



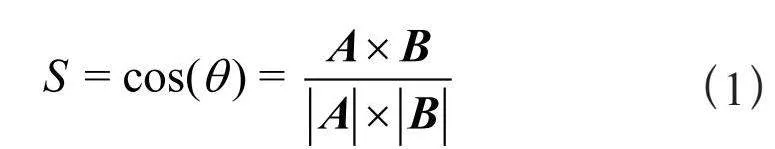
摘" 要:随着人工智能产业的高速发展,国家政策层面出台了大量的人工智能产业政策,对此,文章提出了一种基于语义分析的人工智能政策知识图谱构建方法。首先,根据语义角色标注和依存句法关系提取实体关系三元组;然后运用ChatGLM-6B大语言模型识别政策中的政策客体,用于知识筛选;再计算关系词汇的余弦相似度对关系进行融合对齐,实现知识融合;最后,对实体关系查询和政策信息服务两个应用领域进行了探究。所构建的知识图谱可以精准地向企业等用户提供所需的政策信息,提高政策信息的利用效率。
关键词:产业政策;知识图谱;知识抽取;大语言模型
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)23-0093-07
Research on the Knowledge Graph Construction of Industrial Policies for Artificial Intelligence
ZHAO Jinshi, SHEN Yongluo
(School of Information, Guangdong University of Finance and Economics, Guangzhou" 510320, China)
Abstract: With the rapid development of the Artificial Intelligence industry, a large number of industrial policies for Artificial Intelligence have been introduced at the national policy level. Therefore, this paper proposes a Knowledge Graph construction method of Artificial Intelligence policies based on semantic analysis. Firstly, it extracts entity relationship triples according to semantic role labeling and dependency syntactic relationship. Secondly, it uses the ChatGLM-6B Large Language Model to identify the policy objects in the policies for knowledge screening. Thirdly, it calculates the cosine similarity of the relationship vocabulary to fuse and align the relationship to achieve knowledge fusion. Finally, the