
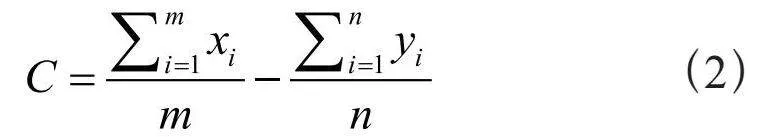

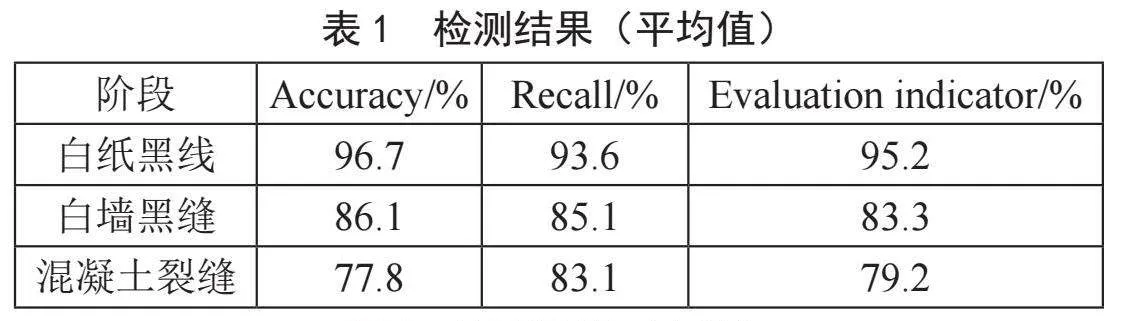
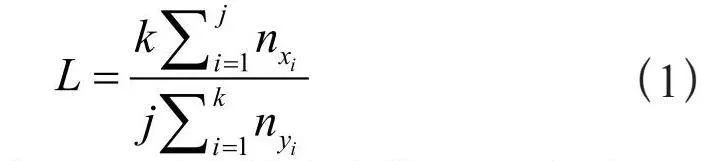



摘" 要:文章提出了一种渐进式全自动标注算法,分三个阶段标注裂缝样本:首先,在白纸上画线绘制假裂缝,提取裂缝轮廓制作标签,训练生成一级权重文件;利用一级权重文件识别白墙上的裂缝,优化掩膜后制作标签,训练生成二级权重文件;最后,用二级权重文件分批检测混凝土裂缝,优化并提取掩膜轮廓,生成标签并循环训练生成三级权重文件。训练后Mask RCNN模型对三类图像的识别综合评价指标(Evaluation indicator)分别为95.2%、83.3%、79.2%,识别率较高,可用于裂缝的快速识别。
关键词:裂缝;渐进式自动标注;轮廓提取;深度学习
中图分类号:TP391.4" 文献标识码:A" 文章编号:2096-4706(2024)24-0111-05
Research on Crack Image Recognition and Progressive Automatic Annotation Method Based on Mask RCNN
QIU Xianzhi1, LI Denghua2,3, GUO Linxiao4, XU Haitao1, DING Yong4
(1.National Energy Group Xinjiang Kaidu River Basin Hydropower Development Co., Ltd., Korla" 841009, China;
2.Nanjing Hydraulic Research Institute, Nanjing" 210029, China; 3.Key Laboratory of Failure Mechanism and Prevention and Control Technology of Earth-Rock Dam, Ministry of Water Resources, Nanjing" 210029, China; 4.Nanjing University of Science and Technology, Nanjing" 210094, China)
Abstract: This paper presents a progressive fully automatic annotation algorithm, which annotates crack samples in three stages. Firstly, it draws fake cracks by drawing lines on white paper, and extracts the crack contours to make labels, and then trains to generate the first-level weight file. Secondly, it uses the first-level weight file to identify the cracks on the white wall, and optimizes the mask to make labels, and then trains to generate the second-level weight file. Finally, it utilizes the second-level weight file to conduct batch detection of concrete cracks, optimizes and extracts the mask contours to generate labels, and then trains cyclically to produce the third-level weight file. After training, the comprehensive evaluation indicators of the Mask RCNN model for the recognition of three types of images are 95.2%, 83.3%, and 79.2%, respectively. The detection rate is relatively high and this model can be applied to the rapid recognition of cracks.
