


摘" 要 :语音增强是语音信号处理的重要分支,在语音识别、语音通信等领域具有重要应用。传统数字信号处理(DSP)方法下的单通道语音增强计算量小,但效果不佳。近年来,深度学习算法大幅提升了单通道语音增强的效果,但往往计算量大,对硬件要求高,难以应用于移动设备或可穿戴设备。针对性能和计算量难以平衡的现状,文章实现了一种低复杂度的基于深度学习的语音增强算法,并在树莓派上进行了实现。该算法采用具有四个隐藏层的循环神经网络(RNN),用于估计理想的临界频带增益,而音高谐波之间的噪声则采用传统音高滤波器处理。实验结果显示,该系统能够有效实现降噪功能,并且性能优于传统的维纳滤波算法。
关键词:语音增强;RNNoise;实时;单通道;树莓派
中图分类号:TN912 文献标识码:A 文章编号:2096-4706(2025)03-0183-06
Research and Implementation of Smart Speech Noise Reduction Algorithm Based on Raspberry Pi
TAO Ran, ZHU Runqian, QIN Yitong, LING Haidong
(School of Communication and Artificial Intelligence, School of Integrated Circuits, Nanjing Institute of Technology, Nanjing" 211167, China)
Abstract: Speech enhancement is an important branch of speech signal processing and has significant applications in fields such as speech recognition and speech communication. The single-channel speech enhancement under traditional Digital Signal Processing (DSP) method has a small amount of computation, but the effect is not satisfactory. In recent years, Deep Learning algorithms have significantly improved the effect of single-channel speech enhancement. However, they usually have a large amount of computation and high hardware requirements, making it difficult to apply them to mobile or wearable devices. In view of the current situation where it is difficult to