two application fields of entity relationship query and policy information service are explored. The constructed Knowledge Graph can accurately provide the required policy information to enterprises and other users and improve the utilization efficiency of policy information.
Keywords: industrial policy; Knowledge Graph; knowledge extraction; Large Language Model
0" 引" 言
随着人工智能产业的蓬勃发展,该领域正成为新一轮科技革命和产业变革的重要驱动力量。国家在人工智能产业政策方面全方位支持该领域的高速发展,从2017年国务院发布《新一代人工智能发展规划》到现在,政府陆续出台了多项政策。然而,由于政策文件往往分散在不同政府部门的网站上,用户难以进行集中查询和检索,同时,政策文本存在信息量大、篇幅长的特点,传统的政策检索方式不利于用户快速从政策中获得重要信息。
知识图谱是以具有知识表达属性的三元组为基础,通过融合多源异构数据,以具有语义关系的有向图结构进一步描述客观世界中的相关概念及其关系,从而形成关系清晰准确、内容翔实的结构化语义数据库[1-2],国内外学者已经将知识图谱运用到学术资源[3]、医疗保健[4]、故障诊断[5]等多个领域。关于知识图谱在政策研究中的应用,部分学者以知识图谱为工具,采用文献计量法对政策进行研究,分析政策的发展脉络和趋势、预测政策热点。例如,新冠疫情期间,霍朝光等构建新冠感染政策知识图谱,用于政策公文归档、追溯法律渊源、监督政策焦点[6]。与之类似的,还有将知识图谱应用于中国数字经济发展政策研究[7]、“双碳”政策理论脉络和发展进路的研究[8]。从文献计量的角度出发,可以在宏观上把握政策的总体发展情况,然而无法有效满足企业和公众实时了解政策内容的需求,从而实现政策的“为民所拥,为民所用”。基于此,部分学者开始将深入政策文本进行知识抽取,构建政策知识图谱并开展应用研究,例如文旅融合政策[9]、创新创业政策[10]、养老产业政策[11]。随着我国人工智能产业的飞速发展,人工智能产业政策知识图谱既可以为企业在获取政策信息、把握政策动向、享受政策优惠上提供帮助,可以为知识图谱在政策领域的应用提供理论参考。
1" 知识图谱构建流程
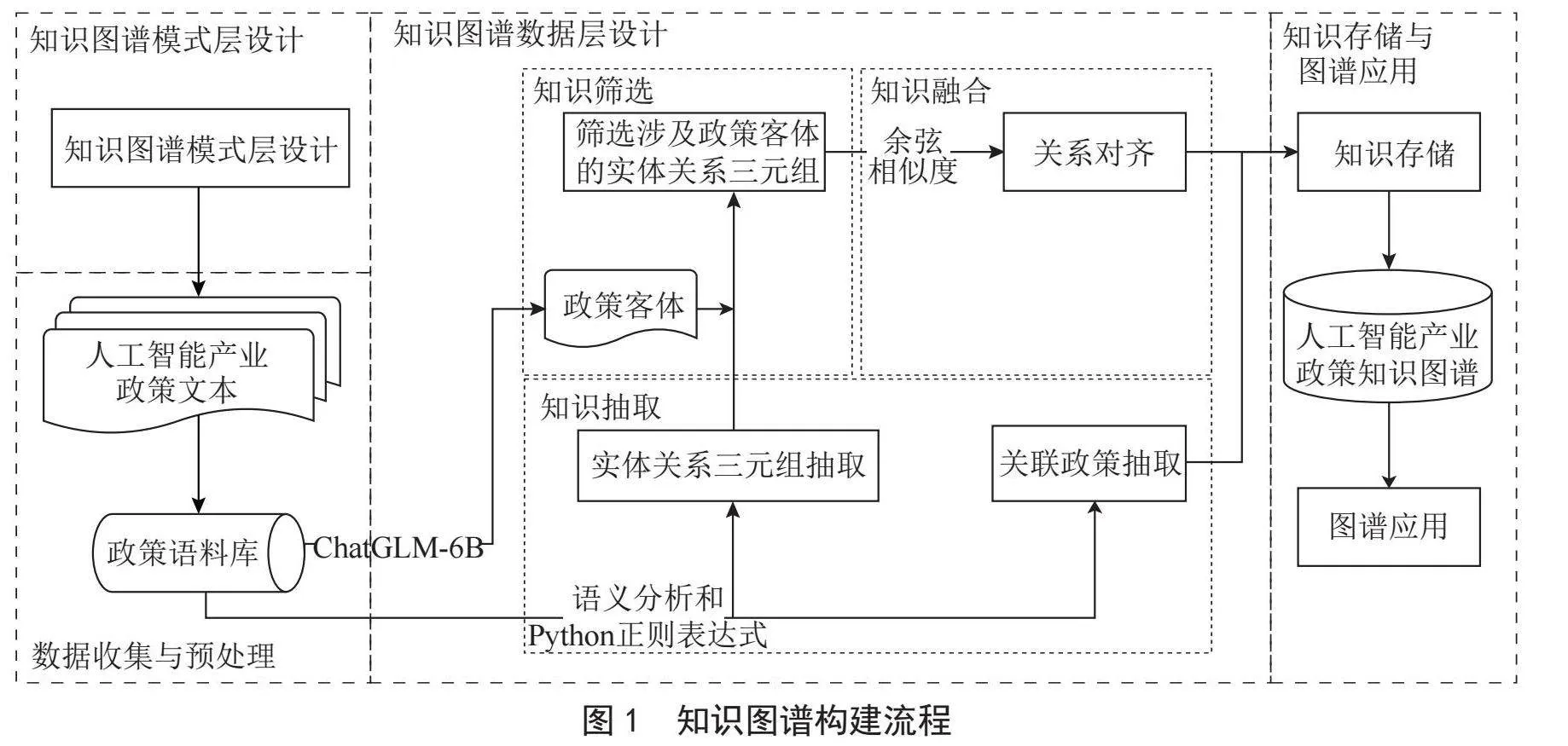
人工智能产业政策知识图谱的构建流程主要包括模式层设计、数据收集与预处理、数据层设计、知识存储与图谱应用4个环节,知识图谱的整体构建流程如图1所示。
环节内容如下:
1)知识图谱模式层设计。根据人工智能产业政策文本的特点,从政策文件和政策内容两个层面考虑,设计知识图谱的模式层。