Keywords: crack; progressive automatic annotation; contour extraction; Deep Learning
0" 引" 言
近年来,深度学习领域在裂缝检测方面飞速发展。Zhang等人[1]将裂缝图像分割成小块进行背景分割;Zeiler等人[2]构建基于区域的快速卷积神经网络,只需0.03 s即可检测出混凝土裂缝部位;Yokoyama等人[3]将训练样本分为5类,其神经网络识别准确率稳定在79%。
裂缝测量精准度取决于样本的质量与数量,大量的裂缝样本让操作者在标注过程中付出大量的时间和精力,Xu等人[4]在CNN+RNN模型基础上,提出了结合注意力机制的图像自动标注算法,但其识别框包含大量背景信息,无法精确分割目标。Maier-Hein等人[5]用人群算法来标注内窥镜图像,在医学图像上获得了很高的准确率,但没有证明算法的普适性。Zhou等人[6]提出了Models Genesis模型,模型的性能虽然提高但也学到很多与背景有关的冗余信息。
如何在节约标注样本集时间的同时,提高模型检测的准确度,是当前研究的重点问题[6-17]。本文提出一种渐进式全自动标注的学习方法,将形态学与深度学习技术相结合,利用形态学的特征为深度学习做牵引,将白纸黑线、白墙黑缝、混凝土裂缝优化后的检测结果转化为标签,迭代过程中反复训练,最终完成裂缝图像的精确分割。
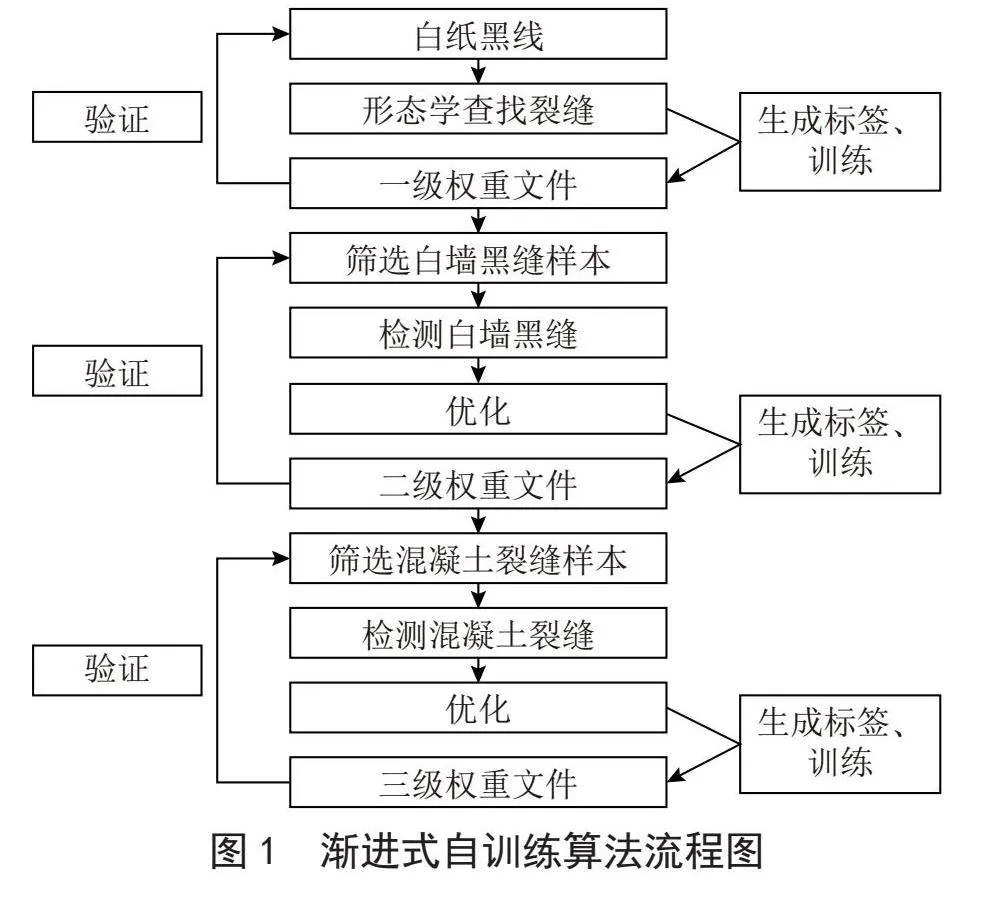
1" 技术路线
技术路线如下:
1)第一阶段,在白纸上手绘黑线条模拟裂缝,将样本裁剪成固定的尺寸,通过二值化、腐蚀、膨胀等预处理方法消除内部存在的空隙,借助边缘检测寻找其轮廓,整合轮廓与样本等信息,生成标签文件进行训练后获得一级权重文件。
