指标也比较均衡,但不如发达省份,最内层是一般类别,指标发展不均衡且发展指数较低。聚类后的省市如表1所示。
从表1结果可以看出,对发达类别聚类的结果大致符合近几年我国经济强省的排名;在中等类别的结果中,四大直辖市(北京、上海、天津、重庆)的体量也明显无法跟发达省比较而只能归入中等,但四大直辖市的综合发展理应是比较全面的,这样的结果虽然正确,但显然不够客观;在一般类别的聚类结果中,只有一个西藏自治区,也显然出现了聚类不均衡情况。综上,我们需要提出更优的算法进行改进。
2" 改进算法
2.1" GMM聚类模型
K-means是假设每个类别都为球形的,或者在高维数据中是超球形的,所有的点都均匀分布在该球形中,而且K-means将数据点分配到聚类时,每个点仅仅给出属于某个类别的结果,属于硬分配。
而Gaussian Mixture Model(GMM)是K个单高斯模型组合而成的模型,用多个高斯分布函数去近似任意形状的概率分布,可以使得聚类更加准确。并且是选择成分最大化的后验概率来完成聚类,后验概率表示的是数据点类别的可能性,而不仅仅是判定属于某个类,所以属于软分配。综上,GMM有可能比K-means聚类效果更优。GMM的概率密度函数为[4]:
其中,K为超参数,表示模型的个数,其他参数需要通过Expectation-Maximization(EM)最大期望算法估计;
αk为第K个高斯的概率(先验概率),需要满足大于0,且和为1;
p(x∣k)为第k个高斯的概率密度,其均值向量为μk,∑k为协方差矩阵。
聚类问题可以通过采用轮廓系数(Silhouette Coefficient)来判断模型的好坏,越趋近于1则表示内聚度和分离度相对越优。使用K-means模型的轮廓系数为0.257,使用GMM的轮廓系数为0.296。轮廓系数公式为[4]:
其中,a(i)为样本点i的内聚度,计算式为:
其中j表示与样本i在同一个类内的其他样本点,dis(i, j)表示i与j的距离。所以a(i)越小说明该类越紧密。b(i)与a(i)类似,但b(i)需要遍历其他类簇得到多个值,并从中选择最小的值作为最终的结果与a(i)相减计算S(i)。
从表2的结果可以看出,聚类结果中的发达类别有6个,其中北京市与上海市被识别为发达。一般类别还是只有西藏1个,剩余的作为中等类别。可见在使用原数据的基础上直接分析,GMM算法有一定提升,但还不够明显,所以可以考虑对数据进行进一步处理,找出更重要的特征。