2)数据收集与预处理。对收集的政策文本进行清洗,主要是去除已失效政策和政策中的无效内容。而后分句、分词并存储,得到政策语料库,以便于后续工作。
3)知识图谱数据层设计。数据层设计包含知识抽取、知识筛选和知识融合三个步骤。首先,利用Python正则表达式对政策文本中的关联政策进行识别,再提出一种基于语义分析的三元组抽取规则,从政策文本中抽取实体关系三元组;再使用开源大语言模型ChatGLM-6B,提取政策中的政策客体,将得到的实体关系三元组与政策客体对比,筛选出涉及政策客体的实体关系三元组;最后训练词向量,根据余弦相似度对关系词汇进行合并对齐。
4)知识存储与图谱应用。将处理后的数据存入Neo4j图数据库,形成人工智能产业政策知识图谱,讨论知识图谱在可视化查询、企业信息服务场景下的应用。
2" 知识图谱模式层设计
结合文献综述的梳理分析及已有的人工智能产业政策文本,政策文件整体与其他政策之间存在着必然的关联,政策文本内容中也包含着该政策自身的许多关键信息。因此,本文认为,人工智能产业的政策研究需要从政策文件和政策内容两个层面考虑,才能更有效地管理政策文本。
2.1" 政策文件
从政策文件层面来看,政策存在演进的过程,一部政策的制定,必然与其他政策存在联系,或是对上位政策的细化和延伸,或是对其他政策的衔接。
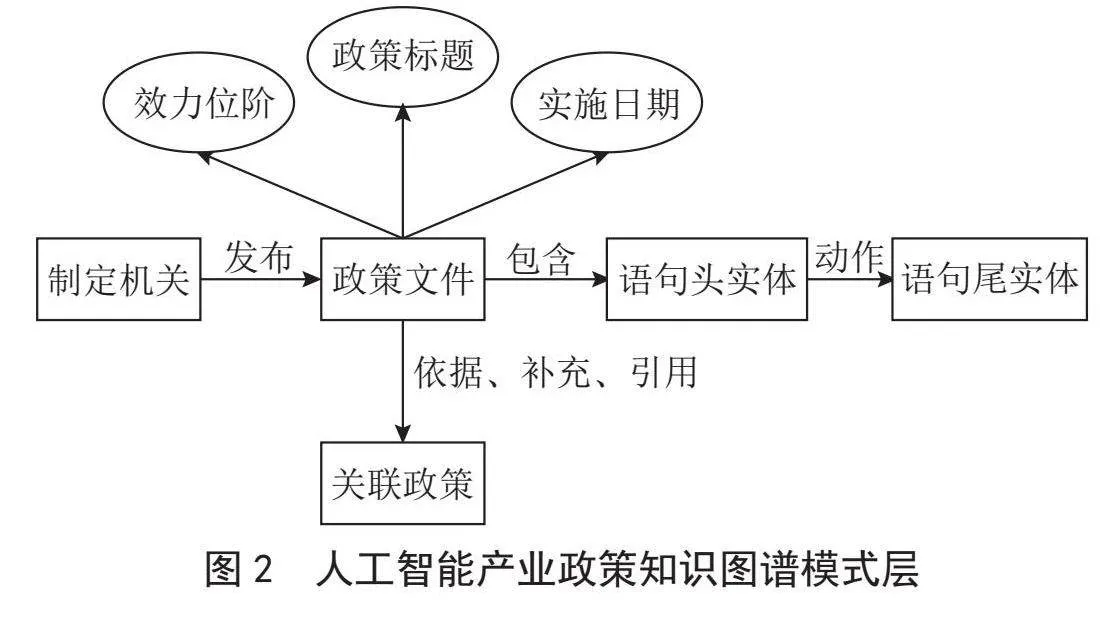
政策文件层面的实体主要为:政策文件、制定机关、关联政策。制定机关与政策文件之间的关系为:发布。政策文件与关联政策之间的关系有:依据、补充、引用。同时,政策标题实体还包含政策标题、效力位阶、实施日期3个属性。
2.2" 政策内容
深入到政策内容中,政策文本必然涉及许多实体,包含多个政策对象,本文将对政策文本进行语义分析,从中抽取实体关系三元组。实体对应政策句子中的名词,实体之间的关系通常是以动词为主的动作关系,例如“加强”“发展”,具体的实体关系三元组抽取流程将在下文详细阐述。综上所述,构建人工智能产业政策知识图谱模式层如图2所示。
3" 数据收集与预处理
3.1" 数据收集
行业知识图谱强调知识的专业性,因此对于数据的质量有更高的要求,收集的政策既要尽可能全面,又要保证完整准确、与相关主题契合度高。本文选择北大法宝数据库作为数据源,从“人工智能”专题的国家层面政策之中进行筛选,着重选取与“人工智能”话题相关性强的政策,获取的数据包含政策标题、时效性、效力位阶、制定机关、实施日期和政策正文,政策文本原网页如图3所示。
3.2" 数据预处理
首先,对获取到的政策正文,按照时效性对已经失效的政策予以剔除,并进一步采用Python正则表达式去除其中的序号(如“(一)”“12.”)、多余空格、换行符等无效内容,而后保存在同一个csv文件中。最终经过统计,共收集到有效政策393篇。其次,对规范后的政策文本进行分句操作,经过分句后,共得到政策句子46 245条。最后,需要对人工智能产业政策文本进行分词操作,人工智能属于新兴产业,伴随产业发展出现了一些专有名词,本文将“语音识别”“计算机视觉”“专家系统”“增强学习”等247个专有名词整理成用户词典,使用LTP工具,完成分词任务。