2)第二阶段,利用一级权重文件识别白墙上的裂缝,计算背景区域与检测区域像素点RGB颜色分量的欧式距离,优化掩膜后获取裂缝坐标;提取裂缝轮廓和裂缝图片信息,自动制作裂缝标签进行训练后生成二级权重文件。
3)第三阶段,将白墙黑缝与混凝土背景进行风格迁移,改变原标签文件中的base64编码后进行训练,再用训练后的二级权重文件检测混凝土裂缝,优化并提取掩膜,生成标签,训练后再识别下一批裂缝,如此往复,最终生成三级权重文件。
渐进式自训练算法流程如图1所示。
2" 标签制作方法
利用上一阶段的权重文件检测裂缝得到掩膜坐标,再进行优化。通过一系列操作将优化后的掩膜转化为新的JSON文件,首先要对检测到的区域提取出轮廓坐标并按照顺序进行排列,再输入裂缝图片相关信息。
2.1" 掩膜轮廓提取算法
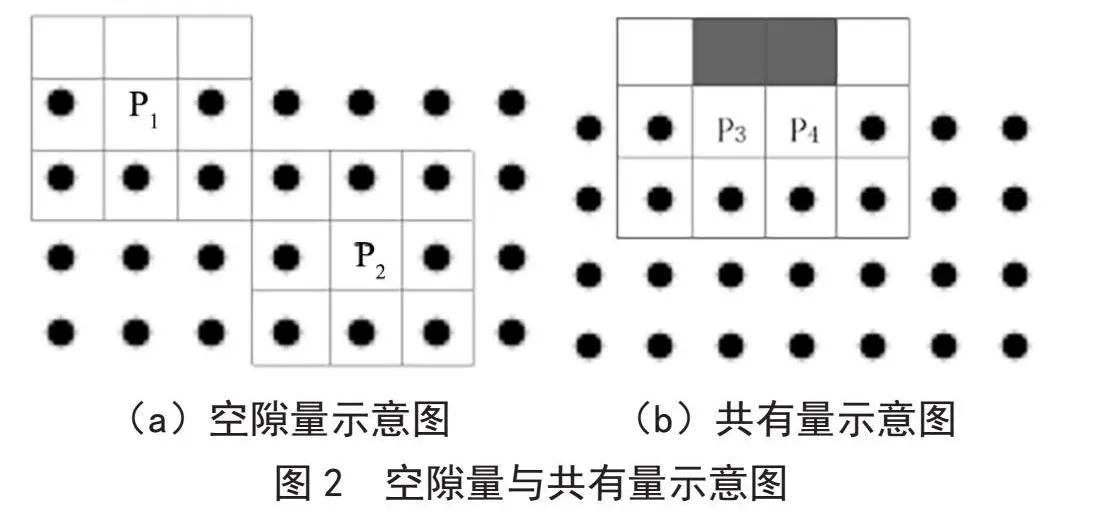
掩膜坐标是由一系列坐标点组成,掩膜轮廓提取就是对一系列坐标点进行分析,去掉内部坐标点,只保留轮廓坐标点。
空隙量是某一特定坐标点周围8个点未被其他坐标点占用的数量。如图2(a)所示,轮廓上某点P1周围有3个空点,空隙量为3;内部某点P2周围8个点没有空点,空隙量为0。共有量为相邻两个掩膜坐标点共有的空点数量。如图2(b)所示,黑色区域表示P3和P4拥有2个共同的空点,共有量为2。
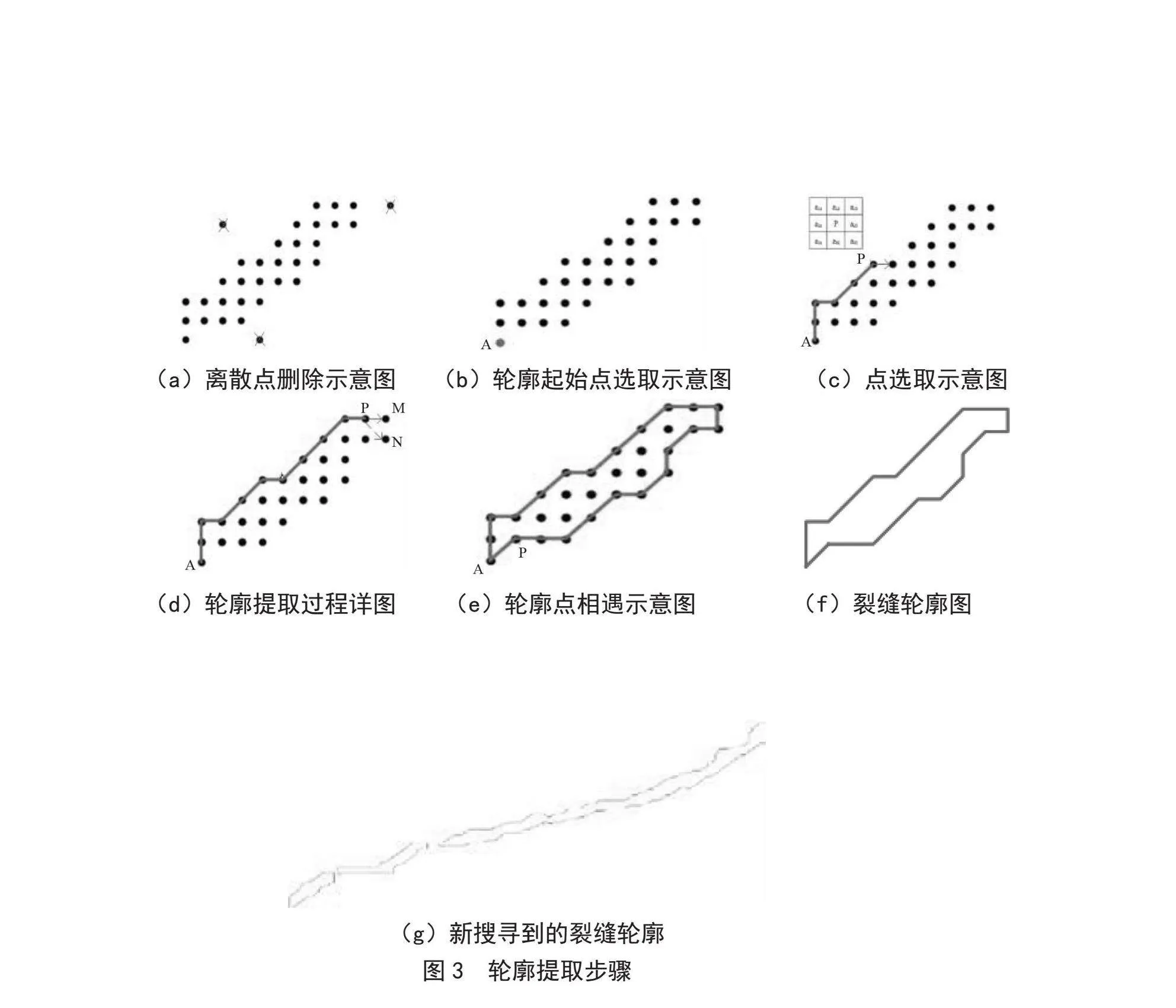
