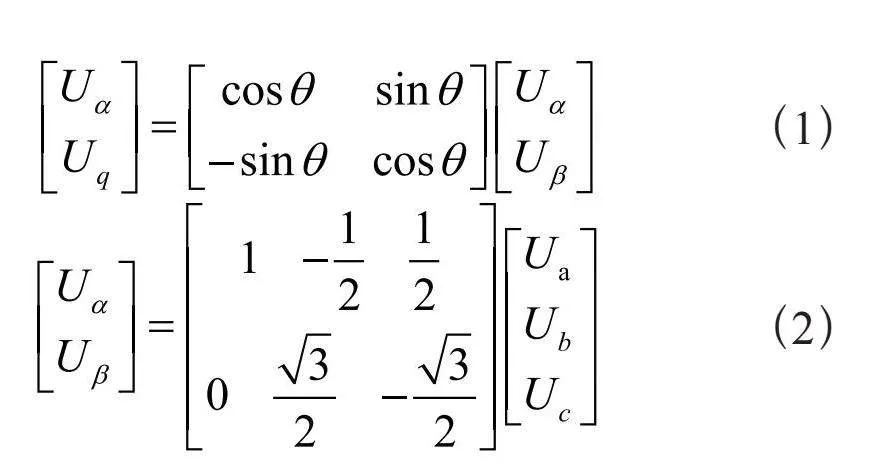
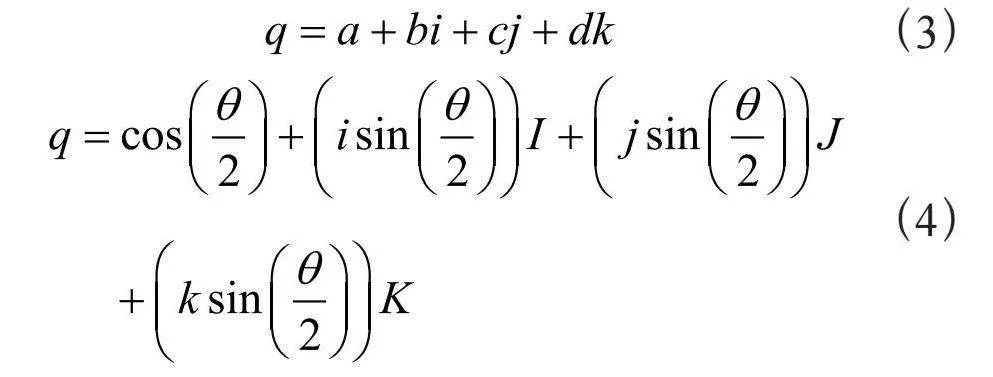

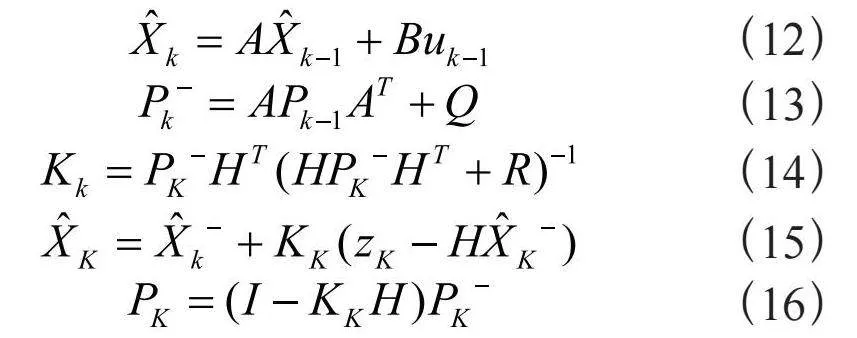
摘" 要:为了更好地传承传统文化皮影戏,提出了一套基于人体姿态估计的多维交互智能皮影系统,包括皮影机器人和虚拟皮影人。该系统应用了人体姿态估计网络,使用运动算法计算骨骼旋转角度,并设计了一款类人体机械结构应用到皮影上,可以与观众进行多维交互。为了优化皮影系统的流畅性,文章提出了针对皮影戏表演特点的基于透视投影约束的三维关键点优化方案和防遮挡策略。在输出上,增加了卡尔曼滤波,在Jetson AGX上将模型轻量化,并实现了TensorRT加速。经过这些模块处理后,皮影系统的识别准确度和动作流畅度都得到了不小于30%的提升,帧速率达到了33帧/秒。
关键词:深度学习;人体姿态估计;多维交互;皮影戏
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)03-0056-06
Multi-dimensional Interactive Intelligent Shadow Play System Based on Human Pose Estimation
ZHAO Jianwen1, ZENG Junying1, QIN Chuanbo1, ZHANG Zhongheng1, WU Jiantao1, WU Liu2, NI Zijun1
(1.School of Electronics and Information Engineering, Wuyi University, Jiangmen" 529020, China;
2.Guangzhou Preschool Teachers College, Guangzhou" 511300, China)
Abstract: In order to better inherit traditional culture shadow play, a multi-dimensional interactive intelligent shadow play system based on human pose estimation is proposed, including shadow play robot and virtual shadow play person. The system applies