4" 知识图谱数据层设计
知识抽取是知识图谱数据层构建过程中的一个重要流程,具体地,从非结构化的政策文本中抽取出需要的结构化数据,知识抽取包含实体抽取、实体属性抽取和实体间关系抽取。在本章第一节的数据收集与预处理阶段,政策标题、制定机关等部分数据已经为结构化数据,可以直接使用。
4.1" 关联政策抽取
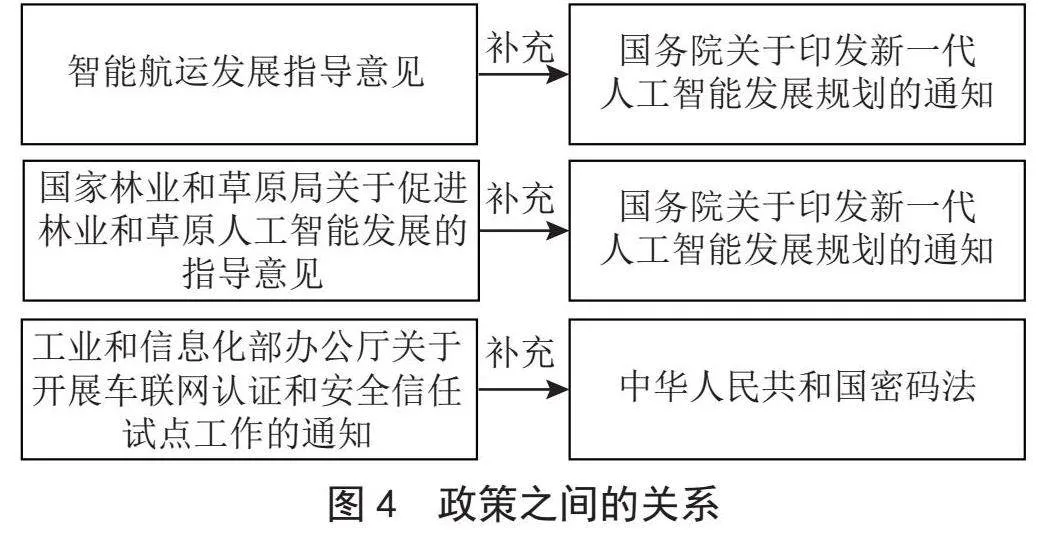
关联政策的抽取,可以使用Python正则表达式。在观察多篇政策文本后,可以得到如下规律:在政策文本中,在使用“《》”时,绝大部分是提及其他的政策;在关联政策的标题中,会有“方案”“规划”“办法”“条例”等标志词;政策全称的字数通常不会太短,字数不会少于6个字,只有在重复提及某个政策使用简称时,字数才会少于6,例如“《条例》”“《纲要》”。基于这些规律,提取的具体步骤可以设计为:首先识别文本中的“《》”,得到书名号之间的字符串;再检测字符串中是否包含相关的标志词;最后检测字符串的长度,只保留字数大于等于6的字符串,再将最终保留下来的字符串作为关联政策予以保存。
政策文件与关联政策间的关系,在抽取完毕后,由人工进行判别,处理后的效果如图4所示。
4.2" 实体关系三元组抽取
政策内容知识图谱的构建主要是从政策文本中抽取实体关系三元组,政策文本中的实体和关系的数量种类多,无法按照先划分实体关系类型在抽取三元组的方式进行。通过观察多篇政策文本,可以发现,政策文本中的语句鲜明的特点:从句类上来看,陈述句占绝大多数;从句型上来看,语句中有相当一部分的无主句;此外政策文本简洁凝练、用词专业。因此本文提出一种基于语义分析的人工智能产业政策知识抽取方法,使用语义角色标注和依存句法分析的方式,设计相应的抽取规则,从文本中直接抽取实体关系三元组。
4.2.1" 语义角色标注
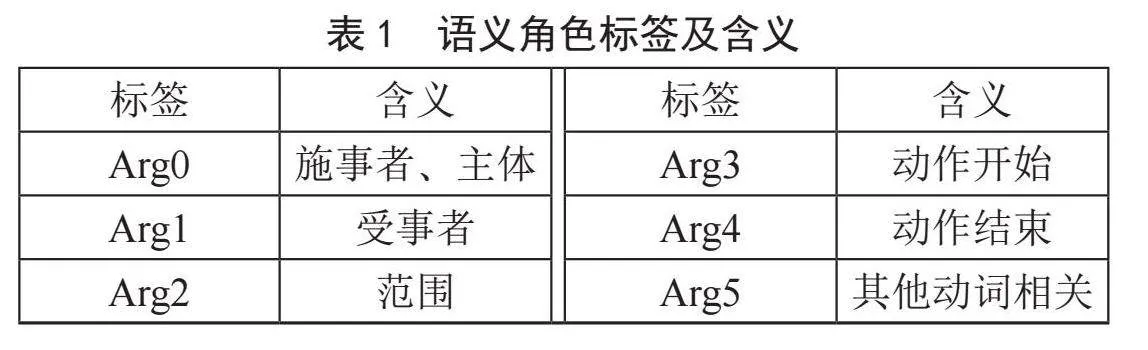
语义角色标注是以句子为单位,分析语句中“谓词-论元”结构。具体地,语义角色标注就是要针对句子中的谓语,研究句子中其他各成分与谓语之间的关系,并以不同的标签来描述关系的类型。其中,核心的语义角色有6种,标签和具体含义如表1所示。
以“制造业企业提高信息化水平”为例,在该句子中,施事者是“制造业企业”,语义角色标签为Arg0;受事者是“信息化水平”是受事者,语义角色标签为Arg1。依据语义角色标注的结果,可以抽取“施事者-谓语-受事者”作为实体关系三元组,上述例子抽取后得到的结果为“(制造业企业,提高,信息化水平)”。
上文提到,在政策语句中,包含着相当一部分无主句,无主句是一种没有主语但仍然可以清晰完整地表达句意的句子,政策中出现的部分无主句如表2所示。
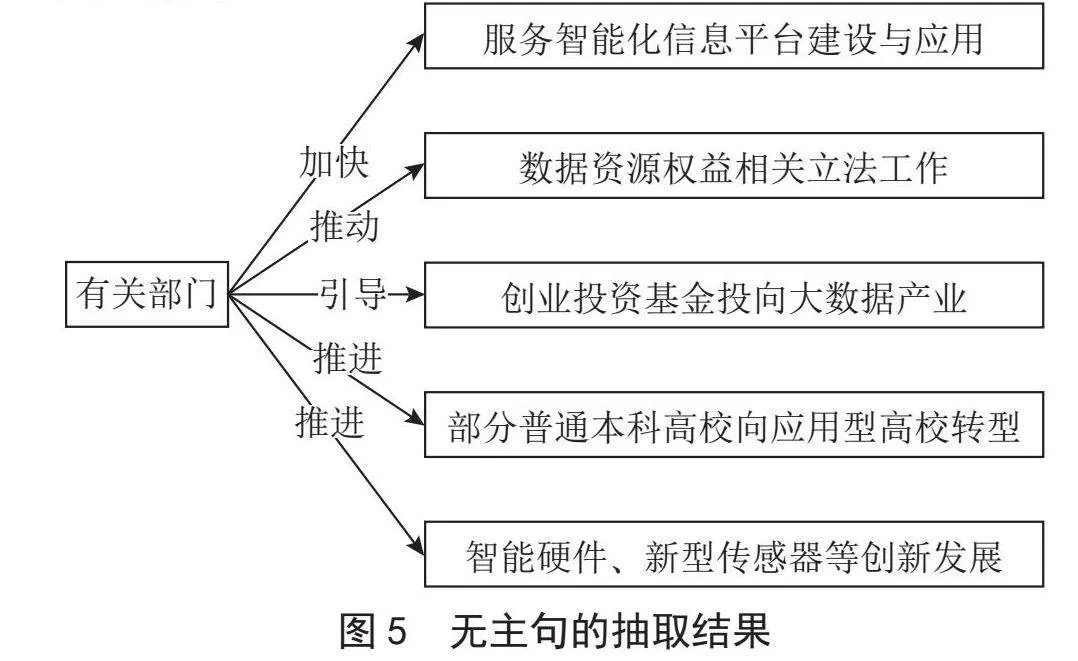
从上述例子中可以看出,无主句是具有实际含义的,需要从中抽取实体关系三元组。无主句以动词为核心,强调动作和事物发展,而不在于“谁”实施了这一动作,在政策中,可以将这类句子的主语直接理解为“有关部门”。因此在语义角色标注的结果中,只有受事者Arg1的标签,而没有施事者Arg0的标签,考虑为无主句,在抽取实体关系三元组时,将头实体统一命名为“有关部门”,上述例子最终的抽取结果如图5所示。