balance performance and computation, this paper implements a low-complexity Deep Learning-based speech enhancement algorithm and realizes it on a Raspberry Pi. This algorithm adopts a Recurrent Neural Network (RNN) with four hidden layers to estimate the ideal critical band gain, while the noise between pitch harmonics is processed using traditional pitch filters. Experimental results show that this system can effectively achieve the noise reduction function and outperforms the traditional Wiener filtering algorithm.
Keywords: speech enhancement; RNNoise; real-time; single-channel; Raspberry Pi
0" 引" 言
语音增强是语音信号处理的重要分支,目的是从含噪语音信号中分离出带有信息的语音信号。随着科技发展,出现了越来越多的语音场景,如移动通信、语音控制系统、听力辅助等场景,往往会受到环境噪声的干扰,显著降低语音的可懂程度,从而降低人与人之间的交流效率,或是影响系统的识别和控制。并且,数量庞大的听障人群更容易受到信号中噪声的干扰,此时就需要语音增强来提升信号中语音的质量与可懂度。同时,随着语音技术的进步,自动语音识别(Automatic Speech Recognition, ASR)的使用也越来越广,无论是百度等搜索引擎,还是智能家居等交互设备,在复杂环境下的识别率都会大打折扣。因此,有效的语音增强技术对语音技术的发展而言极为重要。
语音增强技术相关的研究已经有了50多年的历史,早期的语音增强算法主要是对带噪语音估计其噪声谱。对于单通道语音增强算法,如谱减法[1]、维纳滤波法[2],对数最小均方误差法[3]等。这些早期的算法具有计算简单、实时性高的优势。然而,考虑到背景噪声的复杂统计特性,噪声谱的估计往往会遇到很多问题。噪声的复杂特性促使人们去借鉴人类的神经推导能力,因而早期有学者提出利用浅层神经网络的非线性模型来学习带噪语音信号在时域以及变换域上到目标语音信号的映射。然而早期的浅层神经网络算法的规模较为有限,其对于具有复杂统计特性的语音信号的拟合能力有限,无法准确表示带噪语音到干净语音之间的映射。并且由于早期缺少合理的训练优化方案,这种有监督学习很容易陷入局部最优解。而当参数继续增加的时候,这一问题会更加严重。