a human pose estimation network, uses a motion algorithm to calculate the rotation angle of the bone, and designs a human-like mechanical structure applied to the shadow play, which can interact with the audience in multiple dimensions. In order to optimize the fluency of the shadow play system, this paper proposes a three-dimensional key point optimization scheme and anti-occlusion strategy based on perspective projection constraint for the characteristics of shadow play performances. In the output, the Kalman filter is added, the model is lightweight on Jetson AGX, and TensorRT acceleration is realized. After processing by these modules, the recognition accuracy and action fluency of the shadow play system are improved by no less than 30%, and the frame rate reaches 33 FPS.
Keywords: Deep Learning; human pose estimation; multi-dimensional interaction; shadow play
0" 引" 言
当今社会,受社会环境影响,优秀传统文化逐渐淡出人们的视野,以皮影戏为代表的优秀传统文化面临着传播形式缺乏创新、吸引力不足等难题。本文将人工智能融入非遗文化传承,旨在为新时代传统文化发展注入新动力[1-2]。近年来,深度学习,尤其是人体姿态估计网络的发展[3-5],为皮影戏的创新提供了有力的工具。传统的皮影戏需要熟练的艺人手工操作,而皮影机器人和虚拟皮影数字人的创新使得操作变得更加简便,观众可以通过自身动作与皮影机器人或虚拟数字人进行交互。