此外,一些修饰谓语动词的状语会表达否定的含义,如果不考虑这些状语,可能会完全反转政策所要表达的意思。以“服务提供商不允许违规收集个人信息”为例,其中的“不”做状语修饰谓语动词“允许”,在不考虑状语的情况下,得到的实体关系三元组会是“(服务提供商,允许,违规收集个人信息)”,这与政策所要传达的意思完全相反。在政策中,表达否定的状语主要有10种,分别为“不”“非”“没”“没有”“不用”“未”“别”“不必”“无须”和“勿”。如果在抽取三元组时,修饰核心动词的状语属于以上10种词语,则将其与动词合并作为关系词。
4.2.2" 依存句法分析
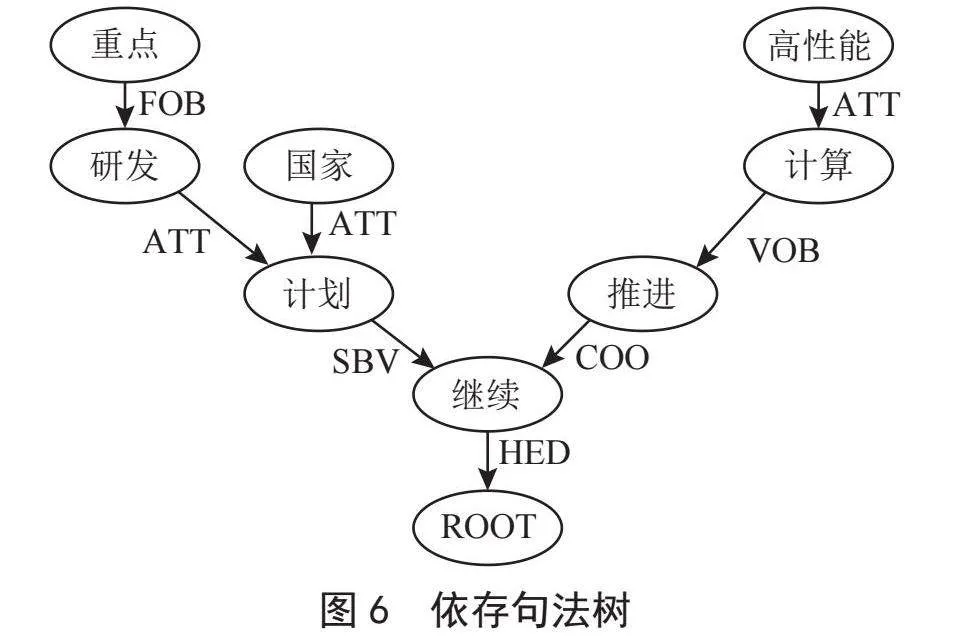
语义角色标注不一定能完整获取到所有的实体关系三元组,需要基于依存句法分析的结果进行补充。依存句法分析是分析句子的语法结构,研究句子中各词语之间的语法联系,并以树的形式表达。当一个句子的所有词语的依存关系全部被分析以后,就可以得到该句子的一棵依存句法树。以政策句子“国家重点研发计划继续推进高性能计算”为例,经过依存句法分析后,该句子的依存句法树如图6所示。
基于依存句法分析的抽取流程如下:
1)根据词性标注的结果,对于标注为动词的词语,若在依存句法树中,以它为根节点的子树里同时存在主谓关系和动宾关系,首先根据主谓关系找到头实体,再根据动宾关系找到尾实体,最后判断核心动词是否存在并列动词,若存在,则将其与核心动词合并抽取,最后形成由主语、核心动词(+并列动词)、宾语组成三元组。
2)子树中出现主谓关系和介宾关系,则以介宾关系寻找尾实体。假若核心动词同时存在动补结构,则需要将核心动词与其补语合并抽取,最后形成由主语、核心动词(+补语)、宾语构成的三元组。
3)当主语和宾语与其他词语存在定中关系,则需要找到修饰主语或宾语的定语,对三元组的头实体和尾实体进行扩展,以便让三元组能描述更加准确的含义。
4)同样,考虑修饰核心动词的表达否定含义的状语,将其与核心动词合并作为关系词。
4.3" 知识筛选
在对人工智能产业政策进行知识抽取后,会得到大量的实体关系三元组,但并非所有的三元组都有包含政策的重要信息,为保证后续人工智能产业政策知识图谱的质量,需要对得到的三元组进行筛选。对于知识图谱的使用者,其作为受政策影响的群体,主要关心政策发挥作用时所指向的对象,即政策客体。根据公共政策理论,政策客体包含特定的政策问题和目标群体,其中,政策问题是引起政府关注并采取行动的社会问题,目标群体是政策直接作用和影响的社会群体[12]。
从一篇政策文本上来看,其核心内容也总是围绕着特定的政策问题和目标群体进行论述,提出具体的处理原则和行动方案。因此,保留涉及政策客体的三元组,可以最大程度过滤无价值的三元组,保留政策中的关键信息。