随着深度学习的不断发展与进步,如今流行将深度神经网络应用于整个问题,即端到端的方法[4-7],已经应用于语音识别等方面。虽然许多端到端的系统已经证明了深度神经网络应用于语音信号处理的成功,但这些系统可能不是最优的,存在对系统资源的浪费,在一些降噪算法中,往往要用到几千个神经元和几千万个权值,仅仅为了构成一层神经网络,降噪效果的代价是计算成本和模型本身大小的庞大,硬件的实现必然需要高性能的GPU,难以用于小型设备。小型移动设备如助听器等无法搭载GPU,采用深度学习的降噪算法即使质量高也无法使用,将深度神经网络应用于整个问题,需要非常多的神经元和权值进行模拟,在这里我们需要减少神经网络模拟的部分,从而降低所需的神经元数量,降低算法对硬件算力的要求,因此我们选择RNNoise作为系统的核心算法,在此基础上设计实时单通道语音增强系统。在48 kHz采样率下,不需要GPU,在CPU低功耗状态下也能实现语音增强效果。实验中,该系统对硬件要求低于端到端的语音增强方法,效果明显优于传统维纳滤波法,在树莓派上也可以轻松实现高质量语音增强。
1" 基于RNN的单通道语音增强算法
1.1" RNNoise算法原理
循环神经网络(Recurrent Neural Network, RNN)是一种仿照人类记忆体系创造出的具有短期记忆能力的神经网络,由Elman[8]提出。在RNN中,神经元可以接受其他神经元的信息,也可以接受自身信息,形成环路。同时RNN的记忆特性使其同时被当前时刻的输入与历史输入影响,这使得RNN适合学习数据在时间上的依赖关系,天然适合在时序数据上建模。语音信号数据往往在时间上相关性高,且属于变长序列,因此选择RNN来处理。但是,由于通过随时间反向传播算法来学习,当输入序列较长时,会带来梯度爆炸和消失的问题,LSTM[9-10]通过引入门机制来解决这些问题,像GRU等LSTM变体,可以基本解决RNN的长程依赖问题。
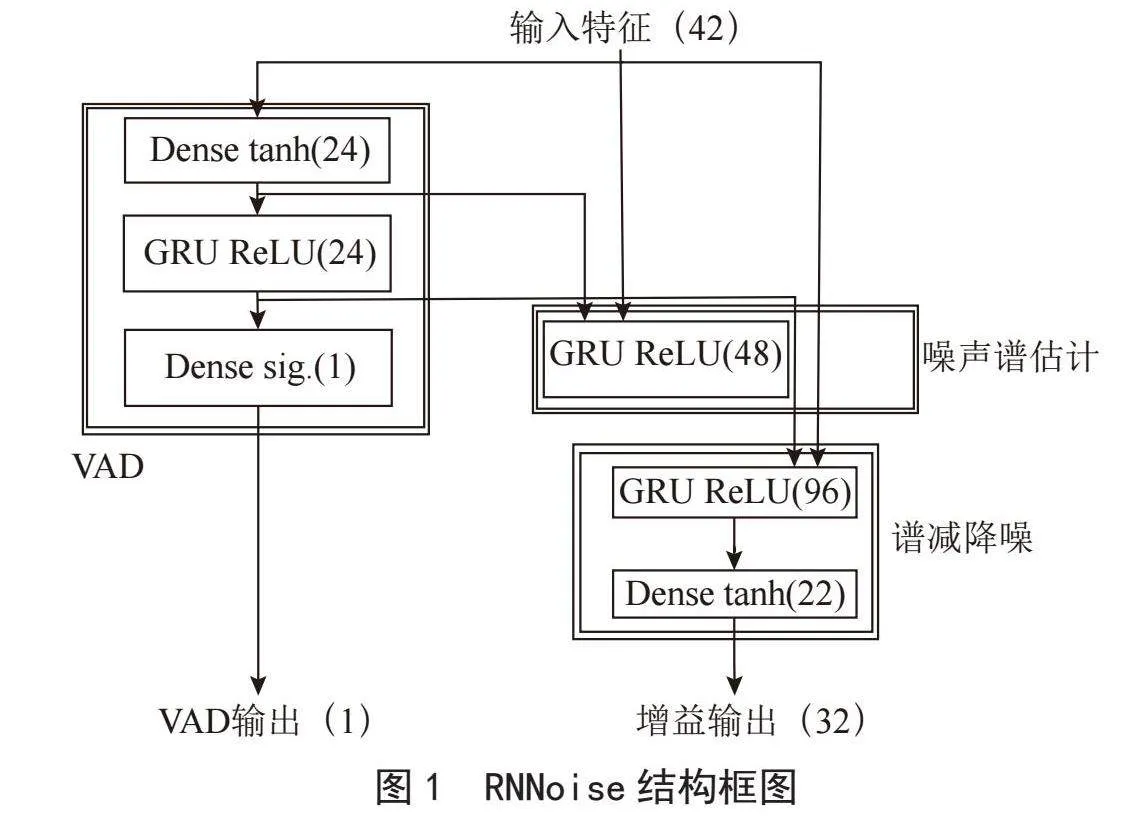
RNNoise算法由Valin[11]提出,按照传统的噪声抑制结果设计,如图1所示。传统结构分为三个部分:语音活动检测(VAD)、噪声频谱估计、谱减。因此RNNoise中涉及三个循环层,分别负责这三个模块。除此之外,该网络还包含一个VAD输出模块,用来保证相应的GRU能够区分噪声和语音,提升训练精度。
Valin假设信号中噪声和语音的频谱包络足够平坦,从而在较低分辨率的频带结构上进行降噪处理。RNNoise可通过较低的复杂度来实现高质量的语音增强。
大多数方法直接用神经网络估计frequency bins,而大量的输出需要设计大量的神经元,从而增加系统的复杂程度,因此需要调整方法。人耳对声音的感知是非线性的,对低频段更加敏感,基于Opus频带,使用Bark频率标度进行划分,在48 kHz采样率下划分出22个子带。由此提取出22维的BFCCs和前六个BFCCs的一阶和二阶时间导数,基音周期和频谱非平稳性度量参数,以及基音相关系数的DCT的前六个系数,一共包括了42个维度特征。
同时,计算理想临界频带增益作为网络的学习目标。可将其看成一种频带上IRM的形式:
(1)
其中,Es(a)为a内干净语音的能量,Ev(a)为噪声的能量。