轮廓提取遵循如图3所示的原则。查找轮廓前,遍历掩膜点,需删除集合中离散(即空隙量大于6/8)的点,如图3(a)所示;轮廓起始点A的选取原则依次为:空隙量最大、x最小、y最小,如图3(b)所示;在P四周寻找空隙量最大的点作为下个点,新找到的点不可与已有点重复,如图3(c)所示;若P点下一个点存在2个最大空隙量都相等的M点和N点,选择与P共有量大的M点,如图3(d)所示;当轮廓点P再次回到A时,轮廓寻找结束,如图3(e)所示;保存轮廓,并删除原集合中轮廓内部坐标,如图3(f)所示;寻找原文件中的坐标点,绘制轮廓,直至坐标点全部被删除,如图3(g)所示。
2.2" 生成JSON文件
首先统计闭合轮廓的数量,根据其建立起标签固定框架。文件主要分为五个部分:Labelme版本信息、轮廓坐标、图片路径、编码及尺寸。将格式调整后的轮廓坐标、图片路径与它的格式编码按照标签固定结构导入JSON文件中。以二进制的形式读取图片,获取原始字节码,转化为base64编码,插入JSON文件相应位置。最后将完整的JSON文件放入Mask RCNN模型中,在上一级权重文件的基础上继续训练,形成新的权重文件。
3" 训练过程
3.1" 白纸黑线阶段
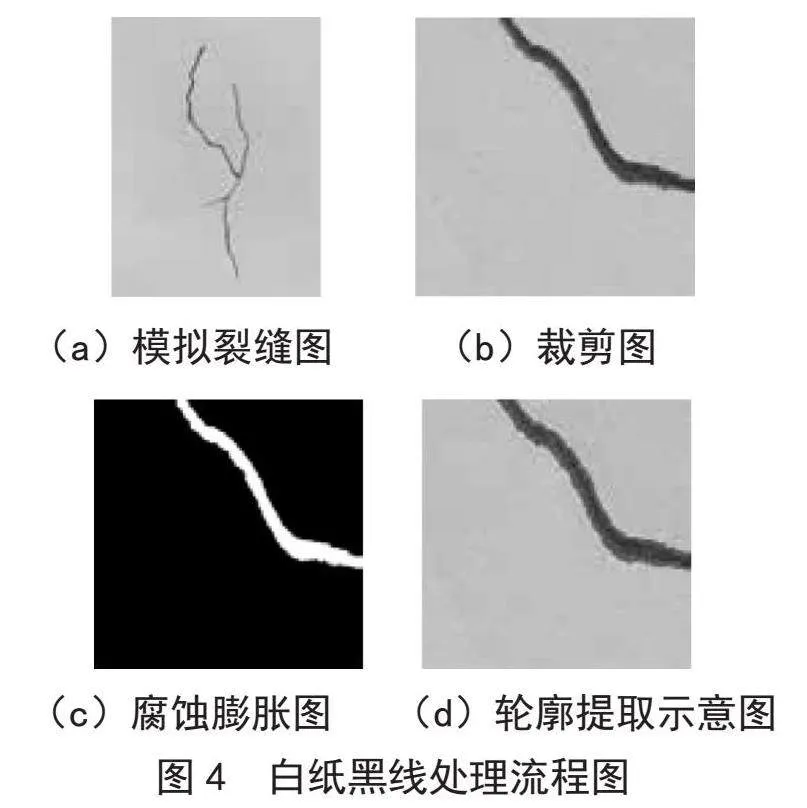
如图4(a)所示,在白纸上用12B铅笔绘制黑色线条模拟墙体上的裂缝并拍照。将拍摄的原图裁剪成512×512(图4(b))后得到20 000张图片,二值化处理后,对像素点做腐蚀、膨胀操作(图4(c)),再寻找裂缝的轮廓(图4(d));将每张图片及其对应的JSON文件放入模型Mask RCNN进行训练得到一级权重文件。
3.2" 白墙黑缝
白纸黑线与白墙黑缝在外观上具有相似性,检测结果表明模型在两类样本集上可以过渡,利用一级权重文件顺利筛选并检测出白墙中的裂缝。将优化后的掩膜坐标通过标签算法转化成JSON文件,放入模型中继续训练,最后生成二级权重文件。