由于政策客体数量多,全部采用人工标注的方式效率很低。本文使用清华大学发布的开源大语言模型ChatGLM-6B[13-14]对政策文本中的政策客体进行识别并提取。目前,对于大语言模型,可以使用已经训练好的预训练模型,在不同的应用场景下,提供少量的数据用以微调,即可获得良好的效果。本文先使用人工的方式提取了3 060条政策句子中的政策客体用于微调工作,微调所用数据的形式如图7所示。将微调后的模型用于提取政策正文中的政策客体,对于每一篇政策,将实体关系三元组与该政策所包含的政策客体进行对比,若尾实体中涉及政策客体,则保留,否则,予以剔除。
4.4" 知识融合
在政策内容知识图谱的构建过程中,经过知识抽取得到实体与实体间关系。由于关系的词汇是从政策文本中直接提取的,部分关系虽然有不同的名称,却表达了相同的意思,例如“推动”和“推进”,“鼓励”和“激励”,“反映”和“反映出”等。因此,需要对表达意思相同的关系进行合并,消除冗余。
本文采用余弦相似度的方法完成实体间关系进行合并,以获得更加简洁、清晰的人工智能产业政策知识图谱。在数据预处理阶段,已经完成文本分词工作,使用Gensim库中Word2Vec方法训练词向量。最后计算不同关系词汇之间的余弦相似度,其计算式如式(1)所示。
(1)
其中,S表示关系词汇之间的相似程度,A和B表示关系词汇的词向量。余弦相似度越大,说明两个词语之间的差异越小,即两个词语越相似。借鉴已有的研究,将阈值设置在0.8时,融合效果最佳[15],关系合并后得到的部分结果如表4所示。
5" 知识图谱应用研究
构建人工智能产业政策知识图谱是将政策中的知识进行细粒度化的处理,其最终目的是实现对政策的可视化查询和信息匹配,为企业等用户了解政策提供帮助。本文采用Neo4j数据库来存储抽取的实体、属性和关系。Neo4j是一个高性能的NoSQL图形数据库,它将结构化的数据存储在图上,因而具有强大的可视化能力,Neo4j也是目前使用最广泛的图数据库[16]。Neo4j自带Cypher语言,可以方便地实现对知识图谱的创建、更新和可视化查询。本文的实体、关系数量较多,因此将实体及其属性、实体间关系按照一定的格式存储在CSV文件中,使用Cypher语言中的LOAD CSV语句直接导入,最终得到人工智能产业政策知识图谱。
5.1" 政策的实体关系查询
Neo4j同样可以使用Cypher语言查询政策实体、实体属性,并以可视化的方式展示实体间的关系,可以高效地获取政策关键信息,也可以用于政策文献研究,梳理政策之间关系、反映政策演进过程、预测政策热点趋势。例如,在知识图谱中检索某一篇政策,可以使用“match (m:政策文件)-[r:`包含`]-gt;(n) where m.标题 = “国务院关于印发新一代人工智能发展规划的通知”" return m,r,n limit 20”语句查询该政策中的实体关系三元组。由于节点数量过多,使用limit子句限制显示节点的数量为20,查询结果如图8所示。查询结果中,不同类型的实体以不同颜色的节点区分,节点之间的连线表示实体间的关系,鼠标单击某一实体可以查看实体属性信息,在查询结果中可以清楚地获悉到,国家超前布局人工智能的基础研究,推动脑科学研究、军民科技创新成果转化、人机协同等领域,人工智能将作为经济发展新引擎,最终实现社会生产力的整体跃升。