2.2" 数据降维
在原始数据的所有特征中,有的是起主要作用的,有的是冗余或噪声数据,为此,可以通过数据降维(Dimensionality Reduction),减少冗余信息和噪声信息造成的误差影响,从而提高模型分析的精度。主成分分析(Principal Component Analysis, PCA)是最常用的一种数据降维方式,可找到数据中的主要变化方向(即主成分),并通过主成分来表示原始数据[3]。
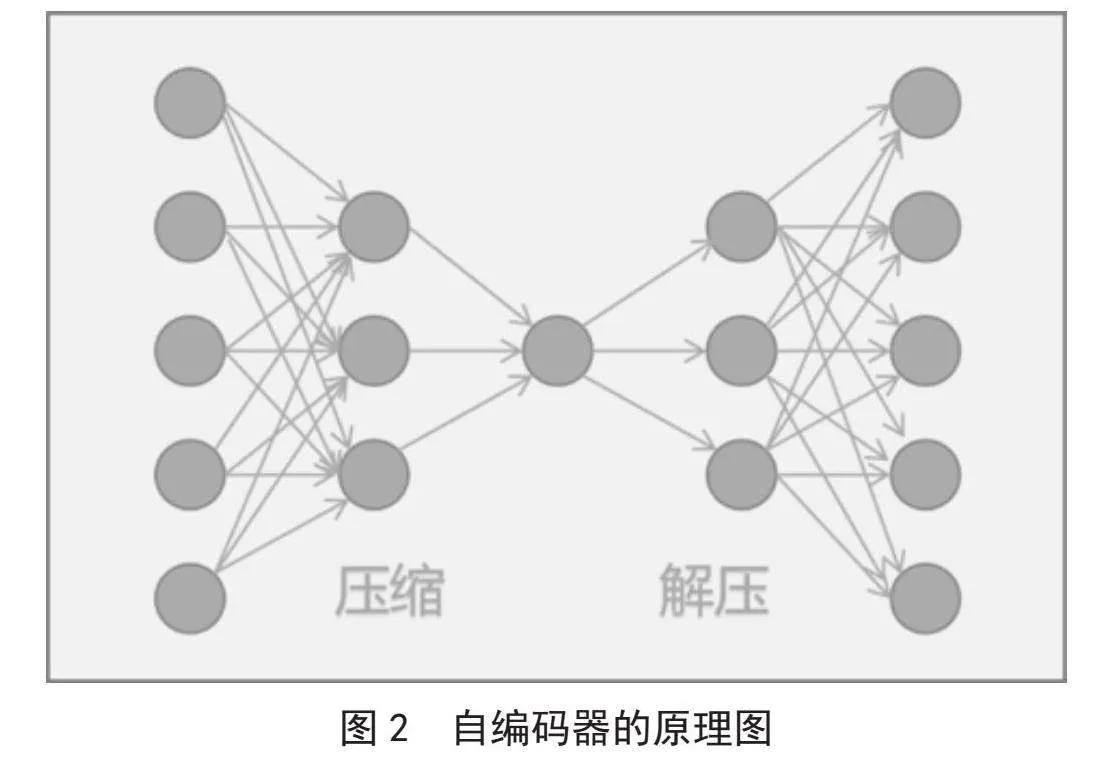
自编码器(Autoencoder)是一种无监督学习算法,可用于数据降维与特征提取。先通过编码器将输入数据压缩成低维表示,再通过解码器将低维表示解压缩还原数据[5]。通过这种方式,自编码器可以学习到数据的紧凑特征表示。自编码器的原理图如图2所示。
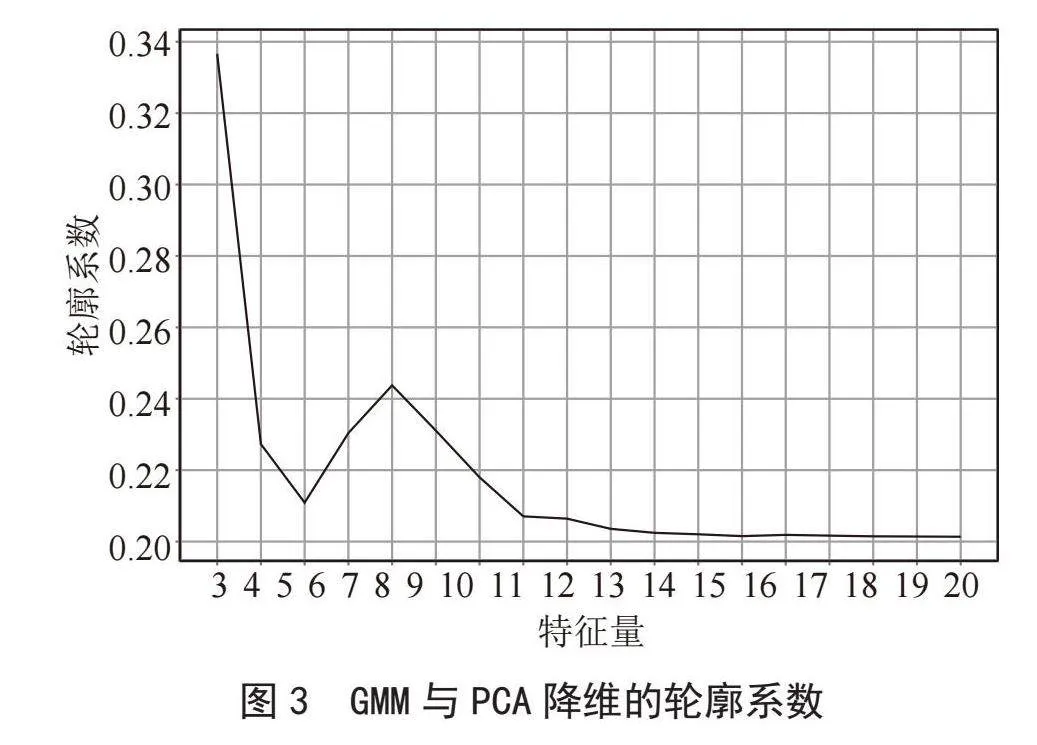
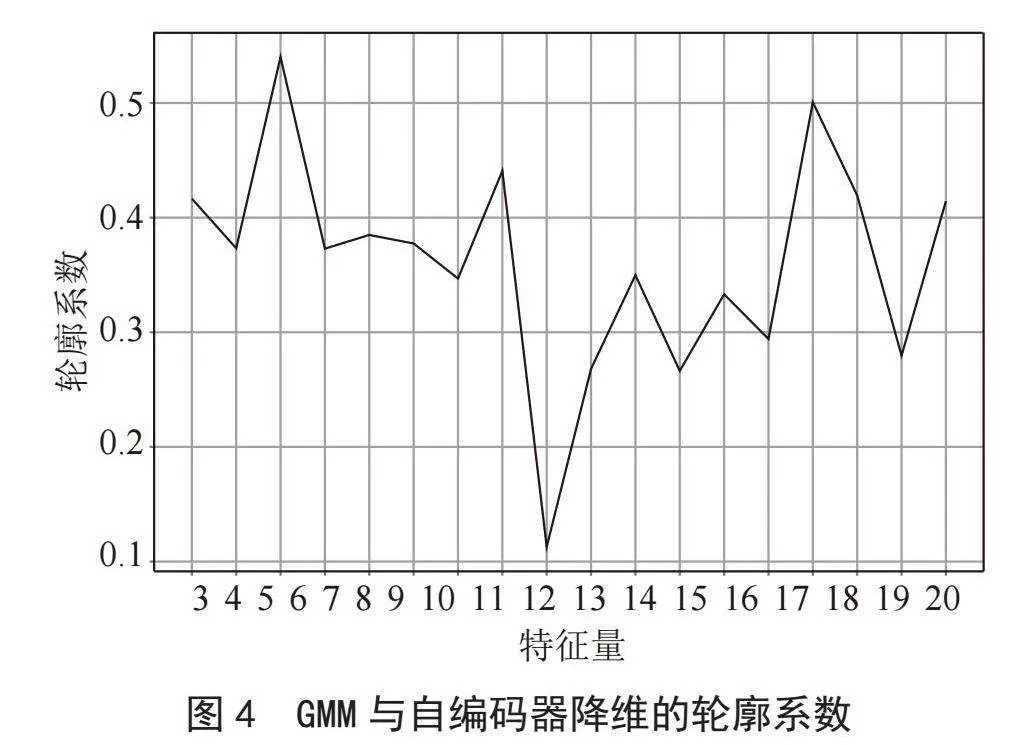
经过实验发现,K-means无论结合PCA还是自编码器,选择的特征数都非常稳定,轮廓系数仍然是0.257,跟未进行降维相同,但也意味着K-means无法对聚类结果进行改进。而从图3可以看出,GMM结合PCA的最优特征个数为3,轮廓系数为0.336。从图4可以看出,GMM结合自编码器认为的最优特征个数为5,轮廓系数为0.540;次优特征个数为17,轮廓系数为0.501。GMM结合自编码器得到的轮廓系数高于GMM结合PCA的轮廓系数。防止过拟合现象,折中选择轮廓系数为0.437的第三优的10个特征进行聚类分析,使用自编码器特征降维后GMM聚类的我国大陆省市发展程度结果如表3所示。
从表3聚类结果可以看出,发达类别中包含了国家统计局数据2021年中GDP前14的经济强省,广西壮族自治区被归为发达稍显不合理。一般类别有3个,也符合国家统计局GDP后末三位的省份,其他归为中等类别。从聚类结果可以看出,使用自编码器的GMM模型比单纯使用GMM模型有了较大的改进,缺点是聚类结果还不够准确,并且一般类别数量依然只有3个,不够均衡。
3" 特征工程
通过对比上述结果,并结合现实情况可以发现,模型的聚类结果基本都是按“地区生产总值”GDP发展高低作为最重要的特征,为探索城乡的综合发展,需考虑构造特征工程。