目前,基于深度学习的机器人已得到较为广泛的应用,主流方式为机械臂运动,例如采用一种可拓展的皮影机器人装置[6],崔鑫等[7]采用了机电一体化的设计。然而,随着时代的进步,上述方式已经不能满足当代需求,它们无法进行多维交互,而且皮影机器人的动作显得生硬。针对皮影戏传承难的问题,本文提出基于人体姿态评估的多维交互智能皮影系统,期望能通过该系统提高人们对传统文化的重视程度,活化传统文化,从而增强人们的文化自信。
1" 智能皮影系统设计
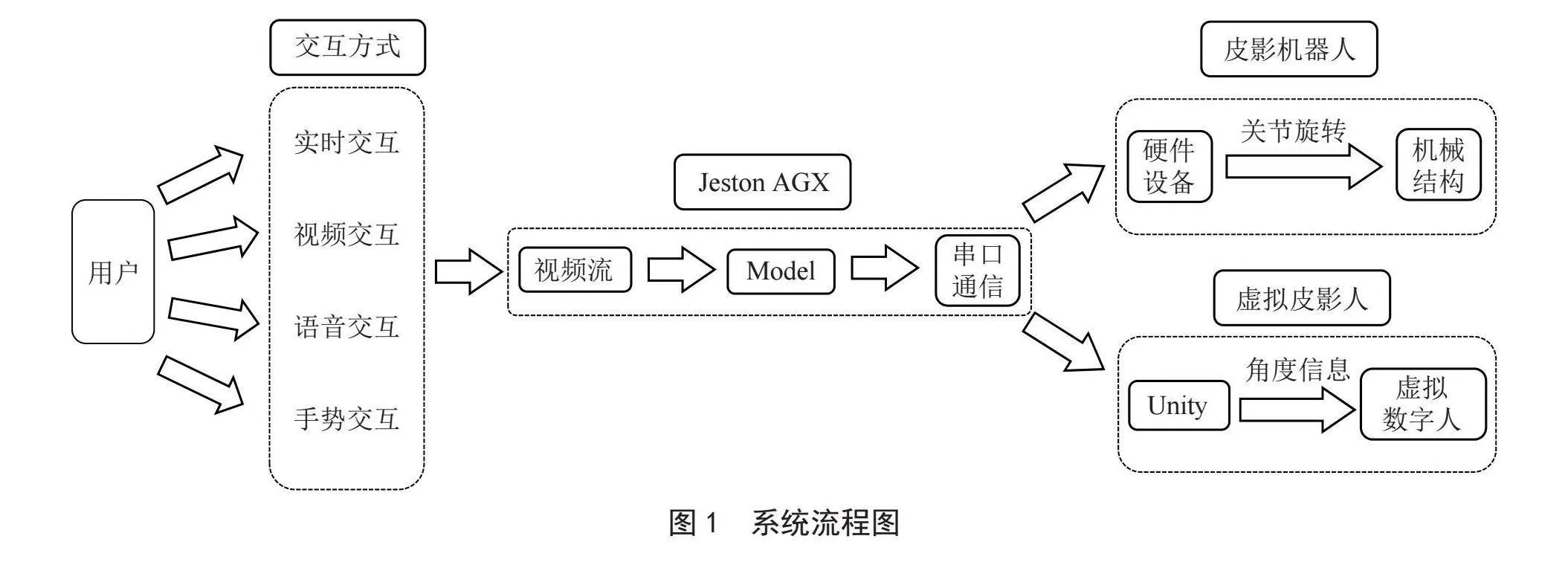
本文提出的智能皮影系统,主要包括图像采集模块、语音识别模块、显示终端、Jetson AGX、皮影机器人、虚拟数字人等。系统流程图如图1所示。
本套智能皮影系统可以进行多维交互,包括实时交互、视频交互、语音交互、手势交互等多种交互方式。该系统可以满足用户的以下需求:
1)实时交互。利用USB摄像头或CSI摄像头通过实时拍摄获取人体姿态估计检测所需要的数据,其分辨率不低于710P,传输速率不低于每秒30帧。摄像头捕获到画面后,传输至Jetson AGX的MediaPipe Holistic进行人体关键点提取。
2)视频交互。通过输入一段包含人体运动的视频到Jetson AGX,在Jetson AGX上将导入的视频流输入到MediaPipe Holistic做人体关键点提取,机器人据此表演视频中的人物动作。实时交互和视频交互均需对视频流信息进行人体姿态估计,然后将关键点信息进行基于几何算法、坐标系变换、向量法求角等的处理,算出各个关节之间的旋转角度,再通过串口通信,传送至下位机,实现皮影机器人与用户实时交互。
3)语音识别。皮影表演系统配备了语音设备模块,用户可录入特定的语音。开启语音识别表演模式后,LD3320语音识别模块接收到特定的语音信息,皮影表演机器人会做出系统预先编排好的表演动作。
4)手势交互。基于摄像头模块,采用2D摄像头进行二维手势识别,同时使用了动态手势识别技术。手势识别的实现,采用了MediaPipe Hands的手势识别框架[7-9],在开启手势识别表演模式时,摄像头采集手势图像信息再进行深度学习神经网络的识别。识别特定手势后,皮影机器人会表演特定的姿势或者做出预先设定好的动作。
1.1" 皮影机器人
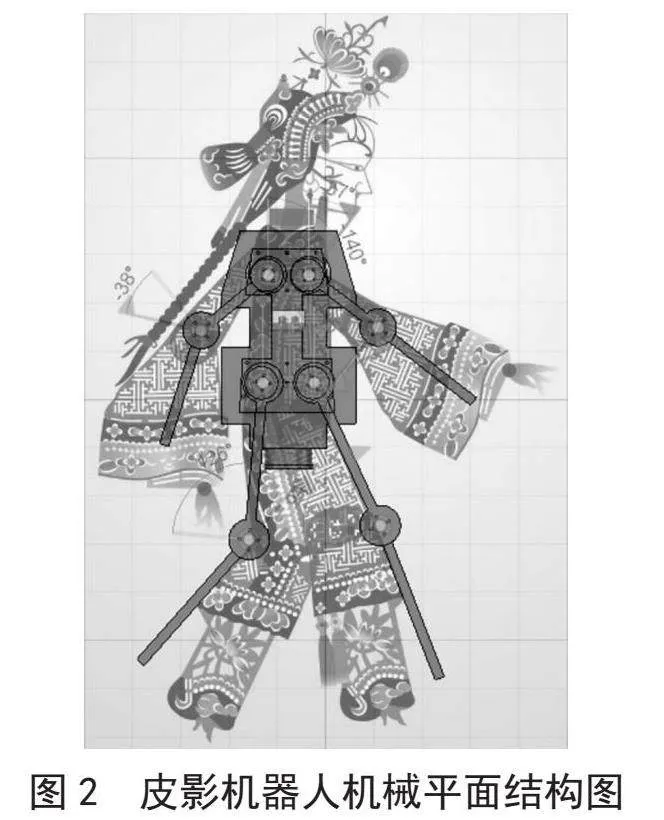
皮影机器人的机械结构主要由机械臂与BLDC三相无刷直流电机[10]组成。与传统皮影相比,皮影机器人采用夹层式设计,将八个三相无刷直流电机设置在机器人内部,实现正反面的灵活转换,增加了表演的多样性。