3.2.1" 标签筛除
在裂缝检测过程中,对于阴影部分、砂浆处的坑洼常常存在一些误检的情况,对于误检的结果,常采用以下筛除原则:
删除置信度小于0.95的检测结果,如图5所示。
删除识别掩膜数小于750的检测结果,如图6所示。
旋转坐标系,将掩膜坐标分别投影到x、y轴上,计算二者个数均值的比值L,计算为:
(1)
其中,nxi表示x = xi时坐标的个数,nyi表示y = yi时坐标的个数。
若L接近1,则筛除误检出的块状检测结果,如图7所示。
剔除宽度大于100像素的裂缝,如图8所示。
图像灰度化后,计算识别结果与背景像素平均值的差值C,计算式为:
(2)
其中,m表示背景像素点个数,n表示识别出的像素点个数,xi表示背景中第i个像素点的像素值,yi表示识别结果中第i个像素点的像素值。
当C在[-10,10]范围内则找出误检或颜色太淡的裂缝,执行剔除操作,如图9所示。
3.2.2" 优化算法
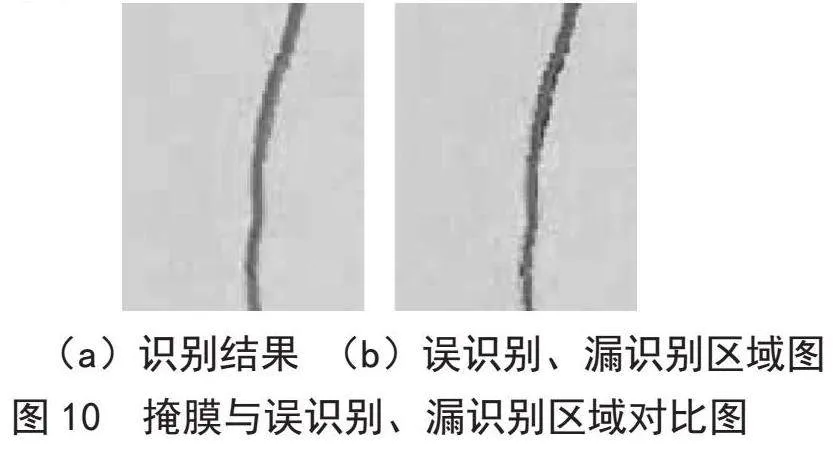
借助原图像的RGB三通道分量,优化裂缝识别结果如图10(a)所示。将识别结果划分为三部分:识别准确区域(红色)、误识别区域(蓝色)、漏识别区域(黄色),如图10(b)所示。
矩形框内所有像素点分为裂缝、背景区域两部分,以两部分像素点RGB三通道分量的平均值作为后续判别指标。裂缝区域像素点RGB三通道颜色分量平均值计算公式为:
(3)
(4)
(5)
其中,、、分别表示裂缝区域像素点RGB三通道颜色分量中各通道颜色分量的平均值;NUMc为裂缝区域像素点的总个数;Rci、Gci、Bci分别表示裂缝区域第i个像素点各通道的颜色分量。下标c表示裂缝,b表示背景。同理可得背景区域像素点RGB三通道颜色分量平均值。