3.1" 拓展分析
城乡的发展,首要关注的依然还是地区生产总值,而通过热力图的分析,如图5所示,可以看出地区的生产总值与城镇人口、三次产业就业人员、普通高等学校数(所)、房地产营业利润、城乡居民养老参保人数,呈现一个强正相关的关系,可见这些特征也是关键特征。为此,可以在此基础上,进行特征工程,构建新的特征。
3.2" 特征工程分析
通过特征间的相关性分析,对原始数据的20个指标重新构建为以下8个指标,分别是:
1)人均生产值=地区生产总值(亿元)/(城镇人口(万人)+乡村人口(万人))
2)房地产占总值比=房地产营业利润(亿元)/地区生产总值(亿元)
3)人均普通高等学校数=普通高等学校数(所)/(城镇人口(万人)+乡村人口(万人))
4)人均绿地面积=(城市人均公园绿地面积×城镇人口(万人))+(乡市人均公园绿地面积×乡村人口(万人))/(城镇人口(万人)+乡村人口(万人))
5)养老参保比例=城乡居民社会养老保险参保人数(万人)/(城镇人口(万人)+乡村人口(万人))
6)城市-乡市的供水率=(乡市的供水普及率+城市的供水普及率)/2
7)城市-乡市的燃气率=(乡市燃气普及率/城市燃气普及率)/2
8)城市-乡市的污水处理率=(乡市污水处理率/城市污水处理率)/2
保留原数据中的第一、第二、第三产业人员3个特征,共计11个特征。
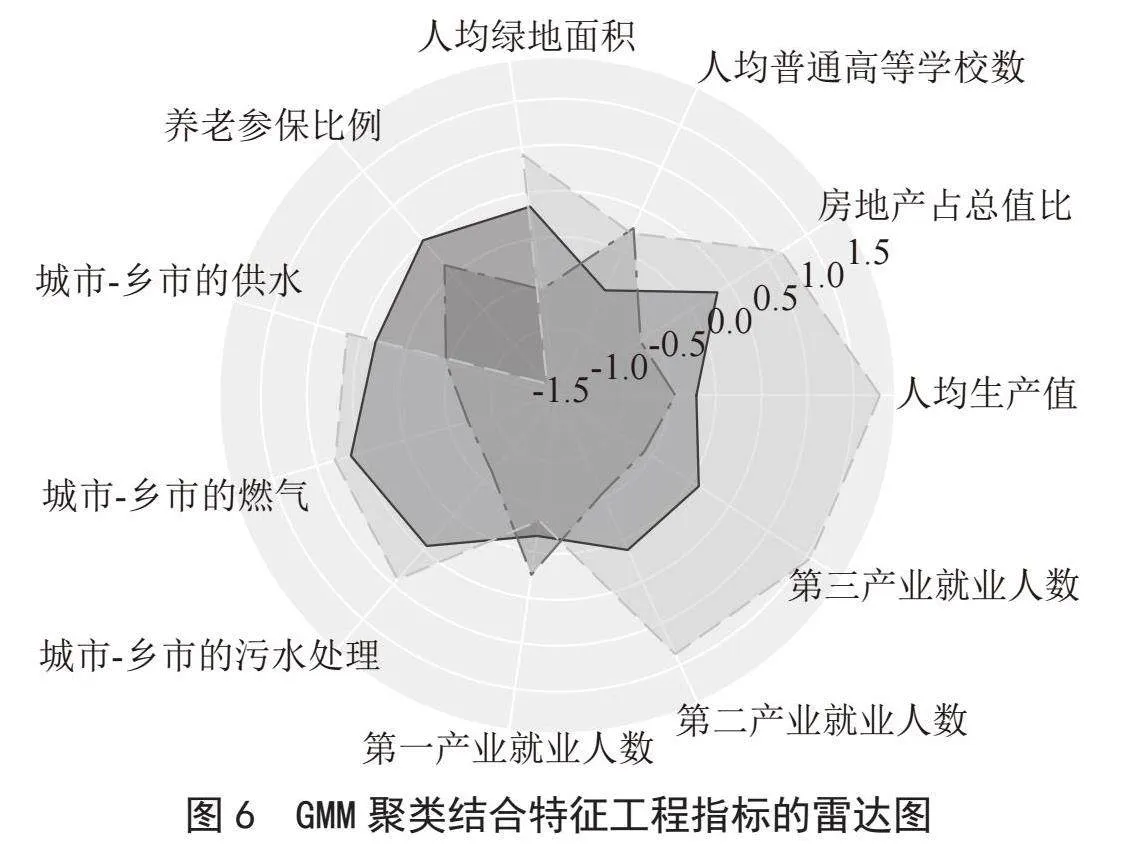
使用GMM模型对特征工程构造后的11个指标的新数据进行训练,根据指标特征绘制出对应的雷达图,如图6所示,其中外层虚线为发达,中层实线为中等,内层虚线为一般。聚类结果如表4所示。
3.3" 结果分析
综合图6和表4可以看出:
1)发达类别的雷达图面积最大说明整体水平高,整体基础设施覆盖率高,主要体现在供水率、燃气率、污水处理率、人均绿地面积的比率高;房地产对经济发展占比偏高;最大问题是养老参保率偏低,这可能跟发达省份的生活成本和社保制度有关[6];该类别很重要的一个特点是第二、三产业所占比重远高于第一产业。
该类别的省市是北京市、上海市、广东省、江苏省、浙江省,这5个是当前我国公认经济发展、综合发展最好的5个省市。