根据频带划分,可将原先复杂的降噪任务看作一个长度为22的频率均衡器,通过改变子带上的值使噪声衰减,实现语音增强。
1.2" 语音增强系统工作流程
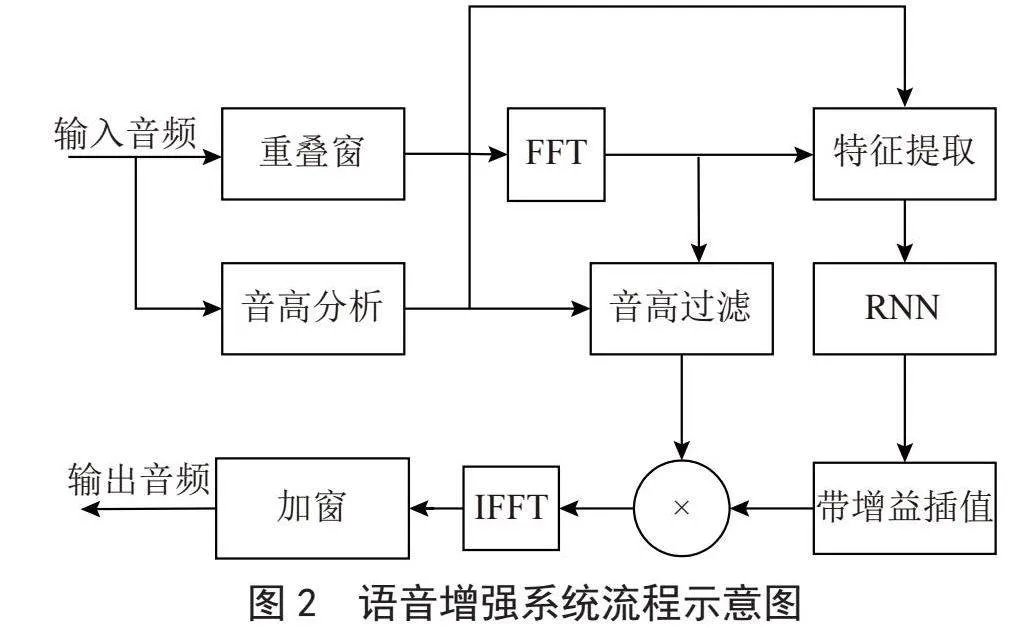
语音增强系统流程示意图如图2所示。主要处理循环基于10毫秒的窗口,重叠50%(偏移5毫秒)。分析和综合都使用相同的Vorbis窗口,满足PrincenBradley准则[12]。窗口定义为:
(2)
其中,N = 480为窗长。
在低分辨率的音频包络上使用RNN计算增益,完成大部分噪声抑制,同时使用音高梳滤波器衰减音高谐波之间的噪声来完成更精细的调整。
2" 基于树莓派的语音增强系统实现
2.1" 硬件整体构成
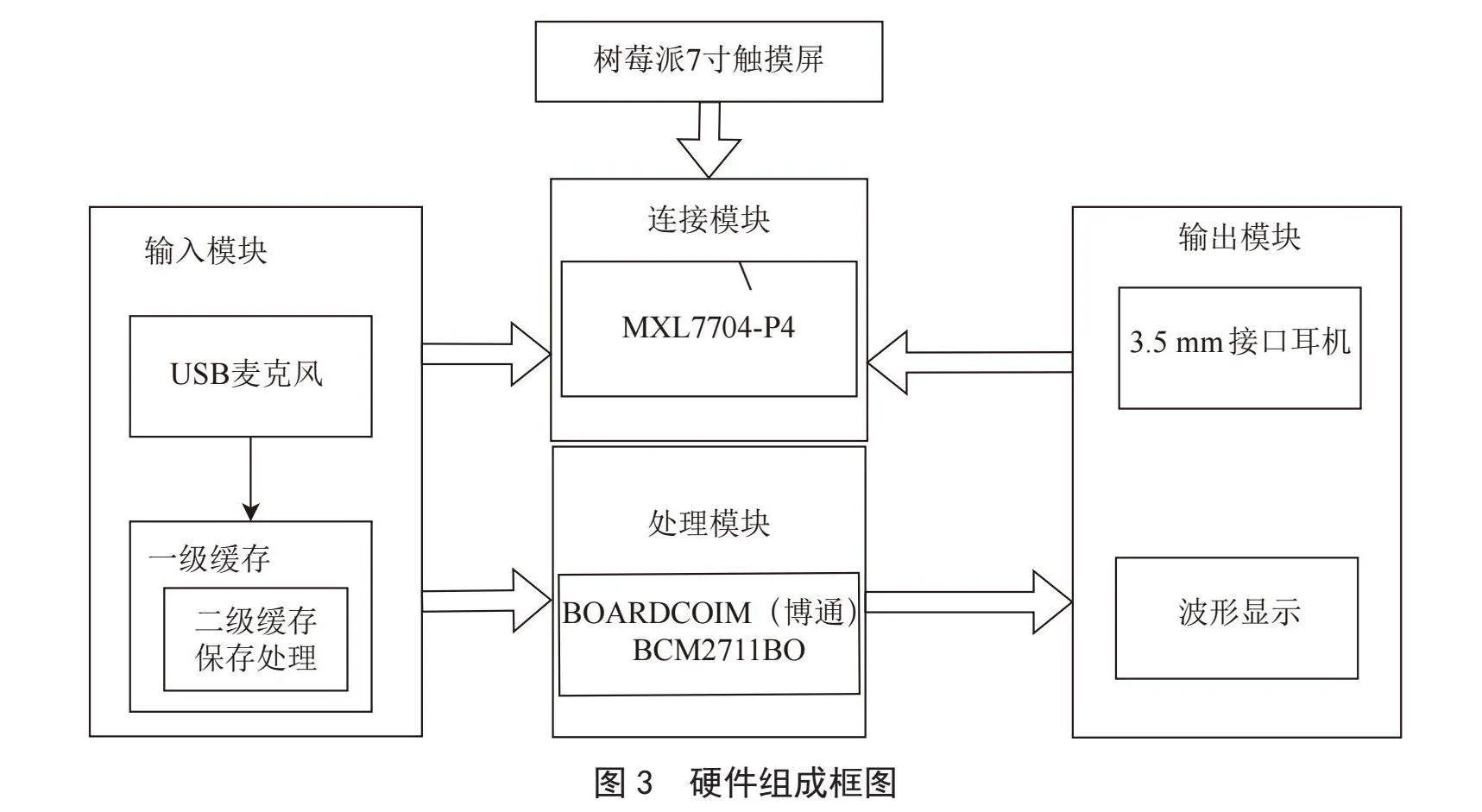
服务器端硬件的主要目的是为了实时采集语音,将语音增强后的音频提供给用户。软件中设计了调用硬件的可视化交互界面。我们选择用树莓派搭载USB麦克风和3.5 mm耳机当作服务器,完成对声音的收集,再通过树莓派处理,进行语音增强,最后播放给用户。硬件组成框图如图3所示。
其中树莓派作为处理核心,我们选择的是Raspberry Pi 4B版本,操作系统为官方提供的Raspberry Pi镜像系统,SD卡大小为16 GB。
2.2" 软件实现
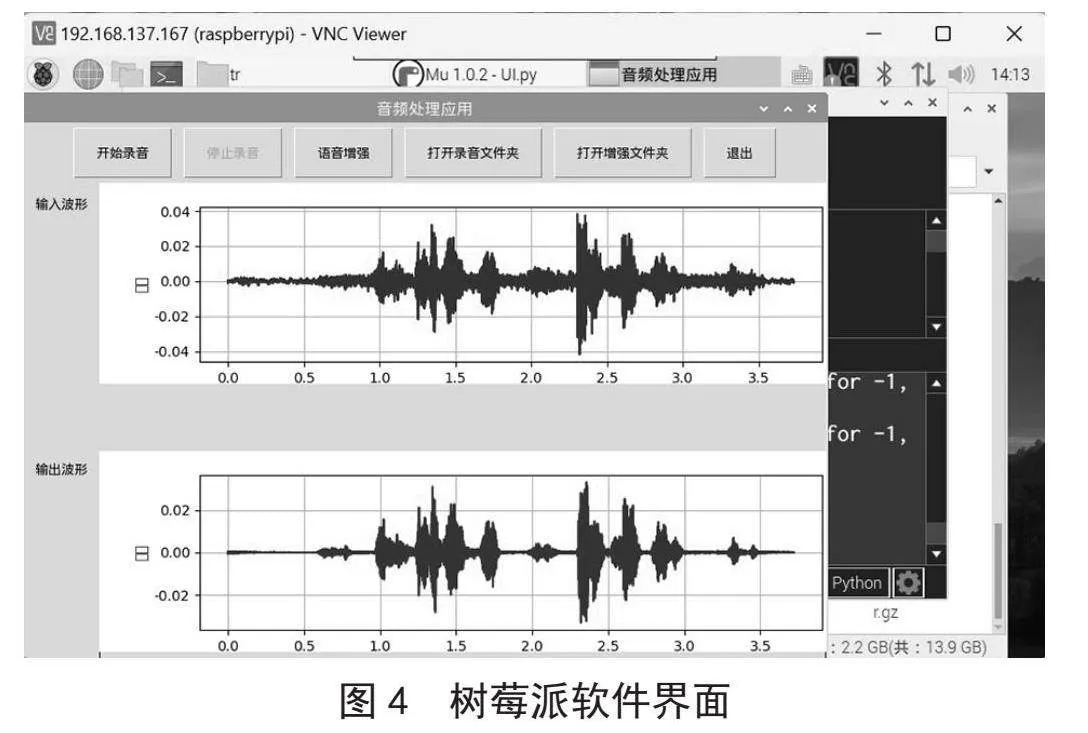
我们通过USB麦克风采集音频数据,在树莓派中完成语音增强任务,在屏幕上显示可视化界面,如图4所示是树莓派软件界面图,程序使用Python 3编写,调用训练后的RNNoise算法处理音频。因此软件分为底层运行程序与可视化界面程序两个部分。
如图5所示,可视化界面我们选择Python中tkinter库,交互界面分为四个部分:上部为菜单栏,根据用户不同的需求有不同的按键;在命令设置部分,通过用户点击产生不同的指令,树莓派后台得到指令并进行对应的处理;开始录音后弹窗显示实时波形图;并且开始实时语音增强处理,停止录音后在输入波形标签右侧显示输入音频波形和语音增强后对应输出波形; 通过打开文件夹方式可以直接显示出保存的输入和输出音频文件。
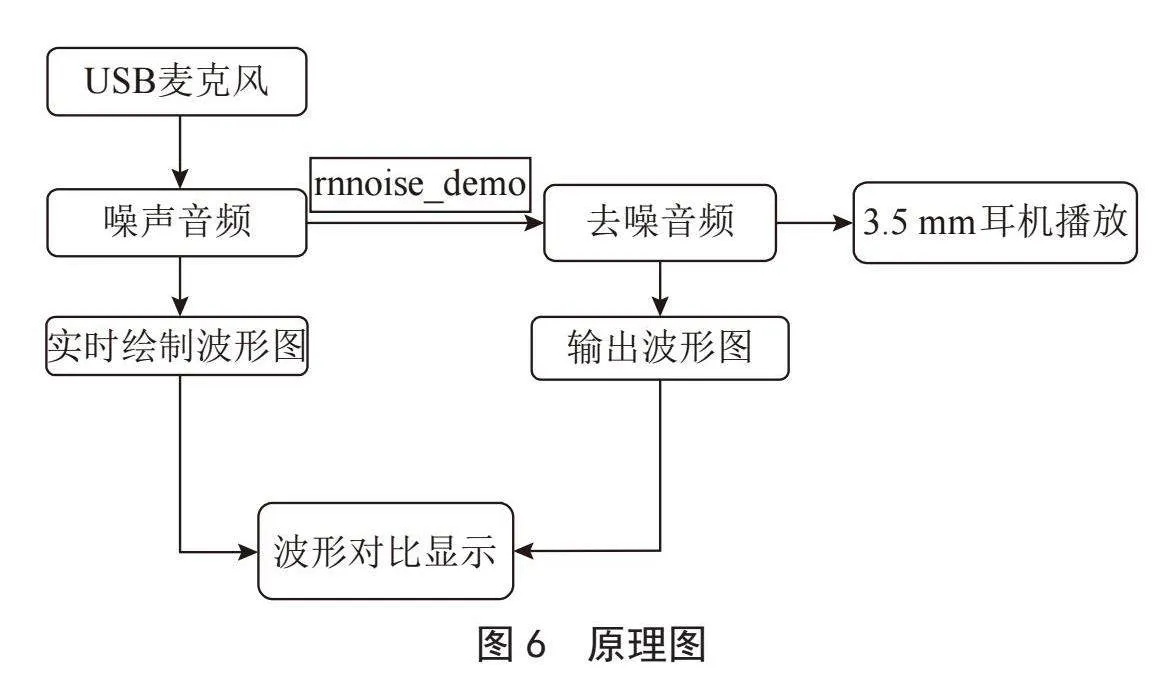
如图6所示,通过触摸屏可以独立显示并操作树莓派界面采用USB麦克风实现对声音的输入,通过3.5 mm耳机实现音频输出。原理图如下:
3" 实验与讨论
3.1" 实验设置
3.1.1" 测试数据构成
本实验使用到的干净语音数据集数据来自LibriSpeech,是一个阅读语音语料库,基于 LibriVox 的公共领域有声读物其中包含11 350名志愿者用多种语言阅读的10 000余条公共有声读物,并且从中筛选了65 000余条语音,得到的干净语音集总时长为560 h。
噪声数据我们选择使用NoiseX-92 噪声库,该噪声库包15种噪声,如汽车、人声、街道等常见的生活场景。
我们使用代码将每条干净语音与每种噪声,在-5 dB、0 dB、5 dB、10 dB、15 dB范围中的每一个SNR结合,生成在15种噪声下,各5种SNR的含噪语音库,使用Keras深度学习库在Python中完成。