机器人在内部设置灯珠作为机器人表演时的透射光源,机身材料采用透明亚克力,既增加了机身透明度,又提高了机器人的表演效果,避免了传统皮影表演中光源遮挡被的缺陷。此外,机器人的机械臂杆采用了镂空设计,以减小机械臂的质量,从而达到减轻电机负载的目的。
这种设计有效地减轻了机器人长时间表演产生的负载过大、发热严重的问题。将三相无刷直流电机、机械臂与皮影三者组装在一起,通过单片机产生的三相电流控制三相无刷直流电机达到固定的速度、处于固定的位置状态并实现特定的摆动曲线。图2为皮影机器人机械平面结构图。
皮影机器人采用STM32H723VGT6作为主控芯片,电机驱动电路由DRV8313三相无刷电机驱动器构成。当上位机传来角度数据包时,本系统会对其进行解包,计算出电机需要达到的角度和力矩大小,再通过磁场定向控制(Field Oriented Control, FOC)算法模型[11]计算出所需的三相电压与电流。式(1)、式(2)可以表示三相电压Ua、Ub、Uc的计算过程,这些电压值将被用于驱动电机,使皮影机器人完成预定的动作。
(1)
(2)
1.2" 虚拟皮影人
一个皮影虚拟人模型是由大量的顶点组成的,顶点与顶点之间的位置是相对固定的。因此,手动将每一帧如此大量的顶点移动到指定位置,显然是一项难以完成的任务。
在这个虚拟骨骼结构中,每一个骨头都控制着附近区域的顶点。通过建立父子关系,使一个物体的移动服从另一个物体。这样,当骨头移动时,它控制的顶点也会随之移动。这种设计使得我们只需要移动部分骨骼,就可以达到符合人体动力学的效果。
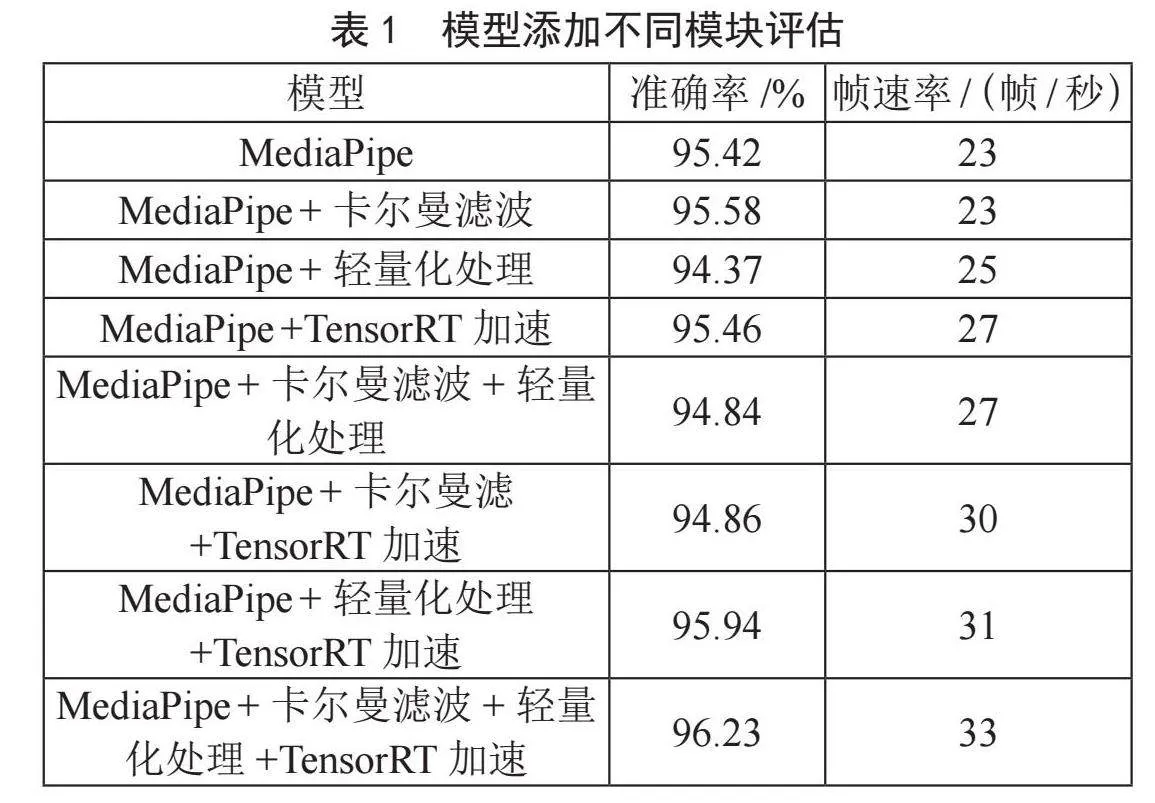
通过蒙皮操作将骨骼和模型结合起来,最后通过刷新权重,分配这些骨头对每个顶点的控制权,以防止模型发生不自然的扭曲,从而实现更为自然的动画效果。最终,我们可以通过驱动骨骼来调整人物模型的动作。图3为虚拟皮影人框架图。
本文在Unity3D中建立虚拟皮影人开发,方便部署到各个平台应用,如Linux、Android等。同时,配置了物理引擎,加入了质量、速度、摩擦、空气阻力等各种物理量,可高度模拟真实世界中的物理效果,有效还原皮影的打斗场景及打斗动作效果。为了实现这一目标,本文将Unity3D与关键点识别模型MediaPipe Holistic进行了端对端的连接。本系统可以实时接收模型识别到的三维坐标点信息,并通过预设的算法实现预测坐标到骨骼坐标的转换。这种转换是通过关键点的三维坐标信息到Unity3D的映射操作实现的。