2)中等类别的雷达图面积次大,说明整体水平没有发达类别突出,但也比较均衡,该类别最突出的特征是养老参保率最高,也反映了我国当前发展不光以发展经济为主,而且还能兼顾全面发展相关的民生配套设施,让人民努力过上小康社会,努力缩小地方差距。
该类别的省市包含了华东七省中剩余四省的山东省、福建省、江西省、安徽省;而广西壮族自治区和海南作为华南地区,有其得天独厚的地理发展优势,特别是海南省自2018年被定位为“自由贸易港”后,在2021年以11.2%的经济增速位列全国第二[2];河北作为与北京一体化发展的重要省份,承接了许多北京的产业优势,如建设雄安新区、大兴机场等,都使得河北的发展越来越好。华中三省中的河南省、湖北省,以及西南地区的重庆市、四川省发展也都非常迅速。
3)一般类别的雷达图面积相对最小,说明发展相对缓慢,其最突出的特点是第一产业占比最多。
该类别中,作为华中地区的湖南省被模型认为是一般类别可能稍有争议。其余的结果包含有全部西北五省(陕西省、甘肃省、青海省、宁夏回族自治区和新疆维吾尔自治区),西北地区虽然地域辽阔,但许多地区自然条件严酷,不利于经济的发展,符合需要“西部大开发”的政策。也包含了全部的东北四省(黑龙江省、吉林省、辽宁省以及内蒙古自治区),东北地区气候寒冷,一直以来依赖重工业的发展,缺乏创新和竞争力,符合需要“振兴东北”的政策。西南地区中剩下的云南省、贵州省、西藏自治区由于地势高峻,气候寒冷,交通不便等原因都制约了经济的发展[7]。在山西省和天津直辖市是当前华北地区发展相对缓慢的,山西省是资源型经济转型发展大省,近代发展过于依赖煤炭资源,低技术制造业比例较大[8];天津市的滨海新区曾经发展潜力非常大,但当前发展也出现增长乏力态势[9]。
综上,通过模型聚类可以看出,我国存在区域经济发展非均衡的情况,南方与东部地区(东南沿海、珠三角地区、长三角地区)普遍较为发达,北方与西部地区(华北部分地区、西北地区、东北地区、西南大部分地区)普遍发展相对缓慢,但也符合因地制宜、效率优先的区域经济协调发展策略与规律[10]。我国存在产业结构发展非均衡的情况,发达地区更注重第二、第三产业的发展,而欠发达地区则以发展第一产业为主,但这也符合经济发达程度越高,第一产业所占比重越低,而第二、三产业所占比重越高的标志[11]。
4" 结" 论
本研究结合2023年广东省大学生计算机设计大赛提供的数据和提出的要求,通过机器学习聚类模型得到的分析结果比较符合现实情况,并且三种类别数量呈现从小到大的金字塔结构,取得了较好的结论,成功解决了竞赛提出的问题,为通过大数据分析我国大陆省市城乡发展评定提供了新的思路。