以语句“match (n:关联政策)-[r]-gt;(m:政策文件) where m.标题 = “国务院关于印发新一代人工智能发展规划的通知” return n”查询该政策的被引用情况,查询结果如图9所示。结果显示,有多篇科技部的回函以该政策为依据,这些回函均是支持地方建设国家新一代人工智能创新发展试验区,说明该政策在发展人工智能产业的政策体系中具有重要的地位。
5.2" 企业的政策信息服务
信息服务是利用计算机和现代通信技术,对信息进行收集和处理,使之转化为方便利用的形式并进行存储,按需向用户提供有价值的信息。近年来,信息服务也在朝着智能化、精细化的方向不断发展。政策的扶持可以对企业的发展起到很大的帮助作用,而企业难以有合适的方法及时获取到政策信息,结合知识图谱的政策信息服务可以智能化、精细化地为企业提供政策信息服务。
政府部门或政策信息服务的提供商,可以提供的服务有:
1)政策信息查询。企业根据自身的需要,以关键词查询或提问的方式获取政策信息。
2)智能信息推荐。通过企业提供的各项信息,如公司性质、业务范围、经营概况等,为企业绘制用户画像,进而实时地为企业客户提供政策情报。同时,处于产业链当中一环的企业,对行业上下游的信息往往比较关注,知识图谱可以充分发挥关联关系挖掘的作用,向企业提供上下游的政策动向,从而帮助企业及早调整战略规划。
K公司是亚太地区知名的智能语音和人工智能上市企业,一直从事智能语音、计算机视觉、自然语言理解等核心技术研究,积极推动人工智能产品和行业应用落地。以该公司的智能语音和计算机视觉两项业务为例,通过语句“MATCH (m)-[r:关系]-gt;(n:政策客体) WHERE n.政策客体 =~ .*智能语音.* or n.政策客体 =~ .*计算机视觉.* return m,r,n”,可以得到与智能语音、计算机视觉相关的政策信息,查询结果如图10所示。
6" 结" 论
本文提出一种人工智能产业政策知识图谱的构建流程,内容主要分为以下三个部分:从政策文件和政策内容两个层面考虑,设计了人工智能产业政策知识图谱模式层;根据政策文本特点,设计了一套基于语义分析的三元组抽取方法,抽取政策文本中的实体关系三元组;借助大语言模型识别政策客体用于筛选实体关系三元组,计算关系词向量之间的余弦相似度实现关系的合并对齐。将所有的实体、实体属性和实体间关系导入Neo4j图数据库中,构建人工智能产业政策知识图谱,并研究了知识图谱在实体关系查询和企业信息服务领域的应用,可以帮助企业更好地获取所需的政策信息。由于人工智能产业政策还在持续新增,后续的研究中,将进一步研究如何实现对政策知识库的动态更新,以实现更高效的政策分类管理和更精准的政策检索。
参考文献:
[1] 付雷杰,曹岩,白瑀,等.国内垂直领域知识图谱发展现状与展望 [J].计算机应用研究,2021,38(11):3201-3214.
[2] 于皓,张杰,吴明辉,等.领域知识图谱快速构建和应用框架 [J].智能系统学报,2021,16(5):871-884.