3.1.2" 性能评价指标
为了更好展示语音增强后的效果,我们选择以下几种客观指标评价树莓派的语音增强性能:
1)客观语音质量评估 (Perceptual Evaluation of Speech Quality, PESQ)[13-14]。范围为1.0~4.5,在语言质量极差的情况下指标数值会小于1.0。
2)短时客观可懂度(Short-Time Objective Intelligibility, STOI)[15]。指标范围在0~1之间。
3)尺度不变信噪比(Scale-Invariant Signal-to-Noise Ratio, SISNR)[16]。其定义如下:
(3)
其中和s分别为增强语音和干净语音在时域的信号,为保证尺度不变性,和s均被标准化为零均值。
3.2" 实验结果及分析
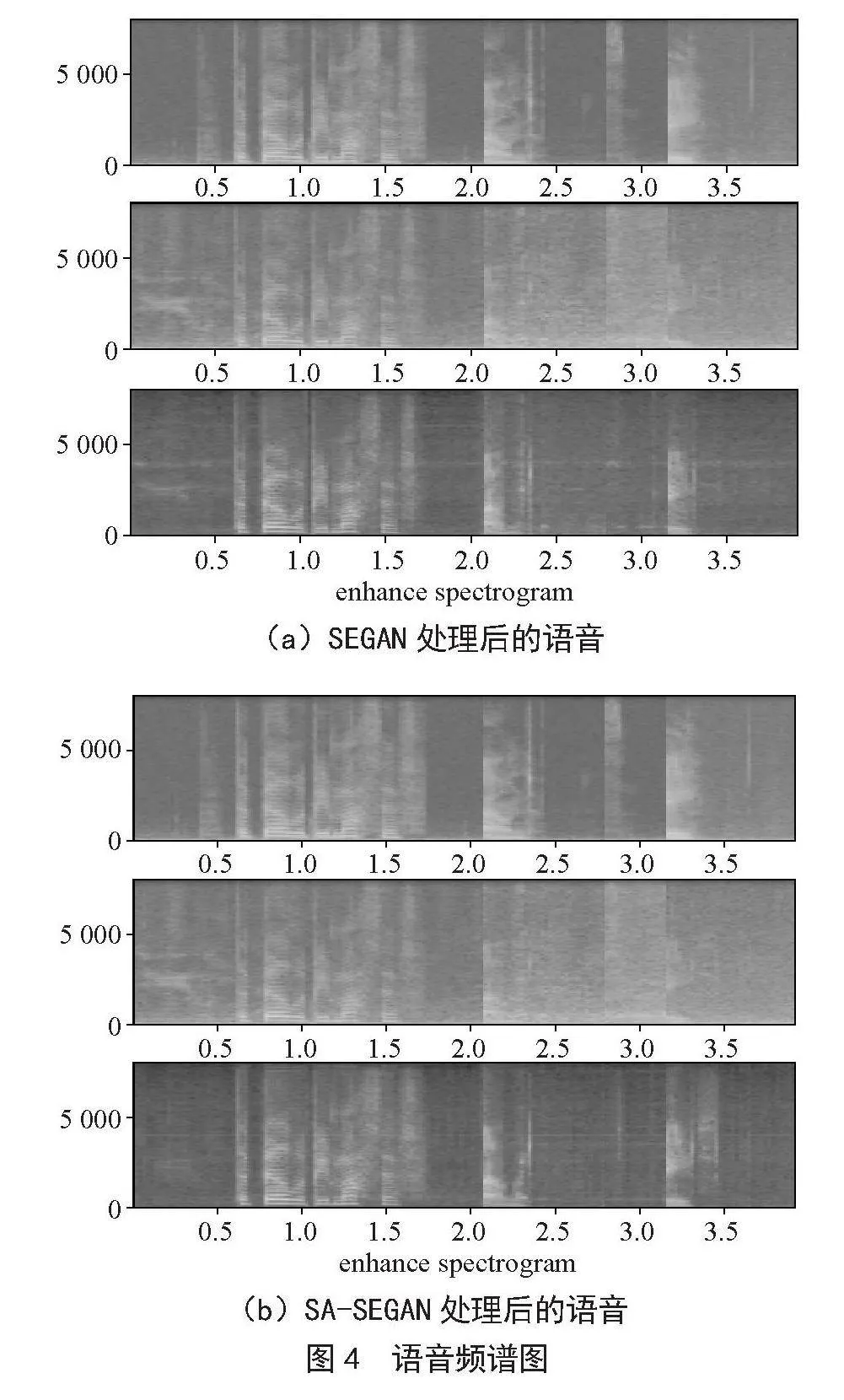
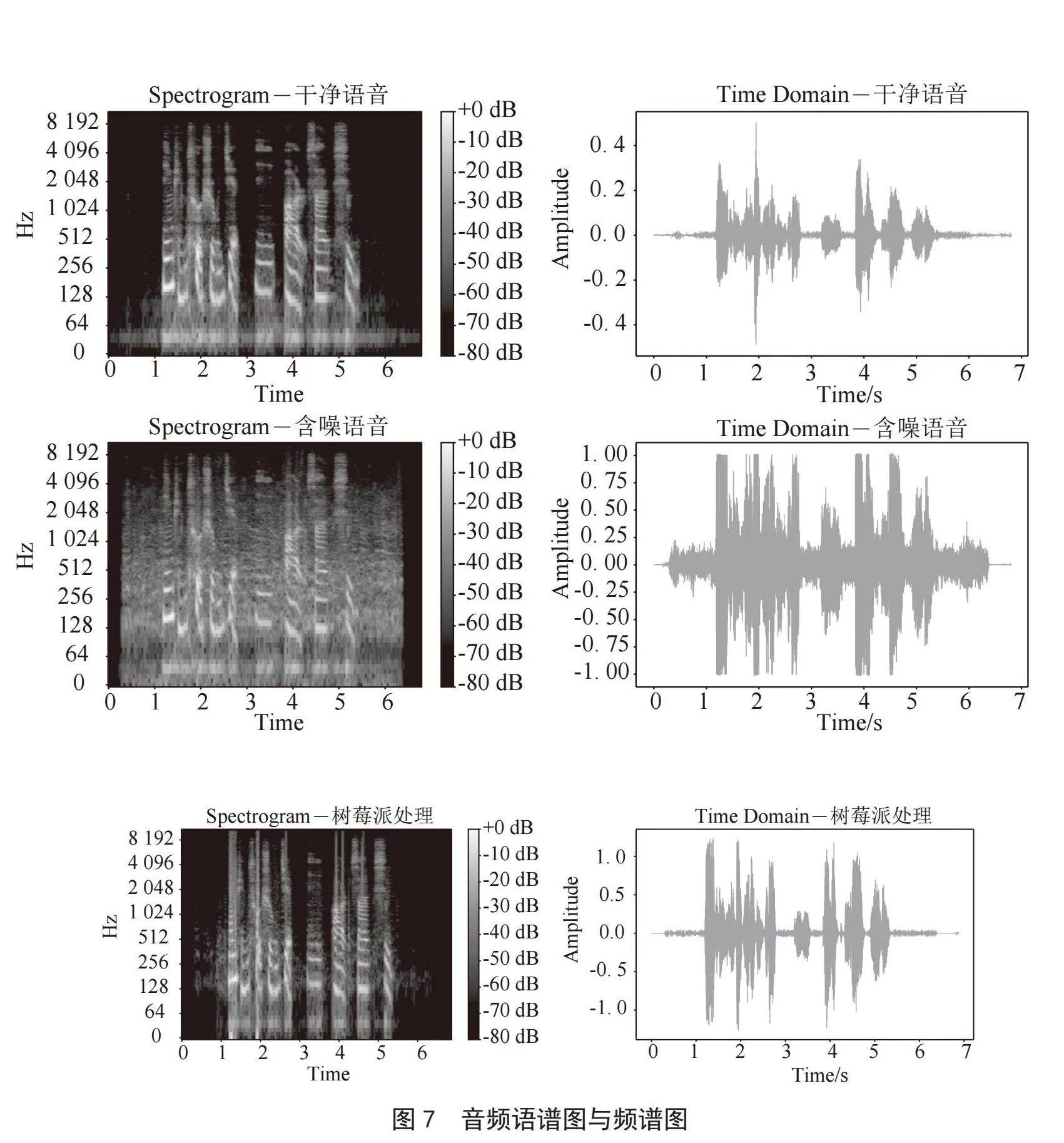
本实验将NOISEX-92噪声库中的Speech babble噪声作为噪音,使用信噪比设置为15 dB的含噪语音文件实验语音增强效果,如图7所示,从上至下分别为纯净语音、含噪语音和树莓派处理后的语谱图和时域频谱图,可看出,即便在强人声背景噪音下,本语音增强系统仍然可以有效滤除背景噪音,因为是实时以480个样本处理,所以在文件开头以及结尾处无语音部分,无法完全去除强烈的人声背景噪音,而在包含信息的语音部分,以及中间无语音段,均能实现良好的语音增强效果。
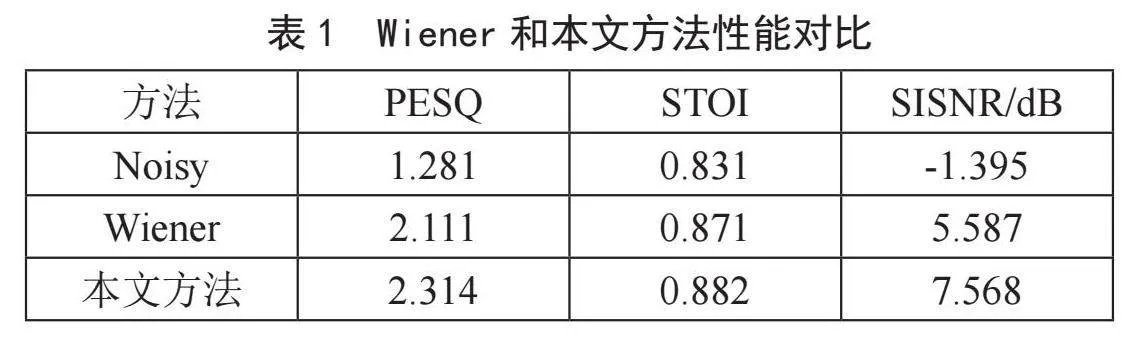
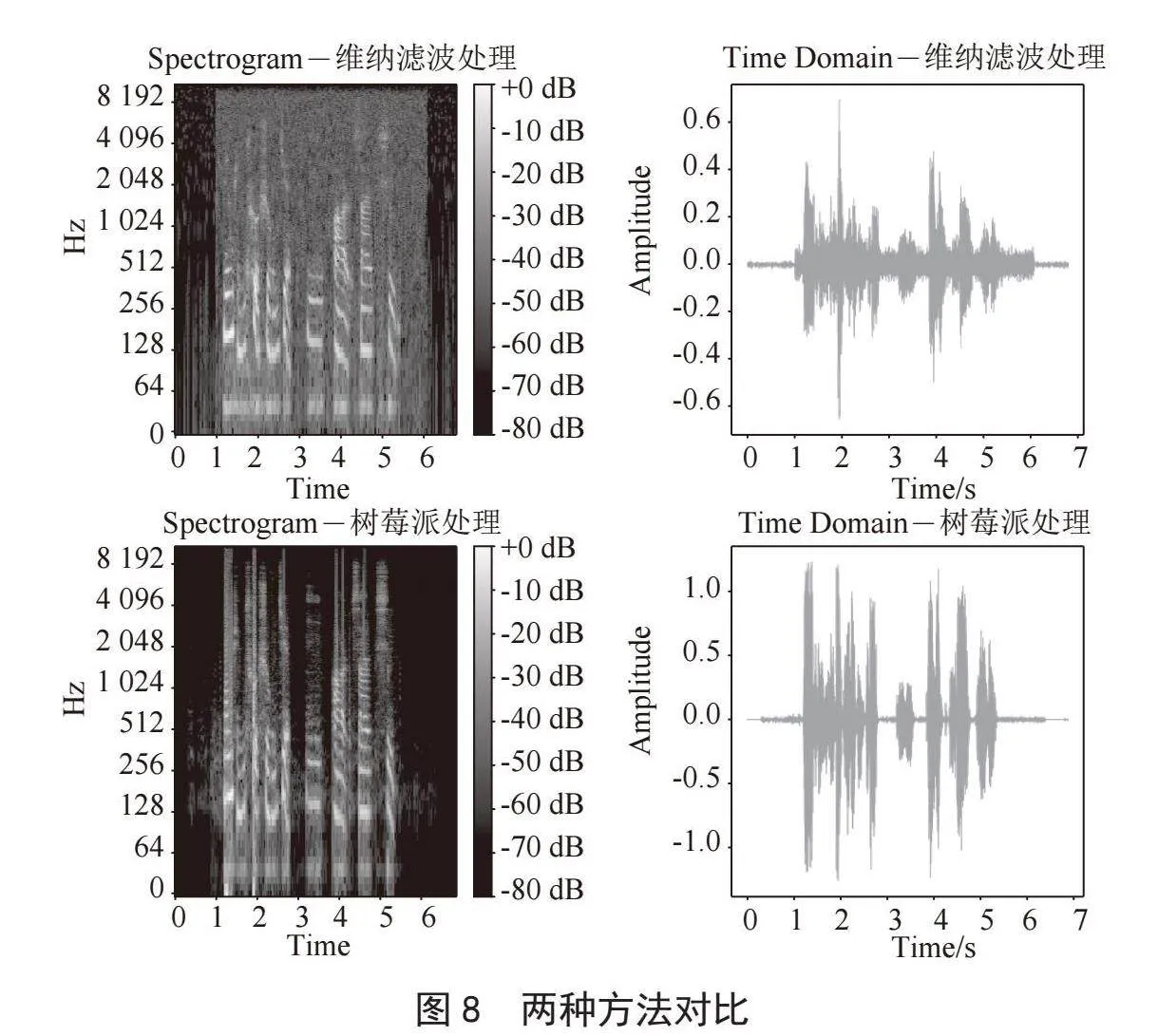
本实验选择使用维纳滤波法与搭载本系统的树莓派处理含噪语音文件进行对比,实验选择NOISEX-92噪声库中的Speech babble噪声作为背景,信噪比设置为15 dB的含噪语音文件进行实验。结果如图8所示,可以看出,面对以人声为背景的语音信号中,传统方法的降噪效果非常差,尤其在噪声的能量大于语音的能量时,几乎无法有效恢复语音,并且由于传统算法存在许多假设,在实时处理过程中难以解决瞬态噪声,因此留下大量底噪,语音增强效果并不好,经计算本实验中维纳滤波处理音频后PESQ为1.941,STOI为0.869。而本语音增强系统在噪声抑制方面得益于RNN的模拟,能够更好地消除人声噪声,有效的恢复语音,并且瞬态噪声的影响更小,处理后的音频PESQ为2.415,STOI为0.876。相比之下本系统能够更出色地完成语音增强任务。
我们使用训练集中未使用的语音和噪声数据来测试维纳滤波与本文方法处理的性能,并计算平均指标如表1所示,其中因为PESQ对音频的限制,我们将音频从48 kHz重采样至16 kHz后进行检验,本文方法处理后的音频与维纳滤波法相比,平均PESQ高0.203,平均STOI高0.011,平均SISNR高1.981,各项指标均高于维纳滤波法。
3.3" 算法复杂度分析