3.2.3" 对掩膜区域进行筛选
遍历掩膜区域所有像素点,计算各像素点RGB三通道颜色分量RGB值与裂缝区域像素点平均RGB值、背景区域像素点平均RGB值的欧式距离,计算式为:
(6)
(7)
其中,Dc、Db分别表示所选像素点与裂缝区域、背景区域像素平均RGB值的欧式距、离;R0、G0、B0分别表示所选像素点R、G、B三通道颜色分量。若Dc>Db,此点与背景区域像素点平均值欧式距离更小,即此点RGB值与背景区域更接近,将此点剔除;反之,则保留此点。遍历所有像素点,获得新的掩膜坐标。
3.2.4" 对掩膜区域进行扩张
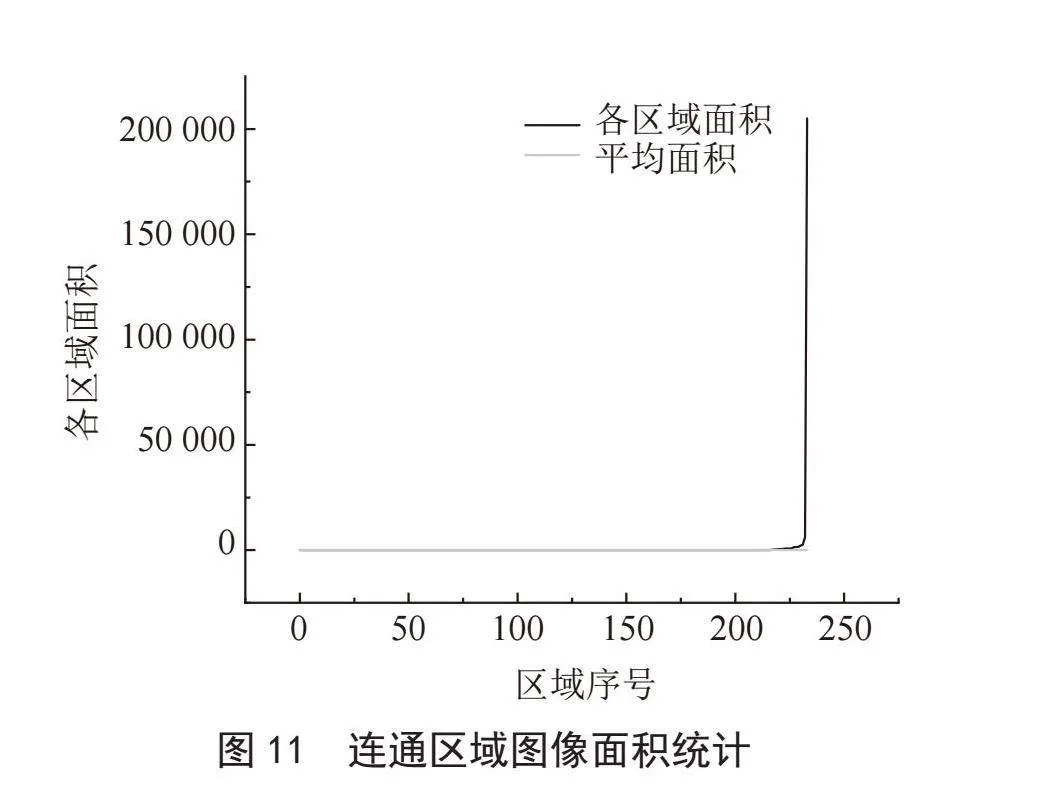
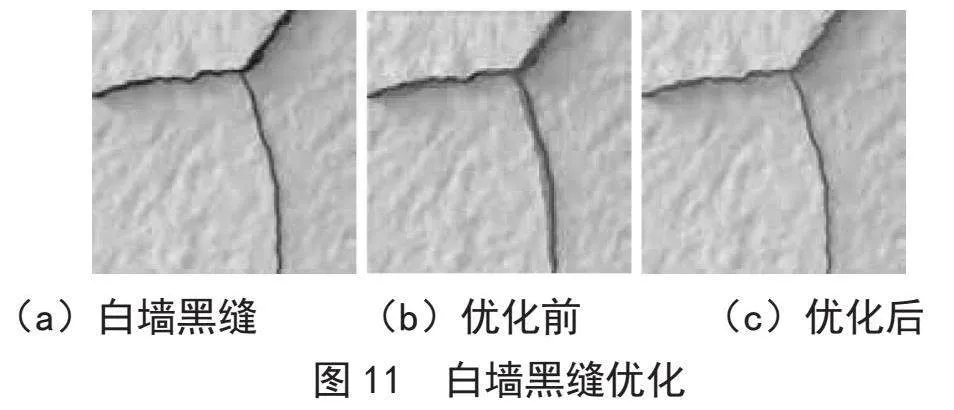
将掩膜像素点按边界向外膨胀,获得新增像素点后按照上节方法判断是否保留。每一次筛选、扩张后,重新计算掩膜内外颜色分量的平均值。当迭代前后掩膜坐标集一致,即可认为该次迭代未对掩膜区域修正,停止迭代,得到优化后的最终裂缝掩膜。原图、优化前、后,如图11所示。
3.3" 混凝土裂缝
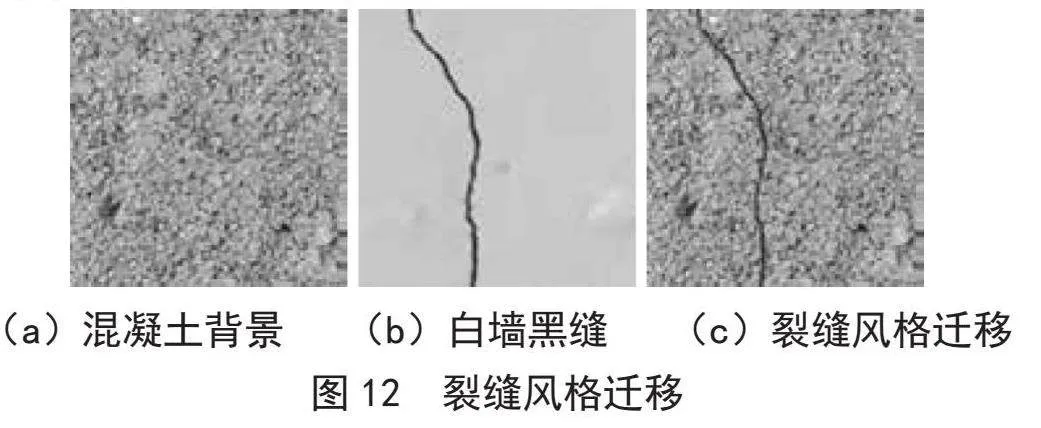
首先对素混凝土图片裁剪,筛选出2 000张512×512无裂缝的背景图像,如图12(a)所示;如图12(b)所示,用二级权重文件检测白墙黑缝,获取裂缝掩膜坐标,并复制到无裂缝的背景图片中;对于原白墙黑缝JSON标签文件的修改,主要是替换原文件中图像编码,并对文件路径与标签文件名进行调整,轮廓坐标区域保持不变,新生成的图像如图12(c)所示。