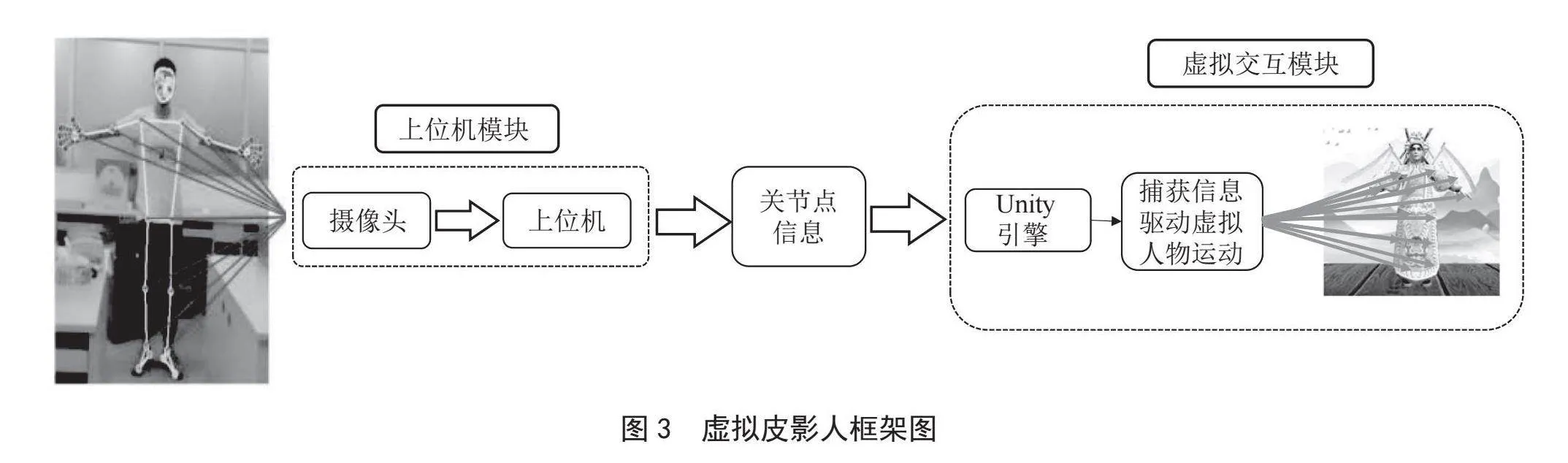
通过这种映射,系统可以实时更新皮影人物模型的骨骼坐标状态,从而驱动皮影人物模型进行模仿运动。这个模型不仅具有高度的真实感,而且具有很强的交互性,为用户提供了一种全新的皮影戏观赏体验,如图4所示。
在Unity3D中,需要自己逐个计算关节与关节之间形成的夹角。为解决使用欧拉角计算旋转时会出现的万向锁问题,可使用四元数矩阵来表示骨骼相对于父骨骼的旋转。通过使用四元数矩阵,可以在骨骼层次结构中更稳定地计算和应用旋转变换,确保物体在旋转过程中不会出现不自然的扭曲或翻转。在动画和姿势控制中,通过计算骨骼的四元数偏移量,可以更精确地调整骨骼的朝向,使其更符合期望的动作效果。
式(3)则表示在三维空间中一个四元数的表示,其中a,b,c,d为实数部分和虚数部分的系数。四元数的实数部分a通常用于表示旋转的角度,而虚数部分则表示旋转轴的方向。一个单位四元数表示一个旋转。四元数的旋转运算可以通过式(4)表示,其中,θ为旋转的角度,I,J,K为单位向量,表示旋转轴的方向。
(3)
(4)
旋转的基本原理是通过四元数的乘法来进行组合。给定两个四元数和,它们的乘积可以通过式(5)~式(8)计算:
(5)
(6)
(7)
(8)
通过将两个旋转用四元数表示,可以通过乘法运算合并它们的旋转效果。四元数的使用有助于避免由欧拉角带来的问题,提供更可靠和精确的旋转表示。
1.3" 算法设计
在算法设计中,采用MediaPipe Holistic算法作为人体关键点提取模型,以解决关键点三维坐标信息的识别与提取问题,并处理视频流分辨率、帧率问题。后续,对提取到的坐标信息基于物理动学方程使用向量法进行分析与计算,以得到关节运动时的角度信息[12-15]。
系统的运动算法采用向量法计算关节转动角度,通过二维向量角公式求解对应骨骼之间的角度信息,这简化了算法模型,降低了计算过程中的参数量,提升了运算效率。本文设计了一套皮影运动算法,用于确定任务模型骨骼旋转量,计算并估计根关节的位置以及各个关节的旋转信息。算法中,节点的Z轴和Y轴方向在运动过程中始终保持相互垂直,以达到精准指向。为保证运动方向的正确,将所有的关节都利用初始旋转量(InitRotation)做了当前关节的旋转量(LookRotation)对齐,得到了一个中间矩阵(Intermediate matrix),通过Intermediate matrix,就能够在骨骼驱动的过程中使各个骨骼点的坐标系统一起来。