为了降低系统对硬件的要求,需要保持算法大小和复杂度低。我们假设语音和噪声的频谱包络足够平坦,不直接估计频谱幅度,而是估计理想的临界波段增益,这具有在0到1之间有界地显著优势,并且基于Opus频带,使用Bark频率标度进行划分,总共有22个子带。因此,我们的网络只需要[0,1]范围内的22个输出值,本算法包括总共215个单元、4个隐藏层,最大层96个单元。
可执行文件的大小主要由神经网络中215个单元所需的87 503个权重决定。为了尽可能小,选择将权重量化为8位。这使得在CPU的L2缓存中拟合所有权重成为可能。IFFT和每帧两个FFT需要大约7.5MFLOPs,音高搜索(以12 kHz运行)需要大约10 MFLOPs。同时由于在乘法加法操作中每帧仅使用每个权重一次,因此神经网络每帧需要175 000次浮点运算(我们将乘加视作两次运算),因此实时使用17.5 MFLOPs。该算法的总复杂度约为40 MFLOPs,与全频带语音编码器相当。
实际运行中,该系统在1.5 GHz ARMv7 Processor rev 3(v7l)(Raspberry Pi 4)单个核心上执行实时单通道48 kHz语音增强的占用率为14.8%,内存使用率为3.1%。可见本系统可以在树莓派CPU上低功耗运行。
4" 结" 论
本文设计的语音增强系统,整体设计仍采用传统信号处理框架设计,但在难以调谐的噪声抑制方面引入RNNoise实现实时单通道语音增强算法,将问题简化为仅计算22个理想的临界频带增益,再通过使用简单的音高滤波器处理频带的粗分辨率,由此实现低复杂性的智能语音增强系统,在消耗更低硬件性能的条件下仍能取得高质量的语音增强效果,在树莓派上也能轻松运行,具有较低的延迟性,并且质量明显高于纯信号处理的方法,有更广阔的应用场景以及更好的实际性能。
参考文献:
[1] BOLL S. Suppression of Acoustic Noise in Speech Using Spectral Subtraction [J].IEEE Transactions on Acoustics, Speech, and Signal Processing,1979,27(2):113-120.
[2] GRIFFIN D,LIM J. Signal Estimation from Modified Short-Time Fourier Transform [C]//ICASSP 83. IEEE International Conference on Acoustics, Speech, and Signal Processing.Boston:IEEE,1983:804-807.
[3] SELTZER M L,TASHEV I. A LOG-MMSE Adaptive Beamformer Using a Nonlinear Spatial Filter [C]//Proceedings of the 11th International Workshop on Acoustic Echo and Noise Control.Seattle:IWANEC,2008:1-4.