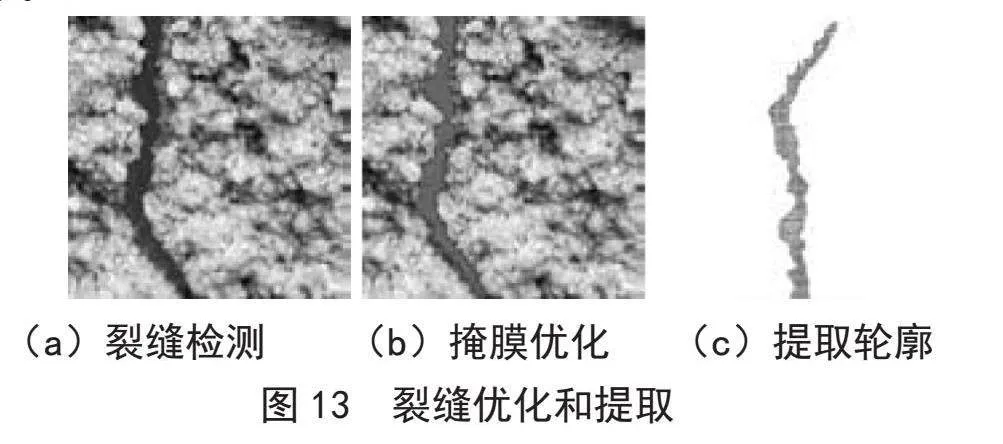
成功从白墙黑缝过渡到混凝土裂缝后重复上一阶段:筛选、进行检测(图13(a))、优化(图13(b))、提取掩膜轮廓(图13(c))和图片信息、标签转化、训练。
4" 评价指标
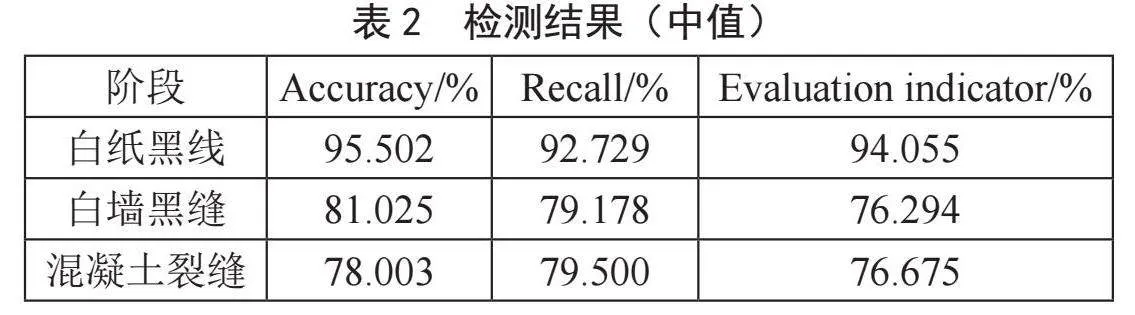
将数据集分为白纸黑线、白墙黑缝和混凝裂缝三种类型,80%的图像为训练集,20%的图像为验证集。检测平均值和中值分别如表1、表2所示,
5" 结" 论
优化算法可以进一步优化裂纹掩模以获得完整掩模坐标;选择裂纹的原理可以有效地从背景图像中找到裂缝图像;轮廓提取算法可以提取掩模坐标,自动完成裂纹的标注;边缘检测可以在白纸黑线上准确地找到裂缝轮廓;将白纸黑线数据集训练后获取的一阶权重文件可以过滤和检测白墙裂缝,并将优化后的掩膜坐标转换为新的标签文件;将裂缝掩模坐标转移到混凝土无;裂缝背景图像中,生成新的JSON文件,可以进一步训练模型;通过混凝土裂缝图像自动标注方法获得的模型在建筑裂缝识别中具有良好的识别速度和准确性,仅需0.02 s即可检测出裂缝位置;在裂缝检测精度综合评价指标中,白纸黑线达到95.2%,白墙黑缝达到83.3%,混凝土裂缝达到79.2%。
参考文献:
[1] ZHANG L,YANG F,ZHANG D. Road Crack Detection Using Deep Convolutional Neural Network [C]//IEEE International Conference on Image Processing.Phoenix:IEEE,2016:3708-3712.