参考文献:
[1] 巩艳红,殷亚男.我国城乡融合效益及区域发展差异——基于三维均值聚类 [J].未来与发展,2022,46(10):71-78.
[2] 国家统计局.中国统计年鉴2021 [EB/OL].[2024-07-12].http://www.stats.gov.cn/sj/ndsj/2021/indexch.htm 2022.
[3] 周志华.机器学习 [M].北京:清华大学出版社,2016.
[4] 李航.统计学习方法:第2版 [M].北京:清华大学出版社,2019.
[5] ARIYO O,UMAR M A,EDWARD B,et al. Attention Autoencoder for Generative Latent Representational Learning in Anomaly Detection [J/OL].Sensors,2021,22(1):123[2024-06-25].https://doi.org/10.3390/s22010123.
[6] 贾洪波,周心怡.城乡居民基本养老保险对参保者获得感的影响——基于CSS2019数据的准实验研究 [J].北京航空航天大学学报:社会科学版,2023,36(3):106-122.
[7] 王健,高铭.基于新发展理念的中国省域经济发展评估 [J].现代管理科学,2021(4):3-16.
[8] 李梅芳.山西省制造业和生产性服务业协调发展研究 [J].现代工业经济和信息化,2023,13(7):8-10.
[9] 李维,李建国,田子寒,等.天津市产业结构优化升级路径研究——以电力产业数据为基础 [J].科技和产业,2023,23(3):130-136.
[10] 李梅.我国区域经济发展现状问题及其对策研究 [J].商讯,2021(32):146-148.
[11] 郑伟,张瑞书,关南星.三次产业拉动GDP增长的多元线性回归分析——基于1998-2017年数据 [J].统计与管理,2019(6):9-12.
作者简介:黄杰晟(1982—),男,汉族,广东广州人,讲师,工学硕士,研究方向:数据分析、计算机视觉;李晓强(2000—),男,汉族,广东揭阳人,研究方向:数据分析。