对于某些特定的关节,需要单独设置用计算中间变换矩阵关节旋转量(LookRotation)信息,在实际模型中做了躯干、头和手掌的独立中间变换矩阵。式(9)可表示为LookRotation计算公式,LR表示当前关节旋转量(LookRotation),IR表示初始旋转量(InitRotation),IM表示中间矩阵(Intermediate matrix)。
(9)
通过LookRotation公式,得到了每个关节的对齐矩阵信息,再通过Rotation(旋转量)计算公式,得到每个关节的当前旋转信息,对齐矩阵是从初始姿态中获取的,通过深度学习预测的3D关节坐标中计算对应的LookRotation参数,再通过Rotation计算公式,计算出实时的关节旋转量,模型即可根据实时的当前Rotation进行动作模仿。式(10)可表示为Rotation计算公式,R表示旋转量(Rotation),LR表示当前关节旋转量(LookRotation),IM表示中间矩阵(Intermediate matrix)。
(10)
2" 系统改进与测试
对于原始的模型来说,皮影系统的帧速率(FPS)和交互性能还达不到理想的要求,对此本文进行了一系列的改进。
在人体姿态估计中,姿态、照明、遮挡和低分辨率等情况都是任务中的关键障碍。为此,针对皮影的表演特点,本文提出了新的人体关键点防遮挡策略。当人体的某一个关键点被物体遮挡时,防遮挡算法可以将遮挡点的对称点反转到遮挡点,具体做法为将对称点的关节转动量反映到遮挡点的关节转动量上,可以实现对称点与遮挡点同步运动。即使人体某个关键点被物体短暂地遮挡了,依然可以预测人体关键点的位置,不至于丢失关键点位置,实现了皮影机器人能够更流畅地做出动作。
同时,在实际应用场景中,皮影系统的摄像头选用的是成本更低的单目摄像头,因此系统应将二维的检测点转换成三维立体的信息。
本文提出了针对皮影基于透视投影约束的三维关键点优化方案[16]。首先,对输入图像中的噪声利用透视投影矫正方法进行优化处理;其次,在更紧凑的运动空间中,用人体拓扑对关节运动进行显式分解,得到更紧凑、更易于估计的三维静态结构,进一步估计三维关键点信息;最后,剔除处理得到的不可靠估计的3D关键点信息并细化关键点信息。
通过三维关键点优化方案,系统能够在不同环境中识别人体运动,减少了背景和噪声的干扰,更准确地捕捉到人体姿态和动作,同时忽略背景干扰,从而提高了系统的稳定性和可靠性,能够适应更极端的环境,为各种实际应用场景提供了更为可靠的解决方案。
式(11)为投影变换矩阵M,其中N为摄像头到近裁剪平面的距离,F为摄像头到远裁剪平面的距离。