[4] MAAS A L,LE Q V,ONEIL T M,et al. Recurrent Neural Networks for Noise Reduction in Robust ASR [C]//INTERSPEECH 2012 ISCAs 13th Annual Conference.Portland:ISCA,2012:22-25.
[5] LIU D,SMARAGDIS P,KIM M. Experiments on Deep Learning for Speech Denoising [C]//INTERSPEECH 2014 Fifteenth Annual Conference of the International Speech Communication Association.Singapore:ISCA,2014:2685-2689.
[6] XU Y,DU J,DAI L R,et al. A Regression Approach to Speech Enhancement based on Deep Neural Networks [J].IEEE Transactions on Acoustics, Speech, and Signal Processing,2015,23(1):7–19.
[7] NARAYANAN A,WANG D L. Ideal Ratio Mask Estimation Using Deep Neural Networks for Robust Speech Recognition [C]//2013 IEEE International Conference on Acoustics,Speech and Signal Processing.Vancouver:IEEE,2013:7092–7096.
[8] ELMAN J L. Finding Structure in Time [J].Cognitive Science,1990,14(2):179-211.
[9] HOCHREITER S,SCHMIDHUBER J. Long Short-Term Memory [J].Neural Computation,1997,9(8):1735-1780.
[10] GERS F,SCHMIDHUBER J,CUMMINS F. Learning to Forget: Continual Prediction with LSTM [J].Neural Computation,2000,12(10):2451–2471.
[11] VALIN J M. A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement [C]//2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP).Vancouver:IEEE,2018:1-5.