[3] 秦玥.面向创业领域科技论文的知识图谱构建与应用研究 [D].长春:吉林大学,2018.
[4] 刘东方,杨思帆.我国教师教育研究的热点领域与知识基础——基于2001年以来CSSCI学术论文的知识图谱分析 [J].教育理论与实践,2019,39(13):37-40.
[5] MURALI L,GOPAKUMAR G,VISWANATHAN D M,et al. Towards Electronic Health Record-based Medical Knowledge Graph Construction, Completion, and Applications: A Literature Study [J].Journal of Biomedical Informatics,2023,143:104403.
[6] 霍朝光,钱毅,祁天娇.基于开放公文的新冠肺炎政策知识图谱构建与分析 [J].档案学通讯,2021(2):53-62.
[7] 师博,常青,张良悦.中国数字经济发展的政策演进与理论研究脉络 [J].技术经济,2022,41(8):1-10.
[8] 周成.“双碳”政策的知识图谱、研究热点与理论框架 [J].北京理工大学学报:社会科学版,2023,25(4):94-112.
[9] 董天宇.文旅融合政策知识图谱的构建与应用 [D].大连:辽宁师范大学,2023.
[10] 刘科.基于知识图谱的创新创业政策服务研究 [D].北京:北京交通大学,2021.
[11] 揣子昂,耿骞,潘慧瑶,等.产业政策知识图谱的自动化构建 [J].情报工程,2022,8(3):28-51.
[12] 杨宏山.公共政策学 [M].北京:中国人民大学出版社,2020.
[13] DU Z X,QIAN Y J,LIU X,et al. GLM: General Language Model Pretraining with Autoregressive Blank Infilling [J/OL].arXiv:2103.10360 [cs.CL].(2021-03-18).https://arxiv.org/abs/2103.10360?context=cs.
[14] ZENG A H,LIU X,DU Z X,et al. GLM-130B: An Open Bilingual Pre-trained Model [J/OL].(2022-10-05).https://arxiv.org/abs/2210.02414.
[15] 刘勘,徐勤亚,于陆.面向营商环境的知识图谱构建研究 [J].数据分析与知识发现,2022,6(4):82-96.
[16] 徐增林,盛泳潘,贺丽荣,等.知识图谱技术综述 [J].电子科技大学学报,2016,45(4):589-606.
作者简介:赵晋世(2001—),男,汉族,湖南衡阳人,硕士在读,研究方向:知识图谱、自然语言处理、知识挖掘;沈永珞(1979—),男,汉族,湖北武汉人,副教授,博士,研究方向:自然语言处理、智能计算、智能系统设计与应用。