(11)
带有噪声的情况下,仍然可以实现实时人体姿态估计的效果。在加入卡尔曼滤波处理后,能够有效消除皮影系统出现过多抖动的情况,使皮影系统的动作更加流畅。式(12)~式(16)分别为计算向前推算状态变量、卡尔曼增益、zk更新估计、误差协方差、向前推算误差协方差的计算式:
(12)
(13)
(14)
(15)
(16)
在算法计算层面,采用了权值共享和权重矩阵剪枝策略。在权值量化层面,将模型的权值参数从32位浮点数量化为8位的定点数,使参数大小缩小为原来的1/4,整个模型的大小也随之缩小为原来的1/4,从而有效地减少网络参数计算量,加快运算速度[17-19]。
由于本皮影系统选用的上位机为Jetson AGX,因此本文使用TensorRT进行加速[20-21],使得训练的模型在测试阶段的速度加快。由于在Jetson AGX上实时推理人体姿态模型的检测速度较慢,在应用TensorRT加速后,能够有效地提升模型在Jetson AGX上的运行速度。
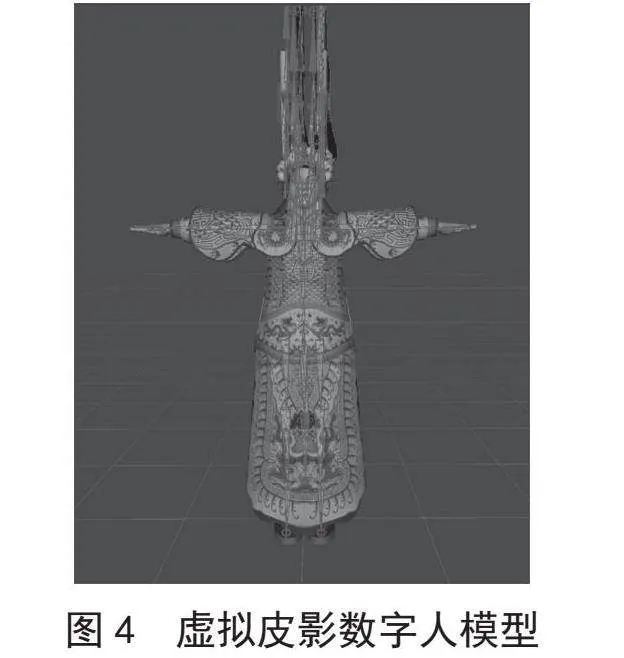
为确保本文所提出的各个模块是有效的,针对各个模块进行了实验对比。实验对比结果显示,原模型MediaPipe的准确率为95.42%,帧速率为23帧/秒;在添加了卡尔曼滤波处理、模型轻量化处理、TensorRT加速混合模块后,准确率为96.23%,帧速率FPS为33,说明本文添加的模块是可行且有效的。实验结果如表1所示。
3" 结" 论
本文提出了一套基于人体姿态估计的多维交互智能皮影系统。首先,该皮影系统由皮影机器人和虚拟皮影两大部分组成,具备实时交互、视频交互、语音交互、手势交互等多种交互方式。由于皮影运动对实时性要求较高,因此本文训练出的人体姿态估计模型具有较高的精度和较快的帧速率。同时,本研究提出了防遮挡策略、基于透视投影约束的三维关键点优化方案、卡尔曼滤波等多模块,并将它们应用到皮影系统上。经过实验验证,本文所提出的模型在皮影系统上的准确率和帧速率(FPS)均优于原模型,由此论证了本文模型改进的正确性。
本文的主要贡献如下:一是创造性地将类人体机械结构与传统皮影相结合,开发了新的机械结构,为未来的研究提供了新的发展方向;二是利用人体姿态估计模型和运动算法计算骨骼旋转角度,使皮影系统具有较高的自由度。基于人体姿态估计的皮影系统为传统文化传承提供了新的思路,具有重要的应用价值。
参考文献:
[1] 欧阳军喜,崔春雪.中国传统文化与社会主义核心价值观的培育 [J].山东社会科学,2013(3):11-15.