[2] ZEILER M.D,FERGUS R. Visualizing and Understanding Convolutional Networks [C]//Computer vision-ECCV 2014.Zurich:Springer,2014:818–833.
[3] YOKOYAMA S,MATSUMOTO T. Development of an Automatic Detector of Cracks in Concrete Using Machine Learning [J].Procedia Engineering,2017,171(Complete):1250-1255.
[4] XU K,BA J,KIROS R. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention [C]//ICML15: Proceedings of the 32nd International Conference on International Conference on Machine Learning.[S.I.]:JMLR,2015:2048-2057.
[5] MAIER-HEIN L,ROSS T,GRHL J. Crowd-Algorithm Collaboration for Large-Scale Endoscopic Image Annotation with Confidence [C]//International Conference on Medical Image Computing and Computer-Assisted Intervention.Istanbul:Springer,2016:616-623.
[6] ZHOU Z,SODHA V,SIDDIQUEE M M R. Models Genesis: Generic Autodidactic Models for 3D Medical Image Analysis [C]//Medical Image Computing and Computer Assisted Intervention-MICCAI 2019.Shenzhen:Springer,2019:384-393.
[7] JIANG L,LI C,WANG S. Deep Feature Weighting for Naive Bayes and its Application to Text Classification [J].Engineering Applications of Artificial Intelligence,2016(52):26-39.
[8] LIU K,GUO Y,WANG S. Semi-supervised Learning Based on Improved Co-training by Committee [C]//International Conference on Intelligent Science and Big Data Engineering.Suzhou:Springer-Verlag,2015:413-421.
[9] SUI Y,WEI Y,ZHAO D Z. Computer-Aided Lung Nodule Recognition by SVM Classifier Based on Combination of Random Undersampling and SMOTE [J/OL].Computational and Mathematical Methods in Medicine,2015:368674(2015-04-06).https://doi.org/10.1155/2015/368674.
[10] KALLENBERG M,PETERSEN K,NIELSEN M. Unsupervised Deep Learning Applied to Breast Density Segmentation and Mammographic Risk Scoring [J].IEEE Transactions on Medical Imaging,2016,35(5),1322-1331.
[11] SHEN W,ZHOU M,YANG F. Multi-crop Convolutional Neural Networks for Lung Nodule Malignancy Suspiciousness Classification [J].Pattern Recognition,2017,61(61):663-673.
[12] KITAGAWA W,INABA A,TAKESHITA T. Objective Function Optimization for Electrical Machine by using Multi-Objective Genetic Programming and Display Method of Its Results [J].IEEE Transactions on Electronics, Information and Systems, 2019,139(7):796-801.
[13] XU Y,JIA Z P,AI Y Q,et al. Deep Convolutional Activation Features for Large Scale Brain Tumor histopathology Image Classification and Segmentation [C]//2015 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).South Brisbane:IEEE,2015:947-951.
[14] BAHROLOLOUM A,NEZAMABADI-POUR H. A Multi-Expert based Framework for Automatic Image Annotation [J].Pattern Recognition,2017,61:169-184.
[15] XU Y Y. Multiple-Instance Learning Based Decision Neural Networks for Image Retrieval and Classification [J].Neurocomputing,2016,171:826-836.
[16] KONG T,YAO A B,CHEN Y R,et al. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:845-853.
[17] HE Y,WANG J,KANG C. Large Scale Image Annotation via Deep Representation Learning and Tag Embedding Learning [C]//ACM on International Conference on Multimedia Retrieval.New York:ACM,2015:523-526.
作者简介:邱先志(1990—),男,汉族,新疆霍城县人,工程师,本科,研究方向:水电站大坝安全管理、水工建筑物安全监测及运行维护。