[12] MONTGOMERY C. Vorbis I Specification [EB/OL].(2020-07-04).https://www.xiph.org/vorbis/doc/Vorbis_I_spec.html.
[13] ITU-T. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method Forend-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs [S/OL].(2001-02-23).https://www.itu.int/rec/T-REC-P.862/.
[14] RIX A W,BEERENDS J G,HOLLIER M P,et al. Perceptual Evaluation of Speech Quality(PESQ)-A New Method for Speech Quality Assessment of Telephone Networks and Codecs [C]//2001 IEEE International Conference on Acoustics, Speech,and Signal Processing.Salt Lake City:IEEE,2001:749-752.
[15] TAAL C H,HENDRIKS R C,HEUSDENS R,et al. An Algorithm for Intelligibility Prediction of Time-Frequency Weighted Noisy Speech [J].IEEE Transactions on Acoustics, Speech, and Signal Processing,2011,19(7):2125–2136.
[16] ISIK Y,ROUX J L,CHEN Z,et al. Single-Channel Multi-Speaker Separation Using Deep Clustering [C]//Interspeech 2016. San Francisco:ISCA,2016:545-549.
[17] PRINCEN J,BRADLEY A. Analysis/Synthesis Filter Bank Design Based on Time Domain Aliasing Cancellation [J].IEEE Transactions on Acoustics, Speech, and Signal Processing,1986,34(5):1153-1161.
[18] 孔凡留.基于深度学习的语音增强算法研究 [D].南京:东南大学,2021.
作者简介:陶然(2004—),男,汉族,江苏南京人,本科在读,研究方向:语音信号处理;朱润干(2004—),男,汉族,江苏泰州人,本科在读,研究方向:语音信号处理;秦怡童(2004—),女,汉族,河南洛阳人,本科在读,研究方向:深度学习;凌海东(2004—),男,汉族,安徽合肥人,本科在读,研究方向:语音信号处理。