[2] 李宗桂.试论中国优秀传统文化的内涵 [J].学术研究,2013(11):35-39.
[3] 张宇,温光照,米思娅,等.基于深度学习的二维人体姿态估计综述 [J].软件学报,2022,33(11):4173-4191.
[4] 孔英会,秦胤峰,张珂.深度学习二维人体姿态估计方法综述 [J].中国图象图形学报,2023,28(7):1965-1989.
[5] 曹晓瑜,夏端峰.基于深度学习的人体姿态估计方法综述 [J].现代信息科技,2022,6(23):1-6.
[6] 廖海燕,王婧怡,希治远,等.一种用于皮影戏表演的可扩展机器人装置 [J].电子制作,2022,30(18):83-85+89.
[7] 崔鑫,王新怀,徐茵,等.机电一体化的智能皮影表演系统 [J].电子产品世界,2020,27(9):50-52.
[8] 倪广兴,徐华,王超.融合改进YOLOv5及Mediapipe的手势识别研究[J].计算机工程与应用,2024,60(7):108-118.
[9] 陈敬宇,徐金,罗容,等.基于手势识别的3D人机交互系统 [J].现代信息科技,2023,7(22):88-91.
[10] 王枫.无传感器无刷直流电机控制系统研究与设计 [D].苏州:苏州大学,2020.
[11] LIU Z C,LI Y D,ZHENG Z D. A Review of Drive Techniques for Multiphase Machines [J].CES Transactions on Electrical Machines and Systems,2018,2(2): 243-251.
[12] 王楚.仿人机械臂的运动规划与优化算法研究 [D].杭州:浙江大学,2018.
[13] 袁蒙恩.基于单目视觉估计的机械臂运动规划算法 [D].开封:河南大学,2020.
[14] 黄水华.多约束下的机械臂运动控制算法研究 [D].杭州:浙江大学,2016.
[15] 朱宇辉.基于Kinect的机械臂人机交互控制系统设计 [D].绵阳:西南科技大学,2016.
[16] 张峻宁,苏群星,刘鹏远,等.一种基于透视投影的单目3D目标检测网络 [J].机器人,2020,42(3):278-288.
[17] 符惠桐.基于深度学习的目标识别轻量化模型研究 [D].西安:西安工业大学,2022.
[18] 袁哲明,袁鸿杰,言雨璇,等.基于深度学习的轻量化田间昆虫识别及分类模型 [J].吉林大学学报:工学版,2021,51(3):1131-1139.
[19] XIONG B,SUN Z Z,WANG J,et al. A Lightweight Model for Ship Detection and Recognition in Complex-Scene SAR Images [J]. Remote Sensing,2022,14(23):6053.
[20] LIU Z Q,DING D. TensorRT Acceleration Based on Deep Learning OFDM Channel Compensation [J/OL].Journal of Physics: Conference Series,2022,2303(1):012047[2025-02-14].https://iopscience.iop.org/article/10.1088/1742-6596/2303/1/012047.
[21] YEGULALP S. Nvidias New TensorRT Speeds Machine Learning Predictions [EB/OL].[2025-02-14].https://www.infoworld.com/article/2253746/nvidias-new-tensorrt-speeds-machine-learning-predictions.html.
作者简介:赵健文(2004—),男,汉族,广东江门人,硕士研究生在读,研究方向:深度学习理论与应用、计算机视觉;曾军英(1977—),男,汉族,江西赣州人,教授,博士,研究方向:图像处理、深度学习理论与应用、信息处理、机器视觉;通信作者:秦传波(1982—),男,汉族,安徽宿州人,副教授,博士,研究方向:医学影像处理